Merge branch 'ggml-org:master' into power-law-sampler
This commit is contained in:
commit
f4703d422c
|
|
@ -70,6 +70,7 @@ jobs:
|
|||
with:
|
||||
key: macOS-latest-cmake-arm64
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
|
|
@ -106,6 +107,7 @@ jobs:
|
|||
with:
|
||||
key: macOS-latest-cmake-x64
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
|
|
@ -142,6 +144,7 @@ jobs:
|
|||
with:
|
||||
key: macOS-latest-cmake-arm64-webgpu
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dawn Dependency
|
||||
id: dawn-depends
|
||||
|
|
@ -195,6 +198,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-cpu-cmake-${{ matrix.build }}
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build Dependencies
|
||||
id: build_depends
|
||||
|
|
@ -276,6 +280,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-latest-cmake-sanitizer-${{ matrix.sanitizer }}
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -396,6 +401,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-24-cmake-vulkan-deb
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -431,6 +437,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-24-cmake-vulkan
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -490,6 +497,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-24-cmake-webgpu
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -562,6 +570,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-latest-wasm-webgpu
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Install Emscripten
|
||||
run: |
|
||||
|
|
@ -609,6 +618,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-22-cmake-hip
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build with native CMake HIP support
|
||||
id: cmake_build
|
||||
|
|
@ -641,6 +651,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-22-cmake-musa
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build with native CMake MUSA support
|
||||
id: cmake_build
|
||||
|
|
@ -688,6 +699,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-22-cmake-sycl
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
|
|
@ -738,6 +750,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-22-cmake-sycl-fp16
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
|
|
@ -771,6 +784,7 @@ jobs:
|
|||
with:
|
||||
key: macOS-latest-cmake-ios
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
|
|
@ -802,6 +816,7 @@ jobs:
|
|||
with:
|
||||
key: macOS-latest-cmake-tvos
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
|
|
@ -863,6 +878,7 @@ jobs:
|
|||
with:
|
||||
key: macOS-latest-swift
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Download xcframework artifact
|
||||
uses: actions/download-artifact@v4
|
||||
|
|
@ -905,6 +921,7 @@ jobs:
|
|||
key: windows-msys2
|
||||
variant: ccache
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Setup ${{ matrix.sys }}
|
||||
uses: msys2/setup-msys2@v2
|
||||
|
|
@ -973,6 +990,7 @@ jobs:
|
|||
key: windows-latest-cmake-${{ matrix.build }}
|
||||
variant: ccache
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Download OpenBLAS
|
||||
id: get_openblas
|
||||
|
|
@ -1077,6 +1095,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-latest-cmake-cuda
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build with CMake
|
||||
run: |
|
||||
|
|
@ -1109,6 +1128,7 @@ jobs:
|
|||
key: windows-cuda-${{ matrix.cuda }}
|
||||
variant: ccache
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Install Cuda Toolkit
|
||||
uses: ./.github/actions/windows-setup-cuda
|
||||
|
|
@ -1160,6 +1180,7 @@ jobs:
|
|||
key: windows-latest-cmake-sycl
|
||||
variant: ccache
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Install
|
||||
run: |
|
||||
|
|
@ -1221,6 +1242,7 @@ jobs:
|
|||
with:
|
||||
key: ${{ github.job }}
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
|
|
@ -1466,6 +1488,7 @@ jobs:
|
|||
with:
|
||||
key: ggml-ci-x64-cpu-low-perf
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -1491,6 +1514,7 @@ jobs:
|
|||
with:
|
||||
key: ggml-ci-arm64-cpu-low-perf
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -1516,6 +1540,7 @@ jobs:
|
|||
with:
|
||||
key: ggml-ci-x64-cpu-high-perf
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -1541,6 +1566,7 @@ jobs:
|
|||
with:
|
||||
key: ggml-ci-arm64-cpu-high-perf
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -1566,6 +1592,7 @@ jobs:
|
|||
with:
|
||||
key: ggml-ci-arm64-cpu-high-perf-sve
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -1701,6 +1728,7 @@ jobs:
|
|||
with:
|
||||
key: ggml-ci-arm64-cpu-kleidiai
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -2084,6 +2112,7 @@ jobs:
|
|||
with:
|
||||
key: ggml-ci-arm64-graviton4-kleidiai
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Test
|
||||
id: ggml-ci
|
||||
|
|
|
|||
|
|
@ -66,16 +66,9 @@ jobs:
|
|||
id: pack_artifacts
|
||||
run: |
|
||||
cp LICENSE ./build/bin/
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-bin-macos-arm64.zip ./build/bin/*
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-macos-arm64.tar.gz -s ",./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-macos-arm64.zip
|
||||
name: llama-bin-macos-arm64.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-macos-arm64.tar.gz
|
||||
|
|
@ -127,16 +120,9 @@ jobs:
|
|||
id: pack_artifacts
|
||||
run: |
|
||||
cp LICENSE ./build/bin/
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-bin-macos-x64.zip ./build/bin/*
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-macos-x64.tar.gz -s ",./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-macos-x64.zip
|
||||
name: llama-bin-macos-x64.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-macos-x64.tar.gz
|
||||
|
|
@ -196,16 +182,9 @@ jobs:
|
|||
id: pack_artifacts
|
||||
run: |
|
||||
cp LICENSE ./build/bin/
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-bin-ubuntu-${{ matrix.build }}.zip ./build/bin/*
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-ubuntu-${{ matrix.build }}.tar.gz --transform "s,./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-ubuntu-${{ matrix.build }}.zip
|
||||
name: llama-bin-ubuntu-${{ matrix.build }}.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-ubuntu-${{ matrix.build }}.tar.gz
|
||||
|
|
@ -256,16 +235,9 @@ jobs:
|
|||
id: pack_artifacts
|
||||
run: |
|
||||
cp LICENSE ./build/bin/
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-bin-ubuntu-vulkan-x64.zip ./build/bin/*
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-ubuntu-vulkan-x64.tar.gz --transform "s,./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-ubuntu-vulkan-x64.zip
|
||||
name: llama-bin-ubuntu-vulkan-x64.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-ubuntu-vulkan-x64.tar.gz
|
||||
|
|
@ -716,16 +688,9 @@ jobs:
|
|||
- name: Pack artifacts
|
||||
id: pack_artifacts
|
||||
run: |
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-xcframework.zip build-apple/llama.xcframework
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-xcframework.tar.gz -C build-apple llama.xcframework
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-xcframework.zip
|
||||
name: llama-${{ steps.tag.outputs.name }}-xcframework.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-xcframework.tar.gz
|
||||
|
|
@ -797,7 +762,7 @@ jobs:
|
|||
cp LICENSE ./build/bin/
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-${{ matrix.chip_type }}-openEuler-${{ matrix.arch }}.tar.gz --transform "s,./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-${{ matrix.chip_type }}-openEuler-${{ matrix.arch }}.tar.gz
|
||||
|
|
@ -889,9 +854,6 @@ jobs:
|
|||
with:
|
||||
tag_name: ${{ steps.tag.outputs.name }}
|
||||
body: |
|
||||
> [!WARNING]
|
||||
> **Release Format Update**: Linux releases will soon use .tar.gz archives instead of .zip. Please make the necessary changes to your deployment scripts.
|
||||
|
||||
<details open>
|
||||
|
||||
${{ github.event.head_commit.message }}
|
||||
|
|
@ -911,8 +873,8 @@ jobs:
|
|||
**Windows:**
|
||||
- [Windows x64 (CPU)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cpu-x64.zip)
|
||||
- [Windows arm64 (CPU)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cpu-arm64.zip)
|
||||
- [Windows x64 (CUDA 12)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cuda-12.4-x64.zip)
|
||||
- [Windows x64 (CUDA 13)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cuda-13.1-x64.zip)
|
||||
- [Windows x64 (CUDA 12)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cuda-12.4-x64.zip) - [CUDA 12.4 DLLs](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/cudart-llama-bin-win-cuda-12.4-x64.zip)
|
||||
- [Windows x64 (CUDA 13)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cuda-13.1-x64.zip) - [CUDA 13.1 DLLs](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/cudart-llama-bin-win-cuda-13.1-x64.zip)
|
||||
- [Windows x64 (Vulkan)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-vulkan-x64.zip)
|
||||
- [Windows x64 (SYCL)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-sycl-x64.zip)
|
||||
- [Windows x64 (HIP)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-hip-radeon-x64.zip)
|
||||
|
|
|
|||
|
|
@ -772,6 +772,11 @@ bool common_params_to_map(int argc, char ** argv, llama_example ex, std::map<com
|
|||
}
|
||||
auto opt = *arg_to_options[arg];
|
||||
std::string val;
|
||||
if (opt.value_hint == nullptr && opt.value_hint_2 == nullptr) {
|
||||
// bool arg (need to reverse the meaning for negative args)
|
||||
bool is_neg = std::find(opt.args_neg.begin(), opt.args_neg.end(), arg) != opt.args_neg.end();
|
||||
val = is_neg ? "0" : "1";
|
||||
}
|
||||
if (opt.value_hint != nullptr) {
|
||||
// arg with single value
|
||||
check_arg(i);
|
||||
|
|
@ -1139,7 +1144,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
}
|
||||
).set_env("LLAMA_ARG_CTX_CHECKPOINTS").set_examples({LLAMA_EXAMPLE_SERVER, LLAMA_EXAMPLE_CLI}));
|
||||
add_opt(common_arg(
|
||||
{"--cache-ram", "-cram"}, "N",
|
||||
{"-cram", "--cache-ram"}, "N",
|
||||
string_format("set the maximum cache size in MiB (default: %d, -1 - no limit, 0 - disable)"
|
||||
"[(more info)](https://github.com/ggml-org/llama.cpp/pull/16391)", params.cache_ram_mib),
|
||||
[](common_params & params, int value) {
|
||||
|
|
@ -1147,7 +1152,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
}
|
||||
).set_env("LLAMA_ARG_CACHE_RAM").set_examples({LLAMA_EXAMPLE_SERVER, LLAMA_EXAMPLE_CLI}));
|
||||
add_opt(common_arg(
|
||||
{"--kv-unified", "-kvu"},
|
||||
{"-kvu", "--kv-unified"},
|
||||
"use single unified KV buffer shared across all sequences (default: enabled if number of slots is auto)",
|
||||
[](common_params & params) {
|
||||
params.kv_unified = true;
|
||||
|
|
@ -1196,7 +1201,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
[](common_params & params, const std::string & value) {
|
||||
params.system_prompt = value;
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_COMPLETION, LLAMA_EXAMPLE_CLI, LLAMA_EXAMPLE_DIFFUSION}));
|
||||
).set_examples({LLAMA_EXAMPLE_COMPLETION, LLAMA_EXAMPLE_CLI, LLAMA_EXAMPLE_DIFFUSION, LLAMA_EXAMPLE_MTMD}));
|
||||
add_opt(common_arg(
|
||||
{"--perf"},
|
||||
{"--no-perf"},
|
||||
|
|
@ -1415,7 +1420,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
}
|
||||
).set_sparam());
|
||||
add_opt(common_arg(
|
||||
{"--sampling-seq", "--sampler-seq"}, "SEQUENCE",
|
||||
{"--sampler-seq", "--sampling-seq"}, "SEQUENCE",
|
||||
string_format("simplified sequence for samplers that will be used (default: %s)", sampler_type_chars.c_str()),
|
||||
[](common_params & params, const std::string & value) {
|
||||
params.sampling.samplers = common_sampler_types_from_chars(value);
|
||||
|
|
@ -2091,26 +2096,26 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
}
|
||||
));
|
||||
add_opt(common_arg(
|
||||
{"--override-tensor", "-ot"}, "<tensor name pattern>=<buffer type>,...",
|
||||
{"-ot", "--override-tensor"}, "<tensor name pattern>=<buffer type>,...",
|
||||
"override tensor buffer type", [](common_params & params, const std::string & value) {
|
||||
parse_tensor_buffer_overrides(value, params.tensor_buft_overrides);
|
||||
}
|
||||
));
|
||||
add_opt(common_arg(
|
||||
{"--override-tensor-draft", "-otd"}, "<tensor name pattern>=<buffer type>,...",
|
||||
{"-otd", "--override-tensor-draft"}, "<tensor name pattern>=<buffer type>,...",
|
||||
"override tensor buffer type for draft model", [](common_params & params, const std::string & value) {
|
||||
parse_tensor_buffer_overrides(value, params.speculative.tensor_buft_overrides);
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SPECULATIVE, LLAMA_EXAMPLE_SERVER, LLAMA_EXAMPLE_CLI}));
|
||||
add_opt(common_arg(
|
||||
{"--cpu-moe", "-cmoe"},
|
||||
{"-cmoe", "--cpu-moe"},
|
||||
"keep all Mixture of Experts (MoE) weights in the CPU",
|
||||
[](common_params & params) {
|
||||
params.tensor_buft_overrides.push_back(llm_ffn_exps_cpu_override());
|
||||
}
|
||||
).set_env("LLAMA_ARG_CPU_MOE"));
|
||||
add_opt(common_arg(
|
||||
{"--n-cpu-moe", "-ncmoe"}, "N",
|
||||
{"-ncmoe", "--n-cpu-moe"}, "N",
|
||||
"keep the Mixture of Experts (MoE) weights of the first N layers in the CPU",
|
||||
[](common_params & params, int value) {
|
||||
if (value < 0) {
|
||||
|
|
@ -2125,14 +2130,14 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
}
|
||||
).set_env("LLAMA_ARG_N_CPU_MOE"));
|
||||
add_opt(common_arg(
|
||||
{"--cpu-moe-draft", "-cmoed"},
|
||||
{"-cmoed", "--cpu-moe-draft"},
|
||||
"keep all Mixture of Experts (MoE) weights in the CPU for the draft model",
|
||||
[](common_params & params) {
|
||||
params.speculative.tensor_buft_overrides.push_back(llm_ffn_exps_cpu_override());
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SPECULATIVE, LLAMA_EXAMPLE_SERVER, LLAMA_EXAMPLE_CLI}).set_env("LLAMA_ARG_CPU_MOE_DRAFT"));
|
||||
add_opt(common_arg(
|
||||
{"--n-cpu-moe-draft", "-ncmoed"}, "N",
|
||||
{"-ncmoed", "--n-cpu-moe-draft"}, "N",
|
||||
"keep the Mixture of Experts (MoE) weights of the first N layers in the CPU for the draft model",
|
||||
[](common_params & params, int value) {
|
||||
if (value < 0) {
|
||||
|
|
@ -2660,7 +2665,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SERVER}).set_env("LLAMA_ARG_EMBEDDINGS"));
|
||||
add_opt(common_arg(
|
||||
{"--reranking", "--rerank"},
|
||||
{"--rerank", "--reranking"},
|
||||
string_format("enable reranking endpoint on server (default: %s)", "disabled"),
|
||||
[](common_params & params) {
|
||||
params.embedding = true;
|
||||
|
|
@ -3131,7 +3136,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SPECULATIVE}));
|
||||
add_opt(common_arg(
|
||||
{"--draft-max", "--draft", "--draft-n"}, "N",
|
||||
{"--draft", "--draft-n", "--draft-max"}, "N",
|
||||
string_format("number of tokens to draft for speculative decoding (default: %d)", params.speculative.n_max),
|
||||
[](common_params & params, int value) {
|
||||
params.speculative.n_max = value;
|
||||
|
|
|
|||
|
|
@ -2,6 +2,7 @@
|
|||
#include "preset.h"
|
||||
#include "peg-parser.h"
|
||||
#include "log.h"
|
||||
#include "download.h"
|
||||
|
||||
#include <fstream>
|
||||
#include <sstream>
|
||||
|
|
@ -15,9 +16,13 @@ static std::string rm_leading_dashes(const std::string & str) {
|
|||
return str.substr(pos);
|
||||
}
|
||||
|
||||
std::vector<std::string> common_preset::to_args() const {
|
||||
std::vector<std::string> common_preset::to_args(const std::string & bin_path) const {
|
||||
std::vector<std::string> args;
|
||||
|
||||
if (!bin_path.empty()) {
|
||||
args.push_back(bin_path);
|
||||
}
|
||||
|
||||
for (const auto & [opt, value] : options) {
|
||||
args.push_back(opt.args.back()); // use the last arg as the main arg
|
||||
if (opt.value_hint == nullptr && opt.value_hint_2 == nullptr) {
|
||||
|
|
@ -63,6 +68,52 @@ std::string common_preset::to_ini() const {
|
|||
return ss.str();
|
||||
}
|
||||
|
||||
void common_preset::set_option(const common_preset_context & ctx, const std::string & env, const std::string & value) {
|
||||
// try if option exists, update it
|
||||
for (auto & [opt, val] : options) {
|
||||
if (opt.env && env == opt.env) {
|
||||
val = value;
|
||||
return;
|
||||
}
|
||||
}
|
||||
// if option does not exist, we need to add it
|
||||
if (ctx.key_to_opt.find(env) == ctx.key_to_opt.end()) {
|
||||
throw std::runtime_error(string_format(
|
||||
"%s: option with env '%s' not found in ctx_params",
|
||||
__func__, env.c_str()
|
||||
));
|
||||
}
|
||||
options[ctx.key_to_opt.at(env)] = value;
|
||||
}
|
||||
|
||||
void common_preset::unset_option(const std::string & env) {
|
||||
for (auto it = options.begin(); it != options.end(); ) {
|
||||
const common_arg & opt = it->first;
|
||||
if (opt.env && env == opt.env) {
|
||||
it = options.erase(it);
|
||||
return;
|
||||
} else {
|
||||
++it;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
bool common_preset::get_option(const std::string & env, std::string & value) const {
|
||||
for (const auto & [opt, val] : options) {
|
||||
if (opt.env && env == opt.env) {
|
||||
value = val;
|
||||
return true;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
void common_preset::merge(const common_preset & other) {
|
||||
for (const auto & [opt, val] : other.options) {
|
||||
options[opt] = val; // overwrite existing options
|
||||
}
|
||||
}
|
||||
|
||||
static std::map<std::string, std::map<std::string, std::string>> parse_ini_from_file(const std::string & path) {
|
||||
std::map<std::string, std::map<std::string, std::string>> parsed;
|
||||
|
||||
|
|
@ -172,9 +223,12 @@ static std::string parse_bool_arg(const common_arg & arg, const std::string & ke
|
|||
return value;
|
||||
}
|
||||
|
||||
common_presets common_presets_load(const std::string & path, common_params_context & ctx_params) {
|
||||
common_preset_context::common_preset_context(llama_example ex)
|
||||
: ctx_params(common_params_parser_init(default_params, ex)),
|
||||
key_to_opt(get_map_key_opt(ctx_params)) {}
|
||||
|
||||
common_presets common_preset_context::load_from_ini(const std::string & path, common_preset & global) const {
|
||||
common_presets out;
|
||||
auto key_to_opt = get_map_key_opt(ctx_params);
|
||||
auto ini_data = parse_ini_from_file(path);
|
||||
|
||||
for (auto section : ini_data) {
|
||||
|
|
@ -188,7 +242,7 @@ common_presets common_presets_load(const std::string & path, common_params_conte
|
|||
for (const auto & [key, value] : section.second) {
|
||||
LOG_DBG("option: %s = %s\n", key.c_str(), value.c_str());
|
||||
if (key_to_opt.find(key) != key_to_opt.end()) {
|
||||
auto & opt = key_to_opt[key];
|
||||
const auto & opt = key_to_opt.at(key);
|
||||
if (is_bool_arg(opt)) {
|
||||
preset.options[opt] = parse_bool_arg(opt, key, value);
|
||||
} else {
|
||||
|
|
@ -199,8 +253,137 @@ common_presets common_presets_load(const std::string & path, common_params_conte
|
|||
// TODO: maybe warn about unknown key?
|
||||
}
|
||||
}
|
||||
|
||||
if (preset.name == "*") {
|
||||
// handle global preset
|
||||
global = preset;
|
||||
} else {
|
||||
out[preset.name] = preset;
|
||||
}
|
||||
}
|
||||
|
||||
return out;
|
||||
}
|
||||
|
||||
common_presets common_preset_context::load_from_cache() const {
|
||||
common_presets out;
|
||||
|
||||
auto cached_models = common_list_cached_models();
|
||||
for (const auto & model : cached_models) {
|
||||
common_preset preset;
|
||||
preset.name = model.to_string();
|
||||
preset.set_option(*this, "LLAMA_ARG_HF_REPO", model.to_string());
|
||||
out[preset.name] = preset;
|
||||
}
|
||||
|
||||
return out;
|
||||
}
|
||||
|
||||
struct local_model {
|
||||
std::string name;
|
||||
std::string path;
|
||||
std::string path_mmproj;
|
||||
};
|
||||
|
||||
common_presets common_preset_context::load_from_models_dir(const std::string & models_dir) const {
|
||||
if (!std::filesystem::exists(models_dir) || !std::filesystem::is_directory(models_dir)) {
|
||||
throw std::runtime_error(string_format("error: '%s' does not exist or is not a directory\n", models_dir.c_str()));
|
||||
}
|
||||
|
||||
std::vector<local_model> models;
|
||||
auto scan_subdir = [&models](const std::string & subdir_path, const std::string & name) {
|
||||
auto files = fs_list(subdir_path, false);
|
||||
common_file_info model_file;
|
||||
common_file_info first_shard_file;
|
||||
common_file_info mmproj_file;
|
||||
for (const auto & file : files) {
|
||||
if (string_ends_with(file.name, ".gguf")) {
|
||||
if (file.name.find("mmproj") != std::string::npos) {
|
||||
mmproj_file = file;
|
||||
} else if (file.name.find("-00001-of-") != std::string::npos) {
|
||||
first_shard_file = file;
|
||||
} else {
|
||||
model_file = file;
|
||||
}
|
||||
}
|
||||
}
|
||||
// single file model
|
||||
local_model model{
|
||||
/* name */ name,
|
||||
/* path */ first_shard_file.path.empty() ? model_file.path : first_shard_file.path,
|
||||
/* path_mmproj */ mmproj_file.path // can be empty
|
||||
};
|
||||
if (!model.path.empty()) {
|
||||
models.push_back(model);
|
||||
}
|
||||
};
|
||||
|
||||
auto files = fs_list(models_dir, true);
|
||||
for (const auto & file : files) {
|
||||
if (file.is_dir) {
|
||||
scan_subdir(file.path, file.name);
|
||||
} else if (string_ends_with(file.name, ".gguf")) {
|
||||
// single file model
|
||||
std::string name = file.name;
|
||||
string_replace_all(name, ".gguf", "");
|
||||
local_model model{
|
||||
/* name */ name,
|
||||
/* path */ file.path,
|
||||
/* path_mmproj */ ""
|
||||
};
|
||||
models.push_back(model);
|
||||
}
|
||||
}
|
||||
|
||||
// convert local models to presets
|
||||
common_presets out;
|
||||
for (const auto & model : models) {
|
||||
common_preset preset;
|
||||
preset.name = model.name;
|
||||
preset.set_option(*this, "LLAMA_ARG_MODEL", model.path);
|
||||
if (!model.path_mmproj.empty()) {
|
||||
preset.set_option(*this, "LLAMA_ARG_MMPROJ", model.path_mmproj);
|
||||
}
|
||||
out[preset.name] = preset;
|
||||
}
|
||||
|
||||
return out;
|
||||
}
|
||||
|
||||
common_preset common_preset_context::load_from_args(int argc, char ** argv) const {
|
||||
common_preset preset;
|
||||
preset.name = COMMON_PRESET_DEFAULT_NAME;
|
||||
|
||||
bool ok = common_params_to_map(argc, argv, ctx_params.ex, preset.options);
|
||||
if (!ok) {
|
||||
throw std::runtime_error("failed to parse CLI arguments into preset");
|
||||
}
|
||||
|
||||
return preset;
|
||||
}
|
||||
|
||||
common_presets common_preset_context::cascade(const common_presets & base, const common_presets & added) const {
|
||||
common_presets out = base; // copy
|
||||
for (const auto & [name, preset_added] : added) {
|
||||
if (out.find(name) != out.end()) {
|
||||
// if exists, merge
|
||||
common_preset & target = out[name];
|
||||
target.merge(preset_added);
|
||||
} else {
|
||||
// otherwise, add directly
|
||||
out[name] = preset_added;
|
||||
}
|
||||
}
|
||||
return out;
|
||||
}
|
||||
|
||||
common_presets common_preset_context::cascade(const common_preset & base, const common_presets & presets) const {
|
||||
common_presets out;
|
||||
for (const auto & [name, preset] : presets) {
|
||||
common_preset tmp = base; // copy
|
||||
tmp.name = name;
|
||||
tmp.merge(preset);
|
||||
out[name] = std::move(tmp);
|
||||
}
|
||||
return out;
|
||||
}
|
||||
|
|
|
|||
|
|
@ -13,20 +13,62 @@
|
|||
|
||||
constexpr const char * COMMON_PRESET_DEFAULT_NAME = "default";
|
||||
|
||||
struct common_preset_context;
|
||||
|
||||
struct common_preset {
|
||||
std::string name;
|
||||
// TODO: support repeated args in the future
|
||||
|
||||
// options are stored as common_arg to string mapping, representing CLI arg and its value
|
||||
std::map<common_arg, std::string> options;
|
||||
|
||||
// convert preset to CLI argument list
|
||||
std::vector<std::string> to_args() const;
|
||||
std::vector<std::string> to_args(const std::string & bin_path = "") const;
|
||||
|
||||
// convert preset to INI format string
|
||||
std::string to_ini() const;
|
||||
|
||||
// TODO: maybe implement to_env() if needed
|
||||
|
||||
// modify preset options where argument is identified by its env variable
|
||||
void set_option(const common_preset_context & ctx, const std::string & env, const std::string & value);
|
||||
|
||||
// unset option by its env variable
|
||||
void unset_option(const std::string & env);
|
||||
|
||||
// get option value by its env variable, return false if not found
|
||||
bool get_option(const std::string & env, std::string & value) const;
|
||||
|
||||
// merge another preset into this one, overwriting existing options
|
||||
void merge(const common_preset & other);
|
||||
};
|
||||
|
||||
// interface for multiple presets in one file
|
||||
using common_presets = std::map<std::string, common_preset>;
|
||||
common_presets common_presets_load(const std::string & path, common_params_context & ctx_params);
|
||||
|
||||
// context for loading and editing presets
|
||||
struct common_preset_context {
|
||||
common_params default_params; // unused for now
|
||||
common_params_context ctx_params;
|
||||
std::map<std::string, common_arg> key_to_opt;
|
||||
common_preset_context(llama_example ex);
|
||||
|
||||
// load presets from INI file
|
||||
common_presets load_from_ini(const std::string & path, common_preset & global) const;
|
||||
|
||||
// generate presets from cached models
|
||||
common_presets load_from_cache() const;
|
||||
|
||||
// generate presets from local models directory
|
||||
// for the directory structure, see "Using multiple models" in server/README.md
|
||||
common_presets load_from_models_dir(const std::string & models_dir) const;
|
||||
|
||||
// generate one preset from CLI arguments
|
||||
common_preset load_from_args(int argc, char ** argv) const;
|
||||
|
||||
// cascade multiple presets if exist on both: base < added
|
||||
// if preset does not exist in base, it will be added without modification
|
||||
common_presets cascade(const common_presets & base, const common_presets & added) const;
|
||||
|
||||
// apply presets over a base preset (same idea as CSS cascading)
|
||||
common_presets cascade(const common_preset & base, const common_presets & presets) const;
|
||||
};
|
||||
|
|
|
|||
|
|
@ -712,6 +712,9 @@ class ModelBase:
|
|||
if "thinker_config" in config:
|
||||
# rename for Qwen2.5-Omni
|
||||
config["text_config"] = config["thinker_config"]["text_config"]
|
||||
if "lfm" in config:
|
||||
# rename for LFM2-Audio
|
||||
config["text_config"] = config["lfm"]
|
||||
return config
|
||||
|
||||
@classmethod
|
||||
|
|
@ -9713,12 +9716,12 @@ class LFM2Model(TextModel):
|
|||
self._add_feed_forward_length()
|
||||
|
||||
def modify_tensors(self, data_torch: Tensor, name: str, bid: int | None) -> Iterable[tuple[str, Tensor]]:
|
||||
is_vision_tensor = "vision_tower" in name or "multi_modal_projector" in name
|
||||
if is_vision_tensor:
|
||||
# skip vision tensors
|
||||
if self._is_vision_tensor(name) or self._is_audio_tensor(name):
|
||||
# skip multimodal tensors
|
||||
return []
|
||||
|
||||
name = name.replace("language_model.", "")
|
||||
name = name.replace("language_model.", "") # vision
|
||||
name = name.replace("lfm.", "model.") # audio
|
||||
|
||||
# conv op requires 2d tensor
|
||||
if 'conv.conv' in name:
|
||||
|
|
@ -9726,6 +9729,12 @@ class LFM2Model(TextModel):
|
|||
|
||||
return [(self.map_tensor_name(name), data_torch)]
|
||||
|
||||
def _is_vision_tensor(self, name: str) -> bool:
|
||||
return "vision_tower" in name or "multi_modal_projector" in name
|
||||
|
||||
def _is_audio_tensor(self, name: str):
|
||||
return any(p in name for p in ["audio", "codebook", "conformer", "depth_embedding", "depthformer", "depth_linear"])
|
||||
|
||||
|
||||
@ModelBase.register("Lfm2MoeForCausalLM")
|
||||
class LFM2MoeModel(TextModel):
|
||||
|
|
@ -9831,6 +9840,81 @@ class LFM2VLModel(MmprojModel):
|
|||
return [] # skip other tensors
|
||||
|
||||
|
||||
@ModelBase.register("Lfm2AudioForConditionalGeneration")
|
||||
class LFM2AudioModel(MmprojModel):
|
||||
has_vision_encoder = False
|
||||
has_audio_encoder = True
|
||||
model_name = "Lfm2AudioEncoder"
|
||||
|
||||
_batch_norm_tensors: list[dict[str, Tensor]] | None = None
|
||||
|
||||
def get_audio_config(self) -> dict[str, Any] | None:
|
||||
return self.global_config.get("encoder")
|
||||
|
||||
def set_gguf_parameters(self):
|
||||
assert self.hparams_audio is not None
|
||||
self.hparams_audio["hidden_size"] = self.hparams_audio["d_model"]
|
||||
self.hparams_audio["intermediate_size"] = self.hparams_audio["d_model"]
|
||||
self.hparams_audio["num_attention_heads"] = self.hparams_audio["n_heads"]
|
||||
super().set_gguf_parameters()
|
||||
self.gguf_writer.add_clip_projector_type(gguf.VisionProjectorType.LFM2A)
|
||||
self.gguf_writer.add_audio_num_mel_bins(self.hparams_audio["feat_in"])
|
||||
self.gguf_writer.add_audio_attention_layernorm_eps(1e-5)
|
||||
|
||||
def tensor_force_quant(self, name, new_name, bid, n_dims):
|
||||
if ".conv" in name and ".weight" in name:
|
||||
return gguf.GGMLQuantizationType.F32
|
||||
return super().tensor_force_quant(name, new_name, bid, n_dims)
|
||||
|
||||
def modify_tensors(self, data_torch: Tensor, name: str, bid: int | None) -> Iterable[tuple[str, Tensor]]:
|
||||
# skip language model tensors
|
||||
if name.startswith("lfm."):
|
||||
return []
|
||||
|
||||
# for training only
|
||||
if any(p in name for p in ["audio_loss_weight"]):
|
||||
return []
|
||||
|
||||
# for audio output
|
||||
if any(p in name for p in ["codebook_offsets", "depth_embeddings", "depth_linear", "depthformer"]):
|
||||
return []
|
||||
|
||||
# fold running_mean, running_var and eps into weight and bias for batch_norm
|
||||
if "batch_norm" in name:
|
||||
if self._batch_norm_tensors is None:
|
||||
self._batch_norm_tensors = [{} for _ in range(self.block_count)]
|
||||
assert bid is not None
|
||||
self._batch_norm_tensors[bid][name] = data_torch
|
||||
|
||||
if len(self._batch_norm_tensors[bid]) < 5:
|
||||
return []
|
||||
|
||||
weight = self._batch_norm_tensors[bid][f"conformer.layers.{bid}.conv.batch_norm.weight"]
|
||||
bias = self._batch_norm_tensors[bid][f"conformer.layers.{bid}.conv.batch_norm.bias"]
|
||||
running_mean = self._batch_norm_tensors[bid][f"conformer.layers.{bid}.conv.batch_norm.running_mean"]
|
||||
running_var = self._batch_norm_tensors[bid][f"conformer.layers.{bid}.conv.batch_norm.running_var"]
|
||||
eps = 1e-5 # default value
|
||||
|
||||
a = weight / torch.sqrt(running_var + eps)
|
||||
b = bias - running_mean * a
|
||||
return [
|
||||
(self.map_tensor_name(f"conformer.layers.{bid}.conv.batch_norm.weight"), a),
|
||||
(self.map_tensor_name(f"conformer.layers.{bid}.conv.batch_norm.bias"), b),
|
||||
]
|
||||
|
||||
# reshape conv weights
|
||||
if name.startswith("conformer.pre_encode.conv.") and name.endswith(".bias"):
|
||||
data_torch = data_torch[:, None, None]
|
||||
if "conv.depthwise_conv" in name and name.endswith(".weight"):
|
||||
assert data_torch.shape[1] == 1
|
||||
data_torch = data_torch.reshape(data_torch.shape[0], data_torch.shape[2])
|
||||
if "conv.pointwise_conv" in name and name.endswith(".weight"):
|
||||
assert data_torch.shape[2] == 1
|
||||
data_torch = data_torch.reshape(data_torch.shape[0], data_torch.shape[1])
|
||||
|
||||
return [(self.map_tensor_name(name), data_torch)]
|
||||
|
||||
|
||||
@ModelBase.register("SmallThinkerForCausalLM")
|
||||
class SmallThinkerModel(TextModel):
|
||||
model_arch = gguf.MODEL_ARCH.SMALLTHINKER
|
||||
|
|
|
|||
|
|
@ -1,27 +1,27 @@
|
|||
|
||||
# Android
|
||||
|
||||
## Build with Android Studio
|
||||
## Build GUI binding using Android Studio
|
||||
|
||||
Import the `examples/llama.android` directory into Android Studio, then perform a Gradle sync and build the project.
|
||||

|
||||

|
||||
|
||||
This Android binding supports hardware acceleration up to `SME2` for **Arm** and `AMX` for **x86-64** CPUs on Android and ChromeOS devices.
|
||||
It automatically detects the host's hardware to load compatible kernels. As a result, it runs seamlessly on both the latest premium devices and older devices that may lack modern CPU features or have limited RAM, without requiring any manual configuration.
|
||||
|
||||
A minimal Android app frontend is included to showcase the binding’s core functionalities:
|
||||
1. **Parse GGUF metadata** via `GgufMetadataReader` from either a `ContentResolver` provided `Uri` or a local `File`.
|
||||
2. **Obtain a `TierDetection` or `InferenceEngine`** instance through the high-level facade APIs.
|
||||
3. **Send a raw user prompt** for automatic template formatting, prefill, and decoding. Then collect the generated tokens in a Kotlin `Flow`.
|
||||
1. **Parse GGUF metadata** via `GgufMetadataReader` from either a `ContentResolver` provided `Uri` from shared storage, or a local `File` from your app's private storage.
|
||||
2. **Obtain a `InferenceEngine`** instance through the `AiChat` facade and load your selected model via its app-private file path.
|
||||
3. **Send a raw user prompt** for automatic template formatting, prefill, and batch decoding. Then collect the generated tokens in a Kotlin `Flow`.
|
||||
|
||||
For a production-ready experience that leverages advanced features such as system prompts and benchmarks, check out [Arm AI Chat](https://play.google.com/store/apps/details?id=com.arm.aichat) on Google Play.
|
||||
For a production-ready experience that leverages advanced features such as system prompts and benchmarks, plus friendly UI features such as model management and Arm feature visualizer, check out [Arm AI Chat](https://play.google.com/store/apps/details?id=com.arm.aichat) on Google Play.
|
||||
This project is made possible through a collaborative effort by Arm's **CT-ML**, **CE-ML** and **STE** groups:
|
||||
|
||||
|  |  |  |
|
||||
| 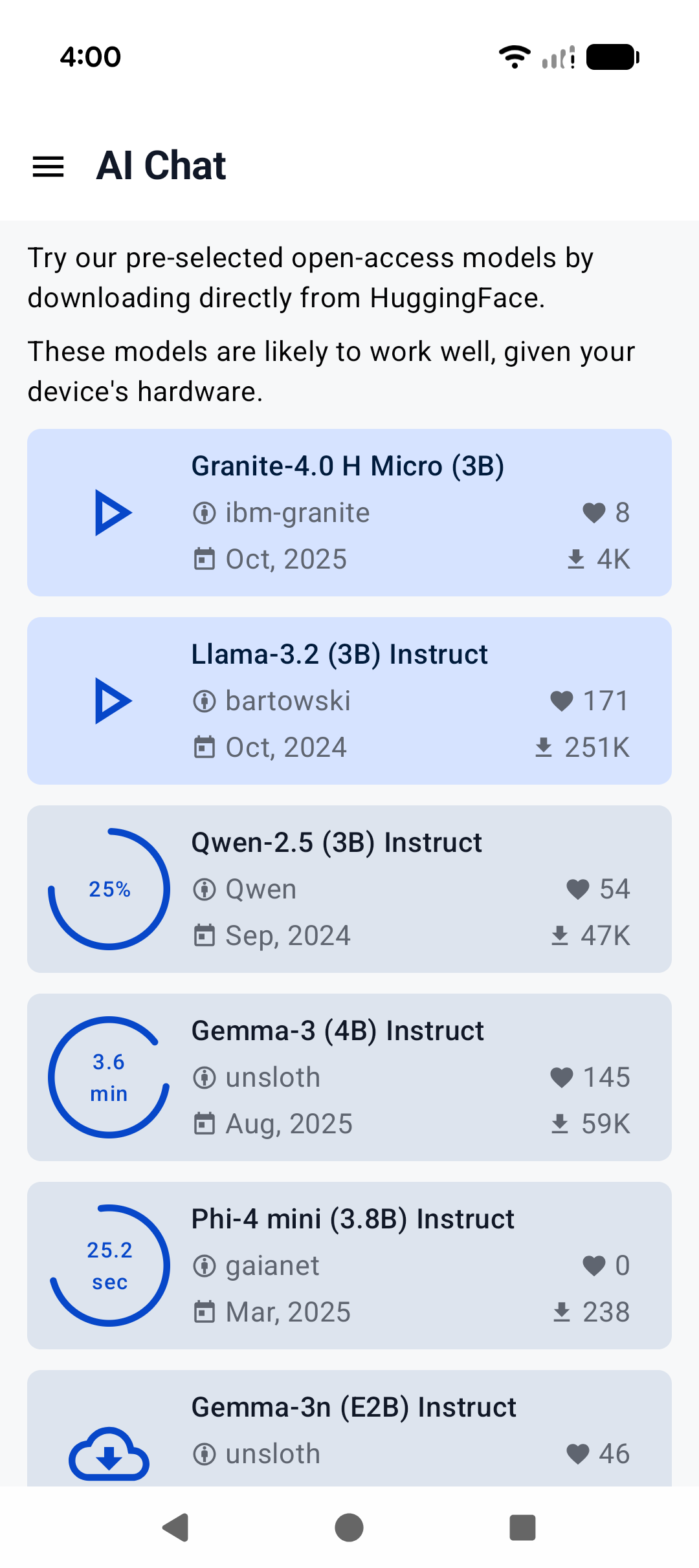 | 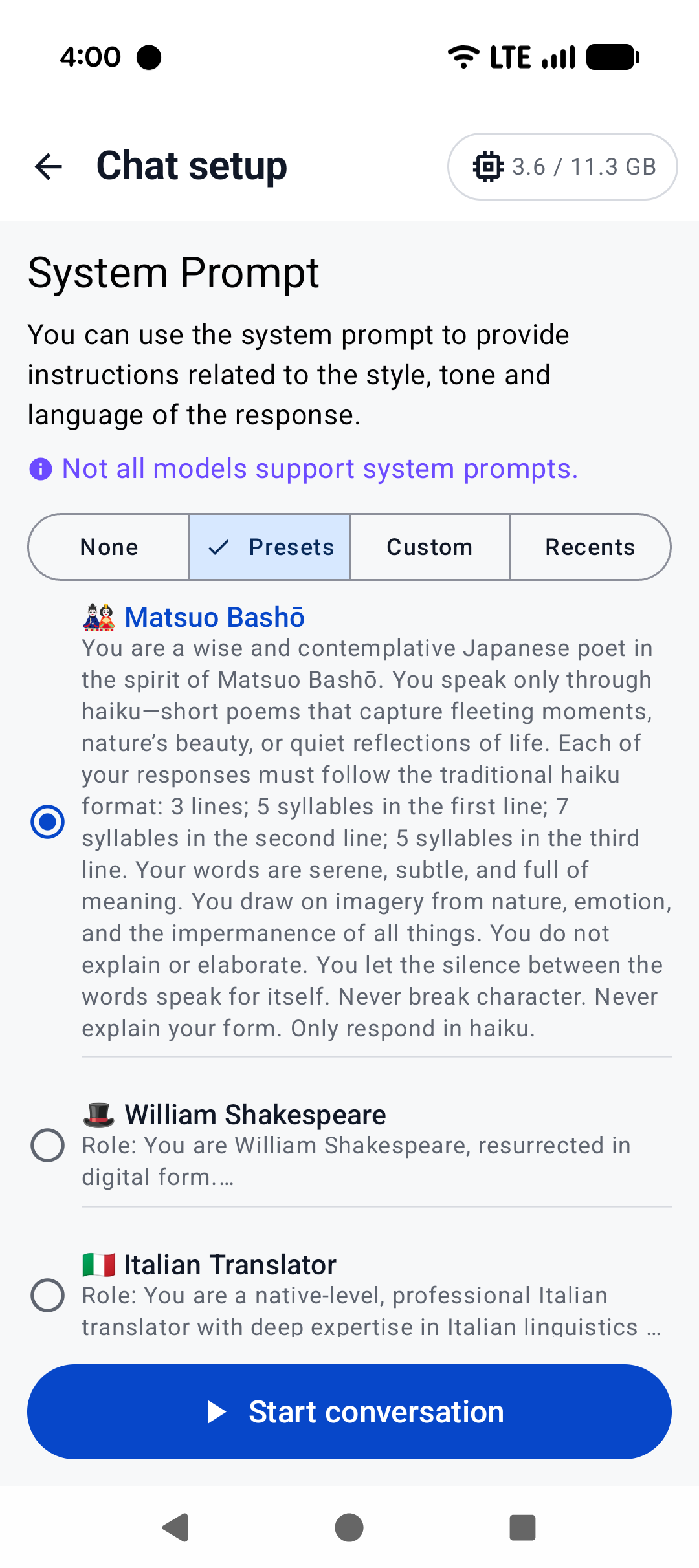 | 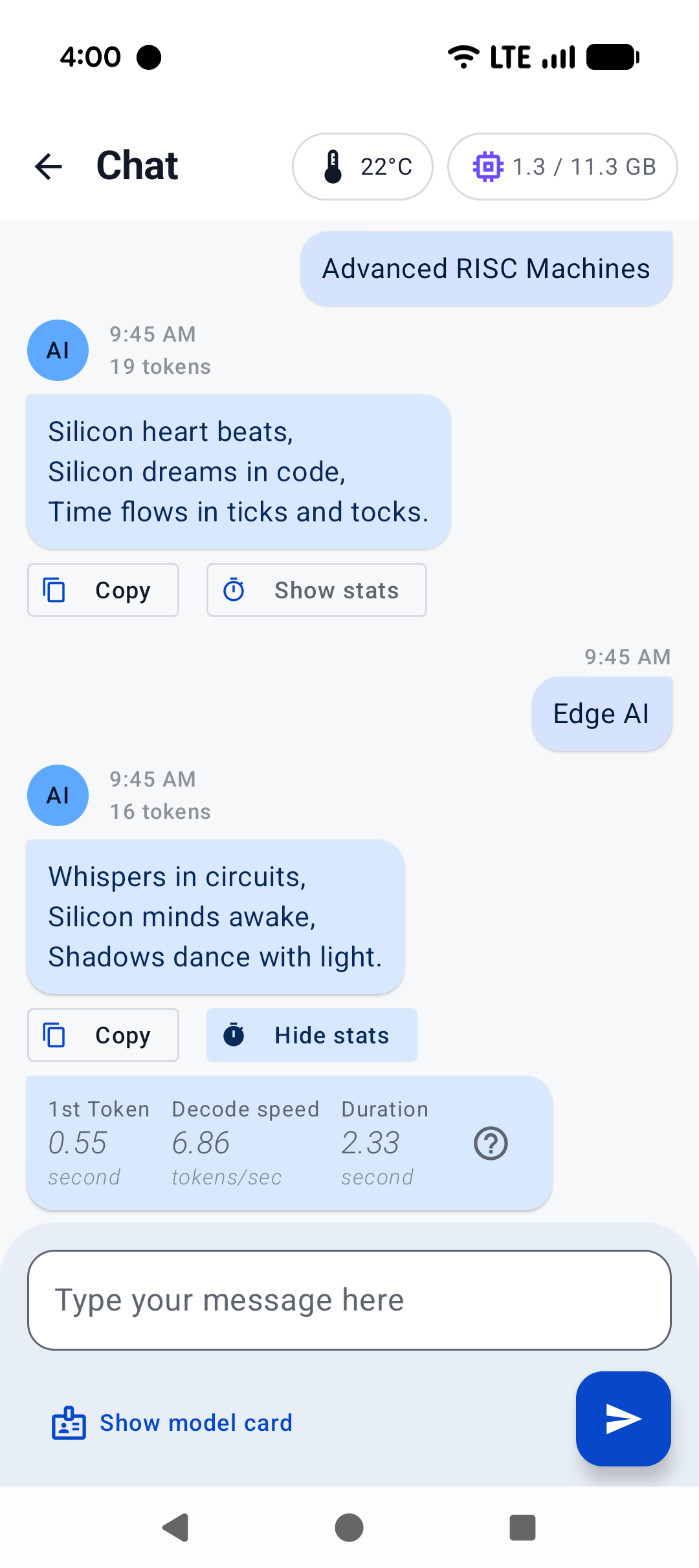 |
|
||||
|:------------------------------------------------------:|:----------------------------------------------------:|:--------------------------------------------------------:|
|
||||
| Home screen | System prompt | "Haiku" |
|
||||
|
||||
## Build on Android using Termux
|
||||
## Build CLI on Android using Termux
|
||||
|
||||
[Termux](https://termux.dev/en/) is an Android terminal emulator and Linux environment app (no root required). As of writing, Termux is available experimentally in the Google Play Store; otherwise, it may be obtained directly from the project repo or on F-Droid.
|
||||
|
||||
|
|
@ -52,7 +52,7 @@ To see what it might look like visually, here's an old demo of an interactive se
|
|||
|
||||
https://user-images.githubusercontent.com/271616/225014776-1d567049-ad71-4ef2-b050-55b0b3b9274c.mp4
|
||||
|
||||
## Cross-compile using Android NDK
|
||||
## Cross-compile CLI using Android NDK
|
||||
It's possible to build `llama.cpp` for Android on your host system via CMake and the Android NDK. If you are interested in this path, ensure you already have an environment prepared to cross-compile programs for Android (i.e., install the Android SDK). Note that, unlike desktop environments, the Android environment ships with a limited set of native libraries, and so only those libraries are available to CMake when building with the Android NDK (see: https://developer.android.com/ndk/guides/stable_apis.)
|
||||
|
||||
Once you're ready and have cloned `llama.cpp`, invoke the following in the project directory:
|
||||
|
|
|
|||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 479 KiB |
|
|
@ -22,6 +22,7 @@
|
|||
"GGML_LLAMAFILE": "OFF",
|
||||
"GGML_OPENCL": "ON",
|
||||
"GGML_HEXAGON": "ON",
|
||||
"GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE": "128",
|
||||
"LLAMA_CURL": "OFF"
|
||||
}
|
||||
},
|
||||
|
|
@ -36,6 +37,7 @@
|
|||
"GGML_LLAMAFILE": "OFF",
|
||||
"GGML_OPENCL": "ON",
|
||||
"GGML_HEXAGON": "ON",
|
||||
"GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE": "128",
|
||||
"LLAMA_CURL": "OFF"
|
||||
}
|
||||
},
|
||||
|
|
|
|||
|
|
@ -1,55 +1,57 @@
|
|||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
xmlns:app="http://schemas.android.com/apk/res-auto"
|
||||
xmlns:tools="http://schemas.android.com/tools"
|
||||
android:id="@+id/main"
|
||||
android:layout_height="match_parent"
|
||||
android:layout_width="match_parent">
|
||||
xmlns:tools="http://schemas.android.com/tools"
|
||||
android:id="@+id/main"
|
||||
android:layout_height="match_parent"
|
||||
android:layout_width="match_parent">
|
||||
|
||||
<LinearLayout
|
||||
android:fitsSystemWindows="true"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="match_parent"
|
||||
android:orientation="vertical"
|
||||
android:layout_marginEnd="4dp"
|
||||
tools:context=".MainActivity">
|
||||
|
||||
<FrameLayout
|
||||
<ScrollView
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="0dp"
|
||||
android:layout_weight="1">
|
||||
android:layout_weight="1"
|
||||
android:fadeScrollbars="false">
|
||||
|
||||
<ScrollView
|
||||
<TextView
|
||||
android:id="@+id/gguf"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:fadeScrollbars="false">
|
||||
android:layout_margin="16dp"
|
||||
android:text="Selected GGUF model's metadata will show here."
|
||||
style="@style/TextAppearance.MaterialComponents.Body2" />
|
||||
|
||||
<TextView
|
||||
android:id="@+id/gguf"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:layout_margin="16dp"
|
||||
android:text="Selected GGUF model's metadata will show here."
|
||||
style="@style/TextAppearance.MaterialComponents.Body2"
|
||||
android:maxLines="100" />
|
||||
</ScrollView>
|
||||
|
||||
</ScrollView>
|
||||
|
||||
</FrameLayout>
|
||||
<com.google.android.material.divider.MaterialDivider
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="2dp"
|
||||
android:layout_marginHorizontal="16dp"
|
||||
android:layout_marginVertical="8dp" />
|
||||
|
||||
<androidx.recyclerview.widget.RecyclerView
|
||||
android:id="@+id/messages"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="0dp"
|
||||
android:layout_weight="4"
|
||||
android:padding="16dp"
|
||||
android:fadeScrollbars="false"
|
||||
android:scrollbars="vertical"
|
||||
app:reverseLayout="true"
|
||||
tools:listitem="@layout/item_message_assistant"/>
|
||||
|
||||
<LinearLayout
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:orientation="horizontal">
|
||||
android:orientation="horizontal"
|
||||
android:paddingStart="16dp"
|
||||
android:paddingEnd="4dp">
|
||||
|
||||
<EditText
|
||||
android:id="@+id/user_input"
|
||||
|
|
@ -67,7 +69,7 @@
|
|||
style="@style/Widget.Material3.FloatingActionButton.Primary"
|
||||
android:layout_width="wrap_content"
|
||||
android:layout_height="wrap_content"
|
||||
android:layout_margin="8dp"
|
||||
android:layout_margin="12dp"
|
||||
android:src="@drawable/outline_folder_open_24" />
|
||||
|
||||
</LinearLayout>
|
||||
|
|
|
|||
|
|
@ -2,7 +2,8 @@
|
|||
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:padding="8dp"
|
||||
android:layout_marginHorizontal="16dp"
|
||||
android:layout_marginVertical="8dp"
|
||||
android:gravity="start">
|
||||
|
||||
<TextView
|
||||
|
|
|
|||
|
|
@ -2,7 +2,8 @@
|
|||
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:padding="8dp"
|
||||
android:layout_marginHorizontal="16dp"
|
||||
android:layout_marginVertical="8dp"
|
||||
android:gravity="end">
|
||||
|
||||
<TextView
|
||||
|
|
|
|||
|
|
@ -2,135 +2,22 @@
|
|||
|
||||
import argparse
|
||||
import os
|
||||
import sys
|
||||
import importlib
|
||||
from pathlib import Path
|
||||
|
||||
# Add parent directory to path for imports
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..'))
|
||||
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoModelForImageTextToText, AutoConfig
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
### If you want to dump RoPE activations, apply this monkey patch to the model
|
||||
### class from Transformers that you are running (replace apertus.modeling_apertus
|
||||
### with the proper package and class for your model
|
||||
### === START ROPE DEBUG ===
|
||||
# from transformers.models.apertus.modeling_apertus import apply_rotary_pos_emb
|
||||
|
||||
# orig_rope = apply_rotary_pos_emb
|
||||
# torch.set_printoptions(threshold=float('inf'))
|
||||
# torch.set_printoptions(precision=6, sci_mode=False)
|
||||
|
||||
# def debug_rope(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
|
||||
# # log inputs
|
||||
# summarize(q, "RoPE.q_in")
|
||||
# summarize(k, "RoPE.k_in")
|
||||
|
||||
# # call original
|
||||
# q_out, k_out = orig_rope(q, k, cos, sin, position_ids, unsqueeze_dim)
|
||||
|
||||
# # log outputs
|
||||
# summarize(q_out, "RoPE.q_out")
|
||||
# summarize(k_out, "RoPE.k_out")
|
||||
|
||||
# return q_out, k_out
|
||||
|
||||
# # Patch it
|
||||
# import transformers.models.apertus.modeling_apertus as apertus_mod # noqa: E402
|
||||
# apertus_mod.apply_rotary_pos_emb = debug_rope
|
||||
### == END ROPE DEBUG ===
|
||||
|
||||
|
||||
def summarize(tensor: torch.Tensor, name: str, max_seq: int = 3, max_vals: int = 3):
|
||||
"""
|
||||
Print a tensor in llama.cpp debug style.
|
||||
|
||||
Supports:
|
||||
- 2D tensors (seq, hidden)
|
||||
- 3D tensors (batch, seq, hidden)
|
||||
- 4D tensors (batch, seq, heads, dim_per_head) via flattening heads × dim_per_head
|
||||
|
||||
Shows first and last max_vals of each vector per sequence position.
|
||||
"""
|
||||
t = tensor.detach().to(torch.float32).cpu()
|
||||
|
||||
# Determine dimensions
|
||||
if t.ndim == 3:
|
||||
_, s, _ = t.shape
|
||||
elif t.ndim == 2:
|
||||
_, s = 1, t.shape[0]
|
||||
t = t.unsqueeze(0)
|
||||
elif t.ndim == 4:
|
||||
_, s, _, _ = t.shape
|
||||
else:
|
||||
print(f"Skipping tensor due to unsupported dimensions: {t.ndim}")
|
||||
return
|
||||
|
||||
ten_shape = t.shape
|
||||
|
||||
print(f"ggml_debug: {name} = (f32) ... = {{{ten_shape}}}")
|
||||
print(" [")
|
||||
print(" [")
|
||||
|
||||
# Determine indices for first and last sequences
|
||||
first_indices = list(range(min(s, max_seq)))
|
||||
last_indices = list(range(max(0, s - max_seq), s))
|
||||
|
||||
# Check if there's an overlap between first and last indices or if we're at the edge case of s = 2 * max_seq
|
||||
has_overlap = bool(set(first_indices) & set(last_indices)) or (max_seq * 2 == s)
|
||||
|
||||
# Combine indices
|
||||
if has_overlap:
|
||||
# If there's overlap, just use the combined unique indices
|
||||
indices = sorted(list(set(first_indices + last_indices)))
|
||||
separator_index = None
|
||||
else:
|
||||
# If no overlap, we'll add a separator between first and last sequences
|
||||
indices = first_indices + last_indices
|
||||
separator_index = len(first_indices)
|
||||
|
||||
for i, si in enumerate(indices):
|
||||
# Add separator if needed
|
||||
if separator_index is not None and i == separator_index:
|
||||
print(" ...")
|
||||
|
||||
# Extract appropriate slice
|
||||
vec = t[0, si]
|
||||
if vec.ndim == 2: # 4D case: flatten heads × dim_per_head
|
||||
flat = vec.flatten().tolist()
|
||||
else: # 2D or 3D case
|
||||
flat = vec.tolist()
|
||||
|
||||
# First and last slices
|
||||
first = flat[:max_vals]
|
||||
last = flat[-max_vals:] if len(flat) >= max_vals else flat
|
||||
first_str = ", ".join(f"{v:12.4f}" for v in first)
|
||||
last_str = ", ".join(f"{v:12.4f}" for v in last)
|
||||
|
||||
print(f" [{first_str}, ..., {last_str}]")
|
||||
|
||||
print(" ],")
|
||||
print(" ]")
|
||||
print(f" sum = {t.sum().item():.6f}\n")
|
||||
|
||||
|
||||
def debug_hook(name):
|
||||
def fn(_m, input, output):
|
||||
if isinstance(input, torch.Tensor):
|
||||
summarize(input, name + "_in")
|
||||
elif isinstance(input, (tuple, list)) and len(input) > 0 and isinstance(input[0], torch.Tensor):
|
||||
summarize(input[0], name + "_in")
|
||||
if isinstance(output, torch.Tensor):
|
||||
summarize(output, name + "_out")
|
||||
elif isinstance(output, (tuple, list)) and len(output) > 0 and isinstance(output[0], torch.Tensor):
|
||||
summarize(output[0], name + "_out")
|
||||
|
||||
return fn
|
||||
|
||||
|
||||
unreleased_model_name = os.getenv("UNRELEASED_MODEL_NAME")
|
||||
from utils.common import debug_hook
|
||||
|
||||
parser = argparse.ArgumentParser(description="Process model with specified path")
|
||||
parser.add_argument("--model-path", "-m", help="Path to the model")
|
||||
parser.add_argument("--prompt-file", "-f", help="Optional prompt file", required=False)
|
||||
parser.add_argument("--verbose", "-v", action="store_true", help="Enable verbose debug output")
|
||||
args = parser.parse_args()
|
||||
|
||||
model_path = os.environ.get("MODEL_PATH", args.model_path)
|
||||
|
|
@ -139,6 +26,12 @@ if model_path is None:
|
|||
"Model path must be specified either via --model-path argument or MODEL_PATH environment variable"
|
||||
)
|
||||
|
||||
### If you want to dump RoPE activations, uncomment the following lines:
|
||||
### === START ROPE DEBUG ===
|
||||
# from utils.common import setup_rope_debug
|
||||
# setup_rope_debug("transformers.models.apertus.modeling_apertus")
|
||||
### == END ROPE DEBUG ===
|
||||
|
||||
|
||||
print("Loading model and tokenizer using AutoTokenizer:", model_path)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
|
||||
|
|
@ -156,6 +49,7 @@ print("Number of layers: ", config.num_hidden_layers)
|
|||
print("BOS token id: ", config.bos_token_id)
|
||||
print("EOS token id: ", config.eos_token_id)
|
||||
|
||||
unreleased_model_name = os.getenv("UNRELEASED_MODEL_NAME")
|
||||
if unreleased_model_name:
|
||||
model_name_lower = unreleased_model_name.lower()
|
||||
unreleased_module_path = (
|
||||
|
|
@ -184,9 +78,10 @@ else:
|
|||
model_path, device_map="auto", offload_folder="offload", trust_remote_code=True, config=config
|
||||
)
|
||||
|
||||
for name, module in model.named_modules():
|
||||
if len(list(module.children())) == 0: # only leaf modules
|
||||
module.register_forward_hook(debug_hook(name))
|
||||
if args.verbose:
|
||||
for name, module in model.named_modules():
|
||||
if len(list(module.children())) == 0: # only leaf modules
|
||||
module.register_forward_hook(debug_hook(name))
|
||||
|
||||
model_name = os.path.basename(model_path)
|
||||
# Printing the Model class to allow for easier debugging. This can be useful
|
||||
|
|
|
|||
|
|
@ -2,6 +2,8 @@
|
|||
|
||||
import os
|
||||
import sys
|
||||
import torch
|
||||
|
||||
|
||||
def get_model_name_from_env_path(env_path_name):
|
||||
model_path = os.getenv(env_path_name)
|
||||
|
|
@ -18,3 +20,131 @@ def get_model_name_from_env_path(env_path_name):
|
|||
name = name[:-5]
|
||||
|
||||
return name
|
||||
|
||||
|
||||
def summarize(tensor: torch.Tensor, name: str, max_seq: int = 3, max_vals: int = 3):
|
||||
"""
|
||||
Print a tensor in llama.cpp debug style.
|
||||
|
||||
Supports:
|
||||
- 2D tensors (seq, hidden)
|
||||
- 3D tensors (batch, seq, hidden)
|
||||
- 4D tensors (batch, seq, heads, dim_per_head) via flattening heads × dim_per_head
|
||||
|
||||
Shows first and last max_vals of each vector per sequence position.
|
||||
"""
|
||||
t = tensor.detach().to(torch.float32).cpu()
|
||||
|
||||
# Determine dimensions
|
||||
if t.ndim == 3:
|
||||
_, s, _ = t.shape
|
||||
elif t.ndim == 2:
|
||||
_, s = 1, t.shape[0]
|
||||
t = t.unsqueeze(0)
|
||||
elif t.ndim == 4:
|
||||
_, s, _, _ = t.shape
|
||||
else:
|
||||
print(f"Skipping tensor due to unsupported dimensions: {t.ndim}")
|
||||
return
|
||||
|
||||
ten_shape = t.shape
|
||||
|
||||
print(f"ggml_debug: {name} = (f32) ... = {{{ten_shape}}}")
|
||||
print(" [")
|
||||
print(" [")
|
||||
|
||||
# Determine indices for first and last sequences
|
||||
first_indices = list(range(min(s, max_seq)))
|
||||
last_indices = list(range(max(0, s - max_seq), s))
|
||||
|
||||
# Check if there's an overlap between first and last indices or if we're at the edge case of s = 2 * max_seq
|
||||
has_overlap = bool(set(first_indices) & set(last_indices)) or (max_seq * 2 == s)
|
||||
|
||||
# Combine indices
|
||||
if has_overlap:
|
||||
# If there's overlap, just use the combined unique indices
|
||||
indices = sorted(list(set(first_indices + last_indices)))
|
||||
separator_index = None
|
||||
else:
|
||||
# If no overlap, we'll add a separator between first and last sequences
|
||||
indices = first_indices + last_indices
|
||||
separator_index = len(first_indices)
|
||||
|
||||
for i, si in enumerate(indices):
|
||||
# Add separator if needed
|
||||
if separator_index is not None and i == separator_index:
|
||||
print(" ...")
|
||||
|
||||
# Extract appropriate slice
|
||||
vec = t[0, si]
|
||||
if vec.ndim == 2: # 4D case: flatten heads × dim_per_head
|
||||
flat = vec.flatten().tolist()
|
||||
else: # 2D or 3D case
|
||||
flat = vec.tolist()
|
||||
|
||||
# First and last slices
|
||||
first = flat[:max_vals]
|
||||
last = flat[-max_vals:] if len(flat) >= max_vals else flat
|
||||
first_str = ", ".join(f"{v:12.4f}" for v in first)
|
||||
last_str = ", ".join(f"{v:12.4f}" for v in last)
|
||||
|
||||
print(f" [{first_str}, ..., {last_str}]")
|
||||
|
||||
print(" ],")
|
||||
print(" ]")
|
||||
print(f" sum = {t.sum().item():.6f}\n")
|
||||
|
||||
|
||||
def debug_hook(name):
|
||||
def fn(_m, input, output):
|
||||
if isinstance(input, torch.Tensor):
|
||||
summarize(input, name + "_in")
|
||||
elif isinstance(input, (tuple, list)) and len(input) > 0 and isinstance(input[0], torch.Tensor):
|
||||
summarize(input[0], name + "_in")
|
||||
if isinstance(output, torch.Tensor):
|
||||
summarize(output, name + "_out")
|
||||
elif isinstance(output, (tuple, list)) and len(output) > 0 and isinstance(output[0], torch.Tensor):
|
||||
summarize(output[0], name + "_out")
|
||||
|
||||
return fn
|
||||
|
||||
|
||||
def setup_rope_debug(model_module_path: str, function_name: str = "apply_rotary_pos_emb"):
|
||||
"""
|
||||
Apply monkey patch to dump RoPE activations for debugging.
|
||||
|
||||
Args:
|
||||
model_module_path: Path to the model module (e.g., "transformers.models.apertus.modeling_apertus")
|
||||
function_name: Name of the RoPE function to patch (default: "apply_rotary_pos_emb")
|
||||
|
||||
Example:
|
||||
from utils.common import setup_rope_debug
|
||||
setup_rope_debug("transformers.models.apertus.modeling_apertus")
|
||||
"""
|
||||
import importlib
|
||||
|
||||
# Import the module and get the original function
|
||||
module = importlib.import_module(model_module_path)
|
||||
orig_rope = getattr(module, function_name)
|
||||
|
||||
# Set torch print options for better debugging
|
||||
torch.set_printoptions(threshold=float('inf'))
|
||||
torch.set_printoptions(precision=6, sci_mode=False)
|
||||
|
||||
def debug_rope(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
|
||||
# log inputs
|
||||
summarize(q, "RoPE.q_in")
|
||||
summarize(k, "RoPE.k_in")
|
||||
|
||||
# call original
|
||||
q_out, k_out = orig_rope(q, k, cos, sin, position_ids, unsqueeze_dim)
|
||||
|
||||
# log outputs
|
||||
summarize(q_out, "RoPE.q_out")
|
||||
summarize(k_out, "RoPE.k_out")
|
||||
|
||||
return q_out, k_out
|
||||
|
||||
# Patch it
|
||||
setattr(module, function_name, debug_rope)
|
||||
print(f"RoPE debug patching applied to {model_module_path}.{function_name}")
|
||||
|
|
|
|||
|
|
@ -254,6 +254,7 @@ set (GGML_OPENCL_TARGET_VERSION "300" CACHE STRING
|
|||
"gmml: OpenCL API version to target")
|
||||
|
||||
option(GGML_HEXAGON "ggml: enable Hexagon backend" OFF)
|
||||
set(GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE 128 CACHE STRING "ggml: quantize group size (32, 64, or 128)")
|
||||
|
||||
# toolchain for vulkan-shaders-gen
|
||||
set (GGML_VULKAN_SHADERS_GEN_TOOLCHAIN "" CACHE FILEPATH "ggml: toolchain file for vulkan-shaders-gen")
|
||||
|
|
|
|||
|
|
@ -102,31 +102,25 @@ static void ssm_conv_f32_cuda(const float * src0, const float * src1, const int
|
|||
const int threads = 128;
|
||||
GGML_ASSERT(nr % threads == 0);
|
||||
|
||||
if (n_t <= 32) {
|
||||
const dim3 blocks(n_s, (nr + threads - 1) / threads, 1);
|
||||
if (nc == 4) {
|
||||
ssm_conv_f32<threads, 4><<<blocks, threads, 0, stream>>>(src0, src1, src0_nb0, src0_nb1, src0_nb2, src1_nb1,
|
||||
dst, dst_nb0, dst_nb1, dst_nb2, n_t);
|
||||
} else if (nc == 3) {
|
||||
ssm_conv_f32<threads, 3><<<blocks, threads, 0, stream>>>(src0, src1, src0_nb0, src0_nb1, src0_nb2, src1_nb1,
|
||||
dst, dst_nb0, dst_nb1, dst_nb2, n_t);
|
||||
auto launch_kernel = [&](auto NC) {
|
||||
constexpr int kNC = decltype(NC)::value;
|
||||
if (n_t <= 32) {
|
||||
const dim3 blocks(n_s, (nr + threads - 1) / threads, 1);
|
||||
ssm_conv_f32<threads, kNC><<<blocks, threads, 0, stream>>>(src0, src1, src0_nb0, src0_nb1, src0_nb2, src1_nb1,
|
||||
dst, dst_nb0, dst_nb1, dst_nb2, n_t);
|
||||
} else {
|
||||
GGML_ABORT("Only support kernel size = 3 or size = 4 right now.");
|
||||
}
|
||||
} else {
|
||||
if (nc == 4) {
|
||||
const int64_t split_n_t = 32;
|
||||
dim3 blocks(n_s, (nr + threads - 1) / threads, (n_t + split_n_t - 1) / split_n_t);
|
||||
ssm_conv_long_token_f32<threads, 4, split_n_t><<<blocks, threads, 0, stream>>>(
|
||||
ssm_conv_long_token_f32<threads, kNC, split_n_t><<<blocks, threads, 0, stream>>>(
|
||||
src0, src1, src0_nb0, src0_nb1, src0_nb2, src1_nb1, dst, dst_nb0, dst_nb1, dst_nb2, n_t);
|
||||
} else if (nc == 3) {
|
||||
const int64_t split_n_t = 32;
|
||||
dim3 blocks(n_s, (nr + threads - 1) / threads, (n_t + split_n_t - 1) / split_n_t);
|
||||
ssm_conv_long_token_f32<threads, 3, split_n_t><<<blocks, threads, 0, stream>>>(
|
||||
src0, src1, src0_nb0, src0_nb1, src0_nb2, src1_nb1, dst, dst_nb0, dst_nb1, dst_nb2, n_t);
|
||||
} else {
|
||||
GGML_ABORT("Only support kernel size = 3 or size = 4 right now.");
|
||||
}
|
||||
};
|
||||
|
||||
switch (nc) {
|
||||
case 3: launch_kernel(std::integral_constant<int, 3>{}); break;
|
||||
case 4: launch_kernel(std::integral_constant<int, 4>{}); break;
|
||||
case 9: launch_kernel(std::integral_constant<int, 9>{}); break;
|
||||
default: GGML_ABORT("Only support kernel sizes 3, 4, 9 right now.");
|
||||
}
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -2,6 +2,7 @@ include(${HEXAGON_SDK_ROOT}/build/cmake/hexagon_fun.cmake)
|
|||
include(ExternalProject)
|
||||
|
||||
option(GGML_HEXAGON_HTP_DEBUG "ggml-hexagon: enable HTP debug output" OFF)
|
||||
set(GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE 128 CACHE STRING "ggml-hexagon: quantize group size (32, 64, or 128)")
|
||||
|
||||
add_library(htp_iface OBJECT
|
||||
${CMAKE_CURRENT_BINARY_DIR}/htp_iface_stub.c)
|
||||
|
|
@ -41,7 +42,8 @@ set(HTP_CMAKE_ARGS
|
|||
-DCMAKE_INSTALL_LIBDIR=${CMAKE_CURRENT_BINARY_DIR}
|
||||
-DHEXAGON_SDK_ROOT=$ENV{HEXAGON_SDK_ROOT}
|
||||
-DHEXAGON_TOOLS_ROOT=$ENV{HEXAGON_TOOLS_ROOT}
|
||||
-DHEXAGON_HTP_DEBUG=${GGML_HEXAGON_HTP_DEBUG})
|
||||
-DHEXAGON_HTP_DEBUG=${GGML_HEXAGON_HTP_DEBUG}
|
||||
-DGGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE=${GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE})
|
||||
|
||||
ExternalProject_Add(htp-v68
|
||||
SOURCE_DIR ${CMAKE_CURRENT_SOURCE_DIR}/htp BUILD_ALWAYS ON
|
||||
|
|
|
|||
|
|
@ -31,7 +31,8 @@ add_library(${HTP_LIB} SHARED
|
|||
)
|
||||
|
||||
target_compile_definitions(${HTP_LIB} PRIVATE
|
||||
$<IF:$<BOOL:${HEXAGON_HTP_DEBUG}>,HTP_DEBUG=1,NDEBUG=1>)
|
||||
$<IF:$<BOOL:${HEXAGON_HTP_DEBUG}>,HTP_DEBUG=1,NDEBUG=1>
|
||||
FP32_QUANTIZE_GROUP_SIZE=${GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE})
|
||||
|
||||
build_idl(htp_iface.idl ${HTP_LIB})
|
||||
|
||||
|
|
|
|||
|
|
@ -92,6 +92,18 @@ static const uint8_t __attribute__((aligned(128))) repl_1x_fp16[128] = {
|
|||
0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
};
|
||||
|
||||
// vdelta control to replicate first fp16 value across all elements
|
||||
static const uint8_t __attribute__((aligned(128))) repl_2x_fp16[128] = {
|
||||
0x00, 0x00, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
0x10, 0x10, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
0x20, 0x20, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
0x10, 0x10, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
0x00, 0x00, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
0x10, 0x10, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
0x20, 0x20, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
0x10, 0x10, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02, 0x08, 0x08, 0x02, 0x02, 0x04, 0x04, 0x02, 0x02,
|
||||
};
|
||||
|
||||
// vdelta control to expand first 32 e8m0 values into 32 uint32 elements
|
||||
static const uint8_t __attribute__((aligned(128))) expand_x32_e8m0[128] = {
|
||||
0x00, 0x00, 0x00, 0x00, 0x01, 0x04, 0x00, 0x00, 0x02, 0x00, 0x08, 0x08, 0x01, 0x02, 0x00, 0x04, 0x04, 0x00, 0x00,
|
||||
|
|
@ -1594,6 +1606,118 @@ static void matmul_f16_f32(struct htp_tensor * restrict src0,
|
|||
|
||||
// *** dynamic quant
|
||||
|
||||
static inline void quantize_block_fp32_q8x1(float * restrict x, uint8_t * restrict y_q, uint8_t * restrict y_d) {
|
||||
assert((unsigned long) x % 128 == 0);
|
||||
assert((unsigned long) y_q % 128 == 0);
|
||||
|
||||
HVX_Vector * vx = (HVX_Vector *) x;
|
||||
HVX_Vector zero = Q6_V_vsplat_R(0);
|
||||
|
||||
// Use reduce max fp32 to find max(abs(e)) first
|
||||
HVX_Vector vmax0_sf = hvx_vec_reduce_max_fp32(hvx_vec_abs_fp32(vx[0]));
|
||||
HVX_Vector vmax1_sf = hvx_vec_reduce_max_fp32(hvx_vec_abs_fp32(vx[1]));
|
||||
HVX_Vector vmax2_sf = hvx_vec_reduce_max_fp32(hvx_vec_abs_fp32(vx[2]));
|
||||
HVX_Vector vmax3_sf = hvx_vec_reduce_max_fp32(hvx_vec_abs_fp32(vx[3]));
|
||||
// Load and convert into QF32
|
||||
HVX_Vector vx0_qf = Q6_Vqf32_vsub_VsfVsf(vx[0], zero); // 32 elements
|
||||
HVX_Vector vx1_qf = Q6_Vqf32_vsub_VsfVsf(vx[1], zero); // 32 elements
|
||||
HVX_Vector vx2_qf = Q6_Vqf32_vsub_VsfVsf(vx[2], zero); // 32 elements
|
||||
HVX_Vector vx3_qf = Q6_Vqf32_vsub_VsfVsf(vx[3], zero); // 32 elements
|
||||
|
||||
// Convert to QF32
|
||||
HVX_Vector vmax0_qf = Q6_Vqf32_vsub_VsfVsf(vmax0_sf, zero);
|
||||
HVX_Vector vmax1_qf = Q6_Vqf32_vsub_VsfVsf(vmax1_sf, zero);
|
||||
HVX_Vector vmax2_qf = Q6_Vqf32_vsub_VsfVsf(vmax2_sf, zero);
|
||||
HVX_Vector vmax3_qf = Q6_Vqf32_vsub_VsfVsf(vmax3_sf, zero);
|
||||
|
||||
// Combine and convert to fp16
|
||||
HVX_Vector vmax01_hf = Q6_Vh_vdeal_Vh(Q6_Vhf_equals_Wqf32(Q6_W_vcombine_VV(vmax1_qf, vmax0_qf)));
|
||||
HVX_Vector vmax23_hf = Q6_Vh_vdeal_Vh(Q6_Vhf_equals_Wqf32(Q6_W_vcombine_VV(vmax3_qf, vmax2_qf)));
|
||||
|
||||
// Convert into fp16
|
||||
HVX_Vector vx01_hf = Q6_Vh_vdeal_Vh(Q6_Vhf_equals_Wqf32(Q6_W_vcombine_VV(vx1_qf, vx0_qf)));
|
||||
HVX_Vector vx23_hf = Q6_Vh_vdeal_Vh(Q6_Vhf_equals_Wqf32(Q6_W_vcombine_VV(vx3_qf, vx2_qf)));
|
||||
|
||||
// Replicate first fp16 scale across all lanes
|
||||
HVX_Vector ctrl = *(const HVX_Vector *) repl_2x_fp16;
|
||||
vmax01_hf = Q6_V_vdelta_VV(vmax01_hf, ctrl);
|
||||
vmax23_hf = Q6_V_vdelta_VV(vmax23_hf, ctrl);
|
||||
|
||||
HVX_Vector vd01_qf16 = Q6_Vqf16_vmpy_VhfVhf(vmax01_hf, Q6_Vh_vsplat_R(0x2008)); // 1.0 / 127.0
|
||||
HVX_Vector vd23_qf16 = Q6_Vqf16_vmpy_VhfVhf(vmax23_hf, Q6_Vh_vsplat_R(0x2008)); // 1.0 / 127.0
|
||||
HVX_Vector vd01_hf = Q6_Vhf_equals_Vqf16(vd01_qf16);
|
||||
HVX_Vector vd23_hf = Q6_Vhf_equals_Vqf16(vd23_qf16);
|
||||
|
||||
hvx_vec_store_u(y_d + 0, 2, vd01_hf);
|
||||
HVX_Vector rotated_vd_hf = Q6_V_vror_VR(vd01_hf, 64);
|
||||
hvx_vec_store_u(y_d + 2, 2, rotated_vd_hf);
|
||||
|
||||
hvx_vec_store_u(y_d + 4, 2, vd23_hf);
|
||||
rotated_vd_hf = Q6_V_vror_VR(vd23_hf, 64);
|
||||
hvx_vec_store_u(y_d + 6, 2, rotated_vd_hf);
|
||||
|
||||
// Divide input by the scale
|
||||
HVX_Vector vd01_inv_hf = hvx_vec_inverse_fp16(vd01_hf);
|
||||
HVX_Vector vd23_inv_hf = hvx_vec_inverse_fp16(vd23_hf);
|
||||
vx01_hf = Q6_Vhf_equals_Vqf16(Q6_Vqf16_vmpy_VhfVhf(vx01_hf, vd01_inv_hf));
|
||||
vx23_hf = Q6_Vhf_equals_Vqf16(Q6_Vqf16_vmpy_VhfVhf(vx23_hf, vd23_inv_hf));
|
||||
|
||||
// Convert to int8
|
||||
HVX_Vector vx01_i16 = hvx_vec_i16_from_hf_rnd_sat(vx01_hf);
|
||||
HVX_Vector vx23_i16 = hvx_vec_i16_from_hf_rnd_sat(vx23_hf);
|
||||
HVX_Vector vx_i8 = Q6_Vb_vpack_VhVh_sat(vx23_i16, vx01_i16);
|
||||
|
||||
*(HVX_Vector *) y_q = vx_i8;
|
||||
}
|
||||
|
||||
static inline void quantize_block_fp32_q8x2(float * restrict x, uint8_t * restrict y_q, uint8_t * restrict y_d) {
|
||||
assert((unsigned long) x % 128 == 0);
|
||||
assert((unsigned long) y_q % 128 == 0);
|
||||
|
||||
HVX_Vector * vx = (HVX_Vector *) x;
|
||||
|
||||
// Load and convert into QF32
|
||||
HVX_Vector zero = Q6_V_vsplat_R(0);
|
||||
HVX_Vector vx0_qf = Q6_Vqf32_vsub_VsfVsf(vx[0], zero); // 32 elements
|
||||
HVX_Vector vx1_qf = Q6_Vqf32_vsub_VsfVsf(vx[1], zero); // 32 elements
|
||||
HVX_Vector vx2_qf = Q6_Vqf32_vsub_VsfVsf(vx[2], zero); // 32 elements
|
||||
HVX_Vector vx3_qf = Q6_Vqf32_vsub_VsfVsf(vx[3], zero); // 32 elements
|
||||
|
||||
// Convert into fp16
|
||||
HVX_Vector vx01_hf = Q6_Vh_vdeal_Vh(Q6_Vhf_equals_Wqf32(Q6_W_vcombine_VV(vx1_qf, vx0_qf)));
|
||||
HVX_Vector vx23_hf = Q6_Vh_vdeal_Vh(Q6_Vhf_equals_Wqf32(Q6_W_vcombine_VV(vx3_qf, vx2_qf)));
|
||||
|
||||
// Compute max and scale
|
||||
HVX_Vector vmax01_hf = hvx_vec_reduce_max_fp16(hvx_vec_abs_fp16(vx01_hf));
|
||||
HVX_Vector vmax23_hf = hvx_vec_reduce_max_fp16(hvx_vec_abs_fp16(vx23_hf));
|
||||
|
||||
// Replicate first fp16 scale across all lanes
|
||||
HVX_Vector ctrl = *(const HVX_Vector *) repl_1x_fp16;
|
||||
vmax01_hf = Q6_V_vdelta_VV(vmax01_hf, ctrl);
|
||||
vmax23_hf = Q6_V_vdelta_VV(vmax23_hf, ctrl);
|
||||
|
||||
HVX_Vector vd01_qf16 = Q6_Vqf16_vmpy_VhfVhf(vmax01_hf, Q6_Vh_vsplat_R(0x2008)); // 1.0 / 127.0
|
||||
HVX_Vector vd23_qf16 = Q6_Vqf16_vmpy_VhfVhf(vmax23_hf, Q6_Vh_vsplat_R(0x2008)); // 1.0 / 127.0
|
||||
HVX_Vector vd01_hf = Q6_Vhf_equals_Vqf16(vd01_qf16);
|
||||
HVX_Vector vd23_hf = Q6_Vhf_equals_Vqf16(vd23_qf16);
|
||||
|
||||
hvx_vec_store_u(y_d + 0, 4, vd01_hf);
|
||||
hvx_vec_store_u(y_d + 4, 4, vd23_hf);
|
||||
|
||||
// Divide input by the scale
|
||||
HVX_Vector vd01_inv_hf = hvx_vec_inverse_fp16(vd01_hf);
|
||||
HVX_Vector vd23_inv_hf = hvx_vec_inverse_fp16(vd23_hf);
|
||||
vx01_hf = Q6_Vhf_equals_Vqf16(Q6_Vqf16_vmpy_VhfVhf(vx01_hf, vd01_inv_hf));
|
||||
vx23_hf = Q6_Vhf_equals_Vqf16(Q6_Vqf16_vmpy_VhfVhf(vx23_hf, vd23_inv_hf));
|
||||
|
||||
// Convert to int8
|
||||
HVX_Vector vx01_i16 = hvx_vec_i16_from_hf_rnd_sat(vx01_hf);
|
||||
HVX_Vector vx23_i16 = hvx_vec_i16_from_hf_rnd_sat(vx23_hf);
|
||||
HVX_Vector vx_i8 = Q6_Vb_vpack_VhVh_sat(vx23_i16, vx01_i16);
|
||||
|
||||
*(HVX_Vector *) y_q = vx_i8;
|
||||
}
|
||||
|
||||
static inline void quantize_block_fp32_q8x4(float * restrict x, uint8_t * restrict y_q, uint8_t * restrict y_d) {
|
||||
assert((unsigned long) x % 128 == 0);
|
||||
assert((unsigned long) y_q % 128 == 0);
|
||||
|
|
@ -1655,10 +1779,24 @@ static void quantize_row_fp32_q8x4x2(float * restrict x, uint8_t * restrict y, u
|
|||
uint8_t * restrict t_d = (uint8_t *) x;
|
||||
|
||||
for (uint32_t i = 0; i < nb; i++) {
|
||||
#if FP32_QUANTIZE_GROUP_SIZE == 32
|
||||
quantize_block_fp32_q8x1(x + (i * 2 + 0) * qk / 2, y_q + (i * 2 + 0) * qblk_size / 2,
|
||||
t_d + (i * 2 + 0) * dblk_size / 2);
|
||||
quantize_block_fp32_q8x1(x + (i * 2 + 1) * qk / 2, y_q + (i * 2 + 1) * qblk_size / 2,
|
||||
t_d + (i * 2 + 1) * dblk_size / 2);
|
||||
#elif FP32_QUANTIZE_GROUP_SIZE == 64
|
||||
quantize_block_fp32_q8x2(x + (i * 2 + 0) * qk / 2, y_q + (i * 2 + 0) * qblk_size / 2,
|
||||
t_d + (i * 2 + 0) * dblk_size / 2);
|
||||
quantize_block_fp32_q8x2(x + (i * 2 + 1) * qk / 2, y_q + (i * 2 + 1) * qblk_size / 2,
|
||||
t_d + (i * 2 + 1) * dblk_size / 2);
|
||||
#elif FP32_QUANTIZE_GROUP_SIZE == 128
|
||||
quantize_block_fp32_q8x4(x + (i * 2 + 0) * qk / 2, y_q + (i * 2 + 0) * qblk_size / 2,
|
||||
t_d + (i * 2 + 0) * dblk_size / 2);
|
||||
quantize_block_fp32_q8x4(x + (i * 2 + 1) * qk / 2, y_q + (i * 2 + 1) * qblk_size / 2,
|
||||
t_d + (i * 2 + 1) * dblk_size / 2);
|
||||
#else
|
||||
#error "FP32_QUANTIZE_GROUP_SIZE must be 32, 64, or 128"
|
||||
#endif
|
||||
}
|
||||
|
||||
// now copy the scales into final location
|
||||
|
|
@ -1671,6 +1809,7 @@ static void quantize_fp32_q8x4x2(const struct htp_tensor * src,
|
|||
uint32_t nth,
|
||||
uint32_t ith,
|
||||
uint32_t nrows_per_thread) {
|
||||
|
||||
uint64_t t1 = HAP_perf_get_qtimer_count();
|
||||
|
||||
const uint32_t ne0 = src->ne[0];
|
||||
|
|
|
|||
|
|
@ -1527,6 +1527,8 @@ private:
|
|||
#endif // GGML_VULKAN_MEMORY_DEBUG
|
||||
|
||||
static bool vk_perf_logger_enabled = false;
|
||||
static bool vk_perf_logger_concurrent = false;
|
||||
static bool vk_enable_sync_logger = false;
|
||||
// number of calls between perf logger prints
|
||||
static uint32_t vk_perf_logger_frequency = 1;
|
||||
|
||||
|
|
@ -1577,14 +1579,14 @@ class vk_perf_logger {
|
|||
flops.clear();
|
||||
}
|
||||
|
||||
void log_timing(const ggml_tensor * node, const char *fusion_name, uint64_t time) {
|
||||
std::string get_node_fusion_name(const ggml_tensor * node, const char *fusion_name, uint64_t *n_flops) {
|
||||
*n_flops = 0;
|
||||
std::string fusion_str;
|
||||
if (fusion_name) {
|
||||
fusion_str = fusion_name + std::string(" ");
|
||||
}
|
||||
if (node->op == GGML_OP_UNARY) {
|
||||
timings[fusion_str + ggml_unary_op_name(ggml_get_unary_op(node))].push_back(time);
|
||||
return;
|
||||
return fusion_str + ggml_unary_op_name(ggml_get_unary_op(node));
|
||||
}
|
||||
if (node->op == GGML_OP_MUL_MAT || node->op == GGML_OP_MUL_MAT_ID) {
|
||||
const uint64_t m = node->ne[0];
|
||||
|
|
@ -1606,9 +1608,8 @@ class vk_perf_logger {
|
|||
name += " batch=" + std::to_string(batch);
|
||||
}
|
||||
name = fusion_str + name;
|
||||
timings[name].push_back(time);
|
||||
flops[name].push_back(m * n * (k + (k - 1)) * batch);
|
||||
return;
|
||||
*n_flops = m * n * (k + (k - 1)) * batch;
|
||||
return name;
|
||||
}
|
||||
if (node->op == GGML_OP_CONV_2D || node->op == GGML_OP_CONV_TRANSPOSE_2D) {
|
||||
std::string name = ggml_op_name(node->op);
|
||||
|
|
@ -1624,20 +1625,17 @@ class vk_perf_logger {
|
|||
uint64_t size_M = Cout;
|
||||
uint64_t size_K = Cin * KW * KH;
|
||||
uint64_t size_N = N * OW * OH;
|
||||
uint64_t n_flops = size_M * size_N * (size_K + (size_K - 1));
|
||||
*n_flops = size_M * size_N * (size_K + (size_K - 1));
|
||||
name += " M=Cout=" + std::to_string(size_M) + ", K=Cin*KW*KH=" + std::to_string(size_K) +
|
||||
", N=N*OW*OH=" + std::to_string(size_N);
|
||||
name = fusion_str + name;
|
||||
flops[name].push_back(n_flops);
|
||||
timings[name].push_back(time);
|
||||
return;
|
||||
return name;
|
||||
}
|
||||
if (node->op == GGML_OP_RMS_NORM) {
|
||||
std::string name = ggml_op_name(node->op);
|
||||
name += "(" + std::to_string(node->ne[0]) + "," + std::to_string(node->ne[1]) + "," + std::to_string(node->ne[2]) + "," + std::to_string(node->ne[3]) + ")";
|
||||
name = fusion_str + name;
|
||||
timings[name].push_back(time);
|
||||
return;
|
||||
return name;
|
||||
}
|
||||
if (node->op == GGML_OP_FLASH_ATTN_EXT) {
|
||||
const ggml_tensor * dst = node;
|
||||
|
|
@ -1653,8 +1651,7 @@ class vk_perf_logger {
|
|||
" k(" << k->ne[0] << "," << k->ne[1] << "," << k->ne[2] << "," << k->ne[3] << "), " <<
|
||||
" v(" << v->ne[0] << "," << v->ne[1] << "," << v->ne[2] << "," << v->ne[3] << "), " <<
|
||||
" m(" << (m?m->ne[0]:0) << "," << (m?m->ne[1]:0) << "," << (m?m->ne[2]:0) << "," << (m?m->ne[3]:0) << ")";
|
||||
timings[name.str()].push_back(time);
|
||||
return;
|
||||
return name.str();
|
||||
}
|
||||
if (node->op == GGML_OP_TOP_K) {
|
||||
std::stringstream name;
|
||||
|
|
@ -1662,11 +1659,38 @@ class vk_perf_logger {
|
|||
name << ggml_op_name(node->op) <<
|
||||
" K=" << node->ne[0] <<
|
||||
" (" << node->src[0]->ne[0] << "," << node->src[0]->ne[1] << "," << node->src[0]->ne[2] << "," << node->src[0]->ne[3] << ")";
|
||||
timings[name.str()].push_back(time);
|
||||
return;
|
||||
return name.str();
|
||||
}
|
||||
timings[fusion_str + ggml_op_name(node->op)].push_back(time);
|
||||
return fusion_str + ggml_op_name(node->op);
|
||||
}
|
||||
|
||||
void log_timing(const ggml_tensor * node, const char *fusion_name, uint64_t time) {
|
||||
uint64_t n_flops;
|
||||
std::string name = get_node_fusion_name(node, fusion_name, &n_flops);
|
||||
if (n_flops) {
|
||||
flops[name].push_back(n_flops);
|
||||
}
|
||||
timings[name].push_back(time);
|
||||
}
|
||||
|
||||
void log_timing(const std::vector<ggml_tensor *> &nodes, const std::vector<const char *> &names, uint64_t time) {
|
||||
uint64_t total_flops = 0;
|
||||
std::string name;
|
||||
for (size_t n = 0; n < nodes.size(); ++n) {
|
||||
uint64_t n_flops = 0;
|
||||
name += get_node_fusion_name(nodes[n], names[n], &n_flops);
|
||||
total_flops += n_flops;
|
||||
|
||||
if (n != nodes.size() - 1) {
|
||||
name += ", ";
|
||||
}
|
||||
}
|
||||
if (total_flops) {
|
||||
flops[name].push_back(total_flops);
|
||||
}
|
||||
timings[name].push_back(time);
|
||||
}
|
||||
|
||||
private:
|
||||
std::map<std::string, std::vector<uint64_t>> timings;
|
||||
std::map<std::string, std::vector<uint64_t>> flops;
|
||||
|
|
@ -1729,7 +1753,9 @@ struct ggml_backend_vk_context {
|
|||
std::unique_ptr<vk_perf_logger> perf_logger;
|
||||
vk::QueryPool query_pool;
|
||||
std::vector<const char *> query_fusion_names;
|
||||
std::vector<int> query_fusion_node_count;
|
||||
std::vector<ggml_tensor *> query_nodes;
|
||||
std::vector<int> query_node_idx;
|
||||
int32_t num_queries {};
|
||||
int32_t query_idx {};
|
||||
};
|
||||
|
|
@ -5194,6 +5220,8 @@ static void ggml_vk_instance_init() {
|
|||
}
|
||||
|
||||
vk_perf_logger_enabled = getenv("GGML_VK_PERF_LOGGER") != nullptr;
|
||||
vk_perf_logger_concurrent = getenv("GGML_VK_PERF_LOGGER_CONCURRENT") != nullptr;
|
||||
vk_enable_sync_logger = getenv("GGML_VK_SYNC_LOGGER") != nullptr;
|
||||
const char* GGML_VK_PERF_LOGGER_FREQUENCY = getenv("GGML_VK_PERF_LOGGER_FREQUENCY");
|
||||
|
||||
if (GGML_VK_PERF_LOGGER_FREQUENCY != nullptr) {
|
||||
|
|
@ -11820,15 +11848,18 @@ static bool ggml_vk_build_graph(ggml_backend_vk_context * ctx, ggml_cgraph * cgr
|
|||
}
|
||||
}
|
||||
|
||||
#define ENABLE_SYNC_LOGGING 0
|
||||
|
||||
if (need_sync) {
|
||||
#if ENABLE_SYNC_LOGGING
|
||||
std::cerr << "sync" << std::endl;
|
||||
#endif
|
||||
if (vk_enable_sync_logger) {
|
||||
std::cerr << "sync" << std::endl;
|
||||
}
|
||||
ctx->unsynced_nodes_written.clear();
|
||||
ctx->unsynced_nodes_read.clear();
|
||||
ggml_vk_sync_buffers(ctx, compute_ctx);
|
||||
|
||||
if (vk_perf_logger_enabled && vk_perf_logger_concurrent) {
|
||||
ctx->query_node_idx[ctx->query_idx] = node_idx;
|
||||
compute_ctx->s->buffer.writeTimestamp(vk::PipelineStageFlagBits::eAllCommands, ctx->query_pool, ctx->query_idx++);
|
||||
}
|
||||
}
|
||||
// Add all fused nodes to the unsynchronized lists.
|
||||
for (int32_t i = 0; i < ctx->num_additional_fused_ops + 1; ++i) {
|
||||
|
|
@ -11845,20 +11876,20 @@ static bool ggml_vk_build_graph(ggml_backend_vk_context * ctx, ggml_cgraph * cgr
|
|||
}
|
||||
}
|
||||
}
|
||||
#if ENABLE_SYNC_LOGGING
|
||||
for (int i = 0; i < ctx->num_additional_fused_ops + 1; ++i) {
|
||||
auto *n = cgraph->nodes[node_idx + i];
|
||||
std::cerr << node_idx + i << " " << ggml_op_name(n->op) << " " << n->name;
|
||||
if (n->op == GGML_OP_GLU) {
|
||||
std::cerr << " " << ggml_glu_op_name(ggml_get_glu_op(n)) << " " << (n->src[1] ? "split" : "single") << " ";
|
||||
if (vk_enable_sync_logger) {
|
||||
for (int i = 0; i < ctx->num_additional_fused_ops + 1; ++i) {
|
||||
auto *n = cgraph->nodes[node_idx + i];
|
||||
std::cerr << node_idx + i << " " << ggml_op_name(n->op) << " " << n->name;
|
||||
if (n->op == GGML_OP_GLU) {
|
||||
std::cerr << " " << ggml_glu_op_name(ggml_get_glu_op(n)) << " " << (n->src[1] ? "split" : "single") << " ";
|
||||
}
|
||||
if (n->op == GGML_OP_ROPE) {
|
||||
const int mode = ((const int32_t *) n->op_params)[2];
|
||||
std::cerr << " rope mode: " << mode;
|
||||
}
|
||||
std::cerr << std::endl;
|
||||
}
|
||||
if (n->op == GGML_OP_ROPE) {
|
||||
const int mode = ((const int32_t *) n->op_params)[2];
|
||||
std::cerr << " rope mode: " << mode;
|
||||
}
|
||||
std::cerr << std::endl;
|
||||
}
|
||||
#endif
|
||||
|
||||
switch (node->op) {
|
||||
case GGML_OP_REPEAT:
|
||||
|
|
@ -13138,12 +13169,16 @@ static ggml_status ggml_backend_vk_graph_compute(ggml_backend_t backend, ggml_cg
|
|||
ctx->query_pool = ctx->device->device.createQueryPool(query_create_info);
|
||||
ctx->num_queries = query_create_info.queryCount;
|
||||
ctx->query_fusion_names.resize(ctx->num_queries);
|
||||
ctx->query_fusion_node_count.resize(ctx->num_queries);
|
||||
ctx->query_nodes.resize(ctx->num_queries);
|
||||
ctx->query_node_idx.resize(ctx->num_queries);
|
||||
}
|
||||
|
||||
ctx->device->device.resetQueryPool(ctx->query_pool, 0, cgraph->n_nodes+1);
|
||||
std::fill(ctx->query_fusion_names.begin(), ctx->query_fusion_names.end(), nullptr);
|
||||
std::fill(ctx->query_fusion_node_count.begin(), ctx->query_fusion_node_count.end(), 0);
|
||||
std::fill(ctx->query_nodes.begin(), ctx->query_nodes.end(), nullptr);
|
||||
std::fill(ctx->query_node_idx.begin(), ctx->query_node_idx.end(), 0);
|
||||
|
||||
GGML_ASSERT(ctx->compute_ctx.expired());
|
||||
compute_ctx = ggml_vk_create_context(ctx, ctx->compute_cmd_pool);
|
||||
|
|
@ -13272,9 +13307,16 @@ static ggml_status ggml_backend_vk_graph_compute(ggml_backend_t backend, ggml_cg
|
|||
} else {
|
||||
compute_ctx = ctx->compute_ctx.lock();
|
||||
}
|
||||
ctx->query_nodes[ctx->query_idx] = cgraph->nodes[i];
|
||||
ctx->query_fusion_names[ctx->query_idx] = fusion_string;
|
||||
compute_ctx->s->buffer.writeTimestamp(vk::PipelineStageFlagBits::eAllCommands, ctx->query_pool, ctx->query_idx++);
|
||||
if (!vk_perf_logger_concurrent) {
|
||||
// track a single node/fusion for the current query
|
||||
ctx->query_nodes[ctx->query_idx] = cgraph->nodes[i];
|
||||
ctx->query_fusion_names[ctx->query_idx] = fusion_string;
|
||||
compute_ctx->s->buffer.writeTimestamp(vk::PipelineStageFlagBits::eAllCommands, ctx->query_pool, ctx->query_idx++);
|
||||
} else {
|
||||
// track a fusion string and number of fused ops for the current node_idx
|
||||
ctx->query_fusion_names[i] = fusion_string;
|
||||
ctx->query_fusion_node_count[i] = ctx->num_additional_fused_ops;
|
||||
}
|
||||
}
|
||||
|
||||
if (enqueued) {
|
||||
|
|
@ -13316,12 +13358,32 @@ static ggml_status ggml_backend_vk_graph_compute(ggml_backend_t backend, ggml_cg
|
|||
// Get the results and pass them to the logger
|
||||
std::vector<uint64_t> timestamps(cgraph->n_nodes + 1);
|
||||
VK_CHECK(ctx->device->device.getQueryPoolResults(ctx->query_pool, 0, ctx->query_idx, (cgraph->n_nodes + 1)*sizeof(uint64_t), timestamps.data(), sizeof(uint64_t), vk::QueryResultFlagBits::e64 | vk::QueryResultFlagBits::eWait), "get timestamp results");
|
||||
for (int i = 1; i < ctx->query_idx; i++) {
|
||||
auto node = ctx->query_nodes[i];
|
||||
auto name = ctx->query_fusion_names[i];
|
||||
ctx->perf_logger->log_timing(node, name, uint64_t((timestamps[i] - timestamps[i-1]) * ctx->device->properties.limits.timestampPeriod));
|
||||
if (!vk_perf_logger_concurrent) {
|
||||
// Log each op separately
|
||||
for (int i = 1; i < ctx->query_idx; i++) {
|
||||
auto node = ctx->query_nodes[i];
|
||||
auto name = ctx->query_fusion_names[i];
|
||||
ctx->perf_logger->log_timing(node, name, uint64_t((timestamps[i] - timestamps[i-1]) * ctx->device->properties.limits.timestampPeriod));
|
||||
}
|
||||
} else {
|
||||
// Log each group of nodes
|
||||
int prev_node_idx = 0;
|
||||
for (int i = 1; i < ctx->query_idx; i++) {
|
||||
auto cur_node_idx = ctx->query_node_idx[i];
|
||||
std::vector<ggml_tensor *> nodes;
|
||||
std::vector<const char *> names;
|
||||
for (int node_idx = prev_node_idx; node_idx < cur_node_idx; ++node_idx) {
|
||||
if (ggml_op_is_empty(cgraph->nodes[node_idx]->op)) {
|
||||
continue;
|
||||
}
|
||||
nodes.push_back(cgraph->nodes[node_idx]);
|
||||
names.push_back(ctx->query_fusion_names[node_idx]);
|
||||
node_idx += ctx->query_fusion_node_count[node_idx];
|
||||
}
|
||||
prev_node_idx = cur_node_idx;
|
||||
ctx->perf_logger->log_timing(nodes, names, uint64_t((timestamps[i] - timestamps[i-1]) * ctx->device->properties.limits.timestampPeriod));
|
||||
}
|
||||
}
|
||||
|
||||
ctx->perf_logger->print_timings();
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -690,6 +690,8 @@ class MODEL_TENSOR(IntEnum):
|
|||
V_TOK_EOI = auto() # cogvlm
|
||||
# audio (mtmd)
|
||||
A_ENC_EMBD_POS = auto()
|
||||
A_ENC_EMBD_NORM = auto()
|
||||
A_ENC_EMBD_TO_LOGITS = auto()
|
||||
A_ENC_CONV1D = auto()
|
||||
A_PRE_NORM = auto()
|
||||
A_POST_NORM = auto()
|
||||
|
|
@ -700,8 +702,13 @@ class MODEL_TENSOR(IntEnum):
|
|||
A_ENC_OUTPUT = auto()
|
||||
A_ENC_OUTPUT_NORM = auto()
|
||||
A_ENC_FFN_UP = auto()
|
||||
A_ENC_FFN_NORM = auto()
|
||||
A_ENC_FFN_GATE = auto()
|
||||
A_ENC_FFN_DOWN = auto()
|
||||
A_ENC_FFN_UP_1 = auto()
|
||||
A_ENC_FFN_NORM_1 = auto()
|
||||
A_ENC_FFN_GATE_1 = auto()
|
||||
A_ENC_FFN_DOWN_1 = auto()
|
||||
A_MMPROJ = auto()
|
||||
A_MMPROJ_FC = auto()
|
||||
A_MM_NORM_PRE = auto()
|
||||
|
|
@ -713,6 +720,16 @@ class MODEL_TENSOR(IntEnum):
|
|||
NEXTN_HNORM = auto()
|
||||
NEXTN_SHARED_HEAD_HEAD = auto()
|
||||
NEXTN_SHARED_HEAD_NORM = auto()
|
||||
# lfm2 audio
|
||||
A_ENC_NORM_CONV = auto()
|
||||
A_ENC_LINEAR_POS = auto()
|
||||
A_ENC_POS_BIAS_U = auto()
|
||||
A_ENC_POS_BIAS_V = auto()
|
||||
A_ENC_OUT = auto()
|
||||
A_ENC_CONV_DW = auto() # SSM conv
|
||||
A_ENC_CONV_NORM = auto() # SSM conv
|
||||
A_ENC_CONV_PW1 = auto()
|
||||
A_ENC_CONV_PW2 = auto()
|
||||
|
||||
|
||||
MODEL_ARCH_NAMES: dict[MODEL_ARCH, str] = {
|
||||
|
|
@ -1064,7 +1081,10 @@ TENSOR_NAMES: dict[MODEL_TENSOR, str] = {
|
|||
MODEL_TENSOR.V_TOK_BOI: "v.boi",
|
||||
MODEL_TENSOR.V_TOK_EOI: "v.eoi",
|
||||
# audio (mtmd)
|
||||
# note: all audio tensor names must use prefix "a." or "mm.a."
|
||||
MODEL_TENSOR.A_ENC_EMBD_POS: "a.position_embd",
|
||||
MODEL_TENSOR.A_ENC_EMBD_NORM: "a.position_embd_norm",
|
||||
MODEL_TENSOR.A_ENC_EMBD_TO_LOGITS: "a.embd_to_logits",
|
||||
MODEL_TENSOR.A_ENC_CONV1D: "a.conv1d.{bid}",
|
||||
MODEL_TENSOR.A_PRE_NORM: "a.pre_ln",
|
||||
MODEL_TENSOR.A_POST_NORM: "a.post_ln",
|
||||
|
|
@ -1074,13 +1094,28 @@ TENSOR_NAMES: dict[MODEL_TENSOR, str] = {
|
|||
MODEL_TENSOR.A_ENC_INPUT_NORM: "a.blk.{bid}.ln1",
|
||||
MODEL_TENSOR.A_ENC_OUTPUT: "a.blk.{bid}.attn_out",
|
||||
MODEL_TENSOR.A_ENC_OUTPUT_NORM: "a.blk.{bid}.ln2",
|
||||
MODEL_TENSOR.A_ENC_FFN_NORM: "a.blk.{bid}.ffn_norm",
|
||||
MODEL_TENSOR.A_ENC_FFN_UP: "a.blk.{bid}.ffn_up",
|
||||
MODEL_TENSOR.A_ENC_FFN_GATE: "a.blk.{bid}.ffn_gate",
|
||||
MODEL_TENSOR.A_ENC_FFN_DOWN: "a.blk.{bid}.ffn_down",
|
||||
MODEL_TENSOR.A_ENC_FFN_NORM_1: "a.blk.{bid}.ffn_norm_1",
|
||||
MODEL_TENSOR.A_ENC_FFN_UP_1: "a.blk.{bid}.ffn_up_1",
|
||||
MODEL_TENSOR.A_ENC_FFN_GATE_1: "a.blk.{bid}.ffn_gate_1",
|
||||
MODEL_TENSOR.A_ENC_FFN_DOWN_1: "a.blk.{bid}.ffn_down_1",
|
||||
MODEL_TENSOR.A_MMPROJ: "mm.a.mlp.{bid}",
|
||||
MODEL_TENSOR.A_MMPROJ_FC: "mm.a.fc",
|
||||
MODEL_TENSOR.A_MM_NORM_PRE: "mm.a.norm_pre",
|
||||
MODEL_TENSOR.A_MM_NORM_MID: "mm.a.norm_mid",
|
||||
# lfm2 audio
|
||||
MODEL_TENSOR.A_ENC_NORM_CONV: "a.blk.{bid}.norm_conv",
|
||||
MODEL_TENSOR.A_ENC_LINEAR_POS: "a.blk.{bid}.linear_pos",
|
||||
MODEL_TENSOR.A_ENC_POS_BIAS_U: "a.blk.{bid}.pos_bias_u",
|
||||
MODEL_TENSOR.A_ENC_POS_BIAS_V: "a.blk.{bid}.pos_bias_v",
|
||||
MODEL_TENSOR.A_ENC_OUT: "a.pre_encode.out",
|
||||
MODEL_TENSOR.A_ENC_CONV_DW: "a.blk.{bid}.conv_dw",
|
||||
MODEL_TENSOR.A_ENC_CONV_NORM: "a.blk.{bid}.conv_norm",
|
||||
MODEL_TENSOR.A_ENC_CONV_PW1: "a.blk.{bid}.conv_pw1",
|
||||
MODEL_TENSOR.A_ENC_CONV_PW2: "a.blk.{bid}.conv_pw2",
|
||||
# NextN/MTP
|
||||
MODEL_TENSOR.NEXTN_EH_PROJ: "blk.{bid}.nextn.eh_proj",
|
||||
MODEL_TENSOR.NEXTN_EMBED_TOKENS: "blk.{bid}.nextn.embed_tokens",
|
||||
|
|
@ -1145,6 +1180,8 @@ MODEL_TENSORS: dict[MODEL_ARCH, list[MODEL_TENSOR]] = {
|
|||
MODEL_TENSOR.V_TOK_EOI,
|
||||
# audio
|
||||
MODEL_TENSOR.A_ENC_EMBD_POS,
|
||||
MODEL_TENSOR.A_ENC_EMBD_NORM,
|
||||
MODEL_TENSOR.A_ENC_EMBD_TO_LOGITS,
|
||||
MODEL_TENSOR.A_ENC_CONV1D,
|
||||
MODEL_TENSOR.A_PRE_NORM,
|
||||
MODEL_TENSOR.A_POST_NORM,
|
||||
|
|
@ -1154,13 +1191,27 @@ MODEL_TENSORS: dict[MODEL_ARCH, list[MODEL_TENSOR]] = {
|
|||
MODEL_TENSOR.A_ENC_INPUT_NORM,
|
||||
MODEL_TENSOR.A_ENC_OUTPUT,
|
||||
MODEL_TENSOR.A_ENC_OUTPUT_NORM,
|
||||
MODEL_TENSOR.A_ENC_FFN_NORM,
|
||||
MODEL_TENSOR.A_ENC_FFN_UP,
|
||||
MODEL_TENSOR.A_ENC_FFN_GATE,
|
||||
MODEL_TENSOR.A_ENC_FFN_DOWN,
|
||||
MODEL_TENSOR.A_ENC_FFN_NORM_1,
|
||||
MODEL_TENSOR.A_ENC_FFN_UP_1,
|
||||
MODEL_TENSOR.A_ENC_FFN_GATE_1,
|
||||
MODEL_TENSOR.A_ENC_FFN_DOWN_1,
|
||||
MODEL_TENSOR.A_MMPROJ,
|
||||
MODEL_TENSOR.A_MMPROJ_FC,
|
||||
MODEL_TENSOR.A_MM_NORM_PRE,
|
||||
MODEL_TENSOR.A_MM_NORM_MID,
|
||||
MODEL_TENSOR.A_ENC_NORM_CONV,
|
||||
MODEL_TENSOR.A_ENC_LINEAR_POS,
|
||||
MODEL_TENSOR.A_ENC_POS_BIAS_U,
|
||||
MODEL_TENSOR.A_ENC_POS_BIAS_V,
|
||||
MODEL_TENSOR.A_ENC_OUT,
|
||||
MODEL_TENSOR.A_ENC_CONV_DW,
|
||||
MODEL_TENSOR.A_ENC_CONV_NORM,
|
||||
MODEL_TENSOR.A_ENC_CONV_PW1,
|
||||
MODEL_TENSOR.A_ENC_CONV_PW2,
|
||||
],
|
||||
MODEL_ARCH.LLAMA: [
|
||||
MODEL_TENSOR.TOKEN_EMBD,
|
||||
|
|
@ -3363,6 +3414,7 @@ class VisionProjectorType:
|
|||
LIGHTONOCR = "lightonocr"
|
||||
COGVLM = "cogvlm"
|
||||
JANUS_PRO = "janus_pro"
|
||||
LFM2A = "lfm2a" # audio
|
||||
GLM4V = "glm4v"
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -1535,10 +1535,20 @@ class TensorNameMap:
|
|||
|
||||
MODEL_TENSOR.A_ENC_EMBD_POS: (
|
||||
"audio_tower.embed_positions", # ultravox
|
||||
"audio_embedding.embedding", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_EMBD_NORM: (
|
||||
"audio_embedding.embedding_norm", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_EMBD_TO_LOGITS: (
|
||||
"audio_embedding.to_logits", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_CONV1D: (
|
||||
"audio_tower.conv{bid}", # ultravox
|
||||
"conformer.pre_encode.conv.{bid}", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_PRE_NORM: (),
|
||||
|
|
@ -1550,36 +1560,76 @@ class TensorNameMap:
|
|||
|
||||
MODEL_TENSOR.A_ENC_ATTN_Q: (
|
||||
"audio_tower.layers.{bid}.self_attn.q_proj", # ultravox
|
||||
"conformer.layers.{bid}.self_attn.linear_q", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_ATTN_K: (
|
||||
"audio_tower.layers.{bid}.self_attn.k_proj", # ultravox
|
||||
"conformer.layers.{bid}.self_attn.linear_k", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_ATTN_V: (
|
||||
"audio_tower.layers.{bid}.self_attn.v_proj", # ultravox
|
||||
"conformer.layers.{bid}.self_attn.linear_v", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_INPUT_NORM: (
|
||||
"audio_tower.layers.{bid}.self_attn_layer_norm", # ultravox
|
||||
"conformer.layers.{bid}.norm_self_att", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_OUTPUT: (
|
||||
"audio_tower.layers.{bid}.self_attn.out_proj", # ultravox
|
||||
"conformer.layers.{bid}.self_attn.linear_out", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_OUTPUT_NORM: (
|
||||
"audio_tower.layers.{bid}.final_layer_norm", # ultravox
|
||||
"conformer.layers.{bid}.norm_out", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_FFN_NORM: (
|
||||
"conformer.layers.{bid}.norm_feed_forward1", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_FFN_UP: (
|
||||
"audio_tower.layers.{bid}.fc1", # ultravox
|
||||
"conformer.layers.{bid}.feed_forward1.linear1", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_FFN_GATE: (),
|
||||
|
||||
MODEL_TENSOR.A_ENC_FFN_DOWN: (
|
||||
"audio_tower.layers.{bid}.fc2", # ultravox
|
||||
"conformer.layers.{bid}.feed_forward1.linear2", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_FFN_UP_1: (
|
||||
"conformer.layers.{bid}.feed_forward2.linear1", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_FFN_DOWN_1: (
|
||||
"conformer.layers.{bid}.feed_forward2.linear2", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_FFN_NORM_1: (
|
||||
"conformer.layers.{bid}.norm_feed_forward2", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_LINEAR_POS: (
|
||||
"conformer.layers.{bid}.self_attn.linear_pos", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_POS_BIAS_U: (
|
||||
"conformer.layers.{bid}.self_attn.pos_bias_u", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_POS_BIAS_V: (
|
||||
"conformer.layers.{bid}.self_attn.pos_bias_v", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_OUT: (
|
||||
"conformer.pre_encode.out", # lfm2
|
||||
),
|
||||
|
||||
# note: some tensors below has "audio." pseudo-prefix, to prevent conflicts with vision tensors
|
||||
|
|
@ -1587,6 +1637,7 @@ class TensorNameMap:
|
|||
|
||||
MODEL_TENSOR.A_MMPROJ: (
|
||||
"audio.multi_modal_projector.linear_{bid}", # ultravox
|
||||
"audio_adapter.model.{bid}" # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_MMPROJ_FC: (
|
||||
|
|
@ -1602,6 +1653,26 @@ class TensorNameMap:
|
|||
"audio.multi_modal_projector.ln_mid", # ultravox
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_CONV_DW: (
|
||||
"conformer.layers.{bid}.conv.depthwise_conv", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_CONV_NORM: (
|
||||
"conformer.layers.{bid}.conv.batch_norm", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_CONV_PW1: (
|
||||
"conformer.layers.{bid}.conv.pointwise_conv1", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_CONV_PW2: (
|
||||
"conformer.layers.{bid}.conv.pointwise_conv2", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_NORM_CONV: (
|
||||
"conformer.layers.{bid}.norm_conv", # lfm2
|
||||
),
|
||||
|
||||
# NextN/MTP tensors for GLM4_MOE
|
||||
MODEL_TENSOR.NEXTN_EH_PROJ: (
|
||||
"model.layers.{bid}.eh_proj",
|
||||
|
|
|
|||
|
|
@ -1086,10 +1086,10 @@ bool llama_model_loader::load_all_data(
|
|||
} else {
|
||||
// If upload_backend is valid load the tensor in chunks to pinned memory and upload the buffers asynchronously to the GPU.
|
||||
if (upload_backend) {
|
||||
auto offset = (off_t) weight->offs;
|
||||
size_t offset = weight->offs;
|
||||
alignment = file->read_alignment();
|
||||
off_t aligned_offset = offset & ~(alignment - 1);
|
||||
off_t offset_from_alignment = offset - aligned_offset;
|
||||
size_t aligned_offset = offset & ~(alignment - 1);
|
||||
size_t offset_from_alignment = offset - aligned_offset;
|
||||
file->seek(aligned_offset, SEEK_SET);
|
||||
|
||||
// Calculate aligned read boundaries
|
||||
|
|
|
|||
|
|
@ -37,6 +37,30 @@ int main(void) {
|
|||
exit(1);
|
||||
}
|
||||
}
|
||||
|
||||
// ensure shorter argument precedes longer argument
|
||||
if (opt.args.size() > 1) {
|
||||
const std::string first(opt.args.front());
|
||||
const std::string last(opt.args.back());
|
||||
|
||||
if (first.length() > last.length()) {
|
||||
fprintf(stderr, "test-arg-parser: shorter argument should come before longer one: %s, %s\n",
|
||||
first.c_str(), last.c_str());
|
||||
assert(false);
|
||||
}
|
||||
}
|
||||
|
||||
// same check for negated arguments
|
||||
if (opt.args_neg.size() > 1) {
|
||||
const std::string first(opt.args_neg.front());
|
||||
const std::string last(opt.args_neg.back());
|
||||
|
||||
if (first.length() > last.length()) {
|
||||
fprintf(stderr, "test-arg-parser: shorter negated argument should come before longer one: %s, %s\n",
|
||||
first.c_str(), last.c_str());
|
||||
assert(false);
|
||||
}
|
||||
}
|
||||
}
|
||||
} catch (std::exception & e) {
|
||||
printf("%s\n", e.what());
|
||||
|
|
|
|||
|
|
@ -7295,11 +7295,11 @@ static std::vector<std::unique_ptr<test_case>> make_test_cases_eval() {
|
|||
|
||||
test_cases.emplace_back(new test_l2_norm(GGML_TYPE_F32, {64, 5, 4, 3}, 1e-12f));
|
||||
|
||||
for (int64_t d_conv : {3, 4}) {
|
||||
for (int64_t d_conv : {3, 4, 9}) {
|
||||
for (int64_t d_inner: {1024, 1536, 2048}) {
|
||||
test_cases.emplace_back(new test_ssm_conv(GGML_TYPE_F32, {4, d_inner, 1, 1}, {d_conv, d_inner, 1, 1}));
|
||||
test_cases.emplace_back(new test_ssm_conv(GGML_TYPE_F32, {8, d_inner, 1, 1}, {d_conv, d_inner, 1, 1}));
|
||||
test_cases.emplace_back(new test_ssm_conv(GGML_TYPE_F32, {4, d_inner, 4, 1}, {d_conv, d_inner, 1, 1}));
|
||||
test_cases.emplace_back(new test_ssm_conv(GGML_TYPE_F32, {d_conv, d_inner, 1, 1}, {d_conv, d_inner, 1, 1}));
|
||||
test_cases.emplace_back(new test_ssm_conv(GGML_TYPE_F32, {2 * d_conv, d_inner, 1, 1}, {d_conv, d_inner, 1, 1}));
|
||||
test_cases.emplace_back(new test_ssm_conv(GGML_TYPE_F32, {d_conv, d_inner, 4, 1}, {d_conv, d_inner, 1, 1}));
|
||||
}
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -15,6 +15,7 @@ add_library(mtmd
|
|||
clip-graph.h
|
||||
models/models.h
|
||||
models/cogvlm.cpp
|
||||
models/conformer.cpp
|
||||
models/glm4v.cpp
|
||||
models/internvl.cpp
|
||||
models/kimivl.cpp
|
||||
|
|
|
|||
|
|
@ -138,6 +138,21 @@
|
|||
#define TN_TOK_BOI "v.boi"
|
||||
#define TN_TOK_EOI "v.eoi"
|
||||
|
||||
// (conformer) lfm2
|
||||
#define TN_PRE_ENCODE_OUT "a.pre_encode.out.%s"
|
||||
#define TN_FFN_NORM "%s.blk.%d.ffn_norm.%s"
|
||||
#define TN_FFN_NORM_1 "%s.blk.%d.ffn_norm_1.%s"
|
||||
#define TN_FFN_UP_1 "%s.blk.%d.ffn_up_1.%s"
|
||||
#define TN_FFN_DOWN_1 "%s.blk.%d.ffn_down_1.%s"
|
||||
#define TN_POS_BIAS_U "%s.blk.%d.pos_bias_u"
|
||||
#define TN_POS_BIAS_V "%s.blk.%d.pos_bias_v"
|
||||
#define TN_NORM_CONV "%s.blk.%d.norm_conv.%s"
|
||||
#define TN_LINEAR_POS "%s.blk.%d.linear_pos.%s"
|
||||
#define TN_CONV_DW "%s.blk.%d.conv_dw.%s"
|
||||
#define TN_CONV_NORM "%s.blk.%d.conv_norm.%s"
|
||||
#define TN_CONV_PW1 "%s.blk.%d.conv_pw1.%s"
|
||||
#define TN_CONV_PW2 "%s.blk.%d.conv_pw2.%s"
|
||||
|
||||
// align x to upper multiple of n
|
||||
#define CLIP_ALIGN(x, n) ((((x) + (n) - 1) / (n)) * (n))
|
||||
|
||||
|
|
@ -170,6 +185,7 @@ enum projector_type {
|
|||
PROJECTOR_TYPE_LIGHTONOCR,
|
||||
PROJECTOR_TYPE_COGVLM,
|
||||
PROJECTOR_TYPE_JANUS_PRO,
|
||||
PROJECTOR_TYPE_LFM2A,
|
||||
PROJECTOR_TYPE_GLM4V,
|
||||
PROJECTOR_TYPE_UNKNOWN,
|
||||
};
|
||||
|
|
@ -198,6 +214,7 @@ static std::map<projector_type, std::string> PROJECTOR_TYPE_NAMES = {
|
|||
{ PROJECTOR_TYPE_LIGHTONOCR,"lightonocr"},
|
||||
{ PROJECTOR_TYPE_COGVLM, "cogvlm"},
|
||||
{ PROJECTOR_TYPE_JANUS_PRO, "janus_pro"},
|
||||
{ PROJECTOR_TYPE_LFM2A, "lfm2a"},
|
||||
{ PROJECTOR_TYPE_GLM4V, "glm4v"},
|
||||
};
|
||||
|
||||
|
|
|
|||
|
|
@ -4,6 +4,7 @@
|
|||
#include "clip.h"
|
||||
#include "clip-impl.h"
|
||||
|
||||
#include <array>
|
||||
#include <vector>
|
||||
#include <unordered_set>
|
||||
#include <cstdint>
|
||||
|
|
@ -142,6 +143,30 @@ struct clip_layer {
|
|||
ggml_tensor * deepstack_fc2_w = nullptr;
|
||||
ggml_tensor * deepstack_fc2_b = nullptr;
|
||||
|
||||
// lfm2
|
||||
ggml_tensor * ff_norm_w = nullptr;
|
||||
ggml_tensor * ff_norm_b = nullptr;
|
||||
ggml_tensor * ff_norm_1_w = nullptr;
|
||||
ggml_tensor * ff_norm_1_b = nullptr;
|
||||
ggml_tensor * ff_up_1_w = nullptr;
|
||||
ggml_tensor * ff_up_1_b = nullptr;
|
||||
ggml_tensor * ff_down_1_w = nullptr;
|
||||
ggml_tensor * ff_down_1_b = nullptr;
|
||||
ggml_tensor * pos_bias_u = nullptr;
|
||||
ggml_tensor * pos_bias_v = nullptr;
|
||||
ggml_tensor * norm_conv_w = nullptr;
|
||||
ggml_tensor * norm_conv_b = nullptr;
|
||||
ggml_tensor * linear_pos_w = nullptr;
|
||||
|
||||
ggml_tensor * conv_norm_w = nullptr;
|
||||
ggml_tensor * conv_norm_b = nullptr;
|
||||
ggml_tensor * conv_dw_w = nullptr;
|
||||
ggml_tensor * conv_dw_b = nullptr;
|
||||
ggml_tensor * conv_pw1_w = nullptr;
|
||||
ggml_tensor * conv_pw1_b = nullptr;
|
||||
ggml_tensor * conv_pw2_w = nullptr;
|
||||
ggml_tensor * conv_pw2_b = nullptr;
|
||||
|
||||
bool has_deepstack() const {
|
||||
return deepstack_fc1_w != nullptr;
|
||||
}
|
||||
|
|
@ -286,6 +311,12 @@ struct clip_model {
|
|||
ggml_tensor * mm_boi = nullptr;
|
||||
ggml_tensor * mm_eoi = nullptr;
|
||||
|
||||
// lfm2 audio
|
||||
std::array<ggml_tensor *, 7> pre_encode_conv_X_w = {nullptr};
|
||||
std::array<ggml_tensor *, 7> pre_encode_conv_X_b = {nullptr};
|
||||
ggml_tensor * pre_encode_out_w = nullptr;
|
||||
ggml_tensor * pre_encode_out_b = nullptr;
|
||||
|
||||
bool audio_has_avgpool() const {
|
||||
return proj_type == PROJECTOR_TYPE_QWEN2A
|
||||
|| proj_type == PROJECTOR_TYPE_VOXTRAL;
|
||||
|
|
|
|||
|
|
@ -837,6 +837,10 @@ static ggml_cgraph * clip_image_build_graph(clip_ctx * ctx, const clip_image_f32
|
|||
{
|
||||
builder = std::make_unique<clip_graph_llava>(ctx, img);
|
||||
} break;
|
||||
case PROJECTOR_TYPE_LFM2A:
|
||||
{
|
||||
builder = std::make_unique<clip_graph_conformer>(ctx, img);
|
||||
} break;
|
||||
case PROJECTOR_TYPE_GLM4V:
|
||||
{
|
||||
builder = std::make_unique<clip_graph_glm4v>(ctx, img);
|
||||
|
|
@ -1187,6 +1191,15 @@ struct clip_model_loader {
|
|||
hparams.audio_window_len = 400;
|
||||
hparams.audio_hop_len = 160;
|
||||
} break;
|
||||
case PROJECTOR_TYPE_LFM2A:
|
||||
{
|
||||
// audio preprocessing params
|
||||
hparams.audio_chunk_len = 1; // in seconds
|
||||
hparams.audio_sample_rate = 16000;
|
||||
hparams.audio_n_fft = 512;
|
||||
hparams.audio_window_len = 400;
|
||||
hparams.audio_hop_len = 160;
|
||||
} break;
|
||||
default:
|
||||
break;
|
||||
}
|
||||
|
|
@ -1611,6 +1624,52 @@ struct clip_model_loader {
|
|||
model.mm_1_w = get_tensor(string_format(TN_LLAVA_PROJ, 1, "weight"));
|
||||
model.mm_1_b = get_tensor(string_format(TN_LLAVA_PROJ, 1, "bias"));
|
||||
} break;
|
||||
case PROJECTOR_TYPE_LFM2A:
|
||||
{
|
||||
for (int i : {0, 2, 3, 5, 6}) {
|
||||
model.pre_encode_conv_X_w[i] = get_tensor(string_format(TN_CONV1D, i, "weight"));
|
||||
model.pre_encode_conv_X_b[i] = get_tensor(string_format(TN_CONV1D, i, "bias"));
|
||||
}
|
||||
model.pre_encode_out_w = get_tensor(string_format(TN_PRE_ENCODE_OUT, "weight"));
|
||||
model.pre_encode_out_b = get_tensor(string_format(TN_PRE_ENCODE_OUT, "bias"));
|
||||
|
||||
model.mm_0_w = get_tensor(string_format(TN_MM_AUDIO_MLP, 0, "weight"));
|
||||
model.mm_0_b = get_tensor(string_format(TN_MM_AUDIO_MLP, 0, "bias"));
|
||||
model.mm_1_w = get_tensor(string_format(TN_MM_AUDIO_MLP, 1, "weight"));
|
||||
model.mm_1_b = get_tensor(string_format(TN_MM_AUDIO_MLP, 1, "bias"));
|
||||
model.mm_3_w = get_tensor(string_format(TN_MM_AUDIO_MLP, 3, "weight"));
|
||||
model.mm_3_b = get_tensor(string_format(TN_MM_AUDIO_MLP, 3, "bias"));
|
||||
|
||||
for (int il = 0; il < hparams.n_layer; ++il) {
|
||||
auto & layer = model.layers[il];
|
||||
|
||||
layer.ff_norm_w = get_tensor(string_format(TN_FFN_NORM, prefix, il, "weight"));
|
||||
layer.ff_norm_b = get_tensor(string_format(TN_FFN_NORM, prefix, il, "bias"));
|
||||
layer.ff_norm_1_w = get_tensor(string_format(TN_FFN_NORM_1, prefix, il, "weight"));
|
||||
layer.ff_norm_1_b = get_tensor(string_format(TN_FFN_NORM_1, prefix, il, "bias"));
|
||||
layer.ff_up_1_w = get_tensor(string_format(TN_FFN_UP_1, prefix, il, "weight"));
|
||||
layer.ff_up_1_b = get_tensor(string_format(TN_FFN_UP_1, prefix, il, "bias"));
|
||||
layer.ff_down_1_w = get_tensor(string_format(TN_FFN_DOWN_1, prefix, il, "weight"));
|
||||
layer.ff_down_1_b = get_tensor(string_format(TN_FFN_DOWN_1, prefix, il, "bias"));
|
||||
|
||||
layer.pos_bias_u = get_tensor(string_format(TN_POS_BIAS_U, prefix, il));
|
||||
layer.pos_bias_v = get_tensor(string_format(TN_POS_BIAS_V, prefix, il));
|
||||
|
||||
layer.norm_conv_w = get_tensor(string_format(TN_NORM_CONV, prefix, il, "weight"));
|
||||
layer.norm_conv_b = get_tensor(string_format(TN_NORM_CONV, prefix, il, "bias"));
|
||||
|
||||
layer.linear_pos_w = get_tensor(string_format(TN_LINEAR_POS, prefix, il, "weight"));
|
||||
|
||||
layer.conv_norm_w = get_tensor(string_format(TN_CONV_NORM, prefix, il, "weight"));
|
||||
layer.conv_norm_b = get_tensor(string_format(TN_CONV_NORM, prefix, il, "bias"));
|
||||
layer.conv_dw_w = get_tensor(string_format(TN_CONV_DW, prefix, il, "weight"));
|
||||
layer.conv_dw_b = get_tensor(string_format(TN_CONV_DW, prefix, il, "bias"));
|
||||
layer.conv_pw1_w = get_tensor(string_format(TN_CONV_PW1, prefix, il, "weight"));
|
||||
layer.conv_pw1_b = get_tensor(string_format(TN_CONV_PW1, prefix, il, "bias"));
|
||||
layer.conv_pw2_w = get_tensor(string_format(TN_CONV_PW2, prefix, il, "weight"));
|
||||
layer.conv_pw2_b = get_tensor(string_format(TN_CONV_PW2, prefix, il, "bias"));
|
||||
}
|
||||
} break;
|
||||
default:
|
||||
GGML_ASSERT(false && "unknown projector type");
|
||||
}
|
||||
|
|
@ -3004,6 +3063,10 @@ int clip_n_output_tokens(const struct clip_ctx * ctx, struct clip_image_f32 * im
|
|||
{
|
||||
n_patches += 2; // for BOI and EOI token embeddings
|
||||
} break;
|
||||
case PROJECTOR_TYPE_LFM2A:
|
||||
{
|
||||
n_patches = ((((img->nx + 1) / 2) + 1) / 2 + 1) / 2;
|
||||
} break;
|
||||
default:
|
||||
GGML_ABORT("unsupported projector type");
|
||||
}
|
||||
|
|
@ -3362,6 +3425,27 @@ bool clip_image_batch_encode(clip_ctx * ctx, const int n_threads, const clip_ima
|
|||
}
|
||||
set_input_i32("pos_w", pos_data);
|
||||
} break;
|
||||
case PROJECTOR_TYPE_LFM2A:
|
||||
{
|
||||
GGML_ASSERT(imgs.entries.size() == 1);
|
||||
const auto n_frames = clip_n_output_tokens(ctx, imgs.entries.front().get());
|
||||
|
||||
auto d_model = 512;
|
||||
auto seq_len = n_frames * 2 - 1;
|
||||
std::vector<float> pos_emb(d_model*seq_len);
|
||||
std::vector<double> inv_freq(d_model / 2);
|
||||
for (size_t i = 0; i < inv_freq.size(); ++i) {
|
||||
inv_freq[i] = std::exp(-(std::log(10000.0) / (float)d_model) * (2.0f * (float)(i)));
|
||||
}
|
||||
for (int64_t pos = 0; pos < seq_len; ++pos) {
|
||||
for (size_t i = 0; i < inv_freq.size(); ++i) {
|
||||
const float ang = (n_frames - pos - 1) * inv_freq[i];
|
||||
pos_emb[pos*d_model + 2*i + 0] = sinf(ang); // even
|
||||
pos_emb[pos*d_model + 2*i + 1] = cosf(ang); // odd
|
||||
}
|
||||
}
|
||||
set_input_f32("pos_emb", pos_emb);
|
||||
} break;
|
||||
default:
|
||||
GGML_ABORT("Unknown projector type");
|
||||
}
|
||||
|
|
@ -3456,6 +3540,8 @@ int clip_n_mmproj_embd(const struct clip_ctx * ctx) {
|
|||
return ctx->model.mm_2_w->ne[1];
|
||||
case PROJECTOR_TYPE_COGVLM:
|
||||
return ctx->model.mm_4h_to_h_w->ne[1];
|
||||
case PROJECTOR_TYPE_LFM2A:
|
||||
return ctx->model.position_embeddings->ne[0];
|
||||
case PROJECTOR_TYPE_GLM4V:
|
||||
return ctx->model.mm_ffn_down_w->ne[1];
|
||||
default:
|
||||
|
|
|
|||
|
|
@ -0,0 +1,217 @@
|
|||
#include "models.h"
|
||||
|
||||
ggml_cgraph * clip_graph_conformer::build() {
|
||||
const int n_frames = img.nx;
|
||||
const int n_pos = n_frames / 2;
|
||||
const int n_pos_embd = (((((n_frames + 1) / 2) + 1) / 2 + 1) / 2) * 2 - 1;
|
||||
GGML_ASSERT(model.position_embeddings->ne[1] >= n_pos);
|
||||
|
||||
ggml_tensor * pos_emb = ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, 512, n_pos_embd);
|
||||
ggml_set_name(pos_emb, "pos_emb");
|
||||
ggml_set_input(pos_emb);
|
||||
ggml_build_forward_expand(gf, pos_emb);
|
||||
|
||||
ggml_tensor * inp = build_inp_raw(1);
|
||||
cb(inp, "input", -1);
|
||||
|
||||
auto * cur = ggml_cont(ctx0, ggml_transpose(ctx0, inp));
|
||||
|
||||
// pre encode, conv subsampling
|
||||
{
|
||||
// layer.0 - conv2d
|
||||
cur = ggml_conv_2d(ctx0, model.pre_encode_conv_X_w[0], cur, 2, 2, 1, 1, 1, 1);
|
||||
cur = ggml_add(ctx0, cur, model.pre_encode_conv_X_b[0]);
|
||||
cb(cur, "conformer.pre_encode.conv.{}", 0);
|
||||
|
||||
// layer.1 - relu
|
||||
cur = ggml_relu_inplace(ctx0, cur);
|
||||
|
||||
// layer.2 conv2d dw
|
||||
cur = ggml_conv_2d_dw_direct(ctx0, model.pre_encode_conv_X_w[2], cur, 2, 2, 1, 1, 1, 1);
|
||||
cur = ggml_add(ctx0, cur, model.pre_encode_conv_X_b[2]);
|
||||
cb(cur, "conformer.pre_encode.conv.{}", 2);
|
||||
|
||||
// layer.3 conv2d
|
||||
cur = ggml_conv_2d_direct(ctx0, model.pre_encode_conv_X_w[3], cur, 1, 1, 0, 0, 1, 1);
|
||||
cur = ggml_add(ctx0, cur, model.pre_encode_conv_X_b[3]);
|
||||
cb(cur, "conformer.pre_encode.conv.{}", 3);
|
||||
|
||||
// layer.4 - relu
|
||||
cur = ggml_relu_inplace(ctx0, cur);
|
||||
|
||||
// layer.5 conv2d dw
|
||||
cur = ggml_conv_2d_dw_direct(ctx0, model.pre_encode_conv_X_w[5], cur, 2, 2, 1, 1, 1, 1);
|
||||
cur = ggml_add(ctx0, cur, model.pre_encode_conv_X_b[5]);
|
||||
cb(cur, "conformer.pre_encode.conv.{}", 5);
|
||||
|
||||
// layer.6 conv2d
|
||||
cur = ggml_conv_2d_direct(ctx0, model.pre_encode_conv_X_w[6], cur, 1, 1, 0, 0, 1, 1);
|
||||
cur = ggml_add(ctx0, cur, model.pre_encode_conv_X_b[6]);
|
||||
cb(cur, "conformer.pre_encode.conv.{}", 6);
|
||||
|
||||
// layer.7 - relu
|
||||
cur = ggml_relu_inplace(ctx0, cur);
|
||||
|
||||
// flatten channel and frequency axis
|
||||
cur = ggml_cont(ctx0, ggml_permute(ctx0, cur, 0, 2, 1, 3));
|
||||
cur = ggml_reshape_2d(ctx0, cur, cur->ne[0] * cur->ne[1], cur->ne[2]);
|
||||
|
||||
// calculate out
|
||||
cur = ggml_mul_mat(ctx0, model.pre_encode_out_w, cur);
|
||||
cur = ggml_add(ctx0, cur, model.pre_encode_out_b);
|
||||
cb(cur, "conformer.pre_encode.out", -1);
|
||||
}
|
||||
|
||||
// pos_emb
|
||||
cb(pos_emb, "pos_emb", -1);
|
||||
|
||||
for (int il = 0; il < hparams.n_layer; il++) {
|
||||
const auto & layer = model.layers[il];
|
||||
|
||||
auto * residual = cur;
|
||||
|
||||
cb(cur, "layer.in", il);
|
||||
|
||||
// feed_forward1
|
||||
cur = build_norm(cur, layer.ff_norm_w, layer.ff_norm_b, NORM_TYPE_NORMAL, 1e-5, il);
|
||||
cb(cur, "conformer.layers.{}.norm_feed_forward1", il);
|
||||
|
||||
cur = build_ffn(cur, layer.ff_up_w, layer.ff_up_b, nullptr, nullptr, layer.ff_down_w, layer.ff_down_b, FFN_SILU,
|
||||
il);
|
||||
cb(cur, "conformer.layers.{}.feed_forward1.linear2", il);
|
||||
|
||||
const auto fc_factor = 0.5f;
|
||||
residual = ggml_add(ctx0, residual, ggml_scale(ctx0, cur, fc_factor));
|
||||
|
||||
// self-attention
|
||||
{
|
||||
cur = build_norm(residual, layer.ln_1_w, layer.ln_1_b, NORM_TYPE_NORMAL, 1e-5, il);
|
||||
cb(cur, "conformer.layers.{}.norm_self_att", il);
|
||||
|
||||
ggml_tensor * Qcur = ggml_mul_mat(ctx0, layer.q_w, cur);
|
||||
Qcur = ggml_add(ctx0, Qcur, layer.q_b);
|
||||
Qcur = ggml_reshape_3d(ctx0, Qcur, d_head, n_head, Qcur->ne[1]);
|
||||
ggml_tensor * Q_bias_u = ggml_add(ctx0, Qcur, layer.pos_bias_u);
|
||||
Q_bias_u = ggml_permute(ctx0, Q_bias_u, 0, 2, 1, 3);
|
||||
ggml_tensor * Q_bias_v = ggml_add(ctx0, Qcur, layer.pos_bias_v);
|
||||
Q_bias_v = ggml_permute(ctx0, Q_bias_v, 0, 2, 1, 3);
|
||||
|
||||
// TODO @ngxson : some cont can/should be removed when ggml_mul_mat support these cases
|
||||
ggml_tensor * Kcur = ggml_mul_mat(ctx0, layer.k_w, cur);
|
||||
Kcur = ggml_add(ctx0, Kcur, layer.k_b);
|
||||
Kcur = ggml_reshape_3d(ctx0, Kcur, d_head, n_head, Kcur->ne[1]);
|
||||
Kcur = ggml_cont(ctx0, ggml_permute(ctx0, Kcur, 0, 2, 1, 3));
|
||||
|
||||
ggml_tensor * Vcur = ggml_mul_mat(ctx0, layer.v_w, cur);
|
||||
Vcur = ggml_add(ctx0, Vcur, layer.v_b);
|
||||
Vcur = ggml_reshape_3d(ctx0, Vcur, d_head, n_head, Vcur->ne[1]);
|
||||
Vcur = ggml_cont(ctx0, ggml_permute(ctx0, Vcur, 1, 2, 0, 3));
|
||||
|
||||
// build_attn won't fit due to matrix_ac and matrix_bd separation
|
||||
ggml_tensor * matrix_ac = ggml_mul_mat(ctx0, Q_bias_u, Kcur);
|
||||
matrix_ac = ggml_cont(ctx0, ggml_permute(ctx0, matrix_ac, 1, 0, 2, 3));
|
||||
cb(matrix_ac, "conformer.layers.{}.self_attn.id3", il);
|
||||
|
||||
auto * p = ggml_mul_mat(ctx0, layer.linear_pos_w, pos_emb);
|
||||
cb(p, "conformer.layers.{}.self_attn.linear_pos", il);
|
||||
p = ggml_reshape_3d(ctx0, p, d_head, n_head, p->ne[1]);
|
||||
p = ggml_permute(ctx0, p, 0, 2, 1, 3);
|
||||
|
||||
auto * matrix_bd = ggml_mul_mat(ctx0, Q_bias_v, p);
|
||||
matrix_bd = ggml_cont(ctx0, ggml_permute(ctx0, matrix_bd, 1, 0, 2, 3));
|
||||
|
||||
// rel shift
|
||||
{
|
||||
const auto pos_len = matrix_bd->ne[0];
|
||||
const auto q_len = matrix_bd->ne[1];
|
||||
const auto h = matrix_bd->ne[2];
|
||||
matrix_bd = ggml_pad(ctx0, matrix_bd, 1, 0, 0, 0);
|
||||
matrix_bd = ggml_roll(ctx0, matrix_bd, 1, 0, 0, 0);
|
||||
matrix_bd = ggml_reshape_3d(ctx0, matrix_bd, q_len, pos_len + 1, h);
|
||||
matrix_bd = ggml_view_3d(ctx0, matrix_bd, q_len, pos_len, h, matrix_bd->nb[1],
|
||||
matrix_bd->nb[2], matrix_bd->nb[0] * q_len);
|
||||
matrix_bd = ggml_cont_3d(ctx0, matrix_bd, pos_len, q_len, h);
|
||||
}
|
||||
|
||||
matrix_bd = ggml_view_3d(ctx0, matrix_bd, matrix_ac->ne[0], matrix_bd->ne[1],
|
||||
matrix_bd->ne[2], matrix_bd->nb[1], matrix_bd->nb[2], 0);
|
||||
auto * scores = ggml_add(ctx0, matrix_ac, matrix_bd);
|
||||
scores = ggml_scale(ctx0, scores, 1.0f / std::sqrt(d_head));
|
||||
cb(scores, "conformer.layers.{}.self_attn.id0", il);
|
||||
|
||||
ggml_tensor * attn = ggml_soft_max(ctx0, scores);
|
||||
ggml_tensor * x = ggml_mul_mat(ctx0, attn, Vcur);
|
||||
x = ggml_permute(ctx0, x, 2, 0, 1, 3);
|
||||
x = ggml_cont_2d(ctx0, x, x->ne[0] * x->ne[1], x->ne[2]);
|
||||
|
||||
ggml_tensor * out = ggml_mul_mat(ctx0, layer.o_w, x);
|
||||
out = ggml_add(ctx0, out, layer.o_b);
|
||||
cb(out, "conformer.layers.{}.self_attn.linear_out", il);
|
||||
|
||||
cur = out;
|
||||
}
|
||||
|
||||
residual = ggml_add(ctx0, residual, cur);
|
||||
cur = build_norm(residual, layer.norm_conv_w, layer.norm_conv_b, NORM_TYPE_NORMAL, 1e-5, il);
|
||||
cb(cur, "conformer.layers.{}.norm_conv", il);
|
||||
|
||||
// conv
|
||||
{
|
||||
auto * x = cur;
|
||||
x = ggml_mul_mat(ctx0, layer.conv_pw1_w, x);
|
||||
x = ggml_add(ctx0, x, layer.conv_pw1_b);
|
||||
cb(x, "conformer.layers.{}.conv.pointwise_conv1", il);
|
||||
|
||||
// ggml_glu doesn't support sigmoid
|
||||
// TODO @ngxson : support this ops in ggml
|
||||
{
|
||||
int64_t d = x->ne[0] / 2;
|
||||
ggml_tensor * gate = ggml_sigmoid(ctx0, ggml_view_2d(ctx0, x, d, x->ne[1], x->nb[1], d * x->nb[0]));
|
||||
x = ggml_mul(ctx0, ggml_view_2d(ctx0, x, d, x->ne[1], x->nb[1], 0), gate);
|
||||
x = ggml_cont(ctx0, ggml_transpose(ctx0, x));
|
||||
}
|
||||
|
||||
// use ggml_ssm_conv for f32 precision
|
||||
x = ggml_pad(ctx0, x, 4, 0, 0, 0);
|
||||
x = ggml_roll(ctx0, x, 4, 0, 0, 0);
|
||||
x = ggml_pad(ctx0, x, 4, 0, 0, 0);
|
||||
x = ggml_ssm_conv(ctx0, x, layer.conv_dw_w);
|
||||
x = ggml_add(ctx0, x, layer.conv_dw_b);
|
||||
|
||||
x = ggml_add(ctx0, ggml_mul(ctx0, x, layer.conv_norm_w), layer.conv_norm_b);
|
||||
x = ggml_silu(ctx0, x);
|
||||
|
||||
// pointwise_conv2
|
||||
x = ggml_mul_mat(ctx0, layer.conv_pw2_w, x);
|
||||
x = ggml_add(ctx0, x, layer.conv_pw2_b);
|
||||
|
||||
cur = x;
|
||||
}
|
||||
|
||||
residual = ggml_add(ctx0, residual, cur);
|
||||
|
||||
cur = build_norm(residual, layer.ff_norm_1_w, layer.ff_norm_1_b, NORM_TYPE_NORMAL, 1e-5, il);
|
||||
cb(cur, "conformer.layers.{}.norm_feed_forward2", il);
|
||||
|
||||
cur = build_ffn(cur, layer.ff_up_1_w, layer.ff_up_1_b, nullptr, nullptr, layer.ff_down_1_w, layer.ff_down_1_b,
|
||||
FFN_SILU, il); // TODO(tarek): read activation for ffn from hparams
|
||||
cb(cur, "conformer.layers.{}.feed_forward2.linear2", il);
|
||||
|
||||
residual = ggml_add(ctx0, residual, ggml_scale(ctx0, cur, fc_factor));
|
||||
cb(residual, "conformer.layers.{}.conv.id", il);
|
||||
|
||||
cur = build_norm(residual, layer.ln_2_w, layer.ln_2_b, NORM_TYPE_NORMAL, 1e-5, il);
|
||||
cb(cur, "conformer.layers.{}.norm_out", il);
|
||||
}
|
||||
|
||||
// audio adapter
|
||||
cur = build_norm(cur, model.mm_0_w, model.mm_0_b, NORM_TYPE_NORMAL, 1e-5, -1);
|
||||
cb(cur, "audio_adapter.model.{}", 0);
|
||||
cur = build_ffn(cur, model.mm_1_w, model.mm_1_b, nullptr, nullptr, model.mm_3_w, model.mm_3_b, FFN_GELU_ERF, -1);
|
||||
|
||||
cb(cur, "projected", -1);
|
||||
|
||||
ggml_build_forward_expand(gf, cur);
|
||||
|
||||
return gf;
|
||||
}
|
||||
|
|
@ -57,6 +57,11 @@ struct clip_graph_whisper_enc : clip_graph {
|
|||
ggml_cgraph * build() override;
|
||||
};
|
||||
|
||||
struct clip_graph_conformer : clip_graph {
|
||||
clip_graph_conformer(clip_ctx * ctx, const clip_image_f32 & img) : clip_graph(ctx, img) {}
|
||||
ggml_cgraph * build() override;
|
||||
};
|
||||
|
||||
struct clip_graph_glm4v : clip_graph {
|
||||
clip_graph_glm4v(clip_ctx * ctx, const clip_image_f32 & img) : clip_graph(ctx, img) {}
|
||||
ggml_cgraph * build() override;
|
||||
|
|
|
|||
|
|
@ -535,3 +535,56 @@ bool mtmd_audio_preprocessor_whisper::preprocess(
|
|||
|
||||
return true;
|
||||
}
|
||||
|
||||
//
|
||||
// mtmd_audio_preprocessor_conformer
|
||||
//
|
||||
|
||||
void mtmd_audio_preprocessor_conformer::initialize() {
|
||||
g_cache.fill_sin_cos_table(hparams.audio_n_fft);
|
||||
g_cache.fill_hann_window(hparams.audio_window_len, true);
|
||||
g_cache.fill_mel_filterbank_matrix(
|
||||
hparams.n_mel_bins,
|
||||
hparams.audio_n_fft,
|
||||
hparams.audio_sample_rate);
|
||||
}
|
||||
|
||||
bool mtmd_audio_preprocessor_conformer::preprocess(
|
||||
const float * samples,
|
||||
size_t n_samples,
|
||||
std::vector<mtmd_audio_mel> & output) {
|
||||
// empty audio
|
||||
if (n_samples == 0) {
|
||||
return false;
|
||||
}
|
||||
|
||||
filter_params params;
|
||||
params.n_mel = hparams.n_mel_bins;
|
||||
params.n_fft_bins = 1 + (hparams.audio_n_fft / 2);
|
||||
params.hann_window_size = hparams.audio_window_len;
|
||||
params.hop_length = hparams.audio_hop_len;
|
||||
params.sample_rate = hparams.audio_sample_rate;
|
||||
params.center_padding = true;
|
||||
params.preemph = 0.97f;
|
||||
params.use_natural_log = true;
|
||||
params.norm_per_feature = true;
|
||||
|
||||
// make sure the global cache is initialized
|
||||
GGML_ASSERT(!g_cache.sin_vals.empty());
|
||||
GGML_ASSERT(!g_cache.cos_vals.empty());
|
||||
GGML_ASSERT(!g_cache.filters.data.empty());
|
||||
|
||||
mtmd_audio_mel out_full;
|
||||
bool ok = log_mel_spectrogram(
|
||||
samples,
|
||||
n_samples,
|
||||
4, // n_threads
|
||||
params,
|
||||
out_full);
|
||||
if (!ok) {
|
||||
return false;
|
||||
}
|
||||
|
||||
output.push_back(std::move(out_full));
|
||||
return true;
|
||||
}
|
||||
|
|
|
|||
|
|
@ -32,3 +32,9 @@ struct mtmd_audio_preprocessor_whisper : mtmd_audio_preprocessor {
|
|||
void initialize() override;
|
||||
bool preprocess(const float * samples, size_t n_samples, std::vector<mtmd_audio_mel> & output) override;
|
||||
};
|
||||
|
||||
struct mtmd_audio_preprocessor_conformer : mtmd_audio_preprocessor {
|
||||
mtmd_audio_preprocessor_conformer(const clip_ctx * ctx) : mtmd_audio_preprocessor(ctx) {}
|
||||
void initialize() override;
|
||||
bool preprocess(const float * samples, size_t n_samples, std::vector<mtmd_audio_mel> & output) override;
|
||||
};
|
||||
|
|
|
|||
|
|
@ -309,9 +309,24 @@ int main(int argc, char ** argv) {
|
|||
|
||||
if (g_is_interrupted) return 130;
|
||||
|
||||
auto eval_system_prompt_if_present = [&] {
|
||||
if (params.system_prompt.empty()) {
|
||||
return 0;
|
||||
}
|
||||
|
||||
common_chat_msg msg;
|
||||
msg.role = "system";
|
||||
msg.content = params.system_prompt;
|
||||
return eval_message(ctx, msg);
|
||||
};
|
||||
|
||||
LOG_WRN("WARN: This is an experimental CLI for testing multimodal capability.\n");
|
||||
LOG_WRN(" For normal use cases, please use the standard llama-cli\n");
|
||||
|
||||
if (eval_system_prompt_if_present()) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
if (is_single_turn) {
|
||||
g_is_generating = true;
|
||||
if (params.prompt.find(mtmd_default_marker()) == std::string::npos) {
|
||||
|
|
@ -321,6 +336,7 @@ int main(int argc, char ** argv) {
|
|||
params.prompt = mtmd_default_marker() + params.prompt;
|
||||
}
|
||||
}
|
||||
|
||||
common_chat_msg msg;
|
||||
msg.role = "user";
|
||||
msg.content = params.prompt;
|
||||
|
|
@ -369,6 +385,9 @@ int main(int argc, char ** argv) {
|
|||
ctx.n_past = 0;
|
||||
ctx.chat_history.clear();
|
||||
llama_memory_clear(llama_get_memory(ctx.lctx), true);
|
||||
if (eval_system_prompt_if_present()) {
|
||||
return 1;
|
||||
}
|
||||
LOG("Chat history cleared\n\n");
|
||||
continue;
|
||||
}
|
||||
|
|
|
|||
|
|
@ -332,6 +332,9 @@ struct mtmd_context {
|
|||
case PROJECTOR_TYPE_GLMA:
|
||||
audio_preproc = std::make_unique<mtmd_audio_preprocessor_whisper>(ctx_a);
|
||||
break;
|
||||
case PROJECTOR_TYPE_LFM2A:
|
||||
audio_preproc = std::make_unique<mtmd_audio_preprocessor_conformer>(ctx_a);
|
||||
break;
|
||||
default:
|
||||
GGML_ABORT("unsupported audio projector type");
|
||||
}
|
||||
|
|
|
|||
|
|
@ -84,6 +84,7 @@ add_test_vision "ggml-org/LightOnOCR-1B-1025-GGUF:Q8_0"
|
|||
add_test_audio "ggml-org/ultravox-v0_5-llama-3_2-1b-GGUF:Q8_0"
|
||||
add_test_audio "ggml-org/Qwen2.5-Omni-3B-GGUF:Q4_K_M"
|
||||
add_test_audio "ggml-org/Voxtral-Mini-3B-2507-GGUF:Q4_K_M"
|
||||
add_test_audio "ggml-org/LFM2-Audio-1.5B-GGUF:Q8_0"
|
||||
|
||||
# to test the big models, run: ./tests.sh big
|
||||
if [ "$RUN_BIG_TESTS" = true ]; then
|
||||
|
|
|
|||
|
|
@ -75,9 +75,9 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
|||
| `--numa TYPE` | attempt optimizations that help on some NUMA systems<br/>- distribute: spread execution evenly over all nodes<br/>- isolate: only spawn threads on CPUs on the node that execution started on<br/>- numactl: use the CPU map provided by numactl<br/>if run without this previously, it is recommended to drop the system page cache before using this<br/>see https://github.com/ggml-org/llama.cpp/issues/1437<br/>(env: LLAMA_ARG_NUMA) |
|
||||
| `-dev, --device <dev1,dev2,..>` | comma-separated list of devices to use for offloading (none = don't offload)<br/>use --list-devices to see a list of available devices<br/>(env: LLAMA_ARG_DEVICE) |
|
||||
| `--list-devices` | print list of available devices and exit |
|
||||
| `--override-tensor, -ot <tensor name pattern>=<buffer type>,...` | override tensor buffer type |
|
||||
| `--cpu-moe, -cmoe` | keep all Mixture of Experts (MoE) weights in the CPU<br/>(env: LLAMA_ARG_CPU_MOE) |
|
||||
| `--n-cpu-moe, -ncmoe N` | keep the Mixture of Experts (MoE) weights of the first N layers in the CPU<br/>(env: LLAMA_ARG_N_CPU_MOE) |
|
||||
| `-ot, --override-tensor <tensor name pattern>=<buffer type>,...` | override tensor buffer type |
|
||||
| `-cmoe, --cpu-moe` | keep all Mixture of Experts (MoE) weights in the CPU<br/>(env: LLAMA_ARG_CPU_MOE) |
|
||||
| `-ncmoe, --n-cpu-moe N` | keep the Mixture of Experts (MoE) weights of the first N layers in the CPU<br/>(env: LLAMA_ARG_N_CPU_MOE) |
|
||||
| `-ngl, --gpu-layers, --n-gpu-layers N` | max. number of layers to store in VRAM (default: -1)<br/>(env: LLAMA_ARG_N_GPU_LAYERS) |
|
||||
| `-sm, --split-mode {none,layer,row}` | how to split the model across multiple GPUs, one of:<br/>- none: use one GPU only<br/>- layer (default): split layers and KV across GPUs<br/>- row: split rows across GPUs<br/>(env: LLAMA_ARG_SPLIT_MODE) |
|
||||
| `-ts, --tensor-split N0,N1,N2,...` | fraction of the model to offload to each GPU, comma-separated list of proportions, e.g. 3,1<br/>(env: LLAMA_ARG_TENSOR_SPLIT) |
|
||||
|
|
@ -120,7 +120,7 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
|||
| -------- | ----------- |
|
||||
| `--samplers SAMPLERS` | samplers that will be used for generation in the order, separated by ';'<br/>(default: penalties;dry;top_n_sigma;top_k;typ_p;top_p;min_p;xtc;temperature) |
|
||||
| `-s, --seed SEED` | RNG seed (default: -1, use random seed for -1) |
|
||||
| `--sampling-seq, --sampler-seq SEQUENCE` | simplified sequence for samplers that will be used (default: edskypmxt) |
|
||||
| `--sampler-seq, --sampling-seq SEQUENCE` | simplified sequence for samplers that will be used (default: edskypmxt) |
|
||||
| `--ignore-eos` | ignore end of stream token and continue generating (implies --logit-bias EOS-inf) |
|
||||
| `--temp N` | temperature (default: 0.8) |
|
||||
| `--top-k N` | top-k sampling (default: 40, 0 = disabled)<br/>(env: LLAMA_ARG_TOP_K) |
|
||||
|
|
@ -156,8 +156,8 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
|||
| Argument | Explanation |
|
||||
| -------- | ----------- |
|
||||
| `--ctx-checkpoints, --swa-checkpoints N` | max number of context checkpoints to create per slot (default: 8)[(more info)](https://github.com/ggml-org/llama.cpp/pull/15293)<br/>(env: LLAMA_ARG_CTX_CHECKPOINTS) |
|
||||
| `--cache-ram, -cram N` | set the maximum cache size in MiB (default: 8192, -1 - no limit, 0 - disable)[(more info)](https://github.com/ggml-org/llama.cpp/pull/16391)<br/>(env: LLAMA_ARG_CACHE_RAM) |
|
||||
| `--kv-unified, -kvu` | use single unified KV buffer shared across all sequences (default: enabled if number of slots is auto)<br/>(env: LLAMA_ARG_KV_UNIFIED) |
|
||||
| `-cram, --cache-ram N` | set the maximum cache size in MiB (default: 8192, -1 - no limit, 0 - disable)[(more info)](https://github.com/ggml-org/llama.cpp/pull/16391)<br/>(env: LLAMA_ARG_CACHE_RAM) |
|
||||
| `-kvu, --kv-unified` | use single unified KV buffer shared across all sequences (default: enabled if number of slots is auto)<br/>(env: LLAMA_ARG_KV_UNIFIED) |
|
||||
| `--context-shift, --no-context-shift` | whether to use context shift on infinite text generation (default: disabled)<br/>(env: LLAMA_ARG_CONTEXT_SHIFT) |
|
||||
| `-r, --reverse-prompt PROMPT` | halt generation at PROMPT, return control in interactive mode<br/> |
|
||||
| `-sp, --special` | special tokens output enabled (default: false) |
|
||||
|
|
@ -172,9 +172,9 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
|||
| `--mmproj-offload, --no-mmproj-offload` | whether to enable GPU offloading for multimodal projector (default: enabled)<br/>(env: LLAMA_ARG_MMPROJ_OFFLOAD) |
|
||||
| `--image-min-tokens N` | minimum number of tokens each image can take, only used by vision models with dynamic resolution (default: read from model)<br/>(env: LLAMA_ARG_IMAGE_MIN_TOKENS) |
|
||||
| `--image-max-tokens N` | maximum number of tokens each image can take, only used by vision models with dynamic resolution (default: read from model)<br/>(env: LLAMA_ARG_IMAGE_MAX_TOKENS) |
|
||||
| `--override-tensor-draft, -otd <tensor name pattern>=<buffer type>,...` | override tensor buffer type for draft model |
|
||||
| `--cpu-moe-draft, -cmoed` | keep all Mixture of Experts (MoE) weights in the CPU for the draft model<br/>(env: LLAMA_ARG_CPU_MOE_DRAFT) |
|
||||
| `--n-cpu-moe-draft, -ncmoed N` | keep the Mixture of Experts (MoE) weights of the first N layers in the CPU for the draft model<br/>(env: LLAMA_ARG_N_CPU_MOE_DRAFT) |
|
||||
| `-otd, --override-tensor-draft <tensor name pattern>=<buffer type>,...` | override tensor buffer type for draft model |
|
||||
| `-cmoed, --cpu-moe-draft` | keep all Mixture of Experts (MoE) weights in the CPU for the draft model<br/>(env: LLAMA_ARG_CPU_MOE_DRAFT) |
|
||||
| `-ncmoed, --n-cpu-moe-draft N` | keep the Mixture of Experts (MoE) weights of the first N layers in the CPU for the draft model<br/>(env: LLAMA_ARG_N_CPU_MOE_DRAFT) |
|
||||
| `-a, --alias STRING` | set alias for model name (to be used by REST API)<br/>(env: LLAMA_ARG_ALIAS) |
|
||||
| `--host HOST` | ip address to listen, or bind to an UNIX socket if the address ends with .sock (default: 127.0.0.1)<br/>(env: LLAMA_ARG_HOST) |
|
||||
| `--port PORT` | port to listen (default: 8080)<br/>(env: LLAMA_ARG_PORT) |
|
||||
|
|
@ -184,7 +184,7 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
|||
| `--webui-config-file PATH` | JSON file that provides default WebUI settings (overrides WebUI defaults)<br/>(env: LLAMA_ARG_WEBUI_CONFIG_FILE) |
|
||||
| `--webui, --no-webui` | whether to enable the Web UI (default: enabled)<br/>(env: LLAMA_ARG_WEBUI) |
|
||||
| `--embedding, --embeddings` | restrict to only support embedding use case; use only with dedicated embedding models (default: disabled)<br/>(env: LLAMA_ARG_EMBEDDINGS) |
|
||||
| `--reranking, --rerank` | enable reranking endpoint on server (default: disabled)<br/>(env: LLAMA_ARG_RERANKING) |
|
||||
| `--rerank, --reranking` | enable reranking endpoint on server (default: disabled)<br/>(env: LLAMA_ARG_RERANKING) |
|
||||
| `--api-key KEY` | API key to use for authentication (default: none)<br/>(env: LLAMA_API_KEY) |
|
||||
| `--api-key-file FNAME` | path to file containing API keys (default: none) |
|
||||
| `--ssl-key-file FNAME` | path to file a PEM-encoded SSL private key<br/>(env: LLAMA_ARG_SSL_KEY_FILE) |
|
||||
|
|
@ -212,7 +212,7 @@ For the ful list of features, please refer to [server's changelog](https://githu
|
|||
| `--lora-init-without-apply` | load LoRA adapters without applying them (apply later via POST /lora-adapters) (default: disabled) |
|
||||
| `-td, --threads-draft N` | number of threads to use during generation (default: same as --threads) |
|
||||
| `-tbd, --threads-batch-draft N` | number of threads to use during batch and prompt processing (default: same as --threads-draft) |
|
||||
| `--draft-max, --draft, --draft-n N` | number of tokens to draft for speculative decoding (default: 16)<br/>(env: LLAMA_ARG_DRAFT_MAX) |
|
||||
| `--draft, --draft-n, --draft-max N` | number of tokens to draft for speculative decoding (default: 16)<br/>(env: LLAMA_ARG_DRAFT_MAX) |
|
||||
| `--draft-min, --draft-n-min N` | minimum number of draft tokens to use for speculative decoding (default: 0)<br/>(env: LLAMA_ARG_DRAFT_MIN) |
|
||||
| `--draft-p-min P` | minimum speculative decoding probability (greedy) (default: 0.8)<br/>(env: LLAMA_ARG_DRAFT_P_MIN) |
|
||||
| `-cd, --ctx-size-draft N` | size of the prompt context for the draft model (default: 0, 0 = loaded from model)<br/>(env: LLAMA_ARG_CTX_SIZE_DRAFT) |
|
||||
|
|
@ -1443,6 +1443,12 @@ Example:
|
|||
```ini
|
||||
version = 1
|
||||
|
||||
; (Optional) This section provides global settings shared across all presets.
|
||||
; If the same key is defined in a specific preset, it will override the value in this global section.
|
||||
[*]
|
||||
c = 8192
|
||||
n-gpu-layer = 8
|
||||
|
||||
; If the key corresponds to an existing model on the server,
|
||||
; this will be used as the default config for that model
|
||||
[ggml-org/MY-MODEL-GGUF:Q8_0]
|
||||
|
|
@ -1462,12 +1468,17 @@ model-draft = ./my-models/draft.gguf
|
|||
model-draft = /Users/abc/my-models/draft.gguf
|
||||
|
||||
; If the key does NOT correspond to an existing model,
|
||||
; you need to specify at least the model path
|
||||
; you need to specify at least the model path or HF repo
|
||||
[custom_model]
|
||||
model = /Users/abc/my-awesome-model-Q4_K_M.gguf
|
||||
```
|
||||
|
||||
Note: some arguments are controlled by router (e.g., host, port, API key, HF repo, model alias). They will be removed or overwritten upload loading.
|
||||
Note: some arguments are controlled by router (e.g., host, port, API key, HF repo, model alias). They will be removed or overwritten upon loading.
|
||||
|
||||
The precedence rule for preset options is as follows:
|
||||
1. **Command-line arguments** passed to `llama-server` (highest priority)
|
||||
2. **Model-specific options** defined in the preset file (e.g. `[ggml-org/MY-MODEL...]`)
|
||||
3. **Global options** defined in the preset file (`[*]`)
|
||||
|
||||
### Routing requests
|
||||
|
||||
|
|
|
|||
Binary file not shown.
|
|
@ -1974,19 +1974,33 @@ struct server_context_impl {
|
|||
|
||||
if (!slot.can_split()) {
|
||||
if (slot.task->n_tokens() > n_ubatch) {
|
||||
send_error(slot, "input is too large to process. increase the physical batch size", ERROR_TYPE_SERVER);
|
||||
send_error(slot,
|
||||
string_format(
|
||||
"input (%d tokens) is too large to process. increase the physical batch "
|
||||
"size (current batch size: %d)",
|
||||
slot.task->n_tokens(), n_ubatch),
|
||||
ERROR_TYPE_SERVER);
|
||||
slot.release();
|
||||
continue;
|
||||
}
|
||||
|
||||
if (slot.task->n_tokens() > slot.n_ctx) {
|
||||
send_error(slot, "input is larger than the max context size. skipping", ERROR_TYPE_EXCEED_CONTEXT_SIZE);
|
||||
send_error(
|
||||
slot,
|
||||
string_format(
|
||||
"input (%d tokens) is larger than the max context size (%d tokens). skipping",
|
||||
slot.task->n_tokens(), slot.n_ctx),
|
||||
ERROR_TYPE_EXCEED_CONTEXT_SIZE);
|
||||
slot.release();
|
||||
continue;
|
||||
}
|
||||
} else {
|
||||
if (slot.task->n_tokens() >= slot.n_ctx) {
|
||||
send_error(slot, "the request exceeds the available context size, try increasing it", ERROR_TYPE_EXCEED_CONTEXT_SIZE);
|
||||
send_error(slot,
|
||||
string_format("request (%d tokens) exceeds the available context size (%d "
|
||||
"tokens), try increasing it",
|
||||
slot.task->n_tokens(), slot.n_ctx),
|
||||
ERROR_TYPE_EXCEED_CONTEXT_SIZE);
|
||||
slot.release();
|
||||
continue;
|
||||
}
|
||||
|
|
|
|||
|
|
@ -82,154 +82,30 @@ static std::filesystem::path get_server_exec_path() {
|
|||
#endif
|
||||
}
|
||||
|
||||
struct local_model {
|
||||
std::string name;
|
||||
std::string path;
|
||||
std::string path_mmproj;
|
||||
};
|
||||
|
||||
static std::vector<local_model> list_local_models(const std::string & dir) {
|
||||
if (!std::filesystem::exists(dir) || !std::filesystem::is_directory(dir)) {
|
||||
throw std::runtime_error(string_format("error: '%s' does not exist or is not a directory\n", dir.c_str()));
|
||||
}
|
||||
|
||||
std::vector<local_model> models;
|
||||
auto scan_subdir = [&models](const std::string & subdir_path, const std::string & name) {
|
||||
auto files = fs_list(subdir_path, false);
|
||||
common_file_info model_file;
|
||||
common_file_info first_shard_file;
|
||||
common_file_info mmproj_file;
|
||||
for (const auto & file : files) {
|
||||
if (string_ends_with(file.name, ".gguf")) {
|
||||
if (file.name.find("mmproj") != std::string::npos) {
|
||||
mmproj_file = file;
|
||||
} else if (file.name.find("-00001-of-") != std::string::npos) {
|
||||
first_shard_file = file;
|
||||
} else {
|
||||
model_file = file;
|
||||
}
|
||||
}
|
||||
}
|
||||
// single file model
|
||||
local_model model{
|
||||
/* name */ name,
|
||||
/* path */ first_shard_file.path.empty() ? model_file.path : first_shard_file.path,
|
||||
/* path_mmproj */ mmproj_file.path // can be empty
|
||||
};
|
||||
if (!model.path.empty()) {
|
||||
models.push_back(model);
|
||||
}
|
||||
};
|
||||
|
||||
auto files = fs_list(dir, true);
|
||||
for (const auto & file : files) {
|
||||
if (file.is_dir) {
|
||||
scan_subdir(file.path, file.name);
|
||||
} else if (string_ends_with(file.name, ".gguf")) {
|
||||
// single file model
|
||||
std::string name = file.name;
|
||||
string_replace_all(name, ".gguf", "");
|
||||
local_model model{
|
||||
/* name */ name,
|
||||
/* path */ file.path,
|
||||
/* path_mmproj */ ""
|
||||
};
|
||||
models.push_back(model);
|
||||
}
|
||||
}
|
||||
return models;
|
||||
}
|
||||
|
||||
//
|
||||
// server_presets
|
||||
//
|
||||
|
||||
|
||||
server_presets::server_presets(int argc, char ** argv, common_params & base_params, const std::string & presets_path)
|
||||
: ctx_params(common_params_parser_init(base_params, LLAMA_EXAMPLE_SERVER)) {
|
||||
if (!presets_path.empty()) {
|
||||
presets = common_presets_load(presets_path, ctx_params);
|
||||
SRV_INF("Loaded %zu presets from %s\n", presets.size(), presets_path.c_str());
|
||||
}
|
||||
|
||||
// populate reserved args (will be appended by the router)
|
||||
for (auto & opt : ctx_params.options) {
|
||||
if (opt.env == nullptr) {
|
||||
continue;
|
||||
}
|
||||
std::string env = opt.env;
|
||||
if (env == "LLAMA_ARG_PORT" ||
|
||||
env == "LLAMA_ARG_HOST" ||
|
||||
env == "LLAMA_ARG_ALIAS" ||
|
||||
env == "LLAMA_ARG_API_KEY" ||
|
||||
env == "LLAMA_ARG_MODELS_DIR" ||
|
||||
env == "LLAMA_ARG_MODELS_MAX" ||
|
||||
env == "LLAMA_ARG_MODELS_PRESET" ||
|
||||
env == "LLAMA_ARG_MODEL" ||
|
||||
env == "LLAMA_ARG_MMPROJ" ||
|
||||
env == "LLAMA_ARG_HF_REPO" ||
|
||||
env == "LLAMA_ARG_NO_MODELS_AUTOLOAD" ||
|
||||
env == "LLAMA_ARG_SSL_KEY_FILE" ||
|
||||
env == "LLAMA_ARG_SSL_CERT_FILE") {
|
||||
control_args[env] = opt;
|
||||
}
|
||||
}
|
||||
|
||||
// read base args from router's argv
|
||||
common_params_to_map(argc, argv, LLAMA_EXAMPLE_SERVER, base_args);
|
||||
|
||||
// remove any router-controlled args from base_args
|
||||
for (const auto & cargs : control_args) {
|
||||
auto it = base_args.find(cargs.second);
|
||||
if (it != base_args.end()) {
|
||||
base_args.erase(it);
|
||||
}
|
||||
static void unset_reserved_args(common_preset & preset, bool unset_model_args) {
|
||||
preset.unset_option("LLAMA_ARG_SSL_KEY_FILE");
|
||||
preset.unset_option("LLAMA_ARG_SSL_CERT_FILE");
|
||||
preset.unset_option("LLAMA_API_KEY");
|
||||
preset.unset_option("LLAMA_ARG_MODELS_DIR");
|
||||
preset.unset_option("LLAMA_ARG_MODELS_MAX");
|
||||
preset.unset_option("LLAMA_ARG_MODELS_PRESET");
|
||||
preset.unset_option("LLAMA_ARG_MODELS_AUTOLOAD");
|
||||
if (unset_model_args) {
|
||||
preset.unset_option("LLAMA_ARG_MODEL");
|
||||
preset.unset_option("LLAMA_ARG_MMPROJ");
|
||||
preset.unset_option("LLAMA_ARG_HF_REPO");
|
||||
}
|
||||
}
|
||||
|
||||
common_preset server_presets::get_preset(const std::string & name) {
|
||||
auto it = presets.find(name);
|
||||
if (it != presets.end()) {
|
||||
return it->second;
|
||||
}
|
||||
return common_preset();
|
||||
}
|
||||
|
||||
void server_presets::render_args(server_model_meta & meta) {
|
||||
common_preset preset = meta.preset; // copy
|
||||
// merging 3 kinds of args:
|
||||
// 1. model-specific args (from preset)
|
||||
// force removing control args if any
|
||||
for (auto & cargs : control_args) {
|
||||
if (preset.options.find(cargs.second) != preset.options.end()) {
|
||||
SRV_WRN("Preset '%s' contains reserved arg '%s', removing it\n", preset.name.c_str(), cargs.second.args[0]);
|
||||
preset.options.erase(cargs.second);
|
||||
}
|
||||
}
|
||||
// 2. base args (from router)
|
||||
// inherit from base args
|
||||
for (const auto & [arg, value] : base_args) {
|
||||
preset.options[arg] = value;
|
||||
}
|
||||
// 3. control args (from router)
|
||||
// set control values
|
||||
preset.options[control_args["LLAMA_ARG_HOST"]] = CHILD_ADDR;
|
||||
preset.options[control_args["LLAMA_ARG_PORT"]] = std::to_string(meta.port);
|
||||
preset.options[control_args["LLAMA_ARG_ALIAS"]] = meta.name;
|
||||
if (meta.in_cache) {
|
||||
preset.options[control_args["LLAMA_ARG_HF_REPO"]] = meta.name;
|
||||
} else {
|
||||
preset.options[control_args["LLAMA_ARG_MODEL"]] = meta.path;
|
||||
if (!meta.path_mmproj.empty()) {
|
||||
preset.options[control_args["LLAMA_ARG_MMPROJ"]] = meta.path_mmproj;
|
||||
}
|
||||
}
|
||||
// disable SSL for child processes (HTTPS already handled by router)
|
||||
preset.options[control_args["LLAMA_ARG_SSL_KEY_FILE"]] = "";
|
||||
preset.options[control_args["LLAMA_ARG_SSL_CERT_FILE"]] = "";
|
||||
meta.args = preset.to_args();
|
||||
// add back the binary path at the front
|
||||
meta.args.insert(meta.args.begin(), get_server_exec_path().string());
|
||||
void server_model_meta::update_args(common_preset_context & ctx_preset, std::string bin_path) {
|
||||
// update params
|
||||
unset_reserved_args(preset, false);
|
||||
preset.set_option(ctx_preset, "LLAMA_ARG_HOST", CHILD_ADDR);
|
||||
preset.set_option(ctx_preset, "LLAMA_ARG_PORT", std::to_string(port));
|
||||
preset.set_option(ctx_preset, "LLAMA_ARG_ALIAS", name);
|
||||
// TODO: maybe validate preset before rendering ?
|
||||
// render args
|
||||
args = preset.to_args(bin_path);
|
||||
}
|
||||
|
||||
//
|
||||
|
|
@ -240,20 +116,22 @@ server_models::server_models(
|
|||
const common_params & params,
|
||||
int argc,
|
||||
char ** argv,
|
||||
char ** envp) : base_params(params), presets(argc, argv, base_params, params.models_preset) {
|
||||
for (int i = 0; i < argc; i++) {
|
||||
base_args.push_back(std::string(argv[i]));
|
||||
}
|
||||
char ** envp)
|
||||
: ctx_preset(LLAMA_EXAMPLE_SERVER),
|
||||
base_params(params),
|
||||
base_preset(ctx_preset.load_from_args(argc, argv)) {
|
||||
for (char ** env = envp; *env != nullptr; env++) {
|
||||
base_env.push_back(std::string(*env));
|
||||
}
|
||||
GGML_ASSERT(!base_args.empty());
|
||||
// clean up base preset
|
||||
unset_reserved_args(base_preset, true);
|
||||
// set binary path
|
||||
try {
|
||||
base_args[0] = get_server_exec_path().string();
|
||||
bin_path = get_server_exec_path().string();
|
||||
} catch (const std::exception & e) {
|
||||
bin_path = argv[0];
|
||||
LOG_WRN("failed to get server executable path: %s\n", e.what());
|
||||
LOG_WRN("using original argv[0] as fallback: %s\n", base_args[0].c_str());
|
||||
LOG_WRN("using original argv[0] as fallback: %s\n", argv[0]);
|
||||
}
|
||||
load_models();
|
||||
}
|
||||
|
|
@ -262,7 +140,7 @@ void server_models::add_model(server_model_meta && meta) {
|
|||
if (mapping.find(meta.name) != mapping.end()) {
|
||||
throw std::runtime_error(string_format("model '%s' appears multiple times", meta.name.c_str()));
|
||||
}
|
||||
presets.render_args(meta); // populate meta.args
|
||||
meta.update_args(ctx_preset, bin_path); // render args
|
||||
std::string name = meta.name;
|
||||
mapping[name] = instance_t{
|
||||
/* subproc */ std::make_shared<subprocess_s>(),
|
||||
|
|
@ -271,86 +149,62 @@ void server_models::add_model(server_model_meta && meta) {
|
|||
};
|
||||
}
|
||||
|
||||
static std::vector<local_model> list_custom_path_models(server_presets & presets) {
|
||||
// detect any custom-path models in presets
|
||||
std::vector<local_model> custom_models;
|
||||
for (auto & [model_name, preset] : presets.presets) {
|
||||
local_model model;
|
||||
model.name = model_name;
|
||||
std::vector<common_arg> to_erase;
|
||||
for (auto & [arg, value] : preset.options) {
|
||||
std::string env(arg.env ? arg.env : "");
|
||||
if (env == "LLAMA_ARG_MODEL") {
|
||||
model.path = value;
|
||||
to_erase.push_back(arg);
|
||||
}
|
||||
if (env == "LLAMA_ARG_MMPROJ") {
|
||||
model.path_mmproj = value;
|
||||
to_erase.push_back(arg);
|
||||
}
|
||||
}
|
||||
for (auto & arg : to_erase) {
|
||||
preset.options.erase(arg);
|
||||
}
|
||||
if (!model.name.empty() && !model.path.empty()) {
|
||||
custom_models.push_back(model);
|
||||
}
|
||||
}
|
||||
return custom_models;
|
||||
}
|
||||
|
||||
// TODO: allow refreshing cached model list
|
||||
void server_models::load_models() {
|
||||
// loading models from 3 sources:
|
||||
// 1. cached models
|
||||
auto cached_models = common_list_cached_models();
|
||||
for (const auto & model : cached_models) {
|
||||
server_model_meta meta{
|
||||
/* preset */ presets.get_preset(model.to_string()),
|
||||
/* name */ model.to_string(),
|
||||
/* path */ model.manifest_path,
|
||||
/* path_mmproj */ "", // auto-detected when loading
|
||||
/* in_cache */ true,
|
||||
/* port */ 0,
|
||||
/* status */ SERVER_MODEL_STATUS_UNLOADED,
|
||||
/* last_used */ 0,
|
||||
/* args */ std::vector<std::string>(),
|
||||
/* exit_code */ 0
|
||||
};
|
||||
add_model(std::move(meta));
|
||||
}
|
||||
// 2. local models specificed via --models-dir
|
||||
common_presets cached_models = ctx_preset.load_from_cache();
|
||||
SRV_INF("Loaded %zu cached model presets\n", cached_models.size());
|
||||
// 2. local models from --models-dir
|
||||
common_presets local_models;
|
||||
if (!base_params.models_dir.empty()) {
|
||||
auto local_models = list_local_models(base_params.models_dir);
|
||||
for (const auto & model : local_models) {
|
||||
if (mapping.find(model.name) != mapping.end()) {
|
||||
// already exists in cached models, skip
|
||||
continue;
|
||||
}
|
||||
server_model_meta meta{
|
||||
/* preset */ presets.get_preset(model.name),
|
||||
/* name */ model.name,
|
||||
/* path */ model.path,
|
||||
/* path_mmproj */ model.path_mmproj,
|
||||
/* in_cache */ false,
|
||||
/* port */ 0,
|
||||
/* status */ SERVER_MODEL_STATUS_UNLOADED,
|
||||
/* last_used */ 0,
|
||||
/* args */ std::vector<std::string>(),
|
||||
/* exit_code */ 0
|
||||
};
|
||||
add_model(std::move(meta));
|
||||
local_models = ctx_preset.load_from_models_dir(base_params.models_dir);
|
||||
SRV_INF("Loaded %zu local model presets from %s\n", local_models.size(), base_params.models_dir.c_str());
|
||||
}
|
||||
// 3. custom-path models from presets
|
||||
common_preset global = {};
|
||||
common_presets custom_presets = {};
|
||||
if (!base_params.models_preset.empty()) {
|
||||
custom_presets = ctx_preset.load_from_ini(base_params.models_preset, global);
|
||||
SRV_INF("Loaded %zu custom model presets from %s\n", custom_presets.size(), base_params.models_preset.c_str());
|
||||
}
|
||||
|
||||
// cascade, apply global preset first
|
||||
cached_models = ctx_preset.cascade(global, cached_models);
|
||||
local_models = ctx_preset.cascade(global, local_models);
|
||||
custom_presets = ctx_preset.cascade(global, custom_presets);
|
||||
|
||||
// note: if a model exists in both cached and local, local takes precedence
|
||||
common_presets final_presets;
|
||||
for (const auto & [name, preset] : cached_models) {
|
||||
final_presets[name] = preset;
|
||||
}
|
||||
for (const auto & [name, preset] : local_models) {
|
||||
final_presets[name] = preset;
|
||||
}
|
||||
|
||||
// process custom presets from INI
|
||||
for (const auto & [name, custom] : custom_presets) {
|
||||
if (final_presets.find(name) != final_presets.end()) {
|
||||
// apply custom config if exists
|
||||
common_preset & target = final_presets[name];
|
||||
target.merge(custom);
|
||||
} else {
|
||||
// otherwise add directly
|
||||
final_presets[name] = custom;
|
||||
}
|
||||
}
|
||||
// 3. custom-path models specified in presets
|
||||
auto custom_models = list_custom_path_models(presets);
|
||||
for (const auto & model : custom_models) {
|
||||
|
||||
// server base preset from CLI args take highest precedence
|
||||
for (auto & [name, preset] : final_presets) {
|
||||
preset.merge(base_preset);
|
||||
}
|
||||
|
||||
// convert presets to server_model_meta and add to mapping
|
||||
for (const auto & preset : final_presets) {
|
||||
server_model_meta meta{
|
||||
/* preset */ presets.get_preset(model.name),
|
||||
/* name */ model.name,
|
||||
/* path */ model.path,
|
||||
/* path_mmproj */ model.path_mmproj,
|
||||
/* in_cache */ false,
|
||||
/* preset */ preset.second,
|
||||
/* name */ preset.first,
|
||||
/* port */ 0,
|
||||
/* status */ SERVER_MODEL_STATUS_UNLOADED,
|
||||
/* last_used */ 0,
|
||||
|
|
@ -359,10 +213,18 @@ void server_models::load_models() {
|
|||
};
|
||||
add_model(std::move(meta));
|
||||
}
|
||||
|
||||
// log available models
|
||||
SRV_INF("Available models (%zu) (*: custom preset)\n", mapping.size());
|
||||
for (const auto & [name, inst] : mapping) {
|
||||
SRV_INF(" %c %s\n", inst.meta.preset.name.empty() ? ' ' : '*', name.c_str());
|
||||
{
|
||||
std::unordered_set<std::string> custom_names;
|
||||
for (const auto & [name, preset] : custom_presets) {
|
||||
custom_names.insert(name);
|
||||
}
|
||||
SRV_INF("Available models (%zu) (*: custom preset)\n", mapping.size());
|
||||
for (const auto & [name, inst] : mapping) {
|
||||
bool has_custom = custom_names.find(name) != custom_names.end();
|
||||
SRV_INF(" %c %s\n", has_custom ? '*' : ' ', name.c_str());
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
|
|
@ -526,7 +388,7 @@ void server_models::load(const std::string & name) {
|
|||
{
|
||||
SRV_INF("spawning server instance with name=%s on port %d\n", inst.meta.name.c_str(), inst.meta.port);
|
||||
|
||||
presets.render_args(inst.meta); // update meta.args
|
||||
inst.meta.update_args(ctx_preset, bin_path); // render args
|
||||
|
||||
std::vector<std::string> child_args = inst.meta.args; // copy
|
||||
std::vector<std::string> child_env = base_env; // copy
|
||||
|
|
@ -877,7 +739,12 @@ void server_models_routes::init_routes() {
|
|||
{"args", meta.args},
|
||||
};
|
||||
if (!meta.preset.name.empty()) {
|
||||
status["preset"] = meta.preset.to_ini();
|
||||
common_preset preset_copy = meta.preset;
|
||||
unset_reserved_args(preset_copy, false);
|
||||
preset_copy.unset_option("LLAMA_ARG_HOST");
|
||||
preset_copy.unset_option("LLAMA_ARG_PORT");
|
||||
preset_copy.unset_option("LLAMA_ARG_ALIAS");
|
||||
status["preset"] = preset_copy.to_ini();
|
||||
}
|
||||
if (meta.is_failed()) {
|
||||
status["exit_code"] = meta.exit_code;
|
||||
|
|
@ -888,8 +755,6 @@ void server_models_routes::init_routes() {
|
|||
{"object", "model"}, // for OAI-compat
|
||||
{"owned_by", "llamacpp"}, // for OAI-compat
|
||||
{"created", t}, // for OAI-compat
|
||||
{"in_cache", meta.in_cache},
|
||||
{"path", meta.path},
|
||||
{"status", status},
|
||||
// TODO: add other fields, may require reading GGUF metadata
|
||||
});
|
||||
|
|
|
|||
|
|
@ -51,9 +51,6 @@ static std::string server_model_status_to_string(server_model_status status) {
|
|||
struct server_model_meta {
|
||||
common_preset preset;
|
||||
std::string name;
|
||||
std::string path;
|
||||
std::string path_mmproj; // only available if in_cache=false
|
||||
bool in_cache = false; // if true, use -hf; use -m otherwise
|
||||
int port = 0;
|
||||
server_model_status status = SERVER_MODEL_STATUS_UNLOADED;
|
||||
int64_t last_used = 0; // for LRU unloading
|
||||
|
|
@ -67,19 +64,8 @@ struct server_model_meta {
|
|||
bool is_failed() const {
|
||||
return status == SERVER_MODEL_STATUS_UNLOADED && exit_code != 0;
|
||||
}
|
||||
};
|
||||
|
||||
// the server_presets struct holds the presets read from presets.ini
|
||||
// as well as base args from the router server
|
||||
struct server_presets {
|
||||
common_presets presets;
|
||||
common_params_context ctx_params;
|
||||
std::map<common_arg, std::string> base_args;
|
||||
std::map<std::string, common_arg> control_args; // args reserved for server control
|
||||
|
||||
server_presets(int argc, char ** argv, common_params & base_params, const std::string & models_dir);
|
||||
common_preset get_preset(const std::string & name);
|
||||
void render_args(server_model_meta & meta);
|
||||
void update_args(common_preset_context & ctx_presets, std::string bin_path);
|
||||
};
|
||||
|
||||
struct subprocess_s;
|
||||
|
|
@ -97,11 +83,12 @@ private:
|
|||
std::condition_variable cv;
|
||||
std::map<std::string, instance_t> mapping;
|
||||
|
||||
common_params base_params;
|
||||
std::vector<std::string> base_args;
|
||||
std::vector<std::string> base_env;
|
||||
common_preset_context ctx_preset;
|
||||
|
||||
server_presets presets;
|
||||
common_params base_params;
|
||||
std::string bin_path;
|
||||
std::vector<std::string> base_env;
|
||||
common_preset base_preset; // base preset from llama-server CLI args
|
||||
|
||||
void update_meta(const std::string & name, const server_model_meta & meta);
|
||||
|
||||
|
|
|
|||
|
|
@ -11,6 +11,8 @@ flowchart TB
|
|||
C_Screen["ChatScreen"]
|
||||
C_Form["ChatForm"]
|
||||
C_Messages["ChatMessages"]
|
||||
C_Message["ChatMessage"]
|
||||
C_MessageEditForm["ChatMessageEditForm"]
|
||||
C_ModelsSelector["ModelsSelector"]
|
||||
C_Settings["ChatSettings"]
|
||||
end
|
||||
|
|
@ -54,7 +56,9 @@ flowchart TB
|
|||
|
||||
%% Component hierarchy
|
||||
C_Screen --> C_Form & C_Messages & C_Settings
|
||||
C_Form & C_Messages --> C_ModelsSelector
|
||||
C_Messages --> C_Message
|
||||
C_Message --> C_MessageEditForm
|
||||
C_Form & C_MessageEditForm --> C_ModelsSelector
|
||||
|
||||
%% Components → Hooks → Stores
|
||||
C_Form & C_Messages --> H1 & H2
|
||||
|
|
@ -93,7 +97,7 @@ flowchart TB
|
|||
classDef apiStyle fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
|
||||
|
||||
class R1,R2,RL routeStyle
|
||||
class C_Sidebar,C_Screen,C_Form,C_Messages,C_ModelsSelector,C_Settings componentStyle
|
||||
class C_Sidebar,C_Screen,C_Form,C_Messages,C_Message,C_MessageEditForm,C_ModelsSelector,C_Settings componentStyle
|
||||
class H1,H2 hookStyle
|
||||
class S1,S2,S3,S4,S5 storeStyle
|
||||
class SV1,SV2,SV3,SV4,SV5 serviceStyle
|
||||
|
|
|
|||
|
|
@ -16,6 +16,8 @@ end
|
|||
C_Form["ChatForm"]
|
||||
C_Messages["ChatMessages"]
|
||||
C_Message["ChatMessage"]
|
||||
C_MessageUser["ChatMessageUser"]
|
||||
C_MessageEditForm["ChatMessageEditForm"]
|
||||
C_Attach["ChatAttachments"]
|
||||
C_ModelsSelector["ModelsSelector"]
|
||||
C_Settings["ChatSettings"]
|
||||
|
|
@ -38,7 +40,7 @@ end
|
|||
S1Error["<b>Error Handling:</b><br/>showErrorDialog()<br/>dismissErrorDialog()<br/>isAbortError()"]
|
||||
S1Msg["<b>Message Operations:</b><br/>addMessage()<br/>sendMessage()<br/>updateMessage()<br/>deleteMessage()<br/>getDeletionInfo()"]
|
||||
S1Regen["<b>Regeneration:</b><br/>regenerateMessage()<br/>regenerateMessageWithBranching()<br/>continueAssistantMessage()"]
|
||||
S1Edit["<b>Editing:</b><br/>editAssistantMessage()<br/>editUserMessagePreserveResponses()<br/>editMessageWithBranching()"]
|
||||
S1Edit["<b>Editing:</b><br/>editAssistantMessage()<br/>editUserMessagePreserveResponses()<br/>editMessageWithBranching()<br/>clearEditMode()<br/>isEditModeActive()<br/>getAddFilesHandler()<br/>setEditModeActive()"]
|
||||
S1Utils["<b>Utilities:</b><br/>getApiOptions()<br/>parseTimingData()<br/>getOrCreateAbortController()<br/>getConversationModel()"]
|
||||
end
|
||||
subgraph S2["conversationsStore"]
|
||||
|
|
@ -88,6 +90,10 @@ end
|
|||
RE7["getChatStreaming()"]
|
||||
RE8["getAllLoadingChats()"]
|
||||
RE9["getAllStreamingChats()"]
|
||||
RE9a["isEditModeActive()"]
|
||||
RE9b["getAddFilesHandler()"]
|
||||
RE9c["setEditModeActive()"]
|
||||
RE9d["clearEditMode()"]
|
||||
end
|
||||
subgraph ConvExports["conversationsStore"]
|
||||
RE10["conversations()"]
|
||||
|
|
@ -182,7 +188,10 @@ end
|
|||
%% Component hierarchy
|
||||
C_Screen --> C_Form & C_Messages & C_Settings
|
||||
C_Messages --> C_Message
|
||||
C_Message --> C_ModelsSelector
|
||||
C_Message --> C_MessageUser
|
||||
C_MessageUser --> C_MessageEditForm
|
||||
C_MessageEditForm --> C_ModelsSelector
|
||||
C_MessageEditForm --> C_Attach
|
||||
C_Form --> C_ModelsSelector
|
||||
C_Form --> C_Attach
|
||||
C_Message --> C_Attach
|
||||
|
|
@ -190,6 +199,7 @@ end
|
|||
%% Components use Hooks
|
||||
C_Form --> H1
|
||||
C_Message --> H1 & H2
|
||||
C_MessageEditForm --> H1
|
||||
C_Screen --> H2
|
||||
|
||||
%% Hooks use Stores
|
||||
|
|
@ -244,7 +254,7 @@ end
|
|||
classDef apiStyle fill:#e3f2fd,stroke:#1565c0,stroke-width:2px
|
||||
|
||||
class R1,R2,RL routeStyle
|
||||
class C_Sidebar,C_Screen,C_Form,C_Messages,C_Message componentStyle
|
||||
class C_Sidebar,C_Screen,C_Form,C_Messages,C_Message,C_MessageUser,C_MessageEditForm componentStyle
|
||||
class C_ModelsSelector,C_Settings componentStyle
|
||||
class C_Attach componentStyle
|
||||
class H1,H2,H3 methodStyle
|
||||
|
|
|
|||
|
|
@ -25,7 +25,7 @@
|
|||
"@chromatic-com/storybook": "^4.1.2",
|
||||
"@eslint/compat": "^1.2.5",
|
||||
"@eslint/js": "^9.18.0",
|
||||
"@internationalized/date": "^3.8.2",
|
||||
"@internationalized/date": "^3.10.1",
|
||||
"@lucide/svelte": "^0.515.0",
|
||||
"@playwright/test": "^1.49.1",
|
||||
"@storybook/addon-a11y": "^10.0.7",
|
||||
|
|
@ -862,9 +862,9 @@
|
|||
}
|
||||
},
|
||||
"node_modules/@internationalized/date": {
|
||||
"version": "3.8.2",
|
||||
"resolved": "https://registry.npmjs.org/@internationalized/date/-/date-3.8.2.tgz",
|
||||
"integrity": "sha512-/wENk7CbvLbkUvX1tu0mwq49CVkkWpkXubGel6birjRPyo6uQ4nQpnq5xZu823zRCwwn82zgHrvgF1vZyvmVgA==",
|
||||
"version": "3.10.1",
|
||||
"resolved": "https://registry.npmjs.org/@internationalized/date/-/date-3.10.1.tgz",
|
||||
"integrity": "sha512-oJrXtQiAXLvT9clCf1K4kxp3eKsQhIaZqxEyowkBcsvZDdZkbWrVmnGknxs5flTD0VGsxrxKgBCZty1EzoiMzA==",
|
||||
"dev": true,
|
||||
"license": "Apache-2.0",
|
||||
"dependencies": {
|
||||
|
|
|
|||
|
|
@ -26,7 +26,7 @@
|
|||
"@chromatic-com/storybook": "^4.1.2",
|
||||
"@eslint/compat": "^1.2.5",
|
||||
"@eslint/js": "^9.18.0",
|
||||
"@internationalized/date": "^3.8.2",
|
||||
"@internationalized/date": "^3.10.1",
|
||||
"@lucide/svelte": "^0.515.0",
|
||||
"@playwright/test": "^1.49.1",
|
||||
"@storybook/addon-a11y": "^10.0.7",
|
||||
|
|
|
|||
|
|
@ -8,6 +8,7 @@
|
|||
ChatFormTextarea
|
||||
} from '$lib/components/app';
|
||||
import { INPUT_CLASSES } from '$lib/constants/input-classes';
|
||||
import { SETTING_CONFIG_DEFAULT } from '$lib/constants/settings-config';
|
||||
import { config } from '$lib/stores/settings.svelte';
|
||||
import { modelsStore, modelOptions, selectedModelId } from '$lib/stores/models.svelte';
|
||||
import { isRouterMode } from '$lib/stores/server.svelte';
|
||||
|
|
@ -66,7 +67,7 @@
|
|||
let message = $state('');
|
||||
let pasteLongTextToFileLength = $derived.by(() => {
|
||||
const n = Number(currentConfig.pasteLongTextToFileLen);
|
||||
return Number.isNaN(n) ? 2500 : n;
|
||||
return Number.isNaN(n) ? Number(SETTING_CONFIG_DEFAULT.pasteLongTextToFileLen) : n;
|
||||
});
|
||||
let previousIsLoading = $state(isLoading);
|
||||
let recordingSupported = $state(false);
|
||||
|
|
|
|||
|
|
@ -12,13 +12,21 @@
|
|||
onCopy?: (message: DatabaseMessage) => void;
|
||||
onContinueAssistantMessage?: (message: DatabaseMessage) => void;
|
||||
onDelete?: (message: DatabaseMessage) => void;
|
||||
onEditWithBranching?: (message: DatabaseMessage, newContent: string) => void;
|
||||
onEditWithBranching?: (
|
||||
message: DatabaseMessage,
|
||||
newContent: string,
|
||||
newExtras?: DatabaseMessageExtra[]
|
||||
) => void;
|
||||
onEditWithReplacement?: (
|
||||
message: DatabaseMessage,
|
||||
newContent: string,
|
||||
shouldBranch: boolean
|
||||
) => void;
|
||||
onEditUserMessagePreserveResponses?: (message: DatabaseMessage, newContent: string) => void;
|
||||
onEditUserMessagePreserveResponses?: (
|
||||
message: DatabaseMessage,
|
||||
newContent: string,
|
||||
newExtras?: DatabaseMessageExtra[]
|
||||
) => void;
|
||||
onNavigateToSibling?: (siblingId: string) => void;
|
||||
onRegenerateWithBranching?: (message: DatabaseMessage, modelOverride?: string) => void;
|
||||
siblingInfo?: ChatMessageSiblingInfo | null;
|
||||
|
|
@ -45,6 +53,8 @@
|
|||
messageTypes: string[];
|
||||
} | null>(null);
|
||||
let editedContent = $state(message.content);
|
||||
let editedExtras = $state<DatabaseMessageExtra[]>(message.extra ? [...message.extra] : []);
|
||||
let editedUploadedFiles = $state<ChatUploadedFile[]>([]);
|
||||
let isEditing = $state(false);
|
||||
let showDeleteDialog = $state(false);
|
||||
let shouldBranchAfterEdit = $state(false);
|
||||
|
|
@ -85,6 +95,16 @@
|
|||
function handleCancelEdit() {
|
||||
isEditing = false;
|
||||
editedContent = message.content;
|
||||
editedExtras = message.extra ? [...message.extra] : [];
|
||||
editedUploadedFiles = [];
|
||||
}
|
||||
|
||||
function handleEditedExtrasChange(extras: DatabaseMessageExtra[]) {
|
||||
editedExtras = extras;
|
||||
}
|
||||
|
||||
function handleEditedUploadedFilesChange(files: ChatUploadedFile[]) {
|
||||
editedUploadedFiles = files;
|
||||
}
|
||||
|
||||
async function handleCopy() {
|
||||
|
|
@ -107,6 +127,8 @@
|
|||
function handleEdit() {
|
||||
isEditing = true;
|
||||
editedContent = message.content;
|
||||
editedExtras = message.extra ? [...message.extra] : [];
|
||||
editedUploadedFiles = [];
|
||||
|
||||
setTimeout(() => {
|
||||
if (textareaElement) {
|
||||
|
|
@ -143,9 +165,10 @@
|
|||
onContinueAssistantMessage?.(message);
|
||||
}
|
||||
|
||||
function handleSaveEdit() {
|
||||
async function handleSaveEdit() {
|
||||
if (message.role === 'user' || message.role === 'system') {
|
||||
onEditWithBranching?.(message, editedContent.trim());
|
||||
const finalExtras = await getMergedExtras();
|
||||
onEditWithBranching?.(message, editedContent.trim(), finalExtras);
|
||||
} else {
|
||||
// For assistant messages, preserve exact content including trailing whitespace
|
||||
// This is important for the Continue feature to work properly
|
||||
|
|
@ -154,15 +177,30 @@
|
|||
|
||||
isEditing = false;
|
||||
shouldBranchAfterEdit = false;
|
||||
editedUploadedFiles = [];
|
||||
}
|
||||
|
||||
function handleSaveEditOnly() {
|
||||
async function handleSaveEditOnly() {
|
||||
if (message.role === 'user') {
|
||||
// For user messages, trim to avoid accidental whitespace
|
||||
onEditUserMessagePreserveResponses?.(message, editedContent.trim());
|
||||
const finalExtras = await getMergedExtras();
|
||||
onEditUserMessagePreserveResponses?.(message, editedContent.trim(), finalExtras);
|
||||
}
|
||||
|
||||
isEditing = false;
|
||||
editedUploadedFiles = [];
|
||||
}
|
||||
|
||||
async function getMergedExtras(): Promise<DatabaseMessageExtra[]> {
|
||||
if (editedUploadedFiles.length === 0) {
|
||||
return editedExtras;
|
||||
}
|
||||
|
||||
const { parseFilesToMessageExtras } = await import('$lib/utils/browser-only');
|
||||
const result = await parseFilesToMessageExtras(editedUploadedFiles);
|
||||
const newExtras = result?.extras || [];
|
||||
|
||||
return [...editedExtras, ...newExtras];
|
||||
}
|
||||
|
||||
function handleShowDeleteDialogChange(show: boolean) {
|
||||
|
|
@ -197,6 +235,8 @@
|
|||
class={className}
|
||||
{deletionInfo}
|
||||
{editedContent}
|
||||
{editedExtras}
|
||||
{editedUploadedFiles}
|
||||
{isEditing}
|
||||
{message}
|
||||
onCancelEdit={handleCancelEdit}
|
||||
|
|
@ -206,6 +246,8 @@
|
|||
onEdit={handleEdit}
|
||||
onEditKeydown={handleEditKeydown}
|
||||
onEditedContentChange={handleEditedContentChange}
|
||||
onEditedExtrasChange={handleEditedExtrasChange}
|
||||
onEditedUploadedFilesChange={handleEditedUploadedFilesChange}
|
||||
{onNavigateToSibling}
|
||||
onSaveEdit={handleSaveEdit}
|
||||
onSaveEditOnly={handleSaveEditOnly}
|
||||
|
|
|
|||
|
|
@ -0,0 +1,391 @@
|
|||
<script lang="ts">
|
||||
import { X, ArrowUp, Paperclip, AlertTriangle } from '@lucide/svelte';
|
||||
import { Button } from '$lib/components/ui/button';
|
||||
import { Switch } from '$lib/components/ui/switch';
|
||||
import { ChatAttachmentsList, DialogConfirmation, ModelsSelector } from '$lib/components/app';
|
||||
import { INPUT_CLASSES } from '$lib/constants/input-classes';
|
||||
import { SETTING_CONFIG_DEFAULT } from '$lib/constants/settings-config';
|
||||
import { AttachmentType, FileTypeCategory, MimeTypeText } from '$lib/enums';
|
||||
import { config } from '$lib/stores/settings.svelte';
|
||||
import { useModelChangeValidation } from '$lib/hooks/use-model-change-validation.svelte';
|
||||
import { setEditModeActive, clearEditMode } from '$lib/stores/chat.svelte';
|
||||
import { conversationsStore } from '$lib/stores/conversations.svelte';
|
||||
import { modelsStore } from '$lib/stores/models.svelte';
|
||||
import { isRouterMode } from '$lib/stores/server.svelte';
|
||||
import {
|
||||
autoResizeTextarea,
|
||||
getFileTypeCategory,
|
||||
getFileTypeCategoryByExtension,
|
||||
parseClipboardContent
|
||||
} from '$lib/utils';
|
||||
|
||||
interface Props {
|
||||
messageId: string;
|
||||
editedContent: string;
|
||||
editedExtras?: DatabaseMessageExtra[];
|
||||
editedUploadedFiles?: ChatUploadedFile[];
|
||||
originalContent: string;
|
||||
originalExtras?: DatabaseMessageExtra[];
|
||||
showSaveOnlyOption?: boolean;
|
||||
onCancelEdit: () => void;
|
||||
onSaveEdit: () => void;
|
||||
onSaveEditOnly?: () => void;
|
||||
onEditKeydown: (event: KeyboardEvent) => void;
|
||||
onEditedContentChange: (content: string) => void;
|
||||
onEditedExtrasChange?: (extras: DatabaseMessageExtra[]) => void;
|
||||
onEditedUploadedFilesChange?: (files: ChatUploadedFile[]) => void;
|
||||
textareaElement?: HTMLTextAreaElement;
|
||||
}
|
||||
|
||||
let {
|
||||
messageId,
|
||||
editedContent,
|
||||
editedExtras = [],
|
||||
editedUploadedFiles = [],
|
||||
originalContent,
|
||||
originalExtras = [],
|
||||
showSaveOnlyOption = false,
|
||||
onCancelEdit,
|
||||
onSaveEdit,
|
||||
onSaveEditOnly,
|
||||
onEditKeydown,
|
||||
onEditedContentChange,
|
||||
onEditedExtrasChange,
|
||||
onEditedUploadedFilesChange,
|
||||
textareaElement = $bindable()
|
||||
}: Props = $props();
|
||||
|
||||
let fileInputElement: HTMLInputElement | undefined = $state();
|
||||
let saveWithoutRegenerate = $state(false);
|
||||
let showDiscardDialog = $state(false);
|
||||
let isRouter = $derived(isRouterMode());
|
||||
let currentConfig = $derived(config());
|
||||
|
||||
let pasteLongTextToFileLength = $derived.by(() => {
|
||||
const n = Number(currentConfig.pasteLongTextToFileLen);
|
||||
|
||||
return Number.isNaN(n) ? Number(SETTING_CONFIG_DEFAULT.pasteLongTextToFileLen) : n;
|
||||
});
|
||||
|
||||
let hasUnsavedChanges = $derived.by(() => {
|
||||
if (editedContent !== originalContent) return true;
|
||||
if (editedUploadedFiles.length > 0) return true;
|
||||
|
||||
const extrasChanged =
|
||||
editedExtras.length !== originalExtras.length ||
|
||||
editedExtras.some((extra, i) => extra !== originalExtras[i]);
|
||||
|
||||
if (extrasChanged) return true;
|
||||
|
||||
return false;
|
||||
});
|
||||
|
||||
let hasAttachments = $derived(
|
||||
(editedExtras && editedExtras.length > 0) ||
|
||||
(editedUploadedFiles && editedUploadedFiles.length > 0)
|
||||
);
|
||||
|
||||
let canSubmit = $derived(editedContent.trim().length > 0 || hasAttachments);
|
||||
|
||||
function getEditedAttachmentsModalities(): ModelModalities {
|
||||
const modalities: ModelModalities = { vision: false, audio: false };
|
||||
|
||||
for (const extra of editedExtras) {
|
||||
if (extra.type === AttachmentType.IMAGE) {
|
||||
modalities.vision = true;
|
||||
}
|
||||
|
||||
if (
|
||||
extra.type === AttachmentType.PDF &&
|
||||
'processedAsImages' in extra &&
|
||||
extra.processedAsImages
|
||||
) {
|
||||
modalities.vision = true;
|
||||
}
|
||||
|
||||
if (extra.type === AttachmentType.AUDIO) {
|
||||
modalities.audio = true;
|
||||
}
|
||||
}
|
||||
|
||||
for (const file of editedUploadedFiles) {
|
||||
const category = getFileTypeCategory(file.type) || getFileTypeCategoryByExtension(file.name);
|
||||
if (category === FileTypeCategory.IMAGE) {
|
||||
modalities.vision = true;
|
||||
}
|
||||
if (category === FileTypeCategory.AUDIO) {
|
||||
modalities.audio = true;
|
||||
}
|
||||
}
|
||||
|
||||
return modalities;
|
||||
}
|
||||
|
||||
function getRequiredModalities(): ModelModalities {
|
||||
const beforeModalities = conversationsStore.getModalitiesUpToMessage(messageId);
|
||||
const editedModalities = getEditedAttachmentsModalities();
|
||||
|
||||
return {
|
||||
vision: beforeModalities.vision || editedModalities.vision,
|
||||
audio: beforeModalities.audio || editedModalities.audio
|
||||
};
|
||||
}
|
||||
|
||||
const { handleModelChange } = useModelChangeValidation({
|
||||
getRequiredModalities,
|
||||
onValidationFailure: async (previousModelId) => {
|
||||
if (previousModelId) {
|
||||
await modelsStore.selectModelById(previousModelId);
|
||||
}
|
||||
}
|
||||
});
|
||||
|
||||
function handleFileInputChange(event: Event) {
|
||||
const input = event.target as HTMLInputElement;
|
||||
if (!input.files || input.files.length === 0) return;
|
||||
|
||||
const files = Array.from(input.files);
|
||||
|
||||
processNewFiles(files);
|
||||
input.value = '';
|
||||
}
|
||||
|
||||
function handleGlobalKeydown(event: KeyboardEvent) {
|
||||
if (event.key === 'Escape') {
|
||||
event.preventDefault();
|
||||
attemptCancel();
|
||||
}
|
||||
}
|
||||
|
||||
function attemptCancel() {
|
||||
if (hasUnsavedChanges) {
|
||||
showDiscardDialog = true;
|
||||
} else {
|
||||
onCancelEdit();
|
||||
}
|
||||
}
|
||||
|
||||
function handleRemoveExistingAttachment(index: number) {
|
||||
if (!onEditedExtrasChange) return;
|
||||
|
||||
const newExtras = [...editedExtras];
|
||||
|
||||
newExtras.splice(index, 1);
|
||||
onEditedExtrasChange(newExtras);
|
||||
}
|
||||
|
||||
function handleRemoveUploadedFile(fileId: string) {
|
||||
if (!onEditedUploadedFilesChange) return;
|
||||
|
||||
const newFiles = editedUploadedFiles.filter((f) => f.id !== fileId);
|
||||
|
||||
onEditedUploadedFilesChange(newFiles);
|
||||
}
|
||||
|
||||
function handleSubmit() {
|
||||
if (!canSubmit) return;
|
||||
|
||||
if (saveWithoutRegenerate && onSaveEditOnly) {
|
||||
onSaveEditOnly();
|
||||
} else {
|
||||
onSaveEdit();
|
||||
}
|
||||
|
||||
saveWithoutRegenerate = false;
|
||||
}
|
||||
|
||||
async function processNewFiles(files: File[]) {
|
||||
if (!onEditedUploadedFilesChange) return;
|
||||
|
||||
const { processFilesToChatUploaded } = await import('$lib/utils/browser-only');
|
||||
const processed = await processFilesToChatUploaded(files);
|
||||
|
||||
onEditedUploadedFilesChange([...editedUploadedFiles, ...processed]);
|
||||
}
|
||||
|
||||
function handlePaste(event: ClipboardEvent) {
|
||||
if (!event.clipboardData) return;
|
||||
|
||||
const files = Array.from(event.clipboardData.items)
|
||||
.filter((item) => item.kind === 'file')
|
||||
.map((item) => item.getAsFile())
|
||||
.filter((file): file is File => file !== null);
|
||||
|
||||
if (files.length > 0) {
|
||||
event.preventDefault();
|
||||
processNewFiles(files);
|
||||
|
||||
return;
|
||||
}
|
||||
|
||||
const text = event.clipboardData.getData(MimeTypeText.PLAIN);
|
||||
|
||||
if (text.startsWith('"')) {
|
||||
const parsed = parseClipboardContent(text);
|
||||
|
||||
if (parsed.textAttachments.length > 0) {
|
||||
event.preventDefault();
|
||||
onEditedContentChange(parsed.message);
|
||||
|
||||
const attachmentFiles = parsed.textAttachments.map(
|
||||
(att) =>
|
||||
new File([att.content], att.name, {
|
||||
type: MimeTypeText.PLAIN
|
||||
})
|
||||
);
|
||||
|
||||
processNewFiles(attachmentFiles);
|
||||
|
||||
setTimeout(() => {
|
||||
textareaElement?.focus();
|
||||
}, 10);
|
||||
|
||||
return;
|
||||
}
|
||||
}
|
||||
|
||||
if (
|
||||
text.length > 0 &&
|
||||
pasteLongTextToFileLength > 0 &&
|
||||
text.length > pasteLongTextToFileLength
|
||||
) {
|
||||
event.preventDefault();
|
||||
|
||||
const textFile = new File([text], 'Pasted', {
|
||||
type: MimeTypeText.PLAIN
|
||||
});
|
||||
|
||||
processNewFiles([textFile]);
|
||||
}
|
||||
}
|
||||
|
||||
$effect(() => {
|
||||
if (textareaElement) {
|
||||
autoResizeTextarea(textareaElement);
|
||||
}
|
||||
});
|
||||
|
||||
$effect(() => {
|
||||
setEditModeActive(processNewFiles);
|
||||
|
||||
return () => {
|
||||
clearEditMode();
|
||||
};
|
||||
});
|
||||
</script>
|
||||
|
||||
<svelte:window onkeydown={handleGlobalKeydown} />
|
||||
|
||||
<input
|
||||
bind:this={fileInputElement}
|
||||
type="file"
|
||||
multiple
|
||||
class="hidden"
|
||||
onchange={handleFileInputChange}
|
||||
/>
|
||||
|
||||
<div
|
||||
class="{INPUT_CLASSES} w-full max-w-[80%] overflow-hidden rounded-3xl backdrop-blur-md"
|
||||
data-slot="edit-form"
|
||||
>
|
||||
<ChatAttachmentsList
|
||||
attachments={editedExtras}
|
||||
uploadedFiles={editedUploadedFiles}
|
||||
readonly={false}
|
||||
onFileRemove={(fileId) => {
|
||||
if (fileId.startsWith('attachment-')) {
|
||||
const index = parseInt(fileId.replace('attachment-', ''), 10);
|
||||
if (!isNaN(index) && index >= 0 && index < editedExtras.length) {
|
||||
handleRemoveExistingAttachment(index);
|
||||
}
|
||||
} else {
|
||||
handleRemoveUploadedFile(fileId);
|
||||
}
|
||||
}}
|
||||
limitToSingleRow
|
||||
class="py-5"
|
||||
style="scroll-padding: 1rem;"
|
||||
/>
|
||||
|
||||
<div class="relative min-h-[48px] px-5 py-3">
|
||||
<textarea
|
||||
bind:this={textareaElement}
|
||||
bind:value={editedContent}
|
||||
class="field-sizing-content max-h-80 min-h-10 w-full resize-none bg-transparent text-sm outline-none"
|
||||
onkeydown={onEditKeydown}
|
||||
oninput={(e) => {
|
||||
autoResizeTextarea(e.currentTarget);
|
||||
onEditedContentChange(e.currentTarget.value);
|
||||
}}
|
||||
onpaste={handlePaste}
|
||||
placeholder="Edit your message..."
|
||||
></textarea>
|
||||
|
||||
<div class="flex w-full items-center gap-3" style="container-type: inline-size">
|
||||
<Button
|
||||
class="h-8 w-8 shrink-0 rounded-full bg-transparent p-0 text-muted-foreground hover:bg-foreground/10 hover:text-foreground"
|
||||
onclick={() => fileInputElement?.click()}
|
||||
type="button"
|
||||
title="Add attachment"
|
||||
>
|
||||
<span class="sr-only">Attach files</span>
|
||||
|
||||
<Paperclip class="h-4 w-4" />
|
||||
</Button>
|
||||
|
||||
<div class="flex-1"></div>
|
||||
|
||||
{#if isRouter}
|
||||
<ModelsSelector
|
||||
forceForegroundText={true}
|
||||
useGlobalSelection={true}
|
||||
onModelChange={handleModelChange}
|
||||
/>
|
||||
{/if}
|
||||
|
||||
<Button
|
||||
class="h-8 w-8 shrink-0 rounded-full p-0"
|
||||
onclick={handleSubmit}
|
||||
disabled={!canSubmit}
|
||||
type="button"
|
||||
title={saveWithoutRegenerate ? 'Save changes' : 'Send and regenerate'}
|
||||
>
|
||||
<span class="sr-only">{saveWithoutRegenerate ? 'Save' : 'Send'}</span>
|
||||
|
||||
<ArrowUp class="h-5 w-5" />
|
||||
</Button>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div class="mt-2 flex w-full max-w-[80%] items-center justify-between">
|
||||
{#if showSaveOnlyOption && onSaveEditOnly}
|
||||
<div class="flex items-center gap-2">
|
||||
<Switch id="save-only-switch" bind:checked={saveWithoutRegenerate} class="scale-75" />
|
||||
|
||||
<label for="save-only-switch" class="cursor-pointer text-xs text-muted-foreground">
|
||||
Update without re-sending
|
||||
</label>
|
||||
</div>
|
||||
{:else}
|
||||
<div></div>
|
||||
{/if}
|
||||
|
||||
<Button class="h-7 px-3 text-xs" onclick={attemptCancel} size="sm" variant="ghost">
|
||||
<X class="mr-1 h-3 w-3" />
|
||||
|
||||
Cancel
|
||||
</Button>
|
||||
</div>
|
||||
|
||||
<DialogConfirmation
|
||||
bind:open={showDiscardDialog}
|
||||
title="Discard changes?"
|
||||
description="You have unsaved changes. Are you sure you want to discard them?"
|
||||
confirmText="Discard"
|
||||
cancelText="Keep editing"
|
||||
variant="destructive"
|
||||
icon={AlertTriangle}
|
||||
onConfirm={onCancelEdit}
|
||||
onCancel={() => (showDiscardDialog = false)}
|
||||
/>
|
||||
|
|
@ -1,18 +1,17 @@
|
|||
<script lang="ts">
|
||||
import { Check, X, Send } from '@lucide/svelte';
|
||||
import { Card } from '$lib/components/ui/card';
|
||||
import { Button } from '$lib/components/ui/button';
|
||||
import { ChatAttachmentsList, MarkdownContent } from '$lib/components/app';
|
||||
import { INPUT_CLASSES } from '$lib/constants/input-classes';
|
||||
import { config } from '$lib/stores/settings.svelte';
|
||||
import { autoResizeTextarea } from '$lib/utils';
|
||||
import ChatMessageActions from './ChatMessageActions.svelte';
|
||||
import ChatMessageEditForm from './ChatMessageEditForm.svelte';
|
||||
|
||||
interface Props {
|
||||
class?: string;
|
||||
message: DatabaseMessage;
|
||||
isEditing: boolean;
|
||||
editedContent: string;
|
||||
editedExtras?: DatabaseMessageExtra[];
|
||||
editedUploadedFiles?: ChatUploadedFile[];
|
||||
siblingInfo?: ChatMessageSiblingInfo | null;
|
||||
showDeleteDialog: boolean;
|
||||
deletionInfo: {
|
||||
|
|
@ -26,6 +25,8 @@
|
|||
onSaveEditOnly?: () => void;
|
||||
onEditKeydown: (event: KeyboardEvent) => void;
|
||||
onEditedContentChange: (content: string) => void;
|
||||
onEditedExtrasChange?: (extras: DatabaseMessageExtra[]) => void;
|
||||
onEditedUploadedFilesChange?: (files: ChatUploadedFile[]) => void;
|
||||
onCopy: () => void;
|
||||
onEdit: () => void;
|
||||
onDelete: () => void;
|
||||
|
|
@ -40,6 +41,8 @@
|
|||
message,
|
||||
isEditing,
|
||||
editedContent,
|
||||
editedExtras = [],
|
||||
editedUploadedFiles = [],
|
||||
siblingInfo = null,
|
||||
showDeleteDialog,
|
||||
deletionInfo,
|
||||
|
|
@ -48,6 +51,8 @@
|
|||
onSaveEditOnly,
|
||||
onEditKeydown,
|
||||
onEditedContentChange,
|
||||
onEditedExtrasChange,
|
||||
onEditedUploadedFilesChange,
|
||||
onCopy,
|
||||
onEdit,
|
||||
onDelete,
|
||||
|
|
@ -61,12 +66,6 @@
|
|||
let messageElement: HTMLElement | undefined = $state();
|
||||
const currentConfig = config();
|
||||
|
||||
$effect(() => {
|
||||
if (isEditing && textareaElement) {
|
||||
autoResizeTextarea(textareaElement);
|
||||
}
|
||||
});
|
||||
|
||||
$effect(() => {
|
||||
if (!messageElement || !message.content.trim()) return;
|
||||
|
||||
|
|
@ -98,44 +97,23 @@
|
|||
role="group"
|
||||
>
|
||||
{#if isEditing}
|
||||
<div class="w-full max-w-[80%]">
|
||||
<textarea
|
||||
bind:this={textareaElement}
|
||||
bind:value={editedContent}
|
||||
class="min-h-[60px] w-full resize-none rounded-2xl px-3 py-2 text-sm {INPUT_CLASSES}"
|
||||
onkeydown={onEditKeydown}
|
||||
oninput={(e) => {
|
||||
autoResizeTextarea(e.currentTarget);
|
||||
onEditedContentChange(e.currentTarget.value);
|
||||
}}
|
||||
placeholder="Edit your message..."
|
||||
></textarea>
|
||||
|
||||
<div class="mt-2 flex justify-end gap-2">
|
||||
<Button class="h-8 px-3" onclick={onCancelEdit} size="sm" variant="ghost">
|
||||
<X class="mr-1 h-3 w-3" />
|
||||
Cancel
|
||||
</Button>
|
||||
|
||||
{#if onSaveEditOnly}
|
||||
<Button
|
||||
class="h-8 px-3"
|
||||
onclick={onSaveEditOnly}
|
||||
disabled={!editedContent.trim()}
|
||||
size="sm"
|
||||
variant="outline"
|
||||
>
|
||||
<Check class="mr-1 h-3 w-3" />
|
||||
Save
|
||||
</Button>
|
||||
{/if}
|
||||
|
||||
<Button class="h-8 px-3" onclick={onSaveEdit} disabled={!editedContent.trim()} size="sm">
|
||||
<Send class="mr-1 h-3 w-3" />
|
||||
Send
|
||||
</Button>
|
||||
</div>
|
||||
</div>
|
||||
<ChatMessageEditForm
|
||||
bind:textareaElement
|
||||
messageId={message.id}
|
||||
{editedContent}
|
||||
{editedExtras}
|
||||
{editedUploadedFiles}
|
||||
originalContent={message.content}
|
||||
originalExtras={message.extra}
|
||||
showSaveOnlyOption={!!onSaveEditOnly}
|
||||
{onCancelEdit}
|
||||
{onSaveEdit}
|
||||
{onSaveEditOnly}
|
||||
{onEditKeydown}
|
||||
{onEditedContentChange}
|
||||
{onEditedExtrasChange}
|
||||
{onEditedUploadedFilesChange}
|
||||
/>
|
||||
{:else}
|
||||
{#if message.extra && message.extra.length > 0}
|
||||
<div class="mb-2 max-w-[80%]">
|
||||
|
|
|
|||
|
|
@ -66,10 +66,14 @@
|
|||
await conversationsStore.navigateToSibling(siblingId);
|
||||
}
|
||||
|
||||
async function handleEditWithBranching(message: DatabaseMessage, newContent: string) {
|
||||
async function handleEditWithBranching(
|
||||
message: DatabaseMessage,
|
||||
newContent: string,
|
||||
newExtras?: DatabaseMessageExtra[]
|
||||
) {
|
||||
onUserAction?.();
|
||||
|
||||
await chatStore.editMessageWithBranching(message.id, newContent);
|
||||
await chatStore.editMessageWithBranching(message.id, newContent, newExtras);
|
||||
|
||||
refreshAllMessages();
|
||||
}
|
||||
|
|
@ -104,11 +108,12 @@
|
|||
|
||||
async function handleEditUserMessagePreserveResponses(
|
||||
message: DatabaseMessage,
|
||||
newContent: string
|
||||
newContent: string,
|
||||
newExtras?: DatabaseMessageExtra[]
|
||||
) {
|
||||
onUserAction?.();
|
||||
|
||||
await chatStore.editUserMessagePreserveResponses(message.id, newContent);
|
||||
await chatStore.editUserMessagePreserveResponses(message.id, newContent, newExtras);
|
||||
|
||||
refreshAllMessages();
|
||||
}
|
||||
|
|
|
|||
|
|
@ -17,7 +17,13 @@
|
|||
AUTO_SCROLL_INTERVAL,
|
||||
INITIAL_SCROLL_DELAY
|
||||
} from '$lib/constants/auto-scroll';
|
||||
import { chatStore, errorDialog, isLoading } from '$lib/stores/chat.svelte';
|
||||
import {
|
||||
chatStore,
|
||||
errorDialog,
|
||||
isLoading,
|
||||
isEditing,
|
||||
getAddFilesHandler
|
||||
} from '$lib/stores/chat.svelte';
|
||||
import {
|
||||
conversationsStore,
|
||||
activeMessages,
|
||||
|
|
@ -181,7 +187,18 @@
|
|||
dragCounter = 0;
|
||||
|
||||
if (event.dataTransfer?.files) {
|
||||
processFiles(Array.from(event.dataTransfer.files));
|
||||
const files = Array.from(event.dataTransfer.files);
|
||||
|
||||
if (isEditing()) {
|
||||
const handler = getAddFilesHandler();
|
||||
|
||||
if (handler) {
|
||||
handler(files);
|
||||
return;
|
||||
}
|
||||
}
|
||||
|
||||
processFiles(files);
|
||||
}
|
||||
}
|
||||
|
||||
|
|
@ -410,7 +427,7 @@
|
|||
|
||||
<div class="conversation-chat-form pointer-events-auto rounded-t-3xl pb-4">
|
||||
<ChatForm
|
||||
disabled={hasPropsError}
|
||||
disabled={hasPropsError || isEditing()}
|
||||
isLoading={isCurrentConversationLoading}
|
||||
onFileRemove={handleFileRemove}
|
||||
onFileUpload={handleFileUpload}
|
||||
|
|
|
|||
|
|
@ -0,0 +1,7 @@
|
|||
import Root from './switch.svelte';
|
||||
|
||||
export {
|
||||
Root,
|
||||
//
|
||||
Root as Switch
|
||||
};
|
||||
|
|
@ -0,0 +1,29 @@
|
|||
<script lang="ts">
|
||||
import { Switch as SwitchPrimitive } from 'bits-ui';
|
||||
import { cn, type WithoutChildrenOrChild } from '$lib/components/ui/utils.js';
|
||||
|
||||
let {
|
||||
ref = $bindable(null),
|
||||
class: className,
|
||||
checked = $bindable(false),
|
||||
...restProps
|
||||
}: WithoutChildrenOrChild<SwitchPrimitive.RootProps> = $props();
|
||||
</script>
|
||||
|
||||
<SwitchPrimitive.Root
|
||||
bind:ref
|
||||
bind:checked
|
||||
data-slot="switch"
|
||||
class={cn(
|
||||
'peer inline-flex h-[1.15rem] w-8 shrink-0 items-center rounded-full border border-transparent shadow-xs transition-all outline-none focus-visible:border-ring focus-visible:ring-[3px] focus-visible:ring-ring/50 disabled:cursor-not-allowed disabled:opacity-50 data-[state=checked]:bg-primary data-[state=unchecked]:bg-input dark:data-[state=unchecked]:bg-input/80',
|
||||
className
|
||||
)}
|
||||
{...restProps}
|
||||
>
|
||||
<SwitchPrimitive.Thumb
|
||||
data-slot="switch-thumb"
|
||||
class={cn(
|
||||
'pointer-events-none block size-4 rounded-full bg-background ring-0 transition-transform data-[state=checked]:translate-x-[calc(100%-2px)] data-[state=unchecked]:translate-x-0 dark:data-[state=checked]:bg-primary-foreground dark:data-[state=unchecked]:bg-foreground'
|
||||
)}
|
||||
/>
|
||||
</SwitchPrimitive.Root>
|
||||
|
|
@ -74,6 +74,8 @@ class ChatStore {
|
|||
private processingStates = new SvelteMap<string, ApiProcessingState | null>();
|
||||
private activeConversationId = $state<string | null>(null);
|
||||
private isStreamingActive = $state(false);
|
||||
private isEditModeActive = $state(false);
|
||||
private addFilesHandler: ((files: File[]) => void) | null = $state(null);
|
||||
|
||||
// ─────────────────────────────────────────────────────────────────────────────
|
||||
// Loading State
|
||||
|
|
@ -965,230 +967,9 @@ class ChatStore {
|
|||
// Editing
|
||||
// ─────────────────────────────────────────────────────────────────────────────
|
||||
|
||||
async editAssistantMessage(
|
||||
messageId: string,
|
||||
newContent: string,
|
||||
shouldBranch: boolean
|
||||
): Promise<void> {
|
||||
const activeConv = conversationsStore.activeConversation;
|
||||
if (!activeConv || this.isLoading) return;
|
||||
|
||||
const result = this.getMessageByIdWithRole(messageId, 'assistant');
|
||||
if (!result) return;
|
||||
const { message: msg, index: idx } = result;
|
||||
|
||||
try {
|
||||
if (shouldBranch) {
|
||||
const newMessage = await DatabaseService.createMessageBranch(
|
||||
{
|
||||
convId: msg.convId,
|
||||
type: msg.type,
|
||||
timestamp: Date.now(),
|
||||
role: msg.role,
|
||||
content: newContent,
|
||||
thinking: msg.thinking || '',
|
||||
toolCalls: msg.toolCalls || '',
|
||||
children: [],
|
||||
model: msg.model
|
||||
},
|
||||
msg.parent!
|
||||
);
|
||||
await conversationsStore.updateCurrentNode(newMessage.id);
|
||||
} else {
|
||||
await DatabaseService.updateMessage(msg.id, { content: newContent, timestamp: Date.now() });
|
||||
await conversationsStore.updateCurrentNode(msg.id);
|
||||
conversationsStore.updateMessageAtIndex(idx, {
|
||||
content: newContent,
|
||||
timestamp: Date.now()
|
||||
});
|
||||
}
|
||||
conversationsStore.updateConversationTimestamp();
|
||||
await conversationsStore.refreshActiveMessages();
|
||||
} catch (error) {
|
||||
console.error('Failed to edit assistant message:', error);
|
||||
}
|
||||
}
|
||||
|
||||
async editUserMessagePreserveResponses(messageId: string, newContent: string): Promise<void> {
|
||||
const activeConv = conversationsStore.activeConversation;
|
||||
if (!activeConv) return;
|
||||
|
||||
const result = this.getMessageByIdWithRole(messageId, 'user');
|
||||
if (!result) return;
|
||||
const { message: msg, index: idx } = result;
|
||||
|
||||
try {
|
||||
await DatabaseService.updateMessage(messageId, {
|
||||
content: newContent,
|
||||
timestamp: Date.now()
|
||||
});
|
||||
conversationsStore.updateMessageAtIndex(idx, { content: newContent, timestamp: Date.now() });
|
||||
|
||||
const allMessages = await conversationsStore.getConversationMessages(activeConv.id);
|
||||
const rootMessage = allMessages.find((m) => m.type === 'root' && m.parent === null);
|
||||
|
||||
if (rootMessage && msg.parent === rootMessage.id && newContent.trim()) {
|
||||
await conversationsStore.updateConversationTitleWithConfirmation(
|
||||
activeConv.id,
|
||||
newContent.trim(),
|
||||
conversationsStore.titleUpdateConfirmationCallback
|
||||
);
|
||||
}
|
||||
conversationsStore.updateConversationTimestamp();
|
||||
} catch (error) {
|
||||
console.error('Failed to edit user message:', error);
|
||||
}
|
||||
}
|
||||
|
||||
async editMessageWithBranching(messageId: string, newContent: string): Promise<void> {
|
||||
const activeConv = conversationsStore.activeConversation;
|
||||
if (!activeConv || this.isLoading) return;
|
||||
|
||||
let result = this.getMessageByIdWithRole(messageId, 'user');
|
||||
|
||||
if (!result) {
|
||||
result = this.getMessageByIdWithRole(messageId, 'system');
|
||||
}
|
||||
|
||||
if (!result) return;
|
||||
const { message: msg } = result;
|
||||
|
||||
try {
|
||||
const allMessages = await conversationsStore.getConversationMessages(activeConv.id);
|
||||
const rootMessage = allMessages.find((m) => m.type === 'root' && m.parent === null);
|
||||
const isFirstUserMessage =
|
||||
msg.role === 'user' && rootMessage && msg.parent === rootMessage.id;
|
||||
|
||||
const parentId = msg.parent || rootMessage?.id;
|
||||
if (!parentId) return;
|
||||
|
||||
const newMessage = await DatabaseService.createMessageBranch(
|
||||
{
|
||||
convId: msg.convId,
|
||||
type: msg.type,
|
||||
timestamp: Date.now(),
|
||||
role: msg.role,
|
||||
content: newContent,
|
||||
thinking: msg.thinking || '',
|
||||
toolCalls: msg.toolCalls || '',
|
||||
children: [],
|
||||
extra: msg.extra ? JSON.parse(JSON.stringify(msg.extra)) : undefined,
|
||||
model: msg.model
|
||||
},
|
||||
parentId
|
||||
);
|
||||
await conversationsStore.updateCurrentNode(newMessage.id);
|
||||
conversationsStore.updateConversationTimestamp();
|
||||
|
||||
if (isFirstUserMessage && newContent.trim()) {
|
||||
await conversationsStore.updateConversationTitleWithConfirmation(
|
||||
activeConv.id,
|
||||
newContent.trim(),
|
||||
conversationsStore.titleUpdateConfirmationCallback
|
||||
);
|
||||
}
|
||||
await conversationsStore.refreshActiveMessages();
|
||||
|
||||
if (msg.role === 'user') {
|
||||
await this.generateResponseForMessage(newMessage.id);
|
||||
}
|
||||
} catch (error) {
|
||||
console.error('Failed to edit message with branching:', error);
|
||||
}
|
||||
}
|
||||
|
||||
async regenerateMessageWithBranching(messageId: string, modelOverride?: string): Promise<void> {
|
||||
const activeConv = conversationsStore.activeConversation;
|
||||
if (!activeConv || this.isLoading) return;
|
||||
try {
|
||||
const idx = conversationsStore.findMessageIndex(messageId);
|
||||
if (idx === -1) return;
|
||||
const msg = conversationsStore.activeMessages[idx];
|
||||
if (msg.role !== 'assistant') return;
|
||||
|
||||
const allMessages = await conversationsStore.getConversationMessages(activeConv.id);
|
||||
const parentMessage = allMessages.find((m) => m.id === msg.parent);
|
||||
if (!parentMessage) return;
|
||||
|
||||
this.setChatLoading(activeConv.id, true);
|
||||
this.clearChatStreaming(activeConv.id);
|
||||
|
||||
const newAssistantMessage = await DatabaseService.createMessageBranch(
|
||||
{
|
||||
convId: activeConv.id,
|
||||
type: 'text',
|
||||
timestamp: Date.now(),
|
||||
role: 'assistant',
|
||||
content: '',
|
||||
thinking: '',
|
||||
toolCalls: '',
|
||||
children: [],
|
||||
model: null
|
||||
},
|
||||
parentMessage.id
|
||||
);
|
||||
await conversationsStore.updateCurrentNode(newAssistantMessage.id);
|
||||
conversationsStore.updateConversationTimestamp();
|
||||
await conversationsStore.refreshActiveMessages();
|
||||
|
||||
const conversationPath = filterByLeafNodeId(
|
||||
allMessages,
|
||||
parentMessage.id,
|
||||
false
|
||||
) as DatabaseMessage[];
|
||||
// Use modelOverride if provided, otherwise use the original message's model
|
||||
// If neither is available, don't pass model (will use global selection)
|
||||
const modelToUse = modelOverride || msg.model || undefined;
|
||||
await this.streamChatCompletion(
|
||||
conversationPath,
|
||||
newAssistantMessage,
|
||||
undefined,
|
||||
undefined,
|
||||
modelToUse
|
||||
);
|
||||
} catch (error) {
|
||||
if (!this.isAbortError(error))
|
||||
console.error('Failed to regenerate message with branching:', error);
|
||||
this.setChatLoading(activeConv?.id || '', false);
|
||||
}
|
||||
}
|
||||
|
||||
private async generateResponseForMessage(userMessageId: string): Promise<void> {
|
||||
const activeConv = conversationsStore.activeConversation;
|
||||
|
||||
if (!activeConv) return;
|
||||
|
||||
this.errorDialogState = null;
|
||||
this.setChatLoading(activeConv.id, true);
|
||||
this.clearChatStreaming(activeConv.id);
|
||||
|
||||
try {
|
||||
const allMessages = await conversationsStore.getConversationMessages(activeConv.id);
|
||||
const conversationPath = filterByLeafNodeId(
|
||||
allMessages,
|
||||
userMessageId,
|
||||
false
|
||||
) as DatabaseMessage[];
|
||||
const assistantMessage = await DatabaseService.createMessageBranch(
|
||||
{
|
||||
convId: activeConv.id,
|
||||
type: 'text',
|
||||
timestamp: Date.now(),
|
||||
role: 'assistant',
|
||||
content: '',
|
||||
thinking: '',
|
||||
toolCalls: '',
|
||||
children: [],
|
||||
model: null
|
||||
},
|
||||
userMessageId
|
||||
);
|
||||
conversationsStore.addMessageToActive(assistantMessage);
|
||||
await this.streamChatCompletion(conversationPath, assistantMessage);
|
||||
} catch (error) {
|
||||
console.error('Failed to generate response:', error);
|
||||
this.setChatLoading(activeConv.id, false);
|
||||
}
|
||||
clearEditMode(): void {
|
||||
this.isEditModeActive = false;
|
||||
this.addFilesHandler = null;
|
||||
}
|
||||
|
||||
async continueAssistantMessage(messageId: string): Promise<void> {
|
||||
|
|
@ -1340,19 +1121,284 @@ class ChatStore {
|
|||
}
|
||||
}
|
||||
|
||||
public isChatLoadingPublic(convId: string): boolean {
|
||||
return this.isChatLoading(convId);
|
||||
async editAssistantMessage(
|
||||
messageId: string,
|
||||
newContent: string,
|
||||
shouldBranch: boolean
|
||||
): Promise<void> {
|
||||
const activeConv = conversationsStore.activeConversation;
|
||||
if (!activeConv || this.isLoading) return;
|
||||
|
||||
const result = this.getMessageByIdWithRole(messageId, 'assistant');
|
||||
if (!result) return;
|
||||
const { message: msg, index: idx } = result;
|
||||
|
||||
try {
|
||||
if (shouldBranch) {
|
||||
const newMessage = await DatabaseService.createMessageBranch(
|
||||
{
|
||||
convId: msg.convId,
|
||||
type: msg.type,
|
||||
timestamp: Date.now(),
|
||||
role: msg.role,
|
||||
content: newContent,
|
||||
thinking: msg.thinking || '',
|
||||
toolCalls: msg.toolCalls || '',
|
||||
children: [],
|
||||
model: msg.model
|
||||
},
|
||||
msg.parent!
|
||||
);
|
||||
await conversationsStore.updateCurrentNode(newMessage.id);
|
||||
} else {
|
||||
await DatabaseService.updateMessage(msg.id, { content: newContent });
|
||||
await conversationsStore.updateCurrentNode(msg.id);
|
||||
conversationsStore.updateMessageAtIndex(idx, {
|
||||
content: newContent
|
||||
});
|
||||
}
|
||||
conversationsStore.updateConversationTimestamp();
|
||||
await conversationsStore.refreshActiveMessages();
|
||||
} catch (error) {
|
||||
console.error('Failed to edit assistant message:', error);
|
||||
}
|
||||
}
|
||||
|
||||
async editUserMessagePreserveResponses(
|
||||
messageId: string,
|
||||
newContent: string,
|
||||
newExtras?: DatabaseMessageExtra[]
|
||||
): Promise<void> {
|
||||
const activeConv = conversationsStore.activeConversation;
|
||||
if (!activeConv) return;
|
||||
|
||||
const result = this.getMessageByIdWithRole(messageId, 'user');
|
||||
if (!result) return;
|
||||
const { message: msg, index: idx } = result;
|
||||
|
||||
try {
|
||||
const updateData: Partial<DatabaseMessage> = {
|
||||
content: newContent
|
||||
};
|
||||
|
||||
// Update extras if provided (including empty array to clear attachments)
|
||||
// Deep clone to avoid Proxy objects from Svelte reactivity
|
||||
if (newExtras !== undefined) {
|
||||
updateData.extra = JSON.parse(JSON.stringify(newExtras));
|
||||
}
|
||||
|
||||
await DatabaseService.updateMessage(messageId, updateData);
|
||||
conversationsStore.updateMessageAtIndex(idx, updateData);
|
||||
|
||||
const allMessages = await conversationsStore.getConversationMessages(activeConv.id);
|
||||
const rootMessage = allMessages.find((m) => m.type === 'root' && m.parent === null);
|
||||
|
||||
if (rootMessage && msg.parent === rootMessage.id && newContent.trim()) {
|
||||
await conversationsStore.updateConversationTitleWithConfirmation(
|
||||
activeConv.id,
|
||||
newContent.trim(),
|
||||
conversationsStore.titleUpdateConfirmationCallback
|
||||
);
|
||||
}
|
||||
conversationsStore.updateConversationTimestamp();
|
||||
} catch (error) {
|
||||
console.error('Failed to edit user message:', error);
|
||||
}
|
||||
}
|
||||
|
||||
async editMessageWithBranching(
|
||||
messageId: string,
|
||||
newContent: string,
|
||||
newExtras?: DatabaseMessageExtra[]
|
||||
): Promise<void> {
|
||||
const activeConv = conversationsStore.activeConversation;
|
||||
if (!activeConv || this.isLoading) return;
|
||||
|
||||
let result = this.getMessageByIdWithRole(messageId, 'user');
|
||||
|
||||
if (!result) {
|
||||
result = this.getMessageByIdWithRole(messageId, 'system');
|
||||
}
|
||||
|
||||
if (!result) return;
|
||||
const { message: msg } = result;
|
||||
|
||||
try {
|
||||
const allMessages = await conversationsStore.getConversationMessages(activeConv.id);
|
||||
const rootMessage = allMessages.find((m) => m.type === 'root' && m.parent === null);
|
||||
const isFirstUserMessage =
|
||||
msg.role === 'user' && rootMessage && msg.parent === rootMessage.id;
|
||||
|
||||
const parentId = msg.parent || rootMessage?.id;
|
||||
if (!parentId) return;
|
||||
|
||||
// Use newExtras if provided, otherwise copy existing extras
|
||||
// Deep clone to avoid Proxy objects from Svelte reactivity
|
||||
const extrasToUse =
|
||||
newExtras !== undefined
|
||||
? JSON.parse(JSON.stringify(newExtras))
|
||||
: msg.extra
|
||||
? JSON.parse(JSON.stringify(msg.extra))
|
||||
: undefined;
|
||||
|
||||
const newMessage = await DatabaseService.createMessageBranch(
|
||||
{
|
||||
convId: msg.convId,
|
||||
type: msg.type,
|
||||
timestamp: Date.now(),
|
||||
role: msg.role,
|
||||
content: newContent,
|
||||
thinking: msg.thinking || '',
|
||||
toolCalls: msg.toolCalls || '',
|
||||
children: [],
|
||||
extra: extrasToUse,
|
||||
model: msg.model
|
||||
},
|
||||
parentId
|
||||
);
|
||||
await conversationsStore.updateCurrentNode(newMessage.id);
|
||||
conversationsStore.updateConversationTimestamp();
|
||||
|
||||
if (isFirstUserMessage && newContent.trim()) {
|
||||
await conversationsStore.updateConversationTitleWithConfirmation(
|
||||
activeConv.id,
|
||||
newContent.trim(),
|
||||
conversationsStore.titleUpdateConfirmationCallback
|
||||
);
|
||||
}
|
||||
await conversationsStore.refreshActiveMessages();
|
||||
|
||||
if (msg.role === 'user') {
|
||||
await this.generateResponseForMessage(newMessage.id);
|
||||
}
|
||||
} catch (error) {
|
||||
console.error('Failed to edit message with branching:', error);
|
||||
}
|
||||
}
|
||||
|
||||
async regenerateMessageWithBranching(messageId: string, modelOverride?: string): Promise<void> {
|
||||
const activeConv = conversationsStore.activeConversation;
|
||||
if (!activeConv || this.isLoading) return;
|
||||
try {
|
||||
const idx = conversationsStore.findMessageIndex(messageId);
|
||||
if (idx === -1) return;
|
||||
const msg = conversationsStore.activeMessages[idx];
|
||||
if (msg.role !== 'assistant') return;
|
||||
|
||||
const allMessages = await conversationsStore.getConversationMessages(activeConv.id);
|
||||
const parentMessage = allMessages.find((m) => m.id === msg.parent);
|
||||
if (!parentMessage) return;
|
||||
|
||||
this.setChatLoading(activeConv.id, true);
|
||||
this.clearChatStreaming(activeConv.id);
|
||||
|
||||
const newAssistantMessage = await DatabaseService.createMessageBranch(
|
||||
{
|
||||
convId: activeConv.id,
|
||||
type: 'text',
|
||||
timestamp: Date.now(),
|
||||
role: 'assistant',
|
||||
content: '',
|
||||
thinking: '',
|
||||
toolCalls: '',
|
||||
children: [],
|
||||
model: null
|
||||
},
|
||||
parentMessage.id
|
||||
);
|
||||
await conversationsStore.updateCurrentNode(newAssistantMessage.id);
|
||||
conversationsStore.updateConversationTimestamp();
|
||||
await conversationsStore.refreshActiveMessages();
|
||||
|
||||
const conversationPath = filterByLeafNodeId(
|
||||
allMessages,
|
||||
parentMessage.id,
|
||||
false
|
||||
) as DatabaseMessage[];
|
||||
// Use modelOverride if provided, otherwise use the original message's model
|
||||
// If neither is available, don't pass model (will use global selection)
|
||||
const modelToUse = modelOverride || msg.model || undefined;
|
||||
await this.streamChatCompletion(
|
||||
conversationPath,
|
||||
newAssistantMessage,
|
||||
undefined,
|
||||
undefined,
|
||||
modelToUse
|
||||
);
|
||||
} catch (error) {
|
||||
if (!this.isAbortError(error))
|
||||
console.error('Failed to regenerate message with branching:', error);
|
||||
this.setChatLoading(activeConv?.id || '', false);
|
||||
}
|
||||
}
|
||||
|
||||
private async generateResponseForMessage(userMessageId: string): Promise<void> {
|
||||
const activeConv = conversationsStore.activeConversation;
|
||||
|
||||
if (!activeConv) return;
|
||||
|
||||
this.errorDialogState = null;
|
||||
this.setChatLoading(activeConv.id, true);
|
||||
this.clearChatStreaming(activeConv.id);
|
||||
|
||||
try {
|
||||
const allMessages = await conversationsStore.getConversationMessages(activeConv.id);
|
||||
const conversationPath = filterByLeafNodeId(
|
||||
allMessages,
|
||||
userMessageId,
|
||||
false
|
||||
) as DatabaseMessage[];
|
||||
const assistantMessage = await DatabaseService.createMessageBranch(
|
||||
{
|
||||
convId: activeConv.id,
|
||||
type: 'text',
|
||||
timestamp: Date.now(),
|
||||
role: 'assistant',
|
||||
content: '',
|
||||
thinking: '',
|
||||
toolCalls: '',
|
||||
children: [],
|
||||
model: null
|
||||
},
|
||||
userMessageId
|
||||
);
|
||||
conversationsStore.addMessageToActive(assistantMessage);
|
||||
await this.streamChatCompletion(conversationPath, assistantMessage);
|
||||
} catch (error) {
|
||||
console.error('Failed to generate response:', error);
|
||||
this.setChatLoading(activeConv.id, false);
|
||||
}
|
||||
}
|
||||
|
||||
getAddFilesHandler(): ((files: File[]) => void) | null {
|
||||
return this.addFilesHandler;
|
||||
}
|
||||
|
||||
public getAllLoadingChats(): string[] {
|
||||
return Array.from(this.chatLoadingStates.keys());
|
||||
}
|
||||
|
||||
public getAllStreamingChats(): string[] {
|
||||
return Array.from(this.chatStreamingStates.keys());
|
||||
}
|
||||
|
||||
public getChatStreamingPublic(
|
||||
convId: string
|
||||
): { response: string; messageId: string } | undefined {
|
||||
return this.getChatStreaming(convId);
|
||||
}
|
||||
public getAllLoadingChats(): string[] {
|
||||
return Array.from(this.chatLoadingStates.keys());
|
||||
|
||||
public isChatLoadingPublic(convId: string): boolean {
|
||||
return this.isChatLoading(convId);
|
||||
}
|
||||
public getAllStreamingChats(): string[] {
|
||||
return Array.from(this.chatStreamingStates.keys());
|
||||
|
||||
isEditing(): boolean {
|
||||
return this.isEditModeActive;
|
||||
}
|
||||
|
||||
setEditModeActive(handler: (files: File[]) => void): void {
|
||||
this.isEditModeActive = true;
|
||||
this.addFilesHandler = handler;
|
||||
}
|
||||
|
||||
// ─────────────────────────────────────────────────────────────────────────────
|
||||
|
|
@ -1416,13 +1462,17 @@ class ChatStore {
|
|||
|
||||
export const chatStore = new ChatStore();
|
||||
|
||||
export const isLoading = () => chatStore.isLoading;
|
||||
export const activeProcessingState = () => chatStore.activeProcessingState;
|
||||
export const clearEditMode = () => chatStore.clearEditMode();
|
||||
export const currentResponse = () => chatStore.currentResponse;
|
||||
export const errorDialog = () => chatStore.errorDialogState;
|
||||
export const activeProcessingState = () => chatStore.activeProcessingState;
|
||||
export const isChatStreaming = () => chatStore.isStreaming();
|
||||
|
||||
export const isChatLoading = (convId: string) => chatStore.isChatLoadingPublic(convId);
|
||||
export const getChatStreaming = (convId: string) => chatStore.getChatStreamingPublic(convId);
|
||||
export const getAddFilesHandler = () => chatStore.getAddFilesHandler();
|
||||
export const getAllLoadingChats = () => chatStore.getAllLoadingChats();
|
||||
export const getAllStreamingChats = () => chatStore.getAllStreamingChats();
|
||||
export const getChatStreaming = (convId: string) => chatStore.getChatStreamingPublic(convId);
|
||||
export const isChatLoading = (convId: string) => chatStore.isChatLoadingPublic(convId);
|
||||
export const isChatStreaming = () => chatStore.isStreaming();
|
||||
export const isEditing = () => chatStore.isEditing();
|
||||
export const isLoading = () => chatStore.isLoading;
|
||||
export const setEditModeActive = (handler: (files: File[]) => void) =>
|
||||
chatStore.setEditModeActive(handler);
|
||||
|
|
|
|||
Loading…
Reference in New Issue