Merge branch 'ggml-org:master' into i8mm-ci
This commit is contained in:
commit
df807bda00
|
|
@ -107,7 +107,7 @@ ENTRYPOINT ["/app/tools.sh"]
|
|||
# ENTRYPOINT ["/app/llama-server"]
|
||||
|
||||
### Target: light
|
||||
# Lightweight image containing only llama-cli
|
||||
# Lightweight image containing only llama-cli and llama-completion
|
||||
# ==============================================================================
|
||||
FROM base AS light
|
||||
|
||||
|
|
|
|||
|
|
@ -23,11 +23,12 @@ ENV LD_LIBRARY_PATH=${ASCEND_TOOLKIT_HOME}/runtime/lib64/stub:$LD_LIBRARY_PATH
|
|||
RUN echo "Building with static libs" && \
|
||||
source /usr/local/Ascend/ascend-toolkit/set_env.sh --force && \
|
||||
cmake -B build -DGGML_NATIVE=OFF -DGGML_CANN=ON -DBUILD_SHARED_LIBS=OFF -DLLAMA_BUILD_TESTS=OFF && \
|
||||
cmake --build build --config Release --target llama-cli
|
||||
cmake --build build --config Release --target llama-cli && \
|
||||
cmake --build build --config Release --target llama-completion
|
||||
|
||||
# TODO: use image with NNRT
|
||||
FROM ascendai/cann:$ASCEND_VERSION AS runtime
|
||||
COPY --from=build /app/build/bin/llama-cli /llama-cli
|
||||
COPY --from=build /app/build/bin/llama-cli /app/build/bin/llama-completion /
|
||||
|
||||
ENV LC_ALL=C.utf8
|
||||
|
||||
|
|
|
|||
|
|
@ -37,6 +37,7 @@ make -j GGML_CUDA=1
|
|||
%install
|
||||
mkdir -p %{buildroot}%{_bindir}/
|
||||
cp -p llama-cli %{buildroot}%{_bindir}/llama-cuda-cli
|
||||
cp -p llama-completion %{buildroot}%{_bindir}/llama-cuda-completion
|
||||
cp -p llama-server %{buildroot}%{_bindir}/llama-cuda-server
|
||||
cp -p llama-simple %{buildroot}%{_bindir}/llama-cuda-simple
|
||||
|
||||
|
|
@ -68,6 +69,7 @@ rm -rf %{_builddir}/*
|
|||
|
||||
%files
|
||||
%{_bindir}/llama-cuda-cli
|
||||
%{_bindir}/llama-cuda-completion
|
||||
%{_bindir}/llama-cuda-server
|
||||
%{_bindir}/llama-cuda-simple
|
||||
/usr/lib/systemd/system/llamacuda.service
|
||||
|
|
|
|||
|
|
@ -39,6 +39,7 @@ make -j
|
|||
%install
|
||||
mkdir -p %{buildroot}%{_bindir}/
|
||||
cp -p llama-cli %{buildroot}%{_bindir}/llama-cli
|
||||
cp -p llama-completion %{buildroot}%{_bindir}/llama-completion
|
||||
cp -p llama-server %{buildroot}%{_bindir}/llama-server
|
||||
cp -p llama-simple %{buildroot}%{_bindir}/llama-simple
|
||||
|
||||
|
|
@ -70,6 +71,7 @@ rm -rf %{_builddir}/*
|
|||
|
||||
%files
|
||||
%{_bindir}/llama-cli
|
||||
%{_bindir}/llama-completion
|
||||
%{_bindir}/llama-server
|
||||
%{_bindir}/llama-simple
|
||||
/usr/lib/systemd/system/llama.service
|
||||
|
|
|
|||
|
|
@ -86,6 +86,7 @@ body:
|
|||
description: >
|
||||
If applicable, please copy and paste any relevant log output, including any generated text.
|
||||
This will be automatically formatted into code, so no need for backticks.
|
||||
If you are encountering problems specifically with the `llama_params_fit` module, always upload `--verbose` logs as well.
|
||||
render: shell
|
||||
validations:
|
||||
required: false
|
||||
|
|
|
|||
|
|
@ -70,6 +70,7 @@ jobs:
|
|||
with:
|
||||
key: macOS-latest-cmake-arm64
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
|
|
@ -106,6 +107,7 @@ jobs:
|
|||
with:
|
||||
key: macOS-latest-cmake-x64
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
|
|
@ -142,6 +144,7 @@ jobs:
|
|||
with:
|
||||
key: macOS-latest-cmake-arm64-webgpu
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dawn Dependency
|
||||
id: dawn-depends
|
||||
|
|
@ -195,6 +198,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-cpu-cmake-${{ matrix.build }}
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build Dependencies
|
||||
id: build_depends
|
||||
|
|
@ -276,6 +280,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-latest-cmake-sanitizer-${{ matrix.sanitizer }}
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -396,6 +401,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-24-cmake-vulkan-deb
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -431,6 +437,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-24-cmake-vulkan
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -490,6 +497,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-24-cmake-webgpu
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -562,6 +570,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-latest-wasm-webgpu
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Install Emscripten
|
||||
run: |
|
||||
|
|
@ -609,6 +618,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-22-cmake-hip
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build with native CMake HIP support
|
||||
id: cmake_build
|
||||
|
|
@ -641,6 +651,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-22-cmake-musa
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build with native CMake MUSA support
|
||||
id: cmake_build
|
||||
|
|
@ -688,6 +699,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-22-cmake-sycl
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
|
|
@ -738,6 +750,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-22-cmake-sycl-fp16
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
|
|
@ -771,6 +784,7 @@ jobs:
|
|||
with:
|
||||
key: macOS-latest-cmake-ios
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
|
|
@ -802,6 +816,7 @@ jobs:
|
|||
with:
|
||||
key: macOS-latest-cmake-tvos
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
|
|
@ -863,6 +878,7 @@ jobs:
|
|||
with:
|
||||
key: macOS-latest-swift
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Download xcframework artifact
|
||||
uses: actions/download-artifact@v4
|
||||
|
|
@ -905,6 +921,7 @@ jobs:
|
|||
key: windows-msys2
|
||||
variant: ccache
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Setup ${{ matrix.sys }}
|
||||
uses: msys2/setup-msys2@v2
|
||||
|
|
@ -973,6 +990,7 @@ jobs:
|
|||
key: windows-latest-cmake-${{ matrix.build }}
|
||||
variant: ccache
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Download OpenBLAS
|
||||
id: get_openblas
|
||||
|
|
@ -1077,6 +1095,7 @@ jobs:
|
|||
with:
|
||||
key: ubuntu-latest-cmake-cuda
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build with CMake
|
||||
run: |
|
||||
|
|
@ -1109,6 +1128,7 @@ jobs:
|
|||
key: windows-cuda-${{ matrix.cuda }}
|
||||
variant: ccache
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Install Cuda Toolkit
|
||||
uses: ./.github/actions/windows-setup-cuda
|
||||
|
|
@ -1160,6 +1180,7 @@ jobs:
|
|||
key: windows-latest-cmake-sycl
|
||||
variant: ccache
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Install
|
||||
run: |
|
||||
|
|
@ -1221,6 +1242,7 @@ jobs:
|
|||
with:
|
||||
key: ${{ github.job }}
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Build
|
||||
id: cmake_build
|
||||
|
|
@ -1466,6 +1488,7 @@ jobs:
|
|||
with:
|
||||
key: ggml-ci-x64-cpu-low-perf
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -1491,6 +1514,7 @@ jobs:
|
|||
with:
|
||||
key: ggml-ci-arm64-cpu-low-perf
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -1516,6 +1540,7 @@ jobs:
|
|||
with:
|
||||
key: ggml-ci-x64-cpu-high-perf
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -1541,6 +1566,7 @@ jobs:
|
|||
with:
|
||||
key: ggml-ci-arm64-cpu-high-perf
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -1566,6 +1592,7 @@ jobs:
|
|||
with:
|
||||
key: ggml-ci-arm64-cpu-high-perf-sve
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -1701,6 +1728,7 @@ jobs:
|
|||
with:
|
||||
key: ggml-ci-arm64-cpu-kleidiai
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
|
|
@ -2084,6 +2112,7 @@ jobs:
|
|||
with:
|
||||
key: ggml-ci-arm64-graviton4-kleidiai
|
||||
evict-old-files: 1d
|
||||
save: ${{ github.event_name == 'push' && github.ref == 'refs/heads/master' }}
|
||||
|
||||
- name: Test
|
||||
id: ggml-ci
|
||||
|
|
|
|||
|
|
@ -66,16 +66,9 @@ jobs:
|
|||
id: pack_artifacts
|
||||
run: |
|
||||
cp LICENSE ./build/bin/
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-bin-macos-arm64.zip ./build/bin/*
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-macos-arm64.tar.gz -s ",./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-macos-arm64.zip
|
||||
name: llama-bin-macos-arm64.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-macos-arm64.tar.gz
|
||||
|
|
@ -127,16 +120,9 @@ jobs:
|
|||
id: pack_artifacts
|
||||
run: |
|
||||
cp LICENSE ./build/bin/
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-bin-macos-x64.zip ./build/bin/*
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-macos-x64.tar.gz -s ",./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-macos-x64.zip
|
||||
name: llama-bin-macos-x64.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-macos-x64.tar.gz
|
||||
|
|
@ -196,16 +182,9 @@ jobs:
|
|||
id: pack_artifacts
|
||||
run: |
|
||||
cp LICENSE ./build/bin/
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-bin-ubuntu-${{ matrix.build }}.zip ./build/bin/*
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-ubuntu-${{ matrix.build }}.tar.gz --transform "s,./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-ubuntu-${{ matrix.build }}.zip
|
||||
name: llama-bin-ubuntu-${{ matrix.build }}.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-ubuntu-${{ matrix.build }}.tar.gz
|
||||
|
|
@ -256,16 +235,9 @@ jobs:
|
|||
id: pack_artifacts
|
||||
run: |
|
||||
cp LICENSE ./build/bin/
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-bin-ubuntu-vulkan-x64.zip ./build/bin/*
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-ubuntu-vulkan-x64.tar.gz --transform "s,./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-ubuntu-vulkan-x64.zip
|
||||
name: llama-bin-ubuntu-vulkan-x64.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-ubuntu-vulkan-x64.tar.gz
|
||||
|
|
@ -716,21 +688,16 @@ jobs:
|
|||
- name: Pack artifacts
|
||||
id: pack_artifacts
|
||||
run: |
|
||||
zip -y -r llama-${{ steps.tag.outputs.name }}-xcframework.zip build-apple/llama.xcframework
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-xcframework.tar.gz -C build-apple llama.xcframework
|
||||
# Zip file is required for Swift Package Manager, which does not support tar.gz for binary targets.
|
||||
# For more details, see https://developer.apple.com/documentation/xcode/distributing-binary-frameworks-as-swift-packages
|
||||
zip -r -y llama-${{ steps.tag.outputs.name }}-xcframework.zip build-apple/llama.xcframework
|
||||
|
||||
- name: Upload artifacts (zip)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-xcframework.zip
|
||||
name: llama-${{ steps.tag.outputs.name }}-xcframework.zip
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-xcframework.tar.gz
|
||||
name: llama-${{ steps.tag.outputs.name }}-xcframework.tar.gz
|
||||
|
||||
|
||||
openEuler-cann:
|
||||
strategy:
|
||||
|
|
@ -797,7 +764,7 @@ jobs:
|
|||
cp LICENSE ./build/bin/
|
||||
tar -czvf llama-${{ steps.tag.outputs.name }}-bin-${{ matrix.chip_type }}-openEuler-${{ matrix.arch }}.tar.gz --transform "s,./,llama-${{ steps.tag.outputs.name }}/," -C ./build/bin .
|
||||
|
||||
- name: Upload artifacts (tar)
|
||||
- name: Upload artifacts
|
||||
uses: actions/upload-artifact@v4
|
||||
with:
|
||||
path: llama-${{ steps.tag.outputs.name }}-bin-${{ matrix.chip_type }}-openEuler-${{ matrix.arch }}.tar.gz
|
||||
|
|
@ -889,9 +856,6 @@ jobs:
|
|||
with:
|
||||
tag_name: ${{ steps.tag.outputs.name }}
|
||||
body: |
|
||||
> [!WARNING]
|
||||
> **Release Format Update**: Linux releases will soon use .tar.gz archives instead of .zip. Please make the necessary changes to your deployment scripts.
|
||||
|
||||
<details open>
|
||||
|
||||
${{ github.event.head_commit.message }}
|
||||
|
|
@ -901,7 +865,7 @@ jobs:
|
|||
**macOS/iOS:**
|
||||
- [macOS Apple Silicon (arm64)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-macos-arm64.tar.gz)
|
||||
- [macOS Intel (x64)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-macos-x64.tar.gz)
|
||||
- [iOS XCFramework](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-xcframework.tar.gz)
|
||||
- [iOS XCFramework](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-xcframework.zip)
|
||||
|
||||
**Linux:**
|
||||
- [Ubuntu x64 (CPU)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-ubuntu-x64.tar.gz)
|
||||
|
|
@ -911,8 +875,8 @@ jobs:
|
|||
**Windows:**
|
||||
- [Windows x64 (CPU)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cpu-x64.zip)
|
||||
- [Windows arm64 (CPU)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cpu-arm64.zip)
|
||||
- [Windows x64 (CUDA 12)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cuda-12.4-x64.zip)
|
||||
- [Windows x64 (CUDA 13)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cuda-13.1-x64.zip)
|
||||
- [Windows x64 (CUDA 12)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cuda-12.4-x64.zip) - [CUDA 12.4 DLLs](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/cudart-llama-bin-win-cuda-12.4-x64.zip)
|
||||
- [Windows x64 (CUDA 13)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-cuda-13.1-x64.zip) - [CUDA 13.1 DLLs](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/cudart-llama-bin-win-cuda-13.1-x64.zip)
|
||||
- [Windows x64 (Vulkan)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-vulkan-x64.zip)
|
||||
- [Windows x64 (SYCL)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-sycl-x64.zip)
|
||||
- [Windows x64 (HIP)](https://github.com/ggml-org/llama.cpp/releases/download/${{ steps.tag.outputs.name }}/llama-${{ steps.tag.outputs.name }}-bin-win-hip-radeon-x64.zip)
|
||||
|
|
|
|||
|
|
@ -0,0 +1,225 @@
|
|||
# Server WebUI build and tests
|
||||
name: Server WebUI
|
||||
|
||||
on:
|
||||
workflow_dispatch: # allows manual triggering
|
||||
inputs:
|
||||
sha:
|
||||
description: 'Commit SHA1 to build'
|
||||
required: false
|
||||
type: string
|
||||
slow_tests:
|
||||
description: 'Run slow tests'
|
||||
required: true
|
||||
type: boolean
|
||||
push:
|
||||
branches:
|
||||
- master
|
||||
paths: ['.github/workflows/server-webui.yml', 'tools/server/webui/**.*', 'tools/server/tests/**.*', 'tools/server/public/**']
|
||||
pull_request:
|
||||
types: [opened, synchronize, reopened]
|
||||
paths: ['.github/workflows/server-webui.yml', 'tools/server/webui/**.*', 'tools/server/tests/**.*', 'tools/server/public/**']
|
||||
|
||||
env:
|
||||
LLAMA_LOG_COLORS: 1
|
||||
LLAMA_LOG_PREFIX: 1
|
||||
LLAMA_LOG_TIMESTAMPS: 1
|
||||
LLAMA_LOG_VERBOSITY: 10
|
||||
|
||||
concurrency:
|
||||
group: ${{ github.workflow }}-${{ github.ref }}-${{ github.head_ref || github.run_id }}
|
||||
cancel-in-progress: true
|
||||
|
||||
jobs:
|
||||
webui-check:
|
||||
name: WebUI Checks
|
||||
runs-on: ubuntu-latest
|
||||
continue-on-error: true
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
fetch-depth: 0
|
||||
ref: ${{ github.event.inputs.sha || github.event.pull_request.head.sha || github.sha || github.head_ref || github.ref_name }}
|
||||
|
||||
- name: Setup Node.js
|
||||
id: node
|
||||
uses: actions/setup-node@v4
|
||||
with:
|
||||
node-version: "22"
|
||||
cache: "npm"
|
||||
cache-dependency-path: "tools/server/webui/package-lock.json"
|
||||
|
||||
- name: Install dependencies
|
||||
id: setup
|
||||
if: ${{ steps.node.conclusion == 'success' }}
|
||||
run: npm ci
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Run type checking
|
||||
if: ${{ always() && steps.setup.conclusion == 'success' }}
|
||||
run: npm run check
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Run linting
|
||||
if: ${{ always() && steps.setup.conclusion == 'success' }}
|
||||
run: npm run lint
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Build application
|
||||
if: ${{ always() && steps.setup.conclusion == 'success' }}
|
||||
run: npm run build
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Install Playwright browsers
|
||||
id: playwright
|
||||
if: ${{ always() && steps.setup.conclusion == 'success' }}
|
||||
run: npx playwright install --with-deps
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Build Storybook
|
||||
if: ${{ always() && steps.playwright.conclusion == 'success' }}
|
||||
run: npm run build-storybook
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Run Client tests
|
||||
if: ${{ always() && steps.playwright.conclusion == 'success' }}
|
||||
run: npm run test:client
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Run Unit tests
|
||||
if: ${{ always() && steps.playwright.conclusion == 'success' }}
|
||||
run: npm run test:unit
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Run UI tests
|
||||
if: ${{ always() && steps.playwright.conclusion == 'success' }}
|
||||
run: npm run test:ui -- --testTimeout=60000
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Run E2E tests
|
||||
if: ${{ always() && steps.playwright.conclusion == 'success' }}
|
||||
run: npm run test:e2e
|
||||
working-directory: tools/server/webui
|
||||
|
||||
server-build:
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
strategy:
|
||||
matrix:
|
||||
sanitizer: [ADDRESS, UNDEFINED] # THREAD is broken
|
||||
build_type: [RelWithDebInfo]
|
||||
include:
|
||||
- build_type: Release
|
||||
sanitizer: ""
|
||||
fail-fast: false # While -DLLAMA_SANITIZE_THREAD=ON is broken
|
||||
|
||||
steps:
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
run: |
|
||||
sudo apt-get update
|
||||
sudo apt-get -y install \
|
||||
build-essential \
|
||||
xxd \
|
||||
git \
|
||||
cmake \
|
||||
curl \
|
||||
wget \
|
||||
language-pack-en \
|
||||
libssl-dev
|
||||
|
||||
- name: Clone
|
||||
id: checkout
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
fetch-depth: 0
|
||||
ref: ${{ github.event.inputs.sha || github.event.pull_request.head.sha || github.sha || github.head_ref || github.ref_name }}
|
||||
|
||||
- name: Python setup
|
||||
id: setup_python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.11'
|
||||
|
||||
- name: Tests dependencies
|
||||
id: test_dependencies
|
||||
run: |
|
||||
pip install -r tools/server/tests/requirements.txt
|
||||
|
||||
- name: Setup Node.js for WebUI
|
||||
uses: actions/setup-node@v4
|
||||
with:
|
||||
node-version: "22"
|
||||
cache: "npm"
|
||||
cache-dependency-path: "tools/server/webui/package-lock.json"
|
||||
|
||||
- name: Install WebUI dependencies
|
||||
run: npm ci
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Build WebUI
|
||||
run: npm run build
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Build (no OpenMP)
|
||||
id: cmake_build_no_openmp
|
||||
if: ${{ matrix.sanitizer == 'THREAD' }}
|
||||
run: |
|
||||
cmake -B build \
|
||||
-DGGML_NATIVE=OFF \
|
||||
-DLLAMA_CURL=OFF \
|
||||
-DLLAMA_OPENSSL=ON \
|
||||
-DLLAMA_BUILD_SERVER=ON \
|
||||
-DCMAKE_BUILD_TYPE=${{ matrix.build_type }} \
|
||||
-DLLAMA_SANITIZE_${{ matrix.sanitizer }}=ON \
|
||||
-DGGML_OPENMP=OFF ;
|
||||
cmake --build build --config ${{ matrix.build_type }} -j $(nproc) --target llama-server
|
||||
|
||||
- name: Build (sanitizers)
|
||||
id: cmake_build_sanitizers
|
||||
if: ${{ matrix.sanitizer != '' && matrix.sanitizer != 'THREAD' }}
|
||||
run: |
|
||||
cmake -B build \
|
||||
-DGGML_NATIVE=OFF \
|
||||
-DLLAMA_CURL=OFF \
|
||||
-DLLAMA_OPENSSL=ON \
|
||||
-DLLAMA_BUILD_SERVER=ON \
|
||||
-DCMAKE_BUILD_TYPE=${{ matrix.build_type }} \
|
||||
-DLLAMA_SANITIZE_${{ matrix.sanitizer }}=ON ;
|
||||
cmake --build build --config ${{ matrix.build_type }} -j $(nproc) --target llama-server
|
||||
|
||||
- name: Build (sanitizers)
|
||||
id: cmake_build
|
||||
if: ${{ matrix.sanitizer == '' }}
|
||||
run: |
|
||||
cmake -B build \
|
||||
-DGGML_NATIVE=OFF \
|
||||
-DLLAMA_CURL=OFF \
|
||||
-DLLAMA_OPENSSL=ON \
|
||||
-DLLAMA_BUILD_SERVER=ON \
|
||||
-DCMAKE_BUILD_TYPE=${{ matrix.build_type }} ;
|
||||
cmake --build build --config ${{ matrix.build_type }} -j $(nproc) --target llama-server
|
||||
|
||||
- name: Tests
|
||||
id: server_integration_tests
|
||||
if: ${{ matrix.sanitizer == '' }}
|
||||
env:
|
||||
GITHUB_ACTIONS: "true"
|
||||
run: |
|
||||
cd tools/server/tests
|
||||
./tests.sh
|
||||
|
||||
- name: Tests (sanitizers)
|
||||
id: server_integration_tests_sanitizers
|
||||
if: ${{ matrix.sanitizer != '' }}
|
||||
run: |
|
||||
cd tools/server/tests
|
||||
LLAMA_SANITIZE=1 ./tests.sh
|
||||
|
||||
- name: Slow tests
|
||||
id: server_integration_tests_slow
|
||||
if: ${{ (github.event.schedule || github.event.inputs.slow_tests == 'true') && matrix.build_type == 'Release' }}
|
||||
run: |
|
||||
cd tools/server/tests
|
||||
SLOW_TESTS=1 ./tests.sh
|
||||
|
|
@ -76,270 +76,6 @@ jobs:
|
|||
run: |
|
||||
pip install -r tools/server/tests/requirements.txt
|
||||
|
||||
webui-setup:
|
||||
name: WebUI Setup
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
fetch-depth: 0
|
||||
ref: ${{ github.event.inputs.sha || github.event.pull_request.head.sha || github.sha || github.head_ref || github.ref_name }}
|
||||
|
||||
- name: Setup Node.js
|
||||
uses: actions/setup-node@v4
|
||||
with:
|
||||
node-version: "22"
|
||||
cache: "npm"
|
||||
cache-dependency-path: "tools/server/webui/package-lock.json"
|
||||
|
||||
- name: Cache node_modules
|
||||
uses: actions/cache@v4
|
||||
id: cache-node-modules
|
||||
with:
|
||||
path: tools/server/webui/node_modules
|
||||
key: ${{ runner.os }}-node-modules-${{ hashFiles('tools/server/webui/package-lock.json') }}
|
||||
restore-keys: |
|
||||
${{ runner.os }}-node-modules-
|
||||
|
||||
- name: Install dependencies
|
||||
if: steps.cache-node-modules.outputs.cache-hit != 'true'
|
||||
run: npm ci
|
||||
working-directory: tools/server/webui
|
||||
|
||||
webui-check:
|
||||
needs: webui-setup
|
||||
name: WebUI Check
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
fetch-depth: 0
|
||||
ref: ${{ github.event.inputs.sha || github.event.pull_request.head.sha || github.sha || github.head_ref || github.ref_name }}
|
||||
|
||||
- name: Setup Node.js
|
||||
uses: actions/setup-node@v4
|
||||
with:
|
||||
node-version: "22"
|
||||
|
||||
- name: Restore node_modules cache
|
||||
uses: actions/cache@v4
|
||||
with:
|
||||
path: tools/server/webui/node_modules
|
||||
key: ${{ runner.os }}-node-modules-${{ hashFiles('tools/server/webui/package-lock.json') }}
|
||||
restore-keys: |
|
||||
${{ runner.os }}-node-modules-
|
||||
|
||||
- name: Run type checking
|
||||
run: npm run check
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Run linting
|
||||
run: npm run lint
|
||||
working-directory: tools/server/webui
|
||||
|
||||
webui-build:
|
||||
needs: webui-check
|
||||
name: WebUI Build
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
fetch-depth: 0
|
||||
ref: ${{ github.event.inputs.sha || github.event.pull_request.head.sha || github.sha || github.head_ref || github.ref_name }}
|
||||
|
||||
- name: Setup Node.js
|
||||
uses: actions/setup-node@v4
|
||||
with:
|
||||
node-version: "22"
|
||||
|
||||
- name: Restore node_modules cache
|
||||
uses: actions/cache@v4
|
||||
with:
|
||||
path: tools/server/webui/node_modules
|
||||
key: ${{ runner.os }}-node-modules-${{ hashFiles('tools/server/webui/package-lock.json') }}
|
||||
restore-keys: |
|
||||
${{ runner.os }}-node-modules-
|
||||
|
||||
- name: Build application
|
||||
run: npm run build
|
||||
working-directory: tools/server/webui
|
||||
|
||||
webui-tests:
|
||||
needs: webui-build
|
||||
name: Run WebUI tests
|
||||
permissions:
|
||||
contents: read
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Checkout code
|
||||
uses: actions/checkout@v4
|
||||
|
||||
- name: Setup Node.js
|
||||
uses: actions/setup-node@v4
|
||||
with:
|
||||
node-version: "22"
|
||||
|
||||
- name: Restore node_modules cache
|
||||
uses: actions/cache@v4
|
||||
with:
|
||||
path: tools/server/webui/node_modules
|
||||
key: ${{ runner.os }}-node-modules-${{ hashFiles('tools/server/webui/package-lock.json') }}
|
||||
restore-keys: |
|
||||
${{ runner.os }}-node-modules-
|
||||
|
||||
- name: Install Playwright browsers
|
||||
run: npx playwright install --with-deps
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Build Storybook
|
||||
run: npm run build-storybook
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Run Client tests
|
||||
run: npm run test:client
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Run Server tests
|
||||
run: npm run test:server
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Run UI tests
|
||||
run: npm run test:ui -- --testTimeout=60000
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Run E2E tests
|
||||
run: npm run test:e2e
|
||||
working-directory: tools/server/webui
|
||||
|
||||
server-build:
|
||||
needs: [webui-tests]
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
strategy:
|
||||
matrix:
|
||||
sanitizer: [ADDRESS, UNDEFINED] # THREAD is broken
|
||||
build_type: [RelWithDebInfo]
|
||||
include:
|
||||
- build_type: Release
|
||||
sanitizer: ""
|
||||
fail-fast: false # While -DLLAMA_SANITIZE_THREAD=ON is broken
|
||||
|
||||
steps:
|
||||
- name: Dependencies
|
||||
id: depends
|
||||
run: |
|
||||
sudo apt-get update
|
||||
sudo apt-get -y install \
|
||||
build-essential \
|
||||
xxd \
|
||||
git \
|
||||
cmake \
|
||||
curl \
|
||||
wget \
|
||||
language-pack-en \
|
||||
libssl-dev
|
||||
|
||||
- name: Clone
|
||||
id: checkout
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
fetch-depth: 0
|
||||
ref: ${{ github.event.inputs.sha || github.event.pull_request.head.sha || github.sha || github.head_ref || github.ref_name }}
|
||||
|
||||
- name: Python setup
|
||||
id: setup_python
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: '3.11'
|
||||
|
||||
- name: Tests dependencies
|
||||
id: test_dependencies
|
||||
run: |
|
||||
pip install -r tools/server/tests/requirements.txt
|
||||
|
||||
- name: Setup Node.js for WebUI
|
||||
uses: actions/setup-node@v4
|
||||
with:
|
||||
node-version: "22"
|
||||
cache: "npm"
|
||||
cache-dependency-path: "tools/server/webui/package-lock.json"
|
||||
|
||||
- name: Install WebUI dependencies
|
||||
run: npm ci
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Build WebUI
|
||||
run: npm run build
|
||||
working-directory: tools/server/webui
|
||||
|
||||
- name: Build (no OpenMP)
|
||||
id: cmake_build_no_openmp
|
||||
if: ${{ matrix.sanitizer == 'THREAD' }}
|
||||
run: |
|
||||
cmake -B build \
|
||||
-DGGML_NATIVE=OFF \
|
||||
-DLLAMA_CURL=OFF \
|
||||
-DLLAMA_OPENSSL=ON \
|
||||
-DLLAMA_BUILD_SERVER=ON \
|
||||
-DCMAKE_BUILD_TYPE=${{ matrix.build_type }} \
|
||||
-DLLAMA_SANITIZE_${{ matrix.sanitizer }}=ON \
|
||||
-DGGML_OPENMP=OFF ;
|
||||
cmake --build build --config ${{ matrix.build_type }} -j $(nproc) --target llama-server
|
||||
|
||||
- name: Build (sanitizers)
|
||||
id: cmake_build_sanitizers
|
||||
if: ${{ matrix.sanitizer != '' && matrix.sanitizer != 'THREAD' }}
|
||||
run: |
|
||||
cmake -B build \
|
||||
-DGGML_NATIVE=OFF \
|
||||
-DLLAMA_CURL=OFF \
|
||||
-DLLAMA_OPENSSL=ON \
|
||||
-DLLAMA_BUILD_SERVER=ON \
|
||||
-DCMAKE_BUILD_TYPE=${{ matrix.build_type }} \
|
||||
-DLLAMA_SANITIZE_${{ matrix.sanitizer }}=ON ;
|
||||
cmake --build build --config ${{ matrix.build_type }} -j $(nproc) --target llama-server
|
||||
|
||||
- name: Build (sanitizers)
|
||||
id: cmake_build
|
||||
if: ${{ matrix.sanitizer == '' }}
|
||||
run: |
|
||||
cmake -B build \
|
||||
-DGGML_NATIVE=OFF \
|
||||
-DLLAMA_CURL=OFF \
|
||||
-DLLAMA_OPENSSL=ON \
|
||||
-DLLAMA_BUILD_SERVER=ON \
|
||||
-DCMAKE_BUILD_TYPE=${{ matrix.build_type }} ;
|
||||
cmake --build build --config ${{ matrix.build_type }} -j $(nproc) --target llama-server
|
||||
|
||||
- name: Tests
|
||||
id: server_integration_tests
|
||||
if: ${{ matrix.sanitizer == '' }}
|
||||
env:
|
||||
GITHUB_ACTIONS: "true"
|
||||
run: |
|
||||
cd tools/server/tests
|
||||
./tests.sh
|
||||
|
||||
- name: Tests (sanitizers)
|
||||
id: server_integration_tests_sanitizers
|
||||
if: ${{ matrix.sanitizer != '' }}
|
||||
run: |
|
||||
cd tools/server/tests
|
||||
LLAMA_SANITIZE=1 ./tests.sh
|
||||
|
||||
- name: Slow tests
|
||||
id: server_integration_tests_slow
|
||||
if: ${{ (github.event.schedule || github.event.inputs.slow_tests == 'true') && matrix.build_type == 'Release' }}
|
||||
run: |
|
||||
cd tools/server/tests
|
||||
SLOW_TESTS=1 ./tests.sh
|
||||
|
||||
|
||||
server-windows:
|
||||
runs-on: windows-2022
|
||||
|
||||
|
|
|
|||
|
|
@ -1,4 +1,4 @@
|
|||
# Copilot Instructions for llama.cpp
|
||||
# Instructions for llama.cpp
|
||||
|
||||
## Repository Overview
|
||||
|
||||
|
|
@ -12,6 +12,24 @@ llama.cpp is a large-scale C/C++ project for efficient LLM (Large Language Model
|
|||
- **Backends supported**: CPU (AVX/NEON/RVV optimized), CUDA, Metal, Vulkan, SYCL, ROCm, MUSA
|
||||
- **License**: MIT
|
||||
|
||||
## Disclose AI Usage
|
||||
|
||||
It is crucial to remind contributors that the project mandates disclosure of any AI usage in pull requests. This requirement stems from the potential for AI-generated code to include suboptimal optimizations and hidden bugs, owing to the inherent overconfidence in AI outputs.
|
||||
|
||||
When generating significant portions of code, address this by:
|
||||
- Informing the user that AI-generated content may be rejected by maintainers.
|
||||
- Clearly marking AI-generated code in commit messages and comments.
|
||||
- Example of commit message: `[AI] Fix a race condition in ...`
|
||||
- Example of code comment: `// [AI] spawn a new thread ...`
|
||||
|
||||
These measures apply to:
|
||||
- Changes resulting in large portions of code or complex logic.
|
||||
- Modifications or additions to public APIs in `llama.h`, `ggml.h`, or `mtmd.h`.
|
||||
- Backend-related changes, such as those involving CPU, CUDA, Metal, Vulkan, etc.
|
||||
- Modifications to `tools/server`.
|
||||
|
||||
Note: These measures can be omitted for small fixes or trivial changes.
|
||||
|
||||
## Build Instructions
|
||||
|
||||
### Prerequisites
|
||||
|
|
@ -251,6 +269,7 @@ Primary tools:
|
|||
- **Cross-platform compatibility**: Test on Linux, macOS, Windows when possible
|
||||
- **Performance focus**: This is a performance-critical inference library
|
||||
- **API stability**: Changes to `include/llama.h` require careful consideration
|
||||
- **Disclose AI Usage**: Refer to the "Disclose AI Usage" earlier in this document
|
||||
|
||||
### Git Workflow
|
||||
- Always create feature branches from `master`
|
||||
|
|
@ -32,7 +32,7 @@
|
|||
/examples/export-docs/ @ggerganov
|
||||
/examples/gen-docs/ @ggerganov
|
||||
/examples/gguf/ @ggerganov
|
||||
/examples/llama.android/ @ggerganov
|
||||
/examples/llama.android/ @ggerganov @hanyin-arm @naco-siren
|
||||
/examples/llama.swiftui/ @ggerganov
|
||||
/examples/llama.vim @ggerganov
|
||||
/examples/lookahead/ @ggerganov
|
||||
|
|
|
|||
|
|
@ -190,6 +190,7 @@ Instructions for adding support for new models: [HOWTO-add-model.md](docs/develo
|
|||
- Swift [ShenghaiWang/SwiftLlama](https://github.com/ShenghaiWang/SwiftLlama)
|
||||
- Delphi [Embarcadero/llama-cpp-delphi](https://github.com/Embarcadero/llama-cpp-delphi)
|
||||
- Go (no CGo needed): [hybridgroup/yzma](https://github.com/hybridgroup/yzma)
|
||||
- Android: [llama.android](/examples/llama.android)
|
||||
|
||||
</details>
|
||||
|
||||
|
|
|
|||
|
|
@ -68,3 +68,6 @@ Please disclose it as a private [security advisory](https://github.com/ggml-org/
|
|||
Please note that using AI to identify vulnerabilities and generate reports is permitted. However, you must (1) explicitly disclose how AI was used and (2) conduct a thorough manual review before submitting the report.
|
||||
|
||||
A team of volunteers on a reasonable-effort basis maintains this project. As such, please give us at least 90 days to work on a fix before public exposure.
|
||||
|
||||
> [!IMPORTANT]
|
||||
> For collaborators: if you are interested in helping out with reviewing privting security disclosures, please see: https://github.com/ggml-org/llama.cpp/discussions/18080
|
||||
|
|
|
|||
|
|
@ -85,6 +85,9 @@ add_library(${TARGET} STATIC
|
|||
unicode.h
|
||||
)
|
||||
|
||||
target_include_directories(${TARGET} PUBLIC . ../vendor)
|
||||
target_compile_features (${TARGET} PUBLIC cxx_std_17)
|
||||
|
||||
if (BUILD_SHARED_LIBS)
|
||||
set_target_properties(${TARGET} PROPERTIES POSITION_INDEPENDENT_CODE ON)
|
||||
endif()
|
||||
|
|
@ -151,9 +154,7 @@ if (LLAMA_LLGUIDANCE)
|
|||
set(LLAMA_COMMON_EXTRA_LIBS ${LLAMA_COMMON_EXTRA_LIBS} llguidance ${LLGUIDANCE_PLATFORM_LIBS})
|
||||
endif ()
|
||||
|
||||
target_include_directories(${TARGET} PUBLIC . ../vendor)
|
||||
target_compile_features (${TARGET} PUBLIC cxx_std_17)
|
||||
target_link_libraries (${TARGET} PRIVATE ${LLAMA_COMMON_EXTRA_LIBS} PUBLIC llama Threads::Threads)
|
||||
target_link_libraries(${TARGET} PRIVATE ${LLAMA_COMMON_EXTRA_LIBS} PUBLIC llama Threads::Threads)
|
||||
|
||||
|
||||
#
|
||||
|
|
|
|||
251
common/arg.cpp
251
common/arg.cpp
|
|
@ -96,6 +96,11 @@ common_arg & common_arg::set_sparam() {
|
|||
return *this;
|
||||
}
|
||||
|
||||
common_arg & common_arg::set_preset_only() {
|
||||
is_preset_only = true;
|
||||
return *this;
|
||||
}
|
||||
|
||||
bool common_arg::in_example(enum llama_example ex) {
|
||||
return examples.find(ex) != examples.end();
|
||||
}
|
||||
|
|
@ -420,6 +425,8 @@ static bool common_params_parse_ex(int argc, char ** argv, common_params_context
|
|||
}
|
||||
};
|
||||
|
||||
std::set<std::string> seen_args;
|
||||
|
||||
for (int i = 1; i < argc; i++) {
|
||||
const std::string arg_prefix = "--";
|
||||
|
||||
|
|
@ -430,6 +437,9 @@ static bool common_params_parse_ex(int argc, char ** argv, common_params_context
|
|||
if (arg_to_options.find(arg) == arg_to_options.end()) {
|
||||
throw std::invalid_argument(string_format("error: invalid argument: %s", arg.c_str()));
|
||||
}
|
||||
if (!seen_args.insert(arg).second) {
|
||||
LOG_WRN("DEPRECATED: argument '%s' specified multiple times, use comma-separated values instead (only last value will be used)\n", arg.c_str());
|
||||
}
|
||||
auto & tmp = arg_to_options[arg];
|
||||
auto opt = *tmp.first;
|
||||
bool is_positive = tmp.second;
|
||||
|
|
@ -750,6 +760,8 @@ bool common_params_to_map(int argc, char ** argv, llama_example ex, std::map<com
|
|||
}
|
||||
};
|
||||
|
||||
std::set<std::string> seen_args;
|
||||
|
||||
for (int i = 1; i < argc; i++) {
|
||||
const std::string arg_prefix = "--";
|
||||
|
||||
|
|
@ -760,8 +772,16 @@ bool common_params_to_map(int argc, char ** argv, llama_example ex, std::map<com
|
|||
if (arg_to_options.find(arg) == arg_to_options.end()) {
|
||||
throw std::invalid_argument(string_format("error: invalid argument: %s", arg.c_str()));
|
||||
}
|
||||
if (!seen_args.insert(arg).second) {
|
||||
LOG_WRN("DEPRECATED: argument '%s' specified multiple times, use comma-separated values instead (only last value will be used)\n", arg.c_str());
|
||||
}
|
||||
auto opt = *arg_to_options[arg];
|
||||
std::string val;
|
||||
if (opt.value_hint == nullptr && opt.value_hint_2 == nullptr) {
|
||||
// bool arg (need to reverse the meaning for negative args)
|
||||
bool is_neg = std::find(opt.args_neg.begin(), opt.args_neg.end(), arg) != opt.args_neg.end();
|
||||
val = is_neg ? "0" : "1";
|
||||
}
|
||||
if (opt.value_hint != nullptr) {
|
||||
// arg with single value
|
||||
check_arg(i);
|
||||
|
|
@ -835,6 +855,19 @@ bool common_arg_utils::is_autoy(const std::string & value) {
|
|||
}
|
||||
|
||||
common_params_context common_params_parser_init(common_params & params, llama_example ex, void(*print_usage)(int, char **)) {
|
||||
// per-example default params
|
||||
// we define here to make sure it's included in llama-gen-docs
|
||||
if (ex == LLAMA_EXAMPLE_COMPLETION) {
|
||||
params.use_jinja = false; // disable jinja by default
|
||||
|
||||
} else if (ex == LLAMA_EXAMPLE_MTMD) {
|
||||
params.use_jinja = false; // disable jinja by default
|
||||
params.sampling.temp = 0.2; // lower temp by default for better quality
|
||||
|
||||
} else if (ex == LLAMA_EXAMPLE_SERVER) {
|
||||
params.n_parallel = -1; // auto by default
|
||||
}
|
||||
|
||||
params.use_color = tty_can_use_colors();
|
||||
|
||||
// load dynamic backends
|
||||
|
|
@ -850,7 +883,9 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
sampler_type_chars += common_sampler_type_to_chr(sampler);
|
||||
sampler_type_names += common_sampler_type_to_str(sampler) + ";";
|
||||
}
|
||||
sampler_type_names.pop_back();
|
||||
if (!sampler_type_names.empty()) {
|
||||
sampler_type_names.pop_back(); // remove last semicolon
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
|
|
@ -1107,28 +1142,27 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
).set_env("LLAMA_ARG_SWA_FULL"));
|
||||
add_opt(common_arg(
|
||||
{"--ctx-checkpoints", "--swa-checkpoints"}, "N",
|
||||
string_format("max number of context checkpoints to create per slot (default: %d)\n"
|
||||
string_format("max number of context checkpoints to create per slot (default: %d)"
|
||||
"[(more info)](https://github.com/ggml-org/llama.cpp/pull/15293)", params.n_ctx_checkpoints),
|
||||
[](common_params & params, int value) {
|
||||
params.n_ctx_checkpoints = value;
|
||||
}
|
||||
).set_env("LLAMA_ARG_CTX_CHECKPOINTS").set_examples({LLAMA_EXAMPLE_SERVER, LLAMA_EXAMPLE_CLI}));
|
||||
add_opt(common_arg(
|
||||
{"--cache-ram", "-cram"}, "N",
|
||||
string_format("set the maximum cache size in MiB (default: %d, -1 - no limit, 0 - disable)\n"
|
||||
{"-cram", "--cache-ram"}, "N",
|
||||
string_format("set the maximum cache size in MiB (default: %d, -1 - no limit, 0 - disable)"
|
||||
"[(more info)](https://github.com/ggml-org/llama.cpp/pull/16391)", params.cache_ram_mib),
|
||||
[](common_params & params, int value) {
|
||||
params.cache_ram_mib = value;
|
||||
}
|
||||
).set_env("LLAMA_ARG_CACHE_RAM").set_examples({LLAMA_EXAMPLE_SERVER, LLAMA_EXAMPLE_CLI}));
|
||||
add_opt(common_arg(
|
||||
{"--kv-unified", "-kvu"},
|
||||
string_format("use single unified KV buffer for the KV cache of all sequences (default: %s)\n"
|
||||
"[(more info)](https://github.com/ggml-org/llama.cpp/pull/14363)", params.kv_unified ? "true" : "false"),
|
||||
{"-kvu", "--kv-unified"},
|
||||
"use single unified KV buffer shared across all sequences (default: enabled if number of slots is auto)",
|
||||
[](common_params & params) {
|
||||
params.kv_unified = true;
|
||||
}
|
||||
).set_env("LLAMA_ARG_KV_UNIFIED"));
|
||||
).set_env("LLAMA_ARG_KV_UNIFIED").set_examples({LLAMA_EXAMPLE_SERVER, LLAMA_EXAMPLE_PERPLEXITY}));
|
||||
add_opt(common_arg(
|
||||
{"--context-shift"},
|
||||
{"--no-context-shift"},
|
||||
|
|
@ -1172,7 +1206,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
[](common_params & params, const std::string & value) {
|
||||
params.system_prompt = value;
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_COMPLETION, LLAMA_EXAMPLE_CLI, LLAMA_EXAMPLE_DIFFUSION}));
|
||||
).set_examples({LLAMA_EXAMPLE_COMPLETION, LLAMA_EXAMPLE_CLI, LLAMA_EXAMPLE_DIFFUSION, LLAMA_EXAMPLE_MTMD}));
|
||||
add_opt(common_arg(
|
||||
{"--perf"},
|
||||
{"--no-perf"},
|
||||
|
|
@ -1214,13 +1248,15 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
).set_examples({LLAMA_EXAMPLE_COMPLETION, LLAMA_EXAMPLE_CLI, LLAMA_EXAMPLE_DIFFUSION}));
|
||||
add_opt(common_arg(
|
||||
{"--in-file"}, "FNAME",
|
||||
"an input file (repeat to specify multiple files)",
|
||||
"an input file (use comma-separated values to specify multiple files)",
|
||||
[](common_params & params, const std::string & value) {
|
||||
std::ifstream file(value);
|
||||
if (!file) {
|
||||
throw std::runtime_error(string_format("error: failed to open file '%s'\n", value.c_str()));
|
||||
for (const auto & item : string_split<std::string>(value, ',')) {
|
||||
std::ifstream file(item);
|
||||
if (!file) {
|
||||
throw std::runtime_error(string_format("error: failed to open file '%s'\n", item.c_str()));
|
||||
}
|
||||
params.in_files.push_back(item);
|
||||
}
|
||||
params.in_files.push_back(value);
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_IMATRIX}));
|
||||
add_opt(common_arg(
|
||||
|
|
@ -1389,7 +1425,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
}
|
||||
).set_sparam());
|
||||
add_opt(common_arg(
|
||||
{"--sampling-seq", "--sampler-seq"}, "SEQUENCE",
|
||||
{"--sampler-seq", "--sampling-seq"}, "SEQUENCE",
|
||||
string_format("simplified sequence for samplers that will be used (default: %s)", sampler_type_chars.c_str()),
|
||||
[](common_params & params, const std::string & value) {
|
||||
params.sampling.samplers = common_sampler_types_from_chars(value);
|
||||
|
|
@ -1888,13 +1924,27 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
LOG_WRN("DEPRECATED: --defrag-thold is deprecated and no longer necessary to specify\n");
|
||||
}
|
||||
).set_env("LLAMA_ARG_DEFRAG_THOLD"));
|
||||
add_opt(common_arg(
|
||||
{"-np", "--parallel"}, "N",
|
||||
string_format("number of parallel sequences to decode (default: %d)", params.n_parallel),
|
||||
[](common_params & params, int value) {
|
||||
params.n_parallel = value;
|
||||
}
|
||||
).set_env("LLAMA_ARG_N_PARALLEL"));
|
||||
if (ex == LLAMA_EXAMPLE_SERVER) {
|
||||
// this is to make sure this option appears in the server-specific section of the help message
|
||||
add_opt(common_arg(
|
||||
{"-np", "--parallel"}, "N",
|
||||
string_format("number of server slots (default: %d, -1 = auto)", params.n_parallel),
|
||||
[](common_params & params, int value) {
|
||||
if (value == 0) {
|
||||
throw std::invalid_argument("error: invalid value for n_parallel\n");
|
||||
}
|
||||
params.n_parallel = value;
|
||||
}
|
||||
).set_env("LLAMA_ARG_N_PARALLEL").set_examples({LLAMA_EXAMPLE_SERVER}));
|
||||
} else {
|
||||
add_opt(common_arg(
|
||||
{"-np", "--parallel"}, "N",
|
||||
string_format("number of parallel sequences to decode (default: %d)", params.n_parallel),
|
||||
[](common_params & params, int value) {
|
||||
params.n_parallel = value;
|
||||
}
|
||||
).set_env("LLAMA_ARG_N_PARALLEL"));
|
||||
}
|
||||
add_opt(common_arg(
|
||||
{"-ns", "--sequences"}, "N",
|
||||
string_format("number of sequences to decode (default: %d)", params.n_sequences),
|
||||
|
|
@ -1943,9 +1993,11 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
).set_examples(mmproj_examples).set_env("LLAMA_ARG_MMPROJ_OFFLOAD"));
|
||||
add_opt(common_arg(
|
||||
{"--image", "--audio"}, "FILE",
|
||||
"path to an image or audio file. use with multimodal models, can be repeated if you have multiple files\n",
|
||||
"path to an image or audio file. use with multimodal models, use comma-separated values for multiple files\n",
|
||||
[](common_params & params, const std::string & value) {
|
||||
params.image.emplace_back(value);
|
||||
for (const auto & item : string_split<std::string>(value, ',')) {
|
||||
params.image.emplace_back(item);
|
||||
}
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_MTMD, LLAMA_EXAMPLE_CLI}));
|
||||
add_opt(common_arg(
|
||||
|
|
@ -2031,26 +2083,26 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
}
|
||||
));
|
||||
add_opt(common_arg(
|
||||
{"--override-tensor", "-ot"}, "<tensor name pattern>=<buffer type>,...",
|
||||
{"-ot", "--override-tensor"}, "<tensor name pattern>=<buffer type>,...",
|
||||
"override tensor buffer type", [](common_params & params, const std::string & value) {
|
||||
parse_tensor_buffer_overrides(value, params.tensor_buft_overrides);
|
||||
}
|
||||
));
|
||||
add_opt(common_arg(
|
||||
{"--override-tensor-draft", "-otd"}, "<tensor name pattern>=<buffer type>,...",
|
||||
{"-otd", "--override-tensor-draft"}, "<tensor name pattern>=<buffer type>,...",
|
||||
"override tensor buffer type for draft model", [](common_params & params, const std::string & value) {
|
||||
parse_tensor_buffer_overrides(value, params.speculative.tensor_buft_overrides);
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SPECULATIVE, LLAMA_EXAMPLE_SERVER, LLAMA_EXAMPLE_CLI}));
|
||||
add_opt(common_arg(
|
||||
{"--cpu-moe", "-cmoe"},
|
||||
{"-cmoe", "--cpu-moe"},
|
||||
"keep all Mixture of Experts (MoE) weights in the CPU",
|
||||
[](common_params & params) {
|
||||
params.tensor_buft_overrides.push_back(llm_ffn_exps_cpu_override());
|
||||
}
|
||||
).set_env("LLAMA_ARG_CPU_MOE"));
|
||||
add_opt(common_arg(
|
||||
{"--n-cpu-moe", "-ncmoe"}, "N",
|
||||
{"-ncmoe", "--n-cpu-moe"}, "N",
|
||||
"keep the Mixture of Experts (MoE) weights of the first N layers in the CPU",
|
||||
[](common_params & params, int value) {
|
||||
if (value < 0) {
|
||||
|
|
@ -2065,14 +2117,14 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
}
|
||||
).set_env("LLAMA_ARG_N_CPU_MOE"));
|
||||
add_opt(common_arg(
|
||||
{"--cpu-moe-draft", "-cmoed"},
|
||||
{"-cmoed", "--cpu-moe-draft"},
|
||||
"keep all Mixture of Experts (MoE) weights in the CPU for the draft model",
|
||||
[](common_params & params) {
|
||||
params.speculative.tensor_buft_overrides.push_back(llm_ffn_exps_cpu_override());
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SPECULATIVE, LLAMA_EXAMPLE_SERVER, LLAMA_EXAMPLE_CLI}).set_env("LLAMA_ARG_CPU_MOE_DRAFT"));
|
||||
add_opt(common_arg(
|
||||
{"--n-cpu-moe-draft", "-ncmoed"}, "N",
|
||||
{"-ncmoed", "--n-cpu-moe-draft"}, "N",
|
||||
"keep the Mixture of Experts (MoE) weights of the first N layers in the CPU for the draft model",
|
||||
[](common_params & params, int value) {
|
||||
if (value < 0) {
|
||||
|
|
@ -2192,12 +2244,39 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
}
|
||||
));
|
||||
add_opt(common_arg(
|
||||
{"--override-kv"}, "KEY=TYPE:VALUE",
|
||||
"advanced option to override model metadata by key. may be specified multiple times.\n"
|
||||
"types: int, float, bool, str. example: --override-kv tokenizer.ggml.add_bos_token=bool:false",
|
||||
{"--override-kv"}, "KEY=TYPE:VALUE,...",
|
||||
"advanced option to override model metadata by key. to specify multiple overrides, either use comma-separated or repeat this argument.\n"
|
||||
"types: int, float, bool, str. example: --override-kv tokenizer.ggml.add_bos_token=bool:false,tokenizer.ggml.add_eos_token=bool:false",
|
||||
[](common_params & params, const std::string & value) {
|
||||
if (!string_parse_kv_override(value.c_str(), params.kv_overrides)) {
|
||||
throw std::runtime_error(string_format("error: Invalid type for KV override: %s\n", value.c_str()));
|
||||
std::vector<std::string> kv_overrides;
|
||||
|
||||
std::string current;
|
||||
bool escaping = false;
|
||||
|
||||
for (const char c : value) {
|
||||
if (escaping) {
|
||||
current.push_back(c);
|
||||
escaping = false;
|
||||
} else if (c == '\\') {
|
||||
escaping = true;
|
||||
} else if (c == ',') {
|
||||
kv_overrides.push_back(current);
|
||||
current.clear();
|
||||
} else {
|
||||
current.push_back(c);
|
||||
}
|
||||
}
|
||||
|
||||
if (escaping) {
|
||||
current.push_back('\\');
|
||||
}
|
||||
|
||||
kv_overrides.push_back(current);
|
||||
|
||||
for (const auto & kv_override : kv_overrides) {
|
||||
if (!string_parse_kv_override(kv_override.c_str(), params.kv_overrides)) {
|
||||
throw std::runtime_error(string_format("error: Invalid type for KV override: %s\n", kv_override.c_str()));
|
||||
}
|
||||
}
|
||||
}
|
||||
));
|
||||
|
|
@ -2211,33 +2290,50 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
));
|
||||
add_opt(common_arg(
|
||||
{"--lora"}, "FNAME",
|
||||
"path to LoRA adapter (can be repeated to use multiple adapters)",
|
||||
"path to LoRA adapter (use comma-separated values to load multiple adapters)",
|
||||
[](common_params & params, const std::string & value) {
|
||||
params.lora_adapters.push_back({ std::string(value), 1.0, "", "", nullptr });
|
||||
for (const auto & item : string_split<std::string>(value, ',')) {
|
||||
params.lora_adapters.push_back({ item, 1.0, "", "", nullptr });
|
||||
}
|
||||
}
|
||||
// we define this arg on both COMMON and EXPORT_LORA, so when showing help message of export-lora, it will be categorized as "example-specific" arg
|
||||
).set_examples({LLAMA_EXAMPLE_COMMON, LLAMA_EXAMPLE_EXPORT_LORA}));
|
||||
add_opt(common_arg(
|
||||
{"--lora-scaled"}, "FNAME", "SCALE",
|
||||
"path to LoRA adapter with user defined scaling (can be repeated to use multiple adapters)",
|
||||
[](common_params & params, const std::string & fname, const std::string & scale) {
|
||||
params.lora_adapters.push_back({ fname, std::stof(scale), "", "", nullptr });
|
||||
{"--lora-scaled"}, "FNAME:SCALE,...",
|
||||
"path to LoRA adapter with user defined scaling (format: FNAME:SCALE,...)\n"
|
||||
"note: use comma-separated values",
|
||||
[](common_params & params, const std::string & value) {
|
||||
for (const auto & item : string_split<std::string>(value, ',')) {
|
||||
auto parts = string_split<std::string>(item, ':');
|
||||
if (parts.size() != 2) {
|
||||
throw std::invalid_argument("lora-scaled format: FNAME:SCALE");
|
||||
}
|
||||
params.lora_adapters.push_back({ parts[0], std::stof(parts[1]), "", "", nullptr });
|
||||
}
|
||||
}
|
||||
// we define this arg on both COMMON and EXPORT_LORA, so when showing help message of export-lora, it will be categorized as "example-specific" arg
|
||||
).set_examples({LLAMA_EXAMPLE_COMMON, LLAMA_EXAMPLE_EXPORT_LORA}));
|
||||
add_opt(common_arg(
|
||||
{"--control-vector"}, "FNAME",
|
||||
"add a control vector\nnote: this argument can be repeated to add multiple control vectors",
|
||||
"add a control vector\nnote: use comma-separated values to add multiple control vectors",
|
||||
[](common_params & params, const std::string & value) {
|
||||
params.control_vectors.push_back({ 1.0f, value, });
|
||||
for (const auto & item : string_split<std::string>(value, ',')) {
|
||||
params.control_vectors.push_back({ 1.0f, item, });
|
||||
}
|
||||
}
|
||||
));
|
||||
add_opt(common_arg(
|
||||
{"--control-vector-scaled"}, "FNAME", "SCALE",
|
||||
{"--control-vector-scaled"}, "FNAME:SCALE,...",
|
||||
"add a control vector with user defined scaling SCALE\n"
|
||||
"note: this argument can be repeated to add multiple scaled control vectors",
|
||||
[](common_params & params, const std::string & fname, const std::string & scale) {
|
||||
params.control_vectors.push_back({ std::stof(scale), fname });
|
||||
"note: use comma-separated values (format: FNAME:SCALE,...)",
|
||||
[](common_params & params, const std::string & value) {
|
||||
for (const auto & item : string_split<std::string>(value, ',')) {
|
||||
auto parts = string_split<std::string>(item, ':');
|
||||
if (parts.size() != 2) {
|
||||
throw std::invalid_argument("control-vector-scaled format: FNAME:SCALE");
|
||||
}
|
||||
params.control_vectors.push_back({ std::stof(parts[1]), parts[0] });
|
||||
}
|
||||
}
|
||||
));
|
||||
add_opt(common_arg(
|
||||
|
|
@ -2327,13 +2423,15 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
).set_env("HF_TOKEN"));
|
||||
add_opt(common_arg(
|
||||
{"--context-file"}, "FNAME",
|
||||
"file to load context from (repeat to specify multiple files)",
|
||||
"file to load context from (use comma-separated values to specify multiple files)",
|
||||
[](common_params & params, const std::string & value) {
|
||||
std::ifstream file(value, std::ios::binary);
|
||||
if (!file) {
|
||||
throw std::runtime_error(string_format("error: failed to open file '%s'\n", value.c_str()));
|
||||
for (const auto & item : string_split<std::string>(value, ',')) {
|
||||
std::ifstream file(item, std::ios::binary);
|
||||
if (!file) {
|
||||
throw std::runtime_error(string_format("error: failed to open file '%s'\n", item.c_str()));
|
||||
}
|
||||
params.context_files.push_back(item);
|
||||
}
|
||||
params.context_files.push_back(value);
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_RETRIEVAL}));
|
||||
add_opt(common_arg(
|
||||
|
|
@ -2524,6 +2622,20 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
params.api_prefix = value;
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SERVER}).set_env("LLAMA_ARG_API_PREFIX"));
|
||||
add_opt(common_arg(
|
||||
{"--webui-config"}, "JSON",
|
||||
"JSON that provides default WebUI settings (overrides WebUI defaults)",
|
||||
[](common_params & params, const std::string & value) {
|
||||
params.webui_config_json = value;
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SERVER}).set_env("LLAMA_ARG_WEBUI_CONFIG"));
|
||||
add_opt(common_arg(
|
||||
{"--webui-config-file"}, "PATH",
|
||||
"JSON file that provides default WebUI settings (overrides WebUI defaults)",
|
||||
[](common_params & params, const std::string & value) {
|
||||
params.webui_config_json = read_file(value);
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SERVER}).set_env("LLAMA_ARG_WEBUI_CONFIG_FILE"));
|
||||
add_opt(common_arg(
|
||||
{"--webui"},
|
||||
{"--no-webui"},
|
||||
|
|
@ -2540,7 +2652,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SERVER}).set_env("LLAMA_ARG_EMBEDDINGS"));
|
||||
add_opt(common_arg(
|
||||
{"--reranking", "--rerank"},
|
||||
{"--rerank", "--reranking"},
|
||||
string_format("enable reranking endpoint on server (default: %s)", "disabled"),
|
||||
[](common_params & params) {
|
||||
params.embedding = true;
|
||||
|
|
@ -2775,6 +2887,16 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
params.lora_init_without_apply = true;
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SERVER}));
|
||||
add_opt(common_arg(
|
||||
{"--sleep-idle-seconds"}, "SECONDS",
|
||||
string_format("number of seconds of idleness after which the server will sleep (default: %d; -1 = disabled)", params.sleep_idle_seconds),
|
||||
[](common_params & params, int value) {
|
||||
if (value == 0 || value < -1) {
|
||||
throw std::invalid_argument("invalid value: cannot be 0 or less than -1");
|
||||
}
|
||||
params.sleep_idle_seconds = value;
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SERVER}));
|
||||
add_opt(common_arg(
|
||||
{"--simple-io"},
|
||||
"use basic IO for better compatibility in subprocesses and limited consoles",
|
||||
|
|
@ -3011,7 +3133,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
}
|
||||
).set_examples({LLAMA_EXAMPLE_SPECULATIVE}));
|
||||
add_opt(common_arg(
|
||||
{"--draft-max", "--draft", "--draft-n"}, "N",
|
||||
{"--draft", "--draft-n", "--draft-max"}, "N",
|
||||
string_format("number of tokens to draft for speculative decoding (default: %d)", params.speculative.n_max),
|
||||
[](common_params & params, int value) {
|
||||
params.speculative.n_max = value;
|
||||
|
|
@ -3387,3 +3509,24 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
|
||||
return ctx_arg;
|
||||
}
|
||||
|
||||
void common_params_add_preset_options(std::vector<common_arg> & args) {
|
||||
// arguments below won't be treated as CLI args, only preset options
|
||||
args.push_back(common_arg(
|
||||
{"load-on-startup"}, "NAME",
|
||||
"in server router mode, autoload this model on startup",
|
||||
[](common_params &, const std::string &) { /* unused */ }
|
||||
).set_env(COMMON_ARG_PRESET_LOAD_ON_STARTUP).set_preset_only());
|
||||
|
||||
// args.push_back(common_arg(
|
||||
// {"pin"},
|
||||
// "in server router mode, do not unload this model if models_max is exceeded",
|
||||
// [](common_params &) { /* unused */ }
|
||||
// ).set_preset_only());
|
||||
|
||||
// args.push_back(common_arg(
|
||||
// {"unload-idle-seconds"}, "SECONDS",
|
||||
// "in server router mode, unload models idle for more than this many seconds",
|
||||
// [](common_params &, int) { /* unused */ }
|
||||
// ).set_preset_only());
|
||||
}
|
||||
|
|
|
|||
11
common/arg.h
11
common/arg.h
|
|
@ -8,6 +8,9 @@
|
|||
#include <vector>
|
||||
#include <cstring>
|
||||
|
||||
// pseudo-env variable to identify preset-only arguments
|
||||
#define COMMON_ARG_PRESET_LOAD_ON_STARTUP "__PRESET_LOAD_ON_STARTUP"
|
||||
|
||||
//
|
||||
// CLI argument parsing
|
||||
//
|
||||
|
|
@ -22,6 +25,7 @@ struct common_arg {
|
|||
const char * env = nullptr;
|
||||
std::string help;
|
||||
bool is_sparam = false; // is current arg a sampling param?
|
||||
bool is_preset_only = false; // is current arg preset-only (not treated as CLI arg)
|
||||
void (*handler_void) (common_params & params) = nullptr;
|
||||
void (*handler_string) (common_params & params, const std::string &) = nullptr;
|
||||
void (*handler_str_str)(common_params & params, const std::string &, const std::string &) = nullptr;
|
||||
|
|
@ -70,6 +74,7 @@ struct common_arg {
|
|||
common_arg & set_excludes(std::initializer_list<enum llama_example> excludes);
|
||||
common_arg & set_env(const char * env);
|
||||
common_arg & set_sparam();
|
||||
common_arg & set_preset_only();
|
||||
bool in_example(enum llama_example ex);
|
||||
bool is_exclude(enum llama_example ex);
|
||||
bool get_value_from_env(std::string & output) const;
|
||||
|
|
@ -114,9 +119,13 @@ struct common_params_context {
|
|||
bool common_params_parse(int argc, char ** argv, common_params & params, llama_example ex, void(*print_usage)(int, char **) = nullptr);
|
||||
|
||||
// parse input arguments from CLI into a map
|
||||
// TODO: support repeated args in the future
|
||||
bool common_params_to_map(int argc, char ** argv, llama_example ex, std::map<common_arg, std::string> & out_map);
|
||||
|
||||
// populate preset-only arguments
|
||||
// these arguments are not treated as command line arguments
|
||||
// see: https://github.com/ggml-org/llama.cpp/issues/18163
|
||||
void common_params_add_preset_options(std::vector<common_arg> & args);
|
||||
|
||||
// initialize argument parser context - used by test-arg-parser and preset
|
||||
common_params_context common_params_parser_init(common_params & params, llama_example ex, void(*print_usage)(int, char **) = nullptr);
|
||||
|
||||
|
|
|
|||
|
|
@ -4,9 +4,14 @@
|
|||
|
||||
using json = nlohmann::json;
|
||||
|
||||
static std::string_view trim_trailing_space(std::string_view sv) {
|
||||
static std::string_view trim_trailing_space(std::string_view sv, int max = -1) {
|
||||
int count = 0;
|
||||
while (!sv.empty() && std::isspace(static_cast<unsigned char>(sv.back()))) {
|
||||
if (max != -1 && count <= max) {
|
||||
break;
|
||||
}
|
||||
sv.remove_suffix(1);
|
||||
count++;
|
||||
}
|
||||
return sv;
|
||||
}
|
||||
|
|
@ -93,7 +98,7 @@ void common_chat_peg_constructed_mapper::map(const common_peg_ast_node & node) {
|
|||
|
||||
if (is_arg_string && current_tool) {
|
||||
// Serialize to JSON, but exclude the end quote
|
||||
std::string dumped = json(node.text).dump();
|
||||
std::string dumped = json(trim_trailing_space(node.text)).dump();
|
||||
current_tool->arguments += dumped.substr(0, dumped.size() - 1);
|
||||
needs_closing_quote = true;
|
||||
}
|
||||
|
|
@ -101,6 +106,7 @@ void common_chat_peg_constructed_mapper::map(const common_peg_ast_node & node) {
|
|||
if (is_arg_close && current_tool) {
|
||||
if (needs_closing_quote) {
|
||||
current_tool->arguments += "\"";
|
||||
needs_closing_quote = false;
|
||||
}
|
||||
}
|
||||
|
||||
|
|
@ -109,6 +115,10 @@ void common_chat_peg_constructed_mapper::map(const common_peg_ast_node & node) {
|
|||
}
|
||||
|
||||
if (is_tool_close && current_tool) {
|
||||
if (needs_closing_quote) {
|
||||
current_tool->arguments += "\"";
|
||||
needs_closing_quote = false;
|
||||
}
|
||||
current_tool->arguments += "}";
|
||||
}
|
||||
}
|
||||
|
|
|
|||
140
common/chat.cpp
140
common/chat.cpp
|
|
@ -711,6 +711,25 @@ static void foreach_function(const json & tools, const std::function<void(const
|
|||
}
|
||||
}
|
||||
|
||||
static void foreach_parameter(const json & function, const std::function<void(const std::string &, const json &, bool)> & fn) {
|
||||
if (!function.contains("parameters") || !function.at("parameters").is_object()) {
|
||||
return;
|
||||
}
|
||||
const auto & params = function.at("parameters");
|
||||
if (!params.contains("properties") || !params.at("properties").is_object()) {
|
||||
return;
|
||||
}
|
||||
const auto & props = params.at("properties");
|
||||
std::set<std::string> required;
|
||||
if (params.contains("required") && params.at("required").is_array()) {
|
||||
params.at("required").get_to(required);
|
||||
}
|
||||
for (const auto & [name, prop] : props.items()) {
|
||||
bool is_required = (required.find(name) != required.end());
|
||||
fn(name, prop, is_required);
|
||||
}
|
||||
}
|
||||
|
||||
static std::string apply(
|
||||
const common_chat_template & tmpl,
|
||||
const struct templates_params & inputs,
|
||||
|
|
@ -1409,6 +1428,123 @@ static common_chat_params common_chat_params_init_nemotron_v2(const common_chat_
|
|||
return data;
|
||||
}
|
||||
|
||||
static common_chat_params common_chat_params_init_nemotron_v3(const common_chat_template & tmpl, const struct templates_params & inputs) {
|
||||
common_chat_params data;
|
||||
|
||||
data.prompt = apply(tmpl, inputs);
|
||||
data.format = COMMON_CHAT_FORMAT_PEG_CONSTRUCTED;
|
||||
|
||||
// Handle thinking tags appropriately based on inputs.enable_thinking
|
||||
if (string_ends_with(data.prompt, "<think>\n")) {
|
||||
if (!inputs.enable_thinking) {
|
||||
data.prompt += "</think>";
|
||||
} else {
|
||||
data.thinking_forced_open = true;
|
||||
}
|
||||
}
|
||||
|
||||
data.preserved_tokens = {
|
||||
"<think>",
|
||||
"</think>",
|
||||
"<tool_call>",
|
||||
"</tool_call>",
|
||||
};
|
||||
|
||||
auto has_tools = inputs.tools.is_array() && !inputs.tools.empty();
|
||||
auto extract_reasoning = inputs.reasoning_format != COMMON_REASONING_FORMAT_NONE;
|
||||
auto include_grammar = true;
|
||||
|
||||
auto parser = build_chat_peg_constructed_parser([&](auto & p) {
|
||||
auto reasoning = p.eps();
|
||||
if (inputs.enable_thinking && extract_reasoning) {
|
||||
auto reasoning_content = p.reasoning(p.until("</think>")) + ("</think>" | p.end());
|
||||
if (data.thinking_forced_open) {
|
||||
reasoning = reasoning_content;
|
||||
}
|
||||
}
|
||||
|
||||
// Response format parser
|
||||
if (inputs.json_schema.is_object() && !inputs.json_schema.empty()) {
|
||||
return reasoning << p.content(p.schema(p.json(), "response-format", inputs.json_schema));
|
||||
}
|
||||
|
||||
// Tool call parser
|
||||
if (has_tools && inputs.tool_choice != COMMON_CHAT_TOOL_CHOICE_NONE) {
|
||||
auto tool_choice = p.choice();
|
||||
foreach_function(inputs.tools, [&](const json & tool) {
|
||||
const auto & function = tool.at("function");
|
||||
std::string name = function.at("name");
|
||||
auto parameters = function.at("parameters");
|
||||
|
||||
auto schema_info = common_schema_info();
|
||||
schema_info.resolve_refs(parameters);
|
||||
|
||||
auto tool_open = "<function=" + p.tool_name(p.literal(name)) + ">\n";
|
||||
auto tool_close = p.literal("</function>\n");
|
||||
auto args = p.sequence();
|
||||
auto arg_string = p.rule("xml-arg-string", p.until_one_of({
|
||||
"\n</parameter>",
|
||||
"\n<parameter=",
|
||||
"\n</function>"
|
||||
}));
|
||||
|
||||
foreach_parameter(function, [&](const auto & param_name, const json & param_schema, bool is_required) {
|
||||
auto rule_name = "tool-" + name + "-arg-" + param_name;
|
||||
|
||||
auto arg_open = "<parameter=" + p.tool_arg_name(p.literal(param_name)) + ">\n";
|
||||
auto arg_close = p.literal("</parameter>\n");
|
||||
auto arg_value = p.eps();
|
||||
|
||||
if (schema_info.resolves_to_string(param_schema)) {
|
||||
arg_value = p.tool_arg_string_value(arg_string) + "\n";
|
||||
} else {
|
||||
arg_value = p.tool_arg_json_value(p.schema(p.json(), rule_name + "-schema", param_schema));
|
||||
}
|
||||
|
||||
// Model may or my not close with </parameter>
|
||||
auto arg_rule = p.rule(rule_name, p.tool_arg_open(arg_open) + arg_value + p.optional(p.tool_arg_close(arg_close)));
|
||||
args += p.repeat(arg_rule, /* min = */ is_required ? 1 : 0, /* max = */ 1);
|
||||
});
|
||||
|
||||
tool_choice |= p.rule("tool-" + name, p.tool_open(tool_open) + args + p.tool_close(tool_close));
|
||||
});
|
||||
|
||||
auto min_calls = inputs.tool_choice == COMMON_CHAT_TOOL_CHOICE_REQUIRED ? 1 : 0;
|
||||
auto max_calls = inputs.parallel_tool_calls ? -1 : 1;
|
||||
auto tool_call = p.rule("tool-call", "<tool_call>\n" + tool_choice + "</tool_call>" + p.space());
|
||||
auto tool_calls = p.trigger_rule("tool-call-root", p.repeat(tool_call, /* min = */ min_calls, /* max = */ max_calls));
|
||||
|
||||
return reasoning << p.content(p.until("<tool_call>")) << tool_calls;
|
||||
}
|
||||
|
||||
// Content only parser
|
||||
include_grammar = false;
|
||||
return reasoning << p.content(p.rest());
|
||||
});
|
||||
|
||||
data.parser = parser.save();
|
||||
|
||||
if (include_grammar) {
|
||||
data.grammar_lazy = has_tools && inputs.tool_choice == COMMON_CHAT_TOOL_CHOICE_AUTO;
|
||||
|
||||
data.grammar = build_grammar([&](const common_grammar_builder & builder) {
|
||||
foreach_function(inputs.tools, [&](const json & tool) {
|
||||
const auto & function = tool.at("function");
|
||||
auto schema = function.at("parameters");
|
||||
builder.resolve_refs(schema);
|
||||
});
|
||||
parser.build_grammar(builder, data.grammar_lazy);
|
||||
});
|
||||
|
||||
data.grammar_triggers = {
|
||||
{COMMON_GRAMMAR_TRIGGER_TYPE_WORD, "<tool_call>"}
|
||||
};
|
||||
}
|
||||
|
||||
return data;
|
||||
}
|
||||
|
||||
|
||||
static common_chat_params common_chat_params_init_apertus(const common_chat_template & tmpl, const struct templates_params & inputs) {
|
||||
common_chat_params data;
|
||||
|
||||
|
|
@ -2534,6 +2670,10 @@ static common_chat_params common_chat_templates_apply_jinja(
|
|||
src.find("<function=") != std::string::npos &&
|
||||
src.find("<parameters>") != std::string::npos &&
|
||||
src.find("<parameter=") != std::string::npos) {
|
||||
// Nemotron 3 Nano 30B A3B
|
||||
if (src.find("<think>") != std::string::npos) {
|
||||
return common_chat_params_init_nemotron_v3(tmpl, params);
|
||||
}
|
||||
return common_chat_params_init_qwen3_coder_xml(tmpl, params);
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -1078,6 +1078,8 @@ struct common_init_result::impl {
|
|||
impl() = default;
|
||||
~impl() = default;
|
||||
|
||||
// note: the order in which model, context, etc. are declared matters because their destructors will be called bottom-to-top
|
||||
|
||||
llama_model_ptr model;
|
||||
llama_context_ptr context;
|
||||
|
||||
|
|
@ -1092,7 +1094,7 @@ common_init_result::common_init_result(common_params & params) :
|
|||
auto cparams = common_context_params_to_llama(params);
|
||||
|
||||
if (params.fit_params) {
|
||||
LOG_INF("%s: fitting params to device memory, to report bugs during this step use -fit off (or --verbose if you can't)\n", __func__);
|
||||
LOG_INF("%s: fitting params to device memory, for bugs during this step try to reproduce them with -fit off, or provide --verbose logs if the bug only occurs with -fit on\n", __func__);
|
||||
llama_params_fit(params.model.path.c_str(), &mparams, &cparams,
|
||||
params.tensor_split, params.tensor_buft_overrides.data(), params.fit_params_target, params.fit_params_min_ctx,
|
||||
params.verbosity >= 4 ? GGML_LOG_LEVEL_DEBUG : GGML_LOG_LEVEL_ERROR);
|
||||
|
|
|
|||
|
|
@ -475,7 +475,8 @@ struct common_params {
|
|||
bool enable_chat_template = true;
|
||||
common_reasoning_format reasoning_format = COMMON_REASONING_FORMAT_DEEPSEEK;
|
||||
int reasoning_budget = -1;
|
||||
bool prefill_assistant = true; // if true, any trailing assistant message will be prefilled into the response
|
||||
bool prefill_assistant = true; // if true, any trailing assistant message will be prefilled into the response
|
||||
int sleep_idle_seconds = -1; // if >0, server will sleep after this many seconds of idle time
|
||||
|
||||
std::vector<std::string> api_keys;
|
||||
|
||||
|
|
@ -484,8 +485,11 @@ struct common_params {
|
|||
|
||||
std::map<std::string, std::string> default_template_kwargs;
|
||||
|
||||
// webui configs
|
||||
bool webui = true;
|
||||
std::string webui_config_json;
|
||||
|
||||
// "advanced" endpoints are disabled by default for better security
|
||||
bool webui = true;
|
||||
bool endpoint_slots = true;
|
||||
bool endpoint_props = false; // only control POST requests, not GET
|
||||
bool endpoint_metrics = false;
|
||||
|
|
|
|||
|
|
@ -305,8 +305,9 @@ static std::string format_literal(const std::string & literal) {
|
|||
|
||||
std::string gbnf_format_literal(const std::string & literal) { return format_literal(literal); }
|
||||
|
||||
class SchemaConverter {
|
||||
class common_schema_converter {
|
||||
private:
|
||||
friend class common_schema_info;
|
||||
friend std::string build_grammar(const std::function<void(const common_grammar_builder &)> & cb, const common_grammar_options & options);
|
||||
std::function<json(const std::string &)> _fetch_json;
|
||||
bool _dotall;
|
||||
|
|
@ -729,7 +730,7 @@ private:
|
|||
}
|
||||
|
||||
public:
|
||||
SchemaConverter(
|
||||
common_schema_converter(
|
||||
const std::function<json(const std::string &)> & fetch_json,
|
||||
bool dotall)
|
||||
: _fetch_json(fetch_json), _dotall(dotall)
|
||||
|
|
@ -990,6 +991,134 @@ public:
|
|||
}
|
||||
};
|
||||
|
||||
// common_schema_info implementation (pimpl)
|
||||
|
||||
common_schema_info::common_schema_info()
|
||||
: impl_(std::make_unique<common_schema_converter>(
|
||||
[](const std::string &) { return json(); },
|
||||
false)) {}
|
||||
|
||||
common_schema_info::~common_schema_info() = default;
|
||||
|
||||
common_schema_info::common_schema_info(common_schema_info &&) noexcept = default;
|
||||
common_schema_info & common_schema_info::operator=(common_schema_info &&) noexcept = default;
|
||||
|
||||
void common_schema_info::resolve_refs(nlohmann::ordered_json & schema) {
|
||||
impl_->resolve_refs(schema, "");
|
||||
}
|
||||
|
||||
// Determines if a JSON schema can resolve to a string type through any path.
|
||||
// Some models emit raw string values rather than JSON-encoded strings for string parameters.
|
||||
// If any branch of the schema (via oneOf, anyOf, $ref, etc.) permits a string, this returns
|
||||
// true, allowing callers to handle the value as a raw string for simplicity.
|
||||
bool common_schema_info::resolves_to_string(const nlohmann::ordered_json & schema) {
|
||||
std::unordered_set<std::string> visited_refs;
|
||||
|
||||
std::function<bool(const json &)> check = [&](const json & s) -> bool {
|
||||
if (!s.is_object()) {
|
||||
return false;
|
||||
}
|
||||
|
||||
// Handle $ref
|
||||
if (s.contains("$ref")) {
|
||||
const std::string & ref = s["$ref"];
|
||||
if (visited_refs.find(ref) != visited_refs.end()) {
|
||||
// Circular reference, assume not a string to be safe
|
||||
return false;
|
||||
}
|
||||
visited_refs.insert(ref);
|
||||
auto it = impl_->_refs.find(ref);
|
||||
if (it != impl_->_refs.end()) {
|
||||
return check(it->second);
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
// Check type field
|
||||
if (s.contains("type")) {
|
||||
const json & schema_type = s["type"];
|
||||
if (schema_type.is_string()) {
|
||||
if (schema_type == "string") {
|
||||
return true;
|
||||
}
|
||||
} else if (schema_type.is_array()) {
|
||||
// Type can be an array like ["string", "null"]
|
||||
for (const auto & t : schema_type) {
|
||||
if (t == "string") {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Check oneOf/anyOf - if any alternative can be a string
|
||||
if (s.contains("oneOf")) {
|
||||
for (const auto & alt : s["oneOf"]) {
|
||||
if (check(alt)) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
}
|
||||
if (s.contains("anyOf")) {
|
||||
for (const auto & alt : s["anyOf"]) {
|
||||
if (check(alt)) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Check allOf - all components must be compatible with string type
|
||||
if (s.contains("allOf")) {
|
||||
bool all_string = true;
|
||||
for (const auto & component : s["allOf"]) {
|
||||
if (!check(component)) {
|
||||
all_string = false;
|
||||
break;
|
||||
}
|
||||
}
|
||||
if (all_string) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
|
||||
// Check const - if the constant value is a string
|
||||
if (s.contains("const")) {
|
||||
if (s["const"].is_string()) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
|
||||
// Check enum - if any enum value is a string
|
||||
if (s.contains("enum")) {
|
||||
for (const auto & val : s["enum"]) {
|
||||
if (val.is_string()) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// String-specific keywords imply string type
|
||||
if (s.contains("pattern") || s.contains("minLength") || s.contains("maxLength")) {
|
||||
return true;
|
||||
}
|
||||
|
||||
// Check format - many formats imply string
|
||||
if (s.contains("format")) {
|
||||
const std::string & fmt = s["format"];
|
||||
if (fmt == "date" || fmt == "time" || fmt == "date-time" ||
|
||||
fmt == "uri" || fmt == "email" || fmt == "hostname" ||
|
||||
fmt == "ipv4" || fmt == "ipv6" || fmt == "uuid" ||
|
||||
fmt.find("uuid") == 0) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
|
||||
return false;
|
||||
};
|
||||
|
||||
return check(schema);
|
||||
}
|
||||
|
||||
std::string json_schema_to_grammar(const json & schema, bool force_gbnf) {
|
||||
#ifdef LLAMA_USE_LLGUIDANCE
|
||||
if (!force_gbnf) {
|
||||
|
|
@ -1006,7 +1135,7 @@ std::string json_schema_to_grammar(const json & schema, bool force_gbnf) {
|
|||
}
|
||||
|
||||
std::string build_grammar(const std::function<void(const common_grammar_builder &)> & cb, const common_grammar_options & options) {
|
||||
SchemaConverter converter([&](const std::string &) { return json(); }, options.dotall);
|
||||
common_schema_converter converter([&](const std::string &) { return json(); }, options.dotall);
|
||||
common_grammar_builder builder {
|
||||
/* .add_rule = */ [&](const std::string & name, const std::string & rule) {
|
||||
return converter._add_rule(name, rule);
|
||||
|
|
|
|||
|
|
@ -3,11 +3,31 @@
|
|||
#include <nlohmann/json_fwd.hpp>
|
||||
|
||||
#include <functional>
|
||||
#include <memory>
|
||||
#include <string>
|
||||
|
||||
std::string json_schema_to_grammar(const nlohmann::ordered_json & schema,
|
||||
bool force_gbnf = false);
|
||||
|
||||
class common_schema_converter;
|
||||
|
||||
// Probes a JSON schema to extract information about its structure and type constraints.
|
||||
class common_schema_info {
|
||||
std::unique_ptr<common_schema_converter> impl_;
|
||||
|
||||
public:
|
||||
common_schema_info();
|
||||
~common_schema_info();
|
||||
|
||||
common_schema_info(const common_schema_info &) = delete;
|
||||
common_schema_info & operator=(const common_schema_info &) = delete;
|
||||
common_schema_info(common_schema_info &&) noexcept;
|
||||
common_schema_info & operator=(common_schema_info &&) noexcept;
|
||||
|
||||
void resolve_refs(nlohmann::ordered_json & schema);
|
||||
bool resolves_to_string(const nlohmann::ordered_json & schema);
|
||||
};
|
||||
|
||||
struct common_grammar_builder {
|
||||
std::function<std::string(const std::string &, const std::string &)> add_rule;
|
||||
std::function<std::string(const std::string &, const nlohmann::ordered_json &)> add_schema;
|
||||
|
|
|
|||
|
|
@ -425,7 +425,7 @@ struct parser_executor {
|
|||
|
||||
if (result.need_more_input()) {
|
||||
// Propagate - need to know what child would match before negating
|
||||
return result;
|
||||
return common_peg_parse_result(COMMON_PEG_PARSE_RESULT_NEED_MORE_INPUT, start_pos);
|
||||
}
|
||||
|
||||
// Child failed, so negation succeeds
|
||||
|
|
|
|||
|
|
@ -2,6 +2,7 @@
|
|||
#include "preset.h"
|
||||
#include "peg-parser.h"
|
||||
#include "log.h"
|
||||
#include "download.h"
|
||||
|
||||
#include <fstream>
|
||||
#include <sstream>
|
||||
|
|
@ -15,11 +16,22 @@ static std::string rm_leading_dashes(const std::string & str) {
|
|||
return str.substr(pos);
|
||||
}
|
||||
|
||||
std::vector<std::string> common_preset::to_args() const {
|
||||
std::vector<std::string> common_preset::to_args(const std::string & bin_path) const {
|
||||
std::vector<std::string> args;
|
||||
|
||||
if (!bin_path.empty()) {
|
||||
args.push_back(bin_path);
|
||||
}
|
||||
|
||||
for (const auto & [opt, value] : options) {
|
||||
args.push_back(opt.args.back()); // use the last arg as the main arg
|
||||
if (opt.is_preset_only) {
|
||||
continue; // skip preset-only options (they are not CLI args)
|
||||
}
|
||||
|
||||
// use the last arg as the main arg (i.e. --long-form)
|
||||
args.push_back(opt.args.back());
|
||||
|
||||
// handle value(s)
|
||||
if (opt.value_hint == nullptr && opt.value_hint_2 == nullptr) {
|
||||
// flag option, no value
|
||||
if (common_arg_utils::is_falsey(value)) {
|
||||
|
|
@ -63,6 +75,52 @@ std::string common_preset::to_ini() const {
|
|||
return ss.str();
|
||||
}
|
||||
|
||||
void common_preset::set_option(const common_preset_context & ctx, const std::string & env, const std::string & value) {
|
||||
// try if option exists, update it
|
||||
for (auto & [opt, val] : options) {
|
||||
if (opt.env && env == opt.env) {
|
||||
val = value;
|
||||
return;
|
||||
}
|
||||
}
|
||||
// if option does not exist, we need to add it
|
||||
if (ctx.key_to_opt.find(env) == ctx.key_to_opt.end()) {
|
||||
throw std::runtime_error(string_format(
|
||||
"%s: option with env '%s' not found in ctx_params",
|
||||
__func__, env.c_str()
|
||||
));
|
||||
}
|
||||
options[ctx.key_to_opt.at(env)] = value;
|
||||
}
|
||||
|
||||
void common_preset::unset_option(const std::string & env) {
|
||||
for (auto it = options.begin(); it != options.end(); ) {
|
||||
const common_arg & opt = it->first;
|
||||
if (opt.env && env == opt.env) {
|
||||
it = options.erase(it);
|
||||
return;
|
||||
} else {
|
||||
++it;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
bool common_preset::get_option(const std::string & env, std::string & value) const {
|
||||
for (const auto & [opt, val] : options) {
|
||||
if (opt.env && env == opt.env) {
|
||||
value = val;
|
||||
return true;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
|
||||
void common_preset::merge(const common_preset & other) {
|
||||
for (const auto & [opt, val] : other.options) {
|
||||
options[opt] = val; // overwrite existing options
|
||||
}
|
||||
}
|
||||
|
||||
static std::map<std::string, std::map<std::string, std::string>> parse_ini_from_file(const std::string & path) {
|
||||
std::map<std::string, std::map<std::string, std::string>> parsed;
|
||||
|
||||
|
|
@ -172,9 +230,14 @@ static std::string parse_bool_arg(const common_arg & arg, const std::string & ke
|
|||
return value;
|
||||
}
|
||||
|
||||
common_presets common_presets_load(const std::string & path, common_params_context & ctx_params) {
|
||||
common_preset_context::common_preset_context(llama_example ex)
|
||||
: ctx_params(common_params_parser_init(default_params, ex)) {
|
||||
common_params_add_preset_options(ctx_params.options);
|
||||
key_to_opt = get_map_key_opt(ctx_params);
|
||||
}
|
||||
|
||||
common_presets common_preset_context::load_from_ini(const std::string & path, common_preset & global) const {
|
||||
common_presets out;
|
||||
auto key_to_opt = get_map_key_opt(ctx_params);
|
||||
auto ini_data = parse_ini_from_file(path);
|
||||
|
||||
for (auto section : ini_data) {
|
||||
|
|
@ -188,7 +251,7 @@ common_presets common_presets_load(const std::string & path, common_params_conte
|
|||
for (const auto & [key, value] : section.second) {
|
||||
LOG_DBG("option: %s = %s\n", key.c_str(), value.c_str());
|
||||
if (key_to_opt.find(key) != key_to_opt.end()) {
|
||||
auto & opt = key_to_opt[key];
|
||||
const auto & opt = key_to_opt.at(key);
|
||||
if (is_bool_arg(opt)) {
|
||||
preset.options[opt] = parse_bool_arg(opt, key, value);
|
||||
} else {
|
||||
|
|
@ -199,8 +262,137 @@ common_presets common_presets_load(const std::string & path, common_params_conte
|
|||
// TODO: maybe warn about unknown key?
|
||||
}
|
||||
}
|
||||
|
||||
if (preset.name == "*") {
|
||||
// handle global preset
|
||||
global = preset;
|
||||
} else {
|
||||
out[preset.name] = preset;
|
||||
}
|
||||
}
|
||||
|
||||
return out;
|
||||
}
|
||||
|
||||
common_presets common_preset_context::load_from_cache() const {
|
||||
common_presets out;
|
||||
|
||||
auto cached_models = common_list_cached_models();
|
||||
for (const auto & model : cached_models) {
|
||||
common_preset preset;
|
||||
preset.name = model.to_string();
|
||||
preset.set_option(*this, "LLAMA_ARG_HF_REPO", model.to_string());
|
||||
out[preset.name] = preset;
|
||||
}
|
||||
|
||||
return out;
|
||||
}
|
||||
|
||||
struct local_model {
|
||||
std::string name;
|
||||
std::string path;
|
||||
std::string path_mmproj;
|
||||
};
|
||||
|
||||
common_presets common_preset_context::load_from_models_dir(const std::string & models_dir) const {
|
||||
if (!std::filesystem::exists(models_dir) || !std::filesystem::is_directory(models_dir)) {
|
||||
throw std::runtime_error(string_format("error: '%s' does not exist or is not a directory\n", models_dir.c_str()));
|
||||
}
|
||||
|
||||
std::vector<local_model> models;
|
||||
auto scan_subdir = [&models](const std::string & subdir_path, const std::string & name) {
|
||||
auto files = fs_list(subdir_path, false);
|
||||
common_file_info model_file;
|
||||
common_file_info first_shard_file;
|
||||
common_file_info mmproj_file;
|
||||
for (const auto & file : files) {
|
||||
if (string_ends_with(file.name, ".gguf")) {
|
||||
if (file.name.find("mmproj") != std::string::npos) {
|
||||
mmproj_file = file;
|
||||
} else if (file.name.find("-00001-of-") != std::string::npos) {
|
||||
first_shard_file = file;
|
||||
} else {
|
||||
model_file = file;
|
||||
}
|
||||
}
|
||||
}
|
||||
// single file model
|
||||
local_model model{
|
||||
/* name */ name,
|
||||
/* path */ first_shard_file.path.empty() ? model_file.path : first_shard_file.path,
|
||||
/* path_mmproj */ mmproj_file.path // can be empty
|
||||
};
|
||||
if (!model.path.empty()) {
|
||||
models.push_back(model);
|
||||
}
|
||||
};
|
||||
|
||||
auto files = fs_list(models_dir, true);
|
||||
for (const auto & file : files) {
|
||||
if (file.is_dir) {
|
||||
scan_subdir(file.path, file.name);
|
||||
} else if (string_ends_with(file.name, ".gguf")) {
|
||||
// single file model
|
||||
std::string name = file.name;
|
||||
string_replace_all(name, ".gguf", "");
|
||||
local_model model{
|
||||
/* name */ name,
|
||||
/* path */ file.path,
|
||||
/* path_mmproj */ ""
|
||||
};
|
||||
models.push_back(model);
|
||||
}
|
||||
}
|
||||
|
||||
// convert local models to presets
|
||||
common_presets out;
|
||||
for (const auto & model : models) {
|
||||
common_preset preset;
|
||||
preset.name = model.name;
|
||||
preset.set_option(*this, "LLAMA_ARG_MODEL", model.path);
|
||||
if (!model.path_mmproj.empty()) {
|
||||
preset.set_option(*this, "LLAMA_ARG_MMPROJ", model.path_mmproj);
|
||||
}
|
||||
out[preset.name] = preset;
|
||||
}
|
||||
|
||||
return out;
|
||||
}
|
||||
|
||||
common_preset common_preset_context::load_from_args(int argc, char ** argv) const {
|
||||
common_preset preset;
|
||||
preset.name = COMMON_PRESET_DEFAULT_NAME;
|
||||
|
||||
bool ok = common_params_to_map(argc, argv, ctx_params.ex, preset.options);
|
||||
if (!ok) {
|
||||
throw std::runtime_error("failed to parse CLI arguments into preset");
|
||||
}
|
||||
|
||||
return preset;
|
||||
}
|
||||
|
||||
common_presets common_preset_context::cascade(const common_presets & base, const common_presets & added) const {
|
||||
common_presets out = base; // copy
|
||||
for (const auto & [name, preset_added] : added) {
|
||||
if (out.find(name) != out.end()) {
|
||||
// if exists, merge
|
||||
common_preset & target = out[name];
|
||||
target.merge(preset_added);
|
||||
} else {
|
||||
// otherwise, add directly
|
||||
out[name] = preset_added;
|
||||
}
|
||||
}
|
||||
return out;
|
||||
}
|
||||
|
||||
common_presets common_preset_context::cascade(const common_preset & base, const common_presets & presets) const {
|
||||
common_presets out;
|
||||
for (const auto & [name, preset] : presets) {
|
||||
common_preset tmp = base; // copy
|
||||
tmp.name = name;
|
||||
tmp.merge(preset);
|
||||
out[name] = std::move(tmp);
|
||||
}
|
||||
return out;
|
||||
}
|
||||
|
|
|
|||
|
|
@ -13,20 +13,62 @@
|
|||
|
||||
constexpr const char * COMMON_PRESET_DEFAULT_NAME = "default";
|
||||
|
||||
struct common_preset_context;
|
||||
|
||||
struct common_preset {
|
||||
std::string name;
|
||||
// TODO: support repeated args in the future
|
||||
|
||||
// options are stored as common_arg to string mapping, representing CLI arg and its value
|
||||
std::map<common_arg, std::string> options;
|
||||
|
||||
// convert preset to CLI argument list
|
||||
std::vector<std::string> to_args() const;
|
||||
std::vector<std::string> to_args(const std::string & bin_path = "") const;
|
||||
|
||||
// convert preset to INI format string
|
||||
std::string to_ini() const;
|
||||
|
||||
// TODO: maybe implement to_env() if needed
|
||||
|
||||
// modify preset options where argument is identified by its env variable
|
||||
void set_option(const common_preset_context & ctx, const std::string & env, const std::string & value);
|
||||
|
||||
// unset option by its env variable
|
||||
void unset_option(const std::string & env);
|
||||
|
||||
// get option value by its env variable, return false if not found
|
||||
bool get_option(const std::string & env, std::string & value) const;
|
||||
|
||||
// merge another preset into this one, overwriting existing options
|
||||
void merge(const common_preset & other);
|
||||
};
|
||||
|
||||
// interface for multiple presets in one file
|
||||
using common_presets = std::map<std::string, common_preset>;
|
||||
common_presets common_presets_load(const std::string & path, common_params_context & ctx_params);
|
||||
|
||||
// context for loading and editing presets
|
||||
struct common_preset_context {
|
||||
common_params default_params; // unused for now
|
||||
common_params_context ctx_params;
|
||||
std::map<std::string, common_arg> key_to_opt;
|
||||
common_preset_context(llama_example ex);
|
||||
|
||||
// load presets from INI file
|
||||
common_presets load_from_ini(const std::string & path, common_preset & global) const;
|
||||
|
||||
// generate presets from cached models
|
||||
common_presets load_from_cache() const;
|
||||
|
||||
// generate presets from local models directory
|
||||
// for the directory structure, see "Using multiple models" in server/README.md
|
||||
common_presets load_from_models_dir(const std::string & models_dir) const;
|
||||
|
||||
// generate one preset from CLI arguments
|
||||
common_preset load_from_args(int argc, char ** argv) const;
|
||||
|
||||
// cascade multiple presets if exist on both: base < added
|
||||
// if preset does not exist in base, it will be added without modification
|
||||
common_presets cascade(const common_presets & base, const common_presets & added) const;
|
||||
|
||||
// apply presets over a base preset (same idea as CSS cascading)
|
||||
common_presets cascade(const common_preset & base, const common_presets & presets) const;
|
||||
};
|
||||
|
|
|
|||
|
|
@ -104,10 +104,9 @@ struct ring_buffer {
|
|||
struct common_sampler {
|
||||
common_params_sampling params;
|
||||
|
||||
struct llama_sampler * grmr;
|
||||
struct llama_sampler * chain;
|
||||
|
||||
bool grammar;
|
||||
|
||||
ring_buffer<llama_token> prev;
|
||||
|
||||
std::vector<llama_token_data> cur;
|
||||
|
|
@ -167,15 +166,14 @@ struct common_sampler * common_sampler_init(const struct llama_model * model, co
|
|||
|
||||
lparams.no_perf = params.no_perf;
|
||||
|
||||
llama_sampler * grmr = nullptr;
|
||||
llama_sampler * chain = llama_sampler_chain_init(lparams);
|
||||
|
||||
bool grammar = false;
|
||||
std::vector<llama_sampler *> samplers;
|
||||
|
||||
if (params.grammar.compare(0, 11, "%llguidance") == 0) {
|
||||
#ifdef LLAMA_USE_LLGUIDANCE
|
||||
samplers.push_back(llama_sampler_init_llg(vocab, "lark", params.grammar.c_str()));
|
||||
grammar = true;
|
||||
grmr = llama_sampler_init_llg(vocab, "lark", params.grammar.c_str());
|
||||
#else
|
||||
GGML_ABORT("llguidance (cmake -DLLAMA_LLGUIDANCE=ON) is not enabled");
|
||||
#endif // LLAMA_USE_LLGUIDANCE
|
||||
|
|
@ -224,15 +222,12 @@ struct common_sampler * common_sampler_init(const struct llama_model * model, co
|
|||
|
||||
if (!params.grammar.empty()) {
|
||||
if (params.grammar_lazy) {
|
||||
samplers.push_back(
|
||||
llama_sampler_init_grammar_lazy_patterns(vocab, params.grammar.c_str(), "root",
|
||||
trigger_patterns_c.data(), trigger_patterns_c.size(),
|
||||
trigger_tokens.data(), trigger_tokens.size()));
|
||||
grmr = llama_sampler_init_grammar_lazy_patterns(vocab, params.grammar.c_str(), "root",
|
||||
trigger_patterns_c.data(), trigger_patterns_c.size(),
|
||||
trigger_tokens.data(), trigger_tokens.size());
|
||||
} else {
|
||||
samplers.push_back(llama_sampler_init_grammar(vocab, params.grammar.c_str(), "root"));
|
||||
grmr = llama_sampler_init_grammar(vocab, params.grammar.c_str(), "root");
|
||||
}
|
||||
|
||||
grammar = true;
|
||||
}
|
||||
}
|
||||
|
||||
|
|
@ -303,8 +298,8 @@ struct common_sampler * common_sampler_init(const struct llama_model * model, co
|
|||
|
||||
auto * result = new common_sampler {
|
||||
/* .params = */ params,
|
||||
/* .grmr = */ grmr,
|
||||
/* .chain = */ chain,
|
||||
/* .grammar = */ grammar,
|
||||
/* .prev = */ ring_buffer<llama_token>(std::max(32, params.n_prev)),
|
||||
/* .cur = */ {},
|
||||
/* .cur_p = */ {},
|
||||
|
|
@ -315,6 +310,7 @@ struct common_sampler * common_sampler_init(const struct llama_model * model, co
|
|||
|
||||
void common_sampler_free(struct common_sampler * gsmpl) {
|
||||
if (gsmpl) {
|
||||
llama_sampler_free(gsmpl->grmr);
|
||||
llama_sampler_free(gsmpl->chain);
|
||||
|
||||
delete gsmpl;
|
||||
|
|
@ -324,25 +320,12 @@ void common_sampler_free(struct common_sampler * gsmpl) {
|
|||
void common_sampler_accept(struct common_sampler * gsmpl, llama_token token, bool accept_grammar) {
|
||||
const auto tm = gsmpl->tm();
|
||||
|
||||
if (gsmpl->grammar) {
|
||||
const int n_smpl = llama_sampler_chain_n(gsmpl->chain);
|
||||
|
||||
for (int i = 0; i < n_smpl; i++) {
|
||||
auto * smpl = llama_sampler_chain_get(gsmpl->chain, i);
|
||||
|
||||
// the grammar sampler is always the first one
|
||||
if (i == 0) {
|
||||
if (accept_grammar) {
|
||||
llama_sampler_accept(smpl, token);
|
||||
}
|
||||
} else {
|
||||
llama_sampler_accept(smpl, token);
|
||||
}
|
||||
}
|
||||
} else {
|
||||
llama_sampler_accept(gsmpl->chain, token);
|
||||
if (gsmpl->grmr && accept_grammar) {
|
||||
llama_sampler_accept(gsmpl->grmr, token);
|
||||
}
|
||||
|
||||
llama_sampler_accept(gsmpl->chain, token);
|
||||
|
||||
gsmpl->prev.push_back(token);
|
||||
}
|
||||
|
||||
|
|
@ -353,8 +336,8 @@ void common_sampler_reset(struct common_sampler * gsmpl) {
|
|||
struct common_sampler * common_sampler_clone(common_sampler * gsmpl) {
|
||||
return new common_sampler {
|
||||
/* .params = */ gsmpl->params,
|
||||
/* .grmr = */ llama_sampler_clone(gsmpl->grmr),
|
||||
/* .chain = */ llama_sampler_clone(gsmpl->chain),
|
||||
/* .grammar = */ gsmpl->grammar,
|
||||
/* .prev = */ gsmpl->prev,
|
||||
/* .cur = */ gsmpl->cur,
|
||||
/* .cur_p = */ gsmpl->cur_p,
|
||||
|
|
@ -410,7 +393,7 @@ struct llama_sampler * common_sampler_get(const struct common_sampler * gsmpl) {
|
|||
return gsmpl->chain;
|
||||
}
|
||||
|
||||
llama_token common_sampler_sample(struct common_sampler * gsmpl, struct llama_context * ctx, int idx) {
|
||||
llama_token common_sampler_sample(struct common_sampler * gsmpl, struct llama_context * ctx, int idx, bool grammar_first) {
|
||||
llama_synchronize(ctx);
|
||||
|
||||
// start measuring sampling time after the llama_context synchronization in order to not measure any ongoing async operations
|
||||
|
|
@ -418,11 +401,42 @@ llama_token common_sampler_sample(struct common_sampler * gsmpl, struct llama_co
|
|||
|
||||
llama_token id = LLAMA_TOKEN_NULL;
|
||||
|
||||
auto & grmr = gsmpl->grmr;
|
||||
auto & chain = gsmpl->chain;
|
||||
auto & cur_p = gsmpl->cur_p; // initialized by set_logits
|
||||
|
||||
gsmpl->set_logits(ctx, idx);
|
||||
|
||||
if (grammar_first) {
|
||||
llama_sampler_apply(grmr, &cur_p);
|
||||
}
|
||||
|
||||
llama_sampler_apply(chain, &cur_p);
|
||||
|
||||
id = cur_p.data[cur_p.selected].id;
|
||||
|
||||
if (grammar_first) {
|
||||
return id;
|
||||
}
|
||||
|
||||
// check if it the sampled token fits the grammar (grammar-based rejection sampling)
|
||||
{
|
||||
llama_token_data single_token_data = { id, 1.0f, 0.0f };
|
||||
llama_token_data_array single_token_data_array = { &single_token_data, 1, -1, false };
|
||||
|
||||
llama_sampler_apply(grmr, &single_token_data_array);
|
||||
|
||||
const bool is_valid = single_token_data_array.data[0].logit != -INFINITY;
|
||||
if (is_valid) {
|
||||
return id;
|
||||
}
|
||||
}
|
||||
|
||||
// resampling:
|
||||
// if the token is not valid, sample again, but first apply the grammar sampler and then the sampling chain
|
||||
gsmpl->set_logits(ctx, idx);
|
||||
|
||||
llama_sampler_apply(grmr, &cur_p);
|
||||
llama_sampler_apply(chain, &cur_p);
|
||||
|
||||
GGML_ASSERT(cur_p.selected != -1 && "no selected token during sampling - check your sampling configuration");
|
||||
|
|
@ -432,7 +446,7 @@ llama_token common_sampler_sample(struct common_sampler * gsmpl, struct llama_co
|
|||
return id;
|
||||
}
|
||||
|
||||
std::vector<llama_token> common_sampler_sample_and_accept_n(struct common_sampler * gsmpl, struct llama_context * ctx, const std::vector<int> & idxs, const llama_tokens & draft) {
|
||||
std::vector<llama_token> common_sampler_sample_and_accept_n(struct common_sampler * gsmpl, struct llama_context * ctx, const std::vector<int> & idxs, const llama_tokens & draft, bool grammar_first) {
|
||||
GGML_ASSERT(idxs.size() == draft.size() + 1 && "idxs.size() must be draft.size() + 1");
|
||||
|
||||
std::vector<llama_token> result;
|
||||
|
|
@ -440,7 +454,7 @@ std::vector<llama_token> common_sampler_sample_and_accept_n(struct common_sample
|
|||
|
||||
size_t i = 0;
|
||||
for (; i < draft.size(); i++) {
|
||||
const llama_token id = common_sampler_sample(gsmpl, ctx, idxs[i]);
|
||||
const llama_token id = common_sampler_sample(gsmpl, ctx, idxs[i], grammar_first);
|
||||
|
||||
common_sampler_accept(gsmpl, id, true);
|
||||
|
||||
|
|
@ -452,7 +466,7 @@ std::vector<llama_token> common_sampler_sample_and_accept_n(struct common_sample
|
|||
}
|
||||
|
||||
if (i == draft.size()) {
|
||||
const llama_token id = common_sampler_sample(gsmpl, ctx, idxs[i]);
|
||||
const llama_token id = common_sampler_sample(gsmpl, ctx, idxs[i], grammar_first);
|
||||
|
||||
common_sampler_accept(gsmpl, id, true);
|
||||
|
||||
|
|
@ -462,13 +476,13 @@ std::vector<llama_token> common_sampler_sample_and_accept_n(struct common_sample
|
|||
return result;
|
||||
}
|
||||
|
||||
std::vector<llama_token> common_sampler_sample_and_accept_n(struct common_sampler * gsmpl, struct llama_context * ctx, const llama_tokens & draft) {
|
||||
std::vector<llama_token> common_sampler_sample_and_accept_n(struct common_sampler * gsmpl, struct llama_context * ctx, const llama_tokens & draft, bool grammar_first) {
|
||||
std::vector<int> idxs(draft.size() + 1);
|
||||
for (size_t i = 0; i < idxs.size(); ++i) {
|
||||
idxs[i] = i;
|
||||
}
|
||||
|
||||
return common_sampler_sample_and_accept_n(gsmpl, ctx, idxs, draft);
|
||||
return common_sampler_sample_and_accept_n(gsmpl, ctx, idxs, draft, grammar_first);
|
||||
}
|
||||
|
||||
uint32_t common_sampler_get_seed(const struct common_sampler * gsmpl) {
|
||||
|
|
|
|||
|
|
@ -57,7 +57,10 @@ struct llama_sampler * common_sampler_get(const struct common_sampler * gsmpl);
|
|||
// - check if the token fits the grammar (if any)
|
||||
// - if not: resample by first applying the grammar constraints and then sampling again (slower path)
|
||||
//
|
||||
llama_token common_sampler_sample(struct common_sampler * gsmpl, struct llama_context * ctx, int idx);
|
||||
// if grammar_first is true, the grammar is applied before the samplers (slower)
|
||||
// useful in cases where all the resulting candidates (not just the sampled one) must fit the grammar
|
||||
//
|
||||
llama_token common_sampler_sample(struct common_sampler * gsmpl, struct llama_context * ctx, int idx, bool grammar_first = false);
|
||||
|
||||
// generalized version of common_sampler_sample
|
||||
//
|
||||
|
|
@ -75,10 +78,10 @@ llama_token common_sampler_sample(struct common_sampler * gsmpl, struct llama_co
|
|||
//
|
||||
// returns at least 1 token, up to idxs.size()
|
||||
//
|
||||
std::vector<llama_token> common_sampler_sample_and_accept_n(struct common_sampler * gsmpl, struct llama_context * ctx, const std::vector<int> & idxs, const llama_tokens & draft);
|
||||
std::vector<llama_token> common_sampler_sample_and_accept_n(struct common_sampler * gsmpl, struct llama_context * ctx, const std::vector<int> & idxs, const llama_tokens & draft, bool grammar_first = false);
|
||||
|
||||
// assume idxs == [ 0, 1, 2, ..., draft.size() ]
|
||||
std::vector<llama_token> common_sampler_sample_and_accept_n(struct common_sampler * gsmpl, struct llama_context * ctx, const llama_tokens & draft);
|
||||
std::vector<llama_token> common_sampler_sample_and_accept_n(struct common_sampler * gsmpl, struct llama_context * ctx, const llama_tokens & draft, bool grammar_first = false);
|
||||
|
||||
uint32_t common_sampler_get_seed(const struct common_sampler * gsmpl);
|
||||
|
||||
|
|
|
|||
|
|
@ -315,7 +315,7 @@ llama_tokens common_speculative_gen_draft(
|
|||
for (int i = 0; i < params.n_draft; ++i) {
|
||||
common_batch_clear(batch);
|
||||
|
||||
common_sampler_sample(smpl, ctx_dft, 0);
|
||||
common_sampler_sample(smpl, ctx_dft, 0, true);
|
||||
|
||||
const auto * cur_p = common_sampler_get_candidates(smpl, true);
|
||||
|
||||
|
|
|
|||
|
|
@ -136,29 +136,29 @@ class ModelBase:
|
|||
self.remote_hf_model_id = remote_hf_model_id
|
||||
self.sentence_transformers_dense_modules = sentence_transformers_dense_modules
|
||||
self.hparams = ModelBase.load_hparams(self.dir_model, self.is_mistral_format) if hparams is None else hparams
|
||||
self.rope_parameters = self.hparams.get("rope_parameters", self.hparams.get("rope_scaling")) or {}
|
||||
self.model_tensors = self.index_tensors(remote_hf_model_id=remote_hf_model_id)
|
||||
self.metadata_override = metadata_override
|
||||
self.model_name = model_name
|
||||
self.dir_model_card = dir_model # overridden in convert_lora_to_gguf.py
|
||||
|
||||
# Ensure "rope_theta" and "rope_type" is mirrored in rope_parameters
|
||||
if "full_attention" not in self.rope_parameters and "sliding_attention" not in self.rope_parameters:
|
||||
if "rope_theta" not in self.rope_parameters and (rope_theta := self.find_hparam(["rope_theta", "global_rope_theta", "rotary_emb_base"], optional=True)) is not None:
|
||||
self.rope_parameters["rope_theta"] = rope_theta
|
||||
if "rope_type" not in self.rope_parameters and (rope_type := self.rope_parameters.get("type")) is not None:
|
||||
self.rope_parameters["rope_type"] = rope_type
|
||||
|
||||
# Apply heuristics to figure out typical tensor encoding based on first layer tensor encoding type
|
||||
# Apply heuristics to figure out typical tensor encoding based on first tensor's dtype
|
||||
# NOTE: can't use field "torch_dtype" in config.json, because some finetunes lie.
|
||||
if self.ftype == gguf.LlamaFileType.GUESSED:
|
||||
# NOTE: can't use field "torch_dtype" in config.json, because some finetunes lie.
|
||||
_, first_tensor = next(self.get_tensors())
|
||||
if first_tensor.dtype == torch.float16:
|
||||
logger.info(f"choosing --outtype f16 from first tensor type ({first_tensor.dtype})")
|
||||
self.ftype = gguf.LlamaFileType.MOSTLY_F16
|
||||
for _, tensor in self.get_tensors():
|
||||
if tensor.dim() < 2:
|
||||
continue
|
||||
|
||||
if tensor.dtype == torch.bfloat16:
|
||||
self.ftype = gguf.LlamaFileType.MOSTLY_BF16
|
||||
logger.info("heuristics detected bfloat16 tensor dtype, setting --outtype bf16")
|
||||
break
|
||||
elif tensor.dtype == torch.float16:
|
||||
self.ftype = gguf.LlamaFileType.MOSTLY_F16
|
||||
logger.info("heuristics detected float16 tensor dtype, setting --outtype f16")
|
||||
break
|
||||
else:
|
||||
logger.info(f"choosing --outtype bf16 from first tensor type ({first_tensor.dtype})")
|
||||
self.ftype = gguf.LlamaFileType.MOSTLY_BF16
|
||||
self.ftype = gguf.LlamaFileType.MOSTLY_F16
|
||||
logger.info("heuristics unable to detect tensor dtype, defaulting to --outtype f16")
|
||||
|
||||
self.dequant_model()
|
||||
|
||||
|
|
@ -197,10 +197,10 @@ class ModelBase:
|
|||
return tensors
|
||||
|
||||
prefix = "model" if not self.is_mistral_format else "consolidated"
|
||||
part_names: set[str] = set(ModelBase.get_model_part_names(self.dir_model, prefix, ".safetensors"))
|
||||
part_names: list[str] = ModelBase.get_model_part_names(self.dir_model, prefix, ".safetensors")
|
||||
is_safetensors: bool = len(part_names) > 0
|
||||
if not is_safetensors:
|
||||
part_names = set(ModelBase.get_model_part_names(self.dir_model, "pytorch_model", ".bin"))
|
||||
part_names = ModelBase.get_model_part_names(self.dir_model, "pytorch_model", ".bin")
|
||||
|
||||
tensor_names_from_index: set[str] = set()
|
||||
|
||||
|
|
@ -217,7 +217,8 @@ class ModelBase:
|
|||
if weight_map is None or not isinstance(weight_map, dict):
|
||||
raise ValueError(f"Can't load 'weight_map' from {index_name!r}")
|
||||
tensor_names_from_index.update(weight_map.keys())
|
||||
part_names |= set(weight_map.values())
|
||||
part_dict: dict[str, None] = dict.fromkeys(weight_map.values(), None)
|
||||
part_names = sorted(part_dict.keys())
|
||||
else:
|
||||
weight_map = {}
|
||||
else:
|
||||
|
|
@ -719,6 +720,9 @@ class ModelBase:
|
|||
if "thinker_config" in config:
|
||||
# rename for Qwen2.5-Omni
|
||||
config["text_config"] = config["thinker_config"]["text_config"]
|
||||
if "lfm" in config:
|
||||
# rename for LFM2-Audio
|
||||
config["text_config"] = config["lfm"]
|
||||
return config
|
||||
|
||||
@classmethod
|
||||
|
|
@ -765,6 +769,15 @@ class TextModel(ModelBase):
|
|||
self.block_count = self.find_hparam(["n_layers", "num_hidden_layers", "n_layer", "num_layers"])
|
||||
self.tensor_map = gguf.get_tensor_name_map(self.model_arch, self.block_count)
|
||||
|
||||
self.rope_parameters = self.hparams.get("rope_parameters", self.hparams.get("rope_scaling")) or {}
|
||||
|
||||
# Ensure "rope_theta" and "rope_type" is mirrored in rope_parameters
|
||||
if "full_attention" not in self.rope_parameters and "sliding_attention" not in self.rope_parameters:
|
||||
if "rope_theta" not in self.rope_parameters and (rope_theta := self.find_hparam(["rope_theta", "global_rope_theta", "rotary_emb_base"], optional=True)) is not None:
|
||||
self.rope_parameters["rope_theta"] = rope_theta
|
||||
if "rope_type" not in self.rope_parameters and (rope_type := self.rope_parameters.get("type")) is not None:
|
||||
self.rope_parameters["rope_type"] = rope_type
|
||||
|
||||
@classmethod
|
||||
def __init_subclass__(cls):
|
||||
# can't use an abstract property, because overriding it without type errors
|
||||
|
|
@ -861,6 +874,14 @@ class TextModel(ModelBase):
|
|||
logger.warning(f"Unknown RoPE type: {rope_type}")
|
||||
logger.info(f"gguf: rope scaling type = {rope_gguf_type.name}")
|
||||
|
||||
if "mrope_section" in self.rope_parameters:
|
||||
mrope_section = self.rope_parameters["mrope_section"]
|
||||
# Pad to 4 dimensions [time, height, width, extra]
|
||||
while len(mrope_section) < 4:
|
||||
mrope_section.append(0)
|
||||
self.gguf_writer.add_rope_dimension_sections(mrope_section[:4])
|
||||
logger.info(f"gguf: mrope sections: {mrope_section[:4]}")
|
||||
|
||||
if (rope_theta := rope_params.get("rope_theta")) is not None:
|
||||
self.gguf_writer.add_rope_freq_base(rope_theta)
|
||||
logger.info(f"gguf: rope theta = {rope_theta}")
|
||||
|
|
@ -1203,6 +1224,9 @@ class TextModel(ModelBase):
|
|||
if chkhsh == "f4f37b6c8eb9ea29b3eac6bb8c8487c5ab7885f8d8022e67edc1c68ce8403e95":
|
||||
# ref: https://huggingface.co/MiniMaxAI/MiniMax-M2
|
||||
res = "minimax-m2"
|
||||
if chkhsh == "4a2e2abae11ca2b86d570fc5b44be4d5eb5e72cc8f22dd136a94b37da83ab665":
|
||||
# ref: https://huggingface.co/KORMo-Team/KORMo-tokenizer
|
||||
res = "kormo"
|
||||
|
||||
if res is None:
|
||||
logger.warning("\n")
|
||||
|
|
@ -1826,7 +1850,7 @@ class MmprojModel(ModelBase):
|
|||
|
||||
def tensor_force_quant(self, name, new_name, bid, n_dims):
|
||||
del bid, name, n_dims # unused
|
||||
if ".patch_embd.weight" in new_name:
|
||||
if ".patch_embd.weight" in new_name or ".patch_merger.weight" in new_name:
|
||||
return gguf.GGMLQuantizationType.F16 if self.ftype == gguf.LlamaFileType.MOSTLY_F16 else gguf.GGMLQuantizationType.F32
|
||||
return False
|
||||
|
||||
|
|
@ -3398,7 +3422,7 @@ class QwenModel(TextModel):
|
|||
self._set_vocab_qwen()
|
||||
|
||||
|
||||
@ModelBase.register("Qwen2Model", "Qwen2ForCausalLM", "Qwen2AudioForConditionalGeneration")
|
||||
@ModelBase.register("Qwen2Model", "Qwen2ForCausalLM", "Qwen2AudioForConditionalGeneration", "KORMoForCausalLM")
|
||||
class Qwen2Model(TextModel):
|
||||
model_arch = gguf.MODEL_ARCH.QWEN2
|
||||
|
||||
|
|
@ -3735,9 +3759,6 @@ class Qwen2VLModel(TextModel):
|
|||
|
||||
def set_gguf_parameters(self):
|
||||
super().set_gguf_parameters()
|
||||
mrope_section = self.hparams["rope_scaling"]["mrope_section"]
|
||||
mrope_section += [0] * max(0, 4 - len(mrope_section))
|
||||
self.gguf_writer.add_rope_dimension_sections(mrope_section)
|
||||
|
||||
def set_vocab(self):
|
||||
try:
|
||||
|
|
@ -4373,6 +4394,30 @@ class Qwen3VLVisionModel(MmprojModel):
|
|||
return super().modify_tensors(data_torch, name, bid)
|
||||
|
||||
|
||||
@ModelBase.register("Glm4vForConditionalGeneration", "Glm4vMoeForConditionalGeneration")
|
||||
class Glm4VVisionModel(Qwen3VLVisionModel):
|
||||
def set_gguf_parameters(self):
|
||||
MmprojModel.set_gguf_parameters(self) # skip Qwen3VLVisionModel parameters
|
||||
assert self.hparams_vision is not None
|
||||
self.gguf_writer.add_clip_projector_type(gguf.VisionProjectorType.GLM4V)
|
||||
|
||||
hidden_act = str(self.hparams_vision.get("hidden_act", "")).lower()
|
||||
if hidden_act == "gelu":
|
||||
self.gguf_writer.add_vision_use_gelu(True)
|
||||
elif hidden_act == "silu":
|
||||
self.gguf_writer.add_vision_use_silu(True)
|
||||
|
||||
rms_norm_eps = self.hparams_vision.get("rms_norm_eps", 1e-5)
|
||||
self.gguf_writer.add_vision_attention_layernorm_eps(rms_norm_eps)
|
||||
|
||||
def modify_tensors(self, data_torch: Tensor, name: str, bid: int | None) -> Iterable[tuple[str, Tensor]]:
|
||||
if name.startswith("model.visual."):
|
||||
name = name.replace("model.visual.", "visual.")
|
||||
if name.startswith("visual.merger."):
|
||||
return [(self.map_tensor_name(name), data_torch)]
|
||||
return super().modify_tensors(data_torch, name, bid)
|
||||
|
||||
|
||||
@ModelBase.register("Qwen3VLForConditionalGeneration")
|
||||
class Qwen3VLTextModel(Qwen3Model):
|
||||
model_arch = gguf.MODEL_ARCH.QWEN3VL
|
||||
|
|
@ -4381,20 +4426,6 @@ class Qwen3VLTextModel(Qwen3Model):
|
|||
super().set_gguf_parameters()
|
||||
|
||||
# Handle MRoPE (Multi-axis Rotary Position Embedding) for Qwen3-VL
|
||||
text_config = self.hparams.get("text_config", {})
|
||||
# rope_scaling is deprecated in V5, use rope_parameters instead
|
||||
rope_scaling = text_config.get("rope_scaling") or text_config.get("rope_parameters") or {}
|
||||
|
||||
if rope_scaling.get("mrope_section"):
|
||||
# mrope_section contains [time, height, width] dimensions
|
||||
mrope_section = rope_scaling["mrope_section"]
|
||||
# Pad to 4 dimensions [time, height, width, extra]
|
||||
while len(mrope_section) < 4:
|
||||
mrope_section.append(0)
|
||||
self.gguf_writer.add_rope_dimension_sections(mrope_section[:4])
|
||||
|
||||
logger.info(f"MRoPE sections: {mrope_section[:4]}")
|
||||
|
||||
vision_config = self.hparams.get("vision_config", {})
|
||||
deepstack_layer_num = len(vision_config.get("deepstack_visual_indexes", []))
|
||||
self.gguf_writer.add_num_deepstack_layers(deepstack_layer_num)
|
||||
|
|
@ -4413,22 +4444,6 @@ class Qwen3VLMoeTextModel(Qwen3MoeModel):
|
|||
|
||||
def set_gguf_parameters(self):
|
||||
super().set_gguf_parameters()
|
||||
|
||||
# Handle MRoPE (Multi-axis Rotary Position Embedding) for Qwen3-VL
|
||||
text_config = self.hparams.get("text_config", {})
|
||||
# rope_scaling is deprecated in V5, use rope_parameters instead
|
||||
rope_scaling = text_config.get("rope_scaling") or text_config.get("rope_parameters") or {}
|
||||
|
||||
if rope_scaling.get("mrope_section"):
|
||||
# mrope_section contains [time, height, width] dimensions
|
||||
mrope_section = rope_scaling["mrope_section"]
|
||||
# Pad to 4 dimensions [time, height, width, extra]
|
||||
while len(mrope_section) < 4:
|
||||
mrope_section.append(0)
|
||||
self.gguf_writer.add_rope_dimension_sections(mrope_section[:4])
|
||||
|
||||
logger.info(f"MRoPE sections: {mrope_section[:4]}")
|
||||
|
||||
vision_config = self.hparams.get("vision_config", {})
|
||||
deepstack_layer_num = len(vision_config.get("deepstack_visual_indexes", []))
|
||||
self.gguf_writer.add_num_deepstack_layers(deepstack_layer_num)
|
||||
|
|
@ -7791,6 +7806,15 @@ class JaisModel(TextModel):
|
|||
@ModelBase.register("Glm4ForCausalLM", "Glm4vForConditionalGeneration")
|
||||
class Glm4Model(TextModel):
|
||||
model_arch = gguf.MODEL_ARCH.GLM4
|
||||
use_mrope = False
|
||||
partial_rotary_factor = 0.5
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
super().__init__(*args, **kwargs)
|
||||
self.partial_rotary_factor = self.rope_parameters.get("partial_rotary_factor", 0.5)
|
||||
if "mrope_section" in self.rope_parameters:
|
||||
self.use_mrope = True
|
||||
logger.info("Q/K weight will need to be permuted for M-RoPE")
|
||||
|
||||
def set_vocab(self):
|
||||
from transformers import AutoTokenizer
|
||||
|
|
@ -7812,17 +7836,49 @@ class Glm4Model(TextModel):
|
|||
super().set_gguf_parameters()
|
||||
if (rope_dim := self.hparams.get("head_dim")) is None:
|
||||
rope_dim = self.hparams["hidden_size"] // self.hparams["num_attention_heads"]
|
||||
self.gguf_writer.add_rope_dimension_count(int(rope_dim * self.hparams.get("partial_rotary_factor", 0.5)))
|
||||
self.gguf_writer.add_rope_dimension_count(int(rope_dim * self.partial_rotary_factor))
|
||||
|
||||
@staticmethod
|
||||
def normal_to_neox(weights: Tensor, n_head: int, n_head_kv: int, head_dim: int, partial_rotary_factor: float) -> Tensor:
|
||||
orig_shape = weights.shape
|
||||
if len(orig_shape) == 1:
|
||||
weights = weights.unsqueeze(1) # [out_dim, 1]
|
||||
if len(weights.shape) != 2:
|
||||
raise ValueError("Only 1D and 2D tensors are supported.")
|
||||
n_effective_heads = weights.shape[0] // head_dim
|
||||
if n_head_kv is not None and n_effective_heads != n_head:
|
||||
if n_effective_heads != n_head_kv:
|
||||
raise AssertionError(f"Mismatch in effective heads: computed {n_effective_heads}, expected {n_head} or {n_head_kv}")
|
||||
rotary_dim = int(head_dim * partial_rotary_factor)
|
||||
if rotary_dim % 2 != 0:
|
||||
raise ValueError("rotary_dim must be even.")
|
||||
reshaped = weights.reshape(n_effective_heads, head_dim, -1)
|
||||
rot_part = reshaped[:, :rotary_dim, :]
|
||||
non_rot_part = reshaped[:, rotary_dim:, :]
|
||||
permuted_rot = torch.cat((rot_part[:, ::2, :], rot_part[:, 1::2, :]), dim=1)
|
||||
combined = torch.cat((permuted_rot, non_rot_part), dim=1)
|
||||
result = combined.reshape(weights.shape)
|
||||
return result if len(orig_shape) != 1 else result.squeeze(1)
|
||||
|
||||
def modify_tensors(self, data_torch: Tensor, name: str, bid: int | None) -> Iterable[tuple[str, Tensor]]:
|
||||
if name.startswith("model.visual."): # ignore visual part of Glm4v
|
||||
return []
|
||||
elif name.startswith("model.language_model."):
|
||||
name = name.replace("language_model.", "") # for Glm4v
|
||||
if self.use_mrope:
|
||||
n_head = self.hparams["num_attention_heads"]
|
||||
n_kv_head = self.hparams["num_key_value_heads"]
|
||||
n_embd = self.hparams["hidden_size"]
|
||||
head_dim = n_embd // n_head
|
||||
# because llama.cpp M-RoPE kernel only supports Neox ordering, we have to permute the weights here
|
||||
if name.endswith(("q_proj.weight", "q_proj.bias")):
|
||||
data_torch = Glm4Model.normal_to_neox(data_torch, n_head, n_head, head_dim, self.partial_rotary_factor)
|
||||
if name.endswith(("k_proj.weight", "k_proj.bias")):
|
||||
data_torch = Glm4Model.normal_to_neox(data_torch, n_head, n_kv_head, head_dim, self.partial_rotary_factor)
|
||||
return super().modify_tensors(data_torch, name, bid)
|
||||
|
||||
|
||||
@ModelBase.register("Glm4MoeForCausalLM")
|
||||
@ModelBase.register("Glm4MoeForCausalLM", "Glm4vMoeForConditionalGeneration")
|
||||
class Glm4MoeModel(TextModel):
|
||||
model_arch = gguf.MODEL_ARCH.GLM4_MOE
|
||||
|
||||
|
|
@ -7889,6 +7945,7 @@ class Glm4MoeModel(TextModel):
|
|||
|
||||
_experts: list[dict[str, Tensor]] | None = None
|
||||
|
||||
# note: unlike GLM4V non-MoE, we don't need to permute Q/K here since GLM4V_MOE uses Neox ordering already
|
||||
def modify_tensors(
|
||||
self, data_torch: Tensor, name: str, bid: int | None
|
||||
) -> Iterable[tuple[str, Tensor]]:
|
||||
|
|
@ -8486,8 +8543,18 @@ class GraniteHybridModel(Mamba2Model, GraniteMoeModel):
|
|||
class NemotronHModel(GraniteHybridModel):
|
||||
"""Hybrid mamba2/attention model from NVIDIA"""
|
||||
model_arch = gguf.MODEL_ARCH.NEMOTRON_H
|
||||
is_moe: bool = False
|
||||
|
||||
def __init__(self, *args, **kwargs):
|
||||
# We have to determine the correct model architecture (MoE vs non-MoE) before
|
||||
# calling the parent __init__. This is because the parent constructor
|
||||
# uses self.model_arch to build the tensor name map, and all MoE-specific
|
||||
# mappings would be missed if it were called with the default non-MoE arch.
|
||||
hparams = ModelBase.load_hparams(args[0], self.is_mistral_format)
|
||||
if "num_experts_per_tok" in hparams:
|
||||
self.model_arch = gguf.MODEL_ARCH.NEMOTRON_H_MOE
|
||||
self.is_moe = True
|
||||
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
# Save the top-level head_dim for later
|
||||
|
|
@ -8499,9 +8566,11 @@ class NemotronHModel(GraniteHybridModel):
|
|||
|
||||
# Update the ssm / attn / mlp layers
|
||||
# M: Mamba2, *: Attention, -: MLP
|
||||
# MoE:
|
||||
# M: Mamba2, *: Attention, E: Expert
|
||||
hybrid_override_pattern = self.hparams["hybrid_override_pattern"]
|
||||
self._ssm_layers = [i for i, val in enumerate(hybrid_override_pattern) if val == "M"]
|
||||
self._mlp_layers = [i for i, val in enumerate(hybrid_override_pattern) if val == "-"]
|
||||
self._mlp_layers = [i for i, val in enumerate(hybrid_override_pattern) if val == ("E" if self.is_moe else "-")]
|
||||
|
||||
def get_attn_layers(self):
|
||||
hybrid_override_pattern = self.hparams["hybrid_override_pattern"]
|
||||
|
|
@ -8517,10 +8586,28 @@ class NemotronHModel(GraniteHybridModel):
|
|||
# Set feed_forward_length
|
||||
# NOTE: This will trigger an override warning. This is preferrable to
|
||||
# duplicating all the parent logic
|
||||
n_ff = self.find_hparam(["intermediate_size", "n_inner", "hidden_dim"])
|
||||
self.gguf_writer.add_feed_forward_length([
|
||||
n_ff if i in self._mlp_layers else 0 for i in range(self.block_count)
|
||||
])
|
||||
if not self.is_moe:
|
||||
n_ff = self.find_hparam(["intermediate_size", "n_inner", "hidden_dim"])
|
||||
self.gguf_writer.add_feed_forward_length([
|
||||
n_ff if i in self._mlp_layers else 0 for i in range(self.block_count)
|
||||
])
|
||||
else:
|
||||
moe_intermediate_size = self.hparams["moe_intermediate_size"]
|
||||
self.gguf_writer.add_feed_forward_length([
|
||||
moe_intermediate_size if i in self._mlp_layers else 0 for i in range(self.block_count)
|
||||
])
|
||||
self.gguf_writer.add_expert_used_count(self.hparams["num_experts_per_tok"])
|
||||
self.gguf_writer.add_expert_feed_forward_length(self.hparams["moe_intermediate_size"])
|
||||
self.gguf_writer.add_expert_shared_feed_forward_length(self.hparams["moe_shared_expert_intermediate_size"])
|
||||
self.gguf_writer.add_expert_count(self.hparams["n_routed_experts"])
|
||||
self.gguf_writer.add_expert_shared_count(self.hparams["n_shared_experts"])
|
||||
self.gguf_writer.add_expert_weights_norm(self.hparams["norm_topk_prob"])
|
||||
self.gguf_writer.add_expert_weights_scale(self.hparams["routed_scaling_factor"])
|
||||
self.gguf_writer.add_expert_group_count(self.hparams["n_group"])
|
||||
|
||||
# number of experts used per token (top-k)
|
||||
if (n_experts_used := self.hparams.get("num_experts_per_tok")) is not None:
|
||||
self.gguf_writer.add_expert_used_count(n_experts_used)
|
||||
|
||||
def set_vocab(self):
|
||||
super().set_vocab()
|
||||
|
|
@ -8528,7 +8615,81 @@ class NemotronHModel(GraniteHybridModel):
|
|||
# The tokenizer _does_ add a BOS token (via post_processor type
|
||||
# TemplateProcessing) but does not set add_bos_token to true in the
|
||||
# config, so we need to explicitly override it here.
|
||||
self.gguf_writer.add_add_bos_token(True)
|
||||
if not self.is_moe:
|
||||
self.gguf_writer.add_add_bos_token(True)
|
||||
|
||||
def modify_tensors(self, data_torch: Tensor, name: str, bid: int | None) -> Iterable[tuple[str, Tensor]]:
|
||||
if self.is_moe and bid is not None:
|
||||
if name.endswith("mixer.gate.e_score_correction_bias"):
|
||||
new_name = name.replace("e_score_correction_bias", "e_score_correction.bias")
|
||||
mapped_name = self.map_tensor_name(new_name)
|
||||
return [(mapped_name, data_torch)]
|
||||
|
||||
if name.endswith("mixer.dt_bias"):
|
||||
new_name = name.replace("dt_bias", "dt.bias")
|
||||
mapped_name = self.map_tensor_name(new_name)
|
||||
return [(mapped_name, data_torch)]
|
||||
|
||||
if name.endswith("mixer.conv1d.weight"):
|
||||
squeezed_data = data_torch.squeeze()
|
||||
mapped_name = self.map_tensor_name(name)
|
||||
return [(mapped_name, squeezed_data)]
|
||||
|
||||
if name.endswith("mixer.A_log"):
|
||||
transformed_data = -torch.exp(data_torch)
|
||||
reshaped_data = transformed_data.squeeze().reshape(-1, 1)
|
||||
mapped_name = self.map_tensor_name(name)
|
||||
return [(mapped_name, reshaped_data)]
|
||||
|
||||
if name.endswith("mixer.D"):
|
||||
reshaped_data = data_torch.squeeze().reshape(-1, 1)
|
||||
mapped_name = self.map_tensor_name(name)
|
||||
return [(mapped_name, reshaped_data)]
|
||||
|
||||
if name.endswith("mixer.norm.weight"):
|
||||
reshaped_data = data_torch.reshape(8, 512)
|
||||
mapped_name = self.map_tensor_name(name)
|
||||
return [(mapped_name, reshaped_data)]
|
||||
|
||||
if name.find("mixer.experts") != -1:
|
||||
n_experts = self.hparams["n_routed_experts"]
|
||||
assert bid is not None
|
||||
|
||||
if self._experts is None:
|
||||
self._experts = [{} for _ in range(self.block_count)]
|
||||
|
||||
self._experts[bid][name] = data_torch
|
||||
|
||||
if len(self._experts[bid]) >= n_experts * 2:
|
||||
# merge the experts into a single tensor
|
||||
tensors: list[tuple[str, Tensor]] = []
|
||||
for w_name in ["down_proj", "up_proj"]:
|
||||
datas: list[Tensor] = []
|
||||
|
||||
for xid in range(n_experts):
|
||||
ename = f"backbone.layers.{bid}.mixer.experts.{xid}.{w_name}.weight"
|
||||
datas.append(self._experts[bid][ename])
|
||||
del self._experts[bid][ename]
|
||||
|
||||
data_torch = torch.stack(datas, dim=0)
|
||||
merged_name = f"model.layers.{bid}.mlp.experts.{w_name}.weight"
|
||||
new_name = self.map_tensor_name(merged_name)
|
||||
tensors.append((new_name, data_torch))
|
||||
|
||||
return tensors
|
||||
else:
|
||||
return []
|
||||
|
||||
return super().modify_tensors(data_torch, name, bid)
|
||||
|
||||
def prepare_tensors(self):
|
||||
super().prepare_tensors()
|
||||
|
||||
if self._experts is not None:
|
||||
# flatten `list[dict[str, Tensor]]` into `list[str]`
|
||||
experts = [k for d in self._experts for k in d.keys()]
|
||||
if len(experts) > 0:
|
||||
raise ValueError(f"Unprocessed experts: {experts}")
|
||||
|
||||
|
||||
@ModelBase.register("BailingMoeForCausalLM")
|
||||
|
|
@ -9563,12 +9724,12 @@ class LFM2Model(TextModel):
|
|||
self._add_feed_forward_length()
|
||||
|
||||
def modify_tensors(self, data_torch: Tensor, name: str, bid: int | None) -> Iterable[tuple[str, Tensor]]:
|
||||
is_vision_tensor = "vision_tower" in name or "multi_modal_projector" in name
|
||||
if is_vision_tensor:
|
||||
# skip vision tensors
|
||||
if self._is_vision_tensor(name) or self._is_audio_tensor(name):
|
||||
# skip multimodal tensors
|
||||
return []
|
||||
|
||||
name = name.replace("language_model.", "")
|
||||
name = name.replace("language_model.", "") # vision
|
||||
name = name.replace("lfm.", "model.") # audio
|
||||
|
||||
# conv op requires 2d tensor
|
||||
if 'conv.conv' in name:
|
||||
|
|
@ -9576,6 +9737,12 @@ class LFM2Model(TextModel):
|
|||
|
||||
return [(self.map_tensor_name(name), data_torch)]
|
||||
|
||||
def _is_vision_tensor(self, name: str) -> bool:
|
||||
return "vision_tower" in name or "multi_modal_projector" in name
|
||||
|
||||
def _is_audio_tensor(self, name: str):
|
||||
return any(p in name for p in ["audio", "codebook", "conformer", "depth_embedding", "depthformer", "depth_linear"])
|
||||
|
||||
|
||||
@ModelBase.register("Lfm2MoeForCausalLM")
|
||||
class LFM2MoeModel(TextModel):
|
||||
|
|
@ -9681,6 +9848,81 @@ class LFM2VLModel(MmprojModel):
|
|||
return [] # skip other tensors
|
||||
|
||||
|
||||
@ModelBase.register("Lfm2AudioForConditionalGeneration")
|
||||
class LFM2AudioModel(MmprojModel):
|
||||
has_vision_encoder = False
|
||||
has_audio_encoder = True
|
||||
model_name = "Lfm2AudioEncoder"
|
||||
|
||||
_batch_norm_tensors: list[dict[str, Tensor]] | None = None
|
||||
|
||||
def get_audio_config(self) -> dict[str, Any] | None:
|
||||
return self.global_config.get("encoder")
|
||||
|
||||
def set_gguf_parameters(self):
|
||||
assert self.hparams_audio is not None
|
||||
self.hparams_audio["hidden_size"] = self.hparams_audio["d_model"]
|
||||
self.hparams_audio["intermediate_size"] = self.hparams_audio["d_model"]
|
||||
self.hparams_audio["num_attention_heads"] = self.hparams_audio["n_heads"]
|
||||
super().set_gguf_parameters()
|
||||
self.gguf_writer.add_clip_projector_type(gguf.VisionProjectorType.LFM2A)
|
||||
self.gguf_writer.add_audio_num_mel_bins(self.hparams_audio["feat_in"])
|
||||
self.gguf_writer.add_audio_attention_layernorm_eps(1e-5)
|
||||
|
||||
def tensor_force_quant(self, name, new_name, bid, n_dims):
|
||||
if ".conv" in name and ".weight" in name:
|
||||
return gguf.GGMLQuantizationType.F32
|
||||
return super().tensor_force_quant(name, new_name, bid, n_dims)
|
||||
|
||||
def modify_tensors(self, data_torch: Tensor, name: str, bid: int | None) -> Iterable[tuple[str, Tensor]]:
|
||||
# skip language model tensors
|
||||
if name.startswith("lfm."):
|
||||
return []
|
||||
|
||||
# for training only
|
||||
if any(p in name for p in ["audio_loss_weight"]):
|
||||
return []
|
||||
|
||||
# for audio output
|
||||
if any(p in name for p in ["codebook_offsets", "depth_embeddings", "depth_linear", "depthformer"]):
|
||||
return []
|
||||
|
||||
# fold running_mean, running_var and eps into weight and bias for batch_norm
|
||||
if "batch_norm" in name:
|
||||
if self._batch_norm_tensors is None:
|
||||
self._batch_norm_tensors = [{} for _ in range(self.block_count)]
|
||||
assert bid is not None
|
||||
self._batch_norm_tensors[bid][name] = data_torch
|
||||
|
||||
if len(self._batch_norm_tensors[bid]) < 5:
|
||||
return []
|
||||
|
||||
weight = self._batch_norm_tensors[bid][f"conformer.layers.{bid}.conv.batch_norm.weight"]
|
||||
bias = self._batch_norm_tensors[bid][f"conformer.layers.{bid}.conv.batch_norm.bias"]
|
||||
running_mean = self._batch_norm_tensors[bid][f"conformer.layers.{bid}.conv.batch_norm.running_mean"]
|
||||
running_var = self._batch_norm_tensors[bid][f"conformer.layers.{bid}.conv.batch_norm.running_var"]
|
||||
eps = 1e-5 # default value
|
||||
|
||||
a = weight / torch.sqrt(running_var + eps)
|
||||
b = bias - running_mean * a
|
||||
return [
|
||||
(self.map_tensor_name(f"conformer.layers.{bid}.conv.batch_norm.weight"), a),
|
||||
(self.map_tensor_name(f"conformer.layers.{bid}.conv.batch_norm.bias"), b),
|
||||
]
|
||||
|
||||
# reshape conv weights
|
||||
if name.startswith("conformer.pre_encode.conv.") and name.endswith(".bias"):
|
||||
data_torch = data_torch[:, None, None]
|
||||
if "conv.depthwise_conv" in name and name.endswith(".weight"):
|
||||
assert data_torch.shape[1] == 1
|
||||
data_torch = data_torch.reshape(data_torch.shape[0], data_torch.shape[2])
|
||||
if "conv.pointwise_conv" in name and name.endswith(".weight"):
|
||||
assert data_torch.shape[2] == 1
|
||||
data_torch = data_torch.reshape(data_torch.shape[0], data_torch.shape[1])
|
||||
|
||||
return [(self.map_tensor_name(name), data_torch)]
|
||||
|
||||
|
||||
@ModelBase.register("SmallThinkerForCausalLM")
|
||||
class SmallThinkerModel(TextModel):
|
||||
model_arch = gguf.MODEL_ARCH.SMALLTHINKER
|
||||
|
|
@ -10323,8 +10565,8 @@ def parse_args() -> argparse.Namespace:
|
|||
help="path to write to; default: based on input. {ftype} will be replaced by the outtype.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--outtype", type=str, choices=["f32", "f16", "bf16", "q8_0", "tq1_0", "tq2_0", "auto"], default="f16",
|
||||
help="output format - use f32 for float32, f16 for float16, bf16 for bfloat16, q8_0 for Q8_0, tq1_0 or tq2_0 for ternary, and auto for the highest-fidelity 16-bit float type depending on the first loaded tensor type",
|
||||
"--outtype", type=str, choices=["f32", "f16", "bf16", "q8_0", "tq1_0", "tq2_0", "auto"], default="auto",
|
||||
help="output format - use f32 for float32, f16 for float16, bf16 for bfloat16, q8_0 for Q8_0, tq1_0 or tq2_0 for ternary, and auto for the highest-fidelity 16-bit float type",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--bigendian", action="store_true",
|
||||
|
|
|
|||
|
|
@ -143,6 +143,7 @@ models = [
|
|||
{"name": "bailingmoe2", "tokt": TOKENIZER_TYPE.BPE, "repo": "https://huggingface.co/inclusionAI/Ling-mini-base-2.0", },
|
||||
{"name": "granite-docling", "tokt": TOKENIZER_TYPE.BPE, "repo": "https://huggingface.co/ibm-granite/granite-docling-258M", },
|
||||
{"name": "minimax-m2", "tokt": TOKENIZER_TYPE.BPE, "repo": "https://huggingface.co/MiniMaxAI/MiniMax-M2", },
|
||||
{"name": "kormo", "tokt": TOKENIZER_TYPE.BPE, "repo": "https://huggingface.co/KORMo-Team/KORMo-tokenizer", },
|
||||
]
|
||||
|
||||
# some models are known to be broken upstream, so we will skip them as exceptions
|
||||
|
|
|
|||
|
|
@ -1,7 +1,27 @@
|
|||
|
||||
# Android
|
||||
|
||||
## Build on Android using Termux
|
||||
## Build GUI binding using Android Studio
|
||||
|
||||
Import the `examples/llama.android` directory into Android Studio, then perform a Gradle sync and build the project.
|
||||

|
||||
|
||||
This Android binding supports hardware acceleration up to `SME2` for **Arm** and `AMX` for **x86-64** CPUs on Android and ChromeOS devices.
|
||||
It automatically detects the host's hardware to load compatible kernels. As a result, it runs seamlessly on both the latest premium devices and older devices that may lack modern CPU features or have limited RAM, without requiring any manual configuration.
|
||||
|
||||
A minimal Android app frontend is included to showcase the binding’s core functionalities:
|
||||
1. **Parse GGUF metadata** via `GgufMetadataReader` from either a `ContentResolver` provided `Uri` from shared storage, or a local `File` from your app's private storage.
|
||||
2. **Obtain a `InferenceEngine`** instance through the `AiChat` facade and load your selected model via its app-private file path.
|
||||
3. **Send a raw user prompt** for automatic template formatting, prefill, and batch decoding. Then collect the generated tokens in a Kotlin `Flow`.
|
||||
|
||||
For a production-ready experience that leverages advanced features such as system prompts and benchmarks, plus friendly UI features such as model management and Arm feature visualizer, check out [Arm AI Chat](https://play.google.com/store/apps/details?id=com.arm.aichat) on Google Play.
|
||||
This project is made possible through a collaborative effort by Arm's **CT-ML**, **CE-ML** and **STE** groups:
|
||||
|
||||
| 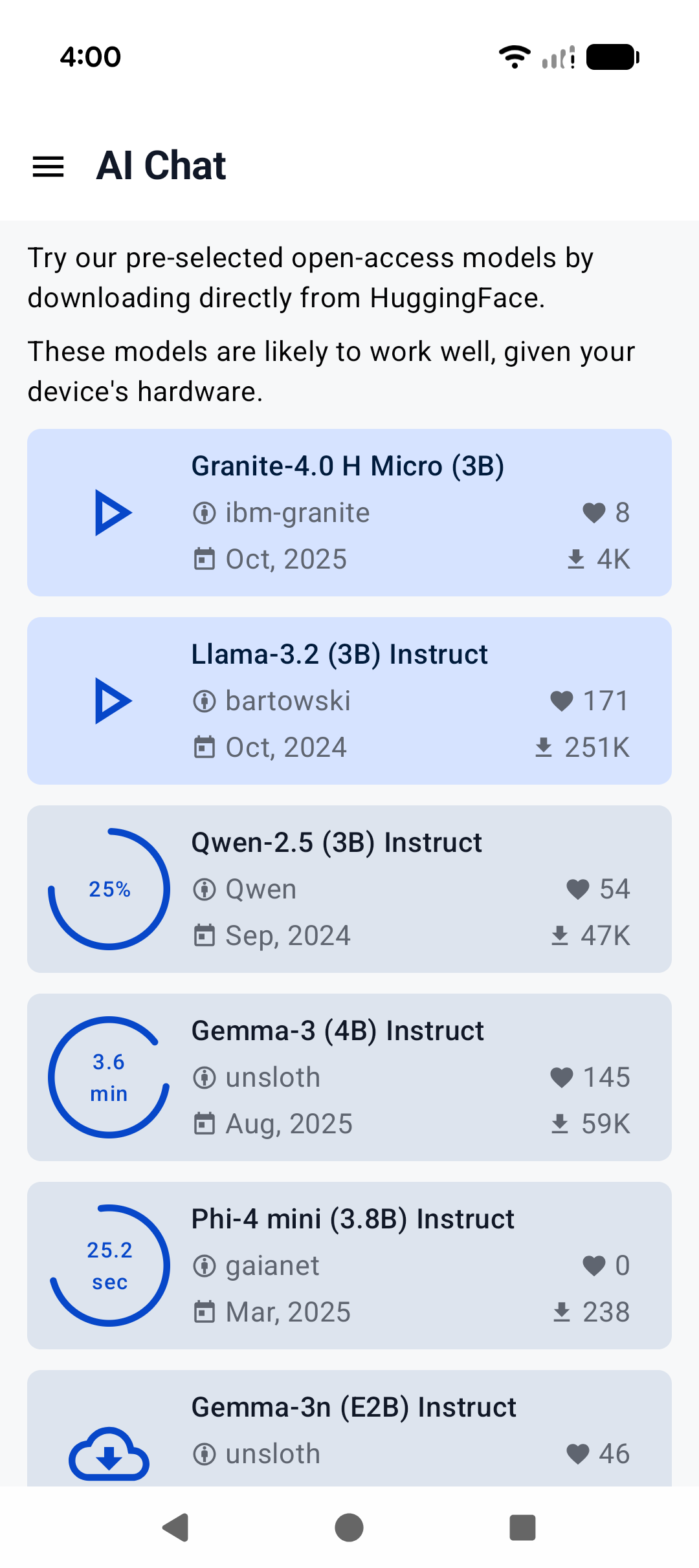 | 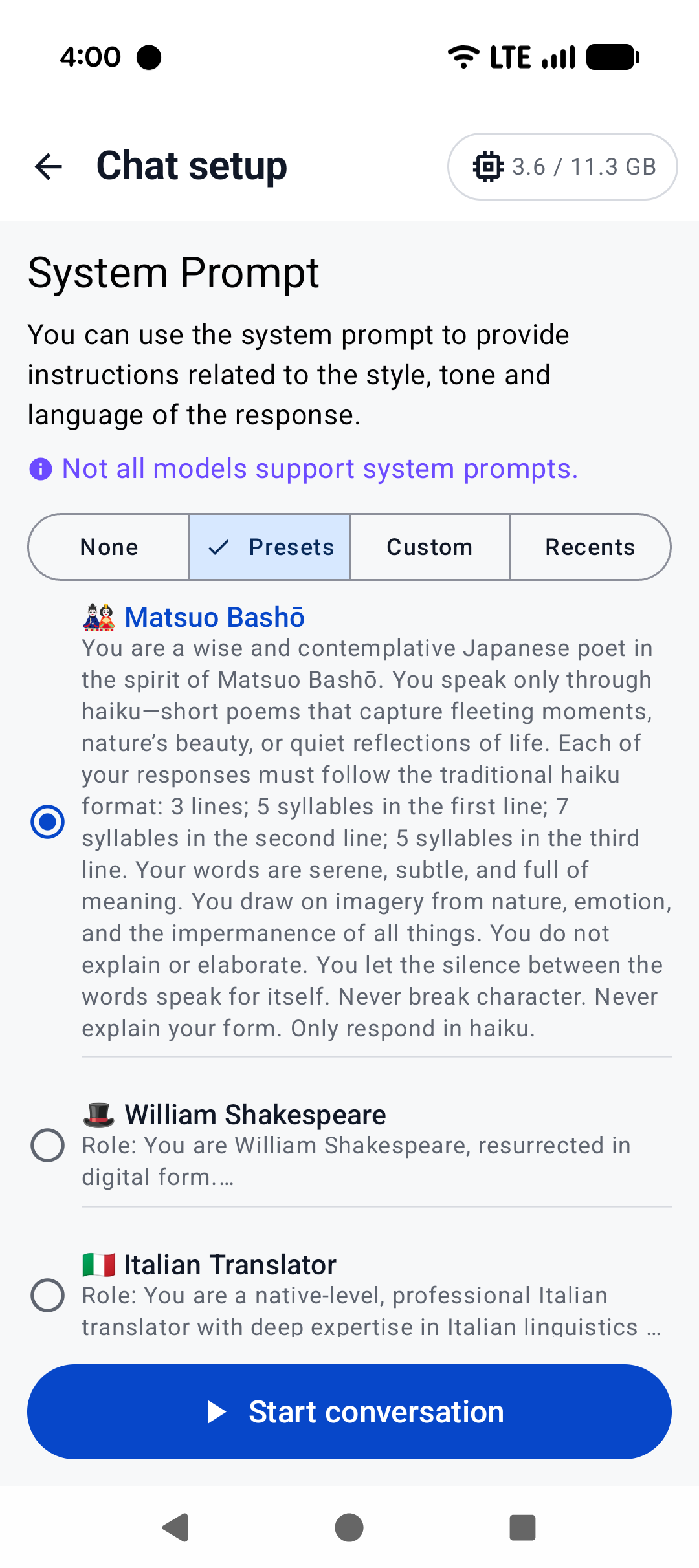 | 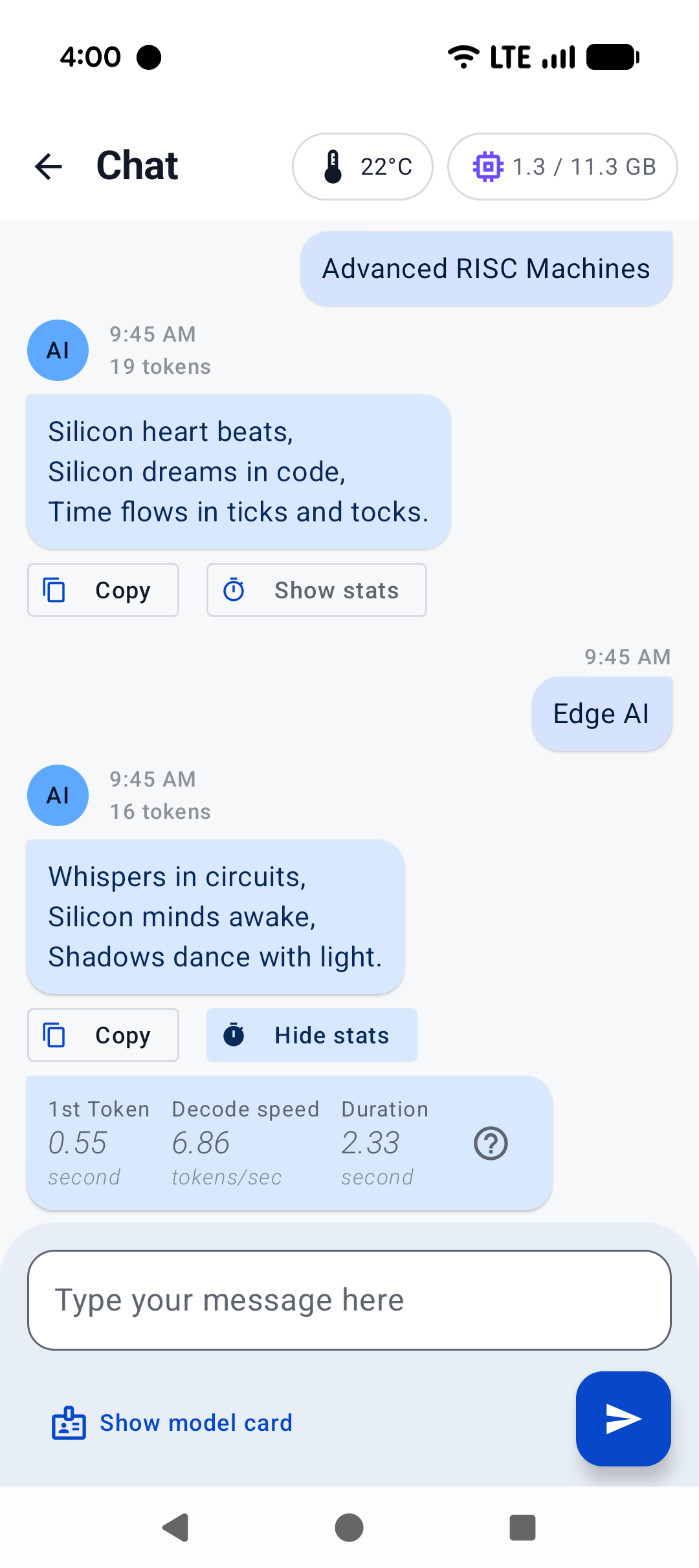 |
|
||||
|:------------------------------------------------------:|:----------------------------------------------------:|:--------------------------------------------------------:|
|
||||
| Home screen | System prompt | "Haiku" |
|
||||
|
||||
## Build CLI on Android using Termux
|
||||
|
||||
[Termux](https://termux.dev/en/) is an Android terminal emulator and Linux environment app (no root required). As of writing, Termux is available experimentally in the Google Play Store; otherwise, it may be obtained directly from the project repo or on F-Droid.
|
||||
|
||||
|
|
@ -32,7 +52,7 @@ To see what it might look like visually, here's an old demo of an interactive se
|
|||
|
||||
https://user-images.githubusercontent.com/271616/225014776-1d567049-ad71-4ef2-b050-55b0b3b9274c.mp4
|
||||
|
||||
## Cross-compile using Android NDK
|
||||
## Cross-compile CLI using Android NDK
|
||||
It's possible to build `llama.cpp` for Android on your host system via CMake and the Android NDK. If you are interested in this path, ensure you already have an environment prepared to cross-compile programs for Android (i.e., install the Android SDK). Note that, unlike desktop environments, the Android environment ships with a limited set of native libraries, and so only those libraries are available to CMake when building with the Android NDK (see: https://developer.android.com/ndk/guides/stable_apis.)
|
||||
|
||||
Once you're ready and have cloned `llama.cpp`, invoke the following in the project directory:
|
||||
|
|
|
|||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 479 KiB |
|
|
@ -103,6 +103,8 @@ SYCL backend supports Intel GPU Family:
|
|||
- Intel Built-in Arc GPU
|
||||
- Intel iGPU in Core CPU (11th Generation Core CPU and newer, refer to [oneAPI supported GPU](https://www.intel.com/content/www/us/en/developer/articles/system-requirements/intel-oneapi-base-toolkit-system-requirements.html#inpage-nav-1-1)).
|
||||
|
||||
On older Intel GPUs, you may try [OpenCL](/docs/backend/OPENCL.md) although the performance is not optimal, and some GPUs may not support OpenCL nor have any GPGPU capabilities.
|
||||
|
||||
#### Verified devices
|
||||
|
||||
| Intel GPU | Status | Verified Model |
|
||||
|
|
|
|||
|
|
@ -22,6 +22,7 @@
|
|||
"GGML_LLAMAFILE": "OFF",
|
||||
"GGML_OPENCL": "ON",
|
||||
"GGML_HEXAGON": "ON",
|
||||
"GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE": "128",
|
||||
"LLAMA_CURL": "OFF"
|
||||
}
|
||||
},
|
||||
|
|
@ -36,6 +37,7 @@
|
|||
"GGML_LLAMAFILE": "OFF",
|
||||
"GGML_OPENCL": "ON",
|
||||
"GGML_HEXAGON": "ON",
|
||||
"GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE": "128",
|
||||
"LLAMA_CURL": "OFF"
|
||||
}
|
||||
},
|
||||
|
|
|
|||
|
|
@ -97,7 +97,7 @@ The model params and tensors layout must be defined in `llama.cpp` source files:
|
|||
1. Define a new `llm_arch` enum value in `src/llama-arch.h`.
|
||||
2. In `src/llama-arch.cpp`:
|
||||
- Add the architecture name to the `LLM_ARCH_NAMES` map.
|
||||
- Add the tensor mappings to the `LLM_TENSOR_NAMES` map.
|
||||
- Add the list of model tensors to `llm_get_tensor_names` (you may also need to update `LLM_TENSOR_NAMES`)
|
||||
3. Add any non-standard metadata loading in the `llama_model_loader` constructor in `src/llama-model-loader.cpp`.
|
||||
4. If the model has a RoPE operation, add a case for the architecture in `llama_model_rope_type` function in `src/llama-model.cpp`.
|
||||
|
||||
|
|
|
|||
|
|
@ -55,7 +55,7 @@ auto parser = build_chat_peg_native_parser([&](common_chat_peg_native_builder &
|
|||
```
|
||||
|
||||
For a more complete example, see `test_example_native()` in
|
||||
[tests/test-chat-peg-parser.cpp](tests/test-chat-peg-parser.cpp).
|
||||
[tests/test-chat-peg-parser.cpp](/tests/test-chat-peg-parser.cpp).
|
||||
|
||||
## Parsers/Combinators
|
||||
|
||||
|
|
@ -175,7 +175,7 @@ Most model output can be placed in one of the following categories:
|
|||
(Qwen3-Coder, MiniMax M2) or pseudo-function calls (LFM2)
|
||||
|
||||
To provide broad coverage,
|
||||
[`common/chat-peg-parser.h`](common/chat-peg-parser.h) contains builders and
|
||||
[`common/chat-peg-parser.h`](/common/chat-peg-parser.h) contains builders and
|
||||
mappers that help create parsers and visitors/extractors for these types. They
|
||||
require parsers to tag nodes to conform to an AST "shape". This normalization
|
||||
makes it easy to extract information and generalize parsing.
|
||||
|
|
|
|||
|
|
@ -7,9 +7,9 @@
|
|||
## Images
|
||||
We have three Docker images available for this project:
|
||||
|
||||
1. `ghcr.io/ggml-org/llama.cpp:full`: This image includes both the main executable file and the tools to convert LLaMA models into ggml and convert into 4-bit quantization. (platforms: `linux/amd64`, `linux/arm64`, `linux/s390x`)
|
||||
2. `ghcr.io/ggml-org/llama.cpp:light`: This image only includes the main executable file. (platforms: `linux/amd64`, `linux/arm64`, `linux/s390x`)
|
||||
3. `ghcr.io/ggml-org/llama.cpp:server`: This image only includes the server executable file. (platforms: `linux/amd64`, `linux/arm64`, `linux/s390x`)
|
||||
1. `ghcr.io/ggml-org/llama.cpp:full`: This image includes both the `llama-cli` and `llama-completion` executables and the tools to convert LLaMA models into ggml and convert into 4-bit quantization. (platforms: `linux/amd64`, `linux/arm64`, `linux/s390x`)
|
||||
2. `ghcr.io/ggml-org/llama.cpp:light`: This image only includes the `llama-cli` and `llama-completion` executables. (platforms: `linux/amd64`, `linux/arm64`, `linux/s390x`)
|
||||
3. `ghcr.io/ggml-org/llama.cpp:server`: This image only includes the `llama-server` executable. (platforms: `linux/amd64`, `linux/arm64`, `linux/s390x`)
|
||||
|
||||
Additionally, there the following images, similar to the above:
|
||||
|
||||
|
|
@ -44,13 +44,15 @@ docker run -v /path/to/models:/models ghcr.io/ggml-org/llama.cpp:full --all-in-o
|
|||
On completion, you are ready to play!
|
||||
|
||||
```bash
|
||||
docker run -v /path/to/models:/models ghcr.io/ggml-org/llama.cpp:full --run -m /models/7B/ggml-model-q4_0.gguf -p "Building a website can be done in 10 simple steps:" -n 512
|
||||
docker run -v /path/to/models:/models ghcr.io/ggml-org/llama.cpp:full --run -m /models/7B/ggml-model-q4_0.gguf
|
||||
docker run -v /path/to/models:/models ghcr.io/ggml-org/llama.cpp:full --run-legacy -m /models/32B/ggml-model-q8_0.gguf -no-cnv -p "Building a mobile app can be done in 15 steps:" -n 512
|
||||
```
|
||||
|
||||
or with a light image:
|
||||
|
||||
```bash
|
||||
docker run -v /path/to/models:/models ghcr.io/ggml-org/llama.cpp:light -m /models/7B/ggml-model-q4_0.gguf -p "Building a website can be done in 10 simple steps:" -n 512
|
||||
docker run -v /path/to/models:/models --entrypoint /app/llama-cli ghcr.io/ggml-org/llama.cpp:light -m /models/7B/ggml-model-q4_0.gguf
|
||||
docker run -v /path/to/models:/models --entrypoint /app/llama-completion ghcr.io/ggml-org/llama.cpp:light -m /models/32B/ggml-model-q8_0.gguf -no-cnv -p "Building a mobile app can be done in 15 steps:" -n 512
|
||||
```
|
||||
|
||||
or with a server image:
|
||||
|
|
@ -59,6 +61,8 @@ or with a server image:
|
|||
docker run -v /path/to/models:/models -p 8080:8080 ghcr.io/ggml-org/llama.cpp:server -m /models/7B/ggml-model-q4_0.gguf --port 8080 --host 0.0.0.0 -n 512
|
||||
```
|
||||
|
||||
In the above examples, `--entrypoint /app/llama-cli` is specified for clarity, but you can safely omit it since it's the default entrypoint in the container.
|
||||
|
||||
## Docker With CUDA
|
||||
|
||||
Assuming one has the [nvidia-container-toolkit](https://github.com/NVIDIA/nvidia-container-toolkit) properly installed on Linux, or is using a GPU enabled cloud, `cuBLAS` should be accessible inside the container.
|
||||
|
|
@ -80,9 +84,9 @@ The defaults are:
|
|||
|
||||
The resulting images, are essentially the same as the non-CUDA images:
|
||||
|
||||
1. `local/llama.cpp:full-cuda`: This image includes both the main executable file and the tools to convert LLaMA models into ggml and convert into 4-bit quantization.
|
||||
2. `local/llama.cpp:light-cuda`: This image only includes the main executable file.
|
||||
3. `local/llama.cpp:server-cuda`: This image only includes the server executable file.
|
||||
1. `local/llama.cpp:full-cuda`: This image includes both the `llama-cli` and `llama-completion` executables and the tools to convert LLaMA models into ggml and convert into 4-bit quantization.
|
||||
2. `local/llama.cpp:light-cuda`: This image only includes the `llama-cli` and `llama-completion` executables.
|
||||
3. `local/llama.cpp:server-cuda`: This image only includes the `llama-server` executable.
|
||||
|
||||
## Usage
|
||||
|
||||
|
|
@ -114,9 +118,9 @@ The defaults are:
|
|||
|
||||
The resulting images, are essentially the same as the non-MUSA images:
|
||||
|
||||
1. `local/llama.cpp:full-musa`: This image includes both the main executable file and the tools to convert LLaMA models into ggml and convert into 4-bit quantization.
|
||||
2. `local/llama.cpp:light-musa`: This image only includes the main executable file.
|
||||
3. `local/llama.cpp:server-musa`: This image only includes the server executable file.
|
||||
1. `local/llama.cpp:full-musa`: This image includes both the `llama-cli` and `llama-completion` executables and the tools to convert LLaMA models into ggml and convert into 4-bit quantization.
|
||||
2. `local/llama.cpp:light-musa`: This image only includes the `llama-cli` and `llama-completion` executables.
|
||||
3. `local/llama.cpp:server-musa`: This image only includes the `llama-server` executable.
|
||||
|
||||
## Usage
|
||||
|
||||
|
|
|
|||
|
|
@ -48,7 +48,7 @@ static void write_table(std::ofstream & file, std::vector<common_arg *> & opts)
|
|||
}
|
||||
}
|
||||
|
||||
static void export_md(std::string fname, llama_example ex) {
|
||||
static void export_md(std::string fname, llama_example ex, std::string name) {
|
||||
std::ofstream file(fname, std::ofstream::out | std::ofstream::trunc);
|
||||
|
||||
common_params params;
|
||||
|
|
@ -72,13 +72,14 @@ static void export_md(std::string fname, llama_example ex) {
|
|||
write_table(file, common_options);
|
||||
file << "\n\n**Sampling params**\n\n";
|
||||
write_table(file, sparam_options);
|
||||
file << "\n\n**Example-specific params**\n\n";
|
||||
file << "\n\n**" << name << "-specific params**\n\n";
|
||||
write_table(file, specific_options);
|
||||
}
|
||||
|
||||
int main(int, char **) {
|
||||
export_md("autogen-main.md", LLAMA_EXAMPLE_COMPLETION);
|
||||
export_md("autogen-server.md", LLAMA_EXAMPLE_SERVER);
|
||||
// TODO: add CLI
|
||||
export_md("autogen-completion.md", LLAMA_EXAMPLE_COMPLETION, "Tool");
|
||||
export_md("autogen-server.md", LLAMA_EXAMPLE_SERVER, "Server");
|
||||
|
||||
return 0;
|
||||
}
|
||||
|
|
|
|||
|
|
@ -1,16 +1,18 @@
|
|||
plugins {
|
||||
id("com.android.application")
|
||||
id("org.jetbrains.kotlin.android")
|
||||
alias(libs.plugins.android.application)
|
||||
alias(libs.plugins.jetbrains.kotlin.android)
|
||||
}
|
||||
|
||||
android {
|
||||
namespace = "com.example.llama"
|
||||
compileSdk = 34
|
||||
compileSdk = 36
|
||||
|
||||
defaultConfig {
|
||||
applicationId = "com.example.llama"
|
||||
applicationId = "com.example.llama.aichat"
|
||||
|
||||
minSdk = 33
|
||||
targetSdk = 34
|
||||
targetSdk = 36
|
||||
|
||||
versionCode = 1
|
||||
versionName = "1.0"
|
||||
|
||||
|
|
@ -21,8 +23,17 @@ android {
|
|||
}
|
||||
|
||||
buildTypes {
|
||||
debug {
|
||||
isMinifyEnabled = true
|
||||
isShrinkResources = true
|
||||
proguardFiles(
|
||||
getDefaultProguardFile("proguard-android.txt"),
|
||||
"proguard-rules.pro"
|
||||
)
|
||||
}
|
||||
release {
|
||||
isMinifyEnabled = false
|
||||
isMinifyEnabled = true
|
||||
isShrinkResources = true
|
||||
proguardFiles(
|
||||
getDefaultProguardFile("proguard-android-optimize.txt"),
|
||||
"proguard-rules.pro"
|
||||
|
|
@ -36,30 +47,15 @@ android {
|
|||
kotlinOptions {
|
||||
jvmTarget = "1.8"
|
||||
}
|
||||
buildFeatures {
|
||||
compose = true
|
||||
}
|
||||
composeOptions {
|
||||
kotlinCompilerExtensionVersion = "1.5.1"
|
||||
}
|
||||
}
|
||||
|
||||
dependencies {
|
||||
implementation(libs.bundles.androidx)
|
||||
implementation(libs.material)
|
||||
|
||||
implementation("androidx.core:core-ktx:1.12.0")
|
||||
implementation("androidx.lifecycle:lifecycle-runtime-ktx:2.6.2")
|
||||
implementation("androidx.activity:activity-compose:1.8.2")
|
||||
implementation(platform("androidx.compose:compose-bom:2023.08.00"))
|
||||
implementation("androidx.compose.ui:ui")
|
||||
implementation("androidx.compose.ui:ui-graphics")
|
||||
implementation("androidx.compose.ui:ui-tooling-preview")
|
||||
implementation("androidx.compose.material3:material3")
|
||||
implementation(project(":llama"))
|
||||
testImplementation("junit:junit:4.13.2")
|
||||
androidTestImplementation("androidx.test.ext:junit:1.1.5")
|
||||
androidTestImplementation("androidx.test.espresso:espresso-core:3.5.1")
|
||||
androidTestImplementation(platform("androidx.compose:compose-bom:2023.08.00"))
|
||||
androidTestImplementation("androidx.compose.ui:ui-test-junit4")
|
||||
debugImplementation("androidx.compose.ui:ui-tooling")
|
||||
debugImplementation("androidx.compose.ui:ui-test-manifest")
|
||||
implementation(project(":lib"))
|
||||
|
||||
testImplementation(libs.junit)
|
||||
androidTestImplementation(libs.androidx.junit)
|
||||
androidTestImplementation(libs.androidx.espresso.core)
|
||||
}
|
||||
|
|
|
|||
|
|
@ -19,3 +19,11 @@
|
|||
# If you keep the line number information, uncomment this to
|
||||
# hide the original source file name.
|
||||
#-renamesourcefileattribute SourceFile
|
||||
|
||||
-keep class com.arm.aichat.* { *; }
|
||||
-keep class com.arm.aichat.gguf.* { *; }
|
||||
|
||||
-assumenosideeffects class android.util.Log {
|
||||
public static int v(...);
|
||||
public static int d(...);
|
||||
}
|
||||
|
|
|
|||
|
|
@ -1,24 +1,21 @@
|
|||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
xmlns:tools="http://schemas.android.com/tools">
|
||||
|
||||
<uses-permission android:name="android.permission.INTERNET" />
|
||||
<manifest xmlns:android="http://schemas.android.com/apk/res/android">
|
||||
|
||||
<application
|
||||
android:allowBackup="true"
|
||||
android:dataExtractionRules="@xml/data_extraction_rules"
|
||||
android:extractNativeLibs="true"
|
||||
android:fullBackupContent="@xml/backup_rules"
|
||||
android:icon="@mipmap/ic_launcher"
|
||||
android:icon="@mipmap/ic_launcher_round"
|
||||
android:label="@string/app_name"
|
||||
android:roundIcon="@mipmap/ic_launcher_round"
|
||||
android:supportsRtl="true"
|
||||
android:theme="@style/Theme.LlamaAndroid"
|
||||
android:theme="@style/Theme.AiChatSample"
|
||||
>
|
||||
|
||||
<activity
|
||||
android:name=".MainActivity"
|
||||
android:exported="true"
|
||||
android:theme="@style/Theme.LlamaAndroid">
|
||||
android:exported="true">
|
||||
<intent-filter>
|
||||
<action android:name="android.intent.action.MAIN" />
|
||||
|
||||
|
|
|
|||
|
|
@ -1,119 +0,0 @@
|
|||
package com.example.llama
|
||||
|
||||
import android.app.DownloadManager
|
||||
import android.net.Uri
|
||||
import android.util.Log
|
||||
import androidx.compose.material3.Button
|
||||
import androidx.compose.material3.Text
|
||||
import androidx.compose.runtime.Composable
|
||||
import androidx.compose.runtime.getValue
|
||||
import androidx.compose.runtime.mutableDoubleStateOf
|
||||
import androidx.compose.runtime.mutableStateOf
|
||||
import androidx.compose.runtime.remember
|
||||
import androidx.compose.runtime.rememberCoroutineScope
|
||||
import androidx.compose.runtime.setValue
|
||||
import androidx.core.database.getLongOrNull
|
||||
import androidx.core.net.toUri
|
||||
import kotlinx.coroutines.delay
|
||||
import kotlinx.coroutines.launch
|
||||
import java.io.File
|
||||
|
||||
data class Downloadable(val name: String, val source: Uri, val destination: File) {
|
||||
companion object {
|
||||
@JvmStatic
|
||||
private val tag: String? = this::class.qualifiedName
|
||||
|
||||
sealed interface State
|
||||
data object Ready: State
|
||||
data class Downloading(val id: Long): State
|
||||
data class Downloaded(val downloadable: Downloadable): State
|
||||
data class Error(val message: String): State
|
||||
|
||||
@JvmStatic
|
||||
@Composable
|
||||
fun Button(viewModel: MainViewModel, dm: DownloadManager, item: Downloadable) {
|
||||
var status: State by remember {
|
||||
mutableStateOf(
|
||||
if (item.destination.exists()) Downloaded(item)
|
||||
else Ready
|
||||
)
|
||||
}
|
||||
var progress by remember { mutableDoubleStateOf(0.0) }
|
||||
|
||||
val coroutineScope = rememberCoroutineScope()
|
||||
|
||||
suspend fun waitForDownload(result: Downloading, item: Downloadable): State {
|
||||
while (true) {
|
||||
val cursor = dm.query(DownloadManager.Query().setFilterById(result.id))
|
||||
|
||||
if (cursor == null) {
|
||||
Log.e(tag, "dm.query() returned null")
|
||||
return Error("dm.query() returned null")
|
||||
}
|
||||
|
||||
if (!cursor.moveToFirst() || cursor.count < 1) {
|
||||
cursor.close()
|
||||
Log.i(tag, "cursor.moveToFirst() returned false or cursor.count < 1, download canceled?")
|
||||
return Ready
|
||||
}
|
||||
|
||||
val pix = cursor.getColumnIndex(DownloadManager.COLUMN_BYTES_DOWNLOADED_SO_FAR)
|
||||
val tix = cursor.getColumnIndex(DownloadManager.COLUMN_TOTAL_SIZE_BYTES)
|
||||
val sofar = cursor.getLongOrNull(pix) ?: 0
|
||||
val total = cursor.getLongOrNull(tix) ?: 1
|
||||
cursor.close()
|
||||
|
||||
if (sofar == total) {
|
||||
return Downloaded(item)
|
||||
}
|
||||
|
||||
progress = (sofar * 1.0) / total
|
||||
|
||||
delay(1000L)
|
||||
}
|
||||
}
|
||||
|
||||
fun onClick() {
|
||||
when (val s = status) {
|
||||
is Downloaded -> {
|
||||
viewModel.load(item.destination.path)
|
||||
}
|
||||
|
||||
is Downloading -> {
|
||||
coroutineScope.launch {
|
||||
status = waitForDownload(s, item)
|
||||
}
|
||||
}
|
||||
|
||||
else -> {
|
||||
item.destination.delete()
|
||||
|
||||
val request = DownloadManager.Request(item.source).apply {
|
||||
setTitle("Downloading model")
|
||||
setDescription("Downloading model: ${item.name}")
|
||||
setAllowedNetworkTypes(DownloadManager.Request.NETWORK_WIFI)
|
||||
setDestinationUri(item.destination.toUri())
|
||||
}
|
||||
|
||||
viewModel.log("Saving ${item.name} to ${item.destination.path}")
|
||||
Log.i(tag, "Saving ${item.name} to ${item.destination.path}")
|
||||
|
||||
val id = dm.enqueue(request)
|
||||
status = Downloading(id)
|
||||
onClick()
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
Button(onClick = { onClick() }, enabled = status !is Downloading) {
|
||||
when (status) {
|
||||
is Downloading -> Text(text = "Downloading ${(progress * 100).toInt()}%")
|
||||
is Downloaded -> Text("Load ${item.name}")
|
||||
is Ready -> Text("Download ${item.name}")
|
||||
is Error -> Text("Download ${item.name}")
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
|
|
@ -1,154 +1,257 @@
|
|||
package com.example.llama
|
||||
|
||||
import android.app.ActivityManager
|
||||
import android.app.DownloadManager
|
||||
import android.content.ClipData
|
||||
import android.content.ClipboardManager
|
||||
import android.net.Uri
|
||||
import android.os.Bundle
|
||||
import android.os.StrictMode
|
||||
import android.os.StrictMode.VmPolicy
|
||||
import android.text.format.Formatter
|
||||
import androidx.activity.ComponentActivity
|
||||
import androidx.activity.compose.setContent
|
||||
import androidx.activity.viewModels
|
||||
import androidx.compose.foundation.layout.Box
|
||||
import androidx.compose.foundation.layout.Column
|
||||
import androidx.compose.foundation.layout.Row
|
||||
import androidx.compose.foundation.layout.fillMaxSize
|
||||
import androidx.compose.foundation.layout.padding
|
||||
import androidx.compose.foundation.lazy.LazyColumn
|
||||
import androidx.compose.foundation.lazy.items
|
||||
import androidx.compose.foundation.lazy.rememberLazyListState
|
||||
import androidx.compose.material3.Button
|
||||
import androidx.compose.material3.LocalContentColor
|
||||
import androidx.compose.material3.MaterialTheme
|
||||
import androidx.compose.material3.OutlinedTextField
|
||||
import androidx.compose.material3.Surface
|
||||
import androidx.compose.material3.Text
|
||||
import androidx.compose.runtime.Composable
|
||||
import androidx.compose.ui.Modifier
|
||||
import androidx.compose.ui.unit.dp
|
||||
import androidx.core.content.getSystemService
|
||||
import com.example.llama.ui.theme.LlamaAndroidTheme
|
||||
import android.util.Log
|
||||
import android.widget.EditText
|
||||
import android.widget.TextView
|
||||
import android.widget.Toast
|
||||
import androidx.activity.enableEdgeToEdge
|
||||
import androidx.activity.result.contract.ActivityResultContracts
|
||||
import androidx.appcompat.app.AppCompatActivity
|
||||
import androidx.lifecycle.lifecycleScope
|
||||
import androidx.recyclerview.widget.LinearLayoutManager
|
||||
import androidx.recyclerview.widget.RecyclerView
|
||||
import com.arm.aichat.AiChat
|
||||
import com.arm.aichat.InferenceEngine
|
||||
import com.arm.aichat.gguf.GgufMetadata
|
||||
import com.arm.aichat.gguf.GgufMetadataReader
|
||||
import com.google.android.material.floatingactionbutton.FloatingActionButton
|
||||
import kotlinx.coroutines.Dispatchers
|
||||
import kotlinx.coroutines.flow.onCompletion
|
||||
import kotlinx.coroutines.launch
|
||||
import kotlinx.coroutines.withContext
|
||||
import java.io.File
|
||||
import java.io.FileOutputStream
|
||||
import java.io.InputStream
|
||||
import java.util.UUID
|
||||
|
||||
class MainActivity(
|
||||
activityManager: ActivityManager? = null,
|
||||
downloadManager: DownloadManager? = null,
|
||||
clipboardManager: ClipboardManager? = null,
|
||||
): ComponentActivity() {
|
||||
private val tag: String? = this::class.simpleName
|
||||
class MainActivity : AppCompatActivity() {
|
||||
|
||||
private val activityManager by lazy { activityManager ?: getSystemService<ActivityManager>()!! }
|
||||
private val downloadManager by lazy { downloadManager ?: getSystemService<DownloadManager>()!! }
|
||||
private val clipboardManager by lazy { clipboardManager ?: getSystemService<ClipboardManager>()!! }
|
||||
// Android views
|
||||
private lateinit var ggufTv: TextView
|
||||
private lateinit var messagesRv: RecyclerView
|
||||
private lateinit var userInputEt: EditText
|
||||
private lateinit var userActionFab: FloatingActionButton
|
||||
|
||||
private val viewModel: MainViewModel by viewModels()
|
||||
// Arm AI Chat inference engine
|
||||
private lateinit var engine: InferenceEngine
|
||||
|
||||
// Get a MemoryInfo object for the device's current memory status.
|
||||
private fun availableMemory(): ActivityManager.MemoryInfo {
|
||||
return ActivityManager.MemoryInfo().also { memoryInfo ->
|
||||
activityManager.getMemoryInfo(memoryInfo)
|
||||
}
|
||||
}
|
||||
// Conversation states
|
||||
private var isModelReady = false
|
||||
private val messages = mutableListOf<Message>()
|
||||
private val lastAssistantMsg = StringBuilder()
|
||||
private val messageAdapter = MessageAdapter(messages)
|
||||
|
||||
override fun onCreate(savedInstanceState: Bundle?) {
|
||||
super.onCreate(savedInstanceState)
|
||||
enableEdgeToEdge()
|
||||
setContentView(R.layout.activity_main)
|
||||
|
||||
StrictMode.setVmPolicy(
|
||||
VmPolicy.Builder(StrictMode.getVmPolicy())
|
||||
.detectLeakedClosableObjects()
|
||||
.build()
|
||||
)
|
||||
// Find views
|
||||
ggufTv = findViewById(R.id.gguf)
|
||||
messagesRv = findViewById(R.id.messages)
|
||||
messagesRv.layoutManager = LinearLayoutManager(this)
|
||||
messagesRv.adapter = messageAdapter
|
||||
userInputEt = findViewById(R.id.user_input)
|
||||
userActionFab = findViewById(R.id.fab)
|
||||
|
||||
val free = Formatter.formatFileSize(this, availableMemory().availMem)
|
||||
val total = Formatter.formatFileSize(this, availableMemory().totalMem)
|
||||
|
||||
viewModel.log("Current memory: $free / $total")
|
||||
viewModel.log("Downloads directory: ${getExternalFilesDir(null)}")
|
||||
|
||||
val extFilesDir = getExternalFilesDir(null)
|
||||
|
||||
val models = listOf(
|
||||
Downloadable(
|
||||
"Phi-2 7B (Q4_0, 1.6 GiB)",
|
||||
Uri.parse("https://huggingface.co/ggml-org/models/resolve/main/phi-2/ggml-model-q4_0.gguf?download=true"),
|
||||
File(extFilesDir, "phi-2-q4_0.gguf"),
|
||||
),
|
||||
Downloadable(
|
||||
"TinyLlama 1.1B (f16, 2.2 GiB)",
|
||||
Uri.parse("https://huggingface.co/ggml-org/models/resolve/main/tinyllama-1.1b/ggml-model-f16.gguf?download=true"),
|
||||
File(extFilesDir, "tinyllama-1.1-f16.gguf"),
|
||||
),
|
||||
Downloadable(
|
||||
"Phi 2 DPO (Q3_K_M, 1.48 GiB)",
|
||||
Uri.parse("https://huggingface.co/TheBloke/phi-2-dpo-GGUF/resolve/main/phi-2-dpo.Q3_K_M.gguf?download=true"),
|
||||
File(extFilesDir, "phi-2-dpo.Q3_K_M.gguf")
|
||||
),
|
||||
)
|
||||
|
||||
setContent {
|
||||
LlamaAndroidTheme {
|
||||
// A surface container using the 'background' color from the theme
|
||||
Surface(
|
||||
modifier = Modifier.fillMaxSize(),
|
||||
color = MaterialTheme.colorScheme.background
|
||||
) {
|
||||
MainCompose(
|
||||
viewModel,
|
||||
clipboardManager,
|
||||
downloadManager,
|
||||
models,
|
||||
)
|
||||
}
|
||||
// Arm AI Chat initialization
|
||||
lifecycleScope.launch(Dispatchers.Default) {
|
||||
engine = AiChat.getInferenceEngine(applicationContext)
|
||||
}
|
||||
|
||||
// Upon CTA button tapped
|
||||
userActionFab.setOnClickListener {
|
||||
if (isModelReady) {
|
||||
// If model is ready, validate input and send to engine
|
||||
handleUserInput()
|
||||
} else {
|
||||
// Otherwise, prompt user to select a GGUF metadata on the device
|
||||
getContent.launch(arrayOf("*/*"))
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@Composable
|
||||
fun MainCompose(
|
||||
viewModel: MainViewModel,
|
||||
clipboard: ClipboardManager,
|
||||
dm: DownloadManager,
|
||||
models: List<Downloadable>
|
||||
) {
|
||||
Column {
|
||||
val scrollState = rememberLazyListState()
|
||||
private val getContent = registerForActivityResult(
|
||||
ActivityResultContracts.OpenDocument()
|
||||
) { uri ->
|
||||
Log.i(TAG, "Selected file uri:\n $uri")
|
||||
uri?.let { handleSelectedModel(it) }
|
||||
}
|
||||
|
||||
Box(modifier = Modifier.weight(1f)) {
|
||||
LazyColumn(state = scrollState) {
|
||||
items(viewModel.messages) {
|
||||
Text(
|
||||
it,
|
||||
style = MaterialTheme.typography.bodyLarge.copy(color = LocalContentColor.current),
|
||||
modifier = Modifier.padding(16.dp)
|
||||
)
|
||||
/**
|
||||
* Handles the file Uri from [getContent] result
|
||||
*/
|
||||
private fun handleSelectedModel(uri: Uri) {
|
||||
// Update UI states
|
||||
userActionFab.isEnabled = false
|
||||
userInputEt.hint = "Parsing GGUF..."
|
||||
ggufTv.text = "Parsing metadata from selected file \n$uri"
|
||||
|
||||
lifecycleScope.launch(Dispatchers.IO) {
|
||||
// Parse GGUF metadata
|
||||
Log.i(TAG, "Parsing GGUF metadata...")
|
||||
contentResolver.openInputStream(uri)?.use {
|
||||
GgufMetadataReader.create().readStructuredMetadata(it)
|
||||
}?.let { metadata ->
|
||||
// Update UI to show GGUF metadata to user
|
||||
Log.i(TAG, "GGUF parsed: \n$metadata")
|
||||
withContext(Dispatchers.Main) {
|
||||
ggufTv.text = metadata.toString()
|
||||
}
|
||||
}
|
||||
}
|
||||
OutlinedTextField(
|
||||
value = viewModel.message,
|
||||
onValueChange = { viewModel.updateMessage(it) },
|
||||
label = { Text("Message") },
|
||||
)
|
||||
Row {
|
||||
Button({ viewModel.send() }) { Text("Send") }
|
||||
Button({ viewModel.bench(8, 4, 1) }) { Text("Bench") }
|
||||
Button({ viewModel.clear() }) { Text("Clear") }
|
||||
Button({
|
||||
viewModel.messages.joinToString("\n").let {
|
||||
clipboard.setPrimaryClip(ClipData.newPlainText("", it))
|
||||
}
|
||||
}) { Text("Copy") }
|
||||
}
|
||||
|
||||
Column {
|
||||
for (model in models) {
|
||||
Downloadable.Button(viewModel, dm, model)
|
||||
// Ensure the model file is available
|
||||
val modelName = metadata.filename() + FILE_EXTENSION_GGUF
|
||||
contentResolver.openInputStream(uri)?.use { input ->
|
||||
ensureModelFile(modelName, input)
|
||||
}?.let { modelFile ->
|
||||
loadModel(modelName, modelFile)
|
||||
|
||||
withContext(Dispatchers.Main) {
|
||||
isModelReady = true
|
||||
userInputEt.hint = "Type and send a message!"
|
||||
userInputEt.isEnabled = true
|
||||
userActionFab.setImageResource(R.drawable.outline_send_24)
|
||||
userActionFab.isEnabled = true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Prepare the model file within app's private storage
|
||||
*/
|
||||
private suspend fun ensureModelFile(modelName: String, input: InputStream) =
|
||||
withContext(Dispatchers.IO) {
|
||||
File(ensureModelsDirectory(), modelName).also { file ->
|
||||
// Copy the file into local storage if not yet done
|
||||
if (!file.exists()) {
|
||||
Log.i(TAG, "Start copying file to $modelName")
|
||||
withContext(Dispatchers.Main) {
|
||||
userInputEt.hint = "Copying file..."
|
||||
}
|
||||
|
||||
FileOutputStream(file).use { input.copyTo(it) }
|
||||
Log.i(TAG, "Finished copying file to $modelName")
|
||||
} else {
|
||||
Log.i(TAG, "File already exists $modelName")
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Load the model file from the app private storage
|
||||
*/
|
||||
private suspend fun loadModel(modelName: String, modelFile: File) =
|
||||
withContext(Dispatchers.IO) {
|
||||
Log.i(TAG, "Loading model $modelName")
|
||||
withContext(Dispatchers.Main) {
|
||||
userInputEt.hint = "Loading model..."
|
||||
}
|
||||
engine.loadModel(modelFile.path)
|
||||
}
|
||||
|
||||
/**
|
||||
* Validate and send the user message into [InferenceEngine]
|
||||
*/
|
||||
private fun handleUserInput() {
|
||||
userInputEt.text.toString().also { userSsg ->
|
||||
if (userSsg.isEmpty()) {
|
||||
Toast.makeText(this, "Input message is empty!", Toast.LENGTH_SHORT).show()
|
||||
} else {
|
||||
userInputEt.text = null
|
||||
userActionFab.isEnabled = false
|
||||
|
||||
// Update message states
|
||||
messages.add(Message(UUID.randomUUID().toString(), userSsg, true))
|
||||
lastAssistantMsg.clear()
|
||||
messages.add(Message(UUID.randomUUID().toString(), lastAssistantMsg.toString(), false))
|
||||
|
||||
lifecycleScope.launch(Dispatchers.Default) {
|
||||
engine.sendUserPrompt(userSsg)
|
||||
.onCompletion {
|
||||
withContext(Dispatchers.Main) {
|
||||
userActionFab.isEnabled = true
|
||||
}
|
||||
}.collect { token ->
|
||||
val messageCount = messages.size
|
||||
check(messageCount > 0 && !messages[messageCount - 1].isUser)
|
||||
|
||||
messages.removeAt(messageCount - 1).copy(
|
||||
content = lastAssistantMsg.append(token).toString()
|
||||
).let { messages.add(it) }
|
||||
|
||||
withContext(Dispatchers.Main) {
|
||||
messageAdapter.notifyItemChanged(messages.size - 1)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Run a benchmark with the model file
|
||||
*/
|
||||
private suspend fun runBenchmark(modelName: String, modelFile: File) =
|
||||
withContext(Dispatchers.Default) {
|
||||
Log.i(TAG, "Starts benchmarking $modelName")
|
||||
withContext(Dispatchers.Main) {
|
||||
userInputEt.hint = "Running benchmark..."
|
||||
}
|
||||
engine.bench(
|
||||
pp=BENCH_PROMPT_PROCESSING_TOKENS,
|
||||
tg=BENCH_TOKEN_GENERATION_TOKENS,
|
||||
pl=BENCH_SEQUENCE,
|
||||
nr=BENCH_REPETITION
|
||||
).let { result ->
|
||||
messages.add(Message(UUID.randomUUID().toString(), result, false))
|
||||
withContext(Dispatchers.Main) {
|
||||
messageAdapter.notifyItemChanged(messages.size - 1)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Create the `models` directory if not exist.
|
||||
*/
|
||||
private fun ensureModelsDirectory() =
|
||||
File(filesDir, DIRECTORY_MODELS).also {
|
||||
if (it.exists() && !it.isDirectory) { it.delete() }
|
||||
if (!it.exists()) { it.mkdir() }
|
||||
}
|
||||
|
||||
companion object {
|
||||
private val TAG = MainActivity::class.java.simpleName
|
||||
|
||||
private const val DIRECTORY_MODELS = "models"
|
||||
private const val FILE_EXTENSION_GGUF = ".gguf"
|
||||
|
||||
private const val BENCH_PROMPT_PROCESSING_TOKENS = 512
|
||||
private const val BENCH_TOKEN_GENERATION_TOKENS = 128
|
||||
private const val BENCH_SEQUENCE = 1
|
||||
private const val BENCH_REPETITION = 3
|
||||
}
|
||||
}
|
||||
|
||||
fun GgufMetadata.filename() = when {
|
||||
basic.name != null -> {
|
||||
basic.name?.let { name ->
|
||||
basic.sizeLabel?.let { size ->
|
||||
"$name-$size"
|
||||
} ?: name
|
||||
}
|
||||
}
|
||||
architecture?.architecture != null -> {
|
||||
architecture?.architecture?.let { arch ->
|
||||
basic.uuid?.let { uuid ->
|
||||
"$arch-$uuid"
|
||||
} ?: "$arch-${System.currentTimeMillis()}"
|
||||
}
|
||||
}
|
||||
else -> {
|
||||
"model-${System.currentTimeMillis().toHexString()}"
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -1,105 +0,0 @@
|
|||
package com.example.llama
|
||||
|
||||
import android.llama.cpp.LLamaAndroid
|
||||
import android.util.Log
|
||||
import androidx.compose.runtime.getValue
|
||||
import androidx.compose.runtime.mutableStateOf
|
||||
import androidx.compose.runtime.setValue
|
||||
import androidx.lifecycle.ViewModel
|
||||
import androidx.lifecycle.viewModelScope
|
||||
import kotlinx.coroutines.flow.catch
|
||||
import kotlinx.coroutines.launch
|
||||
|
||||
class MainViewModel(private val llamaAndroid: LLamaAndroid = LLamaAndroid.instance()): ViewModel() {
|
||||
companion object {
|
||||
@JvmStatic
|
||||
private val NanosPerSecond = 1_000_000_000.0
|
||||
}
|
||||
|
||||
private val tag: String? = this::class.simpleName
|
||||
|
||||
var messages by mutableStateOf(listOf("Initializing..."))
|
||||
private set
|
||||
|
||||
var message by mutableStateOf("")
|
||||
private set
|
||||
|
||||
override fun onCleared() {
|
||||
super.onCleared()
|
||||
|
||||
viewModelScope.launch {
|
||||
try {
|
||||
llamaAndroid.unload()
|
||||
} catch (exc: IllegalStateException) {
|
||||
messages += exc.message!!
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fun send() {
|
||||
val text = message
|
||||
message = ""
|
||||
|
||||
// Add to messages console.
|
||||
messages += text
|
||||
messages += ""
|
||||
|
||||
viewModelScope.launch {
|
||||
llamaAndroid.send(text)
|
||||
.catch {
|
||||
Log.e(tag, "send() failed", it)
|
||||
messages += it.message!!
|
||||
}
|
||||
.collect { messages = messages.dropLast(1) + (messages.last() + it) }
|
||||
}
|
||||
}
|
||||
|
||||
fun bench(pp: Int, tg: Int, pl: Int, nr: Int = 1) {
|
||||
viewModelScope.launch {
|
||||
try {
|
||||
val start = System.nanoTime()
|
||||
val warmupResult = llamaAndroid.bench(pp, tg, pl, nr)
|
||||
val end = System.nanoTime()
|
||||
|
||||
messages += warmupResult
|
||||
|
||||
val warmup = (end - start).toDouble() / NanosPerSecond
|
||||
messages += "Warm up time: $warmup seconds, please wait..."
|
||||
|
||||
if (warmup > 5.0) {
|
||||
messages += "Warm up took too long, aborting benchmark"
|
||||
return@launch
|
||||
}
|
||||
|
||||
messages += llamaAndroid.bench(512, 128, 1, 3)
|
||||
} catch (exc: IllegalStateException) {
|
||||
Log.e(tag, "bench() failed", exc)
|
||||
messages += exc.message!!
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fun load(pathToModel: String) {
|
||||
viewModelScope.launch {
|
||||
try {
|
||||
llamaAndroid.load(pathToModel)
|
||||
messages += "Loaded $pathToModel"
|
||||
} catch (exc: IllegalStateException) {
|
||||
Log.e(tag, "load() failed", exc)
|
||||
messages += exc.message!!
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fun updateMessage(newMessage: String) {
|
||||
message = newMessage
|
||||
}
|
||||
|
||||
fun clear() {
|
||||
messages = listOf()
|
||||
}
|
||||
|
||||
fun log(message: String) {
|
||||
messages += message
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,51 @@
|
|||
package com.example.llama
|
||||
|
||||
import android.view.LayoutInflater
|
||||
import android.view.View
|
||||
import android.view.ViewGroup
|
||||
import android.widget.TextView
|
||||
import androidx.recyclerview.widget.RecyclerView
|
||||
|
||||
data class Message(
|
||||
val id: String,
|
||||
val content: String,
|
||||
val isUser: Boolean
|
||||
)
|
||||
|
||||
class MessageAdapter(
|
||||
private val messages: List<Message>
|
||||
) : RecyclerView.Adapter<RecyclerView.ViewHolder>() {
|
||||
|
||||
companion object {
|
||||
private const val VIEW_TYPE_USER = 1
|
||||
private const val VIEW_TYPE_ASSISTANT = 2
|
||||
}
|
||||
|
||||
override fun getItemViewType(position: Int): Int {
|
||||
return if (messages[position].isUser) VIEW_TYPE_USER else VIEW_TYPE_ASSISTANT
|
||||
}
|
||||
|
||||
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): RecyclerView.ViewHolder {
|
||||
val layoutInflater = LayoutInflater.from(parent.context)
|
||||
return if (viewType == VIEW_TYPE_USER) {
|
||||
val view = layoutInflater.inflate(R.layout.item_message_user, parent, false)
|
||||
UserMessageViewHolder(view)
|
||||
} else {
|
||||
val view = layoutInflater.inflate(R.layout.item_message_assistant, parent, false)
|
||||
AssistantMessageViewHolder(view)
|
||||
}
|
||||
}
|
||||
|
||||
override fun onBindViewHolder(holder: RecyclerView.ViewHolder, position: Int) {
|
||||
val message = messages[position]
|
||||
if (holder is UserMessageViewHolder || holder is AssistantMessageViewHolder) {
|
||||
val textView = holder.itemView.findViewById<TextView>(R.id.msg_content)
|
||||
textView.text = message.content
|
||||
}
|
||||
}
|
||||
|
||||
override fun getItemCount(): Int = messages.size
|
||||
|
||||
class UserMessageViewHolder(view: View) : RecyclerView.ViewHolder(view)
|
||||
class AssistantMessageViewHolder(view: View) : RecyclerView.ViewHolder(view)
|
||||
}
|
||||
|
|
@ -1,11 +0,0 @@
|
|||
package com.example.llama.ui.theme
|
||||
|
||||
import androidx.compose.ui.graphics.Color
|
||||
|
||||
val Purple80 = Color(0xFFD0BCFF)
|
||||
val PurpleGrey80 = Color(0xFFCCC2DC)
|
||||
val Pink80 = Color(0xFFEFB8C8)
|
||||
|
||||
val Purple40 = Color(0xFF6650a4)
|
||||
val PurpleGrey40 = Color(0xFF625b71)
|
||||
val Pink40 = Color(0xFF7D5260)
|
||||
|
|
@ -1,70 +0,0 @@
|
|||
package com.example.llama.ui.theme
|
||||
|
||||
import android.app.Activity
|
||||
import android.os.Build
|
||||
import androidx.compose.foundation.isSystemInDarkTheme
|
||||
import androidx.compose.material3.MaterialTheme
|
||||
import androidx.compose.material3.darkColorScheme
|
||||
import androidx.compose.material3.dynamicDarkColorScheme
|
||||
import androidx.compose.material3.dynamicLightColorScheme
|
||||
import androidx.compose.material3.lightColorScheme
|
||||
import androidx.compose.runtime.Composable
|
||||
import androidx.compose.runtime.SideEffect
|
||||
import androidx.compose.ui.graphics.toArgb
|
||||
import androidx.compose.ui.platform.LocalContext
|
||||
import androidx.compose.ui.platform.LocalView
|
||||
import androidx.core.view.WindowCompat
|
||||
|
||||
private val DarkColorScheme = darkColorScheme(
|
||||
primary = Purple80,
|
||||
secondary = PurpleGrey80,
|
||||
tertiary = Pink80
|
||||
)
|
||||
|
||||
private val LightColorScheme = lightColorScheme(
|
||||
primary = Purple40,
|
||||
secondary = PurpleGrey40,
|
||||
tertiary = Pink40
|
||||
|
||||
/* Other default colors to override
|
||||
background = Color(0xFFFFFBFE),
|
||||
surface = Color(0xFFFFFBFE),
|
||||
onPrimary = Color.White,
|
||||
onSecondary = Color.White,
|
||||
onTertiary = Color.White,
|
||||
onBackground = Color(0xFF1C1B1F),
|
||||
onSurface = Color(0xFF1C1B1F),
|
||||
*/
|
||||
)
|
||||
|
||||
@Composable
|
||||
fun LlamaAndroidTheme(
|
||||
darkTheme: Boolean = isSystemInDarkTheme(),
|
||||
// Dynamic color is available on Android 12+
|
||||
dynamicColor: Boolean = true,
|
||||
content: @Composable () -> Unit
|
||||
) {
|
||||
val colorScheme = when {
|
||||
dynamicColor && Build.VERSION.SDK_INT >= Build.VERSION_CODES.S -> {
|
||||
val context = LocalContext.current
|
||||
if (darkTheme) dynamicDarkColorScheme(context) else dynamicLightColorScheme(context)
|
||||
}
|
||||
|
||||
darkTheme -> DarkColorScheme
|
||||
else -> LightColorScheme
|
||||
}
|
||||
val view = LocalView.current
|
||||
if (!view.isInEditMode) {
|
||||
SideEffect {
|
||||
val window = (view.context as Activity).window
|
||||
window.statusBarColor = colorScheme.primary.toArgb()
|
||||
WindowCompat.getInsetsController(window, view).isAppearanceLightStatusBars = darkTheme
|
||||
}
|
||||
}
|
||||
|
||||
MaterialTheme(
|
||||
colorScheme = colorScheme,
|
||||
typography = Typography,
|
||||
content = content
|
||||
)
|
||||
}
|
||||
|
|
@ -1,34 +0,0 @@
|
|||
package com.example.llama.ui.theme
|
||||
|
||||
import androidx.compose.material3.Typography
|
||||
import androidx.compose.ui.text.TextStyle
|
||||
import androidx.compose.ui.text.font.FontFamily
|
||||
import androidx.compose.ui.text.font.FontWeight
|
||||
import androidx.compose.ui.unit.sp
|
||||
|
||||
// Set of Material typography styles to start with
|
||||
val Typography = Typography(
|
||||
bodyLarge = TextStyle(
|
||||
fontFamily = FontFamily.Default,
|
||||
fontWeight = FontWeight.Normal,
|
||||
fontSize = 16.sp,
|
||||
lineHeight = 24.sp,
|
||||
letterSpacing = 0.5.sp
|
||||
)
|
||||
/* Other default text styles to override
|
||||
titleLarge = TextStyle(
|
||||
fontFamily = FontFamily.Default,
|
||||
fontWeight = FontWeight.Normal,
|
||||
fontSize = 22.sp,
|
||||
lineHeight = 28.sp,
|
||||
letterSpacing = 0.sp
|
||||
),
|
||||
labelSmall = TextStyle(
|
||||
fontFamily = FontFamily.Default,
|
||||
fontWeight = FontWeight.Medium,
|
||||
fontSize = 11.sp,
|
||||
lineHeight = 16.sp,
|
||||
letterSpacing = 0.5.sp
|
||||
)
|
||||
*/
|
||||
)
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
<shape xmlns:android="http://schemas.android.com/apk/res/android" android:shape="rectangle">
|
||||
<solid android:color="#E5E5EA" />
|
||||
<corners android:radius="16dp" />
|
||||
</shape>
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
<shape xmlns:android="http://schemas.android.com/apk/res/android" android:shape="rectangle">
|
||||
<solid android:color="#4285F4" />
|
||||
<corners android:radius="16dp" />
|
||||
</shape>
|
||||
|
|
@ -0,0 +1,10 @@
|
|||
<vector xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
android:width="24dp"
|
||||
android:height="24dp"
|
||||
android:viewportWidth="24"
|
||||
android:viewportHeight="24"
|
||||
android:tint="?attr/colorControlNormal">
|
||||
<path
|
||||
android:fillColor="@android:color/white"
|
||||
android:pathData="M20,6h-8l-2,-2L4,4c-1.1,0 -1.99,0.9 -1.99,2L2,18c0,1.1 0.9,2 2,2h16c1.1,0 2,-0.9 2,-2L22,8c0,-1.1 -0.9,-2 -2,-2zM20,18L4,18L4,8h16v10z"/>
|
||||
</vector>
|
||||
|
|
@ -0,0 +1,11 @@
|
|||
<vector xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
android:width="24dp"
|
||||
android:height="24dp"
|
||||
android:viewportWidth="24"
|
||||
android:viewportHeight="24"
|
||||
android:tint="?attr/colorControlNormal"
|
||||
android:autoMirrored="true">
|
||||
<path
|
||||
android:fillColor="@android:color/white"
|
||||
android:pathData="M4.01,6.03l7.51,3.22 -7.52,-1 0.01,-2.22m7.5,8.72L4,17.97v-2.22l7.51,-1M2.01,3L2,10l15,2 -15,2 0.01,7L23,12 2.01,3z"/>
|
||||
</vector>
|
||||
|
|
@ -0,0 +1,78 @@
|
|||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
xmlns:app="http://schemas.android.com/apk/res-auto"
|
||||
xmlns:tools="http://schemas.android.com/tools"
|
||||
android:id="@+id/main"
|
||||
android:layout_height="match_parent"
|
||||
android:layout_width="match_parent">
|
||||
|
||||
<LinearLayout
|
||||
android:fitsSystemWindows="true"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="match_parent"
|
||||
android:orientation="vertical"
|
||||
android:layout_marginEnd="4dp"
|
||||
tools:context=".MainActivity">
|
||||
|
||||
<ScrollView
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="0dp"
|
||||
android:layout_weight="1"
|
||||
android:fadeScrollbars="false">
|
||||
|
||||
<TextView
|
||||
android:id="@+id/gguf"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:layout_margin="16dp"
|
||||
android:text="Selected GGUF model's metadata will show here."
|
||||
style="@style/TextAppearance.MaterialComponents.Body2" />
|
||||
|
||||
</ScrollView>
|
||||
|
||||
<com.google.android.material.divider.MaterialDivider
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="2dp"
|
||||
android:layout_marginHorizontal="16dp"
|
||||
android:layout_marginVertical="8dp" />
|
||||
|
||||
<androidx.recyclerview.widget.RecyclerView
|
||||
android:id="@+id/messages"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="0dp"
|
||||
android:layout_weight="4"
|
||||
android:fadeScrollbars="false"
|
||||
android:scrollbars="vertical"
|
||||
app:reverseLayout="true"
|
||||
tools:listitem="@layout/item_message_assistant"/>
|
||||
|
||||
<LinearLayout
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:orientation="horizontal"
|
||||
android:paddingStart="16dp"
|
||||
android:paddingEnd="4dp">
|
||||
|
||||
<EditText
|
||||
android:id="@+id/user_input"
|
||||
android:enabled="false"
|
||||
android:layout_width="0dp"
|
||||
android:layout_weight="1"
|
||||
android:layout_height="match_parent"
|
||||
android:padding="8dp"
|
||||
style="@style/TextAppearance.MaterialComponents.Body2"
|
||||
android:hint="Please first pick a GGUF model file to import." />
|
||||
|
||||
<com.google.android.material.floatingactionbutton.FloatingActionButton
|
||||
android:id="@+id/fab"
|
||||
android:enabled="true"
|
||||
style="@style/Widget.Material3.FloatingActionButton.Primary"
|
||||
android:layout_width="wrap_content"
|
||||
android:layout_height="wrap_content"
|
||||
android:layout_margin="12dp"
|
||||
android:src="@drawable/outline_folder_open_24" />
|
||||
|
||||
</LinearLayout>
|
||||
|
||||
</LinearLayout>
|
||||
</androidx.constraintlayout.widget.ConstraintLayout>
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:layout_marginHorizontal="16dp"
|
||||
android:layout_marginVertical="8dp"
|
||||
android:gravity="start">
|
||||
|
||||
<TextView
|
||||
android:id="@+id/msg_content"
|
||||
android:layout_width="wrap_content"
|
||||
android:layout_height="wrap_content"
|
||||
android:background="@drawable/bg_assistant_message"
|
||||
android:padding="12dp"
|
||||
android:textColor="@android:color/black" />
|
||||
</LinearLayout>
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:layout_marginHorizontal="16dp"
|
||||
android:layout_marginVertical="8dp"
|
||||
android:gravity="end">
|
||||
|
||||
<TextView
|
||||
android:id="@+id/msg_content"
|
||||
android:layout_width="wrap_content"
|
||||
android:layout_height="wrap_content"
|
||||
android:background="@drawable/bg_user_message"
|
||||
android:padding="12dp"
|
||||
android:textColor="@android:color/white" />
|
||||
</LinearLayout>
|
||||
|
|
@ -1,3 +1,3 @@
|
|||
<resources>
|
||||
<string name="app_name">LlamaAndroid</string>
|
||||
<string name="app_name">AI Chat basic sample</string>
|
||||
</resources>
|
||||
|
|
|
|||
|
|
@ -1,5 +1,10 @@
|
|||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<resources>
|
||||
|
||||
<style name="Theme.LlamaAndroid" parent="android:Theme.Material.Light.NoActionBar" />
|
||||
<style name="Base.Theme.AiChatSample" parent="Theme.Material3.DayNight.NoActionBar">
|
||||
<!-- Customize your light theme here. -->
|
||||
<!-- <item name="colorPrimary">@color/my_light_primary</item> -->
|
||||
</style>
|
||||
|
||||
<style name="Theme.AiChatSample" parent="Base.Theme.AiChatSample" />
|
||||
</resources>
|
||||
|
|
|
|||
|
|
@ -1,6 +1,6 @@
|
|||
// Top-level build file where you can add configuration options common to all sub-projects/modules.
|
||||
plugins {
|
||||
id("com.android.application") version "8.2.0" apply false
|
||||
id("org.jetbrains.kotlin.android") version "1.9.0" apply false
|
||||
id("com.android.library") version "8.2.0" apply false
|
||||
alias(libs.plugins.android.application) apply false
|
||||
alias(libs.plugins.android.library) apply false
|
||||
alias(libs.plugins.jetbrains.kotlin.android) apply false
|
||||
}
|
||||
|
|
|
|||
|
|
@ -21,3 +21,4 @@ kotlin.code.style=official
|
|||
# resources declared in the library itself and none from the library's dependencies,
|
||||
# thereby reducing the size of the R class for that library
|
||||
android.nonTransitiveRClass=true
|
||||
android.native.buildOutput=verbose
|
||||
|
|
|
|||
|
|
@ -0,0 +1,53 @@
|
|||
[versions]
|
||||
|
||||
# Plugins
|
||||
agp = "8.13.0"
|
||||
kotlin = "2.2.20"
|
||||
|
||||
# AndroidX
|
||||
activity = "1.11.0"
|
||||
appcompat = "1.7.1"
|
||||
core-ktx = "1.17.0"
|
||||
constraint-layout = "2.2.1"
|
||||
datastore-preferences = "1.1.7"
|
||||
|
||||
# Material
|
||||
material = "1.13.0"
|
||||
|
||||
# Testing
|
||||
espresso-core = "3.7.0"
|
||||
androidx-junit = "1.3.0"
|
||||
junit = "4.13.2"
|
||||
|
||||
|
||||
[plugins]
|
||||
android-application = { id = "com.android.application", version.ref = "agp" }
|
||||
android-library = { id = "com.android.library", version.ref = "agp" }
|
||||
jetbrains-kotlin-android = { id = "org.jetbrains.kotlin.android", version.ref = "kotlin" }
|
||||
|
||||
|
||||
[libraries]
|
||||
|
||||
# AndroidX
|
||||
androidx-activity = { group = "androidx.activity", name = "activity", version.ref = "activity" }
|
||||
androidx-appcompat = { group = "androidx.appcompat", name = "appcompat", version.ref = "appcompat" }
|
||||
androidx-constraintlayout = { group = "androidx.constraintlayout", name = "constraintlayout", version.ref = "constraint-layout" }
|
||||
androidx-core-ktx = { group = "androidx.core", name = "core-ktx", version.ref = "core-ktx" }
|
||||
androidx-datastore-preferences = { group = "androidx.datastore", name = "datastore-preferences", version.ref = "datastore-preferences" }
|
||||
|
||||
#Material
|
||||
material = { group = "com.google.android.material", name = "material", version.ref = "material" }
|
||||
|
||||
# Testing
|
||||
androidx-espresso-core = { group = "androidx.test.espresso", name = "espresso-core", version.ref = "espresso-core" }
|
||||
androidx-junit = { group = "androidx.test.ext", name = "junit", version.ref = "androidx-junit" }
|
||||
junit = { group = "junit", name = "junit", version.ref = "junit" }
|
||||
|
||||
[bundles]
|
||||
androidx = [
|
||||
"androidx-activity",
|
||||
"androidx-appcompat",
|
||||
"androidx-constraintlayout",
|
||||
"androidx-core-ktx",
|
||||
"androidx-datastore-preferences",
|
||||
]
|
||||
|
|
@ -1,6 +1,6 @@
|
|||
#Thu Dec 21 14:31:09 AEDT 2023
|
||||
#Tue Apr 01 11:15:06 PDT 2025
|
||||
distributionBase=GRADLE_USER_HOME
|
||||
distributionPath=wrapper/dists
|
||||
distributionUrl=https\://services.gradle.org/distributions/gradle-8.2-bin.zip
|
||||
distributionUrl=https\://services.gradle.org/distributions/gradle-8.14.3-bin.zip
|
||||
zipStoreBase=GRADLE_USER_HOME
|
||||
zipStorePath=wrapper/dists
|
||||
|
|
|
|||
|
|
@ -0,0 +1,78 @@
|
|||
plugins {
|
||||
alias(libs.plugins.android.library)
|
||||
alias(libs.plugins.jetbrains.kotlin.android)
|
||||
}
|
||||
|
||||
android {
|
||||
namespace = "com.arm.aichat"
|
||||
compileSdk = 36
|
||||
|
||||
ndkVersion = "29.0.13113456"
|
||||
|
||||
defaultConfig {
|
||||
minSdk = 33
|
||||
|
||||
testInstrumentationRunner = "androidx.test.runner.AndroidJUnitRunner"
|
||||
consumerProguardFiles("consumer-rules.pro")
|
||||
|
||||
ndk {
|
||||
abiFilters += listOf("arm64-v8a", "x86_64")
|
||||
}
|
||||
externalNativeBuild {
|
||||
cmake {
|
||||
arguments += "-DCMAKE_BUILD_TYPE=Release"
|
||||
arguments += "-DCMAKE_MESSAGE_LOG_LEVEL=DEBUG"
|
||||
arguments += "-DCMAKE_VERBOSE_MAKEFILE=ON"
|
||||
|
||||
arguments += "-DBUILD_SHARED_LIBS=ON"
|
||||
arguments += "-DLLAMA_BUILD_COMMON=ON"
|
||||
arguments += "-DLLAMA_CURL=OFF"
|
||||
|
||||
arguments += "-DGGML_NATIVE=OFF"
|
||||
arguments += "-DGGML_BACKEND_DL=ON"
|
||||
arguments += "-DGGML_CPU_ALL_VARIANTS=ON"
|
||||
arguments += "-DGGML_LLAMAFILE=OFF"
|
||||
}
|
||||
}
|
||||
aarMetadata {
|
||||
minCompileSdk = 35
|
||||
}
|
||||
}
|
||||
externalNativeBuild {
|
||||
cmake {
|
||||
path("src/main/cpp/CMakeLists.txt")
|
||||
version = "3.31.6"
|
||||
}
|
||||
}
|
||||
compileOptions {
|
||||
sourceCompatibility = JavaVersion.VERSION_17
|
||||
targetCompatibility = JavaVersion.VERSION_17
|
||||
}
|
||||
kotlin {
|
||||
jvmToolchain(17)
|
||||
|
||||
compileOptions {
|
||||
targetCompatibility = JavaVersion.VERSION_17
|
||||
}
|
||||
}
|
||||
|
||||
packaging {
|
||||
resources {
|
||||
excludes += "/META-INF/{AL2.0,LGPL2.1}"
|
||||
}
|
||||
}
|
||||
|
||||
publishing {
|
||||
singleVariant("release") {
|
||||
withJavadocJar()
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
dependencies {
|
||||
implementation(libs.androidx.core.ktx)
|
||||
implementation(libs.androidx.datastore.preferences)
|
||||
|
||||
testImplementation(libs.junit)
|
||||
androidTestImplementation(libs.androidx.junit)
|
||||
}
|
||||
|
|
@ -0,0 +1,8 @@
|
|||
-keep class com.arm.aichat.* { *; }
|
||||
-keep class com.arm.aichat.gguf.* { *; }
|
||||
|
||||
-keepclasseswithmembernames class * {
|
||||
native <methods>;
|
||||
}
|
||||
|
||||
-keep class kotlin.Metadata { *; }
|
||||
|
|
@ -0,0 +1,56 @@
|
|||
cmake_minimum_required(VERSION 3.31.6)
|
||||
|
||||
project("ai-chat" VERSION 1.0.0 LANGUAGES C CXX)
|
||||
|
||||
set(CMAKE_C_STANDARD 11)
|
||||
set(CMAKE_C_STANDARD_REQUIRED true)
|
||||
|
||||
set(CMAKE_CXX_STANDARD 17)
|
||||
set(CMAKE_CXX_STANDARD_REQUIRED true)
|
||||
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS}" CACHE STRING "" FORCE)
|
||||
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS}" CACHE STRING "" FORCE)
|
||||
|
||||
# --------------------------------------------------------------------------
|
||||
# AI Chat library
|
||||
# --------------------------------------------------------------------------
|
||||
|
||||
if(DEFINED ANDROID_ABI)
|
||||
message(STATUS "Detected Android ABI: ${ANDROID_ABI}")
|
||||
if(ANDROID_ABI STREQUAL "arm64-v8a")
|
||||
set(GGML_SYSTEM_ARCH "ARM")
|
||||
set(GGML_CPU_KLEIDIAI ON)
|
||||
set(GGML_OPENMP ON)
|
||||
elseif(ANDROID_ABI STREQUAL "x86_64")
|
||||
set(GGML_SYSTEM_ARCH "x86")
|
||||
set(GGML_CPU_KLEIDIAI OFF)
|
||||
set(GGML_OPENMP OFF)
|
||||
else()
|
||||
message(FATAL_ERROR "Unsupported ABI: ${ANDROID_ABI}")
|
||||
endif()
|
||||
endif()
|
||||
|
||||
set(LLAMA_SRC ${CMAKE_CURRENT_LIST_DIR}/../../../../../../)
|
||||
add_subdirectory(${LLAMA_SRC} build-llama)
|
||||
|
||||
add_library(${CMAKE_PROJECT_NAME} SHARED
|
||||
ai_chat.cpp)
|
||||
|
||||
target_compile_definitions(${CMAKE_PROJECT_NAME} PRIVATE
|
||||
GGML_SYSTEM_ARCH=${GGML_SYSTEM_ARCH}
|
||||
GGML_CPU_KLEIDIAI=$<BOOL:${GGML_CPU_KLEIDIAI}>
|
||||
GGML_OPENMP=$<BOOL:${GGML_OPENMP}>
|
||||
)
|
||||
|
||||
target_include_directories(${CMAKE_PROJECT_NAME} PRIVATE
|
||||
${LLAMA_SRC}
|
||||
${LLAMA_SRC}/common
|
||||
${LLAMA_SRC}/include
|
||||
${LLAMA_SRC}/ggml/include
|
||||
${LLAMA_SRC}/ggml/src)
|
||||
|
||||
target_link_libraries(${CMAKE_PROJECT_NAME}
|
||||
llama
|
||||
common
|
||||
android
|
||||
log)
|
||||
|
|
@ -0,0 +1,565 @@
|
|||
#include <android/log.h>
|
||||
#include <jni.h>
|
||||
#include <iomanip>
|
||||
#include <cmath>
|
||||
#include <string>
|
||||
#include <unistd.h>
|
||||
#include <sampling.h>
|
||||
|
||||
#include "logging.h"
|
||||
#include "chat.h"
|
||||
#include "common.h"
|
||||
#include "llama.h"
|
||||
|
||||
template<class T>
|
||||
static std::string join(const std::vector<T> &values, const std::string &delim) {
|
||||
std::ostringstream str;
|
||||
for (size_t i = 0; i < values.size(); i++) {
|
||||
str << values[i];
|
||||
if (i < values.size() - 1) { str << delim; }
|
||||
}
|
||||
return str.str();
|
||||
}
|
||||
|
||||
/**
|
||||
* LLama resources: context, model, batch and sampler
|
||||
*/
|
||||
constexpr int N_THREADS_MIN = 2;
|
||||
constexpr int N_THREADS_MAX = 4;
|
||||
constexpr int N_THREADS_HEADROOM = 2;
|
||||
|
||||
constexpr int DEFAULT_CONTEXT_SIZE = 8192;
|
||||
constexpr int OVERFLOW_HEADROOM = 4;
|
||||
constexpr int BATCH_SIZE = 512;
|
||||
constexpr float DEFAULT_SAMPLER_TEMP = 0.3f;
|
||||
|
||||
static llama_model * g_model;
|
||||
static llama_context * g_context;
|
||||
static llama_batch g_batch;
|
||||
static common_chat_templates_ptr g_chat_templates;
|
||||
static common_sampler * g_sampler;
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT void JNICALL
|
||||
Java_com_arm_aichat_internal_InferenceEngineImpl_init(JNIEnv *env, jobject /*unused*/, jstring nativeLibDir) {
|
||||
// Set llama log handler to Android
|
||||
llama_log_set(aichat_android_log_callback, nullptr);
|
||||
|
||||
// Loading all CPU backend variants
|
||||
const auto *path_to_backend = env->GetStringUTFChars(nativeLibDir, 0);
|
||||
LOGi("Loading backends from %s", path_to_backend);
|
||||
ggml_backend_load_all_from_path(path_to_backend);
|
||||
env->ReleaseStringUTFChars(nativeLibDir, path_to_backend);
|
||||
|
||||
// Initialize backends
|
||||
llama_backend_init();
|
||||
LOGi("Backend initiated; Log handler set.");
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jint JNICALL
|
||||
Java_com_arm_aichat_internal_InferenceEngineImpl_load(JNIEnv *env, jobject, jstring jmodel_path) {
|
||||
llama_model_params model_params = llama_model_default_params();
|
||||
|
||||
const auto *model_path = env->GetStringUTFChars(jmodel_path, 0);
|
||||
LOGd("%s: Loading model from: \n%s\n", __func__, model_path);
|
||||
|
||||
auto *model = llama_model_load_from_file(model_path, model_params);
|
||||
env->ReleaseStringUTFChars(jmodel_path, model_path);
|
||||
if (!model) {
|
||||
return 1;
|
||||
}
|
||||
g_model = model;
|
||||
return 0;
|
||||
}
|
||||
|
||||
static llama_context *init_context(llama_model *model, const int n_ctx = DEFAULT_CONTEXT_SIZE) {
|
||||
if (!model) {
|
||||
LOGe("%s: model cannot be null", __func__);
|
||||
return nullptr;
|
||||
}
|
||||
|
||||
// Multi-threading setup
|
||||
const int n_threads = std::max(N_THREADS_MIN, std::min(N_THREADS_MAX,
|
||||
(int) sysconf(_SC_NPROCESSORS_ONLN) -
|
||||
N_THREADS_HEADROOM));
|
||||
LOGi("%s: Using %d threads", __func__, n_threads);
|
||||
|
||||
// Context parameters setup
|
||||
llama_context_params ctx_params = llama_context_default_params();
|
||||
const int trained_context_size = llama_model_n_ctx_train(model);
|
||||
if (n_ctx > trained_context_size) {
|
||||
LOGw("%s: Model was trained with only %d context size! Enforcing %d context size...",
|
||||
__func__, trained_context_size, n_ctx);
|
||||
}
|
||||
ctx_params.n_ctx = n_ctx;
|
||||
ctx_params.n_batch = BATCH_SIZE;
|
||||
ctx_params.n_ubatch = BATCH_SIZE;
|
||||
ctx_params.n_threads = n_threads;
|
||||
ctx_params.n_threads_batch = n_threads;
|
||||
auto *context = llama_init_from_model(g_model, ctx_params);
|
||||
if (context == nullptr) {
|
||||
LOGe("%s: llama_new_context_with_model() returned null)", __func__);
|
||||
}
|
||||
return context;
|
||||
}
|
||||
|
||||
static common_sampler *new_sampler(float temp) {
|
||||
common_params_sampling sparams;
|
||||
sparams.temp = temp;
|
||||
return common_sampler_init(g_model, sparams);
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jint JNICALL
|
||||
Java_com_arm_aichat_internal_InferenceEngineImpl_prepare(JNIEnv * /*env*/, jobject /*unused*/) {
|
||||
auto *context = init_context(g_model);
|
||||
if (!context) { return 1; }
|
||||
g_context = context;
|
||||
g_batch = llama_batch_init(BATCH_SIZE, 0, 1);
|
||||
g_chat_templates = common_chat_templates_init(g_model, "");
|
||||
g_sampler = new_sampler(DEFAULT_SAMPLER_TEMP);
|
||||
return 0;
|
||||
}
|
||||
|
||||
static std::string get_backend() {
|
||||
std::vector<std::string> backends;
|
||||
for (size_t i = 0; i < ggml_backend_reg_count(); i++) {
|
||||
auto *reg = ggml_backend_reg_get(i);
|
||||
std::string name = ggml_backend_reg_name(reg);
|
||||
if (name != "CPU") {
|
||||
backends.push_back(ggml_backend_reg_name(reg));
|
||||
}
|
||||
}
|
||||
return backends.empty() ? "CPU" : join(backends, ",");
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jstring JNICALL
|
||||
Java_com_arm_aichat_internal_InferenceEngineImpl_systemInfo(JNIEnv *env, jobject /*unused*/) {
|
||||
return env->NewStringUTF(llama_print_system_info());
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jstring JNICALL
|
||||
Java_com_arm_aichat_internal_InferenceEngineImpl_benchModel(JNIEnv *env, jobject /*unused*/, jint pp, jint tg,
|
||||
jint pl, jint nr) {
|
||||
auto *context = init_context(g_model, pp);
|
||||
if (!context) {
|
||||
const auto *const err_msg = "Fail to init_context! Bench aborted.";
|
||||
LOGe(err_msg);
|
||||
return env->NewStringUTF(err_msg);
|
||||
}
|
||||
|
||||
auto pp_avg = 0.0;
|
||||
auto tg_avg = 0.0;
|
||||
auto pp_std = 0.0;
|
||||
auto tg_std = 0.0;
|
||||
|
||||
const uint32_t n_ctx = llama_n_ctx(context);
|
||||
LOGi("n_ctx = %d", n_ctx);
|
||||
|
||||
int i, j;
|
||||
int nri;
|
||||
for (nri = 0; nri < nr; nri++) {
|
||||
LOGi("Benchmark prompt processing (pp = %d)", pp);
|
||||
|
||||
common_batch_clear(g_batch);
|
||||
|
||||
const int n_tokens = pp;
|
||||
for (i = 0; i < n_tokens; i++) {
|
||||
common_batch_add(g_batch, 0, i, {0}, false);
|
||||
}
|
||||
|
||||
g_batch.logits[g_batch.n_tokens - 1] = true;
|
||||
llama_memory_clear(llama_get_memory(context), false);
|
||||
|
||||
const auto t_pp_start = ggml_time_us();
|
||||
if (llama_decode(context, g_batch) != 0) {
|
||||
LOGe("llama_decode() failed during prompt processing");
|
||||
}
|
||||
const auto t_pp_end = ggml_time_us();
|
||||
|
||||
// bench text generation
|
||||
|
||||
LOGi("Benchmark text generation (tg = %d)", tg);
|
||||
|
||||
llama_memory_clear(llama_get_memory(context), false);
|
||||
const auto t_tg_start = ggml_time_us();
|
||||
for (i = 0; i < tg; i++) {
|
||||
common_batch_clear(g_batch);
|
||||
for (j = 0; j < pl; j++) {
|
||||
common_batch_add(g_batch, 0, i, {j}, true);
|
||||
}
|
||||
|
||||
if (llama_decode(context, g_batch) != 0) {
|
||||
LOGe("llama_decode() failed during text generation");
|
||||
}
|
||||
}
|
||||
const auto t_tg_end = ggml_time_us();
|
||||
|
||||
llama_memory_clear(llama_get_memory(context), false);
|
||||
|
||||
const auto t_pp = double(t_pp_end - t_pp_start) / 1000000.0;
|
||||
const auto t_tg = double(t_tg_end - t_tg_start) / 1000000.0;
|
||||
|
||||
const auto speed_pp = double(pp) / t_pp;
|
||||
const auto speed_tg = double(pl * tg) / t_tg;
|
||||
|
||||
pp_avg += speed_pp;
|
||||
tg_avg += speed_tg;
|
||||
|
||||
pp_std += speed_pp * speed_pp;
|
||||
tg_std += speed_tg * speed_tg;
|
||||
|
||||
LOGi("pp %f t/s, tg %f t/s", speed_pp, speed_tg);
|
||||
}
|
||||
|
||||
llama_free(context);
|
||||
|
||||
pp_avg /= double(nr);
|
||||
tg_avg /= double(nr);
|
||||
|
||||
if (nr > 1) {
|
||||
pp_std = sqrt(pp_std / double(nr - 1) - pp_avg * pp_avg * double(nr) / double(nr - 1));
|
||||
tg_std = sqrt(tg_std / double(nr - 1) - tg_avg * tg_avg * double(nr) / double(nr - 1));
|
||||
} else {
|
||||
pp_std = 0;
|
||||
tg_std = 0;
|
||||
}
|
||||
|
||||
char model_desc[128];
|
||||
llama_model_desc(g_model, model_desc, sizeof(model_desc));
|
||||
|
||||
const auto model_size = double(llama_model_size(g_model)) / 1024.0 / 1024.0 / 1024.0;
|
||||
const auto model_n_params = double(llama_model_n_params(g_model)) / 1e9;
|
||||
|
||||
const auto backend = get_backend();
|
||||
std::stringstream result;
|
||||
result << std::setprecision(3);
|
||||
result << "| model | size | params | backend | test | t/s |\n";
|
||||
result << "| --- | --- | --- | --- | --- | --- |\n";
|
||||
result << "| " << model_desc << " | " << model_size << "GiB | " << model_n_params << "B | "
|
||||
<< backend << " | pp " << pp << " | " << pp_avg << " ± " << pp_std << " |\n";
|
||||
result << "| " << model_desc << " | " << model_size << "GiB | " << model_n_params << "B | "
|
||||
<< backend << " | tg " << tg << " | " << tg_avg << " ± " << tg_std << " |\n";
|
||||
return env->NewStringUTF(result.str().c_str());
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
* Completion loop's long-term states:
|
||||
* - chat management
|
||||
* - position tracking
|
||||
*/
|
||||
constexpr const char *ROLE_SYSTEM = "system";
|
||||
constexpr const char *ROLE_USER = "user";
|
||||
constexpr const char *ROLE_ASSISTANT = "assistant";
|
||||
|
||||
static std::vector<common_chat_msg> chat_msgs;
|
||||
static llama_pos system_prompt_position;
|
||||
static llama_pos current_position;
|
||||
|
||||
static void reset_long_term_states(const bool clear_kv_cache = true) {
|
||||
chat_msgs.clear();
|
||||
system_prompt_position = 0;
|
||||
current_position = 0;
|
||||
|
||||
if (clear_kv_cache)
|
||||
llama_memory_clear(llama_get_memory(g_context), false);
|
||||
}
|
||||
|
||||
/**
|
||||
* TODO-hyin: implement sliding-window version as a better alternative
|
||||
*
|
||||
* Context shifting by discarding the older half of the tokens appended after system prompt:
|
||||
* - take the [system_prompt_position] first tokens from the original prompt
|
||||
* - take half of the last (system_prompt_position - system_prompt_position) tokens
|
||||
* - recompute the logits in batches
|
||||
*/
|
||||
static void shift_context() {
|
||||
const int n_discard = (current_position - system_prompt_position) / 2;
|
||||
LOGi("%s: Discarding %d tokens", __func__, n_discard);
|
||||
llama_memory_seq_rm(llama_get_memory(g_context), 0, system_prompt_position, system_prompt_position + n_discard);
|
||||
llama_memory_seq_add(llama_get_memory(g_context), 0, system_prompt_position + n_discard, current_position, -n_discard);
|
||||
current_position -= n_discard;
|
||||
LOGi("%s: Context shifting done! Current position: %d", __func__, current_position);
|
||||
}
|
||||
|
||||
static std::string chat_add_and_format(const std::string &role, const std::string &content) {
|
||||
common_chat_msg new_msg;
|
||||
new_msg.role = role;
|
||||
new_msg.content = content;
|
||||
auto formatted = common_chat_format_single(
|
||||
g_chat_templates.get(), chat_msgs, new_msg, role == ROLE_USER, /* use_jinja */ false);
|
||||
chat_msgs.push_back(new_msg);
|
||||
LOGi("%s: Formatted and added %s message: \n%s\n", __func__, role.c_str(), formatted.c_str());
|
||||
return formatted;
|
||||
}
|
||||
|
||||
/**
|
||||
* Completion loop's short-term states:
|
||||
* - stop generation position
|
||||
* - token chars caching
|
||||
* - current assistant message being generated
|
||||
*/
|
||||
static llama_pos stop_generation_position;
|
||||
static std::string cached_token_chars;
|
||||
static std::ostringstream assistant_ss;
|
||||
|
||||
static void reset_short_term_states() {
|
||||
stop_generation_position = 0;
|
||||
cached_token_chars.clear();
|
||||
assistant_ss.str("");
|
||||
}
|
||||
|
||||
static int decode_tokens_in_batches(
|
||||
llama_context *context,
|
||||
llama_batch &batch,
|
||||
const llama_tokens &tokens,
|
||||
const llama_pos start_pos,
|
||||
const bool compute_last_logit = false) {
|
||||
// Process tokens in batches using the global batch
|
||||
LOGd("%s: Decode %d tokens starting at position %d", __func__, (int) tokens.size(), start_pos);
|
||||
for (int i = 0; i < (int) tokens.size(); i += BATCH_SIZE) {
|
||||
const int cur_batch_size = std::min((int) tokens.size() - i, BATCH_SIZE);
|
||||
common_batch_clear(batch);
|
||||
LOGv("%s: Preparing a batch size of %d starting at: %d", __func__, cur_batch_size, i);
|
||||
|
||||
// Shift context if current batch cannot fit into the context
|
||||
if (start_pos + i + cur_batch_size >= DEFAULT_CONTEXT_SIZE - OVERFLOW_HEADROOM) {
|
||||
LOGw("%s: Current batch won't fit into context! Shifting...", __func__);
|
||||
shift_context();
|
||||
}
|
||||
|
||||
// Add tokens to the batch with proper positions
|
||||
for (int j = 0; j < cur_batch_size; j++) {
|
||||
const llama_token token_id = tokens[i + j];
|
||||
const llama_pos position = start_pos + i + j;
|
||||
const bool want_logit = compute_last_logit && (i + j == tokens.size() - 1);
|
||||
common_batch_add(batch, token_id, position, {0}, want_logit);
|
||||
}
|
||||
|
||||
// Decode this batch
|
||||
const int decode_result = llama_decode(context, batch);
|
||||
if (decode_result) {
|
||||
LOGe("%s: llama_decode failed w/ %d", __func__, decode_result);
|
||||
return 1;
|
||||
}
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jint JNICALL
|
||||
Java_com_arm_aichat_internal_InferenceEngineImpl_processSystemPrompt(
|
||||
JNIEnv *env,
|
||||
jobject /*unused*/,
|
||||
jstring jsystem_prompt
|
||||
) {
|
||||
// Reset long-term & short-term states
|
||||
reset_long_term_states();
|
||||
reset_short_term_states();
|
||||
|
||||
// Obtain system prompt from JEnv
|
||||
const auto *system_prompt = env->GetStringUTFChars(jsystem_prompt, nullptr);
|
||||
LOGd("%s: System prompt received: \n%s", __func__, system_prompt);
|
||||
std::string formatted_system_prompt(system_prompt);
|
||||
env->ReleaseStringUTFChars(jsystem_prompt, system_prompt);
|
||||
|
||||
// Format system prompt if applicable
|
||||
const bool has_chat_template = common_chat_templates_was_explicit(g_chat_templates.get());
|
||||
if (has_chat_template) {
|
||||
formatted_system_prompt = chat_add_and_format(ROLE_SYSTEM, system_prompt);
|
||||
}
|
||||
|
||||
// Tokenize system prompt
|
||||
const auto system_tokens = common_tokenize(g_context, formatted_system_prompt,
|
||||
has_chat_template, has_chat_template);
|
||||
for (auto id: system_tokens) {
|
||||
LOGv("token: `%s`\t -> `%d`", common_token_to_piece(g_context, id).c_str(), id);
|
||||
}
|
||||
|
||||
// Handle context overflow
|
||||
const int max_batch_size = DEFAULT_CONTEXT_SIZE - OVERFLOW_HEADROOM;
|
||||
if ((int) system_tokens.size() > max_batch_size) {
|
||||
LOGe("%s: System prompt too long for context! %d tokens, max: %d",
|
||||
__func__, (int) system_tokens.size(), max_batch_size);
|
||||
return 1;
|
||||
}
|
||||
|
||||
// Decode system tokens in batches
|
||||
if (decode_tokens_in_batches(g_context, g_batch, system_tokens, current_position)) {
|
||||
LOGe("%s: llama_decode() failed!", __func__);
|
||||
return 2;
|
||||
}
|
||||
|
||||
// Update position
|
||||
system_prompt_position = current_position = (int) system_tokens.size();
|
||||
return 0;
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jint JNICALL
|
||||
Java_com_arm_aichat_internal_InferenceEngineImpl_processUserPrompt(
|
||||
JNIEnv *env,
|
||||
jobject /*unused*/,
|
||||
jstring juser_prompt,
|
||||
jint n_predict
|
||||
) {
|
||||
// Reset short-term states
|
||||
reset_short_term_states();
|
||||
|
||||
// Obtain and tokenize user prompt
|
||||
const auto *const user_prompt = env->GetStringUTFChars(juser_prompt, nullptr);
|
||||
LOGd("%s: User prompt received: \n%s", __func__, user_prompt);
|
||||
std::string formatted_user_prompt(user_prompt);
|
||||
env->ReleaseStringUTFChars(juser_prompt, user_prompt);
|
||||
|
||||
// Format user prompt if applicable
|
||||
const bool has_chat_template = common_chat_templates_was_explicit(g_chat_templates.get());
|
||||
if (has_chat_template) {
|
||||
formatted_user_prompt = chat_add_and_format(ROLE_USER, user_prompt);
|
||||
}
|
||||
|
||||
// Decode formatted user prompts
|
||||
auto user_tokens = common_tokenize(g_context, formatted_user_prompt, has_chat_template, has_chat_template);
|
||||
for (auto id: user_tokens) {
|
||||
LOGv("token: `%s`\t -> `%d`", common_token_to_piece(g_context, id).c_str(), id);
|
||||
}
|
||||
|
||||
// Ensure user prompt doesn't exceed the context size by truncating if necessary.
|
||||
const int user_prompt_size = (int) user_tokens.size();
|
||||
const int max_batch_size = DEFAULT_CONTEXT_SIZE - OVERFLOW_HEADROOM;
|
||||
if (user_prompt_size > max_batch_size) {
|
||||
const int skipped_tokens = user_prompt_size - max_batch_size;
|
||||
user_tokens.resize(max_batch_size);
|
||||
LOGw("%s: User prompt too long! Skipped %d tokens!", __func__, skipped_tokens);
|
||||
}
|
||||
|
||||
// Decode user tokens in batches
|
||||
if (decode_tokens_in_batches(g_context, g_batch, user_tokens, current_position, true)) {
|
||||
LOGe("%s: llama_decode() failed!", __func__);
|
||||
return 2;
|
||||
}
|
||||
|
||||
// Update position
|
||||
current_position += user_prompt_size;
|
||||
stop_generation_position = current_position + user_prompt_size + n_predict;
|
||||
return 0;
|
||||
}
|
||||
|
||||
static bool is_valid_utf8(const char *string) {
|
||||
if (!string) { return true; }
|
||||
|
||||
const auto *bytes = (const unsigned char *) string;
|
||||
int num;
|
||||
|
||||
while (*bytes != 0x00) {
|
||||
if ((*bytes & 0x80) == 0x00) {
|
||||
// U+0000 to U+007F
|
||||
num = 1;
|
||||
} else if ((*bytes & 0xE0) == 0xC0) {
|
||||
// U+0080 to U+07FF
|
||||
num = 2;
|
||||
} else if ((*bytes & 0xF0) == 0xE0) {
|
||||
// U+0800 to U+FFFF
|
||||
num = 3;
|
||||
} else if ((*bytes & 0xF8) == 0xF0) {
|
||||
// U+10000 to U+10FFFF
|
||||
num = 4;
|
||||
} else {
|
||||
return false;
|
||||
}
|
||||
|
||||
bytes += 1;
|
||||
for (int i = 1; i < num; ++i) {
|
||||
if ((*bytes & 0xC0) != 0x80) {
|
||||
return false;
|
||||
}
|
||||
bytes += 1;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jstring JNICALL
|
||||
Java_com_arm_aichat_internal_InferenceEngineImpl_generateNextToken(
|
||||
JNIEnv *env,
|
||||
jobject /*unused*/
|
||||
) {
|
||||
// Infinite text generation via context shifting
|
||||
if (current_position >= DEFAULT_CONTEXT_SIZE - OVERFLOW_HEADROOM) {
|
||||
LOGw("%s: Context full! Shifting...", __func__);
|
||||
shift_context();
|
||||
}
|
||||
|
||||
// Stop if reaching the marked position
|
||||
if (current_position >= stop_generation_position) {
|
||||
LOGw("%s: STOP: hitting stop position: %d", __func__, stop_generation_position);
|
||||
return nullptr;
|
||||
}
|
||||
|
||||
// Sample next token
|
||||
const auto new_token_id = common_sampler_sample(g_sampler, g_context, -1);
|
||||
common_sampler_accept(g_sampler, new_token_id, true);
|
||||
|
||||
// Populate the batch with new token, then decode
|
||||
common_batch_clear(g_batch);
|
||||
common_batch_add(g_batch, new_token_id, current_position, {0}, true);
|
||||
if (llama_decode(g_context, g_batch) != 0) {
|
||||
LOGe("%s: llama_decode() failed for generated token", __func__);
|
||||
return nullptr;
|
||||
}
|
||||
|
||||
// Update position
|
||||
current_position++;
|
||||
|
||||
// Stop if next token is EOG
|
||||
if (llama_vocab_is_eog(llama_model_get_vocab(g_model), new_token_id)) {
|
||||
LOGd("id: %d,\tIS EOG!\nSTOP.", new_token_id);
|
||||
chat_add_and_format(ROLE_ASSISTANT, assistant_ss.str());
|
||||
return nullptr;
|
||||
}
|
||||
|
||||
// If not EOG, convert to text
|
||||
auto new_token_chars = common_token_to_piece(g_context, new_token_id);
|
||||
cached_token_chars += new_token_chars;
|
||||
|
||||
// Create and return a valid UTF-8 Java string
|
||||
jstring result = nullptr;
|
||||
if (is_valid_utf8(cached_token_chars.c_str())) {
|
||||
result = env->NewStringUTF(cached_token_chars.c_str());
|
||||
LOGv("id: %d,\tcached: `%s`,\tnew: `%s`", new_token_id, cached_token_chars.c_str(), new_token_chars.c_str());
|
||||
|
||||
assistant_ss << cached_token_chars;
|
||||
cached_token_chars.clear();
|
||||
} else {
|
||||
LOGv("id: %d,\tappend to cache", new_token_id);
|
||||
result = env->NewStringUTF("");
|
||||
}
|
||||
return result;
|
||||
}
|
||||
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT void JNICALL
|
||||
Java_com_arm_aichat_internal_InferenceEngineImpl_unload(JNIEnv * /*unused*/, jobject /*unused*/) {
|
||||
// Reset long-term & short-term states
|
||||
reset_long_term_states();
|
||||
reset_short_term_states();
|
||||
|
||||
// Free up resources
|
||||
common_sampler_free(g_sampler);
|
||||
g_chat_templates.reset();
|
||||
llama_batch_free(g_batch);
|
||||
llama_free(g_context);
|
||||
llama_model_free(g_model);
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT void JNICALL
|
||||
Java_com_arm_aichat_internal_InferenceEngineImpl_shutdown(JNIEnv *env, jobject /*unused*/) {
|
||||
llama_backend_free();
|
||||
}
|
||||
|
|
@ -0,0 +1,61 @@
|
|||
//
|
||||
// Created by Han Yin on 10/31/25.
|
||||
//
|
||||
|
||||
#ifndef AICHAT_LOGGING_H
|
||||
#define AICHAT_LOGGING_H
|
||||
|
||||
#endif //AICHAT_LOGGING_H
|
||||
|
||||
#pragma once
|
||||
#include <android/log.h>
|
||||
|
||||
#ifndef LOG_TAG
|
||||
#define LOG_TAG "ai-chat"
|
||||
#endif
|
||||
|
||||
#ifndef LOG_MIN_LEVEL
|
||||
#if defined(NDEBUG)
|
||||
#define LOG_MIN_LEVEL ANDROID_LOG_INFO
|
||||
#else
|
||||
#define LOG_MIN_LEVEL ANDROID_LOG_VERBOSE
|
||||
#endif
|
||||
#endif
|
||||
|
||||
static inline int ai_should_log(int prio) {
|
||||
return __android_log_is_loggable(prio, LOG_TAG, LOG_MIN_LEVEL);
|
||||
}
|
||||
|
||||
#if LOG_MIN_LEVEL <= ANDROID_LOG_VERBOSE
|
||||
#define LOGv(...) do { if (ai_should_log(ANDROID_LOG_VERBOSE)) __android_log_print(ANDROID_LOG_VERBOSE, LOG_TAG, __VA_ARGS__); } while (0)
|
||||
#else
|
||||
#define LOGv(...) ((void)0)
|
||||
#endif
|
||||
|
||||
#if LOG_MIN_LEVEL <= ANDROID_LOG_DEBUG
|
||||
#define LOGd(...) do { if (ai_should_log(ANDROID_LOG_DEBUG)) __android_log_print(ANDROID_LOG_DEBUG, LOG_TAG, __VA_ARGS__); } while (0)
|
||||
#else
|
||||
#define LOGd(...) ((void)0)
|
||||
#endif
|
||||
|
||||
#define LOGi(...) do { if (ai_should_log(ANDROID_LOG_INFO )) __android_log_print(ANDROID_LOG_INFO , LOG_TAG, __VA_ARGS__); } while (0)
|
||||
#define LOGw(...) do { if (ai_should_log(ANDROID_LOG_WARN )) __android_log_print(ANDROID_LOG_WARN , LOG_TAG, __VA_ARGS__); } while (0)
|
||||
#define LOGe(...) do { if (ai_should_log(ANDROID_LOG_ERROR)) __android_log_print(ANDROID_LOG_ERROR, LOG_TAG, __VA_ARGS__); } while (0)
|
||||
|
||||
static inline int android_log_prio_from_ggml(enum ggml_log_level level) {
|
||||
switch (level) {
|
||||
case GGML_LOG_LEVEL_ERROR: return ANDROID_LOG_ERROR;
|
||||
case GGML_LOG_LEVEL_WARN: return ANDROID_LOG_WARN;
|
||||
case GGML_LOG_LEVEL_INFO: return ANDROID_LOG_INFO;
|
||||
case GGML_LOG_LEVEL_DEBUG: return ANDROID_LOG_DEBUG;
|
||||
default: return ANDROID_LOG_DEFAULT;
|
||||
}
|
||||
}
|
||||
|
||||
static inline void aichat_android_log_callback(enum ggml_log_level level,
|
||||
const char* text,
|
||||
void* /*user*/) {
|
||||
const int prio = android_log_prio_from_ggml(level);
|
||||
if (!ai_should_log(prio)) return;
|
||||
__android_log_write(prio, LOG_TAG, text);
|
||||
}
|
||||
|
|
@ -0,0 +1,14 @@
|
|||
package com.arm.aichat
|
||||
|
||||
import android.content.Context
|
||||
import com.arm.aichat.internal.InferenceEngineImpl
|
||||
|
||||
/**
|
||||
* Main entry point for Arm's AI Chat library.
|
||||
*/
|
||||
object AiChat {
|
||||
/**
|
||||
* Get the inference engine single instance.
|
||||
*/
|
||||
fun getInferenceEngine(context: Context) = InferenceEngineImpl.getInstance(context)
|
||||
}
|
||||
|
|
@ -0,0 +1,89 @@
|
|||
package com.arm.aichat
|
||||
|
||||
import com.arm.aichat.InferenceEngine.State
|
||||
import kotlinx.coroutines.flow.Flow
|
||||
import kotlinx.coroutines.flow.StateFlow
|
||||
|
||||
/**
|
||||
* Interface defining the core LLM inference operations.
|
||||
*/
|
||||
interface InferenceEngine {
|
||||
/**
|
||||
* Current state of the inference engine
|
||||
*/
|
||||
val state: StateFlow<State>
|
||||
|
||||
/**
|
||||
* Load a model from the given path.
|
||||
*
|
||||
* @throws UnsupportedArchitectureException if model architecture not supported
|
||||
*/
|
||||
suspend fun loadModel(pathToModel: String)
|
||||
|
||||
/**
|
||||
* Sends a system prompt to the loaded model
|
||||
*/
|
||||
suspend fun setSystemPrompt(systemPrompt: String)
|
||||
|
||||
/**
|
||||
* Sends a user prompt to the loaded model and returns a Flow of generated tokens.
|
||||
*/
|
||||
fun sendUserPrompt(message: String, predictLength: Int = DEFAULT_PREDICT_LENGTH): Flow<String>
|
||||
|
||||
/**
|
||||
* Runs a benchmark with the specified parameters.
|
||||
*/
|
||||
suspend fun bench(pp: Int, tg: Int, pl: Int, nr: Int = 1): String
|
||||
|
||||
/**
|
||||
* Unloads the currently loaded model.
|
||||
*/
|
||||
suspend fun cleanUp()
|
||||
|
||||
/**
|
||||
* Cleans up resources when the engine is no longer needed.
|
||||
*/
|
||||
fun destroy()
|
||||
|
||||
/**
|
||||
* States of the inference engine
|
||||
*/
|
||||
sealed class State {
|
||||
object Uninitialized : State()
|
||||
object Initializing : State()
|
||||
object Initialized : State()
|
||||
|
||||
object LoadingModel : State()
|
||||
object UnloadingModel : State()
|
||||
object ModelReady : State()
|
||||
|
||||
object Benchmarking : State()
|
||||
object ProcessingSystemPrompt : State()
|
||||
object ProcessingUserPrompt : State()
|
||||
|
||||
object Generating : State()
|
||||
|
||||
data class Error(val exception: Exception) : State()
|
||||
}
|
||||
|
||||
companion object {
|
||||
const val DEFAULT_PREDICT_LENGTH = 1024
|
||||
}
|
||||
}
|
||||
|
||||
val State.isUninterruptible
|
||||
get() = this is State.Initializing ||
|
||||
this is State.LoadingModel ||
|
||||
this is State.UnloadingModel ||
|
||||
this is State.Benchmarking ||
|
||||
this is State.ProcessingSystemPrompt ||
|
||||
this is State.ProcessingUserPrompt
|
||||
|
||||
val State.isModelLoaded: Boolean
|
||||
get() = this is State.ModelReady ||
|
||||
this is State.Benchmarking ||
|
||||
this is State.ProcessingSystemPrompt ||
|
||||
this is State.ProcessingUserPrompt ||
|
||||
this is State.Generating
|
||||
|
||||
class UnsupportedArchitectureException : Exception()
|
||||
|
|
@ -0,0 +1,61 @@
|
|||
package com.arm.aichat.gguf
|
||||
|
||||
import kotlin.collections.get
|
||||
|
||||
|
||||
/**
|
||||
* Numerical codes used by `general.file_type` (see llama.cpp repo's `constants.py`).
|
||||
* The `label` matches what llama‑cli prints.
|
||||
*/
|
||||
enum class FileType(val code: Int, val label: String) {
|
||||
ALL_F32(0, "all F32"),
|
||||
MOSTLY_F16(1, "F16"),
|
||||
MOSTLY_Q4_0(2, "Q4_0"),
|
||||
MOSTLY_Q4_1(3, "Q4_1"),
|
||||
// 4 removed
|
||||
MOSTLY_Q8_0(7, "Q8_0"),
|
||||
MOSTLY_Q5_0(8, "Q5_0"),
|
||||
MOSTLY_Q5_1(9, "Q5_1"),
|
||||
|
||||
/* K‑quants ------------------------------------------------------------ */
|
||||
MOSTLY_Q2_K (10, "Q2_K - Medium"),
|
||||
MOSTLY_Q3_K_S (11, "Q3_K - Small"),
|
||||
MOSTLY_Q3_K_M (12, "Q3_K - Medium"),
|
||||
MOSTLY_Q3_K_L (13, "Q3_K - Large"),
|
||||
MOSTLY_Q4_K_S (14, "Q4_K - Small"),
|
||||
MOSTLY_Q4_K_M (15, "Q4_K - Medium"),
|
||||
MOSTLY_Q5_K_S (16, "Q5_K - Small"),
|
||||
MOSTLY_Q5_K_M (17, "Q5_K - Medium"),
|
||||
MOSTLY_Q6_K (18, "Q6_K"),
|
||||
|
||||
/* IQ quants ----------------------------------------------------------- */
|
||||
MOSTLY_IQ2_XXS (19, "IQ2_XXS - 2.06 bpw"),
|
||||
MOSTLY_IQ2_XS (20, "IQ2_XS - 2.31 bpw"),
|
||||
MOSTLY_Q2_K_S (21, "Q2_K - Small"),
|
||||
MOSTLY_IQ3_XS (22, "IQ3_XS - 3.30 bpw"),
|
||||
MOSTLY_IQ3_XXS (23, "IQ3_XXS - 3.06 bpw"),
|
||||
MOSTLY_IQ1_S (24, "IQ1_S - 1.56 bpw"),
|
||||
MOSTLY_IQ4_NL (25, "IQ4_NL - 4.5 bpw"),
|
||||
MOSTLY_IQ3_S (26, "IQ3_S - 3.44 bpw"),
|
||||
MOSTLY_IQ3_M (27, "IQ3_M - 3.66 bpw"),
|
||||
MOSTLY_IQ2_S (28, "IQ2_S - 2.50 bpw"),
|
||||
MOSTLY_IQ2_M (29, "IQ2_M - 2.70 bpw"),
|
||||
MOSTLY_IQ4_XS (30, "IQ4_XS - 4.25 bpw"),
|
||||
MOSTLY_IQ1_M (31, "IQ1_M - 1.75 bpw"),
|
||||
|
||||
/* BF16 & Ternary ------------------------------------------------------ */
|
||||
MOSTLY_BF16 (32, "BF16"),
|
||||
MOSTLY_TQ1_0 (36, "TQ1_0 - 1.69 bpw ternary"),
|
||||
MOSTLY_TQ2_0 (37, "TQ2_0 - 2.06 bpw ternary"),
|
||||
|
||||
/* Special flag -------------------------------------------------------- */
|
||||
GUESSED(1024, "(guessed)"),
|
||||
|
||||
UNKNOWN(-1, "unknown");
|
||||
|
||||
companion object {
|
||||
private val map = entries.associateBy(FileType::code)
|
||||
|
||||
fun fromCode(code: Int?): FileType = map[code] ?: UNKNOWN
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,132 @@
|
|||
package com.arm.aichat.gguf
|
||||
|
||||
import java.io.IOException
|
||||
|
||||
|
||||
/**
|
||||
* Structured metadata of GGUF
|
||||
*/
|
||||
data class GgufMetadata(
|
||||
// Basic file info
|
||||
val version: GgufVersion,
|
||||
val tensorCount: Long,
|
||||
val kvCount: Long,
|
||||
|
||||
// General info
|
||||
val basic: BasicInfo,
|
||||
val author: AuthorInfo? = null,
|
||||
val additional: AdditionalInfo? = null,
|
||||
val architecture: ArchitectureInfo? = null,
|
||||
val baseModels: List<BaseModelInfo>? = null,
|
||||
val tokenizer: TokenizerInfo? = null,
|
||||
|
||||
// Derivative info
|
||||
val dimensions: DimensionsInfo? = null,
|
||||
val attention: AttentionInfo? = null,
|
||||
val rope: RopeInfo? = null,
|
||||
val experts: ExpertsInfo? = null
|
||||
) {
|
||||
enum class GgufVersion(val code: Int, val label: String) {
|
||||
/** First public draft; little‑endian only, no alignment key. */
|
||||
LEGACY_V1(1, "Legacy v1"),
|
||||
|
||||
/** Added split‑file support and some extra metadata keys. */
|
||||
EXTENDED_V2(2, "Extended v2"),
|
||||
|
||||
/** Current spec: endian‑aware, mandatory alignment, fully validated. */
|
||||
VALIDATED_V3(3, "Validated v3");
|
||||
|
||||
companion object {
|
||||
fun fromCode(code: Int): GgufVersion =
|
||||
entries.firstOrNull { it.code == code }
|
||||
?: throw IOException("Unknown GGUF version code $code")
|
||||
}
|
||||
|
||||
override fun toString(): String = "$label (code=$code)"
|
||||
}
|
||||
|
||||
data class BasicInfo(
|
||||
val uuid: String? = null,
|
||||
val name: String? = null,
|
||||
val nameLabel: String? = null,
|
||||
val sizeLabel: String? = null, // Size label like "7B"
|
||||
)
|
||||
|
||||
data class AuthorInfo(
|
||||
val organization: String? = null,
|
||||
val author: String? = null,
|
||||
val doi: String? = null,
|
||||
val url: String? = null,
|
||||
val repoUrl: String? = null,
|
||||
val license: String? = null,
|
||||
val licenseLink: String? = null,
|
||||
)
|
||||
|
||||
data class AdditionalInfo(
|
||||
val type: String? = null,
|
||||
val description: String? = null,
|
||||
val tags: List<String>? = null,
|
||||
val languages: List<String>? = null,
|
||||
)
|
||||
|
||||
data class ArchitectureInfo(
|
||||
val architecture: String? = null,
|
||||
val fileType: Int? = null,
|
||||
val vocabSize: Int? = null,
|
||||
val finetune: String? = null,
|
||||
val quantizationVersion: Int? = null,
|
||||
)
|
||||
|
||||
data class BaseModelInfo(
|
||||
val name: String? = null,
|
||||
val author: String? = null,
|
||||
val version: String? = null,
|
||||
val organization: String? = null,
|
||||
val url: String? = null,
|
||||
val doi: String? = null,
|
||||
val uuid: String? = null,
|
||||
val repoUrl: String? = null,
|
||||
)
|
||||
|
||||
data class TokenizerInfo(
|
||||
val model: String? = null,
|
||||
val bosTokenId: Int? = null,
|
||||
val eosTokenId: Int? = null,
|
||||
val unknownTokenId: Int? = null,
|
||||
val paddingTokenId: Int? = null,
|
||||
val addBosToken: Boolean? = null,
|
||||
val addEosToken: Boolean? = null,
|
||||
val chatTemplate: String? = null,
|
||||
)
|
||||
|
||||
data class DimensionsInfo(
|
||||
val contextLength: Int? = null,
|
||||
val embeddingSize: Int? = null,
|
||||
val blockCount: Int? = null,
|
||||
val feedForwardSize: Int? = null,
|
||||
)
|
||||
|
||||
data class AttentionInfo(
|
||||
val headCount: Int? = null,
|
||||
val headCountKv: Int? = null,
|
||||
val keyLength: Int? = null,
|
||||
val valueLength: Int? = null,
|
||||
val layerNormEpsilon: Float? = null,
|
||||
val layerNormRmsEpsilon: Float? = null,
|
||||
)
|
||||
|
||||
data class RopeInfo(
|
||||
val frequencyBase: Float? = null,
|
||||
val dimensionCount: Int? = null,
|
||||
val scalingType: String? = null,
|
||||
val scalingFactor: Float? = null,
|
||||
val attnFactor: Float? = null,
|
||||
val originalContextLength: Int? = null,
|
||||
val finetuned: Boolean? = null,
|
||||
)
|
||||
|
||||
data class ExpertsInfo(
|
||||
val count: Int? = null,
|
||||
val usedCount: Int? = null,
|
||||
)
|
||||
}
|
||||
|
|
@ -0,0 +1,77 @@
|
|||
package com.arm.aichat.gguf
|
||||
|
||||
import android.content.Context
|
||||
import android.net.Uri
|
||||
import com.arm.aichat.internal.gguf.GgufMetadataReaderImpl
|
||||
import java.io.File
|
||||
import java.io.IOException
|
||||
import java.io.InputStream
|
||||
|
||||
/**
|
||||
* Interface for reading GGUF metadata from model files.
|
||||
* Use `GgufMetadataReader.create()` to get an instance.
|
||||
*/
|
||||
interface GgufMetadataReader {
|
||||
/**
|
||||
* Reads the magic number from the specified file path.
|
||||
*
|
||||
* @param file Java File to the GGUF file with absolute path
|
||||
* @return true if file is valid GGUF, otherwise false
|
||||
* @throws InvalidFileFormatException if file format is invalid
|
||||
*/
|
||||
suspend fun ensureSourceFileFormat(file: File): Boolean
|
||||
|
||||
/**
|
||||
* Reads the magic number from the specified file path.
|
||||
*
|
||||
* @param context Context for obtaining [android.content.ContentProvider]
|
||||
* @param uri Uri to the GGUF file provided by [android.content.ContentProvider]
|
||||
* @return true if file is valid GGUF, otherwise false
|
||||
* @throws InvalidFileFormatException if file format is invalid
|
||||
*/
|
||||
suspend fun ensureSourceFileFormat(context: Context, uri: Uri): Boolean
|
||||
|
||||
/**
|
||||
* Reads and parses GGUF metadata from the specified file path.
|
||||
*
|
||||
* @param input the [InputStream] obtained from a readable file or content
|
||||
* @return Structured metadata extracted from the file
|
||||
* @throws IOException if file is damaged or cannot be read
|
||||
* @throws InvalidFileFormatException if file format is invalid
|
||||
*/
|
||||
suspend fun readStructuredMetadata(input: InputStream): GgufMetadata
|
||||
|
||||
companion object {
|
||||
private val DEFAULT_SKIP_KEYS = setOf(
|
||||
"tokenizer.chat_template",
|
||||
"tokenizer.ggml.scores",
|
||||
"tokenizer.ggml.tokens",
|
||||
"tokenizer.ggml.token_type"
|
||||
)
|
||||
|
||||
/**
|
||||
* Creates a default GgufMetadataReader instance
|
||||
*/
|
||||
fun create(): GgufMetadataReader = GgufMetadataReaderImpl(
|
||||
skipKeys = DEFAULT_SKIP_KEYS,
|
||||
arraySummariseThreshold = 1_000
|
||||
)
|
||||
|
||||
/**
|
||||
* Creates a GgufMetadataReader with custom configuration
|
||||
*
|
||||
* @param skipKeys Keys whose value should be skipped entirely (not kept in the result map)
|
||||
* @param arraySummariseThreshold If ≥0, arrays longer get summarised, not materialised;
|
||||
* If -1, never summarise.
|
||||
*/
|
||||
fun create(
|
||||
skipKeys: Set<String> = DEFAULT_SKIP_KEYS,
|
||||
arraySummariseThreshold: Int = 1_000
|
||||
): GgufMetadataReader = GgufMetadataReaderImpl(
|
||||
skipKeys = skipKeys,
|
||||
arraySummariseThreshold = arraySummariseThreshold
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
class InvalidFileFormatException : IOException()
|
||||
|
|
@ -0,0 +1,309 @@
|
|||
package com.arm.aichat.internal
|
||||
|
||||
import android.content.Context
|
||||
import android.util.Log
|
||||
import com.arm.aichat.InferenceEngine
|
||||
import com.arm.aichat.UnsupportedArchitectureException
|
||||
import com.arm.aichat.internal.InferenceEngineImpl.Companion.getInstance
|
||||
import dalvik.annotation.optimization.FastNative
|
||||
import kotlinx.coroutines.CancellationException
|
||||
import kotlinx.coroutines.CoroutineScope
|
||||
import kotlinx.coroutines.Dispatchers
|
||||
import kotlinx.coroutines.ExperimentalCoroutinesApi
|
||||
import kotlinx.coroutines.SupervisorJob
|
||||
import kotlinx.coroutines.cancel
|
||||
import kotlinx.coroutines.flow.Flow
|
||||
import kotlinx.coroutines.flow.MutableStateFlow
|
||||
import kotlinx.coroutines.flow.StateFlow
|
||||
import kotlinx.coroutines.flow.flow
|
||||
import kotlinx.coroutines.flow.flowOn
|
||||
import kotlinx.coroutines.launch
|
||||
import kotlinx.coroutines.withContext
|
||||
import java.io.File
|
||||
import java.io.IOException
|
||||
|
||||
/**
|
||||
* JNI wrapper for the llama.cpp library providing Android-friendly access to large language models.
|
||||
*
|
||||
* This class implements a singleton pattern for managing the lifecycle of a single LLM instance.
|
||||
* All operations are executed on a dedicated single-threaded dispatcher to ensure thread safety
|
||||
* with the underlying C++ native code.
|
||||
*
|
||||
* The typical usage flow is:
|
||||
* 1. Get instance via [getInstance]
|
||||
* 2. Load a model with [loadModel]
|
||||
* 3. Send prompts with [sendUserPrompt]
|
||||
* 4. Generate responses as token streams
|
||||
* 5. Perform [cleanUp] when done with a model
|
||||
* 6. Properly [destroy] when completely done
|
||||
*
|
||||
* State transitions are managed automatically and validated at each operation.
|
||||
*
|
||||
* @see ai_chat.cpp for the native implementation details
|
||||
*/
|
||||
internal class InferenceEngineImpl private constructor(
|
||||
private val nativeLibDir: String
|
||||
) : InferenceEngine {
|
||||
|
||||
companion object {
|
||||
private val TAG = InferenceEngineImpl::class.java.simpleName
|
||||
|
||||
@Volatile
|
||||
private var instance: InferenceEngine? = null
|
||||
|
||||
/**
|
||||
* Create or obtain [InferenceEngineImpl]'s single instance.
|
||||
*
|
||||
* @param Context for obtaining native library directory
|
||||
* @throws IllegalArgumentException if native library path is invalid
|
||||
* @throws UnsatisfiedLinkError if library failed to load
|
||||
*/
|
||||
internal fun getInstance(context: Context) =
|
||||
instance ?: synchronized(this) {
|
||||
val nativeLibDir = context.applicationInfo.nativeLibraryDir
|
||||
require(nativeLibDir.isNotBlank()) { "Expected a valid native library path!" }
|
||||
|
||||
try {
|
||||
Log.i(TAG, "Instantiating InferenceEngineImpl,,,")
|
||||
InferenceEngineImpl(nativeLibDir).also { instance = it }
|
||||
} catch (e: UnsatisfiedLinkError) {
|
||||
Log.e(TAG, "Failed to load native library from $nativeLibDir", e)
|
||||
throw e
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* JNI methods
|
||||
* @see ai_chat.cpp
|
||||
*/
|
||||
@FastNative
|
||||
private external fun init(nativeLibDir: String)
|
||||
|
||||
@FastNative
|
||||
private external fun load(modelPath: String): Int
|
||||
|
||||
@FastNative
|
||||
private external fun prepare(): Int
|
||||
|
||||
@FastNative
|
||||
private external fun systemInfo(): String
|
||||
|
||||
@FastNative
|
||||
private external fun benchModel(pp: Int, tg: Int, pl: Int, nr: Int): String
|
||||
|
||||
@FastNative
|
||||
private external fun processSystemPrompt(systemPrompt: String): Int
|
||||
|
||||
@FastNative
|
||||
private external fun processUserPrompt(userPrompt: String, predictLength: Int): Int
|
||||
|
||||
@FastNative
|
||||
private external fun generateNextToken(): String?
|
||||
|
||||
@FastNative
|
||||
private external fun unload()
|
||||
|
||||
@FastNative
|
||||
private external fun shutdown()
|
||||
|
||||
private val _state =
|
||||
MutableStateFlow<InferenceEngine.State>(InferenceEngine.State.Uninitialized)
|
||||
override val state: StateFlow<InferenceEngine.State> = _state
|
||||
|
||||
private var _readyForSystemPrompt = false
|
||||
|
||||
/**
|
||||
* Single-threaded coroutine dispatcher & scope for LLama asynchronous operations
|
||||
*/
|
||||
@OptIn(ExperimentalCoroutinesApi::class)
|
||||
private val llamaDispatcher = Dispatchers.IO.limitedParallelism(1)
|
||||
private val llamaScope = CoroutineScope(llamaDispatcher + SupervisorJob())
|
||||
|
||||
init {
|
||||
llamaScope.launch {
|
||||
try {
|
||||
check(_state.value is InferenceEngine.State.Uninitialized) {
|
||||
"Cannot load native library in ${_state.value.javaClass.simpleName}!"
|
||||
}
|
||||
_state.value = InferenceEngine.State.Initializing
|
||||
Log.i(TAG, "Loading native library...")
|
||||
System.loadLibrary("ai-chat")
|
||||
init(nativeLibDir)
|
||||
_state.value = InferenceEngine.State.Initialized
|
||||
Log.i(TAG, "Native library loaded! System info: \n${systemInfo()}")
|
||||
|
||||
} catch (e: Exception) {
|
||||
Log.e(TAG, "Failed to load native library", e)
|
||||
throw e
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Load the LLM
|
||||
*/
|
||||
override suspend fun loadModel(pathToModel: String) =
|
||||
withContext(llamaDispatcher) {
|
||||
check(_state.value is InferenceEngine.State.Initialized) {
|
||||
"Cannot load model in ${_state.value.javaClass.simpleName}!"
|
||||
}
|
||||
|
||||
try {
|
||||
Log.i(TAG, "Checking access to model file... \n$pathToModel")
|
||||
File(pathToModel).let {
|
||||
require(it.exists()) { "File not found" }
|
||||
require(it.isFile) { "Not a valid file" }
|
||||
require(it.canRead()) { "Cannot read file" }
|
||||
}
|
||||
|
||||
Log.i(TAG, "Loading model... \n$pathToModel")
|
||||
_readyForSystemPrompt = false
|
||||
_state.value = InferenceEngine.State.LoadingModel
|
||||
load(pathToModel).let {
|
||||
// TODO-han.yin: find a better way to pass other error codes
|
||||
if (it != 0) throw UnsupportedArchitectureException()
|
||||
}
|
||||
prepare().let {
|
||||
if (it != 0) throw IOException("Failed to prepare resources")
|
||||
}
|
||||
Log.i(TAG, "Model loaded!")
|
||||
_readyForSystemPrompt = true
|
||||
_state.value = InferenceEngine.State.ModelReady
|
||||
} catch (e: Exception) {
|
||||
Log.e(TAG, (e.message ?: "Error loading model") + "\n" + pathToModel, e)
|
||||
_state.value = InferenceEngine.State.Error(e)
|
||||
throw e
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Process the plain text system prompt
|
||||
*
|
||||
* TODO-han.yin: return error code if system prompt not correct processed?
|
||||
*/
|
||||
override suspend fun setSystemPrompt(prompt: String) =
|
||||
withContext(llamaDispatcher) {
|
||||
require(prompt.isNotBlank()) { "Cannot process empty system prompt!" }
|
||||
check(_readyForSystemPrompt) { "System prompt must be set ** RIGHT AFTER ** model loaded!" }
|
||||
check(_state.value is InferenceEngine.State.ModelReady) {
|
||||
"Cannot process system prompt in ${_state.value.javaClass.simpleName}!"
|
||||
}
|
||||
|
||||
Log.i(TAG, "Sending system prompt...")
|
||||
_readyForSystemPrompt = false
|
||||
_state.value = InferenceEngine.State.ProcessingSystemPrompt
|
||||
processSystemPrompt(prompt).let { result ->
|
||||
if (result != 0) {
|
||||
RuntimeException("Failed to process system prompt: $result").also {
|
||||
_state.value = InferenceEngine.State.Error(it)
|
||||
throw it
|
||||
}
|
||||
}
|
||||
}
|
||||
Log.i(TAG, "System prompt processed! Awaiting user prompt...")
|
||||
_state.value = InferenceEngine.State.ModelReady
|
||||
}
|
||||
|
||||
/**
|
||||
* Send plain text user prompt to LLM, which starts generating tokens in a [Flow]
|
||||
*/
|
||||
override fun sendUserPrompt(
|
||||
message: String,
|
||||
predictLength: Int,
|
||||
): Flow<String> = flow {
|
||||
require(message.isNotEmpty()) { "User prompt discarded due to being empty!" }
|
||||
check(_state.value is InferenceEngine.State.ModelReady) {
|
||||
"User prompt discarded due to: ${_state.value.javaClass.simpleName}"
|
||||
}
|
||||
|
||||
try {
|
||||
Log.i(TAG, "Sending user prompt...")
|
||||
_readyForSystemPrompt = false
|
||||
_state.value = InferenceEngine.State.ProcessingUserPrompt
|
||||
|
||||
processUserPrompt(message, predictLength).let { result ->
|
||||
if (result != 0) {
|
||||
Log.e(TAG, "Failed to process user prompt: $result")
|
||||
return@flow
|
||||
}
|
||||
}
|
||||
|
||||
Log.i(TAG, "User prompt processed. Generating assistant prompt...")
|
||||
_state.value = InferenceEngine.State.Generating
|
||||
while (true) {
|
||||
generateNextToken()?.let { utf8token ->
|
||||
if (utf8token.isNotEmpty()) emit(utf8token)
|
||||
} ?: break
|
||||
}
|
||||
Log.i(TAG, "Assistant generation complete. Awaiting user prompt...")
|
||||
_state.value = InferenceEngine.State.ModelReady
|
||||
} catch (e: CancellationException) {
|
||||
Log.i(TAG, "Generation cancelled by user.")
|
||||
_state.value = InferenceEngine.State.ModelReady
|
||||
throw e
|
||||
} catch (e: Exception) {
|
||||
Log.e(TAG, "Error during generation!", e)
|
||||
_state.value = InferenceEngine.State.Error(e)
|
||||
throw e
|
||||
}
|
||||
}.flowOn(llamaDispatcher)
|
||||
|
||||
/**
|
||||
* Benchmark the model
|
||||
*/
|
||||
override suspend fun bench(pp: Int, tg: Int, pl: Int, nr: Int): String =
|
||||
withContext(llamaDispatcher) {
|
||||
check(_state.value is InferenceEngine.State.ModelReady) {
|
||||
"Benchmark request discarded due to: $state"
|
||||
}
|
||||
Log.i(TAG, "Start benchmark (pp: $pp, tg: $tg, pl: $pl, nr: $nr)")
|
||||
_readyForSystemPrompt = false // Just to be safe
|
||||
_state.value = InferenceEngine.State.Benchmarking
|
||||
benchModel(pp, tg, pl, nr).also {
|
||||
_state.value = InferenceEngine.State.ModelReady
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Unloads the model and frees resources, or reset error states
|
||||
*/
|
||||
override suspend fun cleanUp() =
|
||||
withContext(llamaDispatcher) {
|
||||
when (val state = _state.value) {
|
||||
is InferenceEngine.State.ModelReady -> {
|
||||
Log.i(TAG, "Unloading model and free resources...")
|
||||
_readyForSystemPrompt = false
|
||||
_state.value = InferenceEngine.State.UnloadingModel
|
||||
|
||||
unload()
|
||||
|
||||
_state.value = InferenceEngine.State.Initialized
|
||||
Log.i(TAG, "Model unloaded!")
|
||||
Unit
|
||||
}
|
||||
|
||||
is InferenceEngine.State.Error -> {
|
||||
Log.i(TAG, "Resetting error states...")
|
||||
_state.value = InferenceEngine.State.Initialized
|
||||
Log.i(TAG, "States reset!")
|
||||
Unit
|
||||
}
|
||||
|
||||
else -> throw IllegalStateException("Cannot unload model in ${state.javaClass.simpleName}")
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Cancel all ongoing coroutines and free GGML backends
|
||||
*/
|
||||
override fun destroy() {
|
||||
_readyForSystemPrompt = false
|
||||
llamaScope.cancel()
|
||||
when(_state.value) {
|
||||
is InferenceEngine.State.Uninitialized -> {}
|
||||
is InferenceEngine.State.Initialized -> shutdown()
|
||||
else -> { unload(); shutdown() }
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,590 @@
|
|||
package com.arm.aichat.internal.gguf
|
||||
|
||||
import android.content.Context
|
||||
import android.net.Uri
|
||||
import com.arm.aichat.gguf.GgufMetadata
|
||||
import com.arm.aichat.gguf.GgufMetadataReader
|
||||
import com.arm.aichat.gguf.InvalidFileFormatException
|
||||
import java.io.File
|
||||
import java.io.IOException
|
||||
import java.io.InputStream
|
||||
|
||||
|
||||
/**
|
||||
* Utility class to read GGUF model files and extract metadata key-value pairs.
|
||||
* This parser reads the header and metadata of a GGUF v3 file (little-endian) and skips tensor data.
|
||||
*/
|
||||
internal class GgufMetadataReaderImpl(
|
||||
private val skipKeys: Set<String>,
|
||||
private val arraySummariseThreshold: Int,
|
||||
) : GgufMetadataReader {
|
||||
companion object {
|
||||
private const val ARCH_LLAMA = "llama"
|
||||
}
|
||||
|
||||
/** Enum corresponding to GGUF metadata value types (for convenience and array element typing). */
|
||||
enum class MetadataType(val code: Int) {
|
||||
UINT8(0), INT8(1), UINT16(2), INT16(3),
|
||||
UINT32(4), INT32(5), FLOAT32(6), BOOL(7),
|
||||
STRING(8), ARRAY(9), UINT64(10), INT64(11), FLOAT64(12);
|
||||
companion object {
|
||||
private val codeMap = entries.associateBy(MetadataType::code)
|
||||
fun fromCode(code: Int): MetadataType = codeMap[code]
|
||||
?: throw IOException("Unknown metadata value type code: $code")
|
||||
}
|
||||
}
|
||||
|
||||
/** Sealed class hierarchy for metadata values, providing type-safe representations for each GGUF metadata type. */
|
||||
sealed class MetadataValue {
|
||||
data class UInt8(val value: UByte) : MetadataValue() // 0: 8-bit unsigned int
|
||||
data class Int8(val value: Byte) : MetadataValue() // 1: 8-bit signed int
|
||||
data class UInt16(val value: UShort) : MetadataValue() // 2: 16-bit unsigned int (little-endian)
|
||||
data class Int16(val value: Short) : MetadataValue() // 3: 16-bit signed int (little-endian)
|
||||
data class UInt32(val value: UInt) : MetadataValue() // 4: 32-bit unsigned int (little-endian)
|
||||
data class Int32(val value: Int) : MetadataValue() // 5: 32-bit signed int (little-endian)
|
||||
data class Float32(val value: Float) : MetadataValue() // 6: 32-bit IEEE754 float
|
||||
data class Bool(val value: Boolean) : MetadataValue() // 7: Boolean (1-byte, 0=false, 1=true)
|
||||
data class StringVal(val value: String) : MetadataValue() // 8: UTF-8 string (length-prefixed)
|
||||
data class ArrayVal(val elementType: MetadataType, val elements: List<MetadataValue>) : MetadataValue()
|
||||
data class UInt64(val value: ULong) : MetadataValue() // 10: 64-bit unsigned int (little-endian)
|
||||
data class Int64(val value: Long) : MetadataValue() // 11: 64-bit signed int (little-endian)
|
||||
data class Float64(val value: Double) : MetadataValue() // 12: 64-bit IEEE754 double
|
||||
}
|
||||
|
||||
/* Convert MetadataValue to plain Kotlin primitives for allMetadata map */
|
||||
private fun MetadataValue.toPrimitive(): Any = when (this) {
|
||||
is MetadataValue.UInt8 -> value
|
||||
is MetadataValue.Int8 -> value
|
||||
is MetadataValue.UInt16 -> value
|
||||
is MetadataValue.Int16 -> value
|
||||
is MetadataValue.UInt32 -> value
|
||||
is MetadataValue.Int32 -> value
|
||||
is MetadataValue.Float32 -> value
|
||||
is MetadataValue.Bool -> value
|
||||
is MetadataValue.StringVal -> value
|
||||
is MetadataValue.UInt64 -> value
|
||||
is MetadataValue.Int64 -> value
|
||||
is MetadataValue.Float64 -> value
|
||||
is MetadataValue.ArrayVal -> elements.map { it.toPrimitive() }
|
||||
}
|
||||
|
||||
/**
|
||||
* Reads the magic number from the specified file path.
|
||||
*
|
||||
* @param context Context for obtaining ContentResolver
|
||||
* @param uri Uri to the GGUF file provided by ContentProvider
|
||||
* @return true if file is valid GGUF, otherwise false
|
||||
*/
|
||||
override suspend fun ensureSourceFileFormat(file: File): Boolean =
|
||||
file.inputStream().buffered().use { ensureMagic(it) }
|
||||
|
||||
/**
|
||||
* Reads the magic number from the specified file path.
|
||||
*
|
||||
* @param context Context for obtaining ContentResolver
|
||||
* @param uri Uri to the GGUF file provided by ContentProvider
|
||||
* @return true if file is valid GGUF, otherwise false
|
||||
*/
|
||||
override suspend fun ensureSourceFileFormat(context: Context, uri: Uri): Boolean =
|
||||
context.contentResolver.openInputStream(uri)?.buffered()?.use { ensureMagic(it) } == true
|
||||
|
||||
/** Reads the 4‑byte magic; throws if magic ≠ "GGUF". */
|
||||
private fun ensureMagic(input: InputStream): Boolean =
|
||||
ByteArray(4).let {
|
||||
if (input.read(it) != 4) throw IOException("Not a valid file!")
|
||||
it.contentEquals(byteArrayOf(0x47, 0x47, 0x55, 0x46)) // "GGUF"
|
||||
}
|
||||
|
||||
/**
|
||||
* High‑level entry point: parses a `.gguf` file on disk and returns the fully
|
||||
* populated [GgufMetadata] tree.
|
||||
*
|
||||
* Steps performed internally:
|
||||
* 1. Reads and validates the 8‑byte header (`"GGUF"` magic + version).
|
||||
* 2. Streams through the key‑value section, skipping large blobs if the key
|
||||
* appears in [skipKeys] or if an array exceeds [arraySummariseThreshold].
|
||||
* 3. Converts the resulting raw map into strongly‑typed sub‑structures
|
||||
* (basic info, tokenizer, rope, etc.).
|
||||
*
|
||||
* The method is STREAMING‑ONLY: tensors are never mapped or loaded into
|
||||
* memory, so even multi‑GB model files can be processed in < 50 ms.
|
||||
*
|
||||
* @param path Absolute or relative filesystem path to a `.gguf` file.
|
||||
* @return A [GgufMetadata] instance containing all recognised metadata plus
|
||||
* an `allMetadata` map with any keys that were not given a dedicated
|
||||
* field.
|
||||
* @throws IOException if the file is not GGUF, the version is unsupported,
|
||||
* or the metadata block is truncated / corrupt.
|
||||
*/
|
||||
override suspend fun readStructuredMetadata(input: InputStream): GgufMetadata {
|
||||
// ── 1. header ──────────────────────────────────────────────────────────
|
||||
// throws on mismatch
|
||||
val version = ensureMagicAndVersion(input)
|
||||
val tensorCount = readLittleLong(input)
|
||||
val kvCount = readLittleLong(input)
|
||||
|
||||
// ── 2. metadata map (reuse our raw parser, but we need access to the stream) ──
|
||||
val meta = readMetaMap(input, kvCount) // <String, MetadataValue>
|
||||
|
||||
// ── 3. build structured object ────────────────────────────────────────
|
||||
return buildStructured(meta, version, tensorCount, kvCount)
|
||||
}
|
||||
|
||||
/** Reads the 4‑byte magic + 4‑byte version; throws if magic ≠ "GGUF". */
|
||||
private fun ensureMagicAndVersion(input: InputStream): GgufMetadata.GgufVersion {
|
||||
if (!ensureMagic(input)) throw InvalidFileFormatException()
|
||||
return GgufMetadata.GgufVersion.fromCode(readLEUInt32(input))
|
||||
}
|
||||
|
||||
/**
|
||||
* Read an unsigned 32‑bit little‑endian integer.
|
||||
*
|
||||
* @throws IOException if fewer than four bytes are available.
|
||||
*/
|
||||
private fun readLEUInt32(input: InputStream): Int {
|
||||
val b0 = input.read(); val b1 = input.read(); val b2 = input.read(); val b3 = input.read()
|
||||
if (b3 == -1) throw IOException("Unexpected EOF while reading UInt32")
|
||||
return (b3 and 0xFF shl 24) or
|
||||
(b2 and 0xFF shl 16) or
|
||||
(b1 and 0xFF shl 8) or
|
||||
(b0 and 0xFF)
|
||||
}
|
||||
|
||||
/**
|
||||
* Low‑level helper that reads the entire “key-value” section from the current
|
||||
* stream position.
|
||||
*
|
||||
* @param input Open stream positioned JUST AFTER the header.
|
||||
* @param kvCnt Number of key‑value pairs (taken from the header).
|
||||
* @return Mutable map with one [MetadataValue] for every key that is NOT skipped.
|
||||
*
|
||||
* The function honours [skipKeys] and [arraySummariseThreshold] by invoking
|
||||
* [skipValue] or [parseValue] accordingly.
|
||||
*/
|
||||
private fun readMetaMap(input: InputStream, kvCnt: Long): Map<String, MetadataValue> =
|
||||
mutableMapOf<String, MetadataValue>().apply {
|
||||
repeat(kvCnt.toInt()) {
|
||||
val key = readString(input)
|
||||
val valueT = MetadataType.fromCode(littleEndianBytesToInt(input.readNBytesExact(4)))
|
||||
if (key in skipKeys) {
|
||||
skipValue(input, valueT)
|
||||
} else {
|
||||
this[key] = parseValue(input, valueT)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Converts a flat [Map]<[String], [MetadataValue]> into the strongly‑typed
|
||||
* [GgufMetadata] tree used by the rest of the app.
|
||||
*
|
||||
* Only the keys listed in the spec are copied into dedicated data classes;
|
||||
* everything else is preserved in `GgufMetadata.allMetadata`.
|
||||
*
|
||||
* @param m Raw key/value map.
|
||||
* @param version GGUF file‑format version (enum).
|
||||
* @param tensorCnt Number of tensors (from the header).
|
||||
* @param kvCnt Total metadata pair count (from the header).
|
||||
*/
|
||||
private fun buildStructured(
|
||||
m: Map<String, MetadataValue>,
|
||||
version: GgufMetadata.GgufVersion,
|
||||
tensorCnt: Long,
|
||||
kvCnt: Long
|
||||
): GgufMetadata {
|
||||
// ---------- helpers ----------
|
||||
fun String.str() = (m[this] as? MetadataValue.StringVal)?.value
|
||||
fun String.bool() = (m[this] as? MetadataValue.Bool)?.value
|
||||
fun String.i32() = (m[this] as? MetadataValue.Int32)?.value
|
||||
fun String.u32() = (m[this] as? MetadataValue.UInt32)?.value?.toInt()
|
||||
fun String.f32() = (m[this] as? MetadataValue.Float32)?.value
|
||||
fun String.f64() = (m[this] as? MetadataValue.Float64)?.value?.toFloat()
|
||||
fun String.strList(): List<String>? =
|
||||
(m[this] as? MetadataValue.ArrayVal)
|
||||
?.elements
|
||||
?.mapNotNull { (it as? MetadataValue.StringVal)?.value }
|
||||
|
||||
val arch = "general.architecture".str() ?: ARCH_LLAMA
|
||||
|
||||
// -------------- populate sections ----------------
|
||||
val basic = GgufMetadata.BasicInfo(
|
||||
uuid = "general.uuid".str(),
|
||||
name = "general.basename".str(),
|
||||
nameLabel = "general.name".str(),
|
||||
sizeLabel = "general.size_label".str()
|
||||
)
|
||||
|
||||
val author = GgufMetadata.AuthorInfo(
|
||||
organization = "general.organization".str(),
|
||||
author = "general.author".str(),
|
||||
doi = "general.doi".str(),
|
||||
url = "general.url".str(),
|
||||
repoUrl = "general.repo_url".str(),
|
||||
license = "general.license".str(),
|
||||
licenseLink = "general.license.link".str()
|
||||
).takeUnless {
|
||||
organization == null && author == null && doi == null &&
|
||||
url == null && repoUrl == null && license == null && licenseLink == null
|
||||
}
|
||||
|
||||
val additional = GgufMetadata.AdditionalInfo(
|
||||
type = "general.type".str(),
|
||||
description = "general.description".str(),
|
||||
tags = "general.tags".strList(),
|
||||
languages = "general.languages".strList()
|
||||
).takeUnless {
|
||||
type == null && description == null && tags == null && languages == null
|
||||
}
|
||||
|
||||
val architectureInfo = GgufMetadata.ArchitectureInfo(
|
||||
architecture = arch,
|
||||
fileType = "general.file_type".u32(),
|
||||
vocabSize = "$arch.vocab_size".u32(),
|
||||
finetune = "general.finetune".str(),
|
||||
quantizationVersion = "general.quantization_version".u32()
|
||||
).takeUnless { fileType == null && vocabSize == null && finetune == null && quantizationVersion == null }
|
||||
|
||||
val baseModels = buildList {
|
||||
val n = "general.base_model.count".u32() ?: 0
|
||||
for (i in 0 until n) {
|
||||
fun k(s: String) = "general.base_model.$i.$s"
|
||||
add(
|
||||
GgufMetadata.BaseModelInfo(
|
||||
name = k("name").str(),
|
||||
author = k("author").str(),
|
||||
version = k("version").str(),
|
||||
organization = k("organization").str(),
|
||||
url = k("url").str(),
|
||||
doi = k("doi").str(),
|
||||
uuid = k("uuid").str(),
|
||||
repoUrl = k("repo_url").str(),
|
||||
)
|
||||
)
|
||||
}
|
||||
}.takeIf { it.isNotEmpty() }
|
||||
|
||||
val tokenizer = GgufMetadata.TokenizerInfo(
|
||||
model = "tokenizer.ggml.model".str(),
|
||||
bosTokenId = "tokenizer.ggml.bos_token_id".u32(),
|
||||
eosTokenId = "tokenizer.ggml.eos_token_id".u32(),
|
||||
unknownTokenId = "tokenizer.ggml.unknown_token_id".u32(),
|
||||
paddingTokenId = "tokenizer.ggml.padding_token_id".u32(),
|
||||
addBosToken = "tokenizer.ggml.add_bos_token".bool(),
|
||||
addEosToken = "tokenizer.ggml.add_eos_token".bool(),
|
||||
chatTemplate = "tokenizer.chat_template".str()
|
||||
).takeUnless { model == null && bosTokenId == null && eosTokenId == null &&
|
||||
unknownTokenId == null && paddingTokenId == null &&
|
||||
addBosToken == null && addEosToken == null && chatTemplate == null
|
||||
}
|
||||
|
||||
val dimensions = GgufMetadata.DimensionsInfo(
|
||||
contextLength = "$arch.context_length".u32(),
|
||||
embeddingSize = "$arch.embedding_length".u32(),
|
||||
blockCount = "$arch.block_count".u32(),
|
||||
feedForwardSize = "$arch.feed_forward_length".u32()
|
||||
).takeUnless { contextLength == null && embeddingSize == null && blockCount == null && feedForwardSize == null }
|
||||
|
||||
val attention = GgufMetadata.AttentionInfo(
|
||||
headCount = "$arch.attention.head_count".u32(),
|
||||
headCountKv = "$arch.attention.head_count_kv".u32(),
|
||||
keyLength = "$arch.attention.key_length".u32(),
|
||||
valueLength = "$arch.attention.value_length".u32(),
|
||||
layerNormEpsilon = "$arch.attention.layer_norm_epsilon".f32(),
|
||||
layerNormRmsEpsilon = "$arch.attention.layer_norm_rms_epsilon".f32(),
|
||||
).takeUnless { headCount == null && headCountKv == null && keyLength == null && valueLength == null &&
|
||||
layerNormEpsilon == null && layerNormRmsEpsilon == null
|
||||
}
|
||||
|
||||
val rope = GgufMetadata.RopeInfo(
|
||||
frequencyBase = "$arch.rope.freq_base".f32(),
|
||||
dimensionCount = "$arch.rope.dimension_count".u32(),
|
||||
scalingType = "$arch.rope.scaling.type".str(),
|
||||
scalingFactor = "$arch.rope.scaling.factor".f32(),
|
||||
attnFactor = "$arch.rope.scaling.attn_factor".f32(),
|
||||
originalContextLength = "$arch.rope.scaling.original_context_length".u32(),
|
||||
finetuned = "$arch.rope.scaling.finetuned".bool()
|
||||
).takeUnless { frequencyBase == null && dimensionCount == null &&
|
||||
scalingType == null && scalingFactor == null && attnFactor == null &&
|
||||
originalContextLength == null && finetuned == null
|
||||
}
|
||||
|
||||
val experts = GgufMetadata.ExpertsInfo(
|
||||
count = "$arch.expert_count".u32(),
|
||||
usedCount = "$arch.expert_used_count".u32()
|
||||
).takeUnless { count == null && usedCount == null }
|
||||
|
||||
return GgufMetadata(
|
||||
version = version,
|
||||
tensorCount = tensorCnt,
|
||||
kvCount = kvCnt,
|
||||
basic = basic,
|
||||
author = author,
|
||||
additional = additional,
|
||||
architecture = architectureInfo,
|
||||
baseModels = baseModels,
|
||||
tokenizer = tokenizer,
|
||||
dimensions = dimensions,
|
||||
attention = attention,
|
||||
rope = rope,
|
||||
experts = experts
|
||||
)
|
||||
}
|
||||
|
||||
/**
|
||||
* Recursively parses a metadata value of the given type from the input stream.
|
||||
* @param input The input stream positioned at the start of the value.
|
||||
* @param type The metadata value type to parse.
|
||||
*/
|
||||
private fun parseValue(input: InputStream, type: MetadataType): MetadataValue = when (type) {
|
||||
MetadataType.UINT8 -> {
|
||||
// 1-byte unsigned integer
|
||||
val byteVal = input.read()
|
||||
if (byteVal == -1) throw IOException("Unexpected EOF while reading uint8 value.")
|
||||
MetadataValue.UInt8(byteVal.toUByte())
|
||||
}
|
||||
MetadataType.INT8 -> {
|
||||
// 1-byte signed integer
|
||||
val byteVal = input.read()
|
||||
if (byteVal == -1) throw IOException("Unexpected EOF while reading int8 value.")
|
||||
MetadataValue.Int8(byteVal.toByte())
|
||||
}
|
||||
MetadataType.UINT16 -> {
|
||||
// 2-byte unsigned integer (little-endian)
|
||||
val bytes = ByteArray(2)
|
||||
if (input.read(bytes) != 2) throw IOException("Unexpected EOF while reading uint16 value.")
|
||||
// Combine two bytes (little-endian) into an unsigned 16-bit value
|
||||
val u16 = ((bytes[1].toInt() and 0xFF) shl 8) or (bytes[0].toInt() and 0xFF)
|
||||
MetadataValue.UInt16(u16.toUShort())
|
||||
}
|
||||
MetadataType.INT16 -> {
|
||||
// 2-byte signed integer (little-endian)
|
||||
val bytes = ByteArray(2)
|
||||
if (input.read(bytes) != 2) throw IOException("Unexpected EOF while reading int16 value.")
|
||||
// Combine to 16-bit and interpret as signed
|
||||
val i16 = ((bytes[1].toInt() and 0xFF) shl 8) or (bytes[0].toInt() and 0xFF)
|
||||
MetadataValue.Int16(i16.toShort())
|
||||
}
|
||||
MetadataType.UINT32 -> {
|
||||
// 4-byte unsigned integer (little-endian)
|
||||
val bytes = ByteArray(4)
|
||||
if (input.read(bytes) != 4) throw IOException("Unexpected EOF while reading uint32 value.")
|
||||
// Combine four bytes into a 32-bit value (as Long to avoid overflow), then convert to UInt
|
||||
val u32 = (bytes[3].toLong() and 0xFFL shl 24) or
|
||||
(bytes[2].toLong() and 0xFFL shl 16) or
|
||||
(bytes[1].toLong() and 0xFFL shl 8) or
|
||||
(bytes[0].toLong() and 0xFFL)
|
||||
MetadataValue.UInt32(u32.toUInt())
|
||||
}
|
||||
MetadataType.INT32 -> {
|
||||
// 4-byte signed integer (little-endian)
|
||||
val bytes = ByteArray(4)
|
||||
if (input.read(bytes) != 4) throw IOException("Unexpected EOF while reading int32 value.")
|
||||
// Combine four bytes into a 32-bit signed int
|
||||
val i32 = (bytes[3].toInt() and 0xFF shl 24) or
|
||||
(bytes[2].toInt() and 0xFF shl 16) or
|
||||
(bytes[1].toInt() and 0xFF shl 8) or
|
||||
(bytes[0].toInt() and 0xFF)
|
||||
MetadataValue.Int32(i32)
|
||||
}
|
||||
MetadataType.FLOAT32 -> {
|
||||
// 4-byte IEEE 754 float (little-endian)
|
||||
val bytes = ByteArray(4)
|
||||
if (input.read(bytes) != 4) throw IOException("Unexpected EOF while reading float32 value.")
|
||||
// Assemble 4 bytes into a 32-bit int bit-pattern, then convert to Float
|
||||
val bits = (bytes[3].toInt() and 0xFF shl 24) or
|
||||
(bytes[2].toInt() and 0xFF shl 16) or
|
||||
(bytes[1].toInt() and 0xFF shl 8) or
|
||||
(bytes[0].toInt() and 0xFF)
|
||||
val floatVal = Float.fromBits(bits)
|
||||
MetadataValue.Float32(floatVal)
|
||||
}
|
||||
MetadataType.BOOL -> {
|
||||
// 1-byte boolean (0 = false, 1 = true)
|
||||
val byteVal = input.read()
|
||||
if (byteVal == -1) throw IOException("Unexpected EOF while reading boolean value.")
|
||||
if (byteVal != 0 && byteVal != 1) {
|
||||
throw IOException("Invalid boolean value: $byteVal (must be 0 or 1).")
|
||||
}
|
||||
MetadataValue.Bool(byteVal != 0)
|
||||
}
|
||||
MetadataType.STRING -> {
|
||||
// UTF-8 string (length-prefixed with 8-byte length)
|
||||
val str = readString(input)
|
||||
MetadataValue.StringVal(str)
|
||||
}
|
||||
MetadataType.ARRAY -> {
|
||||
val elemType = MetadataType.fromCode(littleEndianBytesToInt(input.readNBytesExact(4)))
|
||||
val len = readLittleLong(input)
|
||||
val count = len.toInt()
|
||||
|
||||
if (arraySummariseThreshold >= 0 && count > arraySummariseThreshold) {
|
||||
// fast‑forward without allocation
|
||||
repeat(count) { skipValue(input, elemType) }
|
||||
MetadataValue.StringVal("Array($elemType, $count items) /* summarised */")
|
||||
} else {
|
||||
val list = ArrayList<MetadataValue>(count)
|
||||
repeat(count) { list += parseValue(input, elemType) }
|
||||
MetadataValue.ArrayVal(elemType, list)
|
||||
}
|
||||
}
|
||||
MetadataType.UINT64 -> {
|
||||
// 8-byte unsigned integer (little-endian)
|
||||
val bytes = ByteArray(8)
|
||||
if (input.read(bytes) != 8) throw IOException("Unexpected EOF while reading uint64 value.")
|
||||
// Combine 8 bytes into an unsigned 64-bit (ULong). Use ULong for full 0 to 2^64-1 range.
|
||||
val u64 = (bytes[7].toULong() and 0xFFuL shl 56) or
|
||||
(bytes[6].toULong() and 0xFFuL shl 48) or
|
||||
(bytes[5].toULong() and 0xFFuL shl 40) or
|
||||
(bytes[4].toULong() and 0xFFuL shl 32) or
|
||||
(bytes[3].toULong() and 0xFFuL shl 24) or
|
||||
(bytes[2].toULong() and 0xFFuL shl 16) or
|
||||
(bytes[1].toULong() and 0xFFuL shl 8) or
|
||||
(bytes[0].toULong() and 0xFFuL)
|
||||
MetadataValue.UInt64(u64)
|
||||
}
|
||||
MetadataType.INT64 -> {
|
||||
// 8-byte signed integer (little-endian)
|
||||
val bytes = ByteArray(8)
|
||||
if (input.read(bytes) != 8) throw IOException("Unexpected EOF while reading int64 value.")
|
||||
// Combine 8 bytes into a signed 64-bit value (Long)
|
||||
val i64 = (bytes[7].toLong() and 0xFFL shl 56) or
|
||||
(bytes[6].toLong() and 0xFFL shl 48) or
|
||||
(bytes[5].toLong() and 0xFFL shl 40) or
|
||||
(bytes[4].toLong() and 0xFFL shl 32) or
|
||||
(bytes[3].toLong() and 0xFFL shl 24) or
|
||||
(bytes[2].toLong() and 0xFFL shl 16) or
|
||||
(bytes[1].toLong() and 0xFFL shl 8) or
|
||||
(bytes[0].toLong() and 0xFFL)
|
||||
MetadataValue.Int64(i64)
|
||||
}
|
||||
MetadataType.FLOAT64 -> {
|
||||
// 8-byte IEEE 754 double (little-endian)
|
||||
val bytes = ByteArray(8)
|
||||
if (input.read(bytes) != 8) throw IOException("Unexpected EOF while reading float64 value.")
|
||||
// Assemble 8 bytes into a 64-bit bit-pattern, then convert to Double
|
||||
val bits = (bytes[7].toLong() and 0xFFL shl 56) or
|
||||
(bytes[6].toLong() and 0xFFL shl 48) or
|
||||
(bytes[5].toLong() and 0xFFL shl 40) or
|
||||
(bytes[4].toLong() and 0xFFL shl 32) or
|
||||
(bytes[3].toLong() and 0xFFL shl 24) or
|
||||
(bytes[2].toLong() and 0xFFL shl 16) or
|
||||
(bytes[1].toLong() and 0xFFL shl 8) or
|
||||
(bytes[0].toLong() and 0xFFL)
|
||||
val doubleVal = Double.fromBits(bits)
|
||||
MetadataValue.Float64(doubleVal)
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
private fun <T> T?.takeUnless(check: T.() -> Boolean): T? =
|
||||
this?.takeIf { !it.check() }
|
||||
|
||||
/** Helper: Skip a value in the stream without storing it (still maintains pointer). */
|
||||
private fun skipValue(input: InputStream, type: MetadataType) {
|
||||
when (type) {
|
||||
MetadataType.UINT8, MetadataType.INT8, MetadataType.BOOL -> input.skipFully(1)
|
||||
MetadataType.UINT16, MetadataType.INT16 -> input.skipFully(2)
|
||||
MetadataType.UINT32, MetadataType.INT32, MetadataType.FLOAT32 -> input.skipFully(4)
|
||||
MetadataType.UINT64, MetadataType.INT64, MetadataType.FLOAT64 -> input.skipFully(8)
|
||||
MetadataType.STRING -> {
|
||||
val len = readLittleLong(input); input.skipFully(len)
|
||||
}
|
||||
MetadataType.ARRAY -> {
|
||||
val elemType = MetadataType.fromCode(littleEndianBytesToInt(input.readNBytesExact(4)))
|
||||
val len = readLittleLong(input)
|
||||
repeat(len.toInt()) { skipValue(input, elemType) } // recursive skip
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/** Helper: Read an 8-byte little-endian unsigned value and return it as a signed Long (assuming it fits in 63 bits). */
|
||||
private fun readLittleLong(input: InputStream): Long {
|
||||
val bytes = ByteArray(8)
|
||||
input.readFully(bytes)
|
||||
|
||||
// Combine 8 bytes into a 64-bit value (Little Endian).
|
||||
// Note: If the value exceeds Long.MAX_VALUE (bit 63 is 1), this will produce a negative Long (two's complement).
|
||||
// In our context (lengths/counts), such extremely large values are not expected.
|
||||
return (bytes[7].toLong() and 0xFFL shl 56) or
|
||||
(bytes[6].toLong() and 0xFFL shl 48) or
|
||||
(bytes[5].toLong() and 0xFFL shl 40) or
|
||||
(bytes[4].toLong() and 0xFFL shl 32) or
|
||||
(bytes[3].toLong() and 0xFFL shl 24) or
|
||||
(bytes[2].toLong() and 0xFFL shl 16) or
|
||||
(bytes[1].toLong() and 0xFFL shl 8) or
|
||||
(bytes[0].toLong() and 0xFFL)
|
||||
}
|
||||
|
||||
/** Helper: Read a GGUF string from the stream (8-byte length followed by UTF-8 bytes). */
|
||||
private fun readString(input: InputStream): String =
|
||||
// Read 8-byte little-endian length (number of bytes in the string).
|
||||
readLittleLong(input).let { len ->
|
||||
if (len < 0 || len > Int.MAX_VALUE) throw IOException("String too long: $len")
|
||||
|
||||
// Read the UTF-8 bytes of the given length.
|
||||
ByteArray(len.toInt()).let {
|
||||
if (it.isNotEmpty()) input.readFully(it)
|
||||
String(it, Charsets.UTF_8)
|
||||
}
|
||||
}
|
||||
|
||||
/** Helper: Convert a 4-byte little-endian byte array to a 32-bit integer. */
|
||||
private fun littleEndianBytesToInt(bytes: ByteArray): Int =
|
||||
// Note: assumes bytes length is 4.
|
||||
(bytes[3].toInt() and 0xFF shl 24) or
|
||||
(bytes[2].toInt() and 0xFF shl 16) or
|
||||
(bytes[1].toInt() and 0xFF shl 8) or
|
||||
(bytes[0].toInt() and 0xFF)
|
||||
|
||||
/**
|
||||
* Robust skip that works the same on JDK 11 and Android’s desugared runtime.
|
||||
*
|
||||
* @param n Number of bytes to advance in the stream.
|
||||
* @throws IOException on premature EOF.
|
||||
*/
|
||||
private fun InputStream.skipFully(n: Long) {
|
||||
var remaining = n
|
||||
val scratch = ByteArray(8192) // read‑and‑toss buffer
|
||||
while (remaining > 0) {
|
||||
val skipped = skip(remaining)
|
||||
when {
|
||||
skipped > 0 -> remaining -= skipped // normal fast path
|
||||
skipped == 0L -> {
|
||||
// fallback: read and discard
|
||||
val read = read(scratch, 0, minOf(remaining, scratch.size.toLong()).toInt())
|
||||
if (read == -1) throw IOException("EOF while skipping $n bytes")
|
||||
remaining -= read
|
||||
}
|
||||
else -> throw IOException("Skip returned negative value")
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Extension that keeps reading until the requested number of bytes are filled.
|
||||
* Falls back to `read()` when `skip()` returns 0, which happens on some Android
|
||||
* streams.
|
||||
*
|
||||
* @param buf Destination buffer.
|
||||
* @param len Number of bytes to fill (defaults to `buf.size`).
|
||||
* @throws IOException on premature EOF.
|
||||
*/
|
||||
private fun InputStream.readFully(buf: ByteArray, len: Int = buf.size) {
|
||||
var off = 0
|
||||
while (off < len) {
|
||||
val n = read(buf, off, len - off)
|
||||
if (n == -1) throw IOException("EOF after $off of $len bytes")
|
||||
off += n
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Read EXACTLY `n` bytes or throw – never returns a partially‑filled array.
|
||||
* This is used for small fixed‑length reads (e.g. 4‑byte type codes).
|
||||
*
|
||||
* @throws IOException on premature EOF.
|
||||
*/
|
||||
private fun InputStream.readNBytesExact(n: Int) = ByteArray(n).also {
|
||||
if (read(it) != n) throw IOException("Unexpected EOF")
|
||||
}
|
||||
}
|
||||
|
|
@ -1,71 +0,0 @@
|
|||
plugins {
|
||||
id("com.android.library")
|
||||
id("org.jetbrains.kotlin.android")
|
||||
}
|
||||
|
||||
android {
|
||||
namespace = "android.llama.cpp"
|
||||
compileSdk = 34
|
||||
|
||||
defaultConfig {
|
||||
minSdk = 33
|
||||
|
||||
testInstrumentationRunner = "androidx.test.runner.AndroidJUnitRunner"
|
||||
consumerProguardFiles("consumer-rules.pro")
|
||||
ndk {
|
||||
// Add NDK properties if wanted, e.g.
|
||||
// abiFilters += listOf("arm64-v8a")
|
||||
}
|
||||
externalNativeBuild {
|
||||
cmake {
|
||||
arguments += "-DLLAMA_CURL=OFF"
|
||||
arguments += "-DLLAMA_BUILD_COMMON=ON"
|
||||
arguments += "-DGGML_LLAMAFILE=OFF"
|
||||
arguments += "-DCMAKE_BUILD_TYPE=Release"
|
||||
cppFlags += listOf()
|
||||
arguments += listOf()
|
||||
|
||||
cppFlags("")
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
buildTypes {
|
||||
release {
|
||||
isMinifyEnabled = false
|
||||
proguardFiles(
|
||||
getDefaultProguardFile("proguard-android-optimize.txt"),
|
||||
"proguard-rules.pro"
|
||||
)
|
||||
}
|
||||
}
|
||||
externalNativeBuild {
|
||||
cmake {
|
||||
path("src/main/cpp/CMakeLists.txt")
|
||||
version = "3.22.1"
|
||||
}
|
||||
}
|
||||
compileOptions {
|
||||
sourceCompatibility = JavaVersion.VERSION_1_8
|
||||
targetCompatibility = JavaVersion.VERSION_1_8
|
||||
}
|
||||
kotlinOptions {
|
||||
jvmTarget = "1.8"
|
||||
}
|
||||
|
||||
packaging {
|
||||
resources {
|
||||
excludes += "/META-INF/{AL2.0,LGPL2.1}"
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
dependencies {
|
||||
|
||||
implementation("androidx.core:core-ktx:1.12.0")
|
||||
implementation("androidx.appcompat:appcompat:1.6.1")
|
||||
implementation("com.google.android.material:material:1.11.0")
|
||||
testImplementation("junit:junit:4.13.2")
|
||||
androidTestImplementation("androidx.test.ext:junit:1.1.5")
|
||||
androidTestImplementation("androidx.test.espresso:espresso-core:3.5.1")
|
||||
}
|
||||
|
|
@ -1,53 +0,0 @@
|
|||
# For more information about using CMake with Android Studio, read the
|
||||
# documentation: https://d.android.com/studio/projects/add-native-code.html.
|
||||
# For more examples on how to use CMake, see https://github.com/android/ndk-samples.
|
||||
|
||||
# Sets the minimum CMake version required for this project.
|
||||
cmake_minimum_required(VERSION 3.22.1)
|
||||
|
||||
# Declares the project name. The project name can be accessed via ${ PROJECT_NAME},
|
||||
# Since this is the top level CMakeLists.txt, the project name is also accessible
|
||||
# with ${CMAKE_PROJECT_NAME} (both CMake variables are in-sync within the top level
|
||||
# build script scope).
|
||||
project("llama-android")
|
||||
|
||||
#include(FetchContent)
|
||||
#FetchContent_Declare(
|
||||
# llama
|
||||
# GIT_REPOSITORY https://github.com/ggml-org/llama.cpp
|
||||
# GIT_TAG master
|
||||
#)
|
||||
|
||||
# Also provides "common"
|
||||
#FetchContent_MakeAvailable(llama)
|
||||
|
||||
# Creates and names a library, sets it as either STATIC
|
||||
# or SHARED, and provides the relative paths to its source code.
|
||||
# You can define multiple libraries, and CMake builds them for you.
|
||||
# Gradle automatically packages shared libraries with your APK.
|
||||
#
|
||||
# In this top level CMakeLists.txt, ${CMAKE_PROJECT_NAME} is used to define
|
||||
# the target library name; in the sub-module's CMakeLists.txt, ${PROJECT_NAME}
|
||||
# is preferred for the same purpose.
|
||||
#
|
||||
|
||||
#load local llama.cpp
|
||||
add_subdirectory(../../../../../../ build-llama)
|
||||
|
||||
# In order to load a library into your app from Java/Kotlin, you must call
|
||||
# System.loadLibrary() and pass the name of the library defined here;
|
||||
# for GameActivity/NativeActivity derived applications, the same library name must be
|
||||
# used in the AndroidManifest.xml file.
|
||||
add_library(${CMAKE_PROJECT_NAME} SHARED
|
||||
# List C/C++ source files with relative paths to this CMakeLists.txt.
|
||||
llama-android.cpp)
|
||||
|
||||
# Specifies libraries CMake should link to your target library. You
|
||||
# can link libraries from various origins, such as libraries defined in this
|
||||
# build script, prebuilt third-party libraries, or Android system libraries.
|
||||
target_link_libraries(${CMAKE_PROJECT_NAME}
|
||||
# List libraries link to the target library
|
||||
llama
|
||||
common
|
||||
android
|
||||
log)
|
||||
|
|
@ -1,452 +0,0 @@
|
|||
#include <android/log.h>
|
||||
#include <jni.h>
|
||||
#include <iomanip>
|
||||
#include <math.h>
|
||||
#include <string>
|
||||
#include <unistd.h>
|
||||
#include "llama.h"
|
||||
#include "common.h"
|
||||
|
||||
// Write C++ code here.
|
||||
//
|
||||
// Do not forget to dynamically load the C++ library into your application.
|
||||
//
|
||||
// For instance,
|
||||
//
|
||||
// In MainActivity.java:
|
||||
// static {
|
||||
// System.loadLibrary("llama-android");
|
||||
// }
|
||||
//
|
||||
// Or, in MainActivity.kt:
|
||||
// companion object {
|
||||
// init {
|
||||
// System.loadLibrary("llama-android")
|
||||
// }
|
||||
// }
|
||||
|
||||
#define TAG "llama-android.cpp"
|
||||
#define LOGi(...) __android_log_print(ANDROID_LOG_INFO, TAG, __VA_ARGS__)
|
||||
#define LOGe(...) __android_log_print(ANDROID_LOG_ERROR, TAG, __VA_ARGS__)
|
||||
|
||||
jclass la_int_var;
|
||||
jmethodID la_int_var_value;
|
||||
jmethodID la_int_var_inc;
|
||||
|
||||
std::string cached_token_chars;
|
||||
|
||||
bool is_valid_utf8(const char * string) {
|
||||
if (!string) {
|
||||
return true;
|
||||
}
|
||||
|
||||
const unsigned char * bytes = (const unsigned char *)string;
|
||||
int num;
|
||||
|
||||
while (*bytes != 0x00) {
|
||||
if ((*bytes & 0x80) == 0x00) {
|
||||
// U+0000 to U+007F
|
||||
num = 1;
|
||||
} else if ((*bytes & 0xE0) == 0xC0) {
|
||||
// U+0080 to U+07FF
|
||||
num = 2;
|
||||
} else if ((*bytes & 0xF0) == 0xE0) {
|
||||
// U+0800 to U+FFFF
|
||||
num = 3;
|
||||
} else if ((*bytes & 0xF8) == 0xF0) {
|
||||
// U+10000 to U+10FFFF
|
||||
num = 4;
|
||||
} else {
|
||||
return false;
|
||||
}
|
||||
|
||||
bytes += 1;
|
||||
for (int i = 1; i < num; ++i) {
|
||||
if ((*bytes & 0xC0) != 0x80) {
|
||||
return false;
|
||||
}
|
||||
bytes += 1;
|
||||
}
|
||||
}
|
||||
|
||||
return true;
|
||||
}
|
||||
|
||||
static void log_callback(ggml_log_level level, const char * fmt, void * data) {
|
||||
if (level == GGML_LOG_LEVEL_ERROR) __android_log_print(ANDROID_LOG_ERROR, TAG, fmt, data);
|
||||
else if (level == GGML_LOG_LEVEL_INFO) __android_log_print(ANDROID_LOG_INFO, TAG, fmt, data);
|
||||
else if (level == GGML_LOG_LEVEL_WARN) __android_log_print(ANDROID_LOG_WARN, TAG, fmt, data);
|
||||
else __android_log_print(ANDROID_LOG_DEFAULT, TAG, fmt, data);
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jlong JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_load_1model(JNIEnv *env, jobject, jstring filename) {
|
||||
llama_model_params model_params = llama_model_default_params();
|
||||
|
||||
auto path_to_model = env->GetStringUTFChars(filename, 0);
|
||||
LOGi("Loading model from %s", path_to_model);
|
||||
|
||||
auto model = llama_model_load_from_file(path_to_model, model_params);
|
||||
env->ReleaseStringUTFChars(filename, path_to_model);
|
||||
|
||||
if (!model) {
|
||||
LOGe("load_model() failed");
|
||||
env->ThrowNew(env->FindClass("java/lang/IllegalStateException"), "load_model() failed");
|
||||
return 0;
|
||||
}
|
||||
|
||||
return reinterpret_cast<jlong>(model);
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT void JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_free_1model(JNIEnv *, jobject, jlong model) {
|
||||
llama_model_free(reinterpret_cast<llama_model *>(model));
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jlong JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_new_1context(JNIEnv *env, jobject, jlong jmodel) {
|
||||
auto model = reinterpret_cast<llama_model *>(jmodel);
|
||||
|
||||
if (!model) {
|
||||
LOGe("new_context(): model cannot be null");
|
||||
env->ThrowNew(env->FindClass("java/lang/IllegalArgumentException"), "Model cannot be null");
|
||||
return 0;
|
||||
}
|
||||
|
||||
int n_threads = std::max(1, std::min(8, (int) sysconf(_SC_NPROCESSORS_ONLN) - 2));
|
||||
LOGi("Using %d threads", n_threads);
|
||||
|
||||
llama_context_params ctx_params = llama_context_default_params();
|
||||
|
||||
ctx_params.n_ctx = 2048;
|
||||
ctx_params.n_threads = n_threads;
|
||||
ctx_params.n_threads_batch = n_threads;
|
||||
|
||||
llama_context * context = llama_new_context_with_model(model, ctx_params);
|
||||
|
||||
if (!context) {
|
||||
LOGe("llama_new_context_with_model() returned null)");
|
||||
env->ThrowNew(env->FindClass("java/lang/IllegalStateException"),
|
||||
"llama_new_context_with_model() returned null)");
|
||||
return 0;
|
||||
}
|
||||
|
||||
return reinterpret_cast<jlong>(context);
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT void JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_free_1context(JNIEnv *, jobject, jlong context) {
|
||||
llama_free(reinterpret_cast<llama_context *>(context));
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT void JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_backend_1free(JNIEnv *, jobject) {
|
||||
llama_backend_free();
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT void JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_log_1to_1android(JNIEnv *, jobject) {
|
||||
llama_log_set(log_callback, NULL);
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jstring JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_bench_1model(
|
||||
JNIEnv *env,
|
||||
jobject,
|
||||
jlong context_pointer,
|
||||
jlong model_pointer,
|
||||
jlong batch_pointer,
|
||||
jint pp,
|
||||
jint tg,
|
||||
jint pl,
|
||||
jint nr
|
||||
) {
|
||||
auto pp_avg = 0.0;
|
||||
auto tg_avg = 0.0;
|
||||
auto pp_std = 0.0;
|
||||
auto tg_std = 0.0;
|
||||
|
||||
const auto context = reinterpret_cast<llama_context *>(context_pointer);
|
||||
const auto model = reinterpret_cast<llama_model *>(model_pointer);
|
||||
const auto batch = reinterpret_cast<llama_batch *>(batch_pointer);
|
||||
|
||||
const int n_ctx = llama_n_ctx(context);
|
||||
|
||||
LOGi("n_ctx = %d", n_ctx);
|
||||
|
||||
int i, j;
|
||||
int nri;
|
||||
for (nri = 0; nri < nr; nri++) {
|
||||
LOGi("Benchmark prompt processing (pp)");
|
||||
|
||||
common_batch_clear(*batch);
|
||||
|
||||
const int n_tokens = pp;
|
||||
for (i = 0; i < n_tokens; i++) {
|
||||
common_batch_add(*batch, 0, i, { 0 }, false);
|
||||
}
|
||||
|
||||
batch->logits[batch->n_tokens - 1] = true;
|
||||
llama_memory_clear(llama_get_memory(context), false);
|
||||
|
||||
const auto t_pp_start = ggml_time_us();
|
||||
if (llama_decode(context, *batch) != 0) {
|
||||
LOGi("llama_decode() failed during prompt processing");
|
||||
}
|
||||
const auto t_pp_end = ggml_time_us();
|
||||
|
||||
// bench text generation
|
||||
|
||||
LOGi("Benchmark text generation (tg)");
|
||||
|
||||
llama_memory_clear(llama_get_memory(context), false);
|
||||
const auto t_tg_start = ggml_time_us();
|
||||
for (i = 0; i < tg; i++) {
|
||||
|
||||
common_batch_clear(*batch);
|
||||
for (j = 0; j < pl; j++) {
|
||||
common_batch_add(*batch, 0, i, { j }, true);
|
||||
}
|
||||
|
||||
LOGi("llama_decode() text generation: %d", i);
|
||||
if (llama_decode(context, *batch) != 0) {
|
||||
LOGi("llama_decode() failed during text generation");
|
||||
}
|
||||
}
|
||||
|
||||
const auto t_tg_end = ggml_time_us();
|
||||
|
||||
llama_memory_clear(llama_get_memory(context), false);
|
||||
|
||||
const auto t_pp = double(t_pp_end - t_pp_start) / 1000000.0;
|
||||
const auto t_tg = double(t_tg_end - t_tg_start) / 1000000.0;
|
||||
|
||||
const auto speed_pp = double(pp) / t_pp;
|
||||
const auto speed_tg = double(pl * tg) / t_tg;
|
||||
|
||||
pp_avg += speed_pp;
|
||||
tg_avg += speed_tg;
|
||||
|
||||
pp_std += speed_pp * speed_pp;
|
||||
tg_std += speed_tg * speed_tg;
|
||||
|
||||
LOGi("pp %f t/s, tg %f t/s", speed_pp, speed_tg);
|
||||
}
|
||||
|
||||
pp_avg /= double(nr);
|
||||
tg_avg /= double(nr);
|
||||
|
||||
if (nr > 1) {
|
||||
pp_std = sqrt(pp_std / double(nr - 1) - pp_avg * pp_avg * double(nr) / double(nr - 1));
|
||||
tg_std = sqrt(tg_std / double(nr - 1) - tg_avg * tg_avg * double(nr) / double(nr - 1));
|
||||
} else {
|
||||
pp_std = 0;
|
||||
tg_std = 0;
|
||||
}
|
||||
|
||||
char model_desc[128];
|
||||
llama_model_desc(model, model_desc, sizeof(model_desc));
|
||||
|
||||
const auto model_size = double(llama_model_size(model)) / 1024.0 / 1024.0 / 1024.0;
|
||||
const auto model_n_params = double(llama_model_n_params(model)) / 1e9;
|
||||
|
||||
const auto backend = "(Android)"; // TODO: What should this be?
|
||||
|
||||
std::stringstream result;
|
||||
result << std::setprecision(2);
|
||||
result << "| model | size | params | backend | test | t/s |\n";
|
||||
result << "| --- | --- | --- | --- | --- | --- |\n";
|
||||
result << "| " << model_desc << " | " << model_size << "GiB | " << model_n_params << "B | " << backend << " | pp " << pp << " | " << pp_avg << " ± " << pp_std << " |\n";
|
||||
result << "| " << model_desc << " | " << model_size << "GiB | " << model_n_params << "B | " << backend << " | tg " << tg << " | " << tg_avg << " ± " << tg_std << " |\n";
|
||||
|
||||
return env->NewStringUTF(result.str().c_str());
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jlong JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_new_1batch(JNIEnv *, jobject, jint n_tokens, jint embd, jint n_seq_max) {
|
||||
|
||||
// Source: Copy of llama.cpp:llama_batch_init but heap-allocated.
|
||||
|
||||
llama_batch *batch = new llama_batch {
|
||||
0,
|
||||
nullptr,
|
||||
nullptr,
|
||||
nullptr,
|
||||
nullptr,
|
||||
nullptr,
|
||||
nullptr,
|
||||
};
|
||||
|
||||
if (embd) {
|
||||
batch->embd = (float *) malloc(sizeof(float) * n_tokens * embd);
|
||||
} else {
|
||||
batch->token = (llama_token *) malloc(sizeof(llama_token) * n_tokens);
|
||||
}
|
||||
|
||||
batch->pos = (llama_pos *) malloc(sizeof(llama_pos) * n_tokens);
|
||||
batch->n_seq_id = (int32_t *) malloc(sizeof(int32_t) * n_tokens);
|
||||
batch->seq_id = (llama_seq_id **) malloc(sizeof(llama_seq_id *) * n_tokens);
|
||||
for (int i = 0; i < n_tokens; ++i) {
|
||||
batch->seq_id[i] = (llama_seq_id *) malloc(sizeof(llama_seq_id) * n_seq_max);
|
||||
}
|
||||
batch->logits = (int8_t *) malloc(sizeof(int8_t) * n_tokens);
|
||||
|
||||
return reinterpret_cast<jlong>(batch);
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT void JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_free_1batch(JNIEnv *, jobject, jlong batch_pointer) {
|
||||
//llama_batch_free(*reinterpret_cast<llama_batch *>(batch_pointer));
|
||||
const auto batch = reinterpret_cast<llama_batch *>(batch_pointer);
|
||||
delete batch;
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jlong JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_new_1sampler(JNIEnv *, jobject) {
|
||||
auto sparams = llama_sampler_chain_default_params();
|
||||
sparams.no_perf = true;
|
||||
llama_sampler * smpl = llama_sampler_chain_init(sparams);
|
||||
llama_sampler_chain_add(smpl, llama_sampler_init_greedy());
|
||||
|
||||
return reinterpret_cast<jlong>(smpl);
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT void JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_free_1sampler(JNIEnv *, jobject, jlong sampler_pointer) {
|
||||
llama_sampler_free(reinterpret_cast<llama_sampler *>(sampler_pointer));
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT void JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_backend_1init(JNIEnv *, jobject) {
|
||||
llama_backend_init();
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jstring JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_system_1info(JNIEnv *env, jobject) {
|
||||
return env->NewStringUTF(llama_print_system_info());
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jint JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_completion_1init(
|
||||
JNIEnv *env,
|
||||
jobject,
|
||||
jlong context_pointer,
|
||||
jlong batch_pointer,
|
||||
jstring jtext,
|
||||
jboolean format_chat,
|
||||
jint n_len
|
||||
) {
|
||||
|
||||
cached_token_chars.clear();
|
||||
|
||||
const auto text = env->GetStringUTFChars(jtext, 0);
|
||||
const auto context = reinterpret_cast<llama_context *>(context_pointer);
|
||||
const auto batch = reinterpret_cast<llama_batch *>(batch_pointer);
|
||||
|
||||
bool parse_special = (format_chat == JNI_TRUE);
|
||||
const auto tokens_list = common_tokenize(context, text, true, parse_special);
|
||||
|
||||
auto n_ctx = llama_n_ctx(context);
|
||||
auto n_kv_req = tokens_list.size() + n_len;
|
||||
|
||||
LOGi("n_len = %d, n_ctx = %d, n_kv_req = %d", n_len, n_ctx, n_kv_req);
|
||||
|
||||
if (n_kv_req > n_ctx) {
|
||||
LOGe("error: n_kv_req > n_ctx, the required KV cache size is not big enough");
|
||||
}
|
||||
|
||||
for (auto id : tokens_list) {
|
||||
LOGi("token: `%s`-> %d ", common_token_to_piece(context, id).c_str(), id);
|
||||
}
|
||||
|
||||
common_batch_clear(*batch);
|
||||
|
||||
// evaluate the initial prompt
|
||||
for (auto i = 0; i < tokens_list.size(); i++) {
|
||||
common_batch_add(*batch, tokens_list[i], i, { 0 }, false);
|
||||
}
|
||||
|
||||
// llama_decode will output logits only for the last token of the prompt
|
||||
batch->logits[batch->n_tokens - 1] = true;
|
||||
|
||||
if (llama_decode(context, *batch) != 0) {
|
||||
LOGe("llama_decode() failed");
|
||||
}
|
||||
|
||||
env->ReleaseStringUTFChars(jtext, text);
|
||||
|
||||
return batch->n_tokens;
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT jstring JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_completion_1loop(
|
||||
JNIEnv * env,
|
||||
jobject,
|
||||
jlong context_pointer,
|
||||
jlong batch_pointer,
|
||||
jlong sampler_pointer,
|
||||
jint n_len,
|
||||
jobject intvar_ncur
|
||||
) {
|
||||
const auto context = reinterpret_cast<llama_context *>(context_pointer);
|
||||
const auto batch = reinterpret_cast<llama_batch *>(batch_pointer);
|
||||
const auto sampler = reinterpret_cast<llama_sampler *>(sampler_pointer);
|
||||
const auto model = llama_get_model(context);
|
||||
const auto vocab = llama_model_get_vocab(model);
|
||||
|
||||
if (!la_int_var) la_int_var = env->GetObjectClass(intvar_ncur);
|
||||
if (!la_int_var_value) la_int_var_value = env->GetMethodID(la_int_var, "getValue", "()I");
|
||||
if (!la_int_var_inc) la_int_var_inc = env->GetMethodID(la_int_var, "inc", "()V");
|
||||
|
||||
// sample the most likely token
|
||||
const auto new_token_id = llama_sampler_sample(sampler, context, -1);
|
||||
|
||||
const auto n_cur = env->CallIntMethod(intvar_ncur, la_int_var_value);
|
||||
if (llama_vocab_is_eog(vocab, new_token_id) || n_cur == n_len) {
|
||||
return nullptr;
|
||||
}
|
||||
|
||||
auto new_token_chars = common_token_to_piece(context, new_token_id);
|
||||
cached_token_chars += new_token_chars;
|
||||
|
||||
jstring new_token = nullptr;
|
||||
if (is_valid_utf8(cached_token_chars.c_str())) {
|
||||
new_token = env->NewStringUTF(cached_token_chars.c_str());
|
||||
LOGi("cached: %s, new_token_chars: `%s`, id: %d", cached_token_chars.c_str(), new_token_chars.c_str(), new_token_id);
|
||||
cached_token_chars.clear();
|
||||
} else {
|
||||
new_token = env->NewStringUTF("");
|
||||
}
|
||||
|
||||
common_batch_clear(*batch);
|
||||
common_batch_add(*batch, new_token_id, n_cur, { 0 }, true);
|
||||
|
||||
env->CallVoidMethod(intvar_ncur, la_int_var_inc);
|
||||
|
||||
if (llama_decode(context, *batch) != 0) {
|
||||
LOGe("llama_decode() returned null");
|
||||
}
|
||||
|
||||
return new_token;
|
||||
}
|
||||
|
||||
extern "C"
|
||||
JNIEXPORT void JNICALL
|
||||
Java_android_llama_cpp_LLamaAndroid_kv_1cache_1clear(JNIEnv *, jobject, jlong context) {
|
||||
llama_memory_clear(llama_get_memory(reinterpret_cast<llama_context *>(context)), true);
|
||||
}
|
||||
|
|
@ -1,180 +0,0 @@
|
|||
package android.llama.cpp
|
||||
|
||||
import android.util.Log
|
||||
import kotlinx.coroutines.CoroutineDispatcher
|
||||
import kotlinx.coroutines.asCoroutineDispatcher
|
||||
import kotlinx.coroutines.flow.Flow
|
||||
import kotlinx.coroutines.flow.flow
|
||||
import kotlinx.coroutines.flow.flowOn
|
||||
import kotlinx.coroutines.withContext
|
||||
import java.util.concurrent.Executors
|
||||
import kotlin.concurrent.thread
|
||||
|
||||
class LLamaAndroid {
|
||||
private val tag: String? = this::class.simpleName
|
||||
|
||||
private val threadLocalState: ThreadLocal<State> = ThreadLocal.withInitial { State.Idle }
|
||||
|
||||
private val runLoop: CoroutineDispatcher = Executors.newSingleThreadExecutor {
|
||||
thread(start = false, name = "Llm-RunLoop") {
|
||||
Log.d(tag, "Dedicated thread for native code: ${Thread.currentThread().name}")
|
||||
|
||||
// No-op if called more than once.
|
||||
System.loadLibrary("llama-android")
|
||||
|
||||
// Set llama log handler to Android
|
||||
log_to_android()
|
||||
backend_init(false)
|
||||
|
||||
Log.d(tag, system_info())
|
||||
|
||||
it.run()
|
||||
}.apply {
|
||||
uncaughtExceptionHandler = Thread.UncaughtExceptionHandler { _, exception: Throwable ->
|
||||
Log.e(tag, "Unhandled exception", exception)
|
||||
}
|
||||
}
|
||||
}.asCoroutineDispatcher()
|
||||
|
||||
private val nlen: Int = 64
|
||||
|
||||
private external fun log_to_android()
|
||||
private external fun load_model(filename: String): Long
|
||||
private external fun free_model(model: Long)
|
||||
private external fun new_context(model: Long): Long
|
||||
private external fun free_context(context: Long)
|
||||
private external fun backend_init(numa: Boolean)
|
||||
private external fun backend_free()
|
||||
private external fun new_batch(nTokens: Int, embd: Int, nSeqMax: Int): Long
|
||||
private external fun free_batch(batch: Long)
|
||||
private external fun new_sampler(): Long
|
||||
private external fun free_sampler(sampler: Long)
|
||||
private external fun bench_model(
|
||||
context: Long,
|
||||
model: Long,
|
||||
batch: Long,
|
||||
pp: Int,
|
||||
tg: Int,
|
||||
pl: Int,
|
||||
nr: Int
|
||||
): String
|
||||
|
||||
private external fun system_info(): String
|
||||
|
||||
private external fun completion_init(
|
||||
context: Long,
|
||||
batch: Long,
|
||||
text: String,
|
||||
formatChat: Boolean,
|
||||
nLen: Int
|
||||
): Int
|
||||
|
||||
private external fun completion_loop(
|
||||
context: Long,
|
||||
batch: Long,
|
||||
sampler: Long,
|
||||
nLen: Int,
|
||||
ncur: IntVar
|
||||
): String?
|
||||
|
||||
private external fun kv_cache_clear(context: Long)
|
||||
|
||||
suspend fun bench(pp: Int, tg: Int, pl: Int, nr: Int = 1): String {
|
||||
return withContext(runLoop) {
|
||||
when (val state = threadLocalState.get()) {
|
||||
is State.Loaded -> {
|
||||
Log.d(tag, "bench(): $state")
|
||||
bench_model(state.context, state.model, state.batch, pp, tg, pl, nr)
|
||||
}
|
||||
|
||||
else -> throw IllegalStateException("No model loaded")
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
suspend fun load(pathToModel: String) {
|
||||
withContext(runLoop) {
|
||||
when (threadLocalState.get()) {
|
||||
is State.Idle -> {
|
||||
val model = load_model(pathToModel)
|
||||
if (model == 0L) throw IllegalStateException("load_model() failed")
|
||||
|
||||
val context = new_context(model)
|
||||
if (context == 0L) throw IllegalStateException("new_context() failed")
|
||||
|
||||
val batch = new_batch(512, 0, 1)
|
||||
if (batch == 0L) throw IllegalStateException("new_batch() failed")
|
||||
|
||||
val sampler = new_sampler()
|
||||
if (sampler == 0L) throw IllegalStateException("new_sampler() failed")
|
||||
|
||||
Log.i(tag, "Loaded model $pathToModel")
|
||||
threadLocalState.set(State.Loaded(model, context, batch, sampler))
|
||||
}
|
||||
else -> throw IllegalStateException("Model already loaded")
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
fun send(message: String, formatChat: Boolean = false): Flow<String> = flow {
|
||||
when (val state = threadLocalState.get()) {
|
||||
is State.Loaded -> {
|
||||
val ncur = IntVar(completion_init(state.context, state.batch, message, formatChat, nlen))
|
||||
while (ncur.value <= nlen) {
|
||||
val str = completion_loop(state.context, state.batch, state.sampler, nlen, ncur)
|
||||
if (str == null) {
|
||||
break
|
||||
}
|
||||
emit(str)
|
||||
}
|
||||
kv_cache_clear(state.context)
|
||||
}
|
||||
else -> {}
|
||||
}
|
||||
}.flowOn(runLoop)
|
||||
|
||||
/**
|
||||
* Unloads the model and frees resources.
|
||||
*
|
||||
* This is a no-op if there's no model loaded.
|
||||
*/
|
||||
suspend fun unload() {
|
||||
withContext(runLoop) {
|
||||
when (val state = threadLocalState.get()) {
|
||||
is State.Loaded -> {
|
||||
free_context(state.context)
|
||||
free_model(state.model)
|
||||
free_batch(state.batch)
|
||||
free_sampler(state.sampler);
|
||||
|
||||
threadLocalState.set(State.Idle)
|
||||
}
|
||||
else -> {}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
companion object {
|
||||
private class IntVar(value: Int) {
|
||||
@Volatile
|
||||
var value: Int = value
|
||||
private set
|
||||
|
||||
fun inc() {
|
||||
synchronized(this) {
|
||||
value += 1
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
private sealed interface State {
|
||||
data object Idle: State
|
||||
data class Loaded(val model: Long, val context: Long, val batch: Long, val sampler: Long): State
|
||||
}
|
||||
|
||||
// Enforce only one instance of Llm.
|
||||
private val _instance: LLamaAndroid = LLamaAndroid()
|
||||
|
||||
fun instance(): LLamaAndroid = _instance
|
||||
}
|
||||
}
|
||||
|
|
@ -8,11 +8,11 @@ pluginManagement {
|
|||
dependencyResolutionManagement {
|
||||
repositoriesMode.set(RepositoriesMode.FAIL_ON_PROJECT_REPOS)
|
||||
repositories {
|
||||
google()
|
||||
mavenCentral()
|
||||
google()
|
||||
}
|
||||
}
|
||||
|
||||
rootProject.name = "LlamaAndroid"
|
||||
rootProject.name = "AiChat"
|
||||
include(":app")
|
||||
include(":llama")
|
||||
include(":lib")
|
||||
|
|
|
|||
|
|
@ -10,6 +10,13 @@ and in some cases perplexity checked of the quantized model. And finally the
|
|||
model/models need to the ggml-org on Hugging Face. This tool/example tries to
|
||||
help with this process.
|
||||
|
||||
> 📝 **Note:** When adding a new model from an existing family, verify the
|
||||
> previous version passes logits verification first. Existing models can have
|
||||
> subtle numerical differences that don't affect generation quality but cause
|
||||
> logits mismatches. Identifying these upfront whether they exist in llama.cpp,
|
||||
> the conversion script, or in an upstream implementation, can save significant
|
||||
> debugging time.
|
||||
|
||||
### Overview
|
||||
The idea is that the makefile targets and scripts here can be used in the
|
||||
development/conversion process assisting with things like:
|
||||
|
|
|
|||
|
|
@ -7,7 +7,7 @@ base_model:
|
|||
Recommended way to run this model:
|
||||
|
||||
```sh
|
||||
llama-server -hf {namespace}/{model_name}-GGUF -c 0 -fa
|
||||
llama-server -hf {namespace}/{model_name}-GGUF -c 0
|
||||
```
|
||||
|
||||
Then, access http://localhost:8080
|
||||
|
|
|
|||
|
|
@ -2,134 +2,22 @@
|
|||
|
||||
import argparse
|
||||
import os
|
||||
import sys
|
||||
import importlib
|
||||
from pathlib import Path
|
||||
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig
|
||||
# Add parent directory to path for imports
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..'))
|
||||
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoModelForImageTextToText, AutoConfig
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
### If you want to dump RoPE activations, apply this monkey patch to the model
|
||||
### class from Transformers that you are running (replace apertus.modeling_apertus
|
||||
### with the proper package and class for your model
|
||||
### === START ROPE DEBUG ===
|
||||
# from transformers.models.apertus.modeling_apertus import apply_rotary_pos_emb
|
||||
|
||||
# orig_rope = apply_rotary_pos_emb
|
||||
# torch.set_printoptions(threshold=float('inf'))
|
||||
# torch.set_printoptions(precision=6, sci_mode=False)
|
||||
|
||||
# def debug_rope(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
|
||||
# # log inputs
|
||||
# summarize(q, "RoPE.q_in")
|
||||
# summarize(k, "RoPE.k_in")
|
||||
|
||||
# # call original
|
||||
# q_out, k_out = orig_rope(q, k, cos, sin, position_ids, unsqueeze_dim)
|
||||
|
||||
# # log outputs
|
||||
# summarize(q_out, "RoPE.q_out")
|
||||
# summarize(k_out, "RoPE.k_out")
|
||||
|
||||
# return q_out, k_out
|
||||
|
||||
# # Patch it
|
||||
# import transformers.models.apertus.modeling_apertus as apertus_mod # noqa: E402
|
||||
# apertus_mod.apply_rotary_pos_emb = debug_rope
|
||||
### == END ROPE DEBUG ===
|
||||
|
||||
|
||||
def summarize(tensor: torch.Tensor, name: str, max_seq: int = 3, max_vals: int = 3):
|
||||
"""
|
||||
Print a tensor in llama.cpp debug style.
|
||||
|
||||
Supports:
|
||||
- 2D tensors (seq, hidden)
|
||||
- 3D tensors (batch, seq, hidden)
|
||||
- 4D tensors (batch, seq, heads, dim_per_head) via flattening heads × dim_per_head
|
||||
|
||||
Shows first and last max_vals of each vector per sequence position.
|
||||
"""
|
||||
t = tensor.detach().to(torch.float32).cpu()
|
||||
|
||||
# Determine dimensions
|
||||
if t.ndim == 3:
|
||||
_, s, _ = t.shape
|
||||
elif t.ndim == 2:
|
||||
_, s = 1, t.shape[0]
|
||||
t = t.unsqueeze(0)
|
||||
elif t.ndim == 4:
|
||||
_, s, _, _ = t.shape
|
||||
else:
|
||||
print(f"Skipping tensor due to unsupported dimensions: {t.ndim}")
|
||||
return
|
||||
|
||||
ten_shape = t.shape
|
||||
|
||||
print(f"ggml_debug: {name} = (f32) ... = {{{ten_shape}}}")
|
||||
print(" [")
|
||||
print(" [")
|
||||
|
||||
# Determine indices for first and last sequences
|
||||
first_indices = list(range(min(s, max_seq)))
|
||||
last_indices = list(range(max(0, s - max_seq), s))
|
||||
|
||||
# Check if there's an overlap between first and last indices or if we're at the edge case of s = 2 * max_seq
|
||||
has_overlap = bool(set(first_indices) & set(last_indices)) or (max_seq * 2 == s)
|
||||
|
||||
# Combine indices
|
||||
if has_overlap:
|
||||
# If there's overlap, just use the combined unique indices
|
||||
indices = sorted(list(set(first_indices + last_indices)))
|
||||
separator_index = None
|
||||
else:
|
||||
# If no overlap, we'll add a separator between first and last sequences
|
||||
indices = first_indices + last_indices
|
||||
separator_index = len(first_indices)
|
||||
|
||||
for i, si in enumerate(indices):
|
||||
# Add separator if needed
|
||||
if separator_index is not None and i == separator_index:
|
||||
print(" ...")
|
||||
|
||||
# Extract appropriate slice
|
||||
vec = t[0, si]
|
||||
if vec.ndim == 2: # 4D case: flatten heads × dim_per_head
|
||||
flat = vec.flatten().tolist()
|
||||
else: # 2D or 3D case
|
||||
flat = vec.tolist()
|
||||
|
||||
# First and last slices
|
||||
first = flat[:max_vals]
|
||||
last = flat[-max_vals:] if len(flat) >= max_vals else flat
|
||||
first_str = ", ".join(f"{v:12.4f}" for v in first)
|
||||
last_str = ", ".join(f"{v:12.4f}" for v in last)
|
||||
|
||||
print(f" [{first_str}, ..., {last_str}]")
|
||||
|
||||
print(" ],")
|
||||
print(" ]")
|
||||
print(f" sum = {t.sum().item():.6f}\n")
|
||||
|
||||
|
||||
def debug_hook(name):
|
||||
def fn(_m, input, output):
|
||||
if isinstance(input, torch.Tensor):
|
||||
summarize(input, name + "_in")
|
||||
elif isinstance(input, (tuple, list)) and isinstance(input[0], torch.Tensor):
|
||||
summarize(input[0], name + "_in")
|
||||
if isinstance(output, torch.Tensor):
|
||||
summarize(output, name + "_out")
|
||||
elif isinstance(output, (tuple, list)) and isinstance(output[0], torch.Tensor):
|
||||
summarize(output[0], name + "_out")
|
||||
|
||||
return fn
|
||||
|
||||
|
||||
unreleased_model_name = os.getenv("UNRELEASED_MODEL_NAME")
|
||||
from utils.common import debug_hook
|
||||
|
||||
parser = argparse.ArgumentParser(description="Process model with specified path")
|
||||
parser.add_argument("--model-path", "-m", help="Path to the model")
|
||||
parser.add_argument("--prompt-file", "-f", help="Optional prompt file", required=False)
|
||||
parser.add_argument("--verbose", "-v", action="store_true", help="Enable verbose debug output")
|
||||
args = parser.parse_args()
|
||||
|
||||
model_path = os.environ.get("MODEL_PATH", args.model_path)
|
||||
|
|
@ -138,18 +26,30 @@ if model_path is None:
|
|||
"Model path must be specified either via --model-path argument or MODEL_PATH environment variable"
|
||||
)
|
||||
|
||||
### If you want to dump RoPE activations, uncomment the following lines:
|
||||
### === START ROPE DEBUG ===
|
||||
# from utils.common import setup_rope_debug
|
||||
# setup_rope_debug("transformers.models.apertus.modeling_apertus")
|
||||
### == END ROPE DEBUG ===
|
||||
|
||||
|
||||
print("Loading model and tokenizer using AutoTokenizer:", model_path)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
|
||||
config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
|
||||
multimodal = False
|
||||
full_config = config
|
||||
|
||||
print("Model type: ", config.model_type)
|
||||
if "vocab_size" not in config and "text_config" in config:
|
||||
config = config.text_config
|
||||
multimodal = True
|
||||
print("Vocab size: ", config.vocab_size)
|
||||
print("Hidden size: ", config.hidden_size)
|
||||
print("Number of layers: ", config.num_hidden_layers)
|
||||
print("BOS token id: ", config.bos_token_id)
|
||||
print("EOS token id: ", config.eos_token_id)
|
||||
|
||||
unreleased_model_name = os.getenv("UNRELEASED_MODEL_NAME")
|
||||
if unreleased_model_name:
|
||||
model_name_lower = unreleased_model_name.lower()
|
||||
unreleased_module_path = (
|
||||
|
|
@ -169,13 +69,19 @@ if unreleased_model_name:
|
|||
print(f"Failed to import or load model: {e}")
|
||||
exit(1)
|
||||
else:
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
model_path, device_map="auto", offload_folder="offload", trust_remote_code=True, config=config
|
||||
)
|
||||
if multimodal:
|
||||
model = AutoModelForImageTextToText.from_pretrained(
|
||||
model_path, device_map="auto", offload_folder="offload", trust_remote_code=True, config=full_config
|
||||
)
|
||||
else:
|
||||
model = AutoModelForCausalLM.from_pretrained(
|
||||
model_path, device_map="auto", offload_folder="offload", trust_remote_code=True, config=config
|
||||
)
|
||||
|
||||
for name, module in model.named_modules():
|
||||
if len(list(module.children())) == 0: # only leaf modules
|
||||
module.register_forward_hook(debug_hook(name))
|
||||
if args.verbose:
|
||||
for name, module in model.named_modules():
|
||||
if len(list(module.children())) == 0: # only leaf modules
|
||||
module.register_forward_hook(debug_hook(name))
|
||||
|
||||
model_name = os.path.basename(model_path)
|
||||
# Printing the Model class to allow for easier debugging. This can be useful
|
||||
|
|
@ -185,7 +91,10 @@ model_name = os.path.basename(model_path)
|
|||
print(f"Model class: {model.__class__.__name__}")
|
||||
|
||||
device = next(model.parameters()).device
|
||||
if os.getenv("MODEL_TESTING_PROMPT"):
|
||||
if args.prompt_file:
|
||||
with open(args.prompt_file, encoding='utf-8') as f:
|
||||
prompt = f.read()
|
||||
elif os.getenv("MODEL_TESTING_PROMPT"):
|
||||
prompt = os.getenv("MODEL_TESTING_PROMPT")
|
||||
else:
|
||||
prompt = "Hello, my name is"
|
||||
|
|
@ -195,9 +104,18 @@ print(f"Input tokens: {input_ids}")
|
|||
print(f"Input text: {repr(prompt)}")
|
||||
print(f"Tokenized: {tokenizer.convert_ids_to_tokens(input_ids[0])}")
|
||||
|
||||
batch_size = 512
|
||||
|
||||
with torch.no_grad():
|
||||
outputs = model(input_ids.to(model.device))
|
||||
logits = outputs.logits
|
||||
past = None
|
||||
outputs = None
|
||||
for i in range(0, input_ids.size(1), batch_size):
|
||||
print(f"Processing chunk with tokens {i} to {i + batch_size}")
|
||||
chunk = input_ids[:, i:i + batch_size]
|
||||
outputs = model(chunk.to(model.device), past_key_values=past, use_cache=True)
|
||||
past = outputs.past_key_values
|
||||
|
||||
logits = outputs.logits # type: ignore
|
||||
|
||||
# Extract logits for the last token (next token prediction)
|
||||
last_logits = logits[0, -1, :].float().cpu().numpy()
|
||||
|
|
|
|||
|
|
@ -34,8 +34,11 @@ done
|
|||
MODEL_PATH="${MODEL_PATH:-"$EMBEDDING_MODEL_PATH"}"
|
||||
MODEL_NAME="${MODEL_NAME:-$(basename "$MODEL_PATH")}"
|
||||
|
||||
CONVERTED_MODEL_PATH="${CONVERTED_EMBEDDING_PATH:-"$CONVERTED_EMBEDDING_MODEL"}"
|
||||
CONVERTED_MODEL_NAME="${CONVERTED_MODEL_NAME:-$(basename "$CONVERTED_MODEL_PATH" .gguf)}"
|
||||
|
||||
if [ -t 0 ]; then
|
||||
CPP_EMBEDDINGS="data/llamacpp-${MODEL_NAME}-embeddings.bin"
|
||||
CPP_EMBEDDINGS="data/llamacpp-${CONVERTED_MODEL_NAME}-embeddings.bin"
|
||||
else
|
||||
# Process piped JSON data and convert to binary (matching logits.cpp format)
|
||||
TEMP_FILE=$(mktemp /tmp/tmp.XXXXXX.binn)
|
||||
|
|
|
|||
|
|
@ -2,6 +2,8 @@
|
|||
|
||||
import os
|
||||
import sys
|
||||
import torch
|
||||
|
||||
|
||||
def get_model_name_from_env_path(env_path_name):
|
||||
model_path = os.getenv(env_path_name)
|
||||
|
|
@ -18,3 +20,131 @@ def get_model_name_from_env_path(env_path_name):
|
|||
name = name[:-5]
|
||||
|
||||
return name
|
||||
|
||||
|
||||
def summarize(tensor: torch.Tensor, name: str, max_seq: int = 3, max_vals: int = 3):
|
||||
"""
|
||||
Print a tensor in llama.cpp debug style.
|
||||
|
||||
Supports:
|
||||
- 2D tensors (seq, hidden)
|
||||
- 3D tensors (batch, seq, hidden)
|
||||
- 4D tensors (batch, seq, heads, dim_per_head) via flattening heads × dim_per_head
|
||||
|
||||
Shows first and last max_vals of each vector per sequence position.
|
||||
"""
|
||||
t = tensor.detach().to(torch.float32).cpu()
|
||||
|
||||
# Determine dimensions
|
||||
if t.ndim == 3:
|
||||
_, s, _ = t.shape
|
||||
elif t.ndim == 2:
|
||||
_, s = 1, t.shape[0]
|
||||
t = t.unsqueeze(0)
|
||||
elif t.ndim == 4:
|
||||
_, s, _, _ = t.shape
|
||||
else:
|
||||
print(f"Skipping tensor due to unsupported dimensions: {t.ndim}")
|
||||
return
|
||||
|
||||
ten_shape = t.shape
|
||||
|
||||
print(f"ggml_debug: {name} = (f32) ... = {{{ten_shape}}}")
|
||||
print(" [")
|
||||
print(" [")
|
||||
|
||||
# Determine indices for first and last sequences
|
||||
first_indices = list(range(min(s, max_seq)))
|
||||
last_indices = list(range(max(0, s - max_seq), s))
|
||||
|
||||
# Check if there's an overlap between first and last indices or if we're at the edge case of s = 2 * max_seq
|
||||
has_overlap = bool(set(first_indices) & set(last_indices)) or (max_seq * 2 == s)
|
||||
|
||||
# Combine indices
|
||||
if has_overlap:
|
||||
# If there's overlap, just use the combined unique indices
|
||||
indices = sorted(list(set(first_indices + last_indices)))
|
||||
separator_index = None
|
||||
else:
|
||||
# If no overlap, we'll add a separator between first and last sequences
|
||||
indices = first_indices + last_indices
|
||||
separator_index = len(first_indices)
|
||||
|
||||
for i, si in enumerate(indices):
|
||||
# Add separator if needed
|
||||
if separator_index is not None and i == separator_index:
|
||||
print(" ...")
|
||||
|
||||
# Extract appropriate slice
|
||||
vec = t[0, si]
|
||||
if vec.ndim == 2: # 4D case: flatten heads × dim_per_head
|
||||
flat = vec.flatten().tolist()
|
||||
else: # 2D or 3D case
|
||||
flat = vec.tolist()
|
||||
|
||||
# First and last slices
|
||||
first = flat[:max_vals]
|
||||
last = flat[-max_vals:] if len(flat) >= max_vals else flat
|
||||
first_str = ", ".join(f"{v:12.4f}" for v in first)
|
||||
last_str = ", ".join(f"{v:12.4f}" for v in last)
|
||||
|
||||
print(f" [{first_str}, ..., {last_str}]")
|
||||
|
||||
print(" ],")
|
||||
print(" ]")
|
||||
print(f" sum = {t.sum().item():.6f}\n")
|
||||
|
||||
|
||||
def debug_hook(name):
|
||||
def fn(_m, input, output):
|
||||
if isinstance(input, torch.Tensor):
|
||||
summarize(input, name + "_in")
|
||||
elif isinstance(input, (tuple, list)) and len(input) > 0 and isinstance(input[0], torch.Tensor):
|
||||
summarize(input[0], name + "_in")
|
||||
if isinstance(output, torch.Tensor):
|
||||
summarize(output, name + "_out")
|
||||
elif isinstance(output, (tuple, list)) and len(output) > 0 and isinstance(output[0], torch.Tensor):
|
||||
summarize(output[0], name + "_out")
|
||||
|
||||
return fn
|
||||
|
||||
|
||||
def setup_rope_debug(model_module_path: str, function_name: str = "apply_rotary_pos_emb"):
|
||||
"""
|
||||
Apply monkey patch to dump RoPE activations for debugging.
|
||||
|
||||
Args:
|
||||
model_module_path: Path to the model module (e.g., "transformers.models.apertus.modeling_apertus")
|
||||
function_name: Name of the RoPE function to patch (default: "apply_rotary_pos_emb")
|
||||
|
||||
Example:
|
||||
from utils.common import setup_rope_debug
|
||||
setup_rope_debug("transformers.models.apertus.modeling_apertus")
|
||||
"""
|
||||
import importlib
|
||||
|
||||
# Import the module and get the original function
|
||||
module = importlib.import_module(model_module_path)
|
||||
orig_rope = getattr(module, function_name)
|
||||
|
||||
# Set torch print options for better debugging
|
||||
torch.set_printoptions(threshold=float('inf'))
|
||||
torch.set_printoptions(precision=6, sci_mode=False)
|
||||
|
||||
def debug_rope(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
|
||||
# log inputs
|
||||
summarize(q, "RoPE.q_in")
|
||||
summarize(k, "RoPE.k_in")
|
||||
|
||||
# call original
|
||||
q_out, k_out = orig_rope(q, k, cos, sin, position_ids, unsqueeze_dim)
|
||||
|
||||
# log outputs
|
||||
summarize(q_out, "RoPE.q_out")
|
||||
summarize(k_out, "RoPE.k_out")
|
||||
|
||||
return q_out, k_out
|
||||
|
||||
# Patch it
|
||||
setattr(module, function_name, debug_rope)
|
||||
print(f"RoPE debug patching applied to {model_module_path}.{function_name}")
|
||||
|
|
|
|||
|
|
@ -242,7 +242,7 @@ int main(int argc, char ** argv) {
|
|||
bool accept = false;
|
||||
if (params.sampling.temp > 0) {
|
||||
// stochastic verification
|
||||
common_sampler_sample(smpl, ctx_tgt, drafts[s_keep].i_batch_tgt[i_dft]);
|
||||
common_sampler_sample(smpl, ctx_tgt, drafts[s_keep].i_batch_tgt[i_dft], true);
|
||||
|
||||
auto & dist_tgt = *common_sampler_get_candidates(smpl, true);
|
||||
|
||||
|
|
@ -491,7 +491,7 @@ int main(int argc, char ** argv) {
|
|||
continue;
|
||||
}
|
||||
|
||||
common_sampler_sample(drafts[s].smpl, ctx_dft, drafts[s].i_batch_dft);
|
||||
common_sampler_sample(drafts[s].smpl, ctx_dft, drafts[s].i_batch_dft, true);
|
||||
|
||||
const auto * cur_p = common_sampler_get_candidates(drafts[s].smpl, true);
|
||||
|
||||
|
|
|
|||
|
|
@ -254,6 +254,7 @@ set (GGML_OPENCL_TARGET_VERSION "300" CACHE STRING
|
|||
"gmml: OpenCL API version to target")
|
||||
|
||||
option(GGML_HEXAGON "ggml: enable Hexagon backend" OFF)
|
||||
set(GGML_HEXAGON_FP32_QUANTIZE_GROUP_SIZE 128 CACHE STRING "ggml: quantize group size (32, 64, or 128)")
|
||||
|
||||
# toolchain for vulkan-shaders-gen
|
||||
set (GGML_VULKAN_SHADERS_GEN_TOOLCHAIN "" CACHE FILEPATH "ggml: toolchain file for vulkan-shaders-gen")
|
||||
|
|
|
|||
|
|
@ -386,6 +386,9 @@ if (GGML_CPU_ALL_VARIANTS)
|
|||
ggml_add_cpu_backend_variant(android_armv8.2_1 DOTPROD)
|
||||
ggml_add_cpu_backend_variant(android_armv8.2_2 DOTPROD FP16_VECTOR_ARITHMETIC)
|
||||
ggml_add_cpu_backend_variant(android_armv8.6_1 DOTPROD FP16_VECTOR_ARITHMETIC MATMUL_INT8)
|
||||
ggml_add_cpu_backend_variant(android_armv9.0_1 DOTPROD MATMUL_INT8 FP16_VECTOR_ARITHMETIC SVE2)
|
||||
ggml_add_cpu_backend_variant(android_armv9.2_1 DOTPROD MATMUL_INT8 FP16_VECTOR_ARITHMETIC SME)
|
||||
ggml_add_cpu_backend_variant(android_armv9.2_2 DOTPROD MATMUL_INT8 FP16_VECTOR_ARITHMETIC SVE SME)
|
||||
elseif (APPLE)
|
||||
ggml_add_cpu_backend_variant(apple_m1 DOTPROD)
|
||||
ggml_add_cpu_backend_variant(apple_m2_m3 DOTPROD MATMUL_INT8)
|
||||
|
|
|
|||
|
|
@ -458,6 +458,7 @@ function(ggml_add_cpu_backend_variant_impl tag_name)
|
|||
if (GGML_RV_ZFH)
|
||||
string(APPEND MARCH_STR "_zfh")
|
||||
endif()
|
||||
|
||||
if (GGML_XTHEADVECTOR)
|
||||
string(APPEND MARCH_STR "_xtheadvector")
|
||||
elseif (GGML_RVV)
|
||||
|
|
@ -465,6 +466,9 @@ function(ggml_add_cpu_backend_variant_impl tag_name)
|
|||
if (GGML_RV_ZVFH)
|
||||
string(APPEND MARCH_STR "_zvfh")
|
||||
endif()
|
||||
if (GGML_RV_ZVFBFWMA)
|
||||
string(APPEND MARCH_STR "_zvfbfwma")
|
||||
endif()
|
||||
endif()
|
||||
if (GGML_RV_ZICBOP)
|
||||
string(APPEND MARCH_STR "_zicbop")
|
||||
|
|
|
|||
|
|
@ -43,6 +43,8 @@
|
|||
#define ggml_gemv_q2_K_8x8_q8_K_generic ggml_gemv_q2_K_8x8_q8_K
|
||||
#define ggml_gemv_iq4_nl_4x4_q8_0_generic ggml_gemv_iq4_nl_4x4_q8_0
|
||||
#define ggml_gemv_iq4_nl_8x8_q8_0_generic ggml_gemv_iq4_nl_8x8_q8_0
|
||||
#define ggml_gemv_q8_0_4x4_q8_0_generic ggml_gemv_q8_0_4x4_q8_0
|
||||
#define ggml_gemv_q8_0_4x8_q8_0_generic ggml_gemv_q8_0_4x8_q8_0
|
||||
#define ggml_gemm_q4_0_4x4_q8_0_generic ggml_gemm_q4_0_4x4_q8_0
|
||||
#define ggml_gemm_q4_0_4x8_q8_0_generic ggml_gemm_q4_0_4x8_q8_0
|
||||
#define ggml_gemm_q4_0_8x8_q8_0_generic ggml_gemm_q4_0_8x8_q8_0
|
||||
|
|
@ -51,6 +53,8 @@
|
|||
#define ggml_gemm_q2_K_8x8_q8_K_generic ggml_gemm_q2_K_8x8_q8_K
|
||||
#define ggml_gemm_iq4_nl_4x4_q8_0_generic ggml_gemm_iq4_nl_4x4_q8_0
|
||||
#define ggml_gemm_iq4_nl_8x8_q8_0_generic ggml_gemm_iq4_nl_8x8_q8_0
|
||||
#define ggml_gemm_q8_0_4x4_q8_0_generic ggml_gemm_q8_0_4x4_q8_0
|
||||
#define ggml_gemm_q8_0_4x8_q8_0_generic ggml_gemm_q8_0_4x8_q8_0
|
||||
#elif defined(__aarch64__) || defined(__arm__) || defined(_M_ARM) || defined(_M_ARM64)
|
||||
// repack.cpp
|
||||
#define ggml_quantize_mat_q8_K_4x4_generic ggml_quantize_mat_q8_K_4x4
|
||||
|
|
@ -67,10 +71,14 @@
|
|||
#define ggml_gemv_q4_0_4x8_q8_0_generic ggml_gemv_q4_0_4x8_q8_0
|
||||
#define ggml_gemv_q4_K_8x4_q8_K_generic ggml_gemv_q4_K_8x4_q8_K
|
||||
#define ggml_gemv_iq4_nl_4x4_q8_0_generic ggml_gemv_iq4_nl_4x4_q8_0
|
||||
#define ggml_gemv_q8_0_4x4_q8_0_generic ggml_gemv_q8_0_4x4_q8_0
|
||||
#define ggml_gemv_q8_0_4x8_q8_0_generic ggml_gemv_q8_0_4x8_q8_0
|
||||
#define ggml_gemm_q4_0_4x4_q8_0_generic ggml_gemm_q4_0_4x4_q8_0
|
||||
#define ggml_gemm_q4_0_4x8_q8_0_generic ggml_gemm_q4_0_4x8_q8_0
|
||||
#define ggml_gemm_q4_K_8x4_q8_K_generic ggml_gemm_q4_K_8x4_q8_K
|
||||
#define ggml_gemm_iq4_nl_4x4_q8_0_generic ggml_gemm_iq4_nl_4x4_q8_0
|
||||
#define ggml_gemm_q8_0_4x4_q8_0_generic ggml_gemm_q8_0_4x4_q8_0
|
||||
#define ggml_gemm_q8_0_4x8_q8_0_generic ggml_gemm_q8_0_4x8_q8_0
|
||||
#elif defined(__POWERPC__) || defined(__powerpc__)
|
||||
// ref: https://github.com/ggml-org/llama.cpp/pull/14146#issuecomment-2972561679
|
||||
// quants.c
|
||||
|
|
@ -91,6 +99,8 @@
|
|||
#define ggml_gemv_q2_K_8x8_q8_K_generic ggml_gemv_q2_K_8x8_q8_K
|
||||
#define ggml_gemv_iq4_nl_4x4_q8_0_generic ggml_gemv_iq4_nl_4x4_q8_0
|
||||
#define ggml_gemv_iq4_nl_8x8_q8_0_generic ggml_gemv_iq4_nl_8x8_q8_0
|
||||
#define ggml_gemv_q8_0_4x4_q8_0_generic ggml_gemv_q8_0_4x4_q8_0
|
||||
#define ggml_gemv_q8_0_4x8_q8_0_generic ggml_gemv_q8_0_4x8_q8_0
|
||||
#define ggml_gemm_q4_0_4x4_q8_0_generic ggml_gemm_q4_0_4x4_q8_0
|
||||
#define ggml_gemm_q4_0_4x8_q8_0_generic ggml_gemm_q4_0_4x8_q8_0
|
||||
#define ggml_gemm_q4_0_8x8_q8_0_generic ggml_gemm_q4_0_8x8_q8_0
|
||||
|
|
@ -99,6 +109,8 @@
|
|||
#define ggml_gemm_q2_K_8x8_q8_K_generic ggml_gemm_q2_K_8x8_q8_K
|
||||
#define ggml_gemm_iq4_nl_4x4_q8_0_generic ggml_gemm_iq4_nl_4x4_q8_0
|
||||
#define ggml_gemm_iq4_nl_8x8_q8_0_generic ggml_gemm_iq4_nl_8x8_q8_0
|
||||
#define ggml_gemm_q8_0_4x4_q8_0_generic ggml_gemm_q8_0_4x4_q8_0
|
||||
#define ggml_gemm_q8_0_4x8_q8_0_generic ggml_gemm_q8_0_4x8_q8_0
|
||||
#elif defined(__loongarch64)
|
||||
// quants.c
|
||||
#define quantize_row_q8_K_generic quantize_row_q8_K
|
||||
|
|
@ -119,6 +131,8 @@
|
|||
#define ggml_gemv_q2_K_8x8_q8_K_generic ggml_gemv_q2_K_8x8_q8_K
|
||||
#define ggml_gemv_iq4_nl_4x4_q8_0_generic ggml_gemv_iq4_nl_4x4_q8_0
|
||||
#define ggml_gemv_iq4_nl_8x8_q8_0_generic ggml_gemv_iq4_nl_8x8_q8_0
|
||||
#define ggml_gemv_q8_0_4x4_q8_0_generic ggml_gemv_q8_0_4x4_q8_0
|
||||
#define ggml_gemv_q8_0_4x8_q8_0_generic ggml_gemv_q8_0_4x8_q8_0
|
||||
#define ggml_gemm_q4_0_4x4_q8_0_generic ggml_gemm_q4_0_4x4_q8_0
|
||||
#define ggml_gemm_q4_0_4x8_q8_0_generic ggml_gemm_q4_0_4x8_q8_0
|
||||
#define ggml_gemm_q4_0_8x8_q8_0_generic ggml_gemm_q4_0_8x8_q8_0
|
||||
|
|
@ -127,6 +141,8 @@
|
|||
#define ggml_gemm_q2_K_8x8_q8_K_generic ggml_gemm_q2_K_8x8_q8_K
|
||||
#define ggml_gemm_iq4_nl_4x4_q8_0_generic ggml_gemm_iq4_nl_4x4_q8_0
|
||||
#define ggml_gemm_iq4_nl_8x8_q8_0_generic ggml_gemm_iq4_nl_8x8_q8_0
|
||||
#define ggml_gemm_q8_0_4x4_q8_0_generic ggml_gemm_q8_0_4x4_q8_0
|
||||
#define ggml_gemm_q8_0_4x8_q8_0_generic ggml_gemm_q8_0_4x8_q8_0
|
||||
#elif defined(__riscv)
|
||||
// quants.c
|
||||
#define quantize_row_q8_K_generic quantize_row_q8_K
|
||||
|
|
@ -154,6 +170,8 @@
|
|||
#define ggml_gemv_q2_K_8x8_q8_K_generic ggml_gemv_q2_K_8x8_q8_K
|
||||
#define ggml_gemv_iq4_nl_4x4_q8_0_generic ggml_gemv_iq4_nl_4x4_q8_0
|
||||
#define ggml_gemv_iq4_nl_8x8_q8_0_generic ggml_gemv_iq4_nl_8x8_q8_0
|
||||
#define ggml_gemv_q8_0_4x4_q8_0_generic ggml_gemv_q8_0_4x4_q8_0
|
||||
#define ggml_gemv_q8_0_4x8_q8_0_generic ggml_gemv_q8_0_4x8_q8_0
|
||||
#define ggml_gemm_q4_0_4x4_q8_0_generic ggml_gemm_q4_0_4x4_q8_0
|
||||
#define ggml_gemm_q4_0_4x8_q8_0_generic ggml_gemm_q4_0_4x8_q8_0
|
||||
#define ggml_gemm_q4_K_8x4_q8_K_generic ggml_gemm_q4_K_8x4_q8_K
|
||||
|
|
@ -161,6 +179,8 @@
|
|||
#define ggml_gemm_q2_K_8x8_q8_K_generic ggml_gemm_q2_K_8x8_q8_K
|
||||
#define ggml_gemm_iq4_nl_4x4_q8_0_generic ggml_gemm_iq4_nl_4x4_q8_0
|
||||
#define ggml_gemm_iq4_nl_8x8_q8_0_generic ggml_gemm_iq4_nl_8x8_q8_0
|
||||
#define ggml_gemm_q8_0_4x4_q8_0_generic ggml_gemm_q8_0_4x4_q8_0
|
||||
#define ggml_gemm_q8_0_4x8_q8_0_generic ggml_gemm_q8_0_4x8_q8_0
|
||||
#elif defined(__s390x__)
|
||||
// quants.c
|
||||
#define quantize_row_q8_K_generic quantize_row_q8_K
|
||||
|
|
@ -187,6 +207,8 @@
|
|||
#define ggml_gemv_q2_K_8x8_q8_K_generic ggml_gemv_q2_K_8x8_q8_K
|
||||
#define ggml_gemv_iq4_nl_4x4_q8_0_generic ggml_gemv_iq4_nl_4x4_q8_0
|
||||
#define ggml_gemv_iq4_nl_8x8_q8_0_generic ggml_gemv_iq4_nl_8x8_q8_0
|
||||
#define ggml_gemv_q8_0_4x4_q8_0_generic ggml_gemv_q8_0_4x4_q8_0
|
||||
#define ggml_gemv_q8_0_4x8_q8_0_generic ggml_gemv_q8_0_4x8_q8_0
|
||||
#define ggml_gemm_q4_0_4x4_q8_0_generic ggml_gemm_q4_0_4x4_q8_0
|
||||
#define ggml_gemm_q4_0_4x8_q8_0_generic ggml_gemm_q4_0_4x8_q8_0
|
||||
#define ggml_gemm_q4_0_8x8_q8_0_generic ggml_gemm_q4_0_8x8_q8_0
|
||||
|
|
@ -195,6 +217,8 @@
|
|||
#define ggml_gemm_q2_K_8x8_q8_K_generic ggml_gemm_q2_K_8x8_q8_K
|
||||
#define ggml_gemm_iq4_nl_4x4_q8_0_generic ggml_gemm_iq4_nl_4x4_q8_0
|
||||
#define ggml_gemm_iq4_nl_8x8_q8_0_generic ggml_gemm_iq4_nl_8x8_q8_0
|
||||
#define ggml_gemm_q8_0_4x4_q8_0_generic ggml_gemm_q8_0_4x4_q8_0
|
||||
#define ggml_gemm_q8_0_4x8_q8_0_generic ggml_gemm_q8_0_4x8_q8_0
|
||||
#elif defined(__wasm__)
|
||||
// quants.c
|
||||
#define ggml_vec_dot_q4_1_q8_1_generic ggml_vec_dot_q4_1_q8_1
|
||||
|
|
@ -223,6 +247,8 @@
|
|||
#define ggml_gemv_q2_K_8x8_q8_K_generic ggml_gemv_q2_K_8x8_q8_K
|
||||
#define ggml_gemv_iq4_nl_4x4_q8_0_generic ggml_gemv_iq4_nl_4x4_q8_0
|
||||
#define ggml_gemv_iq4_nl_8x8_q8_0_generic ggml_gemv_iq4_nl_8x8_q8_0
|
||||
#define ggml_gemv_q8_0_4x4_q8_0_generic ggml_gemv_q8_0_4x4_q8_0
|
||||
#define ggml_gemv_q8_0_4x8_q8_0_generic ggml_gemv_q8_0_4x8_q8_0
|
||||
#define ggml_gemm_q4_0_4x4_q8_0_generic ggml_gemm_q4_0_4x4_q8_0
|
||||
#define ggml_gemm_q4_0_4x8_q8_0_generic ggml_gemm_q4_0_4x8_q8_0
|
||||
#define ggml_gemm_q4_0_8x8_q8_0_generic ggml_gemm_q4_0_8x8_q8_0
|
||||
|
|
@ -231,4 +257,6 @@
|
|||
#define ggml_gemm_q2_K_8x8_q8_K_generic ggml_gemm_q2_K_8x8_q8_K
|
||||
#define ggml_gemm_iq4_nl_4x4_q8_0_generic ggml_gemm_iq4_nl_4x4_q8_0
|
||||
#define ggml_gemm_iq4_nl_8x8_q8_0_generic ggml_gemm_iq4_nl_8x8_q8_0
|
||||
#define ggml_gemm_q8_0_4x4_q8_0_generic ggml_gemm_q8_0_4x4_q8_0
|
||||
#define ggml_gemm_q8_0_4x8_q8_0_generic ggml_gemm_q8_0_4x8_q8_0
|
||||
#endif
|
||||
|
|
|
|||
|
|
@ -786,6 +786,133 @@ void ggml_gemv_q4_K_8x8_q8_K(int n,
|
|||
ggml_gemv_q4_K_8x8_q8_K_generic(n, s, bs, vx, vy, nr, nc);
|
||||
}
|
||||
|
||||
void ggml_gemv_q8_0_4x4_q8_0(int n,
|
||||
float * GGML_RESTRICT s,
|
||||
size_t bs,
|
||||
const void * GGML_RESTRICT vx,
|
||||
const void * GGML_RESTRICT vy,
|
||||
int nr,
|
||||
int nc) {
|
||||
const int qk = QK8_0;
|
||||
const int nb = n / qk;
|
||||
const int ncols_interleaved = 4;
|
||||
const int blocklen = 4;
|
||||
|
||||
assert(n % qk == 0);
|
||||
assert(nc % ncols_interleaved == 0);
|
||||
|
||||
UNUSED(nb);
|
||||
UNUSED(ncols_interleaved);
|
||||
UNUSED(blocklen);
|
||||
|
||||
#if defined(__aarch64__) && defined(__ARM_NEON) && defined(__ARM_FEATURE_DOTPROD)
|
||||
const block_q8_0x4 * b_ptr = (const block_q8_0x4 *) vx;
|
||||
|
||||
for (int c = 0; c < nc; c += ncols_interleaved) {
|
||||
const block_q8_0 * a_ptr = (const block_q8_0 *) vy;
|
||||
float32x4_t acc = vdupq_n_f32(0);
|
||||
for (int b = 0; b < nb; b++) {
|
||||
int8x16x4_t b_low = vld1q_s8_x4((const int8_t *) b_ptr->qs);
|
||||
int8x16x4_t b_high = vld1q_s8_x4((const int8_t *) b_ptr->qs + 64);
|
||||
float16x4_t bd = vld1_f16((const __fp16 *) b_ptr->d);
|
||||
|
||||
int8x16x2_t a = vld1q_s8_x2(a_ptr->qs);
|
||||
float16x4_t ad = vld1_dup_f16((const __fp16 *) &a_ptr->d);
|
||||
|
||||
int32x4_t ret = vdupq_n_s32(0);
|
||||
|
||||
ret = vdotq_laneq_s32(ret, b_low.val[0], a.val[0], 0);
|
||||
ret = vdotq_laneq_s32(ret, b_low.val[1], a.val[0], 1);
|
||||
ret = vdotq_laneq_s32(ret, b_low.val[2], a.val[0], 2);
|
||||
ret = vdotq_laneq_s32(ret, b_low.val[3], a.val[0], 3);
|
||||
|
||||
ret = vdotq_laneq_s32(ret, b_high.val[0], a.val[1], 0);
|
||||
ret = vdotq_laneq_s32(ret, b_high.val[1], a.val[1], 1);
|
||||
ret = vdotq_laneq_s32(ret, b_high.val[2], a.val[1], 2);
|
||||
ret = vdotq_laneq_s32(ret, b_high.val[3], a.val[1], 3);
|
||||
|
||||
acc = vfmaq_f32(acc, vcvtq_f32_s32(ret), vmulq_f32(vcvt_f32_f16(ad), vcvt_f32_f16(bd)));
|
||||
a_ptr++;
|
||||
b_ptr++;
|
||||
}
|
||||
vst1q_f32(s, acc);
|
||||
s += ncols_interleaved;
|
||||
}
|
||||
return;
|
||||
|
||||
#endif // defined(__aarch64__) && defined(__ARM_NEON) && defined(__ARM_FEATURE_DOTPROD)
|
||||
ggml_gemv_q8_0_4x4_q8_0_generic(n, s, bs, vx, vy, nr, nc);
|
||||
}
|
||||
|
||||
void ggml_gemv_q8_0_4x8_q8_0(int n,
|
||||
float * GGML_RESTRICT s,
|
||||
size_t bs,
|
||||
const void * GGML_RESTRICT vx,
|
||||
const void * GGML_RESTRICT vy,
|
||||
int nr,
|
||||
int nc) {
|
||||
const int qk = QK8_0;
|
||||
const int nb = n / qk;
|
||||
const int ncols_interleaved = 4;
|
||||
const int blocklen = 8;
|
||||
|
||||
assert(n % qk == 0);
|
||||
assert(nc % ncols_interleaved == 0);
|
||||
|
||||
UNUSED(nb);
|
||||
UNUSED(ncols_interleaved);
|
||||
UNUSED(blocklen);
|
||||
|
||||
#if defined(__aarch64__) && defined(__ARM_NEON) && defined(__ARM_FEATURE_DOTPROD)
|
||||
const block_q8_0x4 * b_ptr = (const block_q8_0x4 *) vx;
|
||||
|
||||
for (int c = 0; c < nc; c += ncols_interleaved) {
|
||||
const block_q8_0 * a_ptr = (const block_q8_0 *) vy;
|
||||
float32x4_t acc = vdupq_n_f32(0);
|
||||
|
||||
for (int b = 0; b < nb; b++) {
|
||||
int8x16x4_t b_low = vld1q_s8_x4((const int8_t *) b_ptr->qs);
|
||||
int8x16x4_t b_high = vld1q_s8_x4((const int8_t *) b_ptr->qs + 64);
|
||||
float16x4_t bd = vld1_f16((const __fp16 *) b_ptr->d);
|
||||
|
||||
int8x8x4_t a_chunks = vld1_s8_x4(a_ptr->qs);
|
||||
int8x16_t a0 = vcombine_s8(a_chunks.val[0], a_chunks.val[0]);
|
||||
int8x16_t a1 = vcombine_s8(a_chunks.val[1], a_chunks.val[1]);
|
||||
int8x16_t a2 = vcombine_s8(a_chunks.val[2], a_chunks.val[2]);
|
||||
int8x16_t a3 = vcombine_s8(a_chunks.val[3], a_chunks.val[3]);
|
||||
float16x4_t ad = vld1_dup_f16((const __fp16 *) &a_ptr->d);
|
||||
|
||||
int32x4_t ret0 = vdupq_n_s32(0);
|
||||
int32x4_t ret1 = vdupq_n_s32(0);
|
||||
|
||||
// 0..7
|
||||
ret0 = vdotq_s32(ret0, b_low.val[0], a0);
|
||||
ret1 = vdotq_s32(ret1, b_low.val[1], a0);
|
||||
// 8..15
|
||||
ret0 = vdotq_s32(ret0, b_low.val[2], a1);
|
||||
ret1 = vdotq_s32(ret1, b_low.val[3], a1);
|
||||
// 16..23
|
||||
ret0 = vdotq_s32(ret0, b_high.val[0], a2);
|
||||
ret1 = vdotq_s32(ret1, b_high.val[1], a2);
|
||||
// 24..31
|
||||
ret0 = vdotq_s32(ret0, b_high.val[2], a3);
|
||||
ret1 = vdotq_s32(ret1, b_high.val[3], a3);
|
||||
|
||||
int32x4_t ret = vpaddq_s32(ret0, ret1);
|
||||
|
||||
acc = vfmaq_f32(acc, vcvtq_f32_s32(ret), vmulq_f32(vcvt_f32_f16(ad), vcvt_f32_f16(bd)));
|
||||
a_ptr++;
|
||||
b_ptr++;
|
||||
}
|
||||
vst1q_f32(s, acc);
|
||||
s += ncols_interleaved;
|
||||
}
|
||||
return;
|
||||
|
||||
#endif // defined(__aarch64__) && defined(__ARM_NEON) && defined(__ARM_FEATURE_DOTPROD)
|
||||
ggml_gemv_q8_0_4x8_q8_0_generic(n, s, bs, vx, vy, nr, nc);
|
||||
}
|
||||
|
||||
void ggml_gemm_q4_0_4x4_q8_0(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc) {
|
||||
const int qk = QK8_0;
|
||||
const int nb = n / qk;
|
||||
|
|
@ -2610,3 +2737,159 @@ void ggml_gemm_q4_K_8x8_q8_K(int n,
|
|||
#endif // defined(__aarch64__) && defined(__ARM_NEON) && defined(__ARM_FEATURE_MATMUL_INT8)
|
||||
ggml_gemm_q4_K_8x8_q8_K_generic(n, s, bs, vx, vy, nr, nc);
|
||||
}
|
||||
|
||||
|
||||
void ggml_gemm_q8_0_4x4_q8_0(int n,
|
||||
float * GGML_RESTRICT s,
|
||||
size_t bs,
|
||||
const void * GGML_RESTRICT vx,
|
||||
const void * GGML_RESTRICT vy,
|
||||
int nr,
|
||||
int nc) {
|
||||
const int qk = QK8_0;
|
||||
const int nb = n / qk;
|
||||
const int ncols_interleaved = 4;
|
||||
const int blocklen = 4;
|
||||
|
||||
assert(n % qk == 0);
|
||||
assert(nr % 4 == 0);
|
||||
assert(nc % ncols_interleaved == 0);
|
||||
|
||||
UNUSED(nb);
|
||||
UNUSED(ncols_interleaved);
|
||||
UNUSED(blocklen);
|
||||
|
||||
#if defined(__aarch64__) && defined(__ARM_NEON) && defined(__ARM_FEATURE_DOTPROD)
|
||||
for (int y = 0; y < nr / 4; y++) {
|
||||
const block_q8_0x4 * a_ptr = (const block_q8_0x4 *) vy + (y * nb);
|
||||
for (int x = 0; x < nc / ncols_interleaved; x++) {
|
||||
const block_q8_0x4 * b_ptr = (const block_q8_0x4 *) vx + (x * nb);
|
||||
|
||||
float32x4_t sumf[4];
|
||||
for (int m = 0; m < 4; m++) {
|
||||
sumf[m] = vdupq_n_f32(0);
|
||||
}
|
||||
|
||||
for (int l = 0; l < nb; l++) {
|
||||
float32x4_t a_d = vcvt_f32_f16(vld1_f16((const float16_t *) a_ptr[l].d));
|
||||
float32x4_t b_d = vcvt_f32_f16(vld1_f16((const float16_t *) b_ptr[l].d));
|
||||
|
||||
int32x4_t sumi_0 = vdupq_n_s32(0);
|
||||
int32x4_t sumi_1 = vdupq_n_s32(0);
|
||||
int32x4_t sumi_2 = vdupq_n_s32(0);
|
||||
int32x4_t sumi_3 = vdupq_n_s32(0);
|
||||
|
||||
for (int k_group = 0; k_group < 8; k_group += 4) {
|
||||
int8x16x4_t a = vld1q_s8_x4(a_ptr[l].qs + 16 * k_group);
|
||||
int8x16x4_t b = vld1q_s8_x4(b_ptr[l].qs + 16 * k_group);
|
||||
|
||||
for (int k = 0; k < 4; k++) {
|
||||
sumi_0 = vdotq_laneq_s32(sumi_0, b.val[k], a.val[k], 0);
|
||||
sumi_1 = vdotq_laneq_s32(sumi_1, b.val[k], a.val[k], 1);
|
||||
sumi_2 = vdotq_laneq_s32(sumi_2, b.val[k], a.val[k], 2);
|
||||
sumi_3 = vdotq_laneq_s32(sumi_3, b.val[k], a.val[k], 3);
|
||||
}
|
||||
}
|
||||
|
||||
sumf[0] = vmlaq_f32(sumf[0], vmulq_laneq_f32(b_d, a_d, 0), vcvtq_f32_s32(sumi_0));
|
||||
sumf[1] = vmlaq_f32(sumf[1], vmulq_laneq_f32(b_d, a_d, 1), vcvtq_f32_s32(sumi_1));
|
||||
sumf[2] = vmlaq_f32(sumf[2], vmulq_laneq_f32(b_d, a_d, 2), vcvtq_f32_s32(sumi_2));
|
||||
sumf[3] = vmlaq_f32(sumf[3], vmulq_laneq_f32(b_d, a_d, 3), vcvtq_f32_s32(sumi_3));
|
||||
}
|
||||
|
||||
for (int m = 0; m < 4; m++) {
|
||||
vst1q_f32(s + (y * 4 + m) * bs + x * 4, sumf[m]);
|
||||
}
|
||||
}
|
||||
}
|
||||
return;
|
||||
#endif // defined(__aarch64__) && defined(__ARM_NEON) && defined(__ARM_FEATURE_DOTPROD)
|
||||
ggml_gemm_q8_0_4x4_q8_0_generic(n, s, bs, vx, vy, nr, nc);
|
||||
}
|
||||
|
||||
void ggml_gemm_q8_0_4x8_q8_0(int n,
|
||||
float * GGML_RESTRICT s,
|
||||
size_t bs,
|
||||
const void * GGML_RESTRICT vx,
|
||||
const void * GGML_RESTRICT vy,
|
||||
int nr,
|
||||
int nc) {
|
||||
const int qk = QK8_0;
|
||||
const int nb = n / qk;
|
||||
const int ncols_interleaved = 4;
|
||||
const int blocklen = 8;
|
||||
|
||||
assert(n % qk == 0);
|
||||
assert(nr % 4 == 0);
|
||||
assert(nc % ncols_interleaved == 0);
|
||||
|
||||
UNUSED(nb);
|
||||
UNUSED(ncols_interleaved);
|
||||
UNUSED(blocklen);
|
||||
|
||||
#if defined(__aarch64__) && defined(__ARM_NEON) && defined(__ARM_FEATURE_MATMUL_INT8)
|
||||
const block_q8_0x4 * b_ptr_base = (const block_q8_0x4 *) vx;
|
||||
|
||||
for (int y = 0; y < nr; y += 4) {
|
||||
const block_q8_0x4 * a_ptr_base = (const block_q8_0x4 *) vy + (y / 4) * nb;
|
||||
|
||||
for (int x = 0; x < nc; x += ncols_interleaved) {
|
||||
const block_q8_0x4 * b_ptr = b_ptr_base + (x / 4) * nb;
|
||||
const block_q8_0x4 * a_ptr = a_ptr_base;
|
||||
|
||||
float32x4_t acc_f32[4];
|
||||
for (int i = 0; i < 4; i++) {
|
||||
acc_f32[i] = vdupq_n_f32(0);
|
||||
}
|
||||
|
||||
for (int b = 0; b < nb; b++) {
|
||||
int32x4_t acc[4];
|
||||
for (int i = 0; i < 4; i++) {
|
||||
acc[i] = vdupq_n_s32(0);
|
||||
}
|
||||
|
||||
// Process 4 chunks of 8 positions each
|
||||
for (int chunk = 0; chunk < 4; chunk++) {
|
||||
int8x16_t a01 = vld1q_s8(a_ptr->qs + chunk * 32);
|
||||
int8x16_t a23 = vld1q_s8(a_ptr->qs + chunk * 32 + 16);
|
||||
int8x16_t b01 = vld1q_s8(b_ptr->qs + chunk * 32);
|
||||
int8x16_t b23 = vld1q_s8(b_ptr->qs + chunk * 32 + 16);
|
||||
|
||||
acc[0] = vmmlaq_s32(acc[0], a01, b01);
|
||||
acc[1] = vmmlaq_s32(acc[1], a01, b23);
|
||||
acc[2] = vmmlaq_s32(acc[2], a23, b01);
|
||||
acc[3] = vmmlaq_s32(acc[3], a23, b23);
|
||||
}
|
||||
|
||||
// Reorder outputs from 2×2 tiles to row-major
|
||||
// acc[0] = [r0c0, r0c1, r1c0, r1c1]
|
||||
// acc[1] = [r0c2, r0c3, r1c2, r1c3]
|
||||
// acc[2] = [r2c0, r2c1, r3c0, r3c1]
|
||||
// acc[3] = [r2c2, r2c3, r3c2, r3c3]
|
||||
int32x4_t row0 = vcombine_s32(vget_low_s32(acc[0]), vget_low_s32(acc[1]));
|
||||
int32x4_t row1 = vcombine_s32(vget_high_s32(acc[0]), vget_high_s32(acc[1]));
|
||||
int32x4_t row2 = vcombine_s32(vget_low_s32(acc[2]), vget_low_s32(acc[3]));
|
||||
int32x4_t row3 = vcombine_s32(vget_high_s32(acc[2]), vget_high_s32(acc[3]));
|
||||
|
||||
// Scales
|
||||
float32x4_t a_d = vcvt_f32_f16(vld1_f16((const __fp16 *) a_ptr->d));
|
||||
float32x4_t b_d = vcvt_f32_f16(vld1_f16((const __fp16 *) b_ptr->d));
|
||||
|
||||
acc_f32[0] = vfmaq_f32(acc_f32[0], vcvtq_f32_s32(row0), vmulq_laneq_f32(b_d, a_d, 0));
|
||||
acc_f32[1] = vfmaq_f32(acc_f32[1], vcvtq_f32_s32(row1), vmulq_laneq_f32(b_d, a_d, 1));
|
||||
acc_f32[2] = vfmaq_f32(acc_f32[2], vcvtq_f32_s32(row2), vmulq_laneq_f32(b_d, a_d, 2));
|
||||
acc_f32[3] = vfmaq_f32(acc_f32[3], vcvtq_f32_s32(row3), vmulq_laneq_f32(b_d, a_d, 3));
|
||||
|
||||
a_ptr++;
|
||||
b_ptr++;
|
||||
}
|
||||
|
||||
for (int row = 0; row < 4; row++) {
|
||||
vst1q_f32(s + (y + row) * bs + x, acc_f32[row]);
|
||||
}
|
||||
}
|
||||
}
|
||||
return;
|
||||
#endif // defined(__aarch64__) && defined(__ARM_NEON) && defined(__ARM_FEATURE_MATMUL_INT8)
|
||||
ggml_gemm_q8_0_4x8_q8_0_generic(n, s, bs, vx, vy, nr, nc);
|
||||
}
|
||||
|
|
|
|||
|
|
@ -3320,13 +3320,33 @@ void ggml_cpu_fp16_to_fp32(const ggml_fp16_t * x, float * y, int64_t n) {
|
|||
__m128 y_vec = _mm_cvtph_ps(x_vec);
|
||||
_mm_storeu_ps(y + i, y_vec);
|
||||
}
|
||||
#elif defined(__riscv_zvfh)
|
||||
for (int vl; i < n; i += vl) {
|
||||
vl = __riscv_vsetvl_e16m1(n - i);
|
||||
vfloat16m1_t vx = __riscv_vle16_v_f16m1((_Float16 *)&x[i], vl);
|
||||
vfloat32m2_t vy = __riscv_vfwcvt_f_f_v_f32m2(vx, vl);
|
||||
__riscv_vse32_v_f32m2(&y[i], vy, vl);
|
||||
|
||||
#elif defined(__riscv_v_intrinsic) && defined(__riscv_zvfhmin)
|
||||
// calculate step size
|
||||
const int epr = __riscv_vsetvlmax_e16m2();
|
||||
const int step = epr * 2;
|
||||
const int np = (n & ~(step - 1));
|
||||
|
||||
// unroll by 2
|
||||
for (; i < np; i += step) {
|
||||
vfloat16m2_t ax0 = __riscv_vle16_v_f16m2((const _Float16*)x + i, epr);
|
||||
vfloat32m4_t ay0 = __riscv_vfwcvt_f_f_v_f32m4(ax0, epr);
|
||||
__riscv_vse32_v_f32m4(y + i, ay0, epr);
|
||||
|
||||
vfloat16m2_t ax1 = __riscv_vle16_v_f16m2((const _Float16*)x + i + epr, epr);
|
||||
vfloat32m4_t ay1 = __riscv_vfwcvt_f_f_v_f32m4(ax1, epr);
|
||||
__riscv_vse32_v_f32m4(y + i + epr, ay1, epr);
|
||||
}
|
||||
|
||||
// leftovers
|
||||
int vl;
|
||||
for (i = np; i < n; i += vl) {
|
||||
vl = __riscv_vsetvl_e16m2(n - i);
|
||||
vfloat16m2_t ax0 = __riscv_vle16_v_f16m2((const _Float16*)x + i, vl);
|
||||
vfloat32m4_t ay0 = __riscv_vfwcvt_f_f_v_f32m4(ax0, vl);
|
||||
__riscv_vse32_v_f32m4(y + i, ay0, vl);
|
||||
}
|
||||
|
||||
#endif
|
||||
|
||||
for (; i < n; ++i) {
|
||||
|
|
@ -3371,6 +3391,31 @@ void ggml_cpu_bf16_to_fp32(const ggml_bf16_t * x, float * y, int64_t n) {
|
|||
(const __m128i *)(x + i))),
|
||||
16)));
|
||||
}
|
||||
#elif defined(__riscv_v_intrinsic) && defined(__riscv_zvfbfmin)
|
||||
// calculate step size
|
||||
const int epr = __riscv_vsetvlmax_e16m2();
|
||||
const int step = epr * 2;
|
||||
const int np = (n & ~(step - 1));
|
||||
|
||||
// unroll by 2
|
||||
for (; i < np; i += step) {
|
||||
vbfloat16m2_t ax0 = __riscv_vle16_v_bf16m2((const __bf16*)x + i, epr);
|
||||
vfloat32m4_t ay0 = __riscv_vfwcvtbf16_f_f_v_f32m4(ax0, epr);
|
||||
__riscv_vse32_v_f32m4(y + i, ay0, epr);
|
||||
|
||||
vbfloat16m2_t ax1 = __riscv_vle16_v_bf16m2((const __bf16*)x + i + epr, epr);
|
||||
vfloat32m4_t ay1 = __riscv_vfwcvtbf16_f_f_v_f32m4(ax1, epr);
|
||||
__riscv_vse32_v_f32m4(y + i + epr, ay1, epr);
|
||||
}
|
||||
|
||||
// leftovers
|
||||
int vl;
|
||||
for (i = np; i < n; i += vl) {
|
||||
vl = __riscv_vsetvl_e16m2(n - i);
|
||||
vbfloat16m2_t ax0 = __riscv_vle16_v_bf16m2((const __bf16*)x + i, vl);
|
||||
vfloat32m4_t ay0 = __riscv_vfwcvtbf16_f_f_v_f32m4(ax0, vl);
|
||||
__riscv_vse32_v_f32m4(y + i, ay0, vl);
|
||||
}
|
||||
#endif
|
||||
for (; i < n; i++) {
|
||||
y[i] = GGML_BF16_TO_FP32(x[i]);
|
||||
|
|
|
|||
|
|
@ -692,6 +692,100 @@ void ggml_gemv_iq4_nl_8x8_q8_0_generic(int n, float * GGML_RESTRICT s, size_t bs
|
|||
}
|
||||
}
|
||||
|
||||
void ggml_gemv_q8_0_4x4_q8_0_generic(int n,
|
||||
float * GGML_RESTRICT s,
|
||||
size_t bs,
|
||||
const void * GGML_RESTRICT vx,
|
||||
const void * GGML_RESTRICT vy,
|
||||
int nr,
|
||||
int nc) {
|
||||
const int qk = QK8_0;
|
||||
const int nb = n / qk;
|
||||
const int ncols_interleaved = 4;
|
||||
const int blocklen = 4;
|
||||
|
||||
assert(nr == 1);
|
||||
assert(n % qk == 0);
|
||||
assert(nc % ncols_interleaved == 0);
|
||||
|
||||
UNUSED(bs);
|
||||
UNUSED(nr);
|
||||
|
||||
float sumf[4];
|
||||
int sumi;
|
||||
|
||||
const block_q8_0 * a_ptr = (const block_q8_0 *) vy;
|
||||
for (int x = 0; x < nc / ncols_interleaved; x++) {
|
||||
const block_q8_0x4 * b_ptr = (const block_q8_0x4 *) vx + (x * nb);
|
||||
|
||||
for (int j = 0; j < ncols_interleaved; j++) {
|
||||
sumf[j] = 0.0;
|
||||
}
|
||||
for (int l = 0; l < nb; l++) {
|
||||
for (int k = 0; k < (qk / blocklen); k++) {
|
||||
for (int j = 0; j < ncols_interleaved; j++) {
|
||||
sumi = 0;
|
||||
for (int i = 0; i < blocklen; ++i) {
|
||||
const int v0 = b_ptr[l].qs[k * ncols_interleaved * blocklen + j * blocklen + i];
|
||||
sumi += v0 * a_ptr[l].qs[k * blocklen + i];
|
||||
}
|
||||
sumf[j] += sumi * GGML_CPU_FP16_TO_FP32(b_ptr[l].d[j]) * GGML_CPU_FP16_TO_FP32(a_ptr[l].d);
|
||||
}
|
||||
}
|
||||
}
|
||||
for (int j = 0; j < ncols_interleaved; j++) {
|
||||
s[x * ncols_interleaved + j] = sumf[j];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void ggml_gemv_q8_0_4x8_q8_0_generic(int n,
|
||||
float * GGML_RESTRICT s,
|
||||
size_t bs,
|
||||
const void * GGML_RESTRICT vx,
|
||||
const void * GGML_RESTRICT vy,
|
||||
int nr,
|
||||
int nc) {
|
||||
const int qk = QK8_0;
|
||||
const int nb = n / qk;
|
||||
const int ncols_interleaved = 4;
|
||||
const int blocklen = 8;
|
||||
|
||||
assert(nr == 1);
|
||||
assert(n % qk == 0);
|
||||
assert(nc % ncols_interleaved == 0);
|
||||
|
||||
UNUSED(bs);
|
||||
UNUSED(nr);
|
||||
|
||||
float sumf[4];
|
||||
int sumi;
|
||||
|
||||
const block_q8_0 * a_ptr = (const block_q8_0 *) vy;
|
||||
for (int x = 0; x < nc / ncols_interleaved; x++) {
|
||||
const block_q8_0x4 * b_ptr = (const block_q8_0x4 *) vx + (x * nb);
|
||||
|
||||
for (int j = 0; j < ncols_interleaved; j++) {
|
||||
sumf[j] = 0.0;
|
||||
}
|
||||
for (int l = 0; l < nb; l++) {
|
||||
for (int k = 0; k < (qk / blocklen); k++) {
|
||||
for (int j = 0; j < ncols_interleaved; j++) {
|
||||
sumi = 0;
|
||||
for (int i = 0; i < blocklen; ++i) {
|
||||
const int v0 = b_ptr[l].qs[k * ncols_interleaved * blocklen + j * blocklen + i];
|
||||
sumi += v0 * a_ptr[l].qs[k * blocklen + i];
|
||||
}
|
||||
sumf[j] += sumi * GGML_CPU_FP16_TO_FP32(b_ptr[l].d[j]) * GGML_CPU_FP16_TO_FP32(a_ptr[l].d);
|
||||
}
|
||||
}
|
||||
}
|
||||
for (int j = 0; j < ncols_interleaved; j++) {
|
||||
s[x * ncols_interleaved + j] = sumf[j];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void ggml_gemm_q4_0_4x4_q8_0_generic(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc) {
|
||||
const int qk = QK8_0;
|
||||
const int nb = n / qk;
|
||||
|
|
@ -1219,8 +1313,129 @@ void ggml_gemm_iq4_nl_8x8_q8_0_generic(int n, float * GGML_RESTRICT s, size_t bs
|
|||
}
|
||||
}
|
||||
|
||||
void ggml_gemm_q8_0_4x4_q8_0_generic(int n,
|
||||
float * GGML_RESTRICT s,
|
||||
size_t bs,
|
||||
const void * GGML_RESTRICT vx,
|
||||
const void * GGML_RESTRICT vy,
|
||||
int nr,
|
||||
int nc) {
|
||||
const int qk = QK8_0;
|
||||
const int nb = n / qk;
|
||||
const int ncols_interleaved = 4;
|
||||
const int blocklen = 4;
|
||||
|
||||
assert(n % qk == 0);
|
||||
assert(nr % 4 == 0);
|
||||
assert(nc % ncols_interleaved == 0);
|
||||
|
||||
float sumf[4][4];
|
||||
int sumi;
|
||||
|
||||
for (int y = 0; y < nr / 4; y++) {
|
||||
const block_q8_0x4 * a_ptr = (const block_q8_0x4 *) vy + (y * nb);
|
||||
for (int x = 0; x < nc / ncols_interleaved; x++) {
|
||||
const block_q8_0x4 * b_ptr = (const block_q8_0x4 *) vx + (x * nb);
|
||||
for (int m = 0; m < 4; m++) {
|
||||
for (int j = 0; j < ncols_interleaved; j++) {
|
||||
sumf[m][j] = 0.0;
|
||||
}
|
||||
}
|
||||
for (int l = 0; l < nb; l++) {
|
||||
for (int k = 0; k < (qk / blocklen); k++) {
|
||||
for (int m = 0; m < 4; m++) {
|
||||
for (int j = 0; j < ncols_interleaved; j++) {
|
||||
sumi = 0;
|
||||
for (int i = 0; i < blocklen; ++i) {
|
||||
const int v0 = b_ptr[l].qs[k * ncols_interleaved * blocklen + j * blocklen + i];
|
||||
sumi += v0 * a_ptr[l].qs[k * 4 * blocklen + m * blocklen + i];
|
||||
}
|
||||
sumf[m][j] +=
|
||||
sumi * GGML_CPU_FP16_TO_FP32(b_ptr[l].d[j]) * GGML_CPU_FP16_TO_FP32(a_ptr[l].d[m]);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
for (int m = 0; m < 4; m++) {
|
||||
for (int j = 0; j < ncols_interleaved; j++) {
|
||||
s[(y * 4 + m) * bs + x * ncols_interleaved + j] = sumf[m][j];
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void ggml_gemm_q8_0_4x8_q8_0_generic(int n,
|
||||
float * GGML_RESTRICT s,
|
||||
size_t bs,
|
||||
const void * GGML_RESTRICT vx,
|
||||
const void * GGML_RESTRICT vy,
|
||||
int nr,
|
||||
int nc) {
|
||||
const int qk = QK8_0;
|
||||
const int nb = n / qk;
|
||||
const int ncols_interleaved = 4;
|
||||
const int blocklen = 8;
|
||||
|
||||
assert(n % qk == 0);
|
||||
assert(nr % 4 == 0);
|
||||
assert(nc % ncols_interleaved == 0);
|
||||
|
||||
float sumf[4][4];
|
||||
int sumi;
|
||||
|
||||
for (int y = 0; y < nr / 4; y++) {
|
||||
const block_q8_0x4 * a_ptr = (const block_q8_0x4 *) vy + (y * nb);
|
||||
for (int x = 0; x < nc / ncols_interleaved; x++) {
|
||||
const block_q8_0x4 * b_ptr = (const block_q8_0x4 *) vx + (x * nb);
|
||||
for (int m = 0; m < 4; m++) {
|
||||
for (int j = 0; j < ncols_interleaved; j++) {
|
||||
sumf[m][j] = 0.0;
|
||||
}
|
||||
}
|
||||
for (int l = 0; l < nb; l++) {
|
||||
for (int k = 0; k < (qk / blocklen); k++) {
|
||||
for (int m = 0; m < 4; m++) {
|
||||
for (int j = 0; j < ncols_interleaved; j++) {
|
||||
sumi = 0;
|
||||
for (int i = 0; i < blocklen; ++i) {
|
||||
const int v0 = b_ptr[l].qs[k * ncols_interleaved * blocklen + j * blocklen + i];
|
||||
sumi += v0 * a_ptr[l].qs[k * 4 * blocklen + m * blocklen + i];
|
||||
}
|
||||
sumf[m][j] +=
|
||||
sumi * GGML_CPU_FP16_TO_FP32(b_ptr[l].d[j]) * GGML_CPU_FP16_TO_FP32(a_ptr[l].d[m]);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
for (int m = 0; m < 4; m++) {
|
||||
for (int j = 0; j < ncols_interleaved; j++) {
|
||||
s[(y * 4 + m) * bs + x * ncols_interleaved + j] = sumf[m][j];
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
} // extern "C"
|
||||
|
||||
static block_q8_0x4 make_block_q8_0x4(block_q8_0 * in, unsigned int blck_size_interleave) {
|
||||
block_q8_0x4 out;
|
||||
|
||||
for (int i = 0; i < 4; i++) {
|
||||
out.d[i] = in[i].d;
|
||||
}
|
||||
|
||||
const int end = QK8_0 * 4 / blck_size_interleave;
|
||||
for (int i = 0; i < end; ++i) {
|
||||
int src_id = i % 4;
|
||||
int src_offset = (i / 4) * blck_size_interleave;
|
||||
int dst_offset = i * blck_size_interleave;
|
||||
memcpy(&out.qs[dst_offset], &in[src_id].qs[src_offset], blck_size_interleave);
|
||||
}
|
||||
return out;
|
||||
}
|
||||
|
||||
static block_q4_0x4 make_block_q4_0x4(block_q4_0 * in, unsigned int blck_size_interleave) {
|
||||
block_q4_0x4 out;
|
||||
|
||||
|
|
@ -1534,6 +1749,38 @@ static int repack_q4_0_to_q4_0_8_bl(struct ggml_tensor * t, int interleave_block
|
|||
GGML_UNUSED(data_size);
|
||||
}
|
||||
|
||||
static int repack_q8_0_to_q8_0_4_bl(struct ggml_tensor * t,
|
||||
int interleave_block,
|
||||
const void * GGML_RESTRICT data,
|
||||
size_t data_size) {
|
||||
GGML_ASSERT(t->type == GGML_TYPE_Q8_0);
|
||||
GGML_ASSERT(interleave_block == 4 || interleave_block == 8);
|
||||
constexpr int nrows_interleaved = 4;
|
||||
|
||||
block_q8_0x4 * dst = (block_q8_0x4 *) t->data;
|
||||
const block_q8_0 * src = (const block_q8_0 *) data;
|
||||
block_q8_0 dst_tmp[4];
|
||||
int nrow = ggml_nrows(t);
|
||||
int nblocks = t->ne[0] / QK8_0;
|
||||
|
||||
GGML_ASSERT(data_size == nrow * nblocks * sizeof(block_q8_0));
|
||||
|
||||
if (t->ne[1] % nrows_interleaved != 0 || t->ne[0] % 8 != 0) {
|
||||
return -1;
|
||||
}
|
||||
|
||||
for (int b = 0; b < nrow; b += nrows_interleaved) {
|
||||
for (int64_t x = 0; x < nblocks; x++) {
|
||||
for (int i = 0; i < nrows_interleaved; i++) {
|
||||
dst_tmp[i] = src[x + i * nblocks];
|
||||
}
|
||||
*dst++ = make_block_q8_0x4(dst_tmp, interleave_block);
|
||||
}
|
||||
src += nrows_interleaved * nblocks;
|
||||
}
|
||||
return 0;
|
||||
}
|
||||
|
||||
static block_iq4_nlx4 make_block_iq4_nlx4(block_iq4_nl * in, unsigned int blck_size_interleave) {
|
||||
block_iq4_nlx4 out;
|
||||
|
||||
|
|
@ -1702,6 +1949,14 @@ template <> int repack<block_iq4_nl, 8, 8>(struct ggml_tensor * t, const void *
|
|||
return repack_iq4_nl_to_iq4_nl_8_bl(t, 8, data, data_size);
|
||||
}
|
||||
|
||||
template <> int repack<block_q8_0, 4, 4>(struct ggml_tensor * t, const void * data, size_t data_size) {
|
||||
return repack_q8_0_to_q8_0_4_bl(t, 4, data, data_size);
|
||||
}
|
||||
|
||||
template <> int repack<block_q8_0, 8, 4>(struct ggml_tensor * t, const void * data, size_t data_size) {
|
||||
return repack_q8_0_to_q8_0_4_bl(t, 8, data, data_size);
|
||||
}
|
||||
|
||||
// gemv
|
||||
template <typename BLOC_TYPE, int64_t INTER_SIZE, int64_t NB_COLS, ggml_type PARAM_TYPE>
|
||||
void gemv(int, float *, size_t, const void *, const void *, int, int);
|
||||
|
|
@ -1738,6 +1993,14 @@ template <> void gemv<block_iq4_nl, 8, 8, GGML_TYPE_Q8_0>(int n, float * s, size
|
|||
ggml_gemv_iq4_nl_8x8_q8_0(n, s, bs, vx, vy, nr, nc);
|
||||
}
|
||||
|
||||
template <> void gemv<block_q8_0, 4, 4, GGML_TYPE_Q8_0>(int n, float * s, size_t bs, const void * vx, const void * vy, int nr, int nc) {
|
||||
ggml_gemv_q8_0_4x4_q8_0(n, s, bs, vx, vy, nr, nc);
|
||||
}
|
||||
|
||||
template <> void gemv<block_q8_0, 8, 4, GGML_TYPE_Q8_0>(int n, float * s, size_t bs, const void * vx, const void * vy, int nr, int nc) {
|
||||
ggml_gemv_q8_0_4x8_q8_0(n, s, bs, vx, vy, nr, nc);
|
||||
}
|
||||
|
||||
// gemm
|
||||
template <typename BLOC_TYPE, int64_t INTER_SIZE, int64_t NB_COLS, ggml_type PARAM_TYPE>
|
||||
void gemm(int, float *, size_t, const void *, const void *, int, int);
|
||||
|
|
@ -1774,6 +2037,14 @@ template <> void gemm<block_iq4_nl, 8, 8, GGML_TYPE_Q8_0>(int n, float * s, size
|
|||
ggml_gemm_iq4_nl_8x8_q8_0(n, s, bs, vx, vy, nr, nc);
|
||||
}
|
||||
|
||||
template <> void gemm<block_q8_0, 4, 4, GGML_TYPE_Q8_0>(int n, float * s, size_t bs, const void * vx, const void * vy, int nr, int nc) {
|
||||
ggml_gemm_q8_0_4x4_q8_0(n, s, bs, vx, vy, nr, nc);
|
||||
}
|
||||
|
||||
template <> void gemm<block_q8_0, 8, 4, GGML_TYPE_Q8_0>(int n, float * s, size_t bs, const void * vx, const void * vy, int nr, int nc) {
|
||||
ggml_gemm_q8_0_4x8_q8_0(n, s, bs, vx, vy, nr, nc);
|
||||
}
|
||||
|
||||
class tensor_traits_base : public ggml::cpu::tensor_traits {
|
||||
public:
|
||||
virtual int repack(struct ggml_tensor * t, const void * data, size_t data_size) = 0;
|
||||
|
|
@ -2168,6 +2439,10 @@ static const ggml::cpu::tensor_traits * ggml_repack_get_optimal_repack_type(cons
|
|||
static const ggml::cpu::repack::tensor_traits<block_iq4_nl, 4, 4, GGML_TYPE_Q8_0> iq4_nl_4x4_q8_0;
|
||||
static const ggml::cpu::repack::tensor_traits<block_iq4_nl, 8, 8, GGML_TYPE_Q8_0> iq4_nl_8x8_q8_0;
|
||||
|
||||
// instance for Q8_0
|
||||
static const ggml::cpu::repack::tensor_traits<block_q8_0, 4, 4, GGML_TYPE_Q8_0> q8_0_4x4_q8_0;
|
||||
static const ggml::cpu::repack::tensor_traits<block_q8_0, 8, 4, GGML_TYPE_Q8_0> q8_0_4x8_q8_0;
|
||||
|
||||
if (cur->type == GGML_TYPE_Q4_0) {
|
||||
if (ggml_cpu_has_avx2() || (ggml_cpu_has_sve() && ggml_cpu_has_matmul_int8() && ggml_cpu_get_sve_cnt() == QK8_0)
|
||||
|| (ggml_cpu_has_riscv_v() && (ggml_cpu_get_rvv_vlen() >= QK4_0))) {
|
||||
|
|
@ -2218,6 +2493,17 @@ static const ggml::cpu::tensor_traits * ggml_repack_get_optimal_repack_type(cons
|
|||
return &iq4_nl_4x4_q8_0;
|
||||
}
|
||||
}
|
||||
} else if (cur->type == GGML_TYPE_Q8_0) {
|
||||
if (ggml_cpu_has_neon() && ggml_cpu_has_matmul_int8()) {
|
||||
if (cur->ne[1] % 4 == 0) {
|
||||
return &q8_0_4x8_q8_0;
|
||||
}
|
||||
}
|
||||
if (ggml_cpu_has_neon() && ggml_cpu_has_dotprod()) {
|
||||
if (cur->ne[1] % 4 == 0) {
|
||||
return &q8_0_4x4_q8_0;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
return nullptr;
|
||||
|
|
|
|||
|
|
@ -98,6 +98,10 @@ void ggml_gemm_q4_K_8x8_q8_K(int n, float * GGML_RESTRICT s, size_t bs, const vo
|
|||
void ggml_gemm_q2_K_8x8_q8_K(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc);
|
||||
void ggml_gemm_iq4_nl_4x4_q8_0(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc);
|
||||
void ggml_gemm_iq4_nl_8x8_q8_0(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc);
|
||||
void ggml_gemv_q8_0_4x4_q8_0(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc);
|
||||
void ggml_gemv_q8_0_4x8_q8_0(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc);
|
||||
void ggml_gemm_q8_0_4x4_q8_0(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc);
|
||||
void ggml_gemm_q8_0_4x8_q8_0(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc);
|
||||
|
||||
// Native implementations
|
||||
void ggml_quantize_mat_q8_0_4x4_generic(const float * GGML_RESTRICT x, void * GGML_RESTRICT vy, int64_t k);
|
||||
|
|
@ -120,6 +124,10 @@ void ggml_gemm_q4_K_8x8_q8_K_generic(int n, float * GGML_RESTRICT s, size_t bs,
|
|||
void ggml_gemm_q2_K_8x8_q8_K_generic(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc);
|
||||
void ggml_gemm_iq4_nl_4x4_q8_0_generic(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc);
|
||||
void ggml_gemm_iq4_nl_8x8_q8_0_generic(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc);
|
||||
void ggml_gemv_q8_0_4x4_q8_0_generic(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc);
|
||||
void ggml_gemv_q8_0_4x8_q8_0_generic(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc);
|
||||
void ggml_gemm_q8_0_4x4_q8_0_generic(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc);
|
||||
void ggml_gemm_q8_0_4x8_q8_0_generic(int n, float * GGML_RESTRICT s, size_t bs, const void * GGML_RESTRICT vx, const void * GGML_RESTRICT vy, int nr, int nc);
|
||||
|
||||
#if defined(__cplusplus)
|
||||
} // extern "C"
|
||||
|
|
|
|||
|
|
@ -195,8 +195,48 @@ void ggml_vec_dot_bf16(int n, float * GGML_RESTRICT s, size_t bs, ggml_bf16_t *
|
|||
sumf += (ggml_float)_mm_cvtss_f32(g);
|
||||
|
||||
#undef LOAD
|
||||
#endif
|
||||
#elif defined(__riscv_v_intrinsic) && defined(__riscv_zvfbfwma)
|
||||
size_t vl = __riscv_vsetvlmax_e32m4();
|
||||
|
||||
// initialize accumulators to all zeroes
|
||||
vfloat32m4_t vsum0 = __riscv_vfmv_v_f_f32m4(0.0f, vl);
|
||||
vfloat32m4_t vsum1 = __riscv_vfmv_v_f_f32m4(0.0f, vl);
|
||||
|
||||
// calculate step size
|
||||
const size_t epr = __riscv_vsetvlmax_e16m2();
|
||||
const size_t step = epr * 2;
|
||||
const int np = (n & ~(step - 1));
|
||||
|
||||
// unroll by 2
|
||||
for (; i < np; i += step) {
|
||||
vbfloat16m2_t ax0 = __riscv_vle16_v_bf16m2((const __bf16 *)&x[i], epr);
|
||||
vbfloat16m2_t ay0 = __riscv_vle16_v_bf16m2((const __bf16 *)&y[i], epr);
|
||||
vsum0 = __riscv_vfwmaccbf16_vv_f32m4(vsum0, ax0, ay0, epr);
|
||||
__asm__ __volatile__ ("" ::: "memory");
|
||||
|
||||
vbfloat16m2_t ax1 = __riscv_vle16_v_bf16m2((const __bf16 *)&x[i + epr], epr);
|
||||
vbfloat16m2_t ay1 = __riscv_vle16_v_bf16m2((const __bf16 *)&y[i + epr], epr);
|
||||
vsum1 = __riscv_vfwmaccbf16_vv_f32m4(vsum1, ax1, ay1, epr);
|
||||
__asm__ __volatile__ ("" ::: "memory");
|
||||
}
|
||||
|
||||
// accumulate in 1 register
|
||||
vsum0 = __riscv_vfadd_vv_f32m4(vsum0, vsum1, vl);
|
||||
|
||||
// leftovers
|
||||
for (i = np; i < n; i += vl) {
|
||||
vl = __riscv_vsetvl_e16m2(n - i);
|
||||
vbfloat16m2_t ax0 = __riscv_vle16_v_bf16m2((const __bf16 *)&x[i], vl);
|
||||
vbfloat16m2_t ay0 = __riscv_vle16_v_bf16m2((const __bf16 *)&y[i], vl);
|
||||
vsum0 = __riscv_vfwmaccbf16_vv_f32m4(vsum0, ax0, ay0, vl);
|
||||
}
|
||||
|
||||
// reduce
|
||||
vl = __riscv_vsetvlmax_e32m4();
|
||||
vfloat32m1_t redsum = __riscv_vfredusum_vs_f32m4_f32m1(vsum0, __riscv_vfmv_v_f_f32m1(0.0f, 1), vl);
|
||||
sumf += __riscv_vfmv_f_s_f32m1_f32(redsum);
|
||||
|
||||
#endif
|
||||
for (; i < n; ++i) {
|
||||
sumf += (ggml_float)(GGML_BF16_TO_FP32(x[i]) *
|
||||
GGML_BF16_TO_FP32(y[i]));
|
||||
|
|
|
|||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue