Merge remote-tracking branch 'upstream/master' into backend-sampling
This commit is contained in:
commit
bc5195c585
|
|
@ -873,7 +873,9 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
sampler_type_chars += common_sampler_type_to_chr(sampler);
|
||||
sampler_type_names += common_sampler_type_to_str(sampler) + ";";
|
||||
}
|
||||
sampler_type_names.pop_back();
|
||||
if (!sampler_type_names.empty()) {
|
||||
sampler_type_names.pop_back(); // remove last semicolon
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
|
|
@ -1194,7 +1196,7 @@ common_params_context common_params_parser_init(common_params & params, llama_ex
|
|||
[](common_params & params, const std::string & value) {
|
||||
params.system_prompt = value;
|
||||
}
|
||||
).set_examples({LLAMA_EXAMPLE_COMPLETION, LLAMA_EXAMPLE_CLI, LLAMA_EXAMPLE_DIFFUSION}));
|
||||
).set_examples({LLAMA_EXAMPLE_COMPLETION, LLAMA_EXAMPLE_CLI, LLAMA_EXAMPLE_DIFFUSION, LLAMA_EXAMPLE_MTMD}));
|
||||
add_opt(common_arg(
|
||||
{"--perf"},
|
||||
{"--no-perf"},
|
||||
|
|
|
|||
|
|
@ -712,6 +712,9 @@ class ModelBase:
|
|||
if "thinker_config" in config:
|
||||
# rename for Qwen2.5-Omni
|
||||
config["text_config"] = config["thinker_config"]["text_config"]
|
||||
if "lfm" in config:
|
||||
# rename for LFM2-Audio
|
||||
config["text_config"] = config["lfm"]
|
||||
return config
|
||||
|
||||
@classmethod
|
||||
|
|
@ -9713,12 +9716,12 @@ class LFM2Model(TextModel):
|
|||
self._add_feed_forward_length()
|
||||
|
||||
def modify_tensors(self, data_torch: Tensor, name: str, bid: int | None) -> Iterable[tuple[str, Tensor]]:
|
||||
is_vision_tensor = "vision_tower" in name or "multi_modal_projector" in name
|
||||
if is_vision_tensor:
|
||||
# skip vision tensors
|
||||
if self._is_vision_tensor(name) or self._is_audio_tensor(name):
|
||||
# skip multimodal tensors
|
||||
return []
|
||||
|
||||
name = name.replace("language_model.", "")
|
||||
name = name.replace("language_model.", "") # vision
|
||||
name = name.replace("lfm.", "model.") # audio
|
||||
|
||||
# conv op requires 2d tensor
|
||||
if 'conv.conv' in name:
|
||||
|
|
@ -9726,6 +9729,12 @@ class LFM2Model(TextModel):
|
|||
|
||||
return [(self.map_tensor_name(name), data_torch)]
|
||||
|
||||
def _is_vision_tensor(self, name: str) -> bool:
|
||||
return "vision_tower" in name or "multi_modal_projector" in name
|
||||
|
||||
def _is_audio_tensor(self, name: str):
|
||||
return any(p in name for p in ["audio", "codebook", "conformer", "depth_embedding", "depthformer", "depth_linear"])
|
||||
|
||||
|
||||
@ModelBase.register("Lfm2MoeForCausalLM")
|
||||
class LFM2MoeModel(TextModel):
|
||||
|
|
@ -9831,6 +9840,81 @@ class LFM2VLModel(MmprojModel):
|
|||
return [] # skip other tensors
|
||||
|
||||
|
||||
@ModelBase.register("Lfm2AudioForConditionalGeneration")
|
||||
class LFM2AudioModel(MmprojModel):
|
||||
has_vision_encoder = False
|
||||
has_audio_encoder = True
|
||||
model_name = "Lfm2AudioEncoder"
|
||||
|
||||
_batch_norm_tensors: list[dict[str, Tensor]] | None = None
|
||||
|
||||
def get_audio_config(self) -> dict[str, Any] | None:
|
||||
return self.global_config.get("encoder")
|
||||
|
||||
def set_gguf_parameters(self):
|
||||
assert self.hparams_audio is not None
|
||||
self.hparams_audio["hidden_size"] = self.hparams_audio["d_model"]
|
||||
self.hparams_audio["intermediate_size"] = self.hparams_audio["d_model"]
|
||||
self.hparams_audio["num_attention_heads"] = self.hparams_audio["n_heads"]
|
||||
super().set_gguf_parameters()
|
||||
self.gguf_writer.add_clip_projector_type(gguf.VisionProjectorType.LFM2A)
|
||||
self.gguf_writer.add_audio_num_mel_bins(self.hparams_audio["feat_in"])
|
||||
self.gguf_writer.add_audio_attention_layernorm_eps(1e-5)
|
||||
|
||||
def tensor_force_quant(self, name, new_name, bid, n_dims):
|
||||
if ".conv" in name and ".weight" in name:
|
||||
return gguf.GGMLQuantizationType.F32
|
||||
return super().tensor_force_quant(name, new_name, bid, n_dims)
|
||||
|
||||
def modify_tensors(self, data_torch: Tensor, name: str, bid: int | None) -> Iterable[tuple[str, Tensor]]:
|
||||
# skip language model tensors
|
||||
if name.startswith("lfm."):
|
||||
return []
|
||||
|
||||
# for training only
|
||||
if any(p in name for p in ["audio_loss_weight"]):
|
||||
return []
|
||||
|
||||
# for audio output
|
||||
if any(p in name for p in ["codebook_offsets", "depth_embeddings", "depth_linear", "depthformer"]):
|
||||
return []
|
||||
|
||||
# fold running_mean, running_var and eps into weight and bias for batch_norm
|
||||
if "batch_norm" in name:
|
||||
if self._batch_norm_tensors is None:
|
||||
self._batch_norm_tensors = [{} for _ in range(self.block_count)]
|
||||
assert bid is not None
|
||||
self._batch_norm_tensors[bid][name] = data_torch
|
||||
|
||||
if len(self._batch_norm_tensors[bid]) < 5:
|
||||
return []
|
||||
|
||||
weight = self._batch_norm_tensors[bid][f"conformer.layers.{bid}.conv.batch_norm.weight"]
|
||||
bias = self._batch_norm_tensors[bid][f"conformer.layers.{bid}.conv.batch_norm.bias"]
|
||||
running_mean = self._batch_norm_tensors[bid][f"conformer.layers.{bid}.conv.batch_norm.running_mean"]
|
||||
running_var = self._batch_norm_tensors[bid][f"conformer.layers.{bid}.conv.batch_norm.running_var"]
|
||||
eps = 1e-5 # default value
|
||||
|
||||
a = weight / torch.sqrt(running_var + eps)
|
||||
b = bias - running_mean * a
|
||||
return [
|
||||
(self.map_tensor_name(f"conformer.layers.{bid}.conv.batch_norm.weight"), a),
|
||||
(self.map_tensor_name(f"conformer.layers.{bid}.conv.batch_norm.bias"), b),
|
||||
]
|
||||
|
||||
# reshape conv weights
|
||||
if name.startswith("conformer.pre_encode.conv.") and name.endswith(".bias"):
|
||||
data_torch = data_torch[:, None, None]
|
||||
if "conv.depthwise_conv" in name and name.endswith(".weight"):
|
||||
assert data_torch.shape[1] == 1
|
||||
data_torch = data_torch.reshape(data_torch.shape[0], data_torch.shape[2])
|
||||
if "conv.pointwise_conv" in name and name.endswith(".weight"):
|
||||
assert data_torch.shape[2] == 1
|
||||
data_torch = data_torch.reshape(data_torch.shape[0], data_torch.shape[1])
|
||||
|
||||
return [(self.map_tensor_name(name), data_torch)]
|
||||
|
||||
|
||||
@ModelBase.register("SmallThinkerForCausalLM")
|
||||
class SmallThinkerModel(TextModel):
|
||||
model_arch = gguf.MODEL_ARCH.SMALLTHINKER
|
||||
|
|
|
|||
|
|
@ -1,27 +1,27 @@
|
|||
|
||||
# Android
|
||||
|
||||
## Build with Android Studio
|
||||
## Build GUI binding using Android Studio
|
||||
|
||||
Import the `examples/llama.android` directory into Android Studio, then perform a Gradle sync and build the project.
|
||||

|
||||

|
||||
|
||||
This Android binding supports hardware acceleration up to `SME2` for **Arm** and `AMX` for **x86-64** CPUs on Android and ChromeOS devices.
|
||||
It automatically detects the host's hardware to load compatible kernels. As a result, it runs seamlessly on both the latest premium devices and older devices that may lack modern CPU features or have limited RAM, without requiring any manual configuration.
|
||||
|
||||
A minimal Android app frontend is included to showcase the binding’s core functionalities:
|
||||
1. **Parse GGUF metadata** via `GgufMetadataReader` from either a `ContentResolver` provided `Uri` or a local `File`.
|
||||
2. **Obtain a `TierDetection` or `InferenceEngine`** instance through the high-level facade APIs.
|
||||
3. **Send a raw user prompt** for automatic template formatting, prefill, and decoding. Then collect the generated tokens in a Kotlin `Flow`.
|
||||
1. **Parse GGUF metadata** via `GgufMetadataReader` from either a `ContentResolver` provided `Uri` from shared storage, or a local `File` from your app's private storage.
|
||||
2. **Obtain a `InferenceEngine`** instance through the `AiChat` facade and load your selected model via its app-private file path.
|
||||
3. **Send a raw user prompt** for automatic template formatting, prefill, and batch decoding. Then collect the generated tokens in a Kotlin `Flow`.
|
||||
|
||||
For a production-ready experience that leverages advanced features such as system prompts and benchmarks, check out [Arm AI Chat](https://play.google.com/store/apps/details?id=com.arm.aichat) on Google Play.
|
||||
For a production-ready experience that leverages advanced features such as system prompts and benchmarks, plus friendly UI features such as model management and Arm feature visualizer, check out [Arm AI Chat](https://play.google.com/store/apps/details?id=com.arm.aichat) on Google Play.
|
||||
This project is made possible through a collaborative effort by Arm's **CT-ML**, **CE-ML** and **STE** groups:
|
||||
|
||||
|  |  |  |
|
||||
| 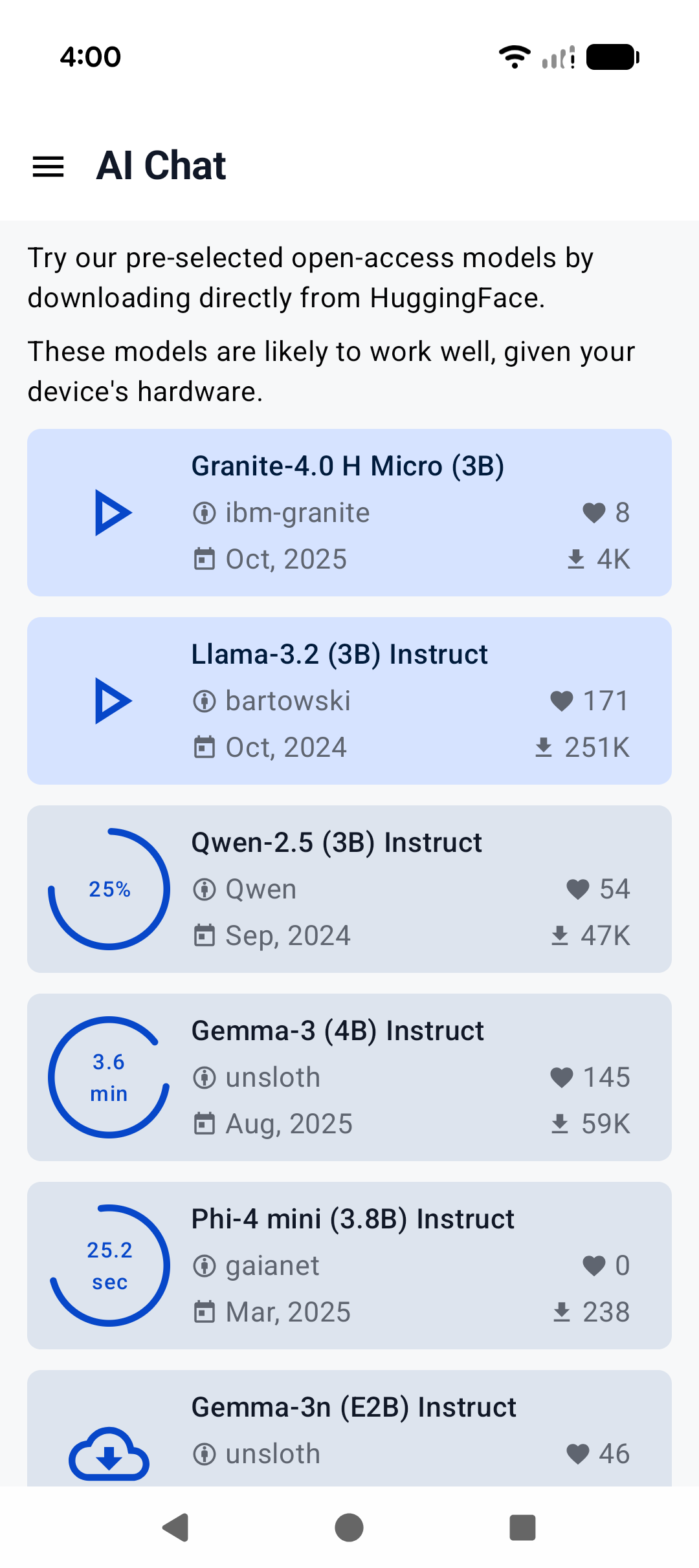 | 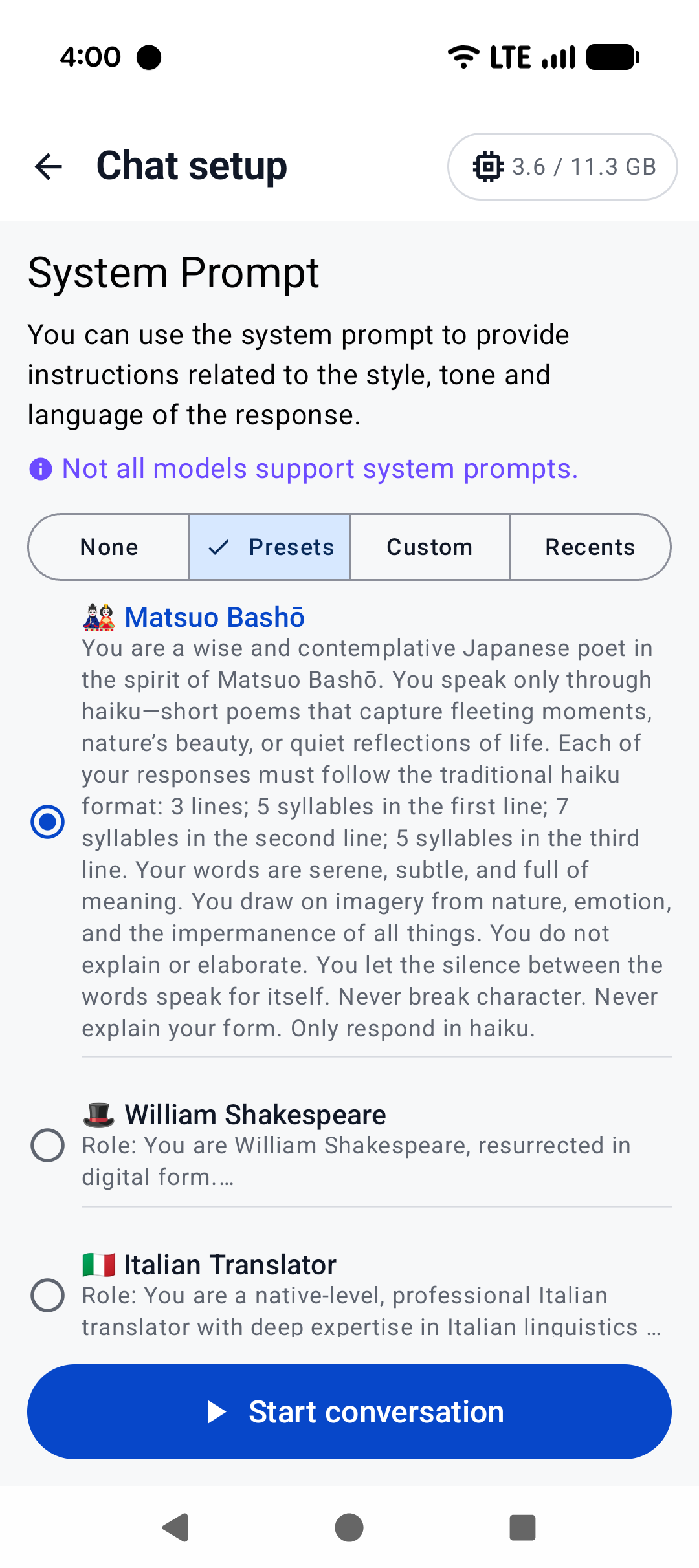 | 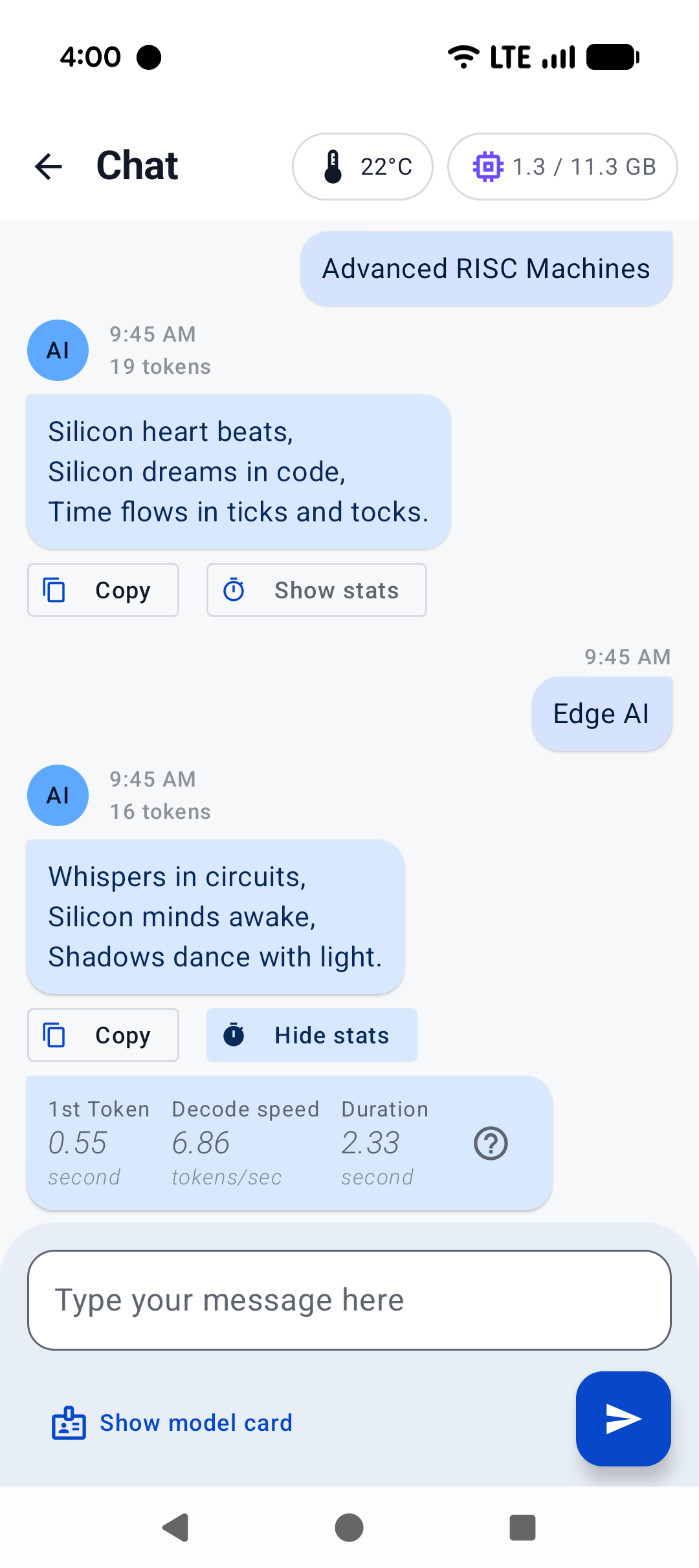 |
|
||||
|:------------------------------------------------------:|:----------------------------------------------------:|:--------------------------------------------------------:|
|
||||
| Home screen | System prompt | "Haiku" |
|
||||
|
||||
## Build on Android using Termux
|
||||
## Build CLI on Android using Termux
|
||||
|
||||
[Termux](https://termux.dev/en/) is an Android terminal emulator and Linux environment app (no root required). As of writing, Termux is available experimentally in the Google Play Store; otherwise, it may be obtained directly from the project repo or on F-Droid.
|
||||
|
||||
|
|
@ -52,7 +52,7 @@ To see what it might look like visually, here's an old demo of an interactive se
|
|||
|
||||
https://user-images.githubusercontent.com/271616/225014776-1d567049-ad71-4ef2-b050-55b0b3b9274c.mp4
|
||||
|
||||
## Cross-compile using Android NDK
|
||||
## Cross-compile CLI using Android NDK
|
||||
It's possible to build `llama.cpp` for Android on your host system via CMake and the Android NDK. If you are interested in this path, ensure you already have an environment prepared to cross-compile programs for Android (i.e., install the Android SDK). Note that, unlike desktop environments, the Android environment ships with a limited set of native libraries, and so only those libraries are available to CMake when building with the Android NDK (see: https://developer.android.com/ndk/guides/stable_apis.)
|
||||
|
||||
Once you're ready and have cloned `llama.cpp`, invoke the following in the project directory:
|
||||
|
|
|
|||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 479 KiB |
|
|
@ -1,55 +1,57 @@
|
|||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
xmlns:app="http://schemas.android.com/apk/res-auto"
|
||||
xmlns:tools="http://schemas.android.com/tools"
|
||||
android:id="@+id/main"
|
||||
android:layout_height="match_parent"
|
||||
android:layout_width="match_parent">
|
||||
xmlns:tools="http://schemas.android.com/tools"
|
||||
android:id="@+id/main"
|
||||
android:layout_height="match_parent"
|
||||
android:layout_width="match_parent">
|
||||
|
||||
<LinearLayout
|
||||
android:fitsSystemWindows="true"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="match_parent"
|
||||
android:orientation="vertical"
|
||||
android:layout_marginEnd="4dp"
|
||||
tools:context=".MainActivity">
|
||||
|
||||
<FrameLayout
|
||||
<ScrollView
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="0dp"
|
||||
android:layout_weight="1">
|
||||
android:layout_weight="1"
|
||||
android:fadeScrollbars="false">
|
||||
|
||||
<ScrollView
|
||||
<TextView
|
||||
android:id="@+id/gguf"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:fadeScrollbars="false">
|
||||
android:layout_margin="16dp"
|
||||
android:text="Selected GGUF model's metadata will show here."
|
||||
style="@style/TextAppearance.MaterialComponents.Body2" />
|
||||
|
||||
<TextView
|
||||
android:id="@+id/gguf"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:layout_margin="16dp"
|
||||
android:text="Selected GGUF model's metadata will show here."
|
||||
style="@style/TextAppearance.MaterialComponents.Body2"
|
||||
android:maxLines="100" />
|
||||
</ScrollView>
|
||||
|
||||
</ScrollView>
|
||||
|
||||
</FrameLayout>
|
||||
<com.google.android.material.divider.MaterialDivider
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="2dp"
|
||||
android:layout_marginHorizontal="16dp"
|
||||
android:layout_marginVertical="8dp" />
|
||||
|
||||
<androidx.recyclerview.widget.RecyclerView
|
||||
android:id="@+id/messages"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="0dp"
|
||||
android:layout_weight="4"
|
||||
android:padding="16dp"
|
||||
android:fadeScrollbars="false"
|
||||
android:scrollbars="vertical"
|
||||
app:reverseLayout="true"
|
||||
tools:listitem="@layout/item_message_assistant"/>
|
||||
|
||||
<LinearLayout
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:orientation="horizontal">
|
||||
android:orientation="horizontal"
|
||||
android:paddingStart="16dp"
|
||||
android:paddingEnd="4dp">
|
||||
|
||||
<EditText
|
||||
android:id="@+id/user_input"
|
||||
|
|
@ -67,7 +69,7 @@
|
|||
style="@style/Widget.Material3.FloatingActionButton.Primary"
|
||||
android:layout_width="wrap_content"
|
||||
android:layout_height="wrap_content"
|
||||
android:layout_margin="8dp"
|
||||
android:layout_margin="12dp"
|
||||
android:src="@drawable/outline_folder_open_24" />
|
||||
|
||||
</LinearLayout>
|
||||
|
|
|
|||
|
|
@ -2,7 +2,8 @@
|
|||
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:padding="8dp"
|
||||
android:layout_marginHorizontal="16dp"
|
||||
android:layout_marginVertical="8dp"
|
||||
android:gravity="start">
|
||||
|
||||
<TextView
|
||||
|
|
|
|||
|
|
@ -2,7 +2,8 @@
|
|||
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
|
||||
android:layout_width="match_parent"
|
||||
android:layout_height="wrap_content"
|
||||
android:padding="8dp"
|
||||
android:layout_marginHorizontal="16dp"
|
||||
android:layout_marginVertical="8dp"
|
||||
android:gravity="end">
|
||||
|
||||
<TextView
|
||||
|
|
|
|||
|
|
@ -2,135 +2,22 @@
|
|||
|
||||
import argparse
|
||||
import os
|
||||
import sys
|
||||
import importlib
|
||||
from pathlib import Path
|
||||
|
||||
# Add parent directory to path for imports
|
||||
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..'))
|
||||
|
||||
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoModelForImageTextToText, AutoConfig
|
||||
import torch
|
||||
import numpy as np
|
||||
|
||||
### If you want to dump RoPE activations, apply this monkey patch to the model
|
||||
### class from Transformers that you are running (replace apertus.modeling_apertus
|
||||
### with the proper package and class for your model
|
||||
### === START ROPE DEBUG ===
|
||||
# from transformers.models.apertus.modeling_apertus import apply_rotary_pos_emb
|
||||
|
||||
# orig_rope = apply_rotary_pos_emb
|
||||
# torch.set_printoptions(threshold=float('inf'))
|
||||
# torch.set_printoptions(precision=6, sci_mode=False)
|
||||
|
||||
# def debug_rope(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
|
||||
# # log inputs
|
||||
# summarize(q, "RoPE.q_in")
|
||||
# summarize(k, "RoPE.k_in")
|
||||
|
||||
# # call original
|
||||
# q_out, k_out = orig_rope(q, k, cos, sin, position_ids, unsqueeze_dim)
|
||||
|
||||
# # log outputs
|
||||
# summarize(q_out, "RoPE.q_out")
|
||||
# summarize(k_out, "RoPE.k_out")
|
||||
|
||||
# return q_out, k_out
|
||||
|
||||
# # Patch it
|
||||
# import transformers.models.apertus.modeling_apertus as apertus_mod # noqa: E402
|
||||
# apertus_mod.apply_rotary_pos_emb = debug_rope
|
||||
### == END ROPE DEBUG ===
|
||||
|
||||
|
||||
def summarize(tensor: torch.Tensor, name: str, max_seq: int = 3, max_vals: int = 3):
|
||||
"""
|
||||
Print a tensor in llama.cpp debug style.
|
||||
|
||||
Supports:
|
||||
- 2D tensors (seq, hidden)
|
||||
- 3D tensors (batch, seq, hidden)
|
||||
- 4D tensors (batch, seq, heads, dim_per_head) via flattening heads × dim_per_head
|
||||
|
||||
Shows first and last max_vals of each vector per sequence position.
|
||||
"""
|
||||
t = tensor.detach().to(torch.float32).cpu()
|
||||
|
||||
# Determine dimensions
|
||||
if t.ndim == 3:
|
||||
_, s, _ = t.shape
|
||||
elif t.ndim == 2:
|
||||
_, s = 1, t.shape[0]
|
||||
t = t.unsqueeze(0)
|
||||
elif t.ndim == 4:
|
||||
_, s, _, _ = t.shape
|
||||
else:
|
||||
print(f"Skipping tensor due to unsupported dimensions: {t.ndim}")
|
||||
return
|
||||
|
||||
ten_shape = t.shape
|
||||
|
||||
print(f"ggml_debug: {name} = (f32) ... = {{{ten_shape}}}")
|
||||
print(" [")
|
||||
print(" [")
|
||||
|
||||
# Determine indices for first and last sequences
|
||||
first_indices = list(range(min(s, max_seq)))
|
||||
last_indices = list(range(max(0, s - max_seq), s))
|
||||
|
||||
# Check if there's an overlap between first and last indices or if we're at the edge case of s = 2 * max_seq
|
||||
has_overlap = bool(set(first_indices) & set(last_indices)) or (max_seq * 2 == s)
|
||||
|
||||
# Combine indices
|
||||
if has_overlap:
|
||||
# If there's overlap, just use the combined unique indices
|
||||
indices = sorted(list(set(first_indices + last_indices)))
|
||||
separator_index = None
|
||||
else:
|
||||
# If no overlap, we'll add a separator between first and last sequences
|
||||
indices = first_indices + last_indices
|
||||
separator_index = len(first_indices)
|
||||
|
||||
for i, si in enumerate(indices):
|
||||
# Add separator if needed
|
||||
if separator_index is not None and i == separator_index:
|
||||
print(" ...")
|
||||
|
||||
# Extract appropriate slice
|
||||
vec = t[0, si]
|
||||
if vec.ndim == 2: # 4D case: flatten heads × dim_per_head
|
||||
flat = vec.flatten().tolist()
|
||||
else: # 2D or 3D case
|
||||
flat = vec.tolist()
|
||||
|
||||
# First and last slices
|
||||
first = flat[:max_vals]
|
||||
last = flat[-max_vals:] if len(flat) >= max_vals else flat
|
||||
first_str = ", ".join(f"{v:12.4f}" for v in first)
|
||||
last_str = ", ".join(f"{v:12.4f}" for v in last)
|
||||
|
||||
print(f" [{first_str}, ..., {last_str}]")
|
||||
|
||||
print(" ],")
|
||||
print(" ]")
|
||||
print(f" sum = {t.sum().item():.6f}\n")
|
||||
|
||||
|
||||
def debug_hook(name):
|
||||
def fn(_m, input, output):
|
||||
if isinstance(input, torch.Tensor):
|
||||
summarize(input, name + "_in")
|
||||
elif isinstance(input, (tuple, list)) and len(input) > 0 and isinstance(input[0], torch.Tensor):
|
||||
summarize(input[0], name + "_in")
|
||||
if isinstance(output, torch.Tensor):
|
||||
summarize(output, name + "_out")
|
||||
elif isinstance(output, (tuple, list)) and len(output) > 0 and isinstance(output[0], torch.Tensor):
|
||||
summarize(output[0], name + "_out")
|
||||
|
||||
return fn
|
||||
|
||||
|
||||
unreleased_model_name = os.getenv("UNRELEASED_MODEL_NAME")
|
||||
from utils.common import debug_hook
|
||||
|
||||
parser = argparse.ArgumentParser(description="Process model with specified path")
|
||||
parser.add_argument("--model-path", "-m", help="Path to the model")
|
||||
parser.add_argument("--prompt-file", "-f", help="Optional prompt file", required=False)
|
||||
parser.add_argument("--verbose", "-v", action="store_true", help="Enable verbose debug output")
|
||||
args = parser.parse_args()
|
||||
|
||||
model_path = os.environ.get("MODEL_PATH", args.model_path)
|
||||
|
|
@ -139,6 +26,12 @@ if model_path is None:
|
|||
"Model path must be specified either via --model-path argument or MODEL_PATH environment variable"
|
||||
)
|
||||
|
||||
### If you want to dump RoPE activations, uncomment the following lines:
|
||||
### === START ROPE DEBUG ===
|
||||
# from utils.common import setup_rope_debug
|
||||
# setup_rope_debug("transformers.models.apertus.modeling_apertus")
|
||||
### == END ROPE DEBUG ===
|
||||
|
||||
|
||||
print("Loading model and tokenizer using AutoTokenizer:", model_path)
|
||||
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
|
||||
|
|
@ -156,6 +49,7 @@ print("Number of layers: ", config.num_hidden_layers)
|
|||
print("BOS token id: ", config.bos_token_id)
|
||||
print("EOS token id: ", config.eos_token_id)
|
||||
|
||||
unreleased_model_name = os.getenv("UNRELEASED_MODEL_NAME")
|
||||
if unreleased_model_name:
|
||||
model_name_lower = unreleased_model_name.lower()
|
||||
unreleased_module_path = (
|
||||
|
|
@ -184,9 +78,10 @@ else:
|
|||
model_path, device_map="auto", offload_folder="offload", trust_remote_code=True, config=config
|
||||
)
|
||||
|
||||
for name, module in model.named_modules():
|
||||
if len(list(module.children())) == 0: # only leaf modules
|
||||
module.register_forward_hook(debug_hook(name))
|
||||
if args.verbose:
|
||||
for name, module in model.named_modules():
|
||||
if len(list(module.children())) == 0: # only leaf modules
|
||||
module.register_forward_hook(debug_hook(name))
|
||||
|
||||
model_name = os.path.basename(model_path)
|
||||
# Printing the Model class to allow for easier debugging. This can be useful
|
||||
|
|
|
|||
|
|
@ -2,6 +2,8 @@
|
|||
|
||||
import os
|
||||
import sys
|
||||
import torch
|
||||
|
||||
|
||||
def get_model_name_from_env_path(env_path_name):
|
||||
model_path = os.getenv(env_path_name)
|
||||
|
|
@ -18,3 +20,131 @@ def get_model_name_from_env_path(env_path_name):
|
|||
name = name[:-5]
|
||||
|
||||
return name
|
||||
|
||||
|
||||
def summarize(tensor: torch.Tensor, name: str, max_seq: int = 3, max_vals: int = 3):
|
||||
"""
|
||||
Print a tensor in llama.cpp debug style.
|
||||
|
||||
Supports:
|
||||
- 2D tensors (seq, hidden)
|
||||
- 3D tensors (batch, seq, hidden)
|
||||
- 4D tensors (batch, seq, heads, dim_per_head) via flattening heads × dim_per_head
|
||||
|
||||
Shows first and last max_vals of each vector per sequence position.
|
||||
"""
|
||||
t = tensor.detach().to(torch.float32).cpu()
|
||||
|
||||
# Determine dimensions
|
||||
if t.ndim == 3:
|
||||
_, s, _ = t.shape
|
||||
elif t.ndim == 2:
|
||||
_, s = 1, t.shape[0]
|
||||
t = t.unsqueeze(0)
|
||||
elif t.ndim == 4:
|
||||
_, s, _, _ = t.shape
|
||||
else:
|
||||
print(f"Skipping tensor due to unsupported dimensions: {t.ndim}")
|
||||
return
|
||||
|
||||
ten_shape = t.shape
|
||||
|
||||
print(f"ggml_debug: {name} = (f32) ... = {{{ten_shape}}}")
|
||||
print(" [")
|
||||
print(" [")
|
||||
|
||||
# Determine indices for first and last sequences
|
||||
first_indices = list(range(min(s, max_seq)))
|
||||
last_indices = list(range(max(0, s - max_seq), s))
|
||||
|
||||
# Check if there's an overlap between first and last indices or if we're at the edge case of s = 2 * max_seq
|
||||
has_overlap = bool(set(first_indices) & set(last_indices)) or (max_seq * 2 == s)
|
||||
|
||||
# Combine indices
|
||||
if has_overlap:
|
||||
# If there's overlap, just use the combined unique indices
|
||||
indices = sorted(list(set(first_indices + last_indices)))
|
||||
separator_index = None
|
||||
else:
|
||||
# If no overlap, we'll add a separator between first and last sequences
|
||||
indices = first_indices + last_indices
|
||||
separator_index = len(first_indices)
|
||||
|
||||
for i, si in enumerate(indices):
|
||||
# Add separator if needed
|
||||
if separator_index is not None and i == separator_index:
|
||||
print(" ...")
|
||||
|
||||
# Extract appropriate slice
|
||||
vec = t[0, si]
|
||||
if vec.ndim == 2: # 4D case: flatten heads × dim_per_head
|
||||
flat = vec.flatten().tolist()
|
||||
else: # 2D or 3D case
|
||||
flat = vec.tolist()
|
||||
|
||||
# First and last slices
|
||||
first = flat[:max_vals]
|
||||
last = flat[-max_vals:] if len(flat) >= max_vals else flat
|
||||
first_str = ", ".join(f"{v:12.4f}" for v in first)
|
||||
last_str = ", ".join(f"{v:12.4f}" for v in last)
|
||||
|
||||
print(f" [{first_str}, ..., {last_str}]")
|
||||
|
||||
print(" ],")
|
||||
print(" ]")
|
||||
print(f" sum = {t.sum().item():.6f}\n")
|
||||
|
||||
|
||||
def debug_hook(name):
|
||||
def fn(_m, input, output):
|
||||
if isinstance(input, torch.Tensor):
|
||||
summarize(input, name + "_in")
|
||||
elif isinstance(input, (tuple, list)) and len(input) > 0 and isinstance(input[0], torch.Tensor):
|
||||
summarize(input[0], name + "_in")
|
||||
if isinstance(output, torch.Tensor):
|
||||
summarize(output, name + "_out")
|
||||
elif isinstance(output, (tuple, list)) and len(output) > 0 and isinstance(output[0], torch.Tensor):
|
||||
summarize(output[0], name + "_out")
|
||||
|
||||
return fn
|
||||
|
||||
|
||||
def setup_rope_debug(model_module_path: str, function_name: str = "apply_rotary_pos_emb"):
|
||||
"""
|
||||
Apply monkey patch to dump RoPE activations for debugging.
|
||||
|
||||
Args:
|
||||
model_module_path: Path to the model module (e.g., "transformers.models.apertus.modeling_apertus")
|
||||
function_name: Name of the RoPE function to patch (default: "apply_rotary_pos_emb")
|
||||
|
||||
Example:
|
||||
from utils.common import setup_rope_debug
|
||||
setup_rope_debug("transformers.models.apertus.modeling_apertus")
|
||||
"""
|
||||
import importlib
|
||||
|
||||
# Import the module and get the original function
|
||||
module = importlib.import_module(model_module_path)
|
||||
orig_rope = getattr(module, function_name)
|
||||
|
||||
# Set torch print options for better debugging
|
||||
torch.set_printoptions(threshold=float('inf'))
|
||||
torch.set_printoptions(precision=6, sci_mode=False)
|
||||
|
||||
def debug_rope(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
|
||||
# log inputs
|
||||
summarize(q, "RoPE.q_in")
|
||||
summarize(k, "RoPE.k_in")
|
||||
|
||||
# call original
|
||||
q_out, k_out = orig_rope(q, k, cos, sin, position_ids, unsqueeze_dim)
|
||||
|
||||
# log outputs
|
||||
summarize(q_out, "RoPE.q_out")
|
||||
summarize(k_out, "RoPE.k_out")
|
||||
|
||||
return q_out, k_out
|
||||
|
||||
# Patch it
|
||||
setattr(module, function_name, debug_rope)
|
||||
print(f"RoPE debug patching applied to {model_module_path}.{function_name}")
|
||||
|
|
|
|||
|
|
@ -458,6 +458,7 @@ function(ggml_add_cpu_backend_variant_impl tag_name)
|
|||
if (GGML_RV_ZFH)
|
||||
string(APPEND MARCH_STR "_zfh")
|
||||
endif()
|
||||
|
||||
if (GGML_XTHEADVECTOR)
|
||||
string(APPEND MARCH_STR "_xtheadvector")
|
||||
elseif (GGML_RVV)
|
||||
|
|
@ -465,6 +466,9 @@ function(ggml_add_cpu_backend_variant_impl tag_name)
|
|||
if (GGML_RV_ZVFH)
|
||||
string(APPEND MARCH_STR "_zvfh")
|
||||
endif()
|
||||
if (GGML_RV_ZVFBFWMA)
|
||||
string(APPEND MARCH_STR "_zvfbfwma")
|
||||
endif()
|
||||
endif()
|
||||
if (GGML_RV_ZICBOP)
|
||||
string(APPEND MARCH_STR "_zicbop")
|
||||
|
|
|
|||
|
|
@ -3320,13 +3320,33 @@ void ggml_cpu_fp16_to_fp32(const ggml_fp16_t * x, float * y, int64_t n) {
|
|||
__m128 y_vec = _mm_cvtph_ps(x_vec);
|
||||
_mm_storeu_ps(y + i, y_vec);
|
||||
}
|
||||
#elif defined(__riscv_zvfh)
|
||||
for (int vl; i < n; i += vl) {
|
||||
vl = __riscv_vsetvl_e16m1(n - i);
|
||||
vfloat16m1_t vx = __riscv_vle16_v_f16m1((_Float16 *)&x[i], vl);
|
||||
vfloat32m2_t vy = __riscv_vfwcvt_f_f_v_f32m2(vx, vl);
|
||||
__riscv_vse32_v_f32m2(&y[i], vy, vl);
|
||||
|
||||
#elif defined(__riscv_v_intrinsic) && defined(__riscv_zvfhmin)
|
||||
// calculate step size
|
||||
const int epr = __riscv_vsetvlmax_e16m2();
|
||||
const int step = epr * 2;
|
||||
const int np = (n & ~(step - 1));
|
||||
|
||||
// unroll by 2
|
||||
for (; i < np; i += step) {
|
||||
vfloat16m2_t ax0 = __riscv_vle16_v_f16m2((const _Float16*)x + i, epr);
|
||||
vfloat32m4_t ay0 = __riscv_vfwcvt_f_f_v_f32m4(ax0, epr);
|
||||
__riscv_vse32_v_f32m4(y + i, ay0, epr);
|
||||
|
||||
vfloat16m2_t ax1 = __riscv_vle16_v_f16m2((const _Float16*)x + i + epr, epr);
|
||||
vfloat32m4_t ay1 = __riscv_vfwcvt_f_f_v_f32m4(ax1, epr);
|
||||
__riscv_vse32_v_f32m4(y + i + epr, ay1, epr);
|
||||
}
|
||||
|
||||
// leftovers
|
||||
int vl;
|
||||
for (i = np; i < n; i += vl) {
|
||||
vl = __riscv_vsetvl_e16m2(n - i);
|
||||
vfloat16m2_t ax0 = __riscv_vle16_v_f16m2((const _Float16*)x + i, vl);
|
||||
vfloat32m4_t ay0 = __riscv_vfwcvt_f_f_v_f32m4(ax0, vl);
|
||||
__riscv_vse32_v_f32m4(y + i, ay0, vl);
|
||||
}
|
||||
|
||||
#endif
|
||||
|
||||
for (; i < n; ++i) {
|
||||
|
|
@ -3371,6 +3391,31 @@ void ggml_cpu_bf16_to_fp32(const ggml_bf16_t * x, float * y, int64_t n) {
|
|||
(const __m128i *)(x + i))),
|
||||
16)));
|
||||
}
|
||||
#elif defined(__riscv_v_intrinsic) && defined(__riscv_zvfbfmin)
|
||||
// calculate step size
|
||||
const int epr = __riscv_vsetvlmax_e16m2();
|
||||
const int step = epr * 2;
|
||||
const int np = (n & ~(step - 1));
|
||||
|
||||
// unroll by 2
|
||||
for (; i < np; i += step) {
|
||||
vbfloat16m2_t ax0 = __riscv_vle16_v_bf16m2((const __bf16*)x + i, epr);
|
||||
vfloat32m4_t ay0 = __riscv_vfwcvtbf16_f_f_v_f32m4(ax0, epr);
|
||||
__riscv_vse32_v_f32m4(y + i, ay0, epr);
|
||||
|
||||
vbfloat16m2_t ax1 = __riscv_vle16_v_bf16m2((const __bf16*)x + i + epr, epr);
|
||||
vfloat32m4_t ay1 = __riscv_vfwcvtbf16_f_f_v_f32m4(ax1, epr);
|
||||
__riscv_vse32_v_f32m4(y + i + epr, ay1, epr);
|
||||
}
|
||||
|
||||
// leftovers
|
||||
int vl;
|
||||
for (i = np; i < n; i += vl) {
|
||||
vl = __riscv_vsetvl_e16m2(n - i);
|
||||
vbfloat16m2_t ax0 = __riscv_vle16_v_bf16m2((const __bf16*)x + i, vl);
|
||||
vfloat32m4_t ay0 = __riscv_vfwcvtbf16_f_f_v_f32m4(ax0, vl);
|
||||
__riscv_vse32_v_f32m4(y + i, ay0, vl);
|
||||
}
|
||||
#endif
|
||||
for (; i < n; i++) {
|
||||
y[i] = GGML_BF16_TO_FP32(x[i]);
|
||||
|
|
|
|||
|
|
@ -195,8 +195,48 @@ void ggml_vec_dot_bf16(int n, float * GGML_RESTRICT s, size_t bs, ggml_bf16_t *
|
|||
sumf += (ggml_float)_mm_cvtss_f32(g);
|
||||
|
||||
#undef LOAD
|
||||
#endif
|
||||
#elif defined(__riscv_v_intrinsic) && defined(__riscv_zvfbfwma)
|
||||
size_t vl = __riscv_vsetvlmax_e32m4();
|
||||
|
||||
// initialize accumulators to all zeroes
|
||||
vfloat32m4_t vsum0 = __riscv_vfmv_v_f_f32m4(0.0f, vl);
|
||||
vfloat32m4_t vsum1 = __riscv_vfmv_v_f_f32m4(0.0f, vl);
|
||||
|
||||
// calculate step size
|
||||
const size_t epr = __riscv_vsetvlmax_e16m2();
|
||||
const size_t step = epr * 2;
|
||||
const int np = (n & ~(step - 1));
|
||||
|
||||
// unroll by 2
|
||||
for (; i < np; i += step) {
|
||||
vbfloat16m2_t ax0 = __riscv_vle16_v_bf16m2((const __bf16 *)&x[i], epr);
|
||||
vbfloat16m2_t ay0 = __riscv_vle16_v_bf16m2((const __bf16 *)&y[i], epr);
|
||||
vsum0 = __riscv_vfwmaccbf16_vv_f32m4(vsum0, ax0, ay0, epr);
|
||||
__asm__ __volatile__ ("" ::: "memory");
|
||||
|
||||
vbfloat16m2_t ax1 = __riscv_vle16_v_bf16m2((const __bf16 *)&x[i + epr], epr);
|
||||
vbfloat16m2_t ay1 = __riscv_vle16_v_bf16m2((const __bf16 *)&y[i + epr], epr);
|
||||
vsum1 = __riscv_vfwmaccbf16_vv_f32m4(vsum1, ax1, ay1, epr);
|
||||
__asm__ __volatile__ ("" ::: "memory");
|
||||
}
|
||||
|
||||
// accumulate in 1 register
|
||||
vsum0 = __riscv_vfadd_vv_f32m4(vsum0, vsum1, vl);
|
||||
|
||||
// leftovers
|
||||
for (i = np; i < n; i += vl) {
|
||||
vl = __riscv_vsetvl_e16m2(n - i);
|
||||
vbfloat16m2_t ax0 = __riscv_vle16_v_bf16m2((const __bf16 *)&x[i], vl);
|
||||
vbfloat16m2_t ay0 = __riscv_vle16_v_bf16m2((const __bf16 *)&y[i], vl);
|
||||
vsum0 = __riscv_vfwmaccbf16_vv_f32m4(vsum0, ax0, ay0, vl);
|
||||
}
|
||||
|
||||
// reduce
|
||||
vl = __riscv_vsetvlmax_e32m4();
|
||||
vfloat32m1_t redsum = __riscv_vfredusum_vs_f32m4_f32m1(vsum0, __riscv_vfmv_v_f_f32m1(0.0f, 1), vl);
|
||||
sumf += __riscv_vfmv_f_s_f32m1_f32(redsum);
|
||||
|
||||
#endif
|
||||
for (; i < n; ++i) {
|
||||
sumf += (ggml_float)(GGML_BF16_TO_FP32(x[i]) *
|
||||
GGML_BF16_TO_FP32(y[i]));
|
||||
|
|
|
|||
|
|
@ -224,13 +224,71 @@ inline static void ggml_vec_dot_f16_unroll(const int n, const int xs, float * GG
|
|||
}
|
||||
GGML_F16x_VEC_REDUCE(sumf[0], sum_00, sum_01, sum_02, sum_03);
|
||||
GGML_F16x_VEC_REDUCE(sumf[1], sum_10, sum_11, sum_12, sum_13);
|
||||
#elif defined(__riscv_v_intrinsic)
|
||||
// todo: RVV impl
|
||||
for (int i = 0; i < n; ++i) {
|
||||
for (int j = 0; j < GGML_VEC_DOT_UNROLL; ++j) {
|
||||
sumf[j] += (ggml_float)(GGML_CPU_FP16_TO_FP32(x[j][i])*GGML_CPU_FP16_TO_FP32(y[i]));
|
||||
}
|
||||
}
|
||||
|
||||
#elif defined(__riscv_v_intrinsic) && defined(__riscv_zvfh)
|
||||
size_t vl = __riscv_vsetvlmax_e32m4();
|
||||
|
||||
// initialize accumulators to all zeroes
|
||||
vfloat32m4_t vsum0_0 = __riscv_vfmv_v_f_f32m4(0.0f, vl);
|
||||
vfloat32m4_t vsum0_1 = __riscv_vfmv_v_f_f32m4(0.0f, vl);
|
||||
vfloat32m4_t vsum1_0 = __riscv_vfmv_v_f_f32m4(0.0f, vl);
|
||||
vfloat32m4_t vsum1_1 = __riscv_vfmv_v_f_f32m4(0.0f, vl);
|
||||
|
||||
// calculate step size
|
||||
const size_t epr = __riscv_vsetvlmax_e16m2();
|
||||
const size_t step = epr * 2;
|
||||
const int np = (n & ~(step - 1));
|
||||
|
||||
// unroll by 2 along the row dimension
|
||||
for (int i = 0; i < np; i += step) {
|
||||
vfloat16m2_t ay0 = __riscv_vle16_v_f16m2((const _Float16 *)(y + i), epr);
|
||||
vfloat16m2_t ax0_0 = __riscv_vle16_v_f16m2((const _Float16 *)(x[0] + i), epr);
|
||||
vfloat16m2_t ax1_0 = __riscv_vle16_v_f16m2((const _Float16 *)(x[1] + i), epr);
|
||||
vsum0_0 = __riscv_vfwmacc_vv_f32m4(vsum0_0, ax0_0, ay0, epr);
|
||||
vsum1_0 = __riscv_vfwmacc_vv_f32m4(vsum1_0, ax1_0, ay0, epr);
|
||||
|
||||
vfloat16m2_t ay1 = __riscv_vle16_v_f16m2((const _Float16 *)(y + i + epr), epr);
|
||||
vfloat16m2_t ax0_1 = __riscv_vle16_v_f16m2((const _Float16 *)(x[0] + i + epr), epr);
|
||||
vfloat16m2_t ax1_1 = __riscv_vle16_v_f16m2((const _Float16 *)(x[1] + i + epr), epr);
|
||||
vsum0_1 = __riscv_vfwmacc_vv_f32m4(vsum0_1, ax0_1, ay1, epr);
|
||||
vsum1_1 = __riscv_vfwmacc_vv_f32m4(vsum1_1, ax1_1, ay1, epr);
|
||||
}
|
||||
|
||||
vfloat32m4_t vsum0 = __riscv_vfadd_vv_f32m4(vsum0_0, vsum0_1, vl);
|
||||
vfloat32m4_t vsum1 = __riscv_vfadd_vv_f32m4(vsum1_0, vsum1_1, vl);
|
||||
|
||||
// leftovers
|
||||
for (int i = np; i < n; i += vl) {
|
||||
vl = __riscv_vsetvl_e16m2(n - i);
|
||||
vfloat16m2_t ay = __riscv_vle16_v_f16m2((const _Float16 *)(y + i), vl);
|
||||
vfloat16m2_t ax0 = __riscv_vle16_v_f16m2((const _Float16 *)(x[0] + i), vl);
|
||||
vfloat16m2_t ax1 = __riscv_vle16_v_f16m2((const _Float16 *)(x[1] + i), vl);
|
||||
|
||||
vsum0 = __riscv_vfwmacc_vv_f32m4(vsum0, ax0, ay, vl);
|
||||
vsum1 = __riscv_vfwmacc_vv_f32m4(vsum1, ax1, ay, vl);
|
||||
}
|
||||
|
||||
// reduce
|
||||
vl = __riscv_vsetvlmax_e32m2();
|
||||
vfloat32m2_t acc0_0 = __riscv_vfadd_vv_f32m2(__riscv_vget_v_f32m4_f32m2(vsum0, 0),
|
||||
__riscv_vget_v_f32m4_f32m2(vsum0, 1), vl);
|
||||
vl = __riscv_vsetvlmax_e32m1();
|
||||
vfloat32m1_t acc0_1 = __riscv_vfadd_vv_f32m1(__riscv_vget_v_f32m2_f32m1(acc0_0, 0),
|
||||
__riscv_vget_v_f32m2_f32m1(acc0_0, 1), vl);
|
||||
vfloat32m1_t redsum0 = __riscv_vfredusum_vs_f32m1_f32m1(
|
||||
acc0_1, __riscv_vfmv_v_f_f32m1(0.0f, 1), vl);
|
||||
|
||||
vl = __riscv_vsetvlmax_e32m2();
|
||||
vfloat32m2_t acc1_0 = __riscv_vfadd_vv_f32m2(__riscv_vget_v_f32m4_f32m2(vsum1, 0),
|
||||
__riscv_vget_v_f32m4_f32m2(vsum1, 1), vl);
|
||||
vl = __riscv_vsetvlmax_e32m1();
|
||||
vfloat32m1_t acc1_1 = __riscv_vfadd_vv_f32m1(__riscv_vget_v_f32m2_f32m1(acc1_0, 0),
|
||||
__riscv_vget_v_f32m2_f32m1(acc1_0, 1), vl);
|
||||
vfloat32m1_t redsum1 = __riscv_vfredusum_vs_f32m1_f32m1(
|
||||
acc1_1, __riscv_vfmv_v_f_f32m1(0.0f, 1), vl);
|
||||
sumf[0] = __riscv_vfmv_f_s_f32m1_f32(redsum0);
|
||||
sumf[1] = __riscv_vfmv_f_s_f32m1_f32(redsum1);
|
||||
|
||||
#else
|
||||
const int np = (n & ~(GGML_F16_STEP - 1));
|
||||
|
||||
|
|
@ -475,15 +533,39 @@ inline static void ggml_vec_mad_f16(const int n, ggml_fp16_t * GGML_RESTRICT y,
|
|||
}
|
||||
np = n;
|
||||
#elif defined(__riscv_zvfh) // implies __riscv_v_intrinsic
|
||||
const int np = n;
|
||||
_Float16 hv = (_Float16)v;
|
||||
for (int i = 0, avl; i < n; i += avl) {
|
||||
avl = __riscv_vsetvl_e16m8(n - i);
|
||||
vfloat16m8_t ax = __riscv_vle16_v_f16m8((const _Float16 *)&x[i], avl);
|
||||
vfloat16m8_t ay = __riscv_vle16_v_f16m8((_Float16 *)&y[i], avl);
|
||||
vfloat16m8_t ny = __riscv_vfmadd_vf_f16m8(ax, hv, ay, avl);
|
||||
__riscv_vse16_v_f16m8((_Float16 *)&y[i], ny, avl);
|
||||
const ggml_fp16_t s = GGML_CPU_FP32_TO_FP16(v);
|
||||
const _Float16 scale = *(const _Float16*)(&s);
|
||||
|
||||
// calculate step size
|
||||
const int epr = __riscv_vsetvlmax_e16m4();
|
||||
const int step = epr * 2;
|
||||
int np = (n & ~(step - 1));
|
||||
|
||||
// unroll by 2
|
||||
for (int i = 0; i < np; i += step) {
|
||||
vfloat16m4_t ax0 = __riscv_vle16_v_f16m4((const _Float16*)x + i, epr);
|
||||
vfloat16m4_t ay0 = __riscv_vle16_v_f16m4((const _Float16*)y + i, epr);
|
||||
ay0 = __riscv_vfmacc_vf_f16m4(ay0, scale, ax0, epr);
|
||||
__riscv_vse16_v_f16m4((_Float16*)y + i, ay0, epr);
|
||||
__asm__ __volatile__ ("" ::: "memory");
|
||||
|
||||
vfloat16m4_t ax1 = __riscv_vle16_v_f16m4((const _Float16*)x + i + epr, epr);
|
||||
vfloat16m4_t ay1 = __riscv_vle16_v_f16m4((const _Float16*)y + i + epr, epr);
|
||||
ay1 = __riscv_vfmacc_vf_f16m4(ay1, scale, ax1, epr);
|
||||
__riscv_vse16_v_f16m4((_Float16*)y + i + epr, ay1, epr);
|
||||
__asm__ __volatile__ ("" ::: "memory");
|
||||
}
|
||||
|
||||
// leftovers
|
||||
int vl;
|
||||
for (int i = np; i < n; i += vl) {
|
||||
vl = __riscv_vsetvl_e16m4(n - i);
|
||||
vfloat16m4_t ax0 = __riscv_vle16_v_f16m4((const _Float16*)x + i, vl);
|
||||
vfloat16m4_t ay0 = __riscv_vle16_v_f16m4((const _Float16*)y + i, vl);
|
||||
ay0 = __riscv_vfmacc_vf_f16m4(ay0, scale, ax0, vl);
|
||||
__riscv_vse16_v_f16m4((_Float16*)y + i, ay0, vl);
|
||||
}
|
||||
np = n;
|
||||
#elif defined(GGML_SIMD)
|
||||
const int np = (n & ~(GGML_F16_STEP - 1));
|
||||
|
||||
|
|
@ -724,13 +806,34 @@ inline static void ggml_vec_scale_f16(const int n, ggml_fp16_t * y, const float
|
|||
svst1_f16(pg, (__fp16 *)(y + np), out);
|
||||
}
|
||||
#elif defined(__riscv_v_intrinsic) && defined(__riscv_zvfh)
|
||||
for (int i = 0, vl; i < n; i += vl) {
|
||||
vl = __riscv_vsetvl_e16m2(n - i);
|
||||
vfloat16m2_t vy = __riscv_vle16_v_f16m2((_Float16 *)&y[i], vl);
|
||||
vfloat32m4_t vy32 = __riscv_vfwcvt_f_f_v_f32m4(vy, vl);
|
||||
vy32 = __riscv_vfmul_vf_f32m4(vy32, v, vl);
|
||||
vy = __riscv_vfncvt_f_f_w_f16m2(vy32, vl);
|
||||
__riscv_vse16_v_f16m2((_Float16 *)&y[i], vy, vl);
|
||||
const ggml_fp16_t s = GGML_CPU_FP32_TO_FP16(v);
|
||||
const _Float16 scale = *(const _Float16*)(&s);
|
||||
|
||||
// calculate step size
|
||||
const int epr = __riscv_vsetvlmax_e16m4();
|
||||
const int step = epr * 2;
|
||||
const int np = (n & ~(step - 1));
|
||||
|
||||
// unroll by 2
|
||||
for (int i = 0; i < np; i += step) {
|
||||
vfloat16m4_t ay0 = __riscv_vle16_v_f16m4((const _Float16*)y + i, epr);
|
||||
ay0 = __riscv_vfmul_vf_f16m4(ay0, scale, epr);
|
||||
__riscv_vse16_v_f16m4((_Float16*)y + i, ay0, epr);
|
||||
__asm__ __volatile__ ("" ::: "memory");
|
||||
|
||||
vfloat16m4_t ay1 = __riscv_vle16_v_f16m4((const _Float16*)y + i + epr, epr);
|
||||
ay1 = __riscv_vfmul_vf_f16m4(ay1, scale, epr);
|
||||
__riscv_vse16_v_f16m4((_Float16*)y + i + epr, ay1, epr);
|
||||
__asm__ __volatile__ ("" ::: "memory");
|
||||
}
|
||||
|
||||
// leftovers
|
||||
int vl;
|
||||
for (int i = np; i < n; i += vl) {
|
||||
vl = __riscv_vsetvl_e16m4(n - i);
|
||||
vfloat16m4_t ay0 = __riscv_vle16_v_f16m4((const _Float16*)y + i, vl);
|
||||
ay0 = __riscv_vfmul_vf_f16m4(ay0, scale, vl);
|
||||
__riscv_vse16_v_f16m4((_Float16*)y + i, ay0, vl);
|
||||
}
|
||||
#elif defined(GGML_SIMD)
|
||||
const int np = (n & ~(GGML_F16_STEP - 1));
|
||||
|
|
|
|||
|
|
@ -78,27 +78,25 @@ namespace ggml_cuda_mma {
|
|||
// MIRRORED == Each data value is held exactly once per thread subgroup.
|
||||
DATA_LAYOUT_I_MAJOR = 0, // Always used for Turing, Ampere, Ada Lovelace, consumer Blackwell, matrix A&B for RDNA4 and CDNA.
|
||||
DATA_LAYOUT_J_MAJOR = 10, // Matrix C for CDNA and RDNA4, int and float matrix C for RDNA3.
|
||||
DATA_LAYOUT_I_MAJOR_MIRRORED = 20,
|
||||
DATA_LAYOUT_I_MAJOR_MIRRORED = 20, // Volta, matrix A&B for RDNA3.
|
||||
DATA_LAYOUT_J_MAJOR_MIRRORED = 30,
|
||||
DATA_LAYOUT_I_MAJOR_DUAL = 40, // Matrix A&B for RDNA3.
|
||||
};
|
||||
// Implemented mma combinations are:
|
||||
// - (I_MAJOR, I_MAJOR) -> I_MAJOR
|
||||
// - (I_MAJOR, I_MAJOR_MIRRORED) -> I_MAJOR
|
||||
// - (I_MAJOR, J_MAJOR_MIRRORED) -> I_MAJOR
|
||||
|
||||
constexpr bool is_i_major(const data_layout dl) {
|
||||
static constexpr bool is_i_major(const data_layout dl) {
|
||||
return dl == DATA_LAYOUT_I_MAJOR ||
|
||||
dl == DATA_LAYOUT_I_MAJOR_MIRRORED ||
|
||||
dl == DATA_LAYOUT_I_MAJOR_DUAL;
|
||||
dl == DATA_LAYOUT_I_MAJOR_MIRRORED;
|
||||
}
|
||||
|
||||
constexpr data_layout get_input_data_layout() {
|
||||
#if defined(RDNA3)
|
||||
return DATA_LAYOUT_I_MAJOR_DUAL;
|
||||
static constexpr __device__ data_layout get_input_data_layout() {
|
||||
#if defined(RDNA3) || __CUDA_ARCH__ == GGML_CUDA_CC_VOLTA
|
||||
return DATA_LAYOUT_I_MAJOR_MIRRORED;
|
||||
#else
|
||||
return DATA_LAYOUT_I_MAJOR;
|
||||
#endif // defined(RDNA3)
|
||||
#endif // defined(RDNA3) || __CUDA_ARCH__ == GGML_CUDA_CC_VOLTA
|
||||
}
|
||||
|
||||
template <int I_, int J_, typename T, data_layout ds_=DATA_LAYOUT_I_MAJOR>
|
||||
|
|
@ -462,11 +460,65 @@ namespace ggml_cuda_mma {
|
|||
}
|
||||
};
|
||||
|
||||
template <int I_, int J_, typename T>
|
||||
struct tile<I_, J_, T, DATA_LAYOUT_I_MAJOR_MIRRORED> {
|
||||
static constexpr int I = I_;
|
||||
static constexpr int J = J_;
|
||||
static constexpr data_layout dl = DATA_LAYOUT_I_MAJOR_MIRRORED;
|
||||
|
||||
// RDNA3
|
||||
static constexpr int ne = I * J / 32 * 2;
|
||||
|
||||
T x[ne] = {0};
|
||||
|
||||
static constexpr __device__ bool supported() {
|
||||
if (I == 16 && J == 16) return true;
|
||||
if (I == 16 && J == 8) return true;
|
||||
if (I == 16 && J == 4) return true;
|
||||
return false;
|
||||
}
|
||||
|
||||
static __device__ __forceinline__ int get_i(const int /*l*/) {
|
||||
if constexpr (supported()) {
|
||||
return threadIdx.x % 16;
|
||||
} else {
|
||||
NO_DEVICE_CODE;
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
static __device__ __forceinline__ int get_j(const int l) {
|
||||
if constexpr (supported()) {
|
||||
return l;
|
||||
} else {
|
||||
NO_DEVICE_CODE;
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
template <int I_, int J_>
|
||||
struct tile<I_, J_, half2, DATA_LAYOUT_I_MAJOR_MIRRORED> {
|
||||
static constexpr int I = I_;
|
||||
static constexpr int J = J_;
|
||||
static constexpr data_layout dl = DATA_LAYOUT_I_MAJOR_MIRRORED;
|
||||
#if defined(RDNA3)
|
||||
static constexpr int ne = tile<I_, J_, float, DATA_LAYOUT_I_MAJOR_MIRRORED>::ne;
|
||||
|
||||
half2 x[ne] = {{0.0f, 0.0f}};
|
||||
|
||||
static constexpr __device__ bool supported() {
|
||||
return tile<I_, J_, float, DATA_LAYOUT_I_MAJOR_MIRRORED>::supported();
|
||||
}
|
||||
|
||||
static __device__ __forceinline__ int get_i(const int l) {
|
||||
return tile<I_, J_, float, DATA_LAYOUT_I_MAJOR_MIRRORED>::get_i(l);
|
||||
}
|
||||
|
||||
static __device__ __forceinline__ int get_j(const int l) {
|
||||
return tile<I_, J_, float, DATA_LAYOUT_I_MAJOR_MIRRORED>::get_j(l);
|
||||
}
|
||||
#else // Volta
|
||||
static constexpr int ne = I * J / (WARP_SIZE/4);
|
||||
|
||||
half2 x[ne] = {{0.0f, 0.0f}};
|
||||
|
|
@ -493,6 +545,29 @@ namespace ggml_cuda_mma {
|
|||
return -1;
|
||||
}
|
||||
}
|
||||
#endif // defined(RDNA3)
|
||||
};
|
||||
|
||||
template <int I_, int J_>
|
||||
struct tile<I_, J_, nv_bfloat162, DATA_LAYOUT_I_MAJOR_MIRRORED> {
|
||||
static constexpr int I = I_;
|
||||
static constexpr int J = J_;
|
||||
static constexpr data_layout dl = DATA_LAYOUT_I_MAJOR_MIRRORED;
|
||||
static constexpr int ne = tile<I_, J_, float, DATA_LAYOUT_I_MAJOR_MIRRORED>::ne;
|
||||
|
||||
nv_bfloat162 x[ne] = {{0.0f, 0.0f}};
|
||||
|
||||
static constexpr __device__ bool supported() {
|
||||
return tile<I_, J_, float, DATA_LAYOUT_I_MAJOR_MIRRORED>::supported();
|
||||
}
|
||||
|
||||
static __device__ __forceinline__ int get_i(const int l) {
|
||||
return tile<I_, J_, float, DATA_LAYOUT_I_MAJOR_MIRRORED>::get_i(l);
|
||||
}
|
||||
|
||||
static __device__ __forceinline__ int get_j(const int l) {
|
||||
return tile<I_, J_, float, DATA_LAYOUT_I_MAJOR_MIRRORED>::get_j(l);
|
||||
}
|
||||
};
|
||||
|
||||
template <int I_, int J_>
|
||||
|
|
@ -528,42 +603,6 @@ namespace ggml_cuda_mma {
|
|||
}
|
||||
};
|
||||
|
||||
template <int I_, int J_, typename T>
|
||||
struct tile<I_, J_, T, DATA_LAYOUT_I_MAJOR_DUAL> {
|
||||
static constexpr int I = I_;
|
||||
static constexpr int J = J_;
|
||||
static constexpr data_layout dl = DATA_LAYOUT_I_MAJOR_DUAL;
|
||||
|
||||
static constexpr int ne = I * J / 32 * 2;
|
||||
|
||||
T x[ne] = {0};
|
||||
|
||||
static constexpr __device__ bool supported() {
|
||||
if (I == 16 && J == 16) return true;
|
||||
if (I == 16 && J == 8) return true;
|
||||
if (I == 16 && J == 4) return true;
|
||||
return false;
|
||||
}
|
||||
|
||||
static __device__ __forceinline__ int get_i(const int l) {
|
||||
if constexpr (supported()) {
|
||||
return threadIdx.x % 16;
|
||||
} else {
|
||||
NO_DEVICE_CODE;
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
static __device__ __forceinline__ int get_j(const int l) {
|
||||
if constexpr (supported()) {
|
||||
return l;
|
||||
} else {
|
||||
NO_DEVICE_CODE;
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
#if defined(TURING_MMA_AVAILABLE)
|
||||
template <int I, int J>
|
||||
static __device__ __forceinline__ tile<I, J/2, half2> get_half2(const tile<I, J, float> & tile_float) {
|
||||
|
|
|
|||
|
|
@ -102,31 +102,25 @@ static void ssm_conv_f32_cuda(const float * src0, const float * src1, const int
|
|||
const int threads = 128;
|
||||
GGML_ASSERT(nr % threads == 0);
|
||||
|
||||
if (n_t <= 32) {
|
||||
const dim3 blocks(n_s, (nr + threads - 1) / threads, 1);
|
||||
if (nc == 4) {
|
||||
ssm_conv_f32<threads, 4><<<blocks, threads, 0, stream>>>(src0, src1, src0_nb0, src0_nb1, src0_nb2, src1_nb1,
|
||||
dst, dst_nb0, dst_nb1, dst_nb2, n_t);
|
||||
} else if (nc == 3) {
|
||||
ssm_conv_f32<threads, 3><<<blocks, threads, 0, stream>>>(src0, src1, src0_nb0, src0_nb1, src0_nb2, src1_nb1,
|
||||
dst, dst_nb0, dst_nb1, dst_nb2, n_t);
|
||||
auto launch_kernel = [&](auto NC) {
|
||||
constexpr int kNC = decltype(NC)::value;
|
||||
if (n_t <= 32) {
|
||||
const dim3 blocks(n_s, (nr + threads - 1) / threads, 1);
|
||||
ssm_conv_f32<threads, kNC><<<blocks, threads, 0, stream>>>(src0, src1, src0_nb0, src0_nb1, src0_nb2, src1_nb1,
|
||||
dst, dst_nb0, dst_nb1, dst_nb2, n_t);
|
||||
} else {
|
||||
GGML_ABORT("Only support kernel size = 3 or size = 4 right now.");
|
||||
}
|
||||
} else {
|
||||
if (nc == 4) {
|
||||
const int64_t split_n_t = 32;
|
||||
dim3 blocks(n_s, (nr + threads - 1) / threads, (n_t + split_n_t - 1) / split_n_t);
|
||||
ssm_conv_long_token_f32<threads, 4, split_n_t><<<blocks, threads, 0, stream>>>(
|
||||
ssm_conv_long_token_f32<threads, kNC, split_n_t><<<blocks, threads, 0, stream>>>(
|
||||
src0, src1, src0_nb0, src0_nb1, src0_nb2, src1_nb1, dst, dst_nb0, dst_nb1, dst_nb2, n_t);
|
||||
} else if (nc == 3) {
|
||||
const int64_t split_n_t = 32;
|
||||
dim3 blocks(n_s, (nr + threads - 1) / threads, (n_t + split_n_t - 1) / split_n_t);
|
||||
ssm_conv_long_token_f32<threads, 3, split_n_t><<<blocks, threads, 0, stream>>>(
|
||||
src0, src1, src0_nb0, src0_nb1, src0_nb2, src1_nb1, dst, dst_nb0, dst_nb1, dst_nb2, n_t);
|
||||
} else {
|
||||
GGML_ABORT("Only support kernel size = 3 or size = 4 right now.");
|
||||
}
|
||||
};
|
||||
|
||||
switch (nc) {
|
||||
case 3: launch_kernel(std::integral_constant<int, 3>{}); break;
|
||||
case 4: launch_kernel(std::integral_constant<int, 4>{}); break;
|
||||
case 9: launch_kernel(std::integral_constant<int, 9>{}); break;
|
||||
default: GGML_ABORT("Only support kernel sizes 3, 4, 9 right now.");
|
||||
}
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -1527,6 +1527,8 @@ private:
|
|||
#endif // GGML_VULKAN_MEMORY_DEBUG
|
||||
|
||||
static bool vk_perf_logger_enabled = false;
|
||||
static bool vk_perf_logger_concurrent = false;
|
||||
static bool vk_enable_sync_logger = false;
|
||||
// number of calls between perf logger prints
|
||||
static uint32_t vk_perf_logger_frequency = 1;
|
||||
|
||||
|
|
@ -1577,14 +1579,14 @@ class vk_perf_logger {
|
|||
flops.clear();
|
||||
}
|
||||
|
||||
void log_timing(const ggml_tensor * node, const char *fusion_name, uint64_t time) {
|
||||
std::string get_node_fusion_name(const ggml_tensor * node, const char *fusion_name, uint64_t *n_flops) {
|
||||
*n_flops = 0;
|
||||
std::string fusion_str;
|
||||
if (fusion_name) {
|
||||
fusion_str = fusion_name + std::string(" ");
|
||||
}
|
||||
if (node->op == GGML_OP_UNARY) {
|
||||
timings[fusion_str + ggml_unary_op_name(ggml_get_unary_op(node))].push_back(time);
|
||||
return;
|
||||
return fusion_str + ggml_unary_op_name(ggml_get_unary_op(node));
|
||||
}
|
||||
if (node->op == GGML_OP_MUL_MAT || node->op == GGML_OP_MUL_MAT_ID) {
|
||||
const uint64_t m = node->ne[0];
|
||||
|
|
@ -1606,9 +1608,8 @@ class vk_perf_logger {
|
|||
name += " batch=" + std::to_string(batch);
|
||||
}
|
||||
name = fusion_str + name;
|
||||
timings[name].push_back(time);
|
||||
flops[name].push_back(m * n * (k + (k - 1)) * batch);
|
||||
return;
|
||||
*n_flops = m * n * (k + (k - 1)) * batch;
|
||||
return name;
|
||||
}
|
||||
if (node->op == GGML_OP_CONV_2D || node->op == GGML_OP_CONV_TRANSPOSE_2D) {
|
||||
std::string name = ggml_op_name(node->op);
|
||||
|
|
@ -1624,20 +1625,17 @@ class vk_perf_logger {
|
|||
uint64_t size_M = Cout;
|
||||
uint64_t size_K = Cin * KW * KH;
|
||||
uint64_t size_N = N * OW * OH;
|
||||
uint64_t n_flops = size_M * size_N * (size_K + (size_K - 1));
|
||||
*n_flops = size_M * size_N * (size_K + (size_K - 1));
|
||||
name += " M=Cout=" + std::to_string(size_M) + ", K=Cin*KW*KH=" + std::to_string(size_K) +
|
||||
", N=N*OW*OH=" + std::to_string(size_N);
|
||||
name = fusion_str + name;
|
||||
flops[name].push_back(n_flops);
|
||||
timings[name].push_back(time);
|
||||
return;
|
||||
return name;
|
||||
}
|
||||
if (node->op == GGML_OP_RMS_NORM) {
|
||||
std::string name = ggml_op_name(node->op);
|
||||
name += "(" + std::to_string(node->ne[0]) + "," + std::to_string(node->ne[1]) + "," + std::to_string(node->ne[2]) + "," + std::to_string(node->ne[3]) + ")";
|
||||
name = fusion_str + name;
|
||||
timings[name].push_back(time);
|
||||
return;
|
||||
return name;
|
||||
}
|
||||
if (node->op == GGML_OP_FLASH_ATTN_EXT) {
|
||||
const ggml_tensor * dst = node;
|
||||
|
|
@ -1653,8 +1651,7 @@ class vk_perf_logger {
|
|||
" k(" << k->ne[0] << "," << k->ne[1] << "," << k->ne[2] << "," << k->ne[3] << "), " <<
|
||||
" v(" << v->ne[0] << "," << v->ne[1] << "," << v->ne[2] << "," << v->ne[3] << "), " <<
|
||||
" m(" << (m?m->ne[0]:0) << "," << (m?m->ne[1]:0) << "," << (m?m->ne[2]:0) << "," << (m?m->ne[3]:0) << ")";
|
||||
timings[name.str()].push_back(time);
|
||||
return;
|
||||
return name.str();
|
||||
}
|
||||
if (node->op == GGML_OP_TOP_K) {
|
||||
std::stringstream name;
|
||||
|
|
@ -1662,11 +1659,38 @@ class vk_perf_logger {
|
|||
name << ggml_op_name(node->op) <<
|
||||
" K=" << node->ne[0] <<
|
||||
" (" << node->src[0]->ne[0] << "," << node->src[0]->ne[1] << "," << node->src[0]->ne[2] << "," << node->src[0]->ne[3] << ")";
|
||||
timings[name.str()].push_back(time);
|
||||
return;
|
||||
return name.str();
|
||||
}
|
||||
timings[fusion_str + ggml_op_name(node->op)].push_back(time);
|
||||
return fusion_str + ggml_op_name(node->op);
|
||||
}
|
||||
|
||||
void log_timing(const ggml_tensor * node, const char *fusion_name, uint64_t time) {
|
||||
uint64_t n_flops;
|
||||
std::string name = get_node_fusion_name(node, fusion_name, &n_flops);
|
||||
if (n_flops) {
|
||||
flops[name].push_back(n_flops);
|
||||
}
|
||||
timings[name].push_back(time);
|
||||
}
|
||||
|
||||
void log_timing(const std::vector<ggml_tensor *> &nodes, const std::vector<const char *> &names, uint64_t time) {
|
||||
uint64_t total_flops = 0;
|
||||
std::string name;
|
||||
for (size_t n = 0; n < nodes.size(); ++n) {
|
||||
uint64_t n_flops = 0;
|
||||
name += get_node_fusion_name(nodes[n], names[n], &n_flops);
|
||||
total_flops += n_flops;
|
||||
|
||||
if (n != nodes.size() - 1) {
|
||||
name += ", ";
|
||||
}
|
||||
}
|
||||
if (total_flops) {
|
||||
flops[name].push_back(total_flops);
|
||||
}
|
||||
timings[name].push_back(time);
|
||||
}
|
||||
|
||||
private:
|
||||
std::map<std::string, std::vector<uint64_t>> timings;
|
||||
std::map<std::string, std::vector<uint64_t>> flops;
|
||||
|
|
@ -1729,7 +1753,9 @@ struct ggml_backend_vk_context {
|
|||
std::unique_ptr<vk_perf_logger> perf_logger;
|
||||
vk::QueryPool query_pool;
|
||||
std::vector<const char *> query_fusion_names;
|
||||
std::vector<int> query_fusion_node_count;
|
||||
std::vector<ggml_tensor *> query_nodes;
|
||||
std::vector<int> query_node_idx;
|
||||
int32_t num_queries {};
|
||||
int32_t query_idx {};
|
||||
};
|
||||
|
|
@ -5194,6 +5220,8 @@ static void ggml_vk_instance_init() {
|
|||
}
|
||||
|
||||
vk_perf_logger_enabled = getenv("GGML_VK_PERF_LOGGER") != nullptr;
|
||||
vk_perf_logger_concurrent = getenv("GGML_VK_PERF_LOGGER_CONCURRENT") != nullptr;
|
||||
vk_enable_sync_logger = getenv("GGML_VK_SYNC_LOGGER") != nullptr;
|
||||
const char* GGML_VK_PERF_LOGGER_FREQUENCY = getenv("GGML_VK_PERF_LOGGER_FREQUENCY");
|
||||
|
||||
if (GGML_VK_PERF_LOGGER_FREQUENCY != nullptr) {
|
||||
|
|
@ -11820,15 +11848,18 @@ static bool ggml_vk_build_graph(ggml_backend_vk_context * ctx, ggml_cgraph * cgr
|
|||
}
|
||||
}
|
||||
|
||||
#define ENABLE_SYNC_LOGGING 0
|
||||
|
||||
if (need_sync) {
|
||||
#if ENABLE_SYNC_LOGGING
|
||||
std::cerr << "sync" << std::endl;
|
||||
#endif
|
||||
if (vk_enable_sync_logger) {
|
||||
std::cerr << "sync" << std::endl;
|
||||
}
|
||||
ctx->unsynced_nodes_written.clear();
|
||||
ctx->unsynced_nodes_read.clear();
|
||||
ggml_vk_sync_buffers(ctx, compute_ctx);
|
||||
|
||||
if (vk_perf_logger_enabled && vk_perf_logger_concurrent) {
|
||||
ctx->query_node_idx[ctx->query_idx] = node_idx;
|
||||
compute_ctx->s->buffer.writeTimestamp(vk::PipelineStageFlagBits::eAllCommands, ctx->query_pool, ctx->query_idx++);
|
||||
}
|
||||
}
|
||||
// Add all fused nodes to the unsynchronized lists.
|
||||
for (int32_t i = 0; i < ctx->num_additional_fused_ops + 1; ++i) {
|
||||
|
|
@ -11845,20 +11876,20 @@ static bool ggml_vk_build_graph(ggml_backend_vk_context * ctx, ggml_cgraph * cgr
|
|||
}
|
||||
}
|
||||
}
|
||||
#if ENABLE_SYNC_LOGGING
|
||||
for (int i = 0; i < ctx->num_additional_fused_ops + 1; ++i) {
|
||||
auto *n = cgraph->nodes[node_idx + i];
|
||||
std::cerr << node_idx + i << " " << ggml_op_name(n->op) << " " << n->name;
|
||||
if (n->op == GGML_OP_GLU) {
|
||||
std::cerr << " " << ggml_glu_op_name(ggml_get_glu_op(n)) << " " << (n->src[1] ? "split" : "single") << " ";
|
||||
if (vk_enable_sync_logger) {
|
||||
for (int i = 0; i < ctx->num_additional_fused_ops + 1; ++i) {
|
||||
auto *n = cgraph->nodes[node_idx + i];
|
||||
std::cerr << node_idx + i << " " << ggml_op_name(n->op) << " " << n->name;
|
||||
if (n->op == GGML_OP_GLU) {
|
||||
std::cerr << " " << ggml_glu_op_name(ggml_get_glu_op(n)) << " " << (n->src[1] ? "split" : "single") << " ";
|
||||
}
|
||||
if (n->op == GGML_OP_ROPE) {
|
||||
const int mode = ((const int32_t *) n->op_params)[2];
|
||||
std::cerr << " rope mode: " << mode;
|
||||
}
|
||||
std::cerr << std::endl;
|
||||
}
|
||||
if (n->op == GGML_OP_ROPE) {
|
||||
const int mode = ((const int32_t *) n->op_params)[2];
|
||||
std::cerr << " rope mode: " << mode;
|
||||
}
|
||||
std::cerr << std::endl;
|
||||
}
|
||||
#endif
|
||||
|
||||
switch (node->op) {
|
||||
case GGML_OP_REPEAT:
|
||||
|
|
@ -13138,12 +13169,16 @@ static ggml_status ggml_backend_vk_graph_compute(ggml_backend_t backend, ggml_cg
|
|||
ctx->query_pool = ctx->device->device.createQueryPool(query_create_info);
|
||||
ctx->num_queries = query_create_info.queryCount;
|
||||
ctx->query_fusion_names.resize(ctx->num_queries);
|
||||
ctx->query_fusion_node_count.resize(ctx->num_queries);
|
||||
ctx->query_nodes.resize(ctx->num_queries);
|
||||
ctx->query_node_idx.resize(ctx->num_queries);
|
||||
}
|
||||
|
||||
ctx->device->device.resetQueryPool(ctx->query_pool, 0, cgraph->n_nodes+1);
|
||||
std::fill(ctx->query_fusion_names.begin(), ctx->query_fusion_names.end(), nullptr);
|
||||
std::fill(ctx->query_fusion_node_count.begin(), ctx->query_fusion_node_count.end(), 0);
|
||||
std::fill(ctx->query_nodes.begin(), ctx->query_nodes.end(), nullptr);
|
||||
std::fill(ctx->query_node_idx.begin(), ctx->query_node_idx.end(), 0);
|
||||
|
||||
GGML_ASSERT(ctx->compute_ctx.expired());
|
||||
compute_ctx = ggml_vk_create_context(ctx, ctx->compute_cmd_pool);
|
||||
|
|
@ -13272,9 +13307,16 @@ static ggml_status ggml_backend_vk_graph_compute(ggml_backend_t backend, ggml_cg
|
|||
} else {
|
||||
compute_ctx = ctx->compute_ctx.lock();
|
||||
}
|
||||
ctx->query_nodes[ctx->query_idx] = cgraph->nodes[i];
|
||||
ctx->query_fusion_names[ctx->query_idx] = fusion_string;
|
||||
compute_ctx->s->buffer.writeTimestamp(vk::PipelineStageFlagBits::eAllCommands, ctx->query_pool, ctx->query_idx++);
|
||||
if (!vk_perf_logger_concurrent) {
|
||||
// track a single node/fusion for the current query
|
||||
ctx->query_nodes[ctx->query_idx] = cgraph->nodes[i];
|
||||
ctx->query_fusion_names[ctx->query_idx] = fusion_string;
|
||||
compute_ctx->s->buffer.writeTimestamp(vk::PipelineStageFlagBits::eAllCommands, ctx->query_pool, ctx->query_idx++);
|
||||
} else {
|
||||
// track a fusion string and number of fused ops for the current node_idx
|
||||
ctx->query_fusion_names[i] = fusion_string;
|
||||
ctx->query_fusion_node_count[i] = ctx->num_additional_fused_ops;
|
||||
}
|
||||
}
|
||||
|
||||
if (enqueued) {
|
||||
|
|
@ -13316,12 +13358,32 @@ static ggml_status ggml_backend_vk_graph_compute(ggml_backend_t backend, ggml_cg
|
|||
// Get the results and pass them to the logger
|
||||
std::vector<uint64_t> timestamps(cgraph->n_nodes + 1);
|
||||
VK_CHECK(ctx->device->device.getQueryPoolResults(ctx->query_pool, 0, ctx->query_idx, (cgraph->n_nodes + 1)*sizeof(uint64_t), timestamps.data(), sizeof(uint64_t), vk::QueryResultFlagBits::e64 | vk::QueryResultFlagBits::eWait), "get timestamp results");
|
||||
for (int i = 1; i < ctx->query_idx; i++) {
|
||||
auto node = ctx->query_nodes[i];
|
||||
auto name = ctx->query_fusion_names[i];
|
||||
ctx->perf_logger->log_timing(node, name, uint64_t((timestamps[i] - timestamps[i-1]) * ctx->device->properties.limits.timestampPeriod));
|
||||
if (!vk_perf_logger_concurrent) {
|
||||
// Log each op separately
|
||||
for (int i = 1; i < ctx->query_idx; i++) {
|
||||
auto node = ctx->query_nodes[i];
|
||||
auto name = ctx->query_fusion_names[i];
|
||||
ctx->perf_logger->log_timing(node, name, uint64_t((timestamps[i] - timestamps[i-1]) * ctx->device->properties.limits.timestampPeriod));
|
||||
}
|
||||
} else {
|
||||
// Log each group of nodes
|
||||
int prev_node_idx = 0;
|
||||
for (int i = 1; i < ctx->query_idx; i++) {
|
||||
auto cur_node_idx = ctx->query_node_idx[i];
|
||||
std::vector<ggml_tensor *> nodes;
|
||||
std::vector<const char *> names;
|
||||
for (int node_idx = prev_node_idx; node_idx < cur_node_idx; ++node_idx) {
|
||||
if (ggml_op_is_empty(cgraph->nodes[node_idx]->op)) {
|
||||
continue;
|
||||
}
|
||||
nodes.push_back(cgraph->nodes[node_idx]);
|
||||
names.push_back(ctx->query_fusion_names[node_idx]);
|
||||
node_idx += ctx->query_fusion_node_count[node_idx];
|
||||
}
|
||||
prev_node_idx = cur_node_idx;
|
||||
ctx->perf_logger->log_timing(nodes, names, uint64_t((timestamps[i] - timestamps[i-1]) * ctx->device->properties.limits.timestampPeriod));
|
||||
}
|
||||
}
|
||||
|
||||
ctx->perf_logger->print_timings();
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -690,6 +690,8 @@ class MODEL_TENSOR(IntEnum):
|
|||
V_TOK_EOI = auto() # cogvlm
|
||||
# audio (mtmd)
|
||||
A_ENC_EMBD_POS = auto()
|
||||
A_ENC_EMBD_NORM = auto()
|
||||
A_ENC_EMBD_TO_LOGITS = auto()
|
||||
A_ENC_CONV1D = auto()
|
||||
A_PRE_NORM = auto()
|
||||
A_POST_NORM = auto()
|
||||
|
|
@ -700,8 +702,13 @@ class MODEL_TENSOR(IntEnum):
|
|||
A_ENC_OUTPUT = auto()
|
||||
A_ENC_OUTPUT_NORM = auto()
|
||||
A_ENC_FFN_UP = auto()
|
||||
A_ENC_FFN_NORM = auto()
|
||||
A_ENC_FFN_GATE = auto()
|
||||
A_ENC_FFN_DOWN = auto()
|
||||
A_ENC_FFN_UP_1 = auto()
|
||||
A_ENC_FFN_NORM_1 = auto()
|
||||
A_ENC_FFN_GATE_1 = auto()
|
||||
A_ENC_FFN_DOWN_1 = auto()
|
||||
A_MMPROJ = auto()
|
||||
A_MMPROJ_FC = auto()
|
||||
A_MM_NORM_PRE = auto()
|
||||
|
|
@ -713,6 +720,16 @@ class MODEL_TENSOR(IntEnum):
|
|||
NEXTN_HNORM = auto()
|
||||
NEXTN_SHARED_HEAD_HEAD = auto()
|
||||
NEXTN_SHARED_HEAD_NORM = auto()
|
||||
# lfm2 audio
|
||||
A_ENC_NORM_CONV = auto()
|
||||
A_ENC_LINEAR_POS = auto()
|
||||
A_ENC_POS_BIAS_U = auto()
|
||||
A_ENC_POS_BIAS_V = auto()
|
||||
A_ENC_OUT = auto()
|
||||
A_ENC_CONV_DW = auto() # SSM conv
|
||||
A_ENC_CONV_NORM = auto() # SSM conv
|
||||
A_ENC_CONV_PW1 = auto()
|
||||
A_ENC_CONV_PW2 = auto()
|
||||
|
||||
|
||||
MODEL_ARCH_NAMES: dict[MODEL_ARCH, str] = {
|
||||
|
|
@ -1064,7 +1081,10 @@ TENSOR_NAMES: dict[MODEL_TENSOR, str] = {
|
|||
MODEL_TENSOR.V_TOK_BOI: "v.boi",
|
||||
MODEL_TENSOR.V_TOK_EOI: "v.eoi",
|
||||
# audio (mtmd)
|
||||
# note: all audio tensor names must use prefix "a." or "mm.a."
|
||||
MODEL_TENSOR.A_ENC_EMBD_POS: "a.position_embd",
|
||||
MODEL_TENSOR.A_ENC_EMBD_NORM: "a.position_embd_norm",
|
||||
MODEL_TENSOR.A_ENC_EMBD_TO_LOGITS: "a.embd_to_logits",
|
||||
MODEL_TENSOR.A_ENC_CONV1D: "a.conv1d.{bid}",
|
||||
MODEL_TENSOR.A_PRE_NORM: "a.pre_ln",
|
||||
MODEL_TENSOR.A_POST_NORM: "a.post_ln",
|
||||
|
|
@ -1074,13 +1094,28 @@ TENSOR_NAMES: dict[MODEL_TENSOR, str] = {
|
|||
MODEL_TENSOR.A_ENC_INPUT_NORM: "a.blk.{bid}.ln1",
|
||||
MODEL_TENSOR.A_ENC_OUTPUT: "a.blk.{bid}.attn_out",
|
||||
MODEL_TENSOR.A_ENC_OUTPUT_NORM: "a.blk.{bid}.ln2",
|
||||
MODEL_TENSOR.A_ENC_FFN_NORM: "a.blk.{bid}.ffn_norm",
|
||||
MODEL_TENSOR.A_ENC_FFN_UP: "a.blk.{bid}.ffn_up",
|
||||
MODEL_TENSOR.A_ENC_FFN_GATE: "a.blk.{bid}.ffn_gate",
|
||||
MODEL_TENSOR.A_ENC_FFN_DOWN: "a.blk.{bid}.ffn_down",
|
||||
MODEL_TENSOR.A_ENC_FFN_NORM_1: "a.blk.{bid}.ffn_norm_1",
|
||||
MODEL_TENSOR.A_ENC_FFN_UP_1: "a.blk.{bid}.ffn_up_1",
|
||||
MODEL_TENSOR.A_ENC_FFN_GATE_1: "a.blk.{bid}.ffn_gate_1",
|
||||
MODEL_TENSOR.A_ENC_FFN_DOWN_1: "a.blk.{bid}.ffn_down_1",
|
||||
MODEL_TENSOR.A_MMPROJ: "mm.a.mlp.{bid}",
|
||||
MODEL_TENSOR.A_MMPROJ_FC: "mm.a.fc",
|
||||
MODEL_TENSOR.A_MM_NORM_PRE: "mm.a.norm_pre",
|
||||
MODEL_TENSOR.A_MM_NORM_MID: "mm.a.norm_mid",
|
||||
# lfm2 audio
|
||||
MODEL_TENSOR.A_ENC_NORM_CONV: "a.blk.{bid}.norm_conv",
|
||||
MODEL_TENSOR.A_ENC_LINEAR_POS: "a.blk.{bid}.linear_pos",
|
||||
MODEL_TENSOR.A_ENC_POS_BIAS_U: "a.blk.{bid}.pos_bias_u",
|
||||
MODEL_TENSOR.A_ENC_POS_BIAS_V: "a.blk.{bid}.pos_bias_v",
|
||||
MODEL_TENSOR.A_ENC_OUT: "a.pre_encode.out",
|
||||
MODEL_TENSOR.A_ENC_CONV_DW: "a.blk.{bid}.conv_dw",
|
||||
MODEL_TENSOR.A_ENC_CONV_NORM: "a.blk.{bid}.conv_norm",
|
||||
MODEL_TENSOR.A_ENC_CONV_PW1: "a.blk.{bid}.conv_pw1",
|
||||
MODEL_TENSOR.A_ENC_CONV_PW2: "a.blk.{bid}.conv_pw2",
|
||||
# NextN/MTP
|
||||
MODEL_TENSOR.NEXTN_EH_PROJ: "blk.{bid}.nextn.eh_proj",
|
||||
MODEL_TENSOR.NEXTN_EMBED_TOKENS: "blk.{bid}.nextn.embed_tokens",
|
||||
|
|
@ -1145,6 +1180,8 @@ MODEL_TENSORS: dict[MODEL_ARCH, list[MODEL_TENSOR]] = {
|
|||
MODEL_TENSOR.V_TOK_EOI,
|
||||
# audio
|
||||
MODEL_TENSOR.A_ENC_EMBD_POS,
|
||||
MODEL_TENSOR.A_ENC_EMBD_NORM,
|
||||
MODEL_TENSOR.A_ENC_EMBD_TO_LOGITS,
|
||||
MODEL_TENSOR.A_ENC_CONV1D,
|
||||
MODEL_TENSOR.A_PRE_NORM,
|
||||
MODEL_TENSOR.A_POST_NORM,
|
||||
|
|
@ -1154,13 +1191,27 @@ MODEL_TENSORS: dict[MODEL_ARCH, list[MODEL_TENSOR]] = {
|
|||
MODEL_TENSOR.A_ENC_INPUT_NORM,
|
||||
MODEL_TENSOR.A_ENC_OUTPUT,
|
||||
MODEL_TENSOR.A_ENC_OUTPUT_NORM,
|
||||
MODEL_TENSOR.A_ENC_FFN_NORM,
|
||||
MODEL_TENSOR.A_ENC_FFN_UP,
|
||||
MODEL_TENSOR.A_ENC_FFN_GATE,
|
||||
MODEL_TENSOR.A_ENC_FFN_DOWN,
|
||||
MODEL_TENSOR.A_ENC_FFN_NORM_1,
|
||||
MODEL_TENSOR.A_ENC_FFN_UP_1,
|
||||
MODEL_TENSOR.A_ENC_FFN_GATE_1,
|
||||
MODEL_TENSOR.A_ENC_FFN_DOWN_1,
|
||||
MODEL_TENSOR.A_MMPROJ,
|
||||
MODEL_TENSOR.A_MMPROJ_FC,
|
||||
MODEL_TENSOR.A_MM_NORM_PRE,
|
||||
MODEL_TENSOR.A_MM_NORM_MID,
|
||||
MODEL_TENSOR.A_ENC_NORM_CONV,
|
||||
MODEL_TENSOR.A_ENC_LINEAR_POS,
|
||||
MODEL_TENSOR.A_ENC_POS_BIAS_U,
|
||||
MODEL_TENSOR.A_ENC_POS_BIAS_V,
|
||||
MODEL_TENSOR.A_ENC_OUT,
|
||||
MODEL_TENSOR.A_ENC_CONV_DW,
|
||||
MODEL_TENSOR.A_ENC_CONV_NORM,
|
||||
MODEL_TENSOR.A_ENC_CONV_PW1,
|
||||
MODEL_TENSOR.A_ENC_CONV_PW2,
|
||||
],
|
||||
MODEL_ARCH.LLAMA: [
|
||||
MODEL_TENSOR.TOKEN_EMBD,
|
||||
|
|
@ -3363,6 +3414,7 @@ class VisionProjectorType:
|
|||
LIGHTONOCR = "lightonocr"
|
||||
COGVLM = "cogvlm"
|
||||
JANUS_PRO = "janus_pro"
|
||||
LFM2A = "lfm2a" # audio
|
||||
GLM4V = "glm4v"
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -1535,10 +1535,20 @@ class TensorNameMap:
|
|||
|
||||
MODEL_TENSOR.A_ENC_EMBD_POS: (
|
||||
"audio_tower.embed_positions", # ultravox
|
||||
"audio_embedding.embedding", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_EMBD_NORM: (
|
||||
"audio_embedding.embedding_norm", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_EMBD_TO_LOGITS: (
|
||||
"audio_embedding.to_logits", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_CONV1D: (
|
||||
"audio_tower.conv{bid}", # ultravox
|
||||
"conformer.pre_encode.conv.{bid}", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_PRE_NORM: (),
|
||||
|
|
@ -1550,36 +1560,76 @@ class TensorNameMap:
|
|||
|
||||
MODEL_TENSOR.A_ENC_ATTN_Q: (
|
||||
"audio_tower.layers.{bid}.self_attn.q_proj", # ultravox
|
||||
"conformer.layers.{bid}.self_attn.linear_q", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_ATTN_K: (
|
||||
"audio_tower.layers.{bid}.self_attn.k_proj", # ultravox
|
||||
"conformer.layers.{bid}.self_attn.linear_k", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_ATTN_V: (
|
||||
"audio_tower.layers.{bid}.self_attn.v_proj", # ultravox
|
||||
"conformer.layers.{bid}.self_attn.linear_v", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_INPUT_NORM: (
|
||||
"audio_tower.layers.{bid}.self_attn_layer_norm", # ultravox
|
||||
"conformer.layers.{bid}.norm_self_att", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_OUTPUT: (
|
||||
"audio_tower.layers.{bid}.self_attn.out_proj", # ultravox
|
||||
"conformer.layers.{bid}.self_attn.linear_out", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_OUTPUT_NORM: (
|
||||
"audio_tower.layers.{bid}.final_layer_norm", # ultravox
|
||||
"conformer.layers.{bid}.norm_out", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_FFN_NORM: (
|
||||
"conformer.layers.{bid}.norm_feed_forward1", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_FFN_UP: (
|
||||
"audio_tower.layers.{bid}.fc1", # ultravox
|
||||
"conformer.layers.{bid}.feed_forward1.linear1", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_FFN_GATE: (),
|
||||
|
||||
MODEL_TENSOR.A_ENC_FFN_DOWN: (
|
||||
"audio_tower.layers.{bid}.fc2", # ultravox
|
||||
"conformer.layers.{bid}.feed_forward1.linear2", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_FFN_UP_1: (
|
||||
"conformer.layers.{bid}.feed_forward2.linear1", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_FFN_DOWN_1: (
|
||||
"conformer.layers.{bid}.feed_forward2.linear2", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_FFN_NORM_1: (
|
||||
"conformer.layers.{bid}.norm_feed_forward2", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_LINEAR_POS: (
|
||||
"conformer.layers.{bid}.self_attn.linear_pos", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_POS_BIAS_U: (
|
||||
"conformer.layers.{bid}.self_attn.pos_bias_u", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_POS_BIAS_V: (
|
||||
"conformer.layers.{bid}.self_attn.pos_bias_v", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_OUT: (
|
||||
"conformer.pre_encode.out", # lfm2
|
||||
),
|
||||
|
||||
# note: some tensors below has "audio." pseudo-prefix, to prevent conflicts with vision tensors
|
||||
|
|
@ -1587,6 +1637,7 @@ class TensorNameMap:
|
|||
|
||||
MODEL_TENSOR.A_MMPROJ: (
|
||||
"audio.multi_modal_projector.linear_{bid}", # ultravox
|
||||
"audio_adapter.model.{bid}" # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_MMPROJ_FC: (
|
||||
|
|
@ -1602,6 +1653,26 @@ class TensorNameMap:
|
|||
"audio.multi_modal_projector.ln_mid", # ultravox
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_CONV_DW: (
|
||||
"conformer.layers.{bid}.conv.depthwise_conv", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_CONV_NORM: (
|
||||
"conformer.layers.{bid}.conv.batch_norm", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_CONV_PW1: (
|
||||
"conformer.layers.{bid}.conv.pointwise_conv1", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_CONV_PW2: (
|
||||
"conformer.layers.{bid}.conv.pointwise_conv2", # lfm2
|
||||
),
|
||||
|
||||
MODEL_TENSOR.A_ENC_NORM_CONV: (
|
||||
"conformer.layers.{bid}.norm_conv", # lfm2
|
||||
),
|
||||
|
||||
# NextN/MTP tensors for GLM4_MOE
|
||||
MODEL_TENSOR.NEXTN_EH_PROJ: (
|
||||
"model.layers.{bid}.eh_proj",
|
||||
|
|
|
|||
|
|
@ -288,7 +288,7 @@ class LocalTensor:
|
|||
data_range: LocalTensorRange
|
||||
|
||||
def mmap_bytes(self) -> np.ndarray:
|
||||
return np.memmap(self.data_range.filename, mode='r', offset=self.data_range.offset, shape=self.data_range.size)
|
||||
return np.memmap(self.data_range.filename, mode='c', offset=self.data_range.offset, shape=self.data_range.size)
|
||||
|
||||
|
||||
class SafetensorsLocal:
|
||||
|
|
|
|||
|
|
@ -7295,11 +7295,11 @@ static std::vector<std::unique_ptr<test_case>> make_test_cases_eval() {
|
|||
|
||||
test_cases.emplace_back(new test_l2_norm(GGML_TYPE_F32, {64, 5, 4, 3}, 1e-12f));
|
||||
|
||||
for (int64_t d_conv : {3, 4}) {
|
||||
for (int64_t d_conv : {3, 4, 9}) {
|
||||
for (int64_t d_inner: {1024, 1536, 2048}) {
|
||||
test_cases.emplace_back(new test_ssm_conv(GGML_TYPE_F32, {4, d_inner, 1, 1}, {d_conv, d_inner, 1, 1}));
|
||||
test_cases.emplace_back(new test_ssm_conv(GGML_TYPE_F32, {8, d_inner, 1, 1}, {d_conv, d_inner, 1, 1}));
|
||||
test_cases.emplace_back(new test_ssm_conv(GGML_TYPE_F32, {4, d_inner, 4, 1}, {d_conv, d_inner, 1, 1}));
|
||||
test_cases.emplace_back(new test_ssm_conv(GGML_TYPE_F32, {d_conv, d_inner, 1, 1}, {d_conv, d_inner, 1, 1}));
|
||||
test_cases.emplace_back(new test_ssm_conv(GGML_TYPE_F32, {2 * d_conv, d_inner, 1, 1}, {d_conv, d_inner, 1, 1}));
|
||||
test_cases.emplace_back(new test_ssm_conv(GGML_TYPE_F32, {d_conv, d_inner, 4, 1}, {d_conv, d_inner, 1, 1}));
|
||||
}
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -15,6 +15,7 @@ add_library(mtmd
|
|||
clip-graph.h
|
||||
models/models.h
|
||||
models/cogvlm.cpp
|
||||
models/conformer.cpp
|
||||
models/glm4v.cpp
|
||||
models/internvl.cpp
|
||||
models/kimivl.cpp
|
||||
|
|
|
|||
|
|
@ -138,6 +138,21 @@
|
|||
#define TN_TOK_BOI "v.boi"
|
||||
#define TN_TOK_EOI "v.eoi"
|
||||
|
||||
// (conformer) lfm2
|
||||
#define TN_PRE_ENCODE_OUT "a.pre_encode.out.%s"
|
||||
#define TN_FFN_NORM "%s.blk.%d.ffn_norm.%s"
|
||||
#define TN_FFN_NORM_1 "%s.blk.%d.ffn_norm_1.%s"
|
||||
#define TN_FFN_UP_1 "%s.blk.%d.ffn_up_1.%s"
|
||||
#define TN_FFN_DOWN_1 "%s.blk.%d.ffn_down_1.%s"
|
||||
#define TN_POS_BIAS_U "%s.blk.%d.pos_bias_u"
|
||||
#define TN_POS_BIAS_V "%s.blk.%d.pos_bias_v"
|
||||
#define TN_NORM_CONV "%s.blk.%d.norm_conv.%s"
|
||||
#define TN_LINEAR_POS "%s.blk.%d.linear_pos.%s"
|
||||
#define TN_CONV_DW "%s.blk.%d.conv_dw.%s"
|
||||
#define TN_CONV_NORM "%s.blk.%d.conv_norm.%s"
|
||||
#define TN_CONV_PW1 "%s.blk.%d.conv_pw1.%s"
|
||||
#define TN_CONV_PW2 "%s.blk.%d.conv_pw2.%s"
|
||||
|
||||
// align x to upper multiple of n
|
||||
#define CLIP_ALIGN(x, n) ((((x) + (n) - 1) / (n)) * (n))
|
||||
|
||||
|
|
@ -170,6 +185,7 @@ enum projector_type {
|
|||
PROJECTOR_TYPE_LIGHTONOCR,
|
||||
PROJECTOR_TYPE_COGVLM,
|
||||
PROJECTOR_TYPE_JANUS_PRO,
|
||||
PROJECTOR_TYPE_LFM2A,
|
||||
PROJECTOR_TYPE_GLM4V,
|
||||
PROJECTOR_TYPE_UNKNOWN,
|
||||
};
|
||||
|
|
@ -198,6 +214,7 @@ static std::map<projector_type, std::string> PROJECTOR_TYPE_NAMES = {
|
|||
{ PROJECTOR_TYPE_LIGHTONOCR,"lightonocr"},
|
||||
{ PROJECTOR_TYPE_COGVLM, "cogvlm"},
|
||||
{ PROJECTOR_TYPE_JANUS_PRO, "janus_pro"},
|
||||
{ PROJECTOR_TYPE_LFM2A, "lfm2a"},
|
||||
{ PROJECTOR_TYPE_GLM4V, "glm4v"},
|
||||
};
|
||||
|
||||
|
|
|
|||
|
|
@ -4,6 +4,7 @@
|
|||
#include "clip.h"
|
||||
#include "clip-impl.h"
|
||||
|
||||
#include <array>
|
||||
#include <vector>
|
||||
#include <unordered_set>
|
||||
#include <cstdint>
|
||||
|
|
@ -142,6 +143,30 @@ struct clip_layer {
|
|||
ggml_tensor * deepstack_fc2_w = nullptr;
|
||||
ggml_tensor * deepstack_fc2_b = nullptr;
|
||||
|
||||
// lfm2
|
||||
ggml_tensor * ff_norm_w = nullptr;
|
||||
ggml_tensor * ff_norm_b = nullptr;
|
||||
ggml_tensor * ff_norm_1_w = nullptr;
|
||||
ggml_tensor * ff_norm_1_b = nullptr;
|
||||
ggml_tensor * ff_up_1_w = nullptr;
|
||||
ggml_tensor * ff_up_1_b = nullptr;
|
||||
ggml_tensor * ff_down_1_w = nullptr;
|
||||
ggml_tensor * ff_down_1_b = nullptr;
|
||||
ggml_tensor * pos_bias_u = nullptr;
|
||||
ggml_tensor * pos_bias_v = nullptr;
|
||||
ggml_tensor * norm_conv_w = nullptr;
|
||||
ggml_tensor * norm_conv_b = nullptr;
|
||||
ggml_tensor * linear_pos_w = nullptr;
|
||||
|
||||
ggml_tensor * conv_norm_w = nullptr;
|
||||
ggml_tensor * conv_norm_b = nullptr;
|
||||
ggml_tensor * conv_dw_w = nullptr;
|
||||
ggml_tensor * conv_dw_b = nullptr;
|
||||
ggml_tensor * conv_pw1_w = nullptr;
|
||||
ggml_tensor * conv_pw1_b = nullptr;
|
||||
ggml_tensor * conv_pw2_w = nullptr;
|
||||
ggml_tensor * conv_pw2_b = nullptr;
|
||||
|
||||
bool has_deepstack() const {
|
||||
return deepstack_fc1_w != nullptr;
|
||||
}
|
||||
|
|
@ -286,6 +311,12 @@ struct clip_model {
|
|||
ggml_tensor * mm_boi = nullptr;
|
||||
ggml_tensor * mm_eoi = nullptr;
|
||||
|
||||
// lfm2 audio
|
||||
std::array<ggml_tensor *, 7> pre_encode_conv_X_w = {nullptr};
|
||||
std::array<ggml_tensor *, 7> pre_encode_conv_X_b = {nullptr};
|
||||
ggml_tensor * pre_encode_out_w = nullptr;
|
||||
ggml_tensor * pre_encode_out_b = nullptr;
|
||||
|
||||
bool audio_has_avgpool() const {
|
||||
return proj_type == PROJECTOR_TYPE_QWEN2A
|
||||
|| proj_type == PROJECTOR_TYPE_VOXTRAL;
|
||||
|
|
|
|||
|
|
@ -837,6 +837,10 @@ static ggml_cgraph * clip_image_build_graph(clip_ctx * ctx, const clip_image_f32
|
|||
{
|
||||
builder = std::make_unique<clip_graph_llava>(ctx, img);
|
||||
} break;
|
||||
case PROJECTOR_TYPE_LFM2A:
|
||||
{
|
||||
builder = std::make_unique<clip_graph_conformer>(ctx, img);
|
||||
} break;
|
||||
case PROJECTOR_TYPE_GLM4V:
|
||||
{
|
||||
builder = std::make_unique<clip_graph_glm4v>(ctx, img);
|
||||
|
|
@ -1187,6 +1191,15 @@ struct clip_model_loader {
|
|||
hparams.audio_window_len = 400;
|
||||
hparams.audio_hop_len = 160;
|
||||
} break;
|
||||
case PROJECTOR_TYPE_LFM2A:
|
||||
{
|
||||
// audio preprocessing params
|
||||
hparams.audio_chunk_len = 1; // in seconds
|
||||
hparams.audio_sample_rate = 16000;
|
||||
hparams.audio_n_fft = 512;
|
||||
hparams.audio_window_len = 400;
|
||||
hparams.audio_hop_len = 160;
|
||||
} break;
|
||||
default:
|
||||
break;
|
||||
}
|
||||
|
|
@ -1611,6 +1624,52 @@ struct clip_model_loader {
|
|||
model.mm_1_w = get_tensor(string_format(TN_LLAVA_PROJ, 1, "weight"));
|
||||
model.mm_1_b = get_tensor(string_format(TN_LLAVA_PROJ, 1, "bias"));
|
||||
} break;
|
||||
case PROJECTOR_TYPE_LFM2A:
|
||||
{
|
||||
for (int i : {0, 2, 3, 5, 6}) {
|
||||
model.pre_encode_conv_X_w[i] = get_tensor(string_format(TN_CONV1D, i, "weight"));
|
||||
model.pre_encode_conv_X_b[i] = get_tensor(string_format(TN_CONV1D, i, "bias"));
|
||||
}
|
||||
model.pre_encode_out_w = get_tensor(string_format(TN_PRE_ENCODE_OUT, "weight"));
|
||||
model.pre_encode_out_b = get_tensor(string_format(TN_PRE_ENCODE_OUT, "bias"));
|
||||
|
||||
model.mm_0_w = get_tensor(string_format(TN_MM_AUDIO_MLP, 0, "weight"));
|
||||
model.mm_0_b = get_tensor(string_format(TN_MM_AUDIO_MLP, 0, "bias"));
|
||||
model.mm_1_w = get_tensor(string_format(TN_MM_AUDIO_MLP, 1, "weight"));
|
||||
model.mm_1_b = get_tensor(string_format(TN_MM_AUDIO_MLP, 1, "bias"));
|
||||
model.mm_3_w = get_tensor(string_format(TN_MM_AUDIO_MLP, 3, "weight"));
|
||||
model.mm_3_b = get_tensor(string_format(TN_MM_AUDIO_MLP, 3, "bias"));
|
||||
|
||||
for (int il = 0; il < hparams.n_layer; ++il) {
|
||||
auto & layer = model.layers[il];
|
||||
|
||||
layer.ff_norm_w = get_tensor(string_format(TN_FFN_NORM, prefix, il, "weight"));
|
||||
layer.ff_norm_b = get_tensor(string_format(TN_FFN_NORM, prefix, il, "bias"));
|
||||
layer.ff_norm_1_w = get_tensor(string_format(TN_FFN_NORM_1, prefix, il, "weight"));
|
||||
layer.ff_norm_1_b = get_tensor(string_format(TN_FFN_NORM_1, prefix, il, "bias"));
|
||||
layer.ff_up_1_w = get_tensor(string_format(TN_FFN_UP_1, prefix, il, "weight"));
|
||||
layer.ff_up_1_b = get_tensor(string_format(TN_FFN_UP_1, prefix, il, "bias"));
|
||||
layer.ff_down_1_w = get_tensor(string_format(TN_FFN_DOWN_1, prefix, il, "weight"));
|
||||
layer.ff_down_1_b = get_tensor(string_format(TN_FFN_DOWN_1, prefix, il, "bias"));
|
||||
|
||||
layer.pos_bias_u = get_tensor(string_format(TN_POS_BIAS_U, prefix, il));
|
||||
layer.pos_bias_v = get_tensor(string_format(TN_POS_BIAS_V, prefix, il));
|
||||
|
||||
layer.norm_conv_w = get_tensor(string_format(TN_NORM_CONV, prefix, il, "weight"));
|
||||
layer.norm_conv_b = get_tensor(string_format(TN_NORM_CONV, prefix, il, "bias"));
|
||||
|
||||
layer.linear_pos_w = get_tensor(string_format(TN_LINEAR_POS, prefix, il, "weight"));
|
||||
|
||||
layer.conv_norm_w = get_tensor(string_format(TN_CONV_NORM, prefix, il, "weight"));
|
||||
layer.conv_norm_b = get_tensor(string_format(TN_CONV_NORM, prefix, il, "bias"));
|
||||
layer.conv_dw_w = get_tensor(string_format(TN_CONV_DW, prefix, il, "weight"));
|
||||
layer.conv_dw_b = get_tensor(string_format(TN_CONV_DW, prefix, il, "bias"));
|
||||
layer.conv_pw1_w = get_tensor(string_format(TN_CONV_PW1, prefix, il, "weight"));
|
||||
layer.conv_pw1_b = get_tensor(string_format(TN_CONV_PW1, prefix, il, "bias"));
|
||||
layer.conv_pw2_w = get_tensor(string_format(TN_CONV_PW2, prefix, il, "weight"));
|
||||
layer.conv_pw2_b = get_tensor(string_format(TN_CONV_PW2, prefix, il, "bias"));
|
||||
}
|
||||
} break;
|
||||
default:
|
||||
GGML_ASSERT(false && "unknown projector type");
|
||||
}
|
||||
|
|
@ -3004,6 +3063,10 @@ int clip_n_output_tokens(const struct clip_ctx * ctx, struct clip_image_f32 * im
|
|||
{
|
||||
n_patches += 2; // for BOI and EOI token embeddings
|
||||
} break;
|
||||
case PROJECTOR_TYPE_LFM2A:
|
||||
{
|
||||
n_patches = ((((img->nx + 1) / 2) + 1) / 2 + 1) / 2;
|
||||
} break;
|
||||
default:
|
||||
GGML_ABORT("unsupported projector type");
|
||||
}
|
||||
|
|
@ -3362,6 +3425,27 @@ bool clip_image_batch_encode(clip_ctx * ctx, const int n_threads, const clip_ima
|
|||
}
|
||||
set_input_i32("pos_w", pos_data);
|
||||
} break;
|
||||
case PROJECTOR_TYPE_LFM2A:
|
||||
{
|
||||
GGML_ASSERT(imgs.entries.size() == 1);
|
||||
const auto n_frames = clip_n_output_tokens(ctx, imgs.entries.front().get());
|
||||
|
||||
auto d_model = 512;
|
||||
auto seq_len = n_frames * 2 - 1;
|
||||
std::vector<float> pos_emb(d_model*seq_len);
|
||||
std::vector<double> inv_freq(d_model / 2);
|
||||
for (size_t i = 0; i < inv_freq.size(); ++i) {
|
||||
inv_freq[i] = std::exp(-(std::log(10000.0) / (float)d_model) * (2.0f * (float)(i)));
|
||||
}
|
||||
for (int64_t pos = 0; pos < seq_len; ++pos) {
|
||||
for (size_t i = 0; i < inv_freq.size(); ++i) {
|
||||
const float ang = (n_frames - pos - 1) * inv_freq[i];
|
||||
pos_emb[pos*d_model + 2*i + 0] = sinf(ang); // even
|
||||
pos_emb[pos*d_model + 2*i + 1] = cosf(ang); // odd
|
||||
}
|
||||
}
|
||||
set_input_f32("pos_emb", pos_emb);
|
||||
} break;
|
||||
default:
|
||||
GGML_ABORT("Unknown projector type");
|
||||
}
|
||||
|
|
@ -3456,6 +3540,8 @@ int clip_n_mmproj_embd(const struct clip_ctx * ctx) {
|
|||
return ctx->model.mm_2_w->ne[1];
|
||||
case PROJECTOR_TYPE_COGVLM:
|
||||
return ctx->model.mm_4h_to_h_w->ne[1];
|
||||
case PROJECTOR_TYPE_LFM2A:
|
||||
return ctx->model.position_embeddings->ne[0];
|
||||
case PROJECTOR_TYPE_GLM4V:
|
||||
return ctx->model.mm_ffn_down_w->ne[1];
|
||||
default:
|
||||
|
|
|
|||
|
|
@ -0,0 +1,217 @@
|
|||
#include "models.h"
|
||||
|
||||
ggml_cgraph * clip_graph_conformer::build() {
|
||||
const int n_frames = img.nx;
|
||||
const int n_pos = n_frames / 2;
|
||||
const int n_pos_embd = (((((n_frames + 1) / 2) + 1) / 2 + 1) / 2) * 2 - 1;
|
||||
GGML_ASSERT(model.position_embeddings->ne[1] >= n_pos);
|
||||
|
||||
ggml_tensor * pos_emb = ggml_new_tensor_2d(ctx0, GGML_TYPE_F32, 512, n_pos_embd);
|
||||
ggml_set_name(pos_emb, "pos_emb");
|
||||
ggml_set_input(pos_emb);
|
||||
ggml_build_forward_expand(gf, pos_emb);
|
||||
|
||||
ggml_tensor * inp = build_inp_raw(1);
|
||||
cb(inp, "input", -1);
|
||||
|
||||
auto * cur = ggml_cont(ctx0, ggml_transpose(ctx0, inp));
|
||||
|
||||
// pre encode, conv subsampling
|
||||
{
|
||||
// layer.0 - conv2d
|
||||
cur = ggml_conv_2d(ctx0, model.pre_encode_conv_X_w[0], cur, 2, 2, 1, 1, 1, 1);
|
||||
cur = ggml_add(ctx0, cur, model.pre_encode_conv_X_b[0]);
|
||||
cb(cur, "conformer.pre_encode.conv.{}", 0);
|
||||
|
||||
// layer.1 - relu
|
||||
cur = ggml_relu_inplace(ctx0, cur);
|
||||
|
||||
// layer.2 conv2d dw
|
||||
cur = ggml_conv_2d_dw_direct(ctx0, model.pre_encode_conv_X_w[2], cur, 2, 2, 1, 1, 1, 1);
|
||||
cur = ggml_add(ctx0, cur, model.pre_encode_conv_X_b[2]);
|
||||
cb(cur, "conformer.pre_encode.conv.{}", 2);
|
||||
|
||||
// layer.3 conv2d
|
||||
cur = ggml_conv_2d_direct(ctx0, model.pre_encode_conv_X_w[3], cur, 1, 1, 0, 0, 1, 1);
|
||||
cur = ggml_add(ctx0, cur, model.pre_encode_conv_X_b[3]);
|
||||
cb(cur, "conformer.pre_encode.conv.{}", 3);
|
||||
|
||||
// layer.4 - relu
|
||||
cur = ggml_relu_inplace(ctx0, cur);
|
||||
|
||||
// layer.5 conv2d dw
|
||||
cur = ggml_conv_2d_dw_direct(ctx0, model.pre_encode_conv_X_w[5], cur, 2, 2, 1, 1, 1, 1);
|
||||
cur = ggml_add(ctx0, cur, model.pre_encode_conv_X_b[5]);
|
||||
cb(cur, "conformer.pre_encode.conv.{}", 5);
|
||||
|
||||
// layer.6 conv2d
|
||||
cur = ggml_conv_2d_direct(ctx0, model.pre_encode_conv_X_w[6], cur, 1, 1, 0, 0, 1, 1);
|
||||
cur = ggml_add(ctx0, cur, model.pre_encode_conv_X_b[6]);
|
||||
cb(cur, "conformer.pre_encode.conv.{}", 6);
|
||||
|
||||
// layer.7 - relu
|
||||
cur = ggml_relu_inplace(ctx0, cur);
|
||||
|
||||
// flatten channel and frequency axis
|
||||
cur = ggml_cont(ctx0, ggml_permute(ctx0, cur, 0, 2, 1, 3));
|
||||
cur = ggml_reshape_2d(ctx0, cur, cur->ne[0] * cur->ne[1], cur->ne[2]);
|
||||
|
||||
// calculate out
|
||||
cur = ggml_mul_mat(ctx0, model.pre_encode_out_w, cur);
|
||||
cur = ggml_add(ctx0, cur, model.pre_encode_out_b);
|
||||
cb(cur, "conformer.pre_encode.out", -1);
|
||||
}
|
||||
|
||||
// pos_emb
|
||||
cb(pos_emb, "pos_emb", -1);
|
||||
|
||||
for (int il = 0; il < hparams.n_layer; il++) {
|
||||
const auto & layer = model.layers[il];
|
||||
|
||||
auto * residual = cur;
|
||||
|
||||
cb(cur, "layer.in", il);
|
||||
|
||||
// feed_forward1
|
||||
cur = build_norm(cur, layer.ff_norm_w, layer.ff_norm_b, NORM_TYPE_NORMAL, 1e-5, il);
|
||||
cb(cur, "conformer.layers.{}.norm_feed_forward1", il);
|
||||
|
||||
cur = build_ffn(cur, layer.ff_up_w, layer.ff_up_b, nullptr, nullptr, layer.ff_down_w, layer.ff_down_b, FFN_SILU,
|
||||
il);
|
||||
cb(cur, "conformer.layers.{}.feed_forward1.linear2", il);
|
||||
|
||||
const auto fc_factor = 0.5f;
|
||||
residual = ggml_add(ctx0, residual, ggml_scale(ctx0, cur, fc_factor));
|
||||
|
||||
// self-attention
|
||||
{
|
||||
cur = build_norm(residual, layer.ln_1_w, layer.ln_1_b, NORM_TYPE_NORMAL, 1e-5, il);
|
||||
cb(cur, "conformer.layers.{}.norm_self_att", il);
|
||||
|
||||
ggml_tensor * Qcur = ggml_mul_mat(ctx0, layer.q_w, cur);
|
||||
Qcur = ggml_add(ctx0, Qcur, layer.q_b);
|
||||
Qcur = ggml_reshape_3d(ctx0, Qcur, d_head, n_head, Qcur->ne[1]);
|
||||
ggml_tensor * Q_bias_u = ggml_add(ctx0, Qcur, layer.pos_bias_u);
|
||||
Q_bias_u = ggml_permute(ctx0, Q_bias_u, 0, 2, 1, 3);
|
||||
ggml_tensor * Q_bias_v = ggml_add(ctx0, Qcur, layer.pos_bias_v);
|
||||
Q_bias_v = ggml_permute(ctx0, Q_bias_v, 0, 2, 1, 3);
|
||||
|
||||
// TODO @ngxson : some cont can/should be removed when ggml_mul_mat support these cases
|
||||
ggml_tensor * Kcur = ggml_mul_mat(ctx0, layer.k_w, cur);
|
||||
Kcur = ggml_add(ctx0, Kcur, layer.k_b);
|
||||
Kcur = ggml_reshape_3d(ctx0, Kcur, d_head, n_head, Kcur->ne[1]);
|
||||
Kcur = ggml_cont(ctx0, ggml_permute(ctx0, Kcur, 0, 2, 1, 3));
|
||||
|
||||
ggml_tensor * Vcur = ggml_mul_mat(ctx0, layer.v_w, cur);
|
||||
Vcur = ggml_add(ctx0, Vcur, layer.v_b);
|
||||
Vcur = ggml_reshape_3d(ctx0, Vcur, d_head, n_head, Vcur->ne[1]);
|
||||
Vcur = ggml_cont(ctx0, ggml_permute(ctx0, Vcur, 1, 2, 0, 3));
|
||||
|
||||
// build_attn won't fit due to matrix_ac and matrix_bd separation
|
||||
ggml_tensor * matrix_ac = ggml_mul_mat(ctx0, Q_bias_u, Kcur);
|
||||
matrix_ac = ggml_cont(ctx0, ggml_permute(ctx0, matrix_ac, 1, 0, 2, 3));
|
||||
cb(matrix_ac, "conformer.layers.{}.self_attn.id3", il);
|
||||
|
||||
auto * p = ggml_mul_mat(ctx0, layer.linear_pos_w, pos_emb);
|
||||
cb(p, "conformer.layers.{}.self_attn.linear_pos", il);
|
||||
p = ggml_reshape_3d(ctx0, p, d_head, n_head, p->ne[1]);
|
||||
p = ggml_permute(ctx0, p, 0, 2, 1, 3);
|
||||
|
||||
auto * matrix_bd = ggml_mul_mat(ctx0, Q_bias_v, p);
|
||||
matrix_bd = ggml_cont(ctx0, ggml_permute(ctx0, matrix_bd, 1, 0, 2, 3));
|
||||
|
||||
// rel shift
|
||||
{
|
||||
const auto pos_len = matrix_bd->ne[0];
|
||||
const auto q_len = matrix_bd->ne[1];
|
||||
const auto h = matrix_bd->ne[2];
|
||||
matrix_bd = ggml_pad(ctx0, matrix_bd, 1, 0, 0, 0);
|
||||
matrix_bd = ggml_roll(ctx0, matrix_bd, 1, 0, 0, 0);
|
||||
matrix_bd = ggml_reshape_3d(ctx0, matrix_bd, q_len, pos_len + 1, h);
|
||||
matrix_bd = ggml_view_3d(ctx0, matrix_bd, q_len, pos_len, h, matrix_bd->nb[1],
|
||||
matrix_bd->nb[2], matrix_bd->nb[0] * q_len);
|
||||
matrix_bd = ggml_cont_3d(ctx0, matrix_bd, pos_len, q_len, h);
|
||||
}
|
||||
|
||||
matrix_bd = ggml_view_3d(ctx0, matrix_bd, matrix_ac->ne[0], matrix_bd->ne[1],
|
||||
matrix_bd->ne[2], matrix_bd->nb[1], matrix_bd->nb[2], 0);
|
||||
auto * scores = ggml_add(ctx0, matrix_ac, matrix_bd);
|
||||
scores = ggml_scale(ctx0, scores, 1.0f / std::sqrt(d_head));
|
||||
cb(scores, "conformer.layers.{}.self_attn.id0", il);
|
||||
|
||||
ggml_tensor * attn = ggml_soft_max(ctx0, scores);
|
||||
ggml_tensor * x = ggml_mul_mat(ctx0, attn, Vcur);
|
||||
x = ggml_permute(ctx0, x, 2, 0, 1, 3);
|
||||
x = ggml_cont_2d(ctx0, x, x->ne[0] * x->ne[1], x->ne[2]);
|
||||
|
||||
ggml_tensor * out = ggml_mul_mat(ctx0, layer.o_w, x);
|
||||
out = ggml_add(ctx0, out, layer.o_b);
|
||||
cb(out, "conformer.layers.{}.self_attn.linear_out", il);
|
||||
|
||||
cur = out;
|
||||
}
|
||||
|
||||
residual = ggml_add(ctx0, residual, cur);
|
||||
cur = build_norm(residual, layer.norm_conv_w, layer.norm_conv_b, NORM_TYPE_NORMAL, 1e-5, il);
|
||||
cb(cur, "conformer.layers.{}.norm_conv", il);
|
||||
|
||||
// conv
|
||||
{
|
||||
auto * x = cur;
|
||||
x = ggml_mul_mat(ctx0, layer.conv_pw1_w, x);
|
||||
x = ggml_add(ctx0, x, layer.conv_pw1_b);
|
||||
cb(x, "conformer.layers.{}.conv.pointwise_conv1", il);
|
||||
|
||||
// ggml_glu doesn't support sigmoid
|
||||
// TODO @ngxson : support this ops in ggml
|
||||
{
|
||||
int64_t d = x->ne[0] / 2;
|
||||
ggml_tensor * gate = ggml_sigmoid(ctx0, ggml_view_2d(ctx0, x, d, x->ne[1], x->nb[1], d * x->nb[0]));
|
||||
x = ggml_mul(ctx0, ggml_view_2d(ctx0, x, d, x->ne[1], x->nb[1], 0), gate);
|
||||
x = ggml_cont(ctx0, ggml_transpose(ctx0, x));
|
||||
}
|
||||
|
||||
// use ggml_ssm_conv for f32 precision
|
||||
x = ggml_pad(ctx0, x, 4, 0, 0, 0);
|
||||
x = ggml_roll(ctx0, x, 4, 0, 0, 0);
|
||||
x = ggml_pad(ctx0, x, 4, 0, 0, 0);
|
||||
x = ggml_ssm_conv(ctx0, x, layer.conv_dw_w);
|
||||
x = ggml_add(ctx0, x, layer.conv_dw_b);
|
||||
|
||||
x = ggml_add(ctx0, ggml_mul(ctx0, x, layer.conv_norm_w), layer.conv_norm_b);
|
||||
x = ggml_silu(ctx0, x);
|
||||
|
||||
// pointwise_conv2
|
||||
x = ggml_mul_mat(ctx0, layer.conv_pw2_w, x);
|
||||
x = ggml_add(ctx0, x, layer.conv_pw2_b);
|
||||
|
||||
cur = x;
|
||||
}
|
||||
|
||||
residual = ggml_add(ctx0, residual, cur);
|
||||
|
||||
cur = build_norm(residual, layer.ff_norm_1_w, layer.ff_norm_1_b, NORM_TYPE_NORMAL, 1e-5, il);
|
||||
cb(cur, "conformer.layers.{}.norm_feed_forward2", il);
|
||||
|
||||
cur = build_ffn(cur, layer.ff_up_1_w, layer.ff_up_1_b, nullptr, nullptr, layer.ff_down_1_w, layer.ff_down_1_b,
|
||||
FFN_SILU, il); // TODO(tarek): read activation for ffn from hparams
|
||||
cb(cur, "conformer.layers.{}.feed_forward2.linear2", il);
|
||||
|
||||
residual = ggml_add(ctx0, residual, ggml_scale(ctx0, cur, fc_factor));
|
||||
cb(residual, "conformer.layers.{}.conv.id", il);
|
||||
|
||||
cur = build_norm(residual, layer.ln_2_w, layer.ln_2_b, NORM_TYPE_NORMAL, 1e-5, il);
|
||||
cb(cur, "conformer.layers.{}.norm_out", il);
|
||||
}
|
||||
|
||||
// audio adapter
|
||||
cur = build_norm(cur, model.mm_0_w, model.mm_0_b, NORM_TYPE_NORMAL, 1e-5, -1);
|
||||
cb(cur, "audio_adapter.model.{}", 0);
|
||||
cur = build_ffn(cur, model.mm_1_w, model.mm_1_b, nullptr, nullptr, model.mm_3_w, model.mm_3_b, FFN_GELU_ERF, -1);
|
||||
|
||||
cb(cur, "projected", -1);
|
||||
|
||||
ggml_build_forward_expand(gf, cur);
|
||||
|
||||
return gf;
|
||||
}
|
||||
|
|
@ -57,6 +57,11 @@ struct clip_graph_whisper_enc : clip_graph {
|
|||
ggml_cgraph * build() override;
|
||||
};
|
||||
|
||||
struct clip_graph_conformer : clip_graph {
|
||||
clip_graph_conformer(clip_ctx * ctx, const clip_image_f32 & img) : clip_graph(ctx, img) {}
|
||||
ggml_cgraph * build() override;
|
||||
};
|
||||
|
||||
struct clip_graph_glm4v : clip_graph {
|
||||
clip_graph_glm4v(clip_ctx * ctx, const clip_image_f32 & img) : clip_graph(ctx, img) {}
|
||||
ggml_cgraph * build() override;
|
||||
|
|
|
|||
|
|
@ -535,3 +535,56 @@ bool mtmd_audio_preprocessor_whisper::preprocess(
|
|||
|
||||
return true;
|
||||
}
|
||||
|
||||
//
|
||||
// mtmd_audio_preprocessor_conformer
|
||||
//
|
||||
|
||||
void mtmd_audio_preprocessor_conformer::initialize() {
|
||||
g_cache.fill_sin_cos_table(hparams.audio_n_fft);
|
||||
g_cache.fill_hann_window(hparams.audio_window_len, true);
|
||||
g_cache.fill_mel_filterbank_matrix(
|
||||
hparams.n_mel_bins,
|
||||
hparams.audio_n_fft,
|
||||
hparams.audio_sample_rate);
|
||||
}
|
||||
|
||||
bool mtmd_audio_preprocessor_conformer::preprocess(
|
||||
const float * samples,
|
||||
size_t n_samples,
|
||||
std::vector<mtmd_audio_mel> & output) {
|
||||
// empty audio
|
||||
if (n_samples == 0) {
|
||||
return false;
|
||||
}
|
||||
|
||||
filter_params params;
|
||||
params.n_mel = hparams.n_mel_bins;
|
||||
params.n_fft_bins = 1 + (hparams.audio_n_fft / 2);
|
||||
params.hann_window_size = hparams.audio_window_len;
|
||||
params.hop_length = hparams.audio_hop_len;
|
||||
params.sample_rate = hparams.audio_sample_rate;
|
||||
params.center_padding = true;
|
||||
params.preemph = 0.97f;
|
||||
params.use_natural_log = true;
|
||||
params.norm_per_feature = true;
|
||||
|
||||
// make sure the global cache is initialized
|
||||
GGML_ASSERT(!g_cache.sin_vals.empty());
|
||||
GGML_ASSERT(!g_cache.cos_vals.empty());
|
||||
GGML_ASSERT(!g_cache.filters.data.empty());
|
||||
|
||||
mtmd_audio_mel out_full;
|
||||
bool ok = log_mel_spectrogram(
|
||||
samples,
|
||||
n_samples,
|
||||
4, // n_threads
|
||||
params,
|
||||
out_full);
|
||||
if (!ok) {
|
||||
return false;
|
||||
}
|
||||
|
||||
output.push_back(std::move(out_full));
|
||||
return true;
|
||||
}
|
||||
|
|
|
|||
|
|
@ -32,3 +32,9 @@ struct mtmd_audio_preprocessor_whisper : mtmd_audio_preprocessor {
|
|||
void initialize() override;
|
||||
bool preprocess(const float * samples, size_t n_samples, std::vector<mtmd_audio_mel> & output) override;
|
||||
};
|
||||
|
||||
struct mtmd_audio_preprocessor_conformer : mtmd_audio_preprocessor {
|
||||
mtmd_audio_preprocessor_conformer(const clip_ctx * ctx) : mtmd_audio_preprocessor(ctx) {}
|
||||
void initialize() override;
|
||||
bool preprocess(const float * samples, size_t n_samples, std::vector<mtmd_audio_mel> & output) override;
|
||||
};
|
||||
|
|
|
|||
|
|
@ -309,9 +309,24 @@ int main(int argc, char ** argv) {
|
|||
|
||||
if (g_is_interrupted) return 130;
|
||||
|
||||
auto eval_system_prompt_if_present = [&] {
|
||||
if (params.system_prompt.empty()) {
|
||||
return 0;
|
||||
}
|
||||
|
||||
common_chat_msg msg;
|
||||
msg.role = "system";
|
||||
msg.content = params.system_prompt;
|
||||
return eval_message(ctx, msg);
|
||||
};
|
||||
|
||||
LOG_WRN("WARN: This is an experimental CLI for testing multimodal capability.\n");
|
||||
LOG_WRN(" For normal use cases, please use the standard llama-cli\n");
|
||||
|
||||
if (eval_system_prompt_if_present()) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
if (is_single_turn) {
|
||||
g_is_generating = true;
|
||||
if (params.prompt.find(mtmd_default_marker()) == std::string::npos) {
|
||||
|
|
@ -321,6 +336,7 @@ int main(int argc, char ** argv) {
|
|||
params.prompt = mtmd_default_marker() + params.prompt;
|
||||
}
|
||||
}
|
||||
|
||||
common_chat_msg msg;
|
||||
msg.role = "user";
|
||||
msg.content = params.prompt;
|
||||
|
|
@ -369,6 +385,9 @@ int main(int argc, char ** argv) {
|
|||
ctx.n_past = 0;
|
||||
ctx.chat_history.clear();
|
||||
llama_memory_clear(llama_get_memory(ctx.lctx), true);
|
||||
if (eval_system_prompt_if_present()) {
|
||||
return 1;
|
||||
}
|
||||
LOG("Chat history cleared\n\n");
|
||||
continue;
|
||||
}
|
||||
|
|
|
|||
|
|
@ -332,6 +332,9 @@ struct mtmd_context {
|
|||
case PROJECTOR_TYPE_GLMA:
|
||||
audio_preproc = std::make_unique<mtmd_audio_preprocessor_whisper>(ctx_a);
|
||||
break;
|
||||
case PROJECTOR_TYPE_LFM2A:
|
||||
audio_preproc = std::make_unique<mtmd_audio_preprocessor_conformer>(ctx_a);
|
||||
break;
|
||||
default:
|
||||
GGML_ABORT("unsupported audio projector type");
|
||||
}
|
||||
|
|
|
|||
|
|
@ -84,6 +84,7 @@ add_test_vision "ggml-org/LightOnOCR-1B-1025-GGUF:Q8_0"
|
|||
add_test_audio "ggml-org/ultravox-v0_5-llama-3_2-1b-GGUF:Q8_0"
|
||||
add_test_audio "ggml-org/Qwen2.5-Omni-3B-GGUF:Q4_K_M"
|
||||
add_test_audio "ggml-org/Voxtral-Mini-3B-2507-GGUF:Q4_K_M"
|
||||
add_test_audio "ggml-org/LFM2-Audio-1.5B-GGUF:Q8_0"
|
||||
|
||||
# to test the big models, run: ./tests.sh big
|
||||
if [ "$RUN_BIG_TESTS" = true ]; then
|
||||
|
|
|
|||
Binary file not shown.
|
|
@ -2109,9 +2109,9 @@
|
|||
}
|
||||
},
|
||||
"node_modules/@sveltejs/kit": {
|
||||
"version": "2.48.5",
|
||||
"resolved": "https://registry.npmjs.org/@sveltejs/kit/-/kit-2.48.5.tgz",
|
||||
"integrity": "sha512-/rnwfSWS3qwUSzvHynUTORF9xSJi7PCR9yXkxUOnRrNqyKmCmh3FPHH+E9BbgqxXfTevGXBqgnlh9kMb+9T5XA==",
|
||||
"version": "2.49.2",
|
||||
"resolved": "https://registry.npmjs.org/@sveltejs/kit/-/kit-2.49.2.tgz",
|
||||
"integrity": "sha512-Vp3zX/qlwerQmHMP6x0Ry1oY7eKKRcOWGc2P59srOp4zcqyn+etJyQpELgOi4+ZSUgteX8Y387NuwruLgGXLUQ==",
|
||||
"dev": true,
|
||||
"license": "MIT",
|
||||
"dependencies": {
|
||||
|
|
@ -5797,9 +5797,9 @@
|
|||
}
|
||||
},
|
||||
"node_modules/mdast-util-to-hast": {
|
||||
"version": "13.2.0",
|
||||
"resolved": "https://registry.npmjs.org/mdast-util-to-hast/-/mdast-util-to-hast-13.2.0.tgz",
|
||||
"integrity": "sha512-QGYKEuUsYT9ykKBCMOEDLsU5JRObWQusAolFMeko/tYPufNkRffBAQjIE+99jbA87xv6FgmjLtwjh9wBWajwAA==",
|
||||
"version": "13.2.1",
|
||||
"resolved": "https://registry.npmjs.org/mdast-util-to-hast/-/mdast-util-to-hast-13.2.1.tgz",
|
||||
"integrity": "sha512-cctsq2wp5vTsLIcaymblUriiTcZd0CwWtCbLvrOzYCDZoWyMNV8sZ7krj09FSnsiJi3WVsHLM4k6Dq/yaPyCXA==",
|
||||
"license": "MIT",
|
||||
"dependencies": {
|
||||
"@types/hast": "^3.0.0",
|
||||
|
|
|
|||
|
|
@ -124,3 +124,10 @@ declare global {
|
|||
SettingsConfigType
|
||||
};
|
||||
}
|
||||
|
||||
declare global {
|
||||
interface Window {
|
||||
idxThemeStyle?: number;
|
||||
idxCodeBlock?: number;
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -244,7 +244,7 @@
|
|||
|
||||
<div class="info my-6 grid gap-4">
|
||||
{#if displayedModel()}
|
||||
<span class="inline-flex flex-wrap items-center gap-2 text-xs text-muted-foreground">
|
||||
<div class="inline-flex flex-wrap items-start gap-2 text-xs text-muted-foreground">
|
||||
{#if isRouter}
|
||||
<ModelsSelector
|
||||
currentModel={displayedModel()}
|
||||
|
|
@ -258,11 +258,13 @@
|
|||
|
||||
{#if currentConfig.showMessageStats && message.timings && message.timings.predicted_n && message.timings.predicted_ms}
|
||||
<ChatMessageStatistics
|
||||
promptTokens={message.timings.prompt_n}
|
||||
promptMs={message.timings.prompt_ms}
|
||||
predictedTokens={message.timings.predicted_n}
|
||||
predictedMs={message.timings.predicted_ms}
|
||||
/>
|
||||
{/if}
|
||||
</span>
|
||||
</div>
|
||||
{/if}
|
||||
|
||||
{#if config().showToolCalls}
|
||||
|
|
|
|||
|
|
@ -1,20 +1,122 @@
|
|||
<script lang="ts">
|
||||
import { Clock, Gauge, WholeWord } from '@lucide/svelte';
|
||||
import { Clock, Gauge, WholeWord, BookOpenText, Sparkles } from '@lucide/svelte';
|
||||
import { BadgeChatStatistic } from '$lib/components/app';
|
||||
import * as Tooltip from '$lib/components/ui/tooltip';
|
||||
import { ChatMessageStatsView } from '$lib/enums';
|
||||
|
||||
interface Props {
|
||||
predictedTokens: number;
|
||||
predictedMs: number;
|
||||
promptTokens?: number;
|
||||
promptMs?: number;
|
||||
}
|
||||
|
||||
let { predictedTokens, predictedMs }: Props = $props();
|
||||
let { predictedTokens, predictedMs, promptTokens, promptMs }: Props = $props();
|
||||
|
||||
let activeView: ChatMessageStatsView = $state(ChatMessageStatsView.GENERATION);
|
||||
|
||||
let tokensPerSecond = $derived((predictedTokens / predictedMs) * 1000);
|
||||
let timeInSeconds = $derived((predictedMs / 1000).toFixed(2));
|
||||
|
||||
let promptTokensPerSecond = $derived(
|
||||
promptTokens !== undefined && promptMs !== undefined
|
||||
? (promptTokens / promptMs) * 1000
|
||||
: undefined
|
||||
);
|
||||
|
||||
let promptTimeInSeconds = $derived(
|
||||
promptMs !== undefined ? (promptMs / 1000).toFixed(2) : undefined
|
||||
);
|
||||
|
||||
let hasPromptStats = $derived(
|
||||
promptTokens !== undefined &&
|
||||
promptMs !== undefined &&
|
||||
promptTokensPerSecond !== undefined &&
|
||||
promptTimeInSeconds !== undefined
|
||||
);
|
||||
</script>
|
||||
|
||||
<BadgeChatStatistic icon={WholeWord} value="{predictedTokens} tokens" />
|
||||
<div class="inline-flex items-center text-xs text-muted-foreground">
|
||||
<div class="inline-flex items-center rounded-sm bg-muted-foreground/15 p-0.5">
|
||||
{#if hasPromptStats}
|
||||
<Tooltip.Root>
|
||||
<Tooltip.Trigger>
|
||||
<button
|
||||
type="button"
|
||||
class="inline-flex h-5 w-5 items-center justify-center rounded-sm transition-colors {activeView ===
|
||||
ChatMessageStatsView.READING
|
||||
? 'bg-background text-foreground shadow-sm'
|
||||
: 'hover:text-foreground'}"
|
||||
onclick={() => (activeView = ChatMessageStatsView.READING)}
|
||||
>
|
||||
<BookOpenText class="h-3 w-3" />
|
||||
<span class="sr-only">Reading</span>
|
||||
</button>
|
||||
</Tooltip.Trigger>
|
||||
<Tooltip.Content>
|
||||
<p>Reading (prompt processing)</p>
|
||||
</Tooltip.Content>
|
||||
</Tooltip.Root>
|
||||
{/if}
|
||||
<Tooltip.Root>
|
||||
<Tooltip.Trigger>
|
||||
<button
|
||||
type="button"
|
||||
class="inline-flex h-5 w-5 items-center justify-center rounded-sm transition-colors {activeView ===
|
||||
ChatMessageStatsView.GENERATION
|
||||
? 'bg-background text-foreground shadow-sm'
|
||||
: 'hover:text-foreground'}"
|
||||
onclick={() => (activeView = ChatMessageStatsView.GENERATION)}
|
||||
>
|
||||
<Sparkles class="h-3 w-3" />
|
||||
<span class="sr-only">Generation</span>
|
||||
</button>
|
||||
</Tooltip.Trigger>
|
||||
<Tooltip.Content>
|
||||
<p>Generation (token output)</p>
|
||||
</Tooltip.Content>
|
||||
</Tooltip.Root>
|
||||
</div>
|
||||
|
||||
<BadgeChatStatistic icon={Clock} value="{timeInSeconds}s" />
|
||||
|
||||
<BadgeChatStatistic icon={Gauge} value="{tokensPerSecond.toFixed(2)} tokens/s" />
|
||||
<div class="flex items-center gap-1 px-2">
|
||||
{#if activeView === ChatMessageStatsView.GENERATION}
|
||||
<BadgeChatStatistic
|
||||
class="bg-transparent"
|
||||
icon={WholeWord}
|
||||
value="{predictedTokens} tokens"
|
||||
tooltipLabel="Generated tokens"
|
||||
/>
|
||||
<BadgeChatStatistic
|
||||
class="bg-transparent"
|
||||
icon={Clock}
|
||||
value="{timeInSeconds}s"
|
||||
tooltipLabel="Generation time"
|
||||
/>
|
||||
<BadgeChatStatistic
|
||||
class="bg-transparent"
|
||||
icon={Gauge}
|
||||
value="{tokensPerSecond.toFixed(2)} tokens/s"
|
||||
tooltipLabel="Generation speed"
|
||||
/>
|
||||
{:else if hasPromptStats}
|
||||
<BadgeChatStatistic
|
||||
class="bg-transparent"
|
||||
icon={WholeWord}
|
||||
value="{promptTokens} tokens"
|
||||
tooltipLabel="Prompt tokens"
|
||||
/>
|
||||
<BadgeChatStatistic
|
||||
class="bg-transparent"
|
||||
icon={Clock}
|
||||
value="{promptTimeInSeconds}s"
|
||||
tooltipLabel="Prompt processing time"
|
||||
/>
|
||||
<BadgeChatStatistic
|
||||
class="bg-transparent"
|
||||
icon={Gauge}
|
||||
value="{promptTokensPerSecond!.toFixed(2)} tokens/s"
|
||||
tooltipLabel="Prompt processing speed"
|
||||
/>
|
||||
{/if}
|
||||
</div>
|
||||
</div>
|
||||
|
|
|
|||
|
|
@ -587,7 +587,7 @@
|
|||
|
||||
&::after {
|
||||
content: '';
|
||||
position: fixed;
|
||||
position: absolute;
|
||||
bottom: 0;
|
||||
z-index: -1;
|
||||
left: 0;
|
||||
|
|
|
|||
|
|
@ -1,5 +1,6 @@
|
|||
<script lang="ts">
|
||||
import { BadgeInfo } from '$lib/components/app';
|
||||
import * as Tooltip from '$lib/components/ui/tooltip';
|
||||
import { copyToClipboard } from '$lib/utils';
|
||||
import type { Component } from 'svelte';
|
||||
|
||||
|
|
@ -7,19 +8,37 @@
|
|||
class?: string;
|
||||
icon: Component;
|
||||
value: string | number;
|
||||
tooltipLabel?: string;
|
||||
}
|
||||
|
||||
let { class: className = '', icon: Icon, value }: Props = $props();
|
||||
let { class: className = '', icon: Icon, value, tooltipLabel }: Props = $props();
|
||||
|
||||
function handleClick() {
|
||||
void copyToClipboard(String(value));
|
||||
}
|
||||
</script>
|
||||
|
||||
<BadgeInfo class={className} onclick={handleClick}>
|
||||
{#snippet icon()}
|
||||
<Icon class="h-3 w-3" />
|
||||
{/snippet}
|
||||
{#if tooltipLabel}
|
||||
<Tooltip.Root>
|
||||
<Tooltip.Trigger>
|
||||
<BadgeInfo class={className} onclick={handleClick}>
|
||||
{#snippet icon()}
|
||||
<Icon class="h-3 w-3" />
|
||||
{/snippet}
|
||||
|
||||
{value}
|
||||
</BadgeInfo>
|
||||
{value}
|
||||
</BadgeInfo>
|
||||
</Tooltip.Trigger>
|
||||
<Tooltip.Content>
|
||||
<p>{tooltipLabel}</p>
|
||||
</Tooltip.Content>
|
||||
</Tooltip.Root>
|
||||
{:else}
|
||||
<BadgeInfo class={className} onclick={handleClick}>
|
||||
{#snippet icon()}
|
||||
<Icon class="h-3 w-3" />
|
||||
{/snippet}
|
||||
|
||||
{value}
|
||||
</BadgeInfo>
|
||||
{/if}
|
||||
|
|
|
|||
|
|
@ -7,15 +7,19 @@
|
|||
import remarkRehype from 'remark-rehype';
|
||||
import rehypeKatex from 'rehype-katex';
|
||||
import rehypeStringify from 'rehype-stringify';
|
||||
import { copyCodeToClipboard, preprocessLaTeX } from '$lib/utils';
|
||||
import { rehypeRestoreTableHtml } from '$lib/markdown/table-html-restorer';
|
||||
import type { Root as HastRoot, RootContent as HastRootContent } from 'hast';
|
||||
import type { Root as MdastRoot } from 'mdast';
|
||||
import { browser } from '$app/environment';
|
||||
import { onDestroy, tick } from 'svelte';
|
||||
import { rehypeRestoreTableHtml } from '$lib/markdown/table-html-restorer';
|
||||
import { rehypeEnhanceLinks } from '$lib/markdown/enhance-links';
|
||||
import { rehypeEnhanceCodeBlocks } from '$lib/markdown/enhance-code-blocks';
|
||||
import { remarkLiteralHtml } from '$lib/markdown/literal-html';
|
||||
import { copyCodeToClipboard, preprocessLaTeX } from '$lib/utils';
|
||||
import '$styles/katex-custom.scss';
|
||||
|
||||
import githubDarkCss from 'highlight.js/styles/github-dark.css?inline';
|
||||
import githubLightCss from 'highlight.js/styles/github.css?inline';
|
||||
import { mode } from 'mode-watcher';
|
||||
import { remarkLiteralHtml } from '$lib/markdown/literal-html';
|
||||
import CodePreviewDialog from './CodePreviewDialog.svelte';
|
||||
|
||||
interface Props {
|
||||
|
|
@ -23,33 +27,24 @@
|
|||
class?: string;
|
||||
}
|
||||
|
||||
interface MarkdownBlock {
|
||||
id: string;
|
||||
html: string;
|
||||
}
|
||||
|
||||
let { content, class: className = '' }: Props = $props();
|
||||
|
||||
let containerRef = $state<HTMLDivElement>();
|
||||
let processedHtml = $state('');
|
||||
let renderedBlocks = $state<MarkdownBlock[]>([]);
|
||||
let unstableBlockHtml = $state('');
|
||||
let previewDialogOpen = $state(false);
|
||||
let previewCode = $state('');
|
||||
let previewLanguage = $state('text');
|
||||
|
||||
function loadHighlightTheme(isDark: boolean) {
|
||||
if (!browser) return;
|
||||
let pendingMarkdown: string | null = null;
|
||||
let isProcessing = false;
|
||||
|
||||
const existingThemes = document.querySelectorAll('style[data-highlight-theme]');
|
||||
existingThemes.forEach((style) => style.remove());
|
||||
|
||||
const style = document.createElement('style');
|
||||
style.setAttribute('data-highlight-theme', 'true');
|
||||
style.textContent = isDark ? githubDarkCss : githubLightCss;
|
||||
|
||||
document.head.appendChild(style);
|
||||
}
|
||||
|
||||
$effect(() => {
|
||||
const currentMode = mode.current;
|
||||
const isDark = currentMode === 'dark';
|
||||
|
||||
loadHighlightTheme(isDark);
|
||||
});
|
||||
const themeStyleId = `highlight-theme-${(window.idxThemeStyle = (window.idxThemeStyle ?? 0) + 1)}`;
|
||||
|
||||
let processor = $derived(() => {
|
||||
return remark()
|
||||
|
|
@ -61,139 +56,64 @@
|
|||
.use(rehypeKatex) // Render math using KaTeX
|
||||
.use(rehypeHighlight) // Add syntax highlighting
|
||||
.use(rehypeRestoreTableHtml) // Restore limited HTML (e.g., <br>, <ul>) inside Markdown tables
|
||||
.use(rehypeStringify); // Convert to HTML string
|
||||
.use(rehypeEnhanceLinks) // Add target="_blank" to links
|
||||
.use(rehypeEnhanceCodeBlocks) // Wrap code blocks with header and actions
|
||||
.use(rehypeStringify, { allowDangerousHtml: true }); // Convert to HTML string
|
||||
});
|
||||
|
||||
function enhanceLinks(html: string): string {
|
||||
if (!html.includes('<a')) {
|
||||
return html;
|
||||
/**
|
||||
* Removes click event listeners from copy and preview buttons.
|
||||
* Called on component destroy.
|
||||
*/
|
||||
function cleanupEventListeners() {
|
||||
if (!containerRef) return;
|
||||
|
||||
const copyButtons = containerRef.querySelectorAll<HTMLButtonElement>('.copy-code-btn');
|
||||
const previewButtons = containerRef.querySelectorAll<HTMLButtonElement>('.preview-code-btn');
|
||||
|
||||
for (const button of copyButtons) {
|
||||
button.removeEventListener('click', handleCopyClick);
|
||||
}
|
||||
|
||||
const tempDiv = document.createElement('div');
|
||||
tempDiv.innerHTML = html;
|
||||
|
||||
// Make all links open in new tabs
|
||||
const linkElements = tempDiv.querySelectorAll('a[href]');
|
||||
let mutated = false;
|
||||
|
||||
for (const link of linkElements) {
|
||||
const target = link.getAttribute('target');
|
||||
const rel = link.getAttribute('rel');
|
||||
|
||||
if (target !== '_blank' || rel !== 'noopener noreferrer') {
|
||||
mutated = true;
|
||||
}
|
||||
|
||||
link.setAttribute('target', '_blank');
|
||||
link.setAttribute('rel', 'noopener noreferrer');
|
||||
}
|
||||
|
||||
return mutated ? tempDiv.innerHTML : html;
|
||||
}
|
||||
|
||||
function enhanceCodeBlocks(html: string): string {
|
||||
if (!html.includes('<pre')) {
|
||||
return html;
|
||||
}
|
||||
|
||||
const tempDiv = document.createElement('div');
|
||||
tempDiv.innerHTML = html;
|
||||
|
||||
const preElements = tempDiv.querySelectorAll('pre');
|
||||
let mutated = false;
|
||||
|
||||
for (const [index, pre] of Array.from(preElements).entries()) {
|
||||
const codeElement = pre.querySelector('code');
|
||||
|
||||
if (!codeElement) {
|
||||
continue;
|
||||
}
|
||||
|
||||
mutated = true;
|
||||
|
||||
let language = 'text';
|
||||
const classList = Array.from(codeElement.classList);
|
||||
|
||||
for (const className of classList) {
|
||||
if (className.startsWith('language-')) {
|
||||
language = className.replace('language-', '');
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
const rawCode = codeElement.textContent || '';
|
||||
const codeId = `code-${Date.now()}-${index}`;
|
||||
codeElement.setAttribute('data-code-id', codeId);
|
||||
codeElement.setAttribute('data-raw-code', rawCode);
|
||||
|
||||
const wrapper = document.createElement('div');
|
||||
wrapper.className = 'code-block-wrapper';
|
||||
|
||||
const header = document.createElement('div');
|
||||
header.className = 'code-block-header';
|
||||
|
||||
const languageLabel = document.createElement('span');
|
||||
languageLabel.className = 'code-language';
|
||||
languageLabel.textContent = language;
|
||||
|
||||
const copyButton = document.createElement('button');
|
||||
copyButton.className = 'copy-code-btn';
|
||||
copyButton.setAttribute('data-code-id', codeId);
|
||||
copyButton.setAttribute('title', 'Copy code');
|
||||
copyButton.setAttribute('type', 'button');
|
||||
|
||||
copyButton.innerHTML = `
|
||||
<svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="lucide lucide-copy-icon lucide-copy"><rect width="14" height="14" x="8" y="8" rx="2" ry="2"/><path d="M4 16c-1.1 0-2-.9-2-2V4c0-1.1.9-2 2-2h10c1.1 0 2 .9 2 2"/></svg>
|
||||
`;
|
||||
|
||||
const actions = document.createElement('div');
|
||||
actions.className = 'code-block-actions';
|
||||
|
||||
actions.appendChild(copyButton);
|
||||
|
||||
if (language.toLowerCase() === 'html') {
|
||||
const previewButton = document.createElement('button');
|
||||
previewButton.className = 'preview-code-btn';
|
||||
previewButton.setAttribute('data-code-id', codeId);
|
||||
previewButton.setAttribute('title', 'Preview code');
|
||||
previewButton.setAttribute('type', 'button');
|
||||
|
||||
previewButton.innerHTML = `
|
||||
<svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="lucide lucide-eye lucide-eye-icon"><path d="M2.062 12.345a1 1 0 0 1 0-.69C3.5 7.73 7.36 5 12 5s8.5 2.73 9.938 6.655a1 1 0 0 1 0 .69C20.5 16.27 16.64 19 12 19s-8.5-2.73-9.938-6.655"/><circle cx="12" cy="12" r="3"/></svg>
|
||||
`;
|
||||
|
||||
actions.appendChild(previewButton);
|
||||
}
|
||||
|
||||
header.appendChild(languageLabel);
|
||||
header.appendChild(actions);
|
||||
wrapper.appendChild(header);
|
||||
|
||||
const clonedPre = pre.cloneNode(true) as HTMLElement;
|
||||
wrapper.appendChild(clonedPre);
|
||||
|
||||
pre.parentNode?.replaceChild(wrapper, pre);
|
||||
}
|
||||
|
||||
return mutated ? tempDiv.innerHTML : html;
|
||||
}
|
||||
|
||||
async function processMarkdown(text: string): Promise<string> {
|
||||
try {
|
||||
let normalized = preprocessLaTeX(text);
|
||||
const result = await processor().process(normalized);
|
||||
const html = String(result);
|
||||
const enhancedLinks = enhanceLinks(html);
|
||||
|
||||
return enhanceCodeBlocks(enhancedLinks);
|
||||
} catch (error) {
|
||||
console.error('Markdown processing error:', error);
|
||||
|
||||
// Fallback to plain text with line breaks
|
||||
return text.replace(/\n/g, '<br>');
|
||||
for (const button of previewButtons) {
|
||||
button.removeEventListener('click', handlePreviewClick);
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Removes this component's highlight.js theme style from the document head.
|
||||
* Called on component destroy to clean up injected styles.
|
||||
*/
|
||||
function cleanupHighlightTheme() {
|
||||
if (!browser) return;
|
||||
|
||||
const existingTheme = document.getElementById(themeStyleId);
|
||||
existingTheme?.remove();
|
||||
}
|
||||
|
||||
/**
|
||||
* Loads the appropriate highlight.js theme based on dark/light mode.
|
||||
* Injects a scoped style element into the document head.
|
||||
* @param isDark - Whether to load the dark theme (true) or light theme (false)
|
||||
*/
|
||||
function loadHighlightTheme(isDark: boolean) {
|
||||
if (!browser) return;
|
||||
|
||||
const existingTheme = document.getElementById(themeStyleId);
|
||||
existingTheme?.remove();
|
||||
|
||||
const style = document.createElement('style');
|
||||
style.id = themeStyleId;
|
||||
style.textContent = isDark ? githubDarkCss : githubLightCss;
|
||||
|
||||
document.head.appendChild(style);
|
||||
}
|
||||
|
||||
/**
|
||||
* Extracts code information from a button click target within a code block.
|
||||
* @param target - The clicked button element
|
||||
* @returns Object with rawCode and language, or null if extraction fails
|
||||
*/
|
||||
function getCodeInfoFromTarget(target: HTMLElement) {
|
||||
const wrapper = target.closest('.code-block-wrapper');
|
||||
|
||||
|
|
@ -209,12 +129,7 @@
|
|||
return null;
|
||||
}
|
||||
|
||||
const rawCode = codeElement.getAttribute('data-raw-code');
|
||||
|
||||
if (rawCode === null) {
|
||||
console.error('No raw code found');
|
||||
return null;
|
||||
}
|
||||
const rawCode = codeElement.textContent ?? '';
|
||||
|
||||
const languageLabel = wrapper.querySelector<HTMLElement>('.code-language');
|
||||
const language = languageLabel?.textContent?.trim() || 'text';
|
||||
|
|
@ -222,6 +137,28 @@
|
|||
return { rawCode, language };
|
||||
}
|
||||
|
||||
/**
|
||||
* Generates a unique identifier for a HAST node based on its position.
|
||||
* Used for stable block identification during incremental rendering.
|
||||
* @param node - The HAST root content node
|
||||
* @param indexFallback - Fallback index if position is unavailable
|
||||
* @returns Unique string identifier for the node
|
||||
*/
|
||||
function getHastNodeId(node: HastRootContent, indexFallback: number): string {
|
||||
const position = node.position;
|
||||
|
||||
if (position?.start?.offset != null && position?.end?.offset != null) {
|
||||
return `hast-${position.start.offset}-${position.end.offset}`;
|
||||
}
|
||||
|
||||
return `${node.type}-${indexFallback}`;
|
||||
}
|
||||
|
||||
/**
|
||||
* Handles click events on copy buttons within code blocks.
|
||||
* Copies the raw code content to the clipboard.
|
||||
* @param event - The click event from the copy button
|
||||
*/
|
||||
async function handleCopyClick(event: Event) {
|
||||
event.preventDefault();
|
||||
event.stopPropagation();
|
||||
|
|
@ -245,6 +182,25 @@
|
|||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Handles preview dialog open state changes.
|
||||
* Clears preview content when dialog is closed.
|
||||
* @param open - Whether the dialog is being opened or closed
|
||||
*/
|
||||
function handlePreviewDialogOpenChange(open: boolean) {
|
||||
previewDialogOpen = open;
|
||||
|
||||
if (!open) {
|
||||
previewCode = '';
|
||||
previewLanguage = 'text';
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Handles click events on preview buttons within HTML code blocks.
|
||||
* Opens a preview dialog with the rendered HTML content.
|
||||
* @param event - The click event from the preview button
|
||||
*/
|
||||
function handlePreviewClick(event: Event) {
|
||||
event.preventDefault();
|
||||
event.stopPropagation();
|
||||
|
|
@ -266,6 +222,61 @@
|
|||
previewDialogOpen = true;
|
||||
}
|
||||
|
||||
/**
|
||||
* Processes markdown content into stable and unstable HTML blocks.
|
||||
* Uses incremental rendering: stable blocks are cached, unstable block is re-rendered.
|
||||
* @param markdown - The raw markdown string to process
|
||||
*/
|
||||
async function processMarkdown(markdown: string) {
|
||||
if (!markdown) {
|
||||
renderedBlocks = [];
|
||||
unstableBlockHtml = '';
|
||||
return;
|
||||
}
|
||||
|
||||
const normalized = preprocessLaTeX(markdown);
|
||||
const processorInstance = processor();
|
||||
const ast = processorInstance.parse(normalized) as MdastRoot;
|
||||
const processedRoot = (await processorInstance.run(ast)) as HastRoot;
|
||||
const processedChildren = processedRoot.children ?? [];
|
||||
const stableCount = Math.max(processedChildren.length - 1, 0);
|
||||
const nextBlocks: MarkdownBlock[] = [];
|
||||
|
||||
for (let index = 0; index < stableCount; index++) {
|
||||
const hastChild = processedChildren[index];
|
||||
const id = getHastNodeId(hastChild, index);
|
||||
const existing = renderedBlocks[index];
|
||||
|
||||
if (existing && existing.id === id) {
|
||||
nextBlocks.push(existing);
|
||||
continue;
|
||||
}
|
||||
|
||||
const html = stringifyProcessedNode(
|
||||
processorInstance,
|
||||
processedRoot,
|
||||
processedChildren[index]
|
||||
);
|
||||
|
||||
nextBlocks.push({ id, html });
|
||||
}
|
||||
|
||||
let unstableHtml = '';
|
||||
|
||||
if (processedChildren.length > stableCount) {
|
||||
const unstableChild = processedChildren[stableCount];
|
||||
unstableHtml = stringifyProcessedNode(processorInstance, processedRoot, unstableChild);
|
||||
}
|
||||
|
||||
renderedBlocks = nextBlocks;
|
||||
await tick(); // Force DOM sync before updating unstable HTML block
|
||||
unstableBlockHtml = unstableHtml;
|
||||
}
|
||||
|
||||
/**
|
||||
* Attaches click event listeners to copy and preview buttons in code blocks.
|
||||
* Uses data-listener-bound attribute to prevent duplicate bindings.
|
||||
*/
|
||||
function setupCodeBlockActions() {
|
||||
if (!containerRef) return;
|
||||
|
||||
|
|
@ -287,40 +298,97 @@
|
|||
}
|
||||
}
|
||||
|
||||
function handlePreviewDialogOpenChange(open: boolean) {
|
||||
previewDialogOpen = open;
|
||||
/**
|
||||
* Converts a single HAST node to an enhanced HTML string.
|
||||
* Applies link and code block enhancements to the output.
|
||||
* @param processorInstance - The remark/rehype processor instance
|
||||
* @param processedRoot - The full processed HAST root (for context)
|
||||
* @param child - The specific HAST child node to stringify
|
||||
* @returns Enhanced HTML string representation of the node
|
||||
*/
|
||||
function stringifyProcessedNode(
|
||||
processorInstance: ReturnType<typeof processor>,
|
||||
processedRoot: HastRoot,
|
||||
child: unknown
|
||||
) {
|
||||
const root: HastRoot = {
|
||||
...(processedRoot as HastRoot),
|
||||
children: [child as never]
|
||||
};
|
||||
|
||||
if (!open) {
|
||||
previewCode = '';
|
||||
previewLanguage = 'text';
|
||||
return processorInstance.stringify(root);
|
||||
}
|
||||
|
||||
/**
|
||||
* Queues markdown for processing with coalescing support.
|
||||
* Only processes the latest markdown when multiple updates arrive quickly.
|
||||
* @param markdown - The markdown content to render
|
||||
*/
|
||||
async function updateRenderedBlocks(markdown: string) {
|
||||
pendingMarkdown = markdown;
|
||||
|
||||
if (isProcessing) {
|
||||
return;
|
||||
}
|
||||
|
||||
isProcessing = true;
|
||||
|
||||
try {
|
||||
while (pendingMarkdown !== null) {
|
||||
const nextMarkdown = pendingMarkdown;
|
||||
pendingMarkdown = null;
|
||||
|
||||
await processMarkdown(nextMarkdown);
|
||||
}
|
||||
} catch (error) {
|
||||
console.error('Failed to process markdown:', error);
|
||||
renderedBlocks = [];
|
||||
unstableBlockHtml = markdown.replace(/\n/g, '<br>');
|
||||
} finally {
|
||||
isProcessing = false;
|
||||
}
|
||||
}
|
||||
|
||||
$effect(() => {
|
||||
if (content) {
|
||||
processMarkdown(content)
|
||||
.then((result) => {
|
||||
processedHtml = result;
|
||||
})
|
||||
.catch((error) => {
|
||||
console.error('Failed to process markdown:', error);
|
||||
processedHtml = content.replace(/\n/g, '<br>');
|
||||
});
|
||||
} else {
|
||||
processedHtml = '';
|
||||
}
|
||||
const currentMode = mode.current;
|
||||
const isDark = currentMode === 'dark';
|
||||
|
||||
loadHighlightTheme(isDark);
|
||||
});
|
||||
|
||||
$effect(() => {
|
||||
if (containerRef && processedHtml) {
|
||||
updateRenderedBlocks(content);
|
||||
});
|
||||
|
||||
$effect(() => {
|
||||
const hasRenderedBlocks = renderedBlocks.length > 0;
|
||||
const hasUnstableBlock = Boolean(unstableBlockHtml);
|
||||
|
||||
if ((hasRenderedBlocks || hasUnstableBlock) && containerRef) {
|
||||
setupCodeBlockActions();
|
||||
}
|
||||
});
|
||||
|
||||
onDestroy(() => {
|
||||
cleanupEventListeners();
|
||||
cleanupHighlightTheme();
|
||||
});
|
||||
</script>
|
||||
|
||||
<div bind:this={containerRef} class={className}>
|
||||
<!-- eslint-disable-next-line no-at-html-tags -->
|
||||
{@html processedHtml}
|
||||
{#each renderedBlocks as block (block.id)}
|
||||
<div class="markdown-block" data-block-id={block.id}>
|
||||
<!-- eslint-disable-next-line no-at-html-tags -->
|
||||
{@html block.html}
|
||||
</div>
|
||||
{/each}
|
||||
|
||||
{#if unstableBlockHtml}
|
||||
<div class="markdown-block markdown-block--unstable" data-block-id="unstable">
|
||||
<!-- eslint-disable-next-line no-at-html-tags -->
|
||||
{@html unstableBlockHtml}
|
||||
</div>
|
||||
{/if}
|
||||
</div>
|
||||
|
||||
<CodePreviewDialog
|
||||
|
|
@ -331,6 +399,11 @@
|
|||
/>
|
||||
|
||||
<style>
|
||||
.markdown-block,
|
||||
.markdown-block--unstable {
|
||||
display: contents;
|
||||
}
|
||||
|
||||
/* Base typography styles */
|
||||
div :global(p:not(:last-child)) {
|
||||
margin-bottom: 1rem;
|
||||
|
|
|
|||
|
|
@ -0,0 +1,4 @@
|
|||
export enum ChatMessageStatsView {
|
||||
GENERATION = 'generation',
|
||||
READING = 'reading'
|
||||
}
|
||||
|
|
@ -1,5 +1,7 @@
|
|||
export { AttachmentType } from './attachment';
|
||||
|
||||
export { ChatMessageStatsView } from './chat';
|
||||
|
||||
export {
|
||||
FileTypeCategory,
|
||||
FileTypeImage,
|
||||
|
|
|
|||
|
|
@ -0,0 +1,162 @@
|
|||
/**
|
||||
* Rehype plugin to enhance code blocks with wrapper, header, and action buttons.
|
||||
*
|
||||
* Wraps <pre><code> elements with a container that includes:
|
||||
* - Language label
|
||||
* - Copy button
|
||||
* - Preview button (for HTML code blocks)
|
||||
*
|
||||
* This operates directly on the HAST tree for better performance,
|
||||
* avoiding the need to stringify and re-parse HTML.
|
||||
*/
|
||||
|
||||
import type { Plugin } from 'unified';
|
||||
import type { Root, Element, ElementContent } from 'hast';
|
||||
import { visit } from 'unist-util-visit';
|
||||
|
||||
declare global {
|
||||
interface Window {
|
||||
idxCodeBlock?: number;
|
||||
}
|
||||
}
|
||||
|
||||
const COPY_ICON_SVG = `<svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="lucide lucide-copy-icon lucide-copy"><rect width="14" height="14" x="8" y="8" rx="2" ry="2"/><path d="M4 16c-1.1 0-2-.9-2-2V4c0-1.1.9-2 2-2h10c1.1 0 2 .9 2 2"/></svg>`;
|
||||
|
||||
const PREVIEW_ICON_SVG = `<svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" viewBox="0 0 24 24" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round" class="lucide lucide-eye lucide-eye-icon"><path d="M2.062 12.345a1 1 0 0 1 0-.69C3.5 7.73 7.36 5 12 5s8.5 2.73 9.938 6.655a1 1 0 0 1 0 .69C20.5 16.27 16.64 19 12 19s-8.5-2.73-9.938-6.655"/><circle cx="12" cy="12" r="3"/></svg>`;
|
||||
|
||||
/**
|
||||
* Creates an SVG element node from raw SVG string.
|
||||
* Since we can't parse HTML in HAST directly, we use the raw property.
|
||||
*/
|
||||
function createRawHtmlElement(html: string): Element {
|
||||
return {
|
||||
type: 'element',
|
||||
tagName: 'span',
|
||||
properties: {},
|
||||
children: [{ type: 'raw', value: html } as unknown as ElementContent]
|
||||
};
|
||||
}
|
||||
|
||||
function createCopyButton(codeId: string): Element {
|
||||
return {
|
||||
type: 'element',
|
||||
tagName: 'button',
|
||||
properties: {
|
||||
className: ['copy-code-btn'],
|
||||
'data-code-id': codeId,
|
||||
title: 'Copy code',
|
||||
type: 'button'
|
||||
},
|
||||
children: [createRawHtmlElement(COPY_ICON_SVG)]
|
||||
};
|
||||
}
|
||||
|
||||
function createPreviewButton(codeId: string): Element {
|
||||
return {
|
||||
type: 'element',
|
||||
tagName: 'button',
|
||||
properties: {
|
||||
className: ['preview-code-btn'],
|
||||
'data-code-id': codeId,
|
||||
title: 'Preview code',
|
||||
type: 'button'
|
||||
},
|
||||
children: [createRawHtmlElement(PREVIEW_ICON_SVG)]
|
||||
};
|
||||
}
|
||||
|
||||
function createHeader(language: string, codeId: string): Element {
|
||||
const actions: Element[] = [createCopyButton(codeId)];
|
||||
|
||||
if (language.toLowerCase() === 'html') {
|
||||
actions.push(createPreviewButton(codeId));
|
||||
}
|
||||
|
||||
return {
|
||||
type: 'element',
|
||||
tagName: 'div',
|
||||
properties: { className: ['code-block-header'] },
|
||||
children: [
|
||||
{
|
||||
type: 'element',
|
||||
tagName: 'span',
|
||||
properties: { className: ['code-language'] },
|
||||
children: [{ type: 'text', value: language }]
|
||||
},
|
||||
{
|
||||
type: 'element',
|
||||
tagName: 'div',
|
||||
properties: { className: ['code-block-actions'] },
|
||||
children: actions
|
||||
}
|
||||
]
|
||||
};
|
||||
}
|
||||
|
||||
function createWrapper(header: Element, preElement: Element): Element {
|
||||
return {
|
||||
type: 'element',
|
||||
tagName: 'div',
|
||||
properties: { className: ['code-block-wrapper'] },
|
||||
children: [header, preElement]
|
||||
};
|
||||
}
|
||||
|
||||
function extractLanguage(codeElement: Element): string {
|
||||
const className = codeElement.properties?.className;
|
||||
if (!Array.isArray(className)) return 'text';
|
||||
|
||||
for (const cls of className) {
|
||||
if (typeof cls === 'string' && cls.startsWith('language-')) {
|
||||
return cls.replace('language-', '');
|
||||
}
|
||||
}
|
||||
|
||||
return 'text';
|
||||
}
|
||||
|
||||
/**
|
||||
* Generates a unique code block ID using a global counter.
|
||||
*/
|
||||
function generateCodeId(): string {
|
||||
if (typeof window !== 'undefined') {
|
||||
return `code-${(window.idxCodeBlock = (window.idxCodeBlock ?? 0) + 1)}`;
|
||||
}
|
||||
// Fallback for SSR - use timestamp + random
|
||||
return `code-${Date.now()}-${Math.random().toString(36).slice(2, 7)}`;
|
||||
}
|
||||
|
||||
/**
|
||||
* Rehype plugin to enhance code blocks with wrapper, header, and action buttons.
|
||||
* This plugin wraps <pre><code> elements with a container that includes:
|
||||
* - Language label
|
||||
* - Copy button
|
||||
* - Preview button (for HTML code blocks)
|
||||
*/
|
||||
export const rehypeEnhanceCodeBlocks: Plugin<[], Root> = () => {
|
||||
return (tree: Root) => {
|
||||
visit(tree, 'element', (node: Element, index, parent) => {
|
||||
if (node.tagName !== 'pre' || !parent || index === undefined) return;
|
||||
|
||||
const codeElement = node.children.find(
|
||||
(child): child is Element => child.type === 'element' && child.tagName === 'code'
|
||||
);
|
||||
|
||||
if (!codeElement) return;
|
||||
|
||||
const language = extractLanguage(codeElement);
|
||||
const codeId = generateCodeId();
|
||||
|
||||
codeElement.properties = {
|
||||
...codeElement.properties,
|
||||
'data-code-id': codeId
|
||||
};
|
||||
|
||||
const header = createHeader(language, codeId);
|
||||
const wrapper = createWrapper(header, node);
|
||||
|
||||
// Replace pre with wrapper in parent
|
||||
(parent.children as ElementContent[])[index] = wrapper;
|
||||
});
|
||||
};
|
||||
};
|
||||
|
|
@ -0,0 +1,33 @@
|
|||
/**
|
||||
* Rehype plugin to enhance links with security attributes.
|
||||
*
|
||||
* Adds target="_blank" and rel="noopener noreferrer" to all anchor elements,
|
||||
* ensuring external links open in new tabs safely.
|
||||
*/
|
||||
|
||||
import type { Plugin } from 'unified';
|
||||
import type { Root, Element } from 'hast';
|
||||
import { visit } from 'unist-util-visit';
|
||||
|
||||
/**
|
||||
* Rehype plugin that adds security attributes to all links.
|
||||
* This plugin ensures external links open in new tabs safely by adding:
|
||||
* - target="_blank"
|
||||
* - rel="noopener noreferrer"
|
||||
*/
|
||||
export const rehypeEnhanceLinks: Plugin<[], Root> = () => {
|
||||
return (tree: Root) => {
|
||||
visit(tree, 'element', (node: Element) => {
|
||||
if (node.tagName !== 'a') return;
|
||||
|
||||
const props = node.properties ?? {};
|
||||
|
||||
// Only modify if href exists
|
||||
if (!props.href) return;
|
||||
|
||||
props.target = '_blank';
|
||||
props.rel = 'noopener noreferrer';
|
||||
node.properties = props;
|
||||
});
|
||||
};
|
||||
};
|
||||
|
|
@ -171,6 +171,7 @@ class ChatStore {
|
|||
updateProcessingStateFromTimings(
|
||||
timingData: {
|
||||
prompt_n: number;
|
||||
prompt_ms?: number;
|
||||
predicted_n: number;
|
||||
predicted_per_second: number;
|
||||
cache_n: number;
|
||||
|
|
@ -212,6 +213,7 @@ class ChatStore {
|
|||
if (message.role === 'assistant' && message.timings) {
|
||||
const restoredState = this.parseTimingData({
|
||||
prompt_n: message.timings.prompt_n || 0,
|
||||
prompt_ms: message.timings.prompt_ms,
|
||||
predicted_n: message.timings.predicted_n || 0,
|
||||
predicted_per_second:
|
||||
message.timings.predicted_n && message.timings.predicted_ms
|
||||
|
|
@ -282,6 +284,7 @@ class ChatStore {
|
|||
|
||||
private parseTimingData(timingData: Record<string, unknown>): ApiProcessingState | null {
|
||||
const promptTokens = (timingData.prompt_n as number) || 0;
|
||||
const promptMs = (timingData.prompt_ms as number) || undefined;
|
||||
const predictedTokens = (timingData.predicted_n as number) || 0;
|
||||
const tokensPerSecond = (timingData.predicted_per_second as number) || 0;
|
||||
const cacheTokens = (timingData.cache_n as number) || 0;
|
||||
|
|
@ -320,6 +323,7 @@ class ChatStore {
|
|||
speculative: false,
|
||||
progressPercent,
|
||||
promptTokens,
|
||||
promptMs,
|
||||
cacheTokens
|
||||
};
|
||||
}
|
||||
|
|
@ -536,6 +540,7 @@ class ChatStore {
|
|||
this.updateProcessingStateFromTimings(
|
||||
{
|
||||
prompt_n: timings?.prompt_n || 0,
|
||||
prompt_ms: timings?.prompt_ms,
|
||||
predicted_n: timings?.predicted_n || 0,
|
||||
predicted_per_second: tokensPerSecond,
|
||||
cache_n: timings?.cache_n || 0,
|
||||
|
|
@ -768,10 +773,11 @@ class ChatStore {
|
|||
content: streamingState.response
|
||||
};
|
||||
if (lastMessage.thinking?.trim()) updateData.thinking = lastMessage.thinking;
|
||||
const lastKnownState = this.getCurrentProcessingStateSync();
|
||||
const lastKnownState = this.getProcessingState(conversationId);
|
||||
if (lastKnownState) {
|
||||
updateData.timings = {
|
||||
prompt_n: lastKnownState.promptTokens || 0,
|
||||
prompt_ms: lastKnownState.promptMs,
|
||||
predicted_n: lastKnownState.tokensDecoded || 0,
|
||||
cache_n: lastKnownState.cacheTokens || 0,
|
||||
predicted_ms:
|
||||
|
|
@ -1253,6 +1259,7 @@ class ChatStore {
|
|||
this.updateProcessingStateFromTimings(
|
||||
{
|
||||
prompt_n: timings?.prompt_n || 0,
|
||||
prompt_ms: timings?.prompt_ms,
|
||||
predicted_n: timings?.predicted_n || 0,
|
||||
predicted_per_second: tokensPerSecond,
|
||||
cache_n: timings?.cache_n || 0,
|
||||
|
|
|
|||
|
|
@ -345,6 +345,7 @@ export interface ApiProcessingState {
|
|||
// Progress information from prompt_progress
|
||||
progressPercent?: number;
|
||||
promptTokens?: number;
|
||||
promptMs?: number;
|
||||
cacheTokens?: number;
|
||||
}
|
||||
|
||||
|
|
|
|||
Loading…
Reference in New Issue