
 -## 检查用户名
+## 检查用户名 { #check-the-username }
以下是更完整的示例。
@@ -52,13 +52,13 @@ if not (credentials.username == "stanleyjobson") or not (credentials.password ==
但使用 `secrets.compare_digest()`,可以防御**时差攻击**,更加安全。
-### 时差攻击
+### 时差攻击 { #timing-attacks }
什么是**时差攻击**?
假设攻击者试图猜出用户名与密码。
-他们发送用户名为 `johndoe`,密码为 `love123` 的请求。
+他们发送用户名为 `johndoe`,密码为 `love123` 的请求。
然后,Python 代码执行如下操作:
@@ -80,28 +80,28 @@ if "stanleyjobsox" == "stanleyjobson" and "love123" == "swordfish":
此时,Python 要对比 `stanleyjobsox` 与 `stanleyjobson` 中的 `stanleyjobso`,才能知道这两个字符串不一样。因此会多花费几微秒来返回**错误的用户或密码**。
-#### 反应时间对攻击者的帮助
+#### 反应时间对攻击者的帮助 { #the-time-to-answer-helps-the-attackers }
通过服务器花费了更多微秒才发送**错误的用户或密码**响应,攻击者会知道猜对了一些内容,起码开头字母是正确的。
然后,他们就可以放弃 `johndoe`,再用类似 `stanleyjobsox` 的内容进行尝试。
-#### **专业**攻击
+#### **专业**攻击 { #a-professional-attack }
当然,攻击者不用手动操作,而是编写每秒能执行成千上万次测试的攻击程序,每次都会找到更多正确字符。
但是,在您的应用的**帮助**下,攻击者利用时间差,就能在几分钟或几小时内,以这种方式猜出正确的用户名和密码。
-#### 使用 `secrets.compare_digest()` 修补
+#### 使用 `secrets.compare_digest()` 修补 { #fix-it-with-secrets-compare-digest }
在此,代码中使用了 `secrets.compare_digest()`。
简单的说,它使用相同的时间对比 `stanleyjobsox` 和 `stanleyjobson`,还有 `johndoe` 和 `stanleyjobson`。对比密码时也一样。
-在代码中使用 `secrets.compare_digest()` ,就可以安全地防御全面攻击了。
+在代码中使用 `secrets.compare_digest()` ,就可以安全地防御这整类安全攻击。
-### 返回错误
+### 返回错误 { #return-the-error }
-检测到凭证不正确后,返回 `HTTPException` 及状态码 401(与无凭证时返回的内容一样),并添加请求头 `WWW-Authenticate`,让浏览器再次显示登录提示:
+检测到凭证不正确后,返回 `HTTPException` 及状态码 401(与无凭证时返回的内容一样),并添加响应头 `WWW-Authenticate`,让浏览器再次显示登录提示:
{* ../../docs_src/security/tutorial007_an_py39.py hl[26:30] *}
diff --git a/docs/zh/docs/advanced/security/index.md b/docs/zh/docs/advanced/security/index.md
index 267e7ced70..84fec7aab8 100644
--- a/docs/zh/docs/advanced/security/index.md
+++ b/docs/zh/docs/advanced/security/index.md
@@ -1,19 +1,19 @@
-# 高级安全
+# 高级安全 { #advanced-security }
-## 附加特性
+## 附加特性 { #additional-features }
-除 [教程 - 用户指南: 安全性](../../tutorial/security/index.md){.internal-link target=_blank} 中涵盖的功能之外,还有一些额外的功能来处理安全性.
+除 [教程 - 用户指南: 安全性](../../tutorial/security/index.md){.internal-link target=_blank} 中涵盖的功能之外,还有一些额外的功能来处理安全性。
-/// tip | 小贴士
+/// tip | 提示
-接下来的章节 **并不一定是 "高级的"**.
+接下来的章节**并不一定是 "高级的"**。
而且对于你的使用场景来说,解决方案很可能就在其中。
///
-## 先阅读教程
+## 先阅读教程 { #read-the-tutorial-first }
-接下来的部分假设你已经阅读了主要的 [教程 - 用户指南: 安全性](../../tutorial/security/index.md){.internal-link target=_blank}.
+接下来的部分假设你已经阅读了主要的 [教程 - 用户指南: 安全性](../../tutorial/security/index.md){.internal-link target=_blank}。
-它们都基于相同的概念,但支持一些额外的功能.
+它们都基于相同的概念,但支持一些额外的功能。
diff --git a/docs/zh/docs/advanced/testing-dependencies.md b/docs/zh/docs/advanced/testing-dependencies.md
index 8d53a6d496..db0b39483d 100644
--- a/docs/zh/docs/advanced/testing-dependencies.md
+++ b/docs/zh/docs/advanced/testing-dependencies.md
@@ -1,6 +1,6 @@
-# 测试依赖项
+# 使用覆盖测试依赖项 { #testing-dependencies-with-overrides }
-## 测试时覆盖依赖项
+## 测试时覆盖依赖项 { #overriding-dependencies-during-testing }
有些场景下,您可能需要在测试时覆盖依赖项。
@@ -8,7 +8,7 @@
反之,要在测试期间(或只是为某些特定测试)提供只用于测试的依赖项,并使用此依赖项的值替换原有依赖项的值。
-### 用例:外部服务
+### 用例:外部服务 { #use-cases-external-service }
常见实例是调用外部第三方身份验证应用。
@@ -20,7 +20,7 @@
此时,最好覆盖调用外部验证应用的依赖项,使用返回模拟测试用户的自定义依赖项就可以了。
-### 使用 `app.dependency_overrides` 属性
+### 使用 `app.dependency_overrides` 属性 { #use-the-app-dependency-overrides-attribute }
对于这些用例,**FastAPI** 应用支持 `app.dependency_overrides` 属性,该属性就是**字典**。
@@ -46,6 +46,7 @@ FastAPI 可以覆盖这些位置的依赖项。
app.dependency_overrides = {}
```
+
/// tip | 提示
如果只在某些测试时覆盖依赖项,您可以在测试开始时(在测试函数内)设置覆盖依赖项,并在结束时(在测试函数结尾)重置覆盖依赖项。
diff --git a/docs/zh/docs/async.md b/docs/zh/docs/async.md
index 4028ed51aa..c94c907873 100644
--- a/docs/zh/docs/async.md
+++ b/docs/zh/docs/async.md
@@ -1,10 +1,10 @@
-# 并发 async / await
+# 并发 async / await { #concurrency-and-async-await }
有关路径操作函数的 `async def` 语法以及异步代码、并发和并行的一些背景知识。
-## 赶时间吗?
+## 赶时间吗? { #in-a-hurry }
-TL;DR:
+TL;DR:
如果你正在使用第三方库,它们会告诉你使用 `await` 关键字来调用它们,就像这样:
@@ -21,7 +21,7 @@ async def read_results():
return results
```
-/// note
+/// note | 注意
你只能在被 `async def` 创建的函数内使用 `await`
@@ -40,7 +40,7 @@ def results():
---
-如果你的应用程序不需要与其他任何东西通信而等待其响应,请使用 `async def`。
+如果你的应用程序不需要与其他任何东西通信而等待其响应,请使用 `async def`,即使函数内部不需要使用 `await`。
---
@@ -54,7 +54,7 @@ def results():
但是,通过遵循上述步骤,它将能够进行一些性能优化。
-## 技术细节
+## 技术细节 { #technical-details }
Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和 `await` 语法的东西来写**”异步代码“**。
@@ -64,7 +64,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
* **`async` 和 `await`**
* **协程**
-## 异步代码
+## 异步代码 { #asynchronous-code }
异步代码仅仅意味着编程语言 💬 有办法告诉计算机/程序 🤖 在代码中的某个点,它 🤖 将不得不等待在某些地方完成一些事情。让我们假设一些事情被称为 "慢文件"📝.
@@ -74,7 +74,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
接下来,它 🤖 完成第一个任务(比如是我们的"慢文件"📝) 并继续与之相关的一切。
-这个"等待其他事情"通常指的是一些相对较慢(与处理器和 RAM 存储器的速度相比)的 I/O 操作,比如说:
+这个"等待其他事情"通常指的是一些相对较慢(与处理器和 RAM 存储器的速度相比)的 I/O 操作,比如说:
* 通过网络发送来自客户端的数据
* 客户端接收来自网络中的数据
@@ -85,7 +85,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
* 一个数据库查询,直到返回结果
* 等等.
-这个执行的时间大多是在等待 I/O 操作,因此它们被叫做 "I/O 密集型" 操作。
+这个执行的时间大多是在等待 I/O 操作,因此它们被叫做 "I/O 密集型" 操作。
它被称为"异步"的原因是因为计算机/程序不必与慢任务"同步",去等待任务完成的确切时刻,而在此期间不做任何事情直到能够获取任务结果才继续工作。
@@ -93,7 +93,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
对于"同步"(与"异步"相反),他们通常也使用"顺序"一词,因为计算机程序在切换到另一个任务之前是按顺序执行所有步骤,即使这些步骤涉及到等待。
-### 并发与汉堡
+### 并发与汉堡 { #concurrency-and-burgers }
上述异步代码的思想有时也被称为“并发”,它不同于“并行”。
@@ -103,7 +103,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
要了解差异,请想象以下关于汉堡的故事:
-### 并发汉堡
+### 并发汉堡 { #concurrent-burgers }
你和你的恋人一起去快餐店,你排队在后面,收银员从你前面的人接单。😍
@@ -139,7 +139,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
-## 检查用户名
+## 检查用户名 { #check-the-username }
以下是更完整的示例。
@@ -52,13 +52,13 @@ if not (credentials.username == "stanleyjobson") or not (credentials.password ==
但使用 `secrets.compare_digest()`,可以防御**时差攻击**,更加安全。
-### 时差攻击
+### 时差攻击 { #timing-attacks }
什么是**时差攻击**?
假设攻击者试图猜出用户名与密码。
-他们发送用户名为 `johndoe`,密码为 `love123` 的请求。
+他们发送用户名为 `johndoe`,密码为 `love123` 的请求。
然后,Python 代码执行如下操作:
@@ -80,28 +80,28 @@ if "stanleyjobsox" == "stanleyjobson" and "love123" == "swordfish":
此时,Python 要对比 `stanleyjobsox` 与 `stanleyjobson` 中的 `stanleyjobso`,才能知道这两个字符串不一样。因此会多花费几微秒来返回**错误的用户或密码**。
-#### 反应时间对攻击者的帮助
+#### 反应时间对攻击者的帮助 { #the-time-to-answer-helps-the-attackers }
通过服务器花费了更多微秒才发送**错误的用户或密码**响应,攻击者会知道猜对了一些内容,起码开头字母是正确的。
然后,他们就可以放弃 `johndoe`,再用类似 `stanleyjobsox` 的内容进行尝试。
-#### **专业**攻击
+#### **专业**攻击 { #a-professional-attack }
当然,攻击者不用手动操作,而是编写每秒能执行成千上万次测试的攻击程序,每次都会找到更多正确字符。
但是,在您的应用的**帮助**下,攻击者利用时间差,就能在几分钟或几小时内,以这种方式猜出正确的用户名和密码。
-#### 使用 `secrets.compare_digest()` 修补
+#### 使用 `secrets.compare_digest()` 修补 { #fix-it-with-secrets-compare-digest }
在此,代码中使用了 `secrets.compare_digest()`。
简单的说,它使用相同的时间对比 `stanleyjobsox` 和 `stanleyjobson`,还有 `johndoe` 和 `stanleyjobson`。对比密码时也一样。
-在代码中使用 `secrets.compare_digest()` ,就可以安全地防御全面攻击了。
+在代码中使用 `secrets.compare_digest()` ,就可以安全地防御这整类安全攻击。
-### 返回错误
+### 返回错误 { #return-the-error }
-检测到凭证不正确后,返回 `HTTPException` 及状态码 401(与无凭证时返回的内容一样),并添加请求头 `WWW-Authenticate`,让浏览器再次显示登录提示:
+检测到凭证不正确后,返回 `HTTPException` 及状态码 401(与无凭证时返回的内容一样),并添加响应头 `WWW-Authenticate`,让浏览器再次显示登录提示:
{* ../../docs_src/security/tutorial007_an_py39.py hl[26:30] *}
diff --git a/docs/zh/docs/advanced/security/index.md b/docs/zh/docs/advanced/security/index.md
index 267e7ced70..84fec7aab8 100644
--- a/docs/zh/docs/advanced/security/index.md
+++ b/docs/zh/docs/advanced/security/index.md
@@ -1,19 +1,19 @@
-# 高级安全
+# 高级安全 { #advanced-security }
-## 附加特性
+## 附加特性 { #additional-features }
-除 [教程 - 用户指南: 安全性](../../tutorial/security/index.md){.internal-link target=_blank} 中涵盖的功能之外,还有一些额外的功能来处理安全性.
+除 [教程 - 用户指南: 安全性](../../tutorial/security/index.md){.internal-link target=_blank} 中涵盖的功能之外,还有一些额外的功能来处理安全性。
-/// tip | 小贴士
+/// tip | 提示
-接下来的章节 **并不一定是 "高级的"**.
+接下来的章节**并不一定是 "高级的"**。
而且对于你的使用场景来说,解决方案很可能就在其中。
///
-## 先阅读教程
+## 先阅读教程 { #read-the-tutorial-first }
-接下来的部分假设你已经阅读了主要的 [教程 - 用户指南: 安全性](../../tutorial/security/index.md){.internal-link target=_blank}.
+接下来的部分假设你已经阅读了主要的 [教程 - 用户指南: 安全性](../../tutorial/security/index.md){.internal-link target=_blank}。
-它们都基于相同的概念,但支持一些额外的功能.
+它们都基于相同的概念,但支持一些额外的功能。
diff --git a/docs/zh/docs/advanced/testing-dependencies.md b/docs/zh/docs/advanced/testing-dependencies.md
index 8d53a6d496..db0b39483d 100644
--- a/docs/zh/docs/advanced/testing-dependencies.md
+++ b/docs/zh/docs/advanced/testing-dependencies.md
@@ -1,6 +1,6 @@
-# 测试依赖项
+# 使用覆盖测试依赖项 { #testing-dependencies-with-overrides }
-## 测试时覆盖依赖项
+## 测试时覆盖依赖项 { #overriding-dependencies-during-testing }
有些场景下,您可能需要在测试时覆盖依赖项。
@@ -8,7 +8,7 @@
反之,要在测试期间(或只是为某些特定测试)提供只用于测试的依赖项,并使用此依赖项的值替换原有依赖项的值。
-### 用例:外部服务
+### 用例:外部服务 { #use-cases-external-service }
常见实例是调用外部第三方身份验证应用。
@@ -20,7 +20,7 @@
此时,最好覆盖调用外部验证应用的依赖项,使用返回模拟测试用户的自定义依赖项就可以了。
-### 使用 `app.dependency_overrides` 属性
+### 使用 `app.dependency_overrides` 属性 { #use-the-app-dependency-overrides-attribute }
对于这些用例,**FastAPI** 应用支持 `app.dependency_overrides` 属性,该属性就是**字典**。
@@ -46,6 +46,7 @@ FastAPI 可以覆盖这些位置的依赖项。
app.dependency_overrides = {}
```
+
/// tip | 提示
如果只在某些测试时覆盖依赖项,您可以在测试开始时(在测试函数内)设置覆盖依赖项,并在结束时(在测试函数结尾)重置覆盖依赖项。
diff --git a/docs/zh/docs/async.md b/docs/zh/docs/async.md
index 4028ed51aa..c94c907873 100644
--- a/docs/zh/docs/async.md
+++ b/docs/zh/docs/async.md
@@ -1,10 +1,10 @@
-# 并发 async / await
+# 并发 async / await { #concurrency-and-async-await }
有关路径操作函数的 `async def` 语法以及异步代码、并发和并行的一些背景知识。
-## 赶时间吗?
+## 赶时间吗? { #in-a-hurry }
-TL;DR:
+TL;DR:
如果你正在使用第三方库,它们会告诉你使用 `await` 关键字来调用它们,就像这样:
@@ -21,7 +21,7 @@ async def read_results():
return results
```
-/// note
+/// note | 注意
你只能在被 `async def` 创建的函数内使用 `await`
@@ -40,7 +40,7 @@ def results():
---
-如果你的应用程序不需要与其他任何东西通信而等待其响应,请使用 `async def`。
+如果你的应用程序不需要与其他任何东西通信而等待其响应,请使用 `async def`,即使函数内部不需要使用 `await`。
---
@@ -54,7 +54,7 @@ def results():
但是,通过遵循上述步骤,它将能够进行一些性能优化。
-## 技术细节
+## 技术细节 { #technical-details }
Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和 `await` 语法的东西来写**”异步代码“**。
@@ -64,7 +64,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
* **`async` 和 `await`**
* **协程**
-## 异步代码
+## 异步代码 { #asynchronous-code }
异步代码仅仅意味着编程语言 💬 有办法告诉计算机/程序 🤖 在代码中的某个点,它 🤖 将不得不等待在某些地方完成一些事情。让我们假设一些事情被称为 "慢文件"📝.
@@ -74,7 +74,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
接下来,它 🤖 完成第一个任务(比如是我们的"慢文件"📝) 并继续与之相关的一切。
-这个"等待其他事情"通常指的是一些相对较慢(与处理器和 RAM 存储器的速度相比)的 I/O 操作,比如说:
+这个"等待其他事情"通常指的是一些相对较慢(与处理器和 RAM 存储器的速度相比)的 I/O 操作,比如说:
* 通过网络发送来自客户端的数据
* 客户端接收来自网络中的数据
@@ -85,7 +85,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
* 一个数据库查询,直到返回结果
* 等等.
-这个执行的时间大多是在等待 I/O 操作,因此它们被叫做 "I/O 密集型" 操作。
+这个执行的时间大多是在等待 I/O 操作,因此它们被叫做 "I/O 密集型" 操作。
它被称为"异步"的原因是因为计算机/程序不必与慢任务"同步",去等待任务完成的确切时刻,而在此期间不做任何事情直到能够获取任务结果才继续工作。
@@ -93,7 +93,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
对于"同步"(与"异步"相反),他们通常也使用"顺序"一词,因为计算机程序在切换到另一个任务之前是按顺序执行所有步骤,即使这些步骤涉及到等待。
-### 并发与汉堡
+### 并发与汉堡 { #concurrency-and-burgers }
上述异步代码的思想有时也被称为“并发”,它不同于“并行”。
@@ -103,7 +103,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
要了解差异,请想象以下关于汉堡的故事:
-### 并发汉堡
+### 并发汉堡 { #concurrent-burgers }
你和你的恋人一起去快餐店,你排队在后面,收银员从你前面的人接单。😍
@@ -139,7 +139,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
 -/// info
+/// info | 信息
漂亮的插画来自 Ketrina Thompson. 🎨
@@ -163,7 +163,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
然后你去柜台🔀, 到现在初始任务已经完成⏯, 拿起汉堡,说声谢谢,然后把它们送到桌上。这就完成了与计数器交互的步骤/任务⏹. 这反过来又产生了一项新任务,即"吃汉堡"🔀 ⏯, 上一个"拿汉堡"的任务已经结束了⏹.
-### 并行汉堡
+### 并行汉堡 { #parallel-burgers }
现在让我们假设不是"并发汉堡",而是"并行汉堡"。
@@ -205,7 +205,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
没有太多的交谈或调情,因为大部分时间 🕙 都在柜台前等待😞。
-/// info
+/// info | 信息
漂亮的插画来自 Ketrina Thompson. 🎨
@@ -233,7 +233,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
你可不会想带你的恋人 😍 和你一起去银行办事🏦.
-### 汉堡结论
+### 汉堡结论 { #burger-conclusion }
在"你与恋人一起吃汉堡"的这个场景中,因为有很多人在等待🕙, 使用并发系统更有意义⏸🔀⏯.
@@ -253,7 +253,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
你可以同时拥有并行性和异步性,你可以获得比大多数经过测试的 NodeJS 框架更高的性能,并且与 Go 不相上下, Go 是一种更接近于 C 的编译语言(全部归功于 Starlette)。
-### 并发比并行好吗?
+### 并发比并行好吗? { #is-concurrency-better-than-parallelism }
不!这不是故事的本意。
@@ -277,7 +277,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
在这个场景中,每个清洁工(包括你)都将是一个处理器,完成这个工作的一部分。
-由于大多数执行时间是由实际工作(而不是等待)占用的,并且计算机中的工作是由 CPU 完成的,所以他们称这些问题为"CPU 密集型"。
+由于大多数执行时间是由实际工作(而不是等待)占用的,并且计算机中的工作是由 CPU 完成的,所以他们称这些问题为"CPU 密集型"。
---
@@ -290,7 +290,7 @@ CPU 密集型操作的常见示例是需要复杂的数学处理。
* **机器学习**: 它通常需要大量的"矩阵"和"向量"乘法。想象一个包含数字的巨大电子表格,并同时将所有数字相乘;
* **深度学习**: 这是机器学习的一个子领域,同样适用。只是没有一个数字的电子表格可以相乘,而是一个庞大的数字集合,在很多情况下,你需要使用一个特殊的处理器来构建和使用这些模型。
-### 并发 + 并行: Web + 机器学习
+### 并发 + 并行: Web + 机器学习 { #concurrency-parallelism-web-machine-learning }
使用 **FastAPI**,你可以利用 Web 开发中常见的并发机制的优势(NodeJS 的主要吸引力)。
@@ -300,7 +300,7 @@ CPU 密集型操作的常见示例是需要复杂的数学处理。
了解如何在生产环境中实现这种并行性,可查看此文 [Deployment](deployment/index.md){.internal-link target=_blank}。
-## `async` 和 `await`
+## `async` 和 `await` { #async-and-await }
现代版本的 Python 有一种非常直观的方式来定义异步代码。这使它看起来就像正常的"顺序"代码,并在适当的时候"等待"。
@@ -316,16 +316,16 @@ burgers = await get_burgers(2)
```Python hl_lines="1"
async def get_burgers(number: int):
- # Do some asynchronous stuff to create the burgers
+ # 执行一些异步操作来制作汉堡
return burgers
```
...而不是 `def`:
```Python hl_lines="2"
-# This is not asynchronous
+# 这不是异步的
def get_sequential_burgers(number: int):
- # Do some sequential stuff to create the burgers
+ # 执行一些顺序操作来制作汉堡
return burgers
```
@@ -334,7 +334,7 @@ def get_sequential_burgers(number: int):
当你想调用一个 `async def` 函数时,你必须"等待"它。因此,这不会起作用:
```Python
-# This won't work, because get_burgers was defined with: async def
+# 这样不行,因为 get_burgers 是用 async def 定义的
burgers = get_burgers(2)
```
@@ -349,7 +349,7 @@ async def read_burgers():
return burgers
```
-### 更多技术细节
+### 更多技术细节 { #more-technical-details }
你可能已经注意到,`await` 只能在 `async def` 定义的函数内部使用。
@@ -361,7 +361,7 @@ async def read_burgers():
但如果你想在没有 FastAPI 的情况下使用 `async` / `await`,则可以这样做。
-### 编写自己的异步代码
+### 编写自己的异步代码 { #write-your-own-async-code }
Starlette (和 **FastAPI**) 是基于 AnyIO 实现的,这使得它们可以兼容 Python 的标准库 asyncio 和 Trio。
@@ -371,7 +371,7 @@ Starlette (和 **FastAPI**) 是基于 Asyncer。如果你有**结合使用异步代码和常规**(阻塞/同步)代码的需求,这个库会特别有用。
-### 其他形式的异步代码
+### 其他形式的异步代码 { #other-forms-of-asynchronous-code }
这种使用 `async` 和 `await` 的风格在语言中相对较新。
@@ -385,13 +385,13 @@ Starlette (和 **FastAPI**) 是基于 I/O 的代码。
+如果你使用过另一个不以上述方式工作的异步框架,并且你习惯于用普通的 `def` 定义普通的仅计算路径操作函数,以获得微小的性能增益(大约100纳秒),请注意,在 FastAPI 中,效果将完全相反。在这些情况下,最好使用 `async def`,除非路径操作函数内使用执行阻塞 I/O 的代码。
-在这两种情况下,与你之前的框架相比,**FastAPI** 可能[仍然很快](index.md#_11){.internal-link target=_blank}。
+在这两种情况下,与你之前的框架相比,**FastAPI** 可能[仍然很快](index.md#performance){.internal-link target=_blank}。
-### 依赖
+### 依赖 { #dependencies }
这同样适用于[依赖](tutorial/dependencies/index.md){.internal-link target=_blank}。如果一个依赖是标准的 `def` 函数而不是 `async def`,它将被运行在外部线程池中。
-### 子依赖
+### 子依赖 { #sub-dependencies }
你可以拥有多个相互依赖的依赖以及[子依赖](tutorial/dependencies/sub-dependencies.md){.internal-link target=_blank} (作为函数的参数),它们中的一些可能是通过 `async def` 声明,也可能是通过 `def` 声明。它们仍然可以正常工作,这些通过 `def` 声明的函数将会在外部线程中调用(来自线程池),而不是"被等待"。
-### 其他函数
+### 其他函数 { #other-utility-functions }
你可直接调用通过 `def` 或 `async def` 创建的任何其他函数,FastAPI 不会影响你调用它们的方式。
@@ -441,4 +441,4 @@ Starlette (和 **FastAPI**) 是基于 赶时间吗?.
+否则,你最好应该遵守的指导原则赶时间吗?.
diff --git a/docs/zh/docs/deployment/cloud.md b/docs/zh/docs/deployment/cloud.md
index 8a892a560b..96883bd6bf 100644
--- a/docs/zh/docs/deployment/cloud.md
+++ b/docs/zh/docs/deployment/cloud.md
@@ -1,13 +1,24 @@
-# 在云上部署 FastAPI
+# 在云服务商上部署 FastAPI { #deploy-fastapi-on-cloud-providers }
-您几乎可以使用**任何云服务商**来部署 FastAPI 应用程序。
+你几乎可以使用**任何云服务商**来部署你的 FastAPI 应用。
-在大多数情况下,主要的云服务商都有部署 FastAPI 的指南。
+在大多数情况下,主流云服务商都有部署 FastAPI 的指南。
-## 云服务商 - 赞助商
+## FastAPI Cloud { #fastapi-cloud }
-一些云服务商 ✨ [**赞助 FastAPI**](../help-fastapi.md#sponsor-the-author){.internal-link target=_blank} ✨,这确保了FastAPI 及其**生态系统**持续健康地**发展**。
+**FastAPI Cloud** 由 **FastAPI** 背后的同一作者与团队打造。
-这表明了他们对 FastAPI 及其**社区**(您)的真正承诺,因为他们不仅想为您提供**良好的服务**,而且还想确保您拥有一个**良好且健康的框架**:FastAPI。 🙇
+它简化了**构建**、**部署**和**访问** API 的流程,几乎不费力。
-您可能想尝试他们的服务并阅读他们的指南.
+它把使用 FastAPI 构建应用时相同的**开发者体验**带到了将应用**部署**到云上的过程。🎉
+
+FastAPI Cloud 是 *FastAPI and friends* 开源项目的主要赞助方和资金提供者。✨
+
+## 云服务商 - 赞助商 { #cloud-providers-sponsors }
+
+还有一些云服务商也会 ✨ [**赞助 FastAPI**](../help-fastapi.md#sponsor-the-author){.internal-link target=_blank} ✨。🙇
+
+你也可以考虑按照他们的指南尝试他们的服务:
+
+* Render
+* Railway
diff --git a/docs/zh/docs/deployment/concepts.md b/docs/zh/docs/deployment/concepts.md
index f7208da7c5..66d32629cb 100644
--- a/docs/zh/docs/deployment/concepts.md
+++ b/docs/zh/docs/deployment/concepts.md
@@ -1,4 +1,4 @@
-# 部署概念
+# 部署概念 { #deployments-concepts }
在部署 **FastAPI** 应用程序或任何类型的 Web API 时,有几个概念值得了解,通过掌握这些概念您可以找到**最合适的**方法来**部署您的应用程序**。
@@ -13,7 +13,7 @@
我们接下来了解它们将如何影响**部署**。
-我们的最终目标是能够以**安全**的方式**为您的 API 客户端**提供服务,同时要**避免中断**,并且尽可能高效地利用**计算资源**( 例如服务器CPU资源)。 🚀
+我们的最终目标是能够以**安全**的方式**为您的 API 客户端**提供服务,同时要**避免中断**,并且尽可能高效地利用**计算资源**(例如远程服务器/虚拟机)。 🚀
我将在这里告诉您更多关于这些**概念**的信息,希望能给您提供**直觉**来决定如何在非常不同的环境中部署 API,甚至在是尚不存在的**未来**的环境里。
@@ -23,7 +23,7 @@
但现在,让我们仔细看一下这些重要的**概念**。 这些概念也适用于任何其他类型的 Web API。 💡
-## 安全性 - HTTPS
+## 安全性 - HTTPS { #security-https }
在[上一章有关 HTTPS](https.md){.internal-link target=_blank} 中,我们了解了 HTTPS 如何为您的 API 提供加密。
@@ -31,21 +31,20 @@
并且必须有某个东西负责**更新 HTTPS 证书**,它可以是相同的组件,也可以是不同的组件。
-
-### HTTPS 示例工具
+### HTTPS 示例工具 { #example-tools-for-https }
您可以用作 TLS 终止代理的一些工具包括:
* Traefik
- * 自动处理证书更新 ✨
+ * 自动处理证书更新 ✨
* Caddy
- * 自动处理证书更新 ✨
+ * 自动处理证书更新 ✨
* Nginx
- * 使用 Certbot 等外部组件进行证书更新
+ * 使用 Certbot 等外部组件进行证书更新
* HAProxy
- * 使用 Certbot 等外部组件进行证书更新
-* 带有 Ingress Controller(如Nginx) 的 Kubernetes
- * 使用诸如 cert-manager 之类的外部组件来进行证书更新
+ * 使用 Certbot 等外部组件进行证书更新
+* 带有 Ingress Controller(如 Nginx) 的 Kubernetes
+ * 使用诸如 cert-manager 之类的外部组件来进行证书更新
* 由云服务商内部处理,作为其服务的一部分(请阅读下文👇)
另一种选择是您可以使用**云服务**来完成更多工作,包括设置 HTTPS。 它可能有一些限制或向您收取更多费用等。但在这种情况下,您不必自己设置 TLS 终止代理。
@@ -56,11 +55,11 @@
接下来要考虑的概念都是关于运行实际 API 的程序(例如 Uvicorn)。
-## 程序和进程
+## 程序和进程 { #program-and-process }
我们将讨论很多关于正在运行的“**进程**”的内容,因此弄清楚它的含义以及与“**程序**”这个词有什么区别是很有用的。
-### 什么是程序
+### 什么是程序 { #what-is-a-program }
**程序**这个词通常用来描述很多东西:
@@ -68,12 +67,12 @@
* 操作系统可以**执行**的**文件**,例如:`python`、`python.exe`或`uvicorn`。
* 在操作系统上**运行**、使用CPU 并将内容存储在内存上的特定程序。 这也被称为**进程**。
-### 什么是进程
+### 什么是进程 { #what-is-a-process }
**进程** 这个词通常以更具体的方式使用,仅指在操作系统中运行的东西(如上面的最后一点):
* 在操作系统上**运行**的特定程序。
- * 这不是指文件,也不是指代码,它**具体**指的是操作系统正在**执行**和管理的东西。
+ * 这不是指文件,也不是指代码,它**具体**指的是操作系统正在**执行**和管理的东西。
* 任何程序,任何代码,**只有在执行时才能做事**。 因此,是当有**进程正在运行**时。
* 该进程可以由您或操作系统**终止**(或“杀死”)。 那时,它停止运行/被执行,并且它可以**不再做事情**。
* 您计算机上运行的每个应用程序背后都有一些进程,每个正在运行的程序,每个窗口等。并且通常在计算机打开时**同时**运行许多进程。
@@ -89,13 +88,13 @@
现在我们知道了术语“进程”和“程序”之间的区别,让我们继续讨论部署。
-## 启动时运行
+## 启动时运行 { #running-on-startup }
在大多数情况下,当您创建 Web API 时,您希望它**始终运行**、不间断,以便您的客户端始终可以访问它。 这是当然的,除非您有特定原因希望它仅在某些情况下运行,但大多数时候您希望它不断运行并且**可用**。
-### 在远程服务器中
+### 在远程服务器中 { #in-a-remote-server }
-当您设置远程服务器(云服务器、虚拟机等)时,您可以做的最简单的事情就是手动运行 Uvicorn(或类似的),就像本地开发时一样。
+当您设置远程服务器(云服务器、虚拟机等)时,您可以做的最简单的事情就是使用 `fastapi run`(它使用 Uvicorn)或类似方式,手动运行,就像本地开发时一样。
它将会在**开发过程中**发挥作用并发挥作用。
@@ -103,16 +102,15 @@
如果服务器重新启动(例如更新后或从云提供商迁移后),您可能**不会注意到它**。 因此,您甚至不知道必须手动重新启动该进程。 所以,你的 API 将一直处于挂掉的状态。 😱
-
-### 启动时自动运行
+### 启动时自动运行 { #run-automatically-on-startup }
一般来说,您可能希望服务器程序(例如 Uvicorn)在服务器启动时自动启动,并且不需要任何**人为干预**,让进程始终与您的 API 一起运行(例如 Uvicorn 运行您的 FastAPI 应用程序) 。
-### 单独的程序
+### 单独的程序 { #separate-program }
为了实现这一点,您通常会有一个**单独的程序**来确保您的应用程序在启动时运行。 在许多情况下,它还可以确保其他组件或应用程序也运行,例如数据库。
-### 启动时运行的示例工具
+### 启动时运行的示例工具 { #example-tools-to-run-at-startup }
可以完成这项工作的工具的一些示例是:
@@ -127,44 +125,43 @@
我将在接下来的章节中为您提供更具体的示例。
-
-## 重新启动
+## 重新启动 { #restarts }
与确保应用程序在启动时运行类似,您可能还想确保它在挂掉后**重新启动**。
-### 我们会犯错误
+### 我们会犯错误 { #we-make-mistakes }
作为人类,我们总是会犯**错误**。 软件几乎*总是*在不同的地方隐藏着**bug**。 🐛
作为开发人员,当我们发现这些bug并实现新功能(也可能添加新bug😅)时,我们会不断改进代码。
-### 自动处理小错误
+### 自动处理小错误 { #small-errors-automatically-handled }
使用 FastAPI 构建 Web API 时,如果我们的代码中存在错误,FastAPI 通常会将其包含到触发错误的单个请求中。 🛡
对于该请求,客户端将收到 **500 内部服务器错误**,但应用程序将继续处理下一个请求,而不是完全崩溃。
-### 更大的错误 - 崩溃
+### 更大的错误 - 崩溃 { #bigger-errors-crashes }
尽管如此,在某些情况下,我们编写的一些代码可能会导致整个应用程序崩溃,从而导致 Uvicorn 和 Python 崩溃。 💥
尽管如此,您可能不希望应用程序因为某个地方出现错误而保持死机状态,您可能希望它**继续运行**,至少对于未破坏的*路径操作*。
-### 崩溃后重新启动
+### 崩溃后重新启动 { #restart-after-crash }
但在那些严重错误导致正在运行的**进程**崩溃的情况下,您需要一个外部组件来负责**重新启动**进程,至少尝试几次......
-/// tip
+/// tip | 提示
...尽管如果整个应用程序只是**立即崩溃**,那么永远重新启动它可能没有意义。 但在这些情况下,您可能会在开发过程中注意到它,或者至少在部署后立即注意到它。
- 因此,让我们关注主要情况,在**未来**的某些特定情况下,它可能会完全崩溃,但重新启动它仍然有意义。
+因此,让我们关注主要情况,在**未来**的某些特定情况下,它可能会完全崩溃,但重新启动它仍然有意义。
///
您可能希望让这个东西作为 **外部组件** 负责重新启动您的应用程序,因为到那时,使用 Uvicorn 和 Python 的同一应用程序已经崩溃了,因此同一应用程序的相同代码中没有东西可以对此做出什么。
-### 自动重新启动的示例工具
+### 自动重新启动的示例工具 { #example-tools-to-restart-automatically }
在大多数情况下,用于**启动时运行程序**的同一工具也用于处理自动**重新启动**。
@@ -173,25 +170,25 @@
* Docker
* Kubernetes
* Docker Compose
-* Docker in Swarm mode
+* Docker in Swarm Mode
* Systemd
* Supervisor
* 作为其服务的一部分由云提供商内部处理
* 其他的...
-## 复制 - 进程和内存
+## 复制 - 进程和内存 { #replication-processes-and-memory }
-对于 FastAPI 应用程序,使用像 Uvicorn 这样的服务器程序,在**一个进程**中运行一次就可以同时为多个客户端提供服务。
+对于 FastAPI 应用程序,使用像 `fastapi` 命令(运行 Uvicorn)这样的服务器程序,在**一个进程**中运行一次就可以同时为多个客户端提供服务。
但在许多情况下,您会希望同时运行多个工作进程。
-### 多进程 - Workers
+### 多进程 - Workers { #multiple-processes-workers }
-如果您的客户端数量多于单个进程可以处理的数量(例如,如果虚拟机不是太大),并且服务器的 CPU 中有 **多个核心**,那么您可以让 **多个进程** 运行 同时处理同一个应用程序,并在它们之间分发所有请求。
+如果您的客户端数量多于单个进程可以处理的数量(例如,如果虚拟机不是太大),并且服务器的 CPU 中有 **多个核心**,那么您可以让 **多个进程** 同时运行同一个应用程序,并在它们之间分发所有请求。
当您运行同一 API 程序的**多个进程**时,它们通常称为 **workers**。
-### 工作进程和端口
+### 工作进程和端口 { #worker-processes-and-ports }
还记得文档 [About HTTPS](https.md){.internal-link target=_blank} 中只有一个进程可以侦听服务器中的端口和 IP 地址的一种组合吗?
@@ -199,20 +196,19 @@
因此,为了能够同时拥有**多个进程**,必须有一个**单个进程侦听端口**,然后以某种方式将通信传输到每个工作进程。
-### 每个进程的内存
+### 每个进程的内存 { #memory-per-process }
现在,当程序将内容加载到内存中时,例如,将机器学习模型加载到变量中,或者将大文件的内容加载到变量中,所有这些都会消耗服务器的一点内存 (RAM) 。
多个进程通常**不共享任何内存**。 这意味着每个正在运行的进程都有自己的东西、变量和内存。 如果您的代码消耗了大量内存,**每个进程**将消耗等量的内存。
-### 服务器内存
+### 服务器内存 { #server-memory }
例如,如果您的代码加载 **1 GB 大小**的机器学习模型,则当您使用 API 运行一个进程时,它将至少消耗 1 GB RAM。 如果您启动 **4 个进程**(4 个工作进程),每个进程将消耗 1 GB RAM。 因此,您的 API 总共将消耗 **4 GB RAM**。
如果您的远程服务器或虚拟机只有 3 GB RAM,尝试加载超过 4 GB RAM 将导致问题。 🚨
-
-### 多进程 - 一个例子
+### 多进程 - 一个例子 { #multiple-processes-an-example }
在此示例中,有一个 **Manager Process** 启动并控制两个 **Worker Processes**。
@@ -224,11 +220,11 @@
当然,除了您的应用程序之外,同一台机器可能还运行**其他进程**。
-一个有趣的细节是,随着时间的推移,每个进程使用的 **CPU 百分比可能会发生很大变化,但内存 (RAM) 通常会或多或少保持稳定**。
+一个有趣的细节是,随着时间的推移,每个进程使用的 **CPU 百分比**可能会发生很大变化,但**内存 (RAM)** 通常会或多或少保持**稳定**。
如果您有一个每次执行相当数量的计算的 API,并且您有很多客户端,那么 **CPU 利用率** 可能也会保持稳定(而不是不断快速上升和下降)。
-### 复制工具和策略示例
+### 复制工具和策略示例 { #examples-of-replication-tools-and-strategies }
可以通过多种方法来实现这一目标,我将在接下来的章节中向您详细介绍具体策略,例如在谈论 Docker 和容器时。
@@ -236,26 +232,22 @@
以下是一些可能的组合和策略:
-* **Gunicorn** 管理 **Uvicorn workers**
- * Gunicorn 将是监听 **IP** 和 **端口** 的 **进程管理器**,复制将通过 **多个 Uvicorn 工作进程** 进行
-* **Uvicorn** 管理 **Uvicorn workers**
- * 一个 Uvicorn **进程管理器** 将监听 **IP** 和 **端口**,并且它将启动 **多个 Uvicorn 工作进程**
+* 带有 `--workers` 的 **Uvicorn**
+ * 一个 Uvicorn **进程管理器** 将监听 **IP** 和 **端口**,并且它将启动 **多个 Uvicorn 工作进程**。
* **Kubernetes** 和其他分布式 **容器系统**
- * **Kubernetes** 层中的某些东西将侦听 **IP** 和 **端口**。 复制将通过拥有**多个容器**,每个容器运行**一个 Uvicorn 进程**
+ * **Kubernetes** 层中的某些东西将侦听 **IP** 和 **端口**。 复制将通过拥有**多个容器**,每个容器运行**一个 Uvicorn 进程**。
* **云服务** 为您处理此问题
- * 云服务可能**为您处理复制**。 它可能会让您定义 **要运行的进程**,或要使用的 **容器映像**,在任何情况下,它很可能是 **单个 Uvicorn 进程**,并且云服务将负责复制它。
+ * 云服务可能**为您处理复制**。 它可能会让您定义 **要运行的进程**,或要使用的 **容器映像**,在任何情况下,它很可能是 **单个 Uvicorn 进程**,并且云服务将负责复制它。
-
-
-/// tip
+/// tip | 提示
如果这些关于 **容器**、Docker 或 Kubernetes 的内容还没有多大意义,请不要担心。
- 我将在以后的章节中向您详细介绍容器镜像、Docker、Kubernetes 等:[容器中的 FastAPI - Docker](docker.md){.internal-link target=_blank}。
+我将在以后的章节中向您详细介绍容器镜像、Docker、Kubernetes 等:[容器中的 FastAPI - Docker](docker.md){.internal-link target=_blank}。
///
-## 启动之前的步骤
+## 启动之前的步骤 { #previous-steps-before-starting }
在很多情况下,您希望在**启动**应用程序之前执行一些步骤。
@@ -269,15 +261,15 @@
当然,也有一些情况,多次运行前面的步骤也没有问题,这样的话就好办多了。
-/// tip
+/// tip | 提示
另外,请记住,根据您的设置,在某些情况下,您在开始应用程序之前**可能甚至不需要任何先前的步骤**。
- 在这种情况下,您就不必担心这些。 🤷
+在这种情况下,您就不必担心这些。 🤷
///
-### 前面步骤策略的示例
+### 前面步骤策略的示例 { #examples-of-previous-steps-strategies }
这将在**很大程度上取决于您部署系统的方式**,并且可能与您启动程序、处理重启等的方式有关。
@@ -285,15 +277,15 @@
* Kubernetes 中的“Init Container”在应用程序容器之前运行
* 一个 bash 脚本,运行前面的步骤,然后启动您的应用程序
- * 您仍然需要一种方法来启动/重新启动 bash 脚本、检测错误等。
+ * 您仍然需要一种方法来启动/重新启动 bash 脚本、检测错误等。
-/// tip
+/// tip | 提示
我将在以后的章节中为您提供使用容器执行此操作的更具体示例:[容器中的 FastAPI - Docker](docker.md){.internal-link target=_blank}。
///
-## 资源利用率
+## 资源利用率 { #resource-utilization }
您的服务器是一个**资源**,您可以通过您的程序消耗或**利用**CPU 上的计算时间以及可用的 RAM 内存。
@@ -313,8 +305,7 @@
您可以使用“htop”等简单工具来查看服务器中使用的 CPU 和 RAM 或每个进程使用的数量。 或者您可以使用更复杂的监控工具,这些工具可能分布在服务器等上。
-
-## 回顾
+## 回顾 { #recap }
您在这里阅读了一些在决定如何部署应用程序时可能需要牢记的主要概念:
diff --git a/docs/zh/docs/deployment/docker.md b/docs/zh/docs/deployment/docker.md
index f120ebfb89..3d0c19903b 100644
--- a/docs/zh/docs/deployment/docker.md
+++ b/docs/zh/docs/deployment/docker.md
@@ -1,17 +1,17 @@
-# 容器中的 FastAPI - Docker
+# 容器中的 FastAPI - Docker { #fastapi-in-containers-docker }
-部署 FastAPI 应用程序时,常见的方法是构建 **Linux 容器镜像**。 通常使用 **Docker** 完成。 然后,你可以通过几种可能的方式之一部署该容器镜像。
+部署 FastAPI 应用时,常见做法是构建一个**Linux 容器镜像**。通常使用 **Docker** 实现。然后你可以用几种方式之一部署该镜像。
-使用 Linux 容器有几个优点,包括**安全性**、**可复制性**、**简单性**等。
+使用 Linux 容器有多种优势,包括**安全性**、**可复制性**、**简单性**等。
-/// tip
+/// tip | 提示
-赶时间并且已经知道这些东西了? 跳转到下面的 [`Dockerfile` 👇](#fastapi-docker_1)。
+赶时间并且已经了解这些?直接跳到下面的 [`Dockerfile` 👇](#build-a-docker-image-for-fastapi)。
///
-/// info
+/// info | 信息
漂亮的插画来自 Ketrina Thompson. 🎨
@@ -163,7 +163,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
然后你去柜台🔀, 到现在初始任务已经完成⏯, 拿起汉堡,说声谢谢,然后把它们送到桌上。这就完成了与计数器交互的步骤/任务⏹. 这反过来又产生了一项新任务,即"吃汉堡"🔀 ⏯, 上一个"拿汉堡"的任务已经结束了⏹.
-### 并行汉堡
+### 并行汉堡 { #parallel-burgers }
现在让我们假设不是"并发汉堡",而是"并行汉堡"。
@@ -205,7 +205,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
没有太多的交谈或调情,因为大部分时间 🕙 都在柜台前等待😞。
-/// info
+/// info | 信息
漂亮的插画来自 Ketrina Thompson. 🎨
@@ -233,7 +233,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
你可不会想带你的恋人 😍 和你一起去银行办事🏦.
-### 汉堡结论
+### 汉堡结论 { #burger-conclusion }
在"你与恋人一起吃汉堡"的这个场景中,因为有很多人在等待🕙, 使用并发系统更有意义⏸🔀⏯.
@@ -253,7 +253,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
你可以同时拥有并行性和异步性,你可以获得比大多数经过测试的 NodeJS 框架更高的性能,并且与 Go 不相上下, Go 是一种更接近于 C 的编译语言(全部归功于 Starlette)。
-### 并发比并行好吗?
+### 并发比并行好吗? { #is-concurrency-better-than-parallelism }
不!这不是故事的本意。
@@ -277,7 +277,7 @@ Python 的现代版本支持通过一种叫**"协程"**——使用 `async` 和
在这个场景中,每个清洁工(包括你)都将是一个处理器,完成这个工作的一部分。
-由于大多数执行时间是由实际工作(而不是等待)占用的,并且计算机中的工作是由 CPU 完成的,所以他们称这些问题为"CPU 密集型"。
+由于大多数执行时间是由实际工作(而不是等待)占用的,并且计算机中的工作是由 CPU 完成的,所以他们称这些问题为"CPU 密集型"。
---
@@ -290,7 +290,7 @@ CPU 密集型操作的常见示例是需要复杂的数学处理。
* **机器学习**: 它通常需要大量的"矩阵"和"向量"乘法。想象一个包含数字的巨大电子表格,并同时将所有数字相乘;
* **深度学习**: 这是机器学习的一个子领域,同样适用。只是没有一个数字的电子表格可以相乘,而是一个庞大的数字集合,在很多情况下,你需要使用一个特殊的处理器来构建和使用这些模型。
-### 并发 + 并行: Web + 机器学习
+### 并发 + 并行: Web + 机器学习 { #concurrency-parallelism-web-machine-learning }
使用 **FastAPI**,你可以利用 Web 开发中常见的并发机制的优势(NodeJS 的主要吸引力)。
@@ -300,7 +300,7 @@ CPU 密集型操作的常见示例是需要复杂的数学处理。
了解如何在生产环境中实现这种并行性,可查看此文 [Deployment](deployment/index.md){.internal-link target=_blank}。
-## `async` 和 `await`
+## `async` 和 `await` { #async-and-await }
现代版本的 Python 有一种非常直观的方式来定义异步代码。这使它看起来就像正常的"顺序"代码,并在适当的时候"等待"。
@@ -316,16 +316,16 @@ burgers = await get_burgers(2)
```Python hl_lines="1"
async def get_burgers(number: int):
- # Do some asynchronous stuff to create the burgers
+ # 执行一些异步操作来制作汉堡
return burgers
```
...而不是 `def`:
```Python hl_lines="2"
-# This is not asynchronous
+# 这不是异步的
def get_sequential_burgers(number: int):
- # Do some sequential stuff to create the burgers
+ # 执行一些顺序操作来制作汉堡
return burgers
```
@@ -334,7 +334,7 @@ def get_sequential_burgers(number: int):
当你想调用一个 `async def` 函数时,你必须"等待"它。因此,这不会起作用:
```Python
-# This won't work, because get_burgers was defined with: async def
+# 这样不行,因为 get_burgers 是用 async def 定义的
burgers = get_burgers(2)
```
@@ -349,7 +349,7 @@ async def read_burgers():
return burgers
```
-### 更多技术细节
+### 更多技术细节 { #more-technical-details }
你可能已经注意到,`await` 只能在 `async def` 定义的函数内部使用。
@@ -361,7 +361,7 @@ async def read_burgers():
但如果你想在没有 FastAPI 的情况下使用 `async` / `await`,则可以这样做。
-### 编写自己的异步代码
+### 编写自己的异步代码 { #write-your-own-async-code }
Starlette (和 **FastAPI**) 是基于 AnyIO 实现的,这使得它们可以兼容 Python 的标准库 asyncio 和 Trio。
@@ -371,7 +371,7 @@ Starlette (和 **FastAPI**) 是基于 Asyncer。如果你有**结合使用异步代码和常规**(阻塞/同步)代码的需求,这个库会特别有用。
-### 其他形式的异步代码
+### 其他形式的异步代码 { #other-forms-of-asynchronous-code }
这种使用 `async` 和 `await` 的风格在语言中相对较新。
@@ -385,13 +385,13 @@ Starlette (和 **FastAPI**) 是基于 I/O 的代码。
+如果你使用过另一个不以上述方式工作的异步框架,并且你习惯于用普通的 `def` 定义普通的仅计算路径操作函数,以获得微小的性能增益(大约100纳秒),请注意,在 FastAPI 中,效果将完全相反。在这些情况下,最好使用 `async def`,除非路径操作函数内使用执行阻塞 I/O 的代码。
-在这两种情况下,与你之前的框架相比,**FastAPI** 可能[仍然很快](index.md#_11){.internal-link target=_blank}。
+在这两种情况下,与你之前的框架相比,**FastAPI** 可能[仍然很快](index.md#performance){.internal-link target=_blank}。
-### 依赖
+### 依赖 { #dependencies }
这同样适用于[依赖](tutorial/dependencies/index.md){.internal-link target=_blank}。如果一个依赖是标准的 `def` 函数而不是 `async def`,它将被运行在外部线程池中。
-### 子依赖
+### 子依赖 { #sub-dependencies }
你可以拥有多个相互依赖的依赖以及[子依赖](tutorial/dependencies/sub-dependencies.md){.internal-link target=_blank} (作为函数的参数),它们中的一些可能是通过 `async def` 声明,也可能是通过 `def` 声明。它们仍然可以正常工作,这些通过 `def` 声明的函数将会在外部线程中调用(来自线程池),而不是"被等待"。
-### 其他函数
+### 其他函数 { #other-utility-functions }
你可直接调用通过 `def` 或 `async def` 创建的任何其他函数,FastAPI 不会影响你调用它们的方式。
@@ -441,4 +441,4 @@ Starlette (和 **FastAPI**) 是基于 赶时间吗?.
+否则,你最好应该遵守的指导原则赶时间吗?.
diff --git a/docs/zh/docs/deployment/cloud.md b/docs/zh/docs/deployment/cloud.md
index 8a892a560b..96883bd6bf 100644
--- a/docs/zh/docs/deployment/cloud.md
+++ b/docs/zh/docs/deployment/cloud.md
@@ -1,13 +1,24 @@
-# 在云上部署 FastAPI
+# 在云服务商上部署 FastAPI { #deploy-fastapi-on-cloud-providers }
-您几乎可以使用**任何云服务商**来部署 FastAPI 应用程序。
+你几乎可以使用**任何云服务商**来部署你的 FastAPI 应用。
-在大多数情况下,主要的云服务商都有部署 FastAPI 的指南。
+在大多数情况下,主流云服务商都有部署 FastAPI 的指南。
-## 云服务商 - 赞助商
+## FastAPI Cloud { #fastapi-cloud }
-一些云服务商 ✨ [**赞助 FastAPI**](../help-fastapi.md#sponsor-the-author){.internal-link target=_blank} ✨,这确保了FastAPI 及其**生态系统**持续健康地**发展**。
+**FastAPI Cloud** 由 **FastAPI** 背后的同一作者与团队打造。
-这表明了他们对 FastAPI 及其**社区**(您)的真正承诺,因为他们不仅想为您提供**良好的服务**,而且还想确保您拥有一个**良好且健康的框架**:FastAPI。 🙇
+它简化了**构建**、**部署**和**访问** API 的流程,几乎不费力。
-您可能想尝试他们的服务并阅读他们的指南.
+它把使用 FastAPI 构建应用时相同的**开发者体验**带到了将应用**部署**到云上的过程。🎉
+
+FastAPI Cloud 是 *FastAPI and friends* 开源项目的主要赞助方和资金提供者。✨
+
+## 云服务商 - 赞助商 { #cloud-providers-sponsors }
+
+还有一些云服务商也会 ✨ [**赞助 FastAPI**](../help-fastapi.md#sponsor-the-author){.internal-link target=_blank} ✨。🙇
+
+你也可以考虑按照他们的指南尝试他们的服务:
+
+* Render
+* Railway
diff --git a/docs/zh/docs/deployment/concepts.md b/docs/zh/docs/deployment/concepts.md
index f7208da7c5..66d32629cb 100644
--- a/docs/zh/docs/deployment/concepts.md
+++ b/docs/zh/docs/deployment/concepts.md
@@ -1,4 +1,4 @@
-# 部署概念
+# 部署概念 { #deployments-concepts }
在部署 **FastAPI** 应用程序或任何类型的 Web API 时,有几个概念值得了解,通过掌握这些概念您可以找到**最合适的**方法来**部署您的应用程序**。
@@ -13,7 +13,7 @@
我们接下来了解它们将如何影响**部署**。
-我们的最终目标是能够以**安全**的方式**为您的 API 客户端**提供服务,同时要**避免中断**,并且尽可能高效地利用**计算资源**( 例如服务器CPU资源)。 🚀
+我们的最终目标是能够以**安全**的方式**为您的 API 客户端**提供服务,同时要**避免中断**,并且尽可能高效地利用**计算资源**(例如远程服务器/虚拟机)。 🚀
我将在这里告诉您更多关于这些**概念**的信息,希望能给您提供**直觉**来决定如何在非常不同的环境中部署 API,甚至在是尚不存在的**未来**的环境里。
@@ -23,7 +23,7 @@
但现在,让我们仔细看一下这些重要的**概念**。 这些概念也适用于任何其他类型的 Web API。 💡
-## 安全性 - HTTPS
+## 安全性 - HTTPS { #security-https }
在[上一章有关 HTTPS](https.md){.internal-link target=_blank} 中,我们了解了 HTTPS 如何为您的 API 提供加密。
@@ -31,21 +31,20 @@
并且必须有某个东西负责**更新 HTTPS 证书**,它可以是相同的组件,也可以是不同的组件。
-
-### HTTPS 示例工具
+### HTTPS 示例工具 { #example-tools-for-https }
您可以用作 TLS 终止代理的一些工具包括:
* Traefik
- * 自动处理证书更新 ✨
+ * 自动处理证书更新 ✨
* Caddy
- * 自动处理证书更新 ✨
+ * 自动处理证书更新 ✨
* Nginx
- * 使用 Certbot 等外部组件进行证书更新
+ * 使用 Certbot 等外部组件进行证书更新
* HAProxy
- * 使用 Certbot 等外部组件进行证书更新
-* 带有 Ingress Controller(如Nginx) 的 Kubernetes
- * 使用诸如 cert-manager 之类的外部组件来进行证书更新
+ * 使用 Certbot 等外部组件进行证书更新
+* 带有 Ingress Controller(如 Nginx) 的 Kubernetes
+ * 使用诸如 cert-manager 之类的外部组件来进行证书更新
* 由云服务商内部处理,作为其服务的一部分(请阅读下文👇)
另一种选择是您可以使用**云服务**来完成更多工作,包括设置 HTTPS。 它可能有一些限制或向您收取更多费用等。但在这种情况下,您不必自己设置 TLS 终止代理。
@@ -56,11 +55,11 @@
接下来要考虑的概念都是关于运行实际 API 的程序(例如 Uvicorn)。
-## 程序和进程
+## 程序和进程 { #program-and-process }
我们将讨论很多关于正在运行的“**进程**”的内容,因此弄清楚它的含义以及与“**程序**”这个词有什么区别是很有用的。
-### 什么是程序
+### 什么是程序 { #what-is-a-program }
**程序**这个词通常用来描述很多东西:
@@ -68,12 +67,12 @@
* 操作系统可以**执行**的**文件**,例如:`python`、`python.exe`或`uvicorn`。
* 在操作系统上**运行**、使用CPU 并将内容存储在内存上的特定程序。 这也被称为**进程**。
-### 什么是进程
+### 什么是进程 { #what-is-a-process }
**进程** 这个词通常以更具体的方式使用,仅指在操作系统中运行的东西(如上面的最后一点):
* 在操作系统上**运行**的特定程序。
- * 这不是指文件,也不是指代码,它**具体**指的是操作系统正在**执行**和管理的东西。
+ * 这不是指文件,也不是指代码,它**具体**指的是操作系统正在**执行**和管理的东西。
* 任何程序,任何代码,**只有在执行时才能做事**。 因此,是当有**进程正在运行**时。
* 该进程可以由您或操作系统**终止**(或“杀死”)。 那时,它停止运行/被执行,并且它可以**不再做事情**。
* 您计算机上运行的每个应用程序背后都有一些进程,每个正在运行的程序,每个窗口等。并且通常在计算机打开时**同时**运行许多进程。
@@ -89,13 +88,13 @@
现在我们知道了术语“进程”和“程序”之间的区别,让我们继续讨论部署。
-## 启动时运行
+## 启动时运行 { #running-on-startup }
在大多数情况下,当您创建 Web API 时,您希望它**始终运行**、不间断,以便您的客户端始终可以访问它。 这是当然的,除非您有特定原因希望它仅在某些情况下运行,但大多数时候您希望它不断运行并且**可用**。
-### 在远程服务器中
+### 在远程服务器中 { #in-a-remote-server }
-当您设置远程服务器(云服务器、虚拟机等)时,您可以做的最简单的事情就是手动运行 Uvicorn(或类似的),就像本地开发时一样。
+当您设置远程服务器(云服务器、虚拟机等)时,您可以做的最简单的事情就是使用 `fastapi run`(它使用 Uvicorn)或类似方式,手动运行,就像本地开发时一样。
它将会在**开发过程中**发挥作用并发挥作用。
@@ -103,16 +102,15 @@
如果服务器重新启动(例如更新后或从云提供商迁移后),您可能**不会注意到它**。 因此,您甚至不知道必须手动重新启动该进程。 所以,你的 API 将一直处于挂掉的状态。 😱
-
-### 启动时自动运行
+### 启动时自动运行 { #run-automatically-on-startup }
一般来说,您可能希望服务器程序(例如 Uvicorn)在服务器启动时自动启动,并且不需要任何**人为干预**,让进程始终与您的 API 一起运行(例如 Uvicorn 运行您的 FastAPI 应用程序) 。
-### 单独的程序
+### 单独的程序 { #separate-program }
为了实现这一点,您通常会有一个**单独的程序**来确保您的应用程序在启动时运行。 在许多情况下,它还可以确保其他组件或应用程序也运行,例如数据库。
-### 启动时运行的示例工具
+### 启动时运行的示例工具 { #example-tools-to-run-at-startup }
可以完成这项工作的工具的一些示例是:
@@ -127,44 +125,43 @@
我将在接下来的章节中为您提供更具体的示例。
-
-## 重新启动
+## 重新启动 { #restarts }
与确保应用程序在启动时运行类似,您可能还想确保它在挂掉后**重新启动**。
-### 我们会犯错误
+### 我们会犯错误 { #we-make-mistakes }
作为人类,我们总是会犯**错误**。 软件几乎*总是*在不同的地方隐藏着**bug**。 🐛
作为开发人员,当我们发现这些bug并实现新功能(也可能添加新bug😅)时,我们会不断改进代码。
-### 自动处理小错误
+### 自动处理小错误 { #small-errors-automatically-handled }
使用 FastAPI 构建 Web API 时,如果我们的代码中存在错误,FastAPI 通常会将其包含到触发错误的单个请求中。 🛡
对于该请求,客户端将收到 **500 内部服务器错误**,但应用程序将继续处理下一个请求,而不是完全崩溃。
-### 更大的错误 - 崩溃
+### 更大的错误 - 崩溃 { #bigger-errors-crashes }
尽管如此,在某些情况下,我们编写的一些代码可能会导致整个应用程序崩溃,从而导致 Uvicorn 和 Python 崩溃。 💥
尽管如此,您可能不希望应用程序因为某个地方出现错误而保持死机状态,您可能希望它**继续运行**,至少对于未破坏的*路径操作*。
-### 崩溃后重新启动
+### 崩溃后重新启动 { #restart-after-crash }
但在那些严重错误导致正在运行的**进程**崩溃的情况下,您需要一个外部组件来负责**重新启动**进程,至少尝试几次......
-/// tip
+/// tip | 提示
...尽管如果整个应用程序只是**立即崩溃**,那么永远重新启动它可能没有意义。 但在这些情况下,您可能会在开发过程中注意到它,或者至少在部署后立即注意到它。
- 因此,让我们关注主要情况,在**未来**的某些特定情况下,它可能会完全崩溃,但重新启动它仍然有意义。
+因此,让我们关注主要情况,在**未来**的某些特定情况下,它可能会完全崩溃,但重新启动它仍然有意义。
///
您可能希望让这个东西作为 **外部组件** 负责重新启动您的应用程序,因为到那时,使用 Uvicorn 和 Python 的同一应用程序已经崩溃了,因此同一应用程序的相同代码中没有东西可以对此做出什么。
-### 自动重新启动的示例工具
+### 自动重新启动的示例工具 { #example-tools-to-restart-automatically }
在大多数情况下,用于**启动时运行程序**的同一工具也用于处理自动**重新启动**。
@@ -173,25 +170,25 @@
* Docker
* Kubernetes
* Docker Compose
-* Docker in Swarm mode
+* Docker in Swarm Mode
* Systemd
* Supervisor
* 作为其服务的一部分由云提供商内部处理
* 其他的...
-## 复制 - 进程和内存
+## 复制 - 进程和内存 { #replication-processes-and-memory }
-对于 FastAPI 应用程序,使用像 Uvicorn 这样的服务器程序,在**一个进程**中运行一次就可以同时为多个客户端提供服务。
+对于 FastAPI 应用程序,使用像 `fastapi` 命令(运行 Uvicorn)这样的服务器程序,在**一个进程**中运行一次就可以同时为多个客户端提供服务。
但在许多情况下,您会希望同时运行多个工作进程。
-### 多进程 - Workers
+### 多进程 - Workers { #multiple-processes-workers }
-如果您的客户端数量多于单个进程可以处理的数量(例如,如果虚拟机不是太大),并且服务器的 CPU 中有 **多个核心**,那么您可以让 **多个进程** 运行 同时处理同一个应用程序,并在它们之间分发所有请求。
+如果您的客户端数量多于单个进程可以处理的数量(例如,如果虚拟机不是太大),并且服务器的 CPU 中有 **多个核心**,那么您可以让 **多个进程** 同时运行同一个应用程序,并在它们之间分发所有请求。
当您运行同一 API 程序的**多个进程**时,它们通常称为 **workers**。
-### 工作进程和端口
+### 工作进程和端口 { #worker-processes-and-ports }
还记得文档 [About HTTPS](https.md){.internal-link target=_blank} 中只有一个进程可以侦听服务器中的端口和 IP 地址的一种组合吗?
@@ -199,20 +196,19 @@
因此,为了能够同时拥有**多个进程**,必须有一个**单个进程侦听端口**,然后以某种方式将通信传输到每个工作进程。
-### 每个进程的内存
+### 每个进程的内存 { #memory-per-process }
现在,当程序将内容加载到内存中时,例如,将机器学习模型加载到变量中,或者将大文件的内容加载到变量中,所有这些都会消耗服务器的一点内存 (RAM) 。
多个进程通常**不共享任何内存**。 这意味着每个正在运行的进程都有自己的东西、变量和内存。 如果您的代码消耗了大量内存,**每个进程**将消耗等量的内存。
-### 服务器内存
+### 服务器内存 { #server-memory }
例如,如果您的代码加载 **1 GB 大小**的机器学习模型,则当您使用 API 运行一个进程时,它将至少消耗 1 GB RAM。 如果您启动 **4 个进程**(4 个工作进程),每个进程将消耗 1 GB RAM。 因此,您的 API 总共将消耗 **4 GB RAM**。
如果您的远程服务器或虚拟机只有 3 GB RAM,尝试加载超过 4 GB RAM 将导致问题。 🚨
-
-### 多进程 - 一个例子
+### 多进程 - 一个例子 { #multiple-processes-an-example }
在此示例中,有一个 **Manager Process** 启动并控制两个 **Worker Processes**。
@@ -224,11 +220,11 @@
当然,除了您的应用程序之外,同一台机器可能还运行**其他进程**。
-一个有趣的细节是,随着时间的推移,每个进程使用的 **CPU 百分比可能会发生很大变化,但内存 (RAM) 通常会或多或少保持稳定**。
+一个有趣的细节是,随着时间的推移,每个进程使用的 **CPU 百分比**可能会发生很大变化,但**内存 (RAM)** 通常会或多或少保持**稳定**。
如果您有一个每次执行相当数量的计算的 API,并且您有很多客户端,那么 **CPU 利用率** 可能也会保持稳定(而不是不断快速上升和下降)。
-### 复制工具和策略示例
+### 复制工具和策略示例 { #examples-of-replication-tools-and-strategies }
可以通过多种方法来实现这一目标,我将在接下来的章节中向您详细介绍具体策略,例如在谈论 Docker 和容器时。
@@ -236,26 +232,22 @@
以下是一些可能的组合和策略:
-* **Gunicorn** 管理 **Uvicorn workers**
- * Gunicorn 将是监听 **IP** 和 **端口** 的 **进程管理器**,复制将通过 **多个 Uvicorn 工作进程** 进行
-* **Uvicorn** 管理 **Uvicorn workers**
- * 一个 Uvicorn **进程管理器** 将监听 **IP** 和 **端口**,并且它将启动 **多个 Uvicorn 工作进程**
+* 带有 `--workers` 的 **Uvicorn**
+ * 一个 Uvicorn **进程管理器** 将监听 **IP** 和 **端口**,并且它将启动 **多个 Uvicorn 工作进程**。
* **Kubernetes** 和其他分布式 **容器系统**
- * **Kubernetes** 层中的某些东西将侦听 **IP** 和 **端口**。 复制将通过拥有**多个容器**,每个容器运行**一个 Uvicorn 进程**
+ * **Kubernetes** 层中的某些东西将侦听 **IP** 和 **端口**。 复制将通过拥有**多个容器**,每个容器运行**一个 Uvicorn 进程**。
* **云服务** 为您处理此问题
- * 云服务可能**为您处理复制**。 它可能会让您定义 **要运行的进程**,或要使用的 **容器映像**,在任何情况下,它很可能是 **单个 Uvicorn 进程**,并且云服务将负责复制它。
+ * 云服务可能**为您处理复制**。 它可能会让您定义 **要运行的进程**,或要使用的 **容器映像**,在任何情况下,它很可能是 **单个 Uvicorn 进程**,并且云服务将负责复制它。
-
-
-/// tip
+/// tip | 提示
如果这些关于 **容器**、Docker 或 Kubernetes 的内容还没有多大意义,请不要担心。
- 我将在以后的章节中向您详细介绍容器镜像、Docker、Kubernetes 等:[容器中的 FastAPI - Docker](docker.md){.internal-link target=_blank}。
+我将在以后的章节中向您详细介绍容器镜像、Docker、Kubernetes 等:[容器中的 FastAPI - Docker](docker.md){.internal-link target=_blank}。
///
-## 启动之前的步骤
+## 启动之前的步骤 { #previous-steps-before-starting }
在很多情况下,您希望在**启动**应用程序之前执行一些步骤。
@@ -269,15 +261,15 @@
当然,也有一些情况,多次运行前面的步骤也没有问题,这样的话就好办多了。
-/// tip
+/// tip | 提示
另外,请记住,根据您的设置,在某些情况下,您在开始应用程序之前**可能甚至不需要任何先前的步骤**。
- 在这种情况下,您就不必担心这些。 🤷
+在这种情况下,您就不必担心这些。 🤷
///
-### 前面步骤策略的示例
+### 前面步骤策略的示例 { #examples-of-previous-steps-strategies }
这将在**很大程度上取决于您部署系统的方式**,并且可能与您启动程序、处理重启等的方式有关。
@@ -285,15 +277,15 @@
* Kubernetes 中的“Init Container”在应用程序容器之前运行
* 一个 bash 脚本,运行前面的步骤,然后启动您的应用程序
- * 您仍然需要一种方法来启动/重新启动 bash 脚本、检测错误等。
+ * 您仍然需要一种方法来启动/重新启动 bash 脚本、检测错误等。
-/// tip
+/// tip | 提示
我将在以后的章节中为您提供使用容器执行此操作的更具体示例:[容器中的 FastAPI - Docker](docker.md){.internal-link target=_blank}。
///
-## 资源利用率
+## 资源利用率 { #resource-utilization }
您的服务器是一个**资源**,您可以通过您的程序消耗或**利用**CPU 上的计算时间以及可用的 RAM 内存。
@@ -313,8 +305,7 @@
您可以使用“htop”等简单工具来查看服务器中使用的 CPU 和 RAM 或每个进程使用的数量。 或者您可以使用更复杂的监控工具,这些工具可能分布在服务器等上。
-
-## 回顾
+## 回顾 { #recap }
您在这里阅读了一些在决定如何部署应用程序时可能需要牢记的主要概念:
diff --git a/docs/zh/docs/deployment/docker.md b/docs/zh/docs/deployment/docker.md
index f120ebfb89..3d0c19903b 100644
--- a/docs/zh/docs/deployment/docker.md
+++ b/docs/zh/docs/deployment/docker.md
@@ -1,17 +1,17 @@
-# 容器中的 FastAPI - Docker
+# 容器中的 FastAPI - Docker { #fastapi-in-containers-docker }
-部署 FastAPI 应用程序时,常见的方法是构建 **Linux 容器镜像**。 通常使用 **Docker** 完成。 然后,你可以通过几种可能的方式之一部署该容器镜像。
+部署 FastAPI 应用时,常见做法是构建一个**Linux 容器镜像**。通常使用 **Docker** 实现。然后你可以用几种方式之一部署该镜像。
-使用 Linux 容器有几个优点,包括**安全性**、**可复制性**、**简单性**等。
+使用 Linux 容器有多种优势,包括**安全性**、**可复制性**、**简单性**等。
-/// tip
+/// tip | 提示
-赶时间并且已经知道这些东西了? 跳转到下面的 [`Dockerfile` 👇](#fastapi-docker_1)。
+赶时间并且已经了解这些?直接跳到下面的 [`Dockerfile` 👇](#build-a-docker-image-for-fastapi)。
///
 -### TLS 握手开始
+### TLS 握手开始 { #tls-handshake-start }
然后,浏览器将在**端口 443**(HTTPS 端口)上与该 IP 地址进行通信。
@@ -98,7 +97,7 @@ DNS 服务器会告诉浏览器使用某个特定的 **IP 地址**。 这将是
客户端和服务器之间建立 TLS 连接的过程称为 **TLS 握手**。
-### 带有 SNI 扩展的 TLS
+### 带有 SNI 扩展的 TLS { #tls-with-sni-extension }
**服务器中只有一个进程**可以侦听特定 **IP 地址**的特定 **端口**。 可能有其他进程在同一 IP 地址的其他端口上侦听,但每个 IP 地址和端口组合只有一个进程。
@@ -128,7 +127,7 @@ TLS 终止代理可以访问一个或多个 **TLS 证书**(HTTPS 证书)。
///
-### HTTPS 请求
+### HTTPS 请求 { #https-request }
现在客户端和服务器(特别是浏览器和 TLS 终止代理)具有 **加密的 TCP 连接**,它们可以开始 **HTTP 通信**。
@@ -136,19 +135,19 @@ TLS 终止代理可以访问一个或多个 **TLS 证书**(HTTPS 证书)。
-### TLS 握手开始
+### TLS 握手开始 { #tls-handshake-start }
然后,浏览器将在**端口 443**(HTTPS 端口)上与该 IP 地址进行通信。
@@ -98,7 +97,7 @@ DNS 服务器会告诉浏览器使用某个特定的 **IP 地址**。 这将是
客户端和服务器之间建立 TLS 连接的过程称为 **TLS 握手**。
-### 带有 SNI 扩展的 TLS
+### 带有 SNI 扩展的 TLS { #tls-with-sni-extension }
**服务器中只有一个进程**可以侦听特定 **IP 地址**的特定 **端口**。 可能有其他进程在同一 IP 地址的其他端口上侦听,但每个 IP 地址和端口组合只有一个进程。
@@ -128,7 +127,7 @@ TLS 终止代理可以访问一个或多个 **TLS 证书**(HTTPS 证书)。
///
-### HTTPS 请求
+### HTTPS 请求 { #https-request }
现在客户端和服务器(特别是浏览器和 TLS 终止代理)具有 **加密的 TCP 连接**,它们可以开始 **HTTP 通信**。
@@ -136,19 +135,19 @@ TLS 终止代理可以访问一个或多个 **TLS 证书**(HTTPS 证书)。
 -### 解密请求
+### 解密请求 { #decrypt-the-request }
TLS 终止代理将使用协商好的加密算法**解密请求**,并将**(解密的)HTTP 请求**传输到运行应用程序的进程(例如运行 FastAPI 应用的 Uvicorn 进程)。
-### 解密请求
+### 解密请求 { #decrypt-the-request }
TLS 终止代理将使用协商好的加密算法**解密请求**,并将**(解密的)HTTP 请求**传输到运行应用程序的进程(例如运行 FastAPI 应用的 Uvicorn 进程)。
 -### HTTP 响应
+### HTTP 响应 { #http-response }
应用程序将处理请求并向 TLS 终止代理发送**(未加密)HTTP 响应**。
-### HTTP 响应
+### HTTP 响应 { #http-response }
应用程序将处理请求并向 TLS 终止代理发送**(未加密)HTTP 响应**。
 -### HTTPS 响应
+### HTTPS 响应 { #https-response }
然后,TLS 终止代理将使用之前协商的加密算法(以`someapp.example.com`的证书开头)对响应进行加密,并将其发送回浏览器。
@@ -158,7 +157,7 @@ TLS 终止代理将使用协商好的加密算法**解密请求**,并将**(
客户端(浏览器)将知道响应来自正确的服务器,因为它使用了他们之前使用 **HTTPS 证书** 协商出的加密算法。
-### 多个应用程序
+### 多个应用程序 { #multiple-applications }
在同一台(或多台)服务器中,可能存在**多个应用程序**,例如其他 API 程序或数据库。
@@ -168,7 +167,7 @@ TLS 终止代理将使用协商好的加密算法**解密请求**,并将**(
这样,TLS 终止代理就可以为多个应用程序处理**多个域名**的 HTTPS 和证书,然后在每种情况下将请求传输到正确的应用程序。
-### 证书更新
+### 证书更新 { #certificate-renewal }
在未来的某个时候,每个证书都会**过期**(大约在获得证书后 3 个月)。
@@ -183,16 +182,48 @@ TLS 终止代理将使用协商好的加密算法**解密请求**,并将**(
有多种方法可以做到这一点。 一些流行的方式是:
* **修改一些DNS记录**。
- * 为此,续订程序需要支持 DNS 提供商的 API,因此,要看你使用的 DNS 提供商是否提供这一功能。
+ * 为此,续订程序需要支持 DNS 提供商的 API,因此,要看你使用的 DNS 提供商是否提供这一功能。
* **在与域名关联的公共 IP 地址上作为服务器运行**(至少在证书获取过程中)。
- * 正如我们上面所说,只有一个进程可以监听特定的 IP 和端口。
- * 这就是当同一个 TLS 终止代理还负责证书续订过程时它非常有用的原因之一。
- * 否则,你可能需要暂时停止 TLS 终止代理,启动续订程序以获取证书,然后使用 TLS 终止代理配置它们,然后重新启动 TLS 终止代理。 这并不理想,因为你的应用程序在 TLS 终止代理关闭期间将不可用。
+ * 正如我们上面所说,只有一个进程可以监听特定的 IP 和端口。
+ * 这就是当同一个 TLS 终止代理还负责证书续订过程时它非常有用的原因之一。
+ * 否则,你可能需要暂时停止 TLS 终止代理,启动续订程序以获取证书,然后使用 TLS 终止代理配置它们,然后重新启动 TLS 终止代理。 这并不理想,因为你的应用程序在 TLS 终止代理关闭期间将不可用。
通过拥有一个**单独的系统来使用 TLS 终止代理来处理 HTTPS**, 而不是直接将 TLS 证书与应用程序服务器一起使用 (例如 Uvicorn),你可以在
更新证书的过程中同时保持提供服务。
-## 回顾
+## 代理转发请求头 { #proxy-forwarded-headers }
+
+当使用代理来处理 HTTPS 时,你的**应用服务器**(例如通过 FastAPI CLI 运行的 Uvicorn)对 HTTPS 过程并不了解,它只通过纯 HTTP 与 **TLS 终止代理**通信。
+
+这个**代理**通常会在将请求转发给**应用服务器**之前,临时设置一些 HTTP 请求头,以便让应用服务器知道该请求是由代理**转发**过来的。
+
+/// note | 技术细节
+
+这些代理请求头包括:
+
+* X-Forwarded-For
+* X-Forwarded-Proto
+* X-Forwarded-Host
+
+///
+
+不过,由于**应用服务器**并不知道自己位于受信任的**代理**之后,默认情况下,它不会信任这些请求头。
+
+但你可以配置**应用服务器**去信任由**代理**发送的这些“转发”请求头。如果你在使用 FastAPI CLI,可以使用命令行选项 `--forwarded-allow-ips` 指定它应该信任哪些 IP 发来的这些“转发”请求头。
+
+例如,如果**应用服务器**只接收来自受信任**代理**的通信,你可以设置 `--forwarded-allow-ips="*"`,让它信任所有传入的 IP,因为它只会接收来自**代理**所使用 IP 的请求。
+
+这样,应用就能知道自己的公共 URL、是否使用 HTTPS、域名等信息。
+
+这在需要正确处理重定向等场景时很有用。
+
+/// tip
+
+你可以在文档中了解更多:[在代理之后 - 启用代理转发请求头](../advanced/behind-a-proxy.md#enable-proxy-forwarded-headers){.internal-link target=_blank}
+
+///
+
+## 回顾 { #recap }
拥有**HTTPS** 非常重要,并且在大多数情况下相当**关键**。 作为开发人员,你围绕 HTTPS 所做的大部分努力就是**理解这些概念**以及它们的工作原理。
diff --git a/docs/zh/docs/deployment/index.md b/docs/zh/docs/deployment/index.md
index 1ec0c5c5b5..47dcede653 100644
--- a/docs/zh/docs/deployment/index.md
+++ b/docs/zh/docs/deployment/index.md
@@ -1,21 +1,23 @@
-# 部署
+# 部署 { #deployment }
部署 **FastAPI** 应用程序相对容易。
-## 部署是什么意思
+## 部署是什么意思 { #what-does-deployment-mean }
**部署**应用程序意味着执行必要的步骤以使其**可供用户使用**。
-对于**Web API**来说,通常涉及将上传到**云服务器**中,搭配一个性能和稳定性都不错的**服务器程序**,以便你的**用户**可以高效地**访问**你的应用程序,而不会出现中断或其他问题。
+对于**Web API**来说,通常涉及将其放到一台**远程机器**中,搭配一个性能和稳定性都不错的**服务器程序**,以便你的**用户**可以高效地**访问**你的应用程序,而不会出现中断或其他问题。
-这与**开发**阶段形成鲜明对比,在**开发**阶段,你不断更改代码、破坏代码、修复代码, 来回停止和重启服务器等。
+这与**开发**阶段形成鲜明对比,在**开发**阶段,你不断更改代码、破坏代码、修复代码,来回停止和重启开发服务器等。
-## 部署策略
+## 部署策略 { #deployment-strategies }
根据你的使用场景和使用的工具,有多种方法可以实现此目的。
你可以使用一些工具自行**部署服务器**,你也可以使用能为你完成部分工作的**云服务**,或其他可能的选项。
+例如,我们(FastAPI 团队)构建了 **FastAPI Cloud**,让将 FastAPI 应用部署到云端尽可能流畅,并且保持与使用 FastAPI 开发时相同的开发者体验。
+
我将向你展示在部署 **FastAPI** 应用程序时你可能应该记住的一些主要概念(尽管其中大部分适用于任何其他类型的 Web 应用程序)。
在接下来的部分中,你将看到更多需要记住的细节以及一些技巧。 ✨
diff --git a/docs/zh/docs/deployment/manually.md b/docs/zh/docs/deployment/manually.md
index 2c2784a640..6f2ad27b2f 100644
--- a/docs/zh/docs/deployment/manually.md
+++ b/docs/zh/docs/deployment/manually.md
@@ -1,6 +1,6 @@
-# 手动运行服务器
+# 手动运行服务器 { #run-a-server-manually }
-## 使用 `fastapi run` 命令
+## 使用 `fastapi run` 命令 { #use-the-fastapi-run-command }
简而言之,使用 `fastapi run` 来运行您的 FastAPI 应用程序:
@@ -42,11 +42,11 @@ $ fastapi run ASGI。FastAPI 本质上是一个 ASGI Web 框架。
+FastAPI 使用了一种用于构建 Python Web 框架和服务器的标准,称为 ASGI。FastAPI 本质上是一个 ASGI Web 框架。
要在远程服务器上运行 **FastAPI** 应用(或任何其他 ASGI 应用),您需要一个 ASGI 服务器程序,例如 **Uvicorn**。它是 `fastapi` 命令默认使用的 ASGI 服务器。
@@ -58,7 +58,7 @@ FastAPI 使用了一种用于构建 Python Web 框架和服务器的标准,称
* Granian:基于 Rust 的 HTTP 服务器,专为 Python 应用设计。
* NGINX Unit:NGINX Unit 是一个轻量级且灵活的 Web 应用运行时环境。
-## 服务器主机和服务器程序
+## 服务器主机和服务器程序 { #server-machine-and-server-program }
关于名称,有一个小细节需要记住。 💡
@@ -68,8 +68,7 @@ FastAPI 使用了一种用于构建 Python Web 框架和服务器的标准,称
当提到远程主机时,通常将其称为**服务器**,但也称为**机器**(machine)、**VM**(虚拟机)、**节点**。 这些都是指某种类型的远程计算机,通常运行 Linux,您可以在其中运行程序。
-
-## 安装服务器程序
+## 安装服务器程序 { #install-the-server-program }
当您安装 FastAPI 时,它自带一个生产环境服务器——Uvicorn,并且您可以使用 `fastapi run` 命令来启动它。
@@ -101,7 +100,7 @@ $ pip install "uvicorn[standard]"
///
-## 运行服务器程序
+## 运行服务器程序 { #run-the-server-program }
如果您手动安装了 ASGI 服务器,通常需要以特定格式传递一个导入字符串,以便服务器能够正确导入您的 FastAPI 应用:
@@ -142,7 +141,7 @@ Uvicorn 和其他服务器支持 `--reload` 选项,该选项在开发过程中
///
-## 部署概念
+## 部署概念 { #deployment-concepts }
这些示例运行服务器程序(例如 Uvicorn),启动**单个进程**,在所有 IP(`0.0.0.0`)上监听预定义端口(例如`80`)。
diff --git a/docs/zh/docs/deployment/server-workers.md b/docs/zh/docs/deployment/server-workers.md
index e46ba7a09d..2bbd5d9b6a 100644
--- a/docs/zh/docs/deployment/server-workers.md
+++ b/docs/zh/docs/deployment/server-workers.md
@@ -1,4 +1,4 @@
-# 服务器工作进程(Workers) - 使用 Uvicorn 的多工作进程模式
+# 服务器工作进程(Workers) - 使用 Uvicorn 的多工作进程模式 { #server-workers-uvicorn-with-workers }
让我们回顾一下之前的部署概念:
@@ -17,7 +17,7 @@
在本章节中,我将向您展示如何使用 `fastapi` 命令或直接使用 `uvicorn` 命令以**多工作进程模式**运行 **Uvicorn**。
-/// info
+/// info | 信息
如果您正在使用容器,例如 Docker 或 Kubernetes,我将在下一章中告诉您更多相关信息:[容器中的 FastAPI - Docker](docker.md){.internal-link target=_blank}。
@@ -25,7 +25,7 @@
///
-## 多个工作进程
+## 多个工作进程 { #multiple-workers }
您可以使用 `--workers` 命令行选项来启动多个工作进程:
@@ -111,7 +111,7 @@ $ uvicorn main:app --host 0.0.0.0 --port 8080 --workers 4
您还可以看到它显示了每个进程的 **PID**,父进程(这是**进程管理器**)的 PID 为`27365`,每个工作进程的 PID 为:`27368`、`27369`, `27370`和`27367`。
-## 部署概念
+## 部署概念 { #deployment-concepts }
在这里,您学习了如何使用多个**工作进程(workers)**来让应用程序的执行**并行化**,充分利用 CPU 的**多核性能**,并能够处理**更多的请求**。
@@ -124,13 +124,13 @@ $ uvicorn main:app --host 0.0.0.0 --port 8080 --workers 4
* **内存**
* **启动之前的先前步骤**
-## 容器和 Docker
+## 容器和 Docker { #containers-and-docker }
在关于 [容器中的 FastAPI - Docker](docker.md){.internal-link target=_blank} 的下一章中,我将介绍一些可用于处理其他**部署概念**的策略。
我将向您展示如何**从零开始构建自己的镜像**,以运行一个单独的 Uvicorn 进程。这个过程相对简单,并且在使用 **Kubernetes** 等分布式容器管理系统时,这通常是您需要采取的方法。
-## 回顾
+## 回顾 { #recap }
您可以在使用 `fastapi` 或 `uvicorn` 命令时,通过 `--workers` CLI 选项启用多个工作进程(workers),以充分利用**多核 CPU**,以**并行运行多个进程**。
diff --git a/docs/zh/docs/deployment/versions.md b/docs/zh/docs/deployment/versions.md
index 228bb07653..23c37f3b5b 100644
--- a/docs/zh/docs/deployment/versions.md
+++ b/docs/zh/docs/deployment/versions.md
@@ -1,4 +1,4 @@
-# 关于 FastAPI 版本
+# 关于 FastAPI 版本 { #about-fastapi-versions }
**FastAPI** 已在许多应用程序和系统的生产环境中使用。 并且测试覆盖率保持在100%。 但其开发进度仍在快速推进。
@@ -8,41 +8,41 @@
你现在就可以使用 **FastAPI** 创建生产环境应用程序(你可能已经这样做了一段时间),你只需确保使用的版本可以与其余代码正确配合即可。
-## 固定你的 `fastapi` 版本
+## 固定你的 `fastapi` 版本 { #pin-your-fastapi-version }
你应该做的第一件事是将你正在使用的 **FastAPI** 版本“固定”到你知道适用于你的应用程序的特定最新版本。
-例如,假设你在应用程序中使用版本`0.45.0`。
+例如,假设你在应用程序中使用版本`0.112.0`。
如果你使用`requirements.txt`文件,你可以使用以下命令指定版本:
-````txt
-fastapi==0.45.0
-````
+```txt
+fastapi[standard]==0.112.0
+```
-这意味着你将使用版本`0.45.0`。
+这意味着你将使用版本`0.112.0`。
或者你也可以将其固定为:
-````txt
-fastapi>=0.45.0,<0.46.0
-````
+```txt
+fastapi[standard]>=0.112.0,<0.113.0
+```
-这意味着你将使用`0.45.0`或更高版本,但低于`0.46.0`,例如,版本`0.45.2`仍会被接受。
+这意味着你将使用`0.112.0`或更高版本,但低于`0.113.0`,例如,版本`0.112.2`仍会被接受。
-如果你使用任何其他工具来管理你的安装,例如 Poetry、Pipenv 或其他工具,它们都有一种定义包的特定版本的方法。
+如果你使用任何其他工具来管理你的安装,例如 `uv`、Poetry、Pipenv 或其他工具,它们都有一种定义包的特定版本的方法。
-## 可用版本
+## 可用版本 { #available-versions }
你可以在[发行说明](../release-notes.md){.internal-link target=_blank}中查看可用版本(例如查看当前最新版本)。
-## 关于版本
+## 关于版本 { #about-versions }
遵循语义版本控制约定,任何低于`1.0.0`的版本都可能会添加 breaking changes。
-FastAPI 还遵循这样的约定:任何`PATCH`版本更改都是为了bug修复和non-breaking changes。
+FastAPI 还遵循这样的约定:任何"PATCH"版本更改都是为了bug修复和non-breaking changes。
-/// tip
+/// tip | 提示
"PATCH"是最后一个数字,例如,在`0.2.3`中,PATCH版本是`3`。
@@ -56,13 +56,13 @@ fastapi>=0.45.0,<0.46.0
"MINOR"版本中会添加breaking changes和新功能。
-/// tip
+/// tip | 提示
"MINOR"是中间的数字,例如,在`0.2.3`中,MINOR版本是`2`。
///
-## 升级FastAPI版本
+## 升级FastAPI版本 { #upgrading-the-fastapi-versions }
你应该为你的应用程序添加测试。
@@ -72,7 +72,7 @@ fastapi>=0.45.0,<0.46.0
如果一切正常,或者在进行必要的更改之后,并且所有测试都通过了,那么你可以将`fastapi`固定到新的版本。
-## 关于Starlette
+## 关于Starlette { #about-starlette }
你不应该固定`starlette`的版本。
@@ -80,14 +80,14 @@ fastapi>=0.45.0,<0.46.0
因此,**FastAPI** 自己可以使用正确的 Starlette 版本。
-## 关于 Pydantic
+## 关于 Pydantic { #about-pydantic }
Pydantic 包含针对 **FastAPI** 的测试及其自己的测试,因此 Pydantic 的新版本(`1.0.0`以上)始终与 FastAPI 兼容。
-你可以将 Pydantic 固定到适合你的`1.0.0`以上和`2.0.0`以下的任何版本。
+你可以将 Pydantic 固定到任何高于 `1.0.0` 且适合你的版本。
例如:
-````txt
-pydantic>=1.2.0,<2.0.0
-````
+```txt
+pydantic>=2.7.0,<3.0.0
+```
diff --git a/docs/zh/docs/fastapi-cli.md b/docs/zh/docs/fastapi-cli.md
index 3b67eb6645..4d3b51a57a 100644
--- a/docs/zh/docs/fastapi-cli.md
+++ b/docs/zh/docs/fastapi-cli.md
@@ -1,8 +1,8 @@
-# FastAPI CLI
+# FastAPI CLI { #fastapi-cli }
**FastAPI CLI** 是一个命令行程序,你可以用它来部署和运行你的 FastAPI 应用程序,管理你的 FastAPI 项目,等等。
-当你安装 FastAPI 时(例如使用 `pip install FastAPI` 命令),会包含一个名为 `fastapi-cli` 的软件包,该软件包在终端中提供 `fastapi` 命令。
+当你安装 FastAPI 时(例如使用 `pip install "fastapi[standard]"`),会包含一个名为 `fastapi-cli` 的软件包,该软件包在终端中提供 `fastapi` 命令。
要在开发环境中运行你的 FastAPI 应用,你可以使用 `fastapi dev` 命令:
@@ -48,32 +48,28 @@ $ fastapi dev Uvicorn,这是一个高性能、适用于生产环境的 ASGI 服务器。😎
-## `fastapi dev`
+## `fastapi dev` { #fastapi-dev }
当你运行 `fastapi dev` 时,它将以开发模式运行。
-默认情况下,它会启用**自动重载**,因此当你更改代码时,它会自动重新加载服务器。该功能是资源密集型的,且相较不启用时更不稳定,因此你应该仅在开发环境下使用它。
+默认情况下,它会启用**自动重载**,因此当你更改代码时,它会自动重新加载服务器。该功能是资源密集型的,且相较不启用时更不稳定,因此你应该仅在开发环境下使用它。它还会监听 IP 地址 `127.0.0.1`,这是你的机器仅与自身通信的 IP(`localhost`)。
-默认情况下,它将监听 IP 地址 `127.0.0.1`,这是你的机器与自身通信的 IP 地址(`localhost`)。
-
-## `fastapi run`
+## `fastapi run` { #fastapi-run }
当你运行 `fastapi run` 时,它默认以生产环境模式运行。
-默认情况下,**自动重载是禁用的**。
-
-它将监听 IP 地址 `0.0.0.0`,即所有可用的 IP 地址,这样任何能够与该机器通信的人都可以公开访问它。这通常是你在生产环境中运行它的方式,例如在容器中运行。
+默认情况下,**自动重载是禁用的**。它将监听 IP 地址 `0.0.0.0`,即所有可用的 IP 地址,这样任何能够与该机器通信的人都可以公开访问它。这通常是你在生产环境中运行它的方式,例如在容器中运行。
在大多数情况下,你会(且应该)有一个“终止代理”在上层为你处理 HTTPS,这取决于你如何部署应用程序,你的服务提供商可能会为你处理此事,或者你可能需要自己设置。
/// tip | 提示
-你可以在 [deployment documentation](deployment/index.md){.internal-link target=_blank} 获得更多信息。
+你可以在[部署文档](deployment/index.md){.internal-link target=_blank}中了解更多。
///
diff --git a/docs/zh/docs/features.md b/docs/zh/docs/features.md
index eaf8daff7e..7d7aa19c06 100644
--- a/docs/zh/docs/features.md
+++ b/docs/zh/docs/features.md
@@ -1,22 +1,21 @@
-# 特性
+# 特性 { #features }
-## FastAPI 特性
+## FastAPI 特性 { #fastapi-features }
**FastAPI** 提供了以下内容:
-### 基于开放标准
+### 基于开放标准 { #based-on-open-standards }
-
-* 用于创建 API 的 OpenAPI 包含了路径操作,请求参数,请求体,安全性等的声明。
-* 使用 JSON Schema (因为 OpenAPI 本身就是基于 JSON Schema 的)自动生成数据模型文档。
+* 用于创建 API 的 OpenAPI,包含对路径 操作、参数、请求体、安全等的声明。
+* 使用 JSON Schema 自动生成数据模型文档(因为 OpenAPI 本身就是基于 JSON Schema 的)。
* 经过了缜密的研究后围绕这些标准而设计。并非狗尾续貂。
* 这也允许了在很多语言中自动**生成客户端代码**。
-### 自动生成文档
+### 自动生成文档 { #automatic-docs }
交互式 API 文档以及具探索性 web 界面。因为该框架是基于 OpenAPI,所以有很多可选项,FastAPI 默认自带两个交互式 API 文档。
-* Swagger UI,可交互式操作,能在浏览器中直接调用和测试你的 API 。
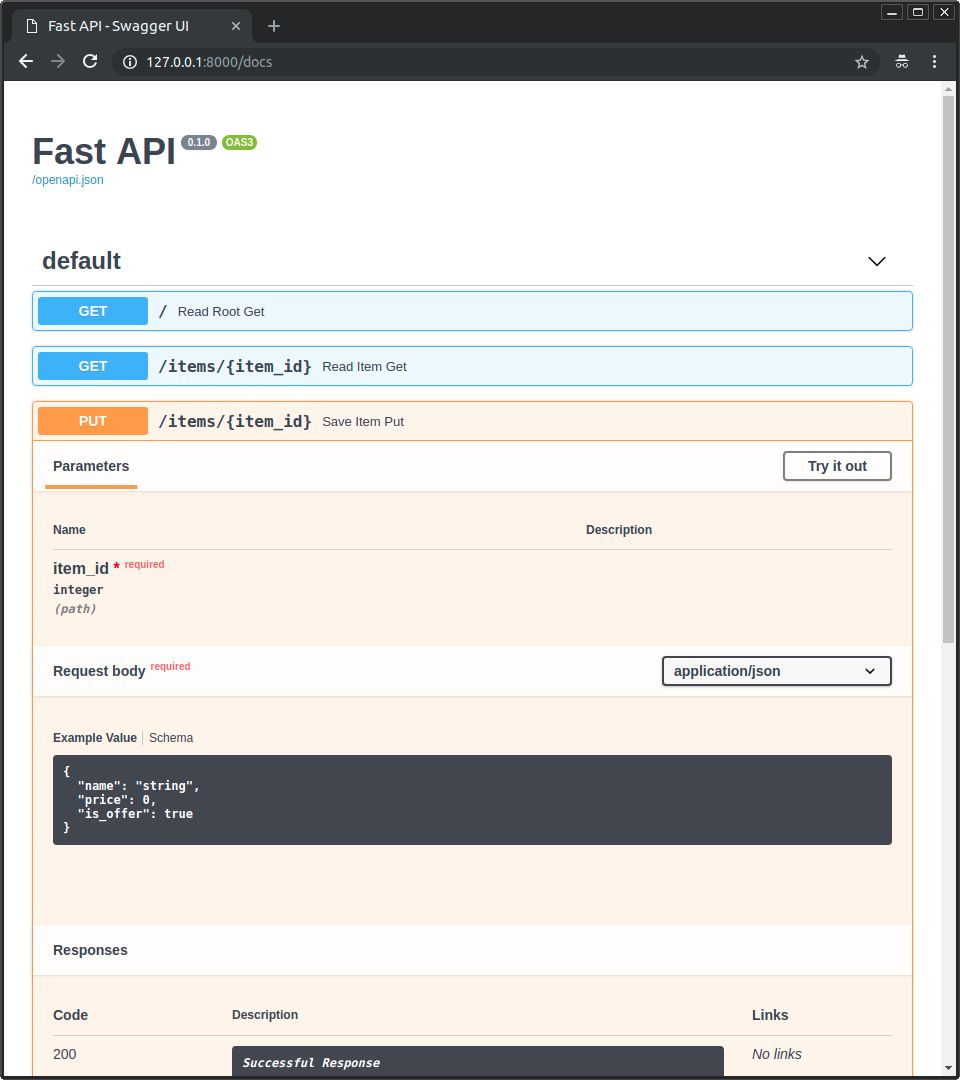
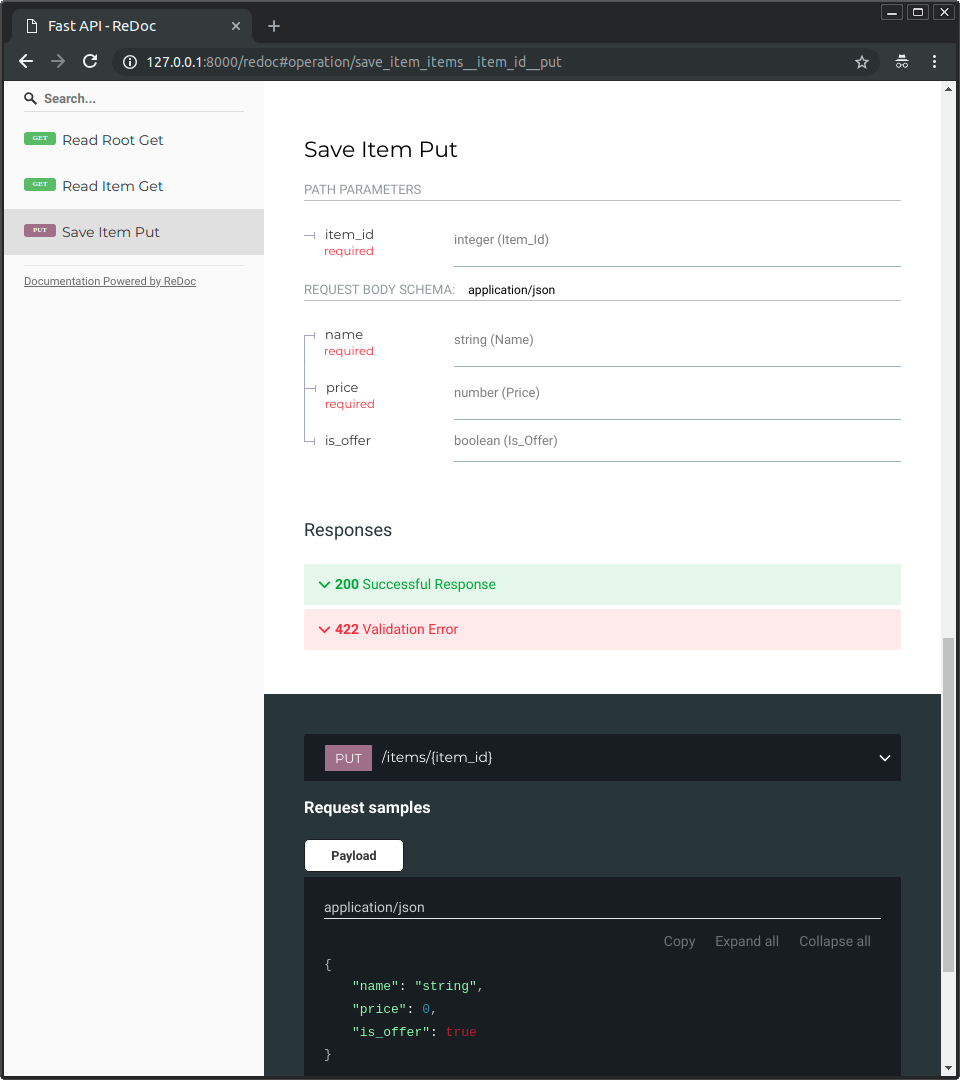
+* Swagger UI,可交互式操作,能在浏览器中直接调用和测试你的 API。
@@ -24,11 +23,11 @@
-### 更主流的 Python
+### 更主流的 Python { #just-modern-python }
-全部都基于标准的 **Python 3.6 类型**声明(感谢 Pydantic )。没有新的语法需要学习。只需要标准的 Python 。
+全部都基于标准的 **Python 类型** 声明(感谢 Pydantic)。没有新的语法需要学习。只需要标准的现代 Python。
-如果你需要2分钟来学习如何使用 Python 类型(即使你不使用 FastAPI ),看看这个简短的教程:[Python Types](python-types.md){.internal-link target=_blank}。
+如果你需要2分钟来学习如何使用 Python 类型(即使你不使用 FastAPI),看看这个简短的教程:[Python Types](python-types.md){.internal-link target=_blank}。
编写带有类型标注的标准 Python:
@@ -37,13 +36,13 @@ from datetime import date
from pydantic import BaseModel
-# Declare a variable as a str
-# and get editor support inside the function
+# 将变量声明为 str
+# 并在函数内获得编辑器支持
def main(user_id: str):
return user_id
-# A Pydantic model
+# 一个 Pydantic 模型
class User(BaseModel):
id: int
name: str
@@ -65,19 +64,19 @@ my_second_user: User = User(**second_user_data)
```
-/// info
+/// info | 信息
-`**second_user_data` 意思是:
+`**second_user_data` 意思是:
-直接将`second_user_data`字典的键和值直接作为key-value参数传递,等同于:`User(id=4, name="Mary", joined="2018-11-30")`
+直接将 `second_user_data` 字典的键和值作为 key-value 参数传入,等同于:`User(id=4, name="Mary", joined="2018-11-30")`
///
-### 编辑器支持
+### 编辑器支持 { #editor-support }
整个框架都被设计得易于使用且直观,所有的决定都在开发之前就在多个编辑器上进行了测试,来确保最佳的开发体验。
-在最近的 Python 开发者调查中,我们能看到 被使用最多的功能是"自动补全"。
+在最近的 Python 开发者调查中,我们能看到 被使用最多的功能是“自动补全”。
整个 **FastAPI** 框架就是基于这一点的。任何地方都可以进行自动补全。
@@ -85,62 +84,58 @@ my_second_user: User = User(**second_user_data)
在这里,你的编辑器可能会这样帮助你:
-* Visual Studio Code 中:
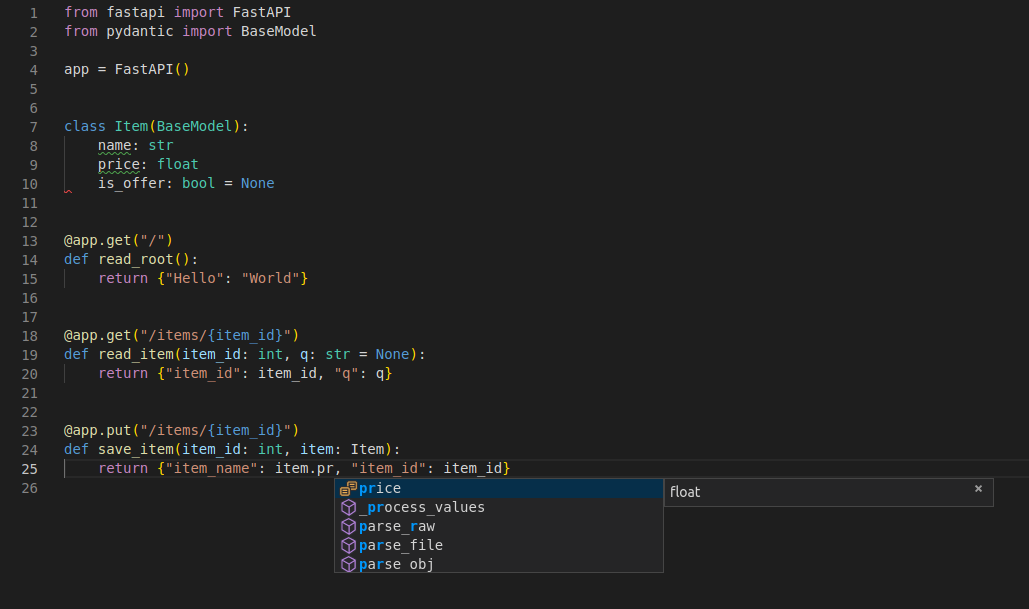
+* 在 Visual Studio Code 中:
-* PyCharm 中:
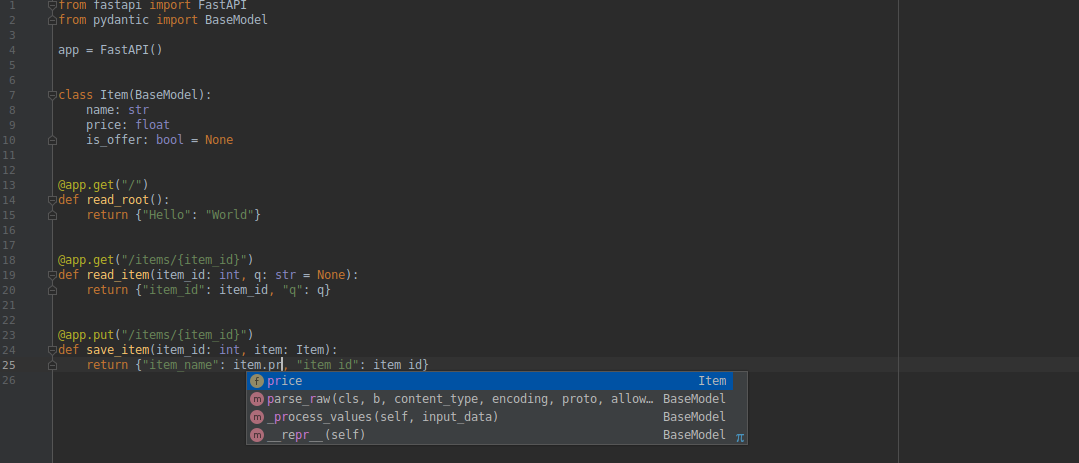
+* 在 PyCharm 中:
你将能进行代码补全,这是在之前你可能曾认为不可能的事。例如,在来自请求 JSON 体(可能是嵌套的)中的键 `price`。
-不会再输错键名,来回翻看文档,或者来回滚动寻找你最后使用的 `username` 或者 `user_name` 。
+不会再输错键名,来回翻看文档,或者来回滚动寻找你最后使用的 `username` 或者 `user_name`。
-
-
-### 简洁
+### 简洁 { #short }
任何类型都有合理的**默认值**,任何和地方都有可选配置。所有的参数被微调,来满足你的需求,定义成你需要的 API。
但是默认情况下,一切都能**“顺利工作”**。
-### 验证
+### 验证 { #validation }
* 校验大部分(甚至所有?)的 Python **数据类型**,包括:
- * JSON 对象 (`dict`).
+ * JSON 对象 (`dict`)。
* JSON 数组 (`list`) 定义成员类型。
- * 字符串 (`str`) 字段, 定义最小或最大长度。
- * 数字 (`int`, `float`) 有最大值和最小值, 等等。
+ * 字符串 (`str`) 字段,定义最小或最大长度。
+ * 数字 (`int`, `float`) 有最大值和最小值,等等。
-* 校验外来类型, 比如:
- * URL.
- * Email.
- * UUID.
- * ...及其他.
+* 校验外来类型,比如:
+ * URL。
+ * Email。
+ * UUID。
+ * ...及其他。
所有的校验都由完善且强大的 **Pydantic** 处理。
-### 安全性及身份验证
+### 安全性及身份验证 { #security-and-authentication }
集成了安全性和身份认证。杜绝数据库或者数据模型的渗透风险。
OpenAPI 中定义的安全模式,包括:
* HTTP 基本认证。
-* **OAuth2** (也使用 **JWT tokens**)。在 [OAuth2 with JWT](tutorial/security/oauth2-jwt.md){.internal-link target=_blank}查看教程。
+* **OAuth2**(也使用 **JWT tokens**)。在 [OAuth2 with JWT](tutorial/security/oauth2-jwt.md){.internal-link target=_blank}查看教程。
* API 密钥,在:
* 请求头。
* 查询参数。
- * Cookies, 等等。
+ * Cookies,等等。
加上来自 Starlette(包括 **session cookie**)的所有安全特性。
所有的这些都是可复用的工具和组件,可以轻松与你的系统,数据仓库,关系型以及 NoSQL 数据库等等集成。
-
-
-### 依赖注入
+### 依赖注入 { #dependency-injection }
FastAPI 有一个使用非常简单,但是非常强大的依赖注入系统。
@@ -149,48 +144,47 @@ FastAPI 有一个使用非常简单,但是非常强大的IDE/linter/brain** 适配:
* 因为 pydantic 数据结构仅仅是你定义的类的实例;自动补全,linting,mypy 以及你的直觉应该可以和你验证的数据一起正常工作。
* 验证**复杂结构**:
- * 使用分层的 Pydantic 模型, Python `typing`的 `List` 和 `Dict` 等等。
- * 验证器使我们能够简单清楚的将复杂的数据模式定义、检查并记录为 JSON Schema。
+ * 使用分层的 Pydantic 模型,Python `typing` 的 `List` 和 `Dict` 等等。
+ * 验证器使我们能够简单清楚地将复杂的数据模式定义、检查并记录为 JSON Schema。
* 你可以拥有深度**嵌套的 JSON** 对象并对它们进行验证和注释。
* **可扩展**:
* Pydantic 允许定义自定义数据类型或者你可以用验证器装饰器对被装饰的模型上的方法扩展验证。
diff --git a/docs/zh/docs/help-fastapi.md b/docs/zh/docs/help-fastapi.md
index f01eb9eb5d..5a5157b5d3 100644
--- a/docs/zh/docs/help-fastapi.md
+++ b/docs/zh/docs/help-fastapi.md
@@ -1,147 +1,254 @@
-# 帮助 FastAPI 与求助
+# 帮助 FastAPI - 获取帮助 { #help-fastapi-get-help }
-您喜欢 **FastAPI** 吗?
+你喜欢 **FastAPI** 吗?
-想帮助 FastAPI?其它用户?还有项目作者?
+想帮助 FastAPI、其他用户和作者吗?
-或要求助怎么使用 **FastAPI**?
+或者你想获取 **FastAPI** 的帮助?
-以下几种帮助的方式都非常简单(有些只需要点击一两下鼠标)。
+有很多非常简单的方式可以帮忙(有些只需点一两下)。
-求助的渠道也很多。
+同样,也有多种途径可以获得帮助。
-## 订阅新闻邮件
+## 订阅新闻邮件 { #subscribe-to-the-newsletter }
-您可以订阅 [**FastAPI 和它的小伙伴** 新闻邮件](newsletter.md){.internal-link target=_blank}(不会经常收到)
+你可以订阅(不频繁的)[**FastAPI and friends** 新闻邮件](newsletter.md){.internal-link target=_blank},获取如下更新:
* FastAPI 及其小伙伴的新闻 🚀
* 指南 📝
* 功能 ✨
* 破坏性更改 🚨
-* 开发技巧 ✅
+* 使用技巧 ✅
-## 在推特上关注 FastAPI
+## 在 X (Twitter) 上关注 FastAPI { #follow-fastapi-on-x-twitter }
-在 **X (Twitter)** 上关注 @fastapi 获取 **FastAPI** 的最新消息。🐦
+在 **X (Twitter)** 上关注 @fastapi 获取 **FastAPI** 的最新动态。🐦
-## 在 GitHub 上为 **FastAPI** 加星
+## 在 GitHub 上为 **FastAPI** 加星 { #star-fastapi-in-github }
-您可以在 GitHub 上 **Star** FastAPI(只要点击右上角的星星就可以了): https://github.com/fastapi/fastapi。⭐️
+你可以在 GitHub 上为 FastAPI 点亮「星标」(点击右上角的星形按钮):https://github.com/fastapi/fastapi。⭐️
-**Star** 以后,其它用户就能更容易找到 FastAPI,并了解到已经有其他用户在使用它了。
+点亮星标后,其他用户更容易发现它,并看到它已经对许多人有帮助。
-## 关注 GitHub 资源库的版本发布
+## 关注 GitHub 资源库的版本发布 { #watch-the-github-repository-for-releases }
-您还可以在 GitHub 上 **Watch** FastAPI,(点击右上角的 **Watch** 按钮)https://github.com/fastapi/fastapi。👀
+你可以在 GitHub 上「关注」FastAPI(点击右上角的「watch」按钮):https://github.com/fastapi/fastapi。👀
-您可以选择只关注发布(**Releases only**)。
+在那里你可以选择「Releases only」。
-这样,您就可以(在电子邮件里)接收到 **FastAPI** 新版发布的通知,及时了解 bug 修复与新功能。
+这样做之后,每当 **FastAPI** 发布新版本(包含修复和新功能),你都会收到通知(邮件)。
-## 联系作者
+## 联系作者 { #connect-with-the-author }
-您可以联系项目作者,就是我(Sebastián Ramírez / `tiangolo`)。
+你可以联系我(Sebastián Ramírez / `tiangolo`),作者本人。
-您可以:
+你可以:
-* 在 **GitHub** 上关注我
- * 了解其它我创建的开源项目,或许对您会有帮助
- * 关注我什么时候创建新的开源项目
-* 在 **X (Twitter)** 上关注我
- * 告诉我您使用 FastAPI(我非常乐意听到这种消息)
- * 接收我发布公告或新工具的消息
- * 您还可以关注@fastapi on X (Twitter),这是个独立的账号
-* 在**领英**上联系我
- * 接收我发布公告或新工具的消息(虽然我用 X (Twitter) 比较多)
-* 阅读我在 **Dev.to** 或 **Medium** 上的文章,或关注我
- * 阅读我的其它想法、文章,了解我创建的工具
- * 关注我,这样就可以随时看到我发布的新文章
+* 在 **GitHub** 上关注我。
+ * 了解我创建的其他开源项目,也许对你有帮助。
+ * 关注我何时创建新的开源项目。
+* 关注我在 **X (Twitter)** 或 Mastodon。
+ * 告诉我你如何使用 FastAPI(我很喜欢听这些)。
+ * 获取我发布公告或新工具的消息。
+ * 你也可以关注 @fastapi on X (Twitter)(独立账号)。
+* 在 **LinkedIn** 上关注我。
+ * 获取我发布公告或新工具的消息(不过我更常用 X (Twitter) 🤷♂)。
+* 阅读我在 **Dev.to** 或 **Medium** 上的文章(或关注我)。
+ * 阅读我的其他想法、文章,以及我创建的工具。
+ * 关注我,这样当我发布新文章时你会第一时间看到。
-## Tweet about **FastAPI**
+## 发推谈谈 **FastAPI** { #tweet-about-fastapi }
-Tweet about **FastAPI** 让我和大家知道您为什么喜欢 FastAPI。🎉
+Tweet about **FastAPI**,告诉我和大家你为什么喜欢它。🎉
-知道有人使用 **FastAPI**,我会很开心,我也想知道您为什么喜欢 FastAPI,以及您在什么项目/哪些公司使用 FastAPI,等等。
+我很高兴听到 **FastAPI** 的使用情况、你喜欢它的哪些点、你在哪个项目/公司使用它,等等。
-## 为 FastAPI 投票
+## 为 FastAPI 投票 { #vote-for-fastapi }
-* 在 Slant 上为 **FastAPI** 投票
-* 在 AlternativeTo 上为 **FastAPI** 投票
+* 在 Slant 上为 **FastAPI** 投票。
+* 在 AlternativeTo 上为 **FastAPI** 投票。
+* 在 StackShare 上标注你在用 **FastAPI**。
-## 在 GitHub 上帮助其他人解决问题
+## 在 GitHub 上帮别人解答问题 { #help-others-with-questions-in-github }
-您可以查看现有 issues,并尝试帮助其他人解决问题,说不定您能解决这些问题呢。🤓
+你可以尝试在以下地方帮助他人解答问题:
-如果帮助很多人解决了问题,您就有可能成为 [FastAPI 的官方专家](fastapi-people.md#_3){.internal-link target=_blank}。🎉
+* GitHub Discussions
+* GitHub Issues
-## 监听 GitHub 资源库
+很多情况下,你也许已经知道这些问题的答案了。🤓
-您可以在 GitHub 上「监听」FastAPI(点击右上角的 "watch" 按钮): https://github.com/fastapi/fastapi. 👀
+如果你帮助了很多人解答问题,你会成为官方的 [FastAPI 专家](fastapi-people.md#fastapi-experts){.internal-link target=_blank}。🎉
-如果您选择 "Watching" 而不是 "Releases only",有人创建新 Issue 时,您会接收到通知。
+只要记住,最重要的一点是:尽量友善。人们带着挫败感而来,很多时候他们的提问方式并不理想,但请尽你所能地友好对待。🤗
-然后您就可以尝试并帮助他们解决问题。
+我们的目标是让 **FastAPI** 社区友好且包容。同时,也不要接受对他人的霸凌或不尊重。我们需要彼此照顾。
-## 创建 Issue
+---
-您可以在 GitHub 资源库中创建 Issue,例如:
+以下是如何帮助他人解答问题(在 Discussions 或 Issues 中):
-* 提出**问题**或**意见**
-* 提出新**特性**建议
+### 理解问题 { #understand-the-question }
-**注意**:如果您创建 Issue,我会要求您也要帮助别的用户。😉
+* 看看你是否能理解提问者的**目的**和使用场景。
-## 创建 PR
+* 然后检查问题(绝大多数是提问)是否**清晰**。
-您可以创建 PR 为源代码做[贡献](contributing.md){.internal-link target=_blank},例如:
+* 很多时候,问题是围绕提问者想象中的解决方案,但可能有**更好的**方案。如果你更好地理解了问题和使用场景,你就可能提出更**合适的替代方案**。
-* 修改文档错别字
-* 编辑这个文件,分享 FastAPI 的文章、视频、博客,不论是您自己的,还是您看到的都成
- * 注意,添加的链接要放在对应区块的开头
-* [翻译文档](contributing.md#_8){.internal-link target=_blank}
- * 审阅别人翻译的文档
-* 添加新的文档内容
-* 修复现有问题/Bug
-* 添加新功能
+* 如果你没能理解问题,请请求更多**细节**。
-## 加入聊天
+### 复现问题 { #reproduce-the-problem }
-快加入 👥 Discord 聊天服务器 👥 和 FastAPI 社区里的小伙伴一起哈皮吧。
+在大多数情况下与问题相关的都是提问者的**原始代码**。
-/// tip | 提示
+很多时候他们只会粘贴一小段代码,但这不足以**复现问题**。
-如有问题,请在 GitHub Issues 里提问,在这里更容易得到 [FastAPI 专家](fastapi-people.md#_3){.internal-link target=_blank}的帮助。
+* 你可以请他们提供一个可最小复现的示例,你可以**复制粘贴**并在本地运行,看到与他们相同的错误或行为,或者更好地理解他们的用例。
-聊天室仅供闲聊。
+* 如果你非常热心,你也可以尝试仅根据问题描述自己**构造一个示例**。不过要记住,这可能会花很多时间,通常先请他们澄清问题会更好。
+
+### 提出解决方案 { #suggest-solutions }
+
+* 在能够理解问题之后,你可以给出一个可能的**答案**。
+
+* 很多情况下,更好的是去理解他们**底层的问题或场景**,因为可能存在比他们尝试的方法更好的解决方式。
+
+### 请求关闭问题 { #ask-to-close }
+
+如果他们回复了,很有可能你已经解决了他们的问题,恭喜,**你是英雄**!🦸
+
+* 现在,如果问题已解决,你可以请他们:
+ * 在 GitHub Discussions 中:将你的评论标记为**答案**。
+ * 在 GitHub Issues 中:**关闭**该 issue。
+
+## 关注 GitHub 资源库 { #watch-the-github-repository }
+
+你可以在 GitHub 上「关注」FastAPI(点击右上角的「watch」按钮):https://github.com/fastapi/fastapi。👀
+
+如果你选择「Watching」而非「Releases only」,当有人创建新的 issue 或问题时你会收到通知。你也可以指定只通知新 issues、discussions、PR 等。
+
+然后你就可以尝试帮助他们解决这些问题。
+
+## 提问 { #ask-questions }
+
+你可以在 GitHub 资源库中创建一个新问题(Question),例如:
+
+* 提出一个**问题**或关于某个**问题**的求助。
+* 建议一个新的**功能**。
+
+**注意**:如果你这么做了,我也会请你去帮助其他人。😉
+
+## 审阅 Pull Request { #review-pull-requests }
+
+你可以帮我审阅他人的 Pull Request。
+
+再次提醒,请尽力保持友善。🤗
+
+---
+
+下面是需要注意的点,以及如何审阅一个 Pull Request:
+
+### 理解问题 { #understand-the-problem }
+
+* 首先,确保你**理解这个 PR 要解决的问题**。它可能在 GitHub Discussion 或 issue 中有更长的讨论。
+
+* 也有很大可能这个 PR 实际上并不需要,因为问题可以用**不同方式**解决。这种情况下你可以提出或询问该方案。
+
+### 不用过分担心风格 { #dont-worry-about-style }
+
+* 不用太在意提交信息风格等,我会在合并时 squash 并手动调整提交信息。
+
+* 也不用过分担心代码风格规则,已经有自动化工具在检查。
+
+如果还有其他风格或一致性需求,我会直接提出,或者我会在其上追加提交做必要修改。
+
+### 检查代码 { #check-the-code }
+
+* 检查并阅读代码,看看是否说得通,**在本地运行**并确认它确实解决了问题。
+
+* 然后**评论**说明你已经这样做了,这样我就知道你确实检查过。
+
+/// info | 信息
+
+不幸的是,我不能仅仅信任那些有很多人批准的 PR。
+
+多次发生过这样的情况:PR 有 3、5 个甚至更多的批准,可能是因为描述很吸引人,但当我检查时,它们实际上是坏的、有 bug,或者并没有解决它声称要解决的问题。😅
+
+所以,真正重要的是你确实读过并运行过代码,并在评论里告诉我你做过这些。🤓
///
-### 别在聊天室里提问
+* 如果 PR 可以在某些方面简化,你可以提出建议,但没必要过分挑剔,很多东西比较主观(我也会有我自己的看法 🙈),因此尽量关注关键点更好。
-注意,聊天室更倾向于“闲聊”,经常有人会提出一些笼统得让人难以回答的问题,所以在这里提问一般没人回答。
+### 测试 { #tests }
-GitHub Issues 里提供了模板,指引您提出正确的问题,有利于获得优质的回答,甚至可能解决您还没有想到的问题。而且就算答疑解惑要耗费不少时间,我还是会尽量在 GitHub 里回答问题。但在聊天室里,我就没功夫这么做了。😅
+* 帮我检查 PR 是否包含**测试**。
-聊天室里的聊天内容也不如 GitHub 里好搜索,聊天里的问答很容易就找不到了。只有在 GitHub Issues 里的问答才能帮助您成为 [FastAPI 专家](fastapi-people.md#_3){.internal-link target=_blank},在 GitHub Issues 中为您带来更多关注。
+* 确认在合并 PR 之前,测试**会失败**。🚨
-另一方面,聊天室里有成千上万的用户,在这里,您有很大可能遇到聊得来的人。😄
+* 然后确认合并 PR 之后,测试**能通过**。✅
-## 赞助作者
+* 很多 PR 没有测试,你可以**提醒**他们添加测试,或者你甚至可以自己**建议**一些测试。这是最耗时的部分之一,你能在这方面帮上大忙。
-您还可以通过 GitHub 赞助商资助本项目的作者(就是我)。
+* 然后也请评论你做了哪些验证,这样我就知道你检查过。🤓
-给我买杯咖啡 ☕️ 以示感谢 😄
+## 创建 Pull Request { #create-a-pull-request }
-当然您也可以成为 FastAPI 的金牌或银牌赞助商。🏅🎉
+你可以通过 Pull Request 为源代码[做贡献](contributing.md){.internal-link target=_blank},例如:
-## 赞助 FastAPI 使用的工具
+* 修正文档中的一个错别字。
+* 通过编辑这个文件分享你创建或发现的关于 FastAPI 的文章、视频或播客。
+ * 请确保把你的链接添加到相应区块的开头。
+* 帮助把[文档翻译](contributing.md#translations){.internal-link target=_blank}成你的语言。
+ * 你也可以审阅他人创建的翻译。
+* 提议新增文档章节。
+* 修复现有 issue/bug。
+ * 记得添加测试。
+* 添加新功能。
+ * 记得添加测试。
+ * 如果相关,记得补充文档。
-如您在本文档中所见,FastAPI 站在巨人的肩膀上,它们分别是 Starlette 和 Pydantic。
+## 帮忙维护 FastAPI { #help-maintain-fastapi }
-您还可以赞助:
+帮我一起维护 **FastAPI** 吧!🤓
-* Samuel Colvin (Pydantic)
-* Encode (Starlette, Uvicorn)
+有很多工作要做,其中大部分其实**你**都能做。
+
+你现在就能做的主要事情有:
+
+* [在 GitHub 上帮别人解答问题](#help-others-with-questions-in-github){.internal-link target=_blank}(见上面的章节)。
+* [审阅 Pull Request](#review-pull-requests){.internal-link target=_blank}(见上面的章节)。
+
+这两项工作是**最耗时**的。这也是维护 FastAPI 的主要工作。
+
+如果你能在这方面帮我,**你就是在帮我维护 FastAPI**,并确保它**更快更好地前进**。🚀
+
+## 加入聊天 { #join-the-chat }
+
+加入 👥 Discord 聊天服务器 👥,和 FastAPI 社区的小伙伴们一起交流。
+
+/// tip | 提示
+
+关于提问,请在 GitHub Discussions 中发布,这样更有机会得到 [FastAPI 专家](fastapi-people.md#fastapi-experts){.internal-link target=_blank} 的帮助。
+
+聊天仅用于其他日常交流。
+
+///
+
+### 别在聊天里提问 { #dont-use-the-chat-for-questions }
+
+请记住,聊天更偏向“自由交流”,很容易提出过于笼统、难以回答的问题,因此你可能收不到解答。
+
+在 GitHub 中,模板会引导你写出恰当的问题,从而更容易获得好的回答,甚至在提问之前就能自己解决。而且在 GitHub 里,我能尽量确保最终回复每个问题,即使这需要一些时间。对聊天系统来说,我个人做不到这一点。😅
+
+聊天系统中的对话也不像 GitHub 那样容易搜索,因此问答可能在聊天中淹没。而且只有在 GitHub 中的问答才会计入成为 [FastAPI 专家](fastapi-people.md#fastapi-experts){.internal-link target=_blank} 的贡献,所以你在 GitHub 上更可能获得关注。
+
+另一方面,聊天系统里有成千上万的用户,你几乎随时都能在那里找到聊得来的人。😄
+
+## 赞助作者 { #sponsor-the-author }
+
+如果你的**产品/公司**依赖或与 **FastAPI** 相关,并且你想触达它的用户,你可以通过 GitHub sponsors 赞助作者(我)。根据赞助层级,你还可能获得一些额外福利,比如在文档中展示徽章。🎁
---
diff --git a/docs/zh/docs/history-design-future.md b/docs/zh/docs/history-design-future.md
index 4db5c84724..00945eab59 100644
--- a/docs/zh/docs/history-design-future.md
+++ b/docs/zh/docs/history-design-future.md
@@ -1,12 +1,12 @@
-# 历史、设计、未来
+# 历史、设计、未来 { #history-design-and-future }
不久前,曾有 **FastAPI** 用户问过:
-> 这个项目有怎样的历史?好像它只用了几周就从默默无闻变得众所周知……
+> 这个项目有怎样的历史?好像它只用了几周就从默默无闻变得众所周知...
在此,我们简单回顾一下 **FastAPI** 的历史。
-## 备选方案
+## 备选方案 { #alternatives }
有那么几年,我曾领导数个开发团队为诸多复杂需求创建各种 API,这些需求包括机器学习、分布系统、异步任务、NoSQL 数据库等领域。
@@ -24,10 +24,9 @@
在那几年中,我一直回避创建新的框架。首先,我尝试使用各种框架、插件、工具解决 **FastAPI** 现在的功能。
但到了一定程度之后,我别无选择,只能从之前的工具中汲取最优思路,并以尽量好的方式把这些思路整合在一起,使用之前甚至是不支持的语言特性(Python 3.6+ 的类型提示),从而创建一个能满足我所有需求的框架。
-
-## 调研
+## 调研 { #investigation }
通过使用之前所有的备选方案,我有机会从它们之中学到了很多东西,获取了很多想法,并以我和我的开发团队能想到的最好方式把这些思路整合成一体。
@@ -37,7 +36,7 @@
因此,甚至在开发 **FastAPI** 前,我就花了几个月的时间研究 OpenAPI、JSON Schema、OAuth2 等规范。深入理解它们之间的关系、重叠及区别之处。
-## 设计
+## 设计 { #design }
然后,我又花了一些时间从用户角度(使用 FastAPI 的开发者)设计了开发者 **API**。
@@ -51,7 +50,7 @@
所有这些都是为了给开发者提供最佳的开发体验。
-## 需求项
+## 需求项 { #requirements }
经过测试多种备选方案,我最终决定使用 **Pydantic**,并充分利用它的优势。
@@ -59,11 +58,11 @@
在开发期间,我还为 **Starlette** 做了不少贡献,这是另一个关键需求项。
-## 开发
+## 开发 { #development }
当我启动 **FastAPI** 开发的时候,绝大多数部件都已经就位,设计已经定义,需求项和工具也已经准备就绪,相关标准与规范的知识储备也非常清晰而新鲜。
-## 未来
+## 未来 { #future }
至此,**FastAPI** 及其理念已经为很多人所用。
@@ -73,6 +72,6 @@
但,**FastAPI** 仍有很多改进的余地,也还需要添加更多的功能。
-总之,**FastAPI** 前景光明。
+**FastAPI** 前景光明。
在此,我们衷心感谢[您的帮助](help-fastapi.md){.internal-link target=_blank}。
diff --git a/docs/zh/docs/how-to/general.md b/docs/zh/docs/how-to/general.md
index e8b6dd3b23..e75ad6c79d 100644
--- a/docs/zh/docs/how-to/general.md
+++ b/docs/zh/docs/how-to/general.md
@@ -1,39 +1,39 @@
-# 通用 - 如何操作 - 诀窍
+# 通用 - 如何操作 - 诀窍 { #general-how-to-recipes }
这里是一些指向文档中其他部分的链接,用于解答一般性或常见问题。
-## 数据过滤 - 安全性
+## 数据过滤 - 安全性 { #filter-data-security }
为确保不返回超过需要的数据,请阅读 [教程 - 响应模型 - 返回类型](../tutorial/response-model.md){.internal-link target=_blank} 文档。
-## 文档的标签 - OpenAPI
+## 文档的标签 - OpenAPI { #documentation-tags-openapi }
在文档界面中添加**路径操作**的标签和进行分组,请阅读 [教程 - 路径操作配置 - Tags 参数](../tutorial/path-operation-configuration.md#tags){.internal-link target=_blank} 文档。
-## 文档的概要和描述 - OpenAPI
+## 文档的概要和描述 - OpenAPI { #documentation-summary-and-description-openapi }
-在文档界面中添加**路径操作**的概要和描述,请阅读 [教程 - 路径操作配置 - Summary 和 Description 参数](../tutorial/path-operation-configuration.md#summary-description){.internal-link target=_blank} 文档。
+在文档界面中添加**路径操作**的概要和描述,请阅读 [教程 - 路径操作配置 - Summary 和 Description 参数](../tutorial/path-operation-configuration.md#summary-and-description){.internal-link target=_blank} 文档。
-## 文档的响应描述 - OpenAPI
+## 文档的响应描述 - OpenAPI { #documentation-response-description-openapi }
在文档界面中定义并显示响应描述,请阅读 [教程 - 路径操作配置 - 响应描述](../tutorial/path-operation-configuration.md#response-description){.internal-link target=_blank} 文档。
-## 文档弃用**路径操作** - OpenAPI
+## 文档弃用**路径操作** - OpenAPI { #documentation-deprecate-a-path-operation-openapi }
在文档界面中显示弃用的**路径操作**,请阅读 [教程 - 路径操作配置 - 弃用](../tutorial/path-operation-configuration.md#deprecate-a-path-operation){.internal-link target=_blank} 文档。
-## 将任何数据转换为 JSON 兼容格式
+## 将任何数据转换为 JSON 兼容格式 { #convert-any-data-to-json-compatible }
要将任何数据转换为 JSON 兼容格式,请阅读 [教程 - JSON 兼容编码器](../tutorial/encoder.md){.internal-link target=_blank} 文档。
-## OpenAPI 元数据 - 文档
+## OpenAPI 元数据 - 文档 { #openapi-metadata-docs }
要添加 OpenAPI 的元数据,包括许可证、版本、联系方式等,请阅读 [教程 - 元数据和文档 URL](../tutorial/metadata.md){.internal-link target=_blank} 文档。
-## OpenAPI 自定义 URL
+## OpenAPI 自定义 URL { #openapi-custom-url }
要自定义 OpenAPI 的 URL(或删除它),请阅读 [教程 - 元数据和文档 URL](../tutorial/metadata.md#openapi-url){.internal-link target=_blank} 文档。
-## OpenAPI 文档 URL
+## OpenAPI 文档 URL { #openapi-docs-urls }
-要更改用于自动生成文档的 URL,请阅读 [教程 - 元数据和文档 URL](../tutorial/metadata.md#docs-urls){.internal-link target=_blank}.
+要更改用于自动生成文档的 URL,请阅读 [教程 - 元数据和文档 URL](../tutorial/metadata.md#docs-urls){.internal-link target=_blank}。
diff --git a/docs/zh/docs/how-to/index.md b/docs/zh/docs/how-to/index.md
index ac097618be..980dcd1a65 100644
--- a/docs/zh/docs/how-to/index.md
+++ b/docs/zh/docs/how-to/index.md
@@ -1,4 +1,4 @@
-# 如何操作 - 诀窍
+# 如何操作 - 诀窍 { #how-to-recipes }
在这里,你将看到关于**多个主题**的不同诀窍或“如何操作”指南。
@@ -6,7 +6,7 @@
如果某些内容看起来对你的项目有用,请继续查阅,否则请直接跳过它们。
-/// tip | 小技巧
+/// tip | 提示
如果你想以系统的方式**学习 FastAPI**(推荐),请阅读 [教程 - 用户指南](../tutorial/index.md){.internal-link target=_blank} 的每一章节。
diff --git a/docs/zh/docs/tutorial/body-fields.md b/docs/zh/docs/tutorial/body-fields.md
index 4cff58bfc5..36be7c4191 100644
--- a/docs/zh/docs/tutorial/body-fields.md
+++ b/docs/zh/docs/tutorial/body-fields.md
@@ -1,8 +1,8 @@
-# 请求体 - 字段
+# 请求体 - 字段 { #body-fields }
与在*路径操作函数*中使用 `Query`、`Path` 、`Body` 声明校验与元数据的方式一样,可以使用 Pydantic 的 `Field` 在 Pydantic 模型内部声明校验和元数据。
-## 导入 `Field`
+## 导入 `Field` { #import-field }
首先,从 Pydantic 中导入 `Field`:
@@ -14,7 +14,7 @@
///
-## 声明模型属性
+## 声明模型属性 { #declare-model-attributes }
然后,使用 `Field` 定义模型的属性:
@@ -24,7 +24,7 @@
/// note | 技术细节
-实际上,`Query`、`Path` 都是 `Params` 的子类,而 `Params` 类又是 Pydantic 中 `FieldInfo` 的子类。
+实际上,`Query`、`Path` 以及你接下来会看到的其它对象,会创建公共 `Param` 类的子类的对象,而 `Param` 本身是 Pydantic 中 `FieldInfo` 的子类。
Pydantic 的 `Field` 返回也是 `FieldInfo` 的类实例。
@@ -40,13 +40,20 @@ Pydantic 的 `Field` 返回也是 `FieldInfo` 的类实例。
///
-## 添加更多信息
+## 添加更多信息 { #add-extra-information }
`Field`、`Query`、`Body` 等对象里可以声明更多信息,并且 JSON Schema 中也会集成这些信息。
*声明示例*一章中将详细介绍添加更多信息的知识。
-## 小结
+/// warning | 警告
+
+传递给 `Field` 的额外键也会出现在你的应用生成的 OpenAPI 架构中。
+由于这些键不一定属于 OpenAPI 规范的一部分,某些 OpenAPI 工具(例如 [OpenAPI 验证器](https://validator.swagger.io/))可能无法处理你生成的架构。
+
+///
+
+## 小结 { #recap }
Pydantic 的 `Field` 可以为模型属性声明更多校验和元数据。
diff --git a/docs/zh/docs/tutorial/cookie-params.md b/docs/zh/docs/tutorial/cookie-params.md
index 4956008149..ab05cd7d24 100644
--- a/docs/zh/docs/tutorial/cookie-params.md
+++ b/docs/zh/docs/tutorial/cookie-params.md
@@ -1,20 +1,19 @@
-# Cookie 参数
+# Cookie 参数 { #cookie-parameters }
- 定义 `Cookie` 参数与定义 `Query` 和 `Path` 参数一样。
+定义 `Cookie` 参数与定义 `Query` 和 `Path` 参数一样。
-## 导入 `Cookie`
+## 导入 `Cookie` { #import-cookie }
首先,导入 `Cookie`:
{* ../../docs_src/cookie_params/tutorial001_an_py310.py hl[3] *}
-## 声明 `Cookie` 参数
+## 声明 `Cookie` 参数 { #declare-cookie-parameters }
声明 `Cookie` 参数的方式与声明 `Query` 和 `Path` 参数相同。
第一个值是默认值,还可以传递所有验证参数或注释参数:
-
{* ../../docs_src/cookie_params/tutorial001_an_py310.py hl[9] *}
/// note | 技术细节
@@ -25,12 +24,22 @@
///
-/// info | 说明
+/// info | 信息
必须使用 `Cookie` 声明 cookie 参数,否则该参数会被解释为查询参数。
///
-## 小结
+/// info | 信息
+
+请注意,由于**浏览器会以特殊方式并在幕后处理 cookies**,它们**不会**轻易允许**JavaScript**访问它们。
+
+如果你前往位于 `/docs` 的**API 文档界面**,你可以看到你的*路径操作*中有关 cookies 的**文档**。
+
+但即使你**填写了数据**并点击 "Execute",由于文档界面依赖于**JavaScript**工作,cookies 也不会被发送,你会看到一个**错误**消息,好像你没有填写任何值一样。
+
+///
+
+## 小结 { #recap }
使用 `Cookie` 声明 cookie 参数的方式与 `Query` 和 `Path` 相同。
diff --git a/docs/zh/docs/tutorial/encoder.md b/docs/zh/docs/tutorial/encoder.md
index e52aaa2ed2..f47a092010 100644
--- a/docs/zh/docs/tutorial/encoder.md
+++ b/docs/zh/docs/tutorial/encoder.md
@@ -1,4 +1,4 @@
-# JSON 兼容编码器
+# JSON 兼容编码器 { #json-compatible-encoder }
在某些情况下,您可能需要将数据类型(如Pydantic模型)转换为与JSON兼容的数据类型(如`dict`、`list`等)。
@@ -6,7 +6,7 @@
对于这种要求, **FastAPI**提供了`jsonable_encoder()`函数。
-## 使用`jsonable_encoder`
+## 使用`jsonable_encoder` { #using-the-jsonable-encoder }
让我们假设你有一个数据库名为`fake_db`,它只能接收与JSON兼容的数据。
@@ -28,7 +28,7 @@
这个操作不会返回一个包含JSON格式(作为字符串)数据的庞大的`str`。它将返回一个Python标准数据结构(例如`dict`),其值和子值都与JSON兼容。
-/// note
+/// note | 注意
`jsonable_encoder`实际上是FastAPI内部用来转换数据的。但是它在许多其他场景中也很有用。
diff --git a/docs/zh/docs/tutorial/extra-data-types.md b/docs/zh/docs/tutorial/extra-data-types.md
index b064ee551e..2cefd163d3 100644
--- a/docs/zh/docs/tutorial/extra-data-types.md
+++ b/docs/zh/docs/tutorial/extra-data-types.md
@@ -1,4 +1,4 @@
-# 额外数据类型
+# 额外数据类型 { #extra-data-types }
到目前为止,您一直在使用常见的数据类型,如:
@@ -15,9 +15,9 @@
* 传入请求的数据转换。
* 响应数据转换。
* 数据验证。
-* 自动补全和文档。
+* 自动注解和文档。
-## 其他数据类型
+## 其他数据类型 { #other-data-types }
下面是一些你可以使用的其他数据类型:
@@ -36,12 +36,12 @@
* `datetime.timedelta`:
* 一个 Python `datetime.timedelta`.
* 在请求和响应中将表示为 `float` 代表总秒数。
- * Pydantic 也允许将其表示为 "ISO 8601 时间差异编码", 查看文档了解更多信息。
+ * Pydantic 也允许将其表示为 "ISO 8601 时间差异编码", 查看文档了解更多信息。
* `frozenset`:
* 在请求和响应中,作为 `set` 对待:
* 在请求中,列表将被读取,消除重复,并将其转换为一个 `set`。
* 在响应中 `set` 将被转换为 `list` 。
- * 产生的模式将指定那些 `set` 的值是唯一的 (使用 JSON 模式的 `uniqueItems`)。
+ * 产生的模式将指定那些 `set` 的值是唯一的 (使用 JSON Schema 的 `uniqueItems`)。
* `bytes`:
* 标准的 Python `bytes`。
* 在请求和响应中被当作 `str` 处理。
@@ -49,9 +49,9 @@
* `Decimal`:
* 标准的 Python `Decimal`。
* 在请求和响应中被当做 `float` 一样处理。
-* 您可以在这里检查所有有效的pydantic数据类型: Pydantic data types.
+* 您可以在这里检查所有有效的 Pydantic 数据类型: Pydantic data types.
-## 例子
+## 例子 { #example }
下面是一个*路径操作*的示例,其中的参数使用了上面的一些类型。
diff --git a/docs/zh/docs/tutorial/extra-models.md b/docs/zh/docs/tutorial/extra-models.md
index ccfb3aa5ab..4d18c76ec1 100644
--- a/docs/zh/docs/tutorial/extra-models.md
+++ b/docs/zh/docs/tutorial/extra-models.md
@@ -1,4 +1,4 @@
-# 更多模型
+# 更多模型 { #extra-models }
书接上文,多个关联模型这种情况很常见。
@@ -6,29 +6,29 @@
* **输入模型**应该含密码
* **输出模型**不应含密码
-* **数据库模型**需要加密的密码
+* **数据库模型**可能需要包含哈希后的密码
-/// danger | 危险
+/// danger
-千万不要存储用户的明文密码。始终存储可以进行验证的**安全哈希值**。
+不要存储用户的明文密码。始终只存储之后可用于校验的“安全哈希”。
-如果不了解这方面的知识,请参阅[安全性中的章节](security/simple-oauth2.md#password-hashing){.internal-link target=_blank},了解什么是**密码哈希**。
+如果你还不了解,可以在[安全性章节](security/simple-oauth2.md#password-hashing){.internal-link target=_blank}中学习什么是“密码哈希”。
///
-## 多个模型
+## 多个模型 { #multiple-models }
下面的代码展示了不同模型处理密码字段的方式,及使用位置的大致思路:
{* ../../docs_src/extra_models/tutorial001_py310.py hl[7,9,14,20,22,27:28,31:33,38:39] *}
-### `**user_in.dict()` 简介
+### 关于 `**user_in.model_dump()` { #about-user-in-model-dump }
-#### Pydantic 的 `.dict()`
+#### Pydantic 的 `.model_dump()` { #pydantics-model-dump }
`user_in` 是类 `UserIn` 的 Pydantic 模型。
-Pydantic 模型支持 `.dict()` 方法,能返回包含模型数据的**字典**。
+Pydantic 模型有 `.model_dump()` 方法,会返回包含模型数据的 `dict`。
因此,如果使用如下方式创建 Pydantic 对象 `user_in`:
@@ -39,10 +39,10 @@ user_in = UserIn(username="john", password="secret", email="john.doe@example.com
就能以如下方式调用:
```Python
-user_dict = user_in.dict()
+user_dict = user_in.model_dump()
```
-现在,变量 `user_dict`中的就是包含数据的**字典**(变量 `user_dict` 是字典,不是 Pydantic 模型对象)。
+现在,变量 `user_dict` 中的是包含数据的 `dict`(它是 `dict`,不是 Pydantic 模型对象)。
以如下方式调用:
@@ -50,7 +50,7 @@ user_dict = user_in.dict()
print(user_dict)
```
-输出的就是 Python **字典**:
+输出的就是 Python `dict`:
```Python
{
@@ -61,9 +61,9 @@ print(user_dict)
}
```
-#### 解包 `dict`
+#### 解包 `dict` { #unpacking-a-dict }
-把**字典** `user_dict` 以 `**user_dict` 形式传递给函数(或类),Python 会执行**解包**操作。它会把 `user_dict` 的键和值作为关键字参数直接传递。
+把 `dict`(如 `user_dict`)以 `**user_dict` 形式传递给函数(或类),Python 会执行“解包”。它会把 `user_dict` 的键和值作为关键字参数直接传递。
因此,接着上面的 `user_dict` 继续编写如下代码:
@@ -82,7 +82,7 @@ UserInDB(
)
```
-或更精准,直接把可能会用到的内容与 `user_dict` 一起使用:
+或更精准,直接使用 `user_dict`(无论它将来包含什么字段):
```Python
UserInDB(
@@ -93,31 +93,31 @@ UserInDB(
)
```
-#### 用其它模型中的内容生成 Pydantic 模型
+#### 用另一个模型的内容生成 Pydantic 模型 { #a-pydantic-model-from-the-contents-of-another }
-上例中 ,从 `user_in.dict()` 中得到了 `user_dict`,下面的代码:
+上例中 ,从 `user_in.model_dump()` 中得到了 `user_dict`,下面的代码:
```Python
-user_dict = user_in.dict()
+user_dict = user_in.model_dump()
UserInDB(**user_dict)
```
等效于:
```Python
-UserInDB(**user_in.dict())
+UserInDB(**user_in.model_dump())
```
-……因为 `user_in.dict()` 是字典,在传递给 `UserInDB` 时,把 `**` 加在 `user_in.dict()` 前,可以让 Python 进行**解包**。
+……因为 `user_in.model_dump()` 是 `dict`,在传递给 `UserInDB` 时,把 `**` 加在 `user_in.model_dump()` 前,可以让 Python 进行解包。
这样,就可以用其它 Pydantic 模型中的数据生成 Pydantic 模型。
-#### 解包 `dict` 和更多关键字
+#### 解包 `dict` 并添加额外关键字参数 { #unpacking-a-dict-and-extra-keywords }
接下来,继续添加关键字参数 `hashed_password=hashed_password`,例如:
```Python
-UserInDB(**user_in.dict(), hashed_password=hashed_password)
+UserInDB(**user_in.model_dump(), hashed_password=hashed_password)
```
……输出结果如下:
@@ -132,68 +132,80 @@ UserInDB(
)
```
-/// warning | 警告
+/// warning
-辅助的附加函数只是为了演示可能的数据流,但它们显然不能提供任何真正的安全机制。
+配套的辅助函数 `fake_password_hasher` 和 `fake_save_user` 仅用于演示可能的数据流,当然并不提供真实的安全性。
///
-## 减少重复
+## 减少重复 { #reduce-duplication }
-**FastAPI** 的核心思想就是减少代码重复。
+减少代码重复是 **FastAPI** 的核心思想之一。
代码重复会导致 bug、安全问题、代码失步等问题(更新了某个位置的代码,但没有同步更新其它位置的代码)。
上面的这些模型共享了大量数据,拥有重复的属性名和类型。
-FastAPI 可以做得更好。
+我们可以做得更好。
-声明 `UserBase` 模型作为其它模型的基类。然后,用该类衍生出继承其属性(类型声明、验证等)的子类。
+声明 `UserBase` 模型作为其它模型的基类。然后,用该类衍生出继承其属性(类型声明、校验等)的子类。
所有数据转换、校验、文档等功能仍将正常运行。
-这样,就可以仅声明模型之间的差异部分(具有明文的 `password`、具有 `hashed_password` 以及不包括密码)。
-
-通过这种方式,可以只声明模型之间的区别(分别包含明文密码、哈希密码,以及无密码的模型)。
+这样,就可以仅声明模型之间的差异部分(具有明文的 `password`、具有 `hashed_password` 以及不包括密码):
{* ../../docs_src/extra_models/tutorial002_py310.py hl[7,13:14,17:18,21:22] *}
-## `Union` 或者 `anyOf`
+## `Union` 或 `anyOf` { #union-or-anyof }
-响应可以声明为两种类型的 `Union` 类型,即该响应可以是两种类型中的任意类型。
+响应可以声明为两个或多个类型的 `Union`,即该响应可以是这些类型中的任意一种。
-在 OpenAPI 中可以使用 `anyOf` 定义。
+在 OpenAPI 中会用 `anyOf` 表示。
为此,请使用 Python 标准类型提示 `typing.Union`:
-/// note | 笔记
+/// note
-定义 `Union` 类型时,要把详细的类型写在前面,然后是不太详细的类型。下例中,更详细的 `PlaneItem` 位于 `Union[PlaneItem,CarItem]` 中的 `CarItem` 之前。
+定义 `Union` 类型时,要把更具体的类型写在前面,然后是不太具体的类型。下例中,更具体的 `PlaneItem` 位于 `Union[PlaneItem, CarItem]` 中的 `CarItem` 之前。
///
{* ../../docs_src/extra_models/tutorial003_py310.py hl[1,14:15,18:20,33] *}
-## 模型列表
+### Python 3.10 中的 `Union` { #union-in-python-3-10 }
-使用同样的方式也可以声明由对象列表构成的响应。
+在这个示例中,我们把 `Union[PlaneItem, CarItem]` 作为参数 `response_model` 的值传入。
-为此,请使用标准的 Python `typing.List`:
+因为这是作为“参数的值”而不是放在“类型注解”中,所以即使在 Python 3.10 也必须使用 `Union`。
+
+如果是在类型注解中,我们就可以使用竖线:
+
+```Python
+some_variable: PlaneItem | CarItem
+```
+
+但如果把它写成赋值 `response_model=PlaneItem | CarItem`,就会报错,因为 Python 会尝试在 `PlaneItem` 和 `CarItem` 之间执行一个“无效的运算”,而不是把它当作类型注解来解析。
+
+## 模型列表 { #list-of-models }
+
+同样地,你可以声明由对象列表构成的响应。
+
+为此,请使用标准的 Python `typing.List`(在 Python 3.9+ 中也可以直接用 `list`):
{* ../../docs_src/extra_models/tutorial004_py39.py hl[18] *}
-## 任意 `dict` 构成的响应
+## 任意 `dict` 的响应 { #response-with-arbitrary-dict }
-任意的 `dict` 都能用于声明响应,只要声明键和值的类型,无需使用 Pydantic 模型。
+你也可以使用普通的任意 `dict` 来声明响应,只需声明键和值的类型,无需使用 Pydantic 模型。
-事先不知道可用的字段 / 属性名时(Pydantic 模型必须知道字段是什么),这种方式特别有用。
+如果你事先不知道有效的字段/属性名(Pydantic 模型需要预先知道字段)时,这很有用。
-此时,可以使用 `typing.Dict`:
+此时,可以使用 `typing.Dict`(在 Python 3.9+ 中也可以直接用 `dict`):
{* ../../docs_src/extra_models/tutorial005_py39.py hl[6] *}
-## 小结
+## 小结 { #recap }
-针对不同场景,可以随意使用不同的 Pydantic 模型继承定义的基类。
+针对不同场景,可以随意使用不同的 Pydantic 模型并通过继承复用。
-实体必须具有不同的**状态**时,不必为不同状态的实体单独定义数据模型。例如,用户**实体**就有包含 `password`、包含 `password_hash` 以及不含密码等多种状态。
+当一个实体需要具备不同的“状态”时,无需只为该实体定义一个数据模型。例如,用户“实体”就可能有包含 `password`、包含 `password_hash` 以及不含密码等多种状态。
diff --git a/docs/zh/docs/tutorial/header-params.md b/docs/zh/docs/tutorial/header-params.md
index 19bb455cf4..ccb88ae7fa 100644
--- a/docs/zh/docs/tutorial/header-params.md
+++ b/docs/zh/docs/tutorial/header-params.md
@@ -1,14 +1,14 @@
-# Header 参数
+# Header 参数 { #header-parameters }
定义 `Header` 参数的方式与定义 `Query`、`Path`、`Cookie` 参数相同。
-## 导入 `Header`
+## 导入 `Header` { #import-header }
首先,导入 `Header`:
{* ../../docs_src/header_params/tutorial001_an_py310.py hl[3] *}
-## 声明 `Header` 参数
+## 声明 `Header` 参数 { #declare-header-parameters }
然后,使用和 `Path`、`Query`、`Cookie` 一样的结构定义 header 参数。
@@ -24,13 +24,13 @@
///
-/// info | 说明
+/// info | 信息
必须使用 `Header` 声明 header 参数,否则该参数会被解释为查询参数。
///
-## 自动转换
+## 自动转换 { #automatic-conversion }
`Header` 比 `Path`、`Query` 和 `Cookie` 提供了更多功能。
@@ -54,7 +54,7 @@
///
-## 重复的请求头
+## 重复的请求头 { #duplicate-headers }
有时,可能需要接收重复的请求头。即同一个请求头有多个值。
@@ -84,7 +84,7 @@ X-Token: bar
}
```
-## 小结
+## 小结 { #recap }
使用 `Header` 声明请求头的方式与 `Query`、`Path` 、`Cookie` 相同。
diff --git a/docs/zh/docs/tutorial/index.md b/docs/zh/docs/tutorial/index.md
index 3ca927337f..7934583023 100644
--- a/docs/zh/docs/tutorial/index.md
+++ b/docs/zh/docs/tutorial/index.md
@@ -1,12 +1,12 @@
-# 教程 - 用户指南
+# 教程 - 用户指南 { #tutorial-user-guide }
本教程将一步步向您展示如何使用 **FastAPI** 的绝大部分特性。
-各个章节的内容循序渐进,但是又围绕着单独的主题,所以您可以直接跳转到某个章节以解决您的特定需求。
+各个章节的内容循序渐进,但是又围绕着单独的主题,所以您可以直接跳转到某个章节以解决您的特定 API 需求。
本教程同样可以作为将来的参考手册,所以您可以随时回到本教程并查阅您需要的内容。
-## 运行代码
+## 运行代码 { #run-the-code }
所有代码片段都可以复制后直接使用(它们实际上是经过测试的 Python 文件)。
@@ -58,7 +58,7 @@ $ fastapi dev
-/// note
+/// note | 注意
-当您使用 `pip install "fastapi[standard]"` 进行安装时,它会附带一些默认的可选标准依赖项。
+当您使用 `pip install "fastapi[standard]"` 安装时,它会附带一些默认的可选标准依赖项,其中包括 `fastapi-cloud-cli`,它可以让您部署到 FastAPI Cloud。
如果您不想安装这些可选依赖,可以选择安装 `pip install fastapi`。
+如果您想安装标准依赖但不包含 `fastapi-cloud-cli`,可以使用 `pip install "fastapi[standard-no-fastapi-cloud-cli]"` 安装。
+
///
-## 进阶用户指南
+## 进阶用户指南 { #advanced-user-guide }
在本**教程-用户指南**之后,您可以阅读**进阶用户指南**。
diff --git a/docs/zh/docs/tutorial/metadata.md b/docs/zh/docs/tutorial/metadata.md
index d29a1e6d05..6ec7e9add1 100644
--- a/docs/zh/docs/tutorial/metadata.md
+++ b/docs/zh/docs/tutorial/metadata.md
@@ -1,28 +1,28 @@
-# 元数据和文档 URL
+# 元数据和文档 URL { #metadata-and-docs-urls }
你可以在 FastAPI 应用程序中自定义多个元数据配置。
-## API 元数据
+## API 元数据 { #metadata-for-api }
你可以在设置 OpenAPI 规范和自动 API 文档 UI 中使用的以下字段:
| 参数 | 类型 | 描述 |
|------------|------|-------------|
| `title` | `str` | API 的标题。 |
-| `summary` | `str` | API 的简短摘要。 自 OpenAPI 3.1.0、FastAPI 0.99.0 起可用。. |
-| `description` | `str` | API 的简短描述。可以使用Markdown。 |
-| `version` | `string` | API 的版本。这是您自己的应用程序的版本,而不是 OpenAPI 的版本。例如 `2.5.0` 。 |
+| `summary` | `str` | API 的简短摘要。 自 OpenAPI 3.1.0、FastAPI 0.99.0 起可用。 |
+| `description` | `str` | API 的简短描述。可以使用 Markdown。 |
+| `version` | `string` | API 的版本。这是您自己的应用程序的版本,而不是 OpenAPI 的版本。例如 `2.5.0`。 |
| `terms_of_service` | `str` | API 服务条款的 URL。如果提供,则必须是 URL。 |
-| `contact` | `dict` | 公开的 API 的联系信息。它可以包含多个字段。
-### HTTPS 响应
+### HTTPS 响应 { #https-response }
然后,TLS 终止代理将使用之前协商的加密算法(以`someapp.example.com`的证书开头)对响应进行加密,并将其发送回浏览器。
@@ -158,7 +157,7 @@ TLS 终止代理将使用协商好的加密算法**解密请求**,并将**(
客户端(浏览器)将知道响应来自正确的服务器,因为它使用了他们之前使用 **HTTPS 证书** 协商出的加密算法。
-### 多个应用程序
+### 多个应用程序 { #multiple-applications }
在同一台(或多台)服务器中,可能存在**多个应用程序**,例如其他 API 程序或数据库。
@@ -168,7 +167,7 @@ TLS 终止代理将使用协商好的加密算法**解密请求**,并将**(
这样,TLS 终止代理就可以为多个应用程序处理**多个域名**的 HTTPS 和证书,然后在每种情况下将请求传输到正确的应用程序。
-### 证书更新
+### 证书更新 { #certificate-renewal }
在未来的某个时候,每个证书都会**过期**(大约在获得证书后 3 个月)。
@@ -183,16 +182,48 @@ TLS 终止代理将使用协商好的加密算法**解密请求**,并将**(
有多种方法可以做到这一点。 一些流行的方式是:
* **修改一些DNS记录**。
- * 为此,续订程序需要支持 DNS 提供商的 API,因此,要看你使用的 DNS 提供商是否提供这一功能。
+ * 为此,续订程序需要支持 DNS 提供商的 API,因此,要看你使用的 DNS 提供商是否提供这一功能。
* **在与域名关联的公共 IP 地址上作为服务器运行**(至少在证书获取过程中)。
- * 正如我们上面所说,只有一个进程可以监听特定的 IP 和端口。
- * 这就是当同一个 TLS 终止代理还负责证书续订过程时它非常有用的原因之一。
- * 否则,你可能需要暂时停止 TLS 终止代理,启动续订程序以获取证书,然后使用 TLS 终止代理配置它们,然后重新启动 TLS 终止代理。 这并不理想,因为你的应用程序在 TLS 终止代理关闭期间将不可用。
+ * 正如我们上面所说,只有一个进程可以监听特定的 IP 和端口。
+ * 这就是当同一个 TLS 终止代理还负责证书续订过程时它非常有用的原因之一。
+ * 否则,你可能需要暂时停止 TLS 终止代理,启动续订程序以获取证书,然后使用 TLS 终止代理配置它们,然后重新启动 TLS 终止代理。 这并不理想,因为你的应用程序在 TLS 终止代理关闭期间将不可用。
通过拥有一个**单独的系统来使用 TLS 终止代理来处理 HTTPS**, 而不是直接将 TLS 证书与应用程序服务器一起使用 (例如 Uvicorn),你可以在
更新证书的过程中同时保持提供服务。
-## 回顾
+## 代理转发请求头 { #proxy-forwarded-headers }
+
+当使用代理来处理 HTTPS 时,你的**应用服务器**(例如通过 FastAPI CLI 运行的 Uvicorn)对 HTTPS 过程并不了解,它只通过纯 HTTP 与 **TLS 终止代理**通信。
+
+这个**代理**通常会在将请求转发给**应用服务器**之前,临时设置一些 HTTP 请求头,以便让应用服务器知道该请求是由代理**转发**过来的。
+
+/// note | 技术细节
+
+这些代理请求头包括:
+
+* X-Forwarded-For
+* X-Forwarded-Proto
+* X-Forwarded-Host
+
+///
+
+不过,由于**应用服务器**并不知道自己位于受信任的**代理**之后,默认情况下,它不会信任这些请求头。
+
+但你可以配置**应用服务器**去信任由**代理**发送的这些“转发”请求头。如果你在使用 FastAPI CLI,可以使用命令行选项 `--forwarded-allow-ips` 指定它应该信任哪些 IP 发来的这些“转发”请求头。
+
+例如,如果**应用服务器**只接收来自受信任**代理**的通信,你可以设置 `--forwarded-allow-ips="*"`,让它信任所有传入的 IP,因为它只会接收来自**代理**所使用 IP 的请求。
+
+这样,应用就能知道自己的公共 URL、是否使用 HTTPS、域名等信息。
+
+这在需要正确处理重定向等场景时很有用。
+
+/// tip
+
+你可以在文档中了解更多:[在代理之后 - 启用代理转发请求头](../advanced/behind-a-proxy.md#enable-proxy-forwarded-headers){.internal-link target=_blank}
+
+///
+
+## 回顾 { #recap }
拥有**HTTPS** 非常重要,并且在大多数情况下相当**关键**。 作为开发人员,你围绕 HTTPS 所做的大部分努力就是**理解这些概念**以及它们的工作原理。
diff --git a/docs/zh/docs/deployment/index.md b/docs/zh/docs/deployment/index.md
index 1ec0c5c5b5..47dcede653 100644
--- a/docs/zh/docs/deployment/index.md
+++ b/docs/zh/docs/deployment/index.md
@@ -1,21 +1,23 @@
-# 部署
+# 部署 { #deployment }
部署 **FastAPI** 应用程序相对容易。
-## 部署是什么意思
+## 部署是什么意思 { #what-does-deployment-mean }
**部署**应用程序意味着执行必要的步骤以使其**可供用户使用**。
-对于**Web API**来说,通常涉及将上传到**云服务器**中,搭配一个性能和稳定性都不错的**服务器程序**,以便你的**用户**可以高效地**访问**你的应用程序,而不会出现中断或其他问题。
+对于**Web API**来说,通常涉及将其放到一台**远程机器**中,搭配一个性能和稳定性都不错的**服务器程序**,以便你的**用户**可以高效地**访问**你的应用程序,而不会出现中断或其他问题。
-这与**开发**阶段形成鲜明对比,在**开发**阶段,你不断更改代码、破坏代码、修复代码, 来回停止和重启服务器等。
+这与**开发**阶段形成鲜明对比,在**开发**阶段,你不断更改代码、破坏代码、修复代码,来回停止和重启开发服务器等。
-## 部署策略
+## 部署策略 { #deployment-strategies }
根据你的使用场景和使用的工具,有多种方法可以实现此目的。
你可以使用一些工具自行**部署服务器**,你也可以使用能为你完成部分工作的**云服务**,或其他可能的选项。
+例如,我们(FastAPI 团队)构建了 **FastAPI Cloud**,让将 FastAPI 应用部署到云端尽可能流畅,并且保持与使用 FastAPI 开发时相同的开发者体验。
+
我将向你展示在部署 **FastAPI** 应用程序时你可能应该记住的一些主要概念(尽管其中大部分适用于任何其他类型的 Web 应用程序)。
在接下来的部分中,你将看到更多需要记住的细节以及一些技巧。 ✨
diff --git a/docs/zh/docs/deployment/manually.md b/docs/zh/docs/deployment/manually.md
index 2c2784a640..6f2ad27b2f 100644
--- a/docs/zh/docs/deployment/manually.md
+++ b/docs/zh/docs/deployment/manually.md
@@ -1,6 +1,6 @@
-# 手动运行服务器
+# 手动运行服务器 { #run-a-server-manually }
-## 使用 `fastapi run` 命令
+## 使用 `fastapi run` 命令 { #use-the-fastapi-run-command }
简而言之,使用 `fastapi run` 来运行您的 FastAPI 应用程序:
@@ -42,11 +42,11 @@ $ fastapi run ASGI。FastAPI 本质上是一个 ASGI Web 框架。
+FastAPI 使用了一种用于构建 Python Web 框架和服务器的标准,称为 ASGI。FastAPI 本质上是一个 ASGI Web 框架。
要在远程服务器上运行 **FastAPI** 应用(或任何其他 ASGI 应用),您需要一个 ASGI 服务器程序,例如 **Uvicorn**。它是 `fastapi` 命令默认使用的 ASGI 服务器。
@@ -58,7 +58,7 @@ FastAPI 使用了一种用于构建 Python Web 框架和服务器的标准,称
* Granian:基于 Rust 的 HTTP 服务器,专为 Python 应用设计。
* NGINX Unit:NGINX Unit 是一个轻量级且灵活的 Web 应用运行时环境。
-## 服务器主机和服务器程序
+## 服务器主机和服务器程序 { #server-machine-and-server-program }
关于名称,有一个小细节需要记住。 💡
@@ -68,8 +68,7 @@ FastAPI 使用了一种用于构建 Python Web 框架和服务器的标准,称
当提到远程主机时,通常将其称为**服务器**,但也称为**机器**(machine)、**VM**(虚拟机)、**节点**。 这些都是指某种类型的远程计算机,通常运行 Linux,您可以在其中运行程序。
-
-## 安装服务器程序
+## 安装服务器程序 { #install-the-server-program }
当您安装 FastAPI 时,它自带一个生产环境服务器——Uvicorn,并且您可以使用 `fastapi run` 命令来启动它。
@@ -101,7 +100,7 @@ $ pip install "uvicorn[standard]"
///
-## 运行服务器程序
+## 运行服务器程序 { #run-the-server-program }
如果您手动安装了 ASGI 服务器,通常需要以特定格式传递一个导入字符串,以便服务器能够正确导入您的 FastAPI 应用:
@@ -142,7 +141,7 @@ Uvicorn 和其他服务器支持 `--reload` 选项,该选项在开发过程中
///
-## 部署概念
+## 部署概念 { #deployment-concepts }
这些示例运行服务器程序(例如 Uvicorn),启动**单个进程**,在所有 IP(`0.0.0.0`)上监听预定义端口(例如`80`)。
diff --git a/docs/zh/docs/deployment/server-workers.md b/docs/zh/docs/deployment/server-workers.md
index e46ba7a09d..2bbd5d9b6a 100644
--- a/docs/zh/docs/deployment/server-workers.md
+++ b/docs/zh/docs/deployment/server-workers.md
@@ -1,4 +1,4 @@
-# 服务器工作进程(Workers) - 使用 Uvicorn 的多工作进程模式
+# 服务器工作进程(Workers) - 使用 Uvicorn 的多工作进程模式 { #server-workers-uvicorn-with-workers }
让我们回顾一下之前的部署概念:
@@ -17,7 +17,7 @@
在本章节中,我将向您展示如何使用 `fastapi` 命令或直接使用 `uvicorn` 命令以**多工作进程模式**运行 **Uvicorn**。
-/// info
+/// info | 信息
如果您正在使用容器,例如 Docker 或 Kubernetes,我将在下一章中告诉您更多相关信息:[容器中的 FastAPI - Docker](docker.md){.internal-link target=_blank}。
@@ -25,7 +25,7 @@
///
-## 多个工作进程
+## 多个工作进程 { #multiple-workers }
您可以使用 `--workers` 命令行选项来启动多个工作进程:
@@ -111,7 +111,7 @@ $ uvicorn main:app --host 0.0.0.0 --port 8080 --workers 4
您还可以看到它显示了每个进程的 **PID**,父进程(这是**进程管理器**)的 PID 为`27365`,每个工作进程的 PID 为:`27368`、`27369`, `27370`和`27367`。
-## 部署概念
+## 部署概念 { #deployment-concepts }
在这里,您学习了如何使用多个**工作进程(workers)**来让应用程序的执行**并行化**,充分利用 CPU 的**多核性能**,并能够处理**更多的请求**。
@@ -124,13 +124,13 @@ $ uvicorn main:app --host 0.0.0.0 --port 8080 --workers 4
* **内存**
* **启动之前的先前步骤**
-## 容器和 Docker
+## 容器和 Docker { #containers-and-docker }
在关于 [容器中的 FastAPI - Docker](docker.md){.internal-link target=_blank} 的下一章中,我将介绍一些可用于处理其他**部署概念**的策略。
我将向您展示如何**从零开始构建自己的镜像**,以运行一个单独的 Uvicorn 进程。这个过程相对简单,并且在使用 **Kubernetes** 等分布式容器管理系统时,这通常是您需要采取的方法。
-## 回顾
+## 回顾 { #recap }
您可以在使用 `fastapi` 或 `uvicorn` 命令时,通过 `--workers` CLI 选项启用多个工作进程(workers),以充分利用**多核 CPU**,以**并行运行多个进程**。
diff --git a/docs/zh/docs/deployment/versions.md b/docs/zh/docs/deployment/versions.md
index 228bb07653..23c37f3b5b 100644
--- a/docs/zh/docs/deployment/versions.md
+++ b/docs/zh/docs/deployment/versions.md
@@ -1,4 +1,4 @@
-# 关于 FastAPI 版本
+# 关于 FastAPI 版本 { #about-fastapi-versions }
**FastAPI** 已在许多应用程序和系统的生产环境中使用。 并且测试覆盖率保持在100%。 但其开发进度仍在快速推进。
@@ -8,41 +8,41 @@
你现在就可以使用 **FastAPI** 创建生产环境应用程序(你可能已经这样做了一段时间),你只需确保使用的版本可以与其余代码正确配合即可。
-## 固定你的 `fastapi` 版本
+## 固定你的 `fastapi` 版本 { #pin-your-fastapi-version }
你应该做的第一件事是将你正在使用的 **FastAPI** 版本“固定”到你知道适用于你的应用程序的特定最新版本。
-例如,假设你在应用程序中使用版本`0.45.0`。
+例如,假设你在应用程序中使用版本`0.112.0`。
如果你使用`requirements.txt`文件,你可以使用以下命令指定版本:
-````txt
-fastapi==0.45.0
-````
+```txt
+fastapi[standard]==0.112.0
+```
-这意味着你将使用版本`0.45.0`。
+这意味着你将使用版本`0.112.0`。
或者你也可以将其固定为:
-````txt
-fastapi>=0.45.0,<0.46.0
-````
+```txt
+fastapi[standard]>=0.112.0,<0.113.0
+```
-这意味着你将使用`0.45.0`或更高版本,但低于`0.46.0`,例如,版本`0.45.2`仍会被接受。
+这意味着你将使用`0.112.0`或更高版本,但低于`0.113.0`,例如,版本`0.112.2`仍会被接受。
-如果你使用任何其他工具来管理你的安装,例如 Poetry、Pipenv 或其他工具,它们都有一种定义包的特定版本的方法。
+如果你使用任何其他工具来管理你的安装,例如 `uv`、Poetry、Pipenv 或其他工具,它们都有一种定义包的特定版本的方法。
-## 可用版本
+## 可用版本 { #available-versions }
你可以在[发行说明](../release-notes.md){.internal-link target=_blank}中查看可用版本(例如查看当前最新版本)。
-## 关于版本
+## 关于版本 { #about-versions }
遵循语义版本控制约定,任何低于`1.0.0`的版本都可能会添加 breaking changes。
-FastAPI 还遵循这样的约定:任何`PATCH`版本更改都是为了bug修复和non-breaking changes。
+FastAPI 还遵循这样的约定:任何"PATCH"版本更改都是为了bug修复和non-breaking changes。
-/// tip
+/// tip | 提示
"PATCH"是最后一个数字,例如,在`0.2.3`中,PATCH版本是`3`。
@@ -56,13 +56,13 @@ fastapi>=0.45.0,<0.46.0
"MINOR"版本中会添加breaking changes和新功能。
-/// tip
+/// tip | 提示
"MINOR"是中间的数字,例如,在`0.2.3`中,MINOR版本是`2`。
///
-## 升级FastAPI版本
+## 升级FastAPI版本 { #upgrading-the-fastapi-versions }
你应该为你的应用程序添加测试。
@@ -72,7 +72,7 @@ fastapi>=0.45.0,<0.46.0
如果一切正常,或者在进行必要的更改之后,并且所有测试都通过了,那么你可以将`fastapi`固定到新的版本。
-## 关于Starlette
+## 关于Starlette { #about-starlette }
你不应该固定`starlette`的版本。
@@ -80,14 +80,14 @@ fastapi>=0.45.0,<0.46.0
因此,**FastAPI** 自己可以使用正确的 Starlette 版本。
-## 关于 Pydantic
+## 关于 Pydantic { #about-pydantic }
Pydantic 包含针对 **FastAPI** 的测试及其自己的测试,因此 Pydantic 的新版本(`1.0.0`以上)始终与 FastAPI 兼容。
-你可以将 Pydantic 固定到适合你的`1.0.0`以上和`2.0.0`以下的任何版本。
+你可以将 Pydantic 固定到任何高于 `1.0.0` 且适合你的版本。
例如:
-````txt
-pydantic>=1.2.0,<2.0.0
-````
+```txt
+pydantic>=2.7.0,<3.0.0
+```
diff --git a/docs/zh/docs/fastapi-cli.md b/docs/zh/docs/fastapi-cli.md
index 3b67eb6645..4d3b51a57a 100644
--- a/docs/zh/docs/fastapi-cli.md
+++ b/docs/zh/docs/fastapi-cli.md
@@ -1,8 +1,8 @@
-# FastAPI CLI
+# FastAPI CLI { #fastapi-cli }
**FastAPI CLI** 是一个命令行程序,你可以用它来部署和运行你的 FastAPI 应用程序,管理你的 FastAPI 项目,等等。
-当你安装 FastAPI 时(例如使用 `pip install FastAPI` 命令),会包含一个名为 `fastapi-cli` 的软件包,该软件包在终端中提供 `fastapi` 命令。
+当你安装 FastAPI 时(例如使用 `pip install "fastapi[standard]"`),会包含一个名为 `fastapi-cli` 的软件包,该软件包在终端中提供 `fastapi` 命令。
要在开发环境中运行你的 FastAPI 应用,你可以使用 `fastapi dev` 命令:
@@ -48,32 +48,28 @@ $ fastapi dev Uvicorn,这是一个高性能、适用于生产环境的 ASGI 服务器。😎
-## `fastapi dev`
+## `fastapi dev` { #fastapi-dev }
当你运行 `fastapi dev` 时,它将以开发模式运行。
-默认情况下,它会启用**自动重载**,因此当你更改代码时,它会自动重新加载服务器。该功能是资源密集型的,且相较不启用时更不稳定,因此你应该仅在开发环境下使用它。
+默认情况下,它会启用**自动重载**,因此当你更改代码时,它会自动重新加载服务器。该功能是资源密集型的,且相较不启用时更不稳定,因此你应该仅在开发环境下使用它。它还会监听 IP 地址 `127.0.0.1`,这是你的机器仅与自身通信的 IP(`localhost`)。
-默认情况下,它将监听 IP 地址 `127.0.0.1`,这是你的机器与自身通信的 IP 地址(`localhost`)。
-
-## `fastapi run`
+## `fastapi run` { #fastapi-run }
当你运行 `fastapi run` 时,它默认以生产环境模式运行。
-默认情况下,**自动重载是禁用的**。
-
-它将监听 IP 地址 `0.0.0.0`,即所有可用的 IP 地址,这样任何能够与该机器通信的人都可以公开访问它。这通常是你在生产环境中运行它的方式,例如在容器中运行。
+默认情况下,**自动重载是禁用的**。它将监听 IP 地址 `0.0.0.0`,即所有可用的 IP 地址,这样任何能够与该机器通信的人都可以公开访问它。这通常是你在生产环境中运行它的方式,例如在容器中运行。
在大多数情况下,你会(且应该)有一个“终止代理”在上层为你处理 HTTPS,这取决于你如何部署应用程序,你的服务提供商可能会为你处理此事,或者你可能需要自己设置。
/// tip | 提示
-你可以在 [deployment documentation](deployment/index.md){.internal-link target=_blank} 获得更多信息。
+你可以在[部署文档](deployment/index.md){.internal-link target=_blank}中了解更多。
///
diff --git a/docs/zh/docs/features.md b/docs/zh/docs/features.md
index eaf8daff7e..7d7aa19c06 100644
--- a/docs/zh/docs/features.md
+++ b/docs/zh/docs/features.md
@@ -1,22 +1,21 @@
-# 特性
+# 特性 { #features }
-## FastAPI 特性
+## FastAPI 特性 { #fastapi-features }
**FastAPI** 提供了以下内容:
-### 基于开放标准
+### 基于开放标准 { #based-on-open-standards }
-
-* 用于创建 API 的 OpenAPI 包含了路径操作,请求参数,请求体,安全性等的声明。
-* 使用 JSON Schema (因为 OpenAPI 本身就是基于 JSON Schema 的)自动生成数据模型文档。
+* 用于创建 API 的 OpenAPI,包含对路径 操作、参数、请求体、安全等的声明。
+* 使用 JSON Schema 自动生成数据模型文档(因为 OpenAPI 本身就是基于 JSON Schema 的)。
* 经过了缜密的研究后围绕这些标准而设计。并非狗尾续貂。
* 这也允许了在很多语言中自动**生成客户端代码**。
-### 自动生成文档
+### 自动生成文档 { #automatic-docs }
交互式 API 文档以及具探索性 web 界面。因为该框架是基于 OpenAPI,所以有很多可选项,FastAPI 默认自带两个交互式 API 文档。
-* Swagger UI,可交互式操作,能在浏览器中直接调用和测试你的 API 。
+* Swagger UI,可交互式操作,能在浏览器中直接调用和测试你的 API。

@@ -24,11 +23,11 @@

-### 更主流的 Python
+### 更主流的 Python { #just-modern-python }
-全部都基于标准的 **Python 3.6 类型**声明(感谢 Pydantic )。没有新的语法需要学习。只需要标准的 Python 。
+全部都基于标准的 **Python 类型** 声明(感谢 Pydantic)。没有新的语法需要学习。只需要标准的现代 Python。
-如果你需要2分钟来学习如何使用 Python 类型(即使你不使用 FastAPI ),看看这个简短的教程:[Python Types](python-types.md){.internal-link target=_blank}。
+如果你需要2分钟来学习如何使用 Python 类型(即使你不使用 FastAPI),看看这个简短的教程:[Python Types](python-types.md){.internal-link target=_blank}。
编写带有类型标注的标准 Python:
@@ -37,13 +36,13 @@ from datetime import date
from pydantic import BaseModel
-# Declare a variable as a str
-# and get editor support inside the function
+# 将变量声明为 str
+# 并在函数内获得编辑器支持
def main(user_id: str):
return user_id
-# A Pydantic model
+# 一个 Pydantic 模型
class User(BaseModel):
id: int
name: str
@@ -65,19 +64,19 @@ my_second_user: User = User(**second_user_data)
```
-/// info
+/// info | 信息
-`**second_user_data` 意思是:
+`**second_user_data` 意思是:
-直接将`second_user_data`字典的键和值直接作为key-value参数传递,等同于:`User(id=4, name="Mary", joined="2018-11-30")`
+直接将 `second_user_data` 字典的键和值作为 key-value 参数传入,等同于:`User(id=4, name="Mary", joined="2018-11-30")`
///
-### 编辑器支持
+### 编辑器支持 { #editor-support }
整个框架都被设计得易于使用且直观,所有的决定都在开发之前就在多个编辑器上进行了测试,来确保最佳的开发体验。
-在最近的 Python 开发者调查中,我们能看到 被使用最多的功能是"自动补全"。
+在最近的 Python 开发者调查中,我们能看到 被使用最多的功能是“自动补全”。
整个 **FastAPI** 框架就是基于这一点的。任何地方都可以进行自动补全。
@@ -85,62 +84,58 @@ my_second_user: User = User(**second_user_data)
在这里,你的编辑器可能会这样帮助你:
-* Visual Studio Code 中:
+* 在 Visual Studio Code 中:

-* PyCharm 中:
+* 在 PyCharm 中:

你将能进行代码补全,这是在之前你可能曾认为不可能的事。例如,在来自请求 JSON 体(可能是嵌套的)中的键 `price`。
-不会再输错键名,来回翻看文档,或者来回滚动寻找你最后使用的 `username` 或者 `user_name` 。
+不会再输错键名,来回翻看文档,或者来回滚动寻找你最后使用的 `username` 或者 `user_name`。
-
-
-### 简洁
+### 简洁 { #short }
任何类型都有合理的**默认值**,任何和地方都有可选配置。所有的参数被微调,来满足你的需求,定义成你需要的 API。
但是默认情况下,一切都能**“顺利工作”**。
-### 验证
+### 验证 { #validation }
* 校验大部分(甚至所有?)的 Python **数据类型**,包括:
- * JSON 对象 (`dict`).
+ * JSON 对象 (`dict`)。
* JSON 数组 (`list`) 定义成员类型。
- * 字符串 (`str`) 字段, 定义最小或最大长度。
- * 数字 (`int`, `float`) 有最大值和最小值, 等等。
+ * 字符串 (`str`) 字段,定义最小或最大长度。
+ * 数字 (`int`, `float`) 有最大值和最小值,等等。
-* 校验外来类型, 比如:
- * URL.
- * Email.
- * UUID.
- * ...及其他.
+* 校验外来类型,比如:
+ * URL。
+ * Email。
+ * UUID。
+ * ...及其他。
所有的校验都由完善且强大的 **Pydantic** 处理。
-### 安全性及身份验证
+### 安全性及身份验证 { #security-and-authentication }
集成了安全性和身份认证。杜绝数据库或者数据模型的渗透风险。
OpenAPI 中定义的安全模式,包括:
* HTTP 基本认证。
-* **OAuth2** (也使用 **JWT tokens**)。在 [OAuth2 with JWT](tutorial/security/oauth2-jwt.md){.internal-link target=_blank}查看教程。
+* **OAuth2**(也使用 **JWT tokens**)。在 [OAuth2 with JWT](tutorial/security/oauth2-jwt.md){.internal-link target=_blank}查看教程。
* API 密钥,在:
* 请求头。
* 查询参数。
- * Cookies, 等等。
+ * Cookies,等等。
加上来自 Starlette(包括 **session cookie**)的所有安全特性。
所有的这些都是可复用的工具和组件,可以轻松与你的系统,数据仓库,关系型以及 NoSQL 数据库等等集成。
-
-
-### 依赖注入
+### 依赖注入 { #dependency-injection }
FastAPI 有一个使用非常简单,但是非常强大的依赖注入系统。
@@ -149,48 +144,47 @@ FastAPI 有一个使用非常简单,但是非常强大的IDE/linter/brain** 适配:
* 因为 pydantic 数据结构仅仅是你定义的类的实例;自动补全,linting,mypy 以及你的直觉应该可以和你验证的数据一起正常工作。
* 验证**复杂结构**:
- * 使用分层的 Pydantic 模型, Python `typing`的 `List` 和 `Dict` 等等。
- * 验证器使我们能够简单清楚的将复杂的数据模式定义、检查并记录为 JSON Schema。
+ * 使用分层的 Pydantic 模型,Python `typing` 的 `List` 和 `Dict` 等等。
+ * 验证器使我们能够简单清楚地将复杂的数据模式定义、检查并记录为 JSON Schema。
* 你可以拥有深度**嵌套的 JSON** 对象并对它们进行验证和注释。
* **可扩展**:
* Pydantic 允许定义自定义数据类型或者你可以用验证器装饰器对被装饰的模型上的方法扩展验证。
diff --git a/docs/zh/docs/help-fastapi.md b/docs/zh/docs/help-fastapi.md
index f01eb9eb5d..5a5157b5d3 100644
--- a/docs/zh/docs/help-fastapi.md
+++ b/docs/zh/docs/help-fastapi.md
@@ -1,147 +1,254 @@
-# 帮助 FastAPI 与求助
+# 帮助 FastAPI - 获取帮助 { #help-fastapi-get-help }
-您喜欢 **FastAPI** 吗?
+你喜欢 **FastAPI** 吗?
-想帮助 FastAPI?其它用户?还有项目作者?
+想帮助 FastAPI、其他用户和作者吗?
-或要求助怎么使用 **FastAPI**?
+或者你想获取 **FastAPI** 的帮助?
-以下几种帮助的方式都非常简单(有些只需要点击一两下鼠标)。
+有很多非常简单的方式可以帮忙(有些只需点一两下)。
-求助的渠道也很多。
+同样,也有多种途径可以获得帮助。
-## 订阅新闻邮件
+## 订阅新闻邮件 { #subscribe-to-the-newsletter }
-您可以订阅 [**FastAPI 和它的小伙伴** 新闻邮件](newsletter.md){.internal-link target=_blank}(不会经常收到)
+你可以订阅(不频繁的)[**FastAPI and friends** 新闻邮件](newsletter.md){.internal-link target=_blank},获取如下更新:
* FastAPI 及其小伙伴的新闻 🚀
* 指南 📝
* 功能 ✨
* 破坏性更改 🚨
-* 开发技巧 ✅
+* 使用技巧 ✅
-## 在推特上关注 FastAPI
+## 在 X (Twitter) 上关注 FastAPI { #follow-fastapi-on-x-twitter }
-在 **X (Twitter)** 上关注 @fastapi 获取 **FastAPI** 的最新消息。🐦
+在 **X (Twitter)** 上关注 @fastapi 获取 **FastAPI** 的最新动态。🐦
-## 在 GitHub 上为 **FastAPI** 加星
+## 在 GitHub 上为 **FastAPI** 加星 { #star-fastapi-in-github }
-您可以在 GitHub 上 **Star** FastAPI(只要点击右上角的星星就可以了): https://github.com/fastapi/fastapi。⭐️
+你可以在 GitHub 上为 FastAPI 点亮「星标」(点击右上角的星形按钮):https://github.com/fastapi/fastapi。⭐️
-**Star** 以后,其它用户就能更容易找到 FastAPI,并了解到已经有其他用户在使用它了。
+点亮星标后,其他用户更容易发现它,并看到它已经对许多人有帮助。
-## 关注 GitHub 资源库的版本发布
+## 关注 GitHub 资源库的版本发布 { #watch-the-github-repository-for-releases }
-您还可以在 GitHub 上 **Watch** FastAPI,(点击右上角的 **Watch** 按钮)https://github.com/fastapi/fastapi。👀
+你可以在 GitHub 上「关注」FastAPI(点击右上角的「watch」按钮):https://github.com/fastapi/fastapi。👀
-您可以选择只关注发布(**Releases only**)。
+在那里你可以选择「Releases only」。
-这样,您就可以(在电子邮件里)接收到 **FastAPI** 新版发布的通知,及时了解 bug 修复与新功能。
+这样做之后,每当 **FastAPI** 发布新版本(包含修复和新功能),你都会收到通知(邮件)。
-## 联系作者
+## 联系作者 { #connect-with-the-author }
-您可以联系项目作者,就是我(Sebastián Ramírez / `tiangolo`)。
+你可以联系我(Sebastián Ramírez / `tiangolo`),作者本人。
-您可以:
+你可以:
-* 在 **GitHub** 上关注我
- * 了解其它我创建的开源项目,或许对您会有帮助
- * 关注我什么时候创建新的开源项目
-* 在 **X (Twitter)** 上关注我
- * 告诉我您使用 FastAPI(我非常乐意听到这种消息)
- * 接收我发布公告或新工具的消息
- * 您还可以关注@fastapi on X (Twitter),这是个独立的账号
-* 在**领英**上联系我
- * 接收我发布公告或新工具的消息(虽然我用 X (Twitter) 比较多)
-* 阅读我在 **Dev.to** 或 **Medium** 上的文章,或关注我
- * 阅读我的其它想法、文章,了解我创建的工具
- * 关注我,这样就可以随时看到我发布的新文章
+* 在 **GitHub** 上关注我。
+ * 了解我创建的其他开源项目,也许对你有帮助。
+ * 关注我何时创建新的开源项目。
+* 关注我在 **X (Twitter)** 或 Mastodon。
+ * 告诉我你如何使用 FastAPI(我很喜欢听这些)。
+ * 获取我发布公告或新工具的消息。
+ * 你也可以关注 @fastapi on X (Twitter)(独立账号)。
+* 在 **LinkedIn** 上关注我。
+ * 获取我发布公告或新工具的消息(不过我更常用 X (Twitter) 🤷♂)。
+* 阅读我在 **Dev.to** 或 **Medium** 上的文章(或关注我)。
+ * 阅读我的其他想法、文章,以及我创建的工具。
+ * 关注我,这样当我发布新文章时你会第一时间看到。
-## Tweet about **FastAPI**
+## 发推谈谈 **FastAPI** { #tweet-about-fastapi }
-Tweet about **FastAPI** 让我和大家知道您为什么喜欢 FastAPI。🎉
+Tweet about **FastAPI**,告诉我和大家你为什么喜欢它。🎉
-知道有人使用 **FastAPI**,我会很开心,我也想知道您为什么喜欢 FastAPI,以及您在什么项目/哪些公司使用 FastAPI,等等。
+我很高兴听到 **FastAPI** 的使用情况、你喜欢它的哪些点、你在哪个项目/公司使用它,等等。
-## 为 FastAPI 投票
+## 为 FastAPI 投票 { #vote-for-fastapi }
-* 在 Slant 上为 **FastAPI** 投票
-* 在 AlternativeTo 上为 **FastAPI** 投票
+* 在 Slant 上为 **FastAPI** 投票。
+* 在 AlternativeTo 上为 **FastAPI** 投票。
+* 在 StackShare 上标注你在用 **FastAPI**。
-## 在 GitHub 上帮助其他人解决问题
+## 在 GitHub 上帮别人解答问题 { #help-others-with-questions-in-github }
-您可以查看现有 issues,并尝试帮助其他人解决问题,说不定您能解决这些问题呢。🤓
+你可以尝试在以下地方帮助他人解答问题:
-如果帮助很多人解决了问题,您就有可能成为 [FastAPI 的官方专家](fastapi-people.md#_3){.internal-link target=_blank}。🎉
+* GitHub Discussions
+* GitHub Issues
-## 监听 GitHub 资源库
+很多情况下,你也许已经知道这些问题的答案了。🤓
-您可以在 GitHub 上「监听」FastAPI(点击右上角的 "watch" 按钮): https://github.com/fastapi/fastapi. 👀
+如果你帮助了很多人解答问题,你会成为官方的 [FastAPI 专家](fastapi-people.md#fastapi-experts){.internal-link target=_blank}。🎉
-如果您选择 "Watching" 而不是 "Releases only",有人创建新 Issue 时,您会接收到通知。
+只要记住,最重要的一点是:尽量友善。人们带着挫败感而来,很多时候他们的提问方式并不理想,但请尽你所能地友好对待。🤗
-然后您就可以尝试并帮助他们解决问题。
+我们的目标是让 **FastAPI** 社区友好且包容。同时,也不要接受对他人的霸凌或不尊重。我们需要彼此照顾。
-## 创建 Issue
+---
-您可以在 GitHub 资源库中创建 Issue,例如:
+以下是如何帮助他人解答问题(在 Discussions 或 Issues 中):
-* 提出**问题**或**意见**
-* 提出新**特性**建议
+### 理解问题 { #understand-the-question }
-**注意**:如果您创建 Issue,我会要求您也要帮助别的用户。😉
+* 看看你是否能理解提问者的**目的**和使用场景。
-## 创建 PR
+* 然后检查问题(绝大多数是提问)是否**清晰**。
-您可以创建 PR 为源代码做[贡献](contributing.md){.internal-link target=_blank},例如:
+* 很多时候,问题是围绕提问者想象中的解决方案,但可能有**更好的**方案。如果你更好地理解了问题和使用场景,你就可能提出更**合适的替代方案**。
-* 修改文档错别字
-* 编辑这个文件,分享 FastAPI 的文章、视频、博客,不论是您自己的,还是您看到的都成
- * 注意,添加的链接要放在对应区块的开头
-* [翻译文档](contributing.md#_8){.internal-link target=_blank}
- * 审阅别人翻译的文档
-* 添加新的文档内容
-* 修复现有问题/Bug
-* 添加新功能
+* 如果你没能理解问题,请请求更多**细节**。
-## 加入聊天
+### 复现问题 { #reproduce-the-problem }
-快加入 👥 Discord 聊天服务器 👥 和 FastAPI 社区里的小伙伴一起哈皮吧。
+在大多数情况下与问题相关的都是提问者的**原始代码**。
-/// tip | 提示
+很多时候他们只会粘贴一小段代码,但这不足以**复现问题**。
-如有问题,请在 GitHub Issues 里提问,在这里更容易得到 [FastAPI 专家](fastapi-people.md#_3){.internal-link target=_blank}的帮助。
+* 你可以请他们提供一个可最小复现的示例,你可以**复制粘贴**并在本地运行,看到与他们相同的错误或行为,或者更好地理解他们的用例。
-聊天室仅供闲聊。
+* 如果你非常热心,你也可以尝试仅根据问题描述自己**构造一个示例**。不过要记住,这可能会花很多时间,通常先请他们澄清问题会更好。
+
+### 提出解决方案 { #suggest-solutions }
+
+* 在能够理解问题之后,你可以给出一个可能的**答案**。
+
+* 很多情况下,更好的是去理解他们**底层的问题或场景**,因为可能存在比他们尝试的方法更好的解决方式。
+
+### 请求关闭问题 { #ask-to-close }
+
+如果他们回复了,很有可能你已经解决了他们的问题,恭喜,**你是英雄**!🦸
+
+* 现在,如果问题已解决,你可以请他们:
+ * 在 GitHub Discussions 中:将你的评论标记为**答案**。
+ * 在 GitHub Issues 中:**关闭**该 issue。
+
+## 关注 GitHub 资源库 { #watch-the-github-repository }
+
+你可以在 GitHub 上「关注」FastAPI(点击右上角的「watch」按钮):https://github.com/fastapi/fastapi。👀
+
+如果你选择「Watching」而非「Releases only」,当有人创建新的 issue 或问题时你会收到通知。你也可以指定只通知新 issues、discussions、PR 等。
+
+然后你就可以尝试帮助他们解决这些问题。
+
+## 提问 { #ask-questions }
+
+你可以在 GitHub 资源库中创建一个新问题(Question),例如:
+
+* 提出一个**问题**或关于某个**问题**的求助。
+* 建议一个新的**功能**。
+
+**注意**:如果你这么做了,我也会请你去帮助其他人。😉
+
+## 审阅 Pull Request { #review-pull-requests }
+
+你可以帮我审阅他人的 Pull Request。
+
+再次提醒,请尽力保持友善。🤗
+
+---
+
+下面是需要注意的点,以及如何审阅一个 Pull Request:
+
+### 理解问题 { #understand-the-problem }
+
+* 首先,确保你**理解这个 PR 要解决的问题**。它可能在 GitHub Discussion 或 issue 中有更长的讨论。
+
+* 也有很大可能这个 PR 实际上并不需要,因为问题可以用**不同方式**解决。这种情况下你可以提出或询问该方案。
+
+### 不用过分担心风格 { #dont-worry-about-style }
+
+* 不用太在意提交信息风格等,我会在合并时 squash 并手动调整提交信息。
+
+* 也不用过分担心代码风格规则,已经有自动化工具在检查。
+
+如果还有其他风格或一致性需求,我会直接提出,或者我会在其上追加提交做必要修改。
+
+### 检查代码 { #check-the-code }
+
+* 检查并阅读代码,看看是否说得通,**在本地运行**并确认它确实解决了问题。
+
+* 然后**评论**说明你已经这样做了,这样我就知道你确实检查过。
+
+/// info | 信息
+
+不幸的是,我不能仅仅信任那些有很多人批准的 PR。
+
+多次发生过这样的情况:PR 有 3、5 个甚至更多的批准,可能是因为描述很吸引人,但当我检查时,它们实际上是坏的、有 bug,或者并没有解决它声称要解决的问题。😅
+
+所以,真正重要的是你确实读过并运行过代码,并在评论里告诉我你做过这些。🤓
///
-### 别在聊天室里提问
+* 如果 PR 可以在某些方面简化,你可以提出建议,但没必要过分挑剔,很多东西比较主观(我也会有我自己的看法 🙈),因此尽量关注关键点更好。
-注意,聊天室更倾向于“闲聊”,经常有人会提出一些笼统得让人难以回答的问题,所以在这里提问一般没人回答。
+### 测试 { #tests }
-GitHub Issues 里提供了模板,指引您提出正确的问题,有利于获得优质的回答,甚至可能解决您还没有想到的问题。而且就算答疑解惑要耗费不少时间,我还是会尽量在 GitHub 里回答问题。但在聊天室里,我就没功夫这么做了。😅
+* 帮我检查 PR 是否包含**测试**。
-聊天室里的聊天内容也不如 GitHub 里好搜索,聊天里的问答很容易就找不到了。只有在 GitHub Issues 里的问答才能帮助您成为 [FastAPI 专家](fastapi-people.md#_3){.internal-link target=_blank},在 GitHub Issues 中为您带来更多关注。
+* 确认在合并 PR 之前,测试**会失败**。🚨
-另一方面,聊天室里有成千上万的用户,在这里,您有很大可能遇到聊得来的人。😄
+* 然后确认合并 PR 之后,测试**能通过**。✅
-## 赞助作者
+* 很多 PR 没有测试,你可以**提醒**他们添加测试,或者你甚至可以自己**建议**一些测试。这是最耗时的部分之一,你能在这方面帮上大忙。
-您还可以通过 GitHub 赞助商资助本项目的作者(就是我)。
+* 然后也请评论你做了哪些验证,这样我就知道你检查过。🤓
-给我买杯咖啡 ☕️ 以示感谢 😄
+## 创建 Pull Request { #create-a-pull-request }
-当然您也可以成为 FastAPI 的金牌或银牌赞助商。🏅🎉
+你可以通过 Pull Request 为源代码[做贡献](contributing.md){.internal-link target=_blank},例如:
-## 赞助 FastAPI 使用的工具
+* 修正文档中的一个错别字。
+* 通过编辑这个文件分享你创建或发现的关于 FastAPI 的文章、视频或播客。
+ * 请确保把你的链接添加到相应区块的开头。
+* 帮助把[文档翻译](contributing.md#translations){.internal-link target=_blank}成你的语言。
+ * 你也可以审阅他人创建的翻译。
+* 提议新增文档章节。
+* 修复现有 issue/bug。
+ * 记得添加测试。
+* 添加新功能。
+ * 记得添加测试。
+ * 如果相关,记得补充文档。
-如您在本文档中所见,FastAPI 站在巨人的肩膀上,它们分别是 Starlette 和 Pydantic。
+## 帮忙维护 FastAPI { #help-maintain-fastapi }
-您还可以赞助:
+帮我一起维护 **FastAPI** 吧!🤓
-* Samuel Colvin (Pydantic)
-* Encode (Starlette, Uvicorn)
+有很多工作要做,其中大部分其实**你**都能做。
+
+你现在就能做的主要事情有:
+
+* [在 GitHub 上帮别人解答问题](#help-others-with-questions-in-github){.internal-link target=_blank}(见上面的章节)。
+* [审阅 Pull Request](#review-pull-requests){.internal-link target=_blank}(见上面的章节)。
+
+这两项工作是**最耗时**的。这也是维护 FastAPI 的主要工作。
+
+如果你能在这方面帮我,**你就是在帮我维护 FastAPI**,并确保它**更快更好地前进**。🚀
+
+## 加入聊天 { #join-the-chat }
+
+加入 👥 Discord 聊天服务器 👥,和 FastAPI 社区的小伙伴们一起交流。
+
+/// tip | 提示
+
+关于提问,请在 GitHub Discussions 中发布,这样更有机会得到 [FastAPI 专家](fastapi-people.md#fastapi-experts){.internal-link target=_blank} 的帮助。
+
+聊天仅用于其他日常交流。
+
+///
+
+### 别在聊天里提问 { #dont-use-the-chat-for-questions }
+
+请记住,聊天更偏向“自由交流”,很容易提出过于笼统、难以回答的问题,因此你可能收不到解答。
+
+在 GitHub 中,模板会引导你写出恰当的问题,从而更容易获得好的回答,甚至在提问之前就能自己解决。而且在 GitHub 里,我能尽量确保最终回复每个问题,即使这需要一些时间。对聊天系统来说,我个人做不到这一点。😅
+
+聊天系统中的对话也不像 GitHub 那样容易搜索,因此问答可能在聊天中淹没。而且只有在 GitHub 中的问答才会计入成为 [FastAPI 专家](fastapi-people.md#fastapi-experts){.internal-link target=_blank} 的贡献,所以你在 GitHub 上更可能获得关注。
+
+另一方面,聊天系统里有成千上万的用户,你几乎随时都能在那里找到聊得来的人。😄
+
+## 赞助作者 { #sponsor-the-author }
+
+如果你的**产品/公司**依赖或与 **FastAPI** 相关,并且你想触达它的用户,你可以通过 GitHub sponsors 赞助作者(我)。根据赞助层级,你还可能获得一些额外福利,比如在文档中展示徽章。🎁
---
diff --git a/docs/zh/docs/history-design-future.md b/docs/zh/docs/history-design-future.md
index 4db5c84724..00945eab59 100644
--- a/docs/zh/docs/history-design-future.md
+++ b/docs/zh/docs/history-design-future.md
@@ -1,12 +1,12 @@
-# 历史、设计、未来
+# 历史、设计、未来 { #history-design-and-future }
不久前,曾有 **FastAPI** 用户问过:
-> 这个项目有怎样的历史?好像它只用了几周就从默默无闻变得众所周知……
+> 这个项目有怎样的历史?好像它只用了几周就从默默无闻变得众所周知...
在此,我们简单回顾一下 **FastAPI** 的历史。
-## 备选方案
+## 备选方案 { #alternatives }
有那么几年,我曾领导数个开发团队为诸多复杂需求创建各种 API,这些需求包括机器学习、分布系统、异步任务、NoSQL 数据库等领域。
@@ -24,10 +24,9 @@
在那几年中,我一直回避创建新的框架。首先,我尝试使用各种框架、插件、工具解决 **FastAPI** 现在的功能。
但到了一定程度之后,我别无选择,只能从之前的工具中汲取最优思路,并以尽量好的方式把这些思路整合在一起,使用之前甚至是不支持的语言特性(Python 3.6+ 的类型提示),从而创建一个能满足我所有需求的框架。
-
-## 调研
+## 调研 { #investigation }
通过使用之前所有的备选方案,我有机会从它们之中学到了很多东西,获取了很多想法,并以我和我的开发团队能想到的最好方式把这些思路整合成一体。
@@ -37,7 +36,7 @@
因此,甚至在开发 **FastAPI** 前,我就花了几个月的时间研究 OpenAPI、JSON Schema、OAuth2 等规范。深入理解它们之间的关系、重叠及区别之处。
-## 设计
+## 设计 { #design }
然后,我又花了一些时间从用户角度(使用 FastAPI 的开发者)设计了开发者 **API**。
@@ -51,7 +50,7 @@
所有这些都是为了给开发者提供最佳的开发体验。
-## 需求项
+## 需求项 { #requirements }
经过测试多种备选方案,我最终决定使用 **Pydantic**,并充分利用它的优势。
@@ -59,11 +58,11 @@
在开发期间,我还为 **Starlette** 做了不少贡献,这是另一个关键需求项。
-## 开发
+## 开发 { #development }
当我启动 **FastAPI** 开发的时候,绝大多数部件都已经就位,设计已经定义,需求项和工具也已经准备就绪,相关标准与规范的知识储备也非常清晰而新鲜。
-## 未来
+## 未来 { #future }
至此,**FastAPI** 及其理念已经为很多人所用。
@@ -73,6 +72,6 @@
但,**FastAPI** 仍有很多改进的余地,也还需要添加更多的功能。
-总之,**FastAPI** 前景光明。
+**FastAPI** 前景光明。
在此,我们衷心感谢[您的帮助](help-fastapi.md){.internal-link target=_blank}。
diff --git a/docs/zh/docs/how-to/general.md b/docs/zh/docs/how-to/general.md
index e8b6dd3b23..e75ad6c79d 100644
--- a/docs/zh/docs/how-to/general.md
+++ b/docs/zh/docs/how-to/general.md
@@ -1,39 +1,39 @@
-# 通用 - 如何操作 - 诀窍
+# 通用 - 如何操作 - 诀窍 { #general-how-to-recipes }
这里是一些指向文档中其他部分的链接,用于解答一般性或常见问题。
-## 数据过滤 - 安全性
+## 数据过滤 - 安全性 { #filter-data-security }
为确保不返回超过需要的数据,请阅读 [教程 - 响应模型 - 返回类型](../tutorial/response-model.md){.internal-link target=_blank} 文档。
-## 文档的标签 - OpenAPI
+## 文档的标签 - OpenAPI { #documentation-tags-openapi }
在文档界面中添加**路径操作**的标签和进行分组,请阅读 [教程 - 路径操作配置 - Tags 参数](../tutorial/path-operation-configuration.md#tags){.internal-link target=_blank} 文档。
-## 文档的概要和描述 - OpenAPI
+## 文档的概要和描述 - OpenAPI { #documentation-summary-and-description-openapi }
-在文档界面中添加**路径操作**的概要和描述,请阅读 [教程 - 路径操作配置 - Summary 和 Description 参数](../tutorial/path-operation-configuration.md#summary-description){.internal-link target=_blank} 文档。
+在文档界面中添加**路径操作**的概要和描述,请阅读 [教程 - 路径操作配置 - Summary 和 Description 参数](../tutorial/path-operation-configuration.md#summary-and-description){.internal-link target=_blank} 文档。
-## 文档的响应描述 - OpenAPI
+## 文档的响应描述 - OpenAPI { #documentation-response-description-openapi }
在文档界面中定义并显示响应描述,请阅读 [教程 - 路径操作配置 - 响应描述](../tutorial/path-operation-configuration.md#response-description){.internal-link target=_blank} 文档。
-## 文档弃用**路径操作** - OpenAPI
+## 文档弃用**路径操作** - OpenAPI { #documentation-deprecate-a-path-operation-openapi }
在文档界面中显示弃用的**路径操作**,请阅读 [教程 - 路径操作配置 - 弃用](../tutorial/path-operation-configuration.md#deprecate-a-path-operation){.internal-link target=_blank} 文档。
-## 将任何数据转换为 JSON 兼容格式
+## 将任何数据转换为 JSON 兼容格式 { #convert-any-data-to-json-compatible }
要将任何数据转换为 JSON 兼容格式,请阅读 [教程 - JSON 兼容编码器](../tutorial/encoder.md){.internal-link target=_blank} 文档。
-## OpenAPI 元数据 - 文档
+## OpenAPI 元数据 - 文档 { #openapi-metadata-docs }
要添加 OpenAPI 的元数据,包括许可证、版本、联系方式等,请阅读 [教程 - 元数据和文档 URL](../tutorial/metadata.md){.internal-link target=_blank} 文档。
-## OpenAPI 自定义 URL
+## OpenAPI 自定义 URL { #openapi-custom-url }
要自定义 OpenAPI 的 URL(或删除它),请阅读 [教程 - 元数据和文档 URL](../tutorial/metadata.md#openapi-url){.internal-link target=_blank} 文档。
-## OpenAPI 文档 URL
+## OpenAPI 文档 URL { #openapi-docs-urls }
-要更改用于自动生成文档的 URL,请阅读 [教程 - 元数据和文档 URL](../tutorial/metadata.md#docs-urls){.internal-link target=_blank}.
+要更改用于自动生成文档的 URL,请阅读 [教程 - 元数据和文档 URL](../tutorial/metadata.md#docs-urls){.internal-link target=_blank}。
diff --git a/docs/zh/docs/how-to/index.md b/docs/zh/docs/how-to/index.md
index ac097618be..980dcd1a65 100644
--- a/docs/zh/docs/how-to/index.md
+++ b/docs/zh/docs/how-to/index.md
@@ -1,4 +1,4 @@
-# 如何操作 - 诀窍
+# 如何操作 - 诀窍 { #how-to-recipes }
在这里,你将看到关于**多个主题**的不同诀窍或“如何操作”指南。
@@ -6,7 +6,7 @@
如果某些内容看起来对你的项目有用,请继续查阅,否则请直接跳过它们。
-/// tip | 小技巧
+/// tip | 提示
如果你想以系统的方式**学习 FastAPI**(推荐),请阅读 [教程 - 用户指南](../tutorial/index.md){.internal-link target=_blank} 的每一章节。
diff --git a/docs/zh/docs/tutorial/body-fields.md b/docs/zh/docs/tutorial/body-fields.md
index 4cff58bfc5..36be7c4191 100644
--- a/docs/zh/docs/tutorial/body-fields.md
+++ b/docs/zh/docs/tutorial/body-fields.md
@@ -1,8 +1,8 @@
-# 请求体 - 字段
+# 请求体 - 字段 { #body-fields }
与在*路径操作函数*中使用 `Query`、`Path` 、`Body` 声明校验与元数据的方式一样,可以使用 Pydantic 的 `Field` 在 Pydantic 模型内部声明校验和元数据。
-## 导入 `Field`
+## 导入 `Field` { #import-field }
首先,从 Pydantic 中导入 `Field`:
@@ -14,7 +14,7 @@
///
-## 声明模型属性
+## 声明模型属性 { #declare-model-attributes }
然后,使用 `Field` 定义模型的属性:
@@ -24,7 +24,7 @@
/// note | 技术细节
-实际上,`Query`、`Path` 都是 `Params` 的子类,而 `Params` 类又是 Pydantic 中 `FieldInfo` 的子类。
+实际上,`Query`、`Path` 以及你接下来会看到的其它对象,会创建公共 `Param` 类的子类的对象,而 `Param` 本身是 Pydantic 中 `FieldInfo` 的子类。
Pydantic 的 `Field` 返回也是 `FieldInfo` 的类实例。
@@ -40,13 +40,20 @@ Pydantic 的 `Field` 返回也是 `FieldInfo` 的类实例。
///
-## 添加更多信息
+## 添加更多信息 { #add-extra-information }
`Field`、`Query`、`Body` 等对象里可以声明更多信息,并且 JSON Schema 中也会集成这些信息。
*声明示例*一章中将详细介绍添加更多信息的知识。
-## 小结
+/// warning | 警告
+
+传递给 `Field` 的额外键也会出现在你的应用生成的 OpenAPI 架构中。
+由于这些键不一定属于 OpenAPI 规范的一部分,某些 OpenAPI 工具(例如 [OpenAPI 验证器](https://validator.swagger.io/))可能无法处理你生成的架构。
+
+///
+
+## 小结 { #recap }
Pydantic 的 `Field` 可以为模型属性声明更多校验和元数据。
diff --git a/docs/zh/docs/tutorial/cookie-params.md b/docs/zh/docs/tutorial/cookie-params.md
index 4956008149..ab05cd7d24 100644
--- a/docs/zh/docs/tutorial/cookie-params.md
+++ b/docs/zh/docs/tutorial/cookie-params.md
@@ -1,20 +1,19 @@
-# Cookie 参数
+# Cookie 参数 { #cookie-parameters }
- 定义 `Cookie` 参数与定义 `Query` 和 `Path` 参数一样。
+定义 `Cookie` 参数与定义 `Query` 和 `Path` 参数一样。
-## 导入 `Cookie`
+## 导入 `Cookie` { #import-cookie }
首先,导入 `Cookie`:
{* ../../docs_src/cookie_params/tutorial001_an_py310.py hl[3] *}
-## 声明 `Cookie` 参数
+## 声明 `Cookie` 参数 { #declare-cookie-parameters }
声明 `Cookie` 参数的方式与声明 `Query` 和 `Path` 参数相同。
第一个值是默认值,还可以传递所有验证参数或注释参数:
-
{* ../../docs_src/cookie_params/tutorial001_an_py310.py hl[9] *}
/// note | 技术细节
@@ -25,12 +24,22 @@
///
-/// info | 说明
+/// info | 信息
必须使用 `Cookie` 声明 cookie 参数,否则该参数会被解释为查询参数。
///
-## 小结
+/// info | 信息
+
+请注意,由于**浏览器会以特殊方式并在幕后处理 cookies**,它们**不会**轻易允许**JavaScript**访问它们。
+
+如果你前往位于 `/docs` 的**API 文档界面**,你可以看到你的*路径操作*中有关 cookies 的**文档**。
+
+但即使你**填写了数据**并点击 "Execute",由于文档界面依赖于**JavaScript**工作,cookies 也不会被发送,你会看到一个**错误**消息,好像你没有填写任何值一样。
+
+///
+
+## 小结 { #recap }
使用 `Cookie` 声明 cookie 参数的方式与 `Query` 和 `Path` 相同。
diff --git a/docs/zh/docs/tutorial/encoder.md b/docs/zh/docs/tutorial/encoder.md
index e52aaa2ed2..f47a092010 100644
--- a/docs/zh/docs/tutorial/encoder.md
+++ b/docs/zh/docs/tutorial/encoder.md
@@ -1,4 +1,4 @@
-# JSON 兼容编码器
+# JSON 兼容编码器 { #json-compatible-encoder }
在某些情况下,您可能需要将数据类型(如Pydantic模型)转换为与JSON兼容的数据类型(如`dict`、`list`等)。
@@ -6,7 +6,7 @@
对于这种要求, **FastAPI**提供了`jsonable_encoder()`函数。
-## 使用`jsonable_encoder`
+## 使用`jsonable_encoder` { #using-the-jsonable-encoder }
让我们假设你有一个数据库名为`fake_db`,它只能接收与JSON兼容的数据。
@@ -28,7 +28,7 @@
这个操作不会返回一个包含JSON格式(作为字符串)数据的庞大的`str`。它将返回一个Python标准数据结构(例如`dict`),其值和子值都与JSON兼容。
-/// note
+/// note | 注意
`jsonable_encoder`实际上是FastAPI内部用来转换数据的。但是它在许多其他场景中也很有用。
diff --git a/docs/zh/docs/tutorial/extra-data-types.md b/docs/zh/docs/tutorial/extra-data-types.md
index b064ee551e..2cefd163d3 100644
--- a/docs/zh/docs/tutorial/extra-data-types.md
+++ b/docs/zh/docs/tutorial/extra-data-types.md
@@ -1,4 +1,4 @@
-# 额外数据类型
+# 额外数据类型 { #extra-data-types }
到目前为止,您一直在使用常见的数据类型,如:
@@ -15,9 +15,9 @@
* 传入请求的数据转换。
* 响应数据转换。
* 数据验证。
-* 自动补全和文档。
+* 自动注解和文档。
-## 其他数据类型
+## 其他数据类型 { #other-data-types }
下面是一些你可以使用的其他数据类型:
@@ -36,12 +36,12 @@
* `datetime.timedelta`:
* 一个 Python `datetime.timedelta`.
* 在请求和响应中将表示为 `float` 代表总秒数。
- * Pydantic 也允许将其表示为 "ISO 8601 时间差异编码", 查看文档了解更多信息。
+ * Pydantic 也允许将其表示为 "ISO 8601 时间差异编码", 查看文档了解更多信息。
* `frozenset`:
* 在请求和响应中,作为 `set` 对待:
* 在请求中,列表将被读取,消除重复,并将其转换为一个 `set`。
* 在响应中 `set` 将被转换为 `list` 。
- * 产生的模式将指定那些 `set` 的值是唯一的 (使用 JSON 模式的 `uniqueItems`)。
+ * 产生的模式将指定那些 `set` 的值是唯一的 (使用 JSON Schema 的 `uniqueItems`)。
* `bytes`:
* 标准的 Python `bytes`。
* 在请求和响应中被当作 `str` 处理。
@@ -49,9 +49,9 @@
* `Decimal`:
* 标准的 Python `Decimal`。
* 在请求和响应中被当做 `float` 一样处理。
-* 您可以在这里检查所有有效的pydantic数据类型: Pydantic data types.
+* 您可以在这里检查所有有效的 Pydantic 数据类型: Pydantic data types.
-## 例子
+## 例子 { #example }
下面是一个*路径操作*的示例,其中的参数使用了上面的一些类型。
diff --git a/docs/zh/docs/tutorial/extra-models.md b/docs/zh/docs/tutorial/extra-models.md
index ccfb3aa5ab..4d18c76ec1 100644
--- a/docs/zh/docs/tutorial/extra-models.md
+++ b/docs/zh/docs/tutorial/extra-models.md
@@ -1,4 +1,4 @@
-# 更多模型
+# 更多模型 { #extra-models }
书接上文,多个关联模型这种情况很常见。
@@ -6,29 +6,29 @@
* **输入模型**应该含密码
* **输出模型**不应含密码
-* **数据库模型**需要加密的密码
+* **数据库模型**可能需要包含哈希后的密码
-/// danger | 危险
+/// danger
-千万不要存储用户的明文密码。始终存储可以进行验证的**安全哈希值**。
+不要存储用户的明文密码。始终只存储之后可用于校验的“安全哈希”。
-如果不了解这方面的知识,请参阅[安全性中的章节](security/simple-oauth2.md#password-hashing){.internal-link target=_blank},了解什么是**密码哈希**。
+如果你还不了解,可以在[安全性章节](security/simple-oauth2.md#password-hashing){.internal-link target=_blank}中学习什么是“密码哈希”。
///
-## 多个模型
+## 多个模型 { #multiple-models }
下面的代码展示了不同模型处理密码字段的方式,及使用位置的大致思路:
{* ../../docs_src/extra_models/tutorial001_py310.py hl[7,9,14,20,22,27:28,31:33,38:39] *}
-### `**user_in.dict()` 简介
+### 关于 `**user_in.model_dump()` { #about-user-in-model-dump }
-#### Pydantic 的 `.dict()`
+#### Pydantic 的 `.model_dump()` { #pydantics-model-dump }
`user_in` 是类 `UserIn` 的 Pydantic 模型。
-Pydantic 模型支持 `.dict()` 方法,能返回包含模型数据的**字典**。
+Pydantic 模型有 `.model_dump()` 方法,会返回包含模型数据的 `dict`。
因此,如果使用如下方式创建 Pydantic 对象 `user_in`:
@@ -39,10 +39,10 @@ user_in = UserIn(username="john", password="secret", email="john.doe@example.com
就能以如下方式调用:
```Python
-user_dict = user_in.dict()
+user_dict = user_in.model_dump()
```
-现在,变量 `user_dict`中的就是包含数据的**字典**(变量 `user_dict` 是字典,不是 Pydantic 模型对象)。
+现在,变量 `user_dict` 中的是包含数据的 `dict`(它是 `dict`,不是 Pydantic 模型对象)。
以如下方式调用:
@@ -50,7 +50,7 @@ user_dict = user_in.dict()
print(user_dict)
```
-输出的就是 Python **字典**:
+输出的就是 Python `dict`:
```Python
{
@@ -61,9 +61,9 @@ print(user_dict)
}
```
-#### 解包 `dict`
+#### 解包 `dict` { #unpacking-a-dict }
-把**字典** `user_dict` 以 `**user_dict` 形式传递给函数(或类),Python 会执行**解包**操作。它会把 `user_dict` 的键和值作为关键字参数直接传递。
+把 `dict`(如 `user_dict`)以 `**user_dict` 形式传递给函数(或类),Python 会执行“解包”。它会把 `user_dict` 的键和值作为关键字参数直接传递。
因此,接着上面的 `user_dict` 继续编写如下代码:
@@ -82,7 +82,7 @@ UserInDB(
)
```
-或更精准,直接把可能会用到的内容与 `user_dict` 一起使用:
+或更精准,直接使用 `user_dict`(无论它将来包含什么字段):
```Python
UserInDB(
@@ -93,31 +93,31 @@ UserInDB(
)
```
-#### 用其它模型中的内容生成 Pydantic 模型
+#### 用另一个模型的内容生成 Pydantic 模型 { #a-pydantic-model-from-the-contents-of-another }
-上例中 ,从 `user_in.dict()` 中得到了 `user_dict`,下面的代码:
+上例中 ,从 `user_in.model_dump()` 中得到了 `user_dict`,下面的代码:
```Python
-user_dict = user_in.dict()
+user_dict = user_in.model_dump()
UserInDB(**user_dict)
```
等效于:
```Python
-UserInDB(**user_in.dict())
+UserInDB(**user_in.model_dump())
```
-……因为 `user_in.dict()` 是字典,在传递给 `UserInDB` 时,把 `**` 加在 `user_in.dict()` 前,可以让 Python 进行**解包**。
+……因为 `user_in.model_dump()` 是 `dict`,在传递给 `UserInDB` 时,把 `**` 加在 `user_in.model_dump()` 前,可以让 Python 进行解包。
这样,就可以用其它 Pydantic 模型中的数据生成 Pydantic 模型。
-#### 解包 `dict` 和更多关键字
+#### 解包 `dict` 并添加额外关键字参数 { #unpacking-a-dict-and-extra-keywords }
接下来,继续添加关键字参数 `hashed_password=hashed_password`,例如:
```Python
-UserInDB(**user_in.dict(), hashed_password=hashed_password)
+UserInDB(**user_in.model_dump(), hashed_password=hashed_password)
```
……输出结果如下:
@@ -132,68 +132,80 @@ UserInDB(
)
```
-/// warning | 警告
+/// warning
-辅助的附加函数只是为了演示可能的数据流,但它们显然不能提供任何真正的安全机制。
+配套的辅助函数 `fake_password_hasher` 和 `fake_save_user` 仅用于演示可能的数据流,当然并不提供真实的安全性。
///
-## 减少重复
+## 减少重复 { #reduce-duplication }
-**FastAPI** 的核心思想就是减少代码重复。
+减少代码重复是 **FastAPI** 的核心思想之一。
代码重复会导致 bug、安全问题、代码失步等问题(更新了某个位置的代码,但没有同步更新其它位置的代码)。
上面的这些模型共享了大量数据,拥有重复的属性名和类型。
-FastAPI 可以做得更好。
+我们可以做得更好。
-声明 `UserBase` 模型作为其它模型的基类。然后,用该类衍生出继承其属性(类型声明、验证等)的子类。
+声明 `UserBase` 模型作为其它模型的基类。然后,用该类衍生出继承其属性(类型声明、校验等)的子类。
所有数据转换、校验、文档等功能仍将正常运行。
-这样,就可以仅声明模型之间的差异部分(具有明文的 `password`、具有 `hashed_password` 以及不包括密码)。
-
-通过这种方式,可以只声明模型之间的区别(分别包含明文密码、哈希密码,以及无密码的模型)。
+这样,就可以仅声明模型之间的差异部分(具有明文的 `password`、具有 `hashed_password` 以及不包括密码):
{* ../../docs_src/extra_models/tutorial002_py310.py hl[7,13:14,17:18,21:22] *}
-## `Union` 或者 `anyOf`
+## `Union` 或 `anyOf` { #union-or-anyof }
-响应可以声明为两种类型的 `Union` 类型,即该响应可以是两种类型中的任意类型。
+响应可以声明为两个或多个类型的 `Union`,即该响应可以是这些类型中的任意一种。
-在 OpenAPI 中可以使用 `anyOf` 定义。
+在 OpenAPI 中会用 `anyOf` 表示。
为此,请使用 Python 标准类型提示 `typing.Union`:
-/// note | 笔记
+/// note
-定义 `Union` 类型时,要把详细的类型写在前面,然后是不太详细的类型。下例中,更详细的 `PlaneItem` 位于 `Union[PlaneItem,CarItem]` 中的 `CarItem` 之前。
+定义 `Union` 类型时,要把更具体的类型写在前面,然后是不太具体的类型。下例中,更具体的 `PlaneItem` 位于 `Union[PlaneItem, CarItem]` 中的 `CarItem` 之前。
///
{* ../../docs_src/extra_models/tutorial003_py310.py hl[1,14:15,18:20,33] *}
-## 模型列表
+### Python 3.10 中的 `Union` { #union-in-python-3-10 }
-使用同样的方式也可以声明由对象列表构成的响应。
+在这个示例中,我们把 `Union[PlaneItem, CarItem]` 作为参数 `response_model` 的值传入。
-为此,请使用标准的 Python `typing.List`:
+因为这是作为“参数的值”而不是放在“类型注解”中,所以即使在 Python 3.10 也必须使用 `Union`。
+
+如果是在类型注解中,我们就可以使用竖线:
+
+```Python
+some_variable: PlaneItem | CarItem
+```
+
+但如果把它写成赋值 `response_model=PlaneItem | CarItem`,就会报错,因为 Python 会尝试在 `PlaneItem` 和 `CarItem` 之间执行一个“无效的运算”,而不是把它当作类型注解来解析。
+
+## 模型列表 { #list-of-models }
+
+同样地,你可以声明由对象列表构成的响应。
+
+为此,请使用标准的 Python `typing.List`(在 Python 3.9+ 中也可以直接用 `list`):
{* ../../docs_src/extra_models/tutorial004_py39.py hl[18] *}
-## 任意 `dict` 构成的响应
+## 任意 `dict` 的响应 { #response-with-arbitrary-dict }
-任意的 `dict` 都能用于声明响应,只要声明键和值的类型,无需使用 Pydantic 模型。
+你也可以使用普通的任意 `dict` 来声明响应,只需声明键和值的类型,无需使用 Pydantic 模型。
-事先不知道可用的字段 / 属性名时(Pydantic 模型必须知道字段是什么),这种方式特别有用。
+如果你事先不知道有效的字段/属性名(Pydantic 模型需要预先知道字段)时,这很有用。
-此时,可以使用 `typing.Dict`:
+此时,可以使用 `typing.Dict`(在 Python 3.9+ 中也可以直接用 `dict`):
{* ../../docs_src/extra_models/tutorial005_py39.py hl[6] *}
-## 小结
+## 小结 { #recap }
-针对不同场景,可以随意使用不同的 Pydantic 模型继承定义的基类。
+针对不同场景,可以随意使用不同的 Pydantic 模型并通过继承复用。
-实体必须具有不同的**状态**时,不必为不同状态的实体单独定义数据模型。例如,用户**实体**就有包含 `password`、包含 `password_hash` 以及不含密码等多种状态。
+当一个实体需要具备不同的“状态”时,无需只为该实体定义一个数据模型。例如,用户“实体”就可能有包含 `password`、包含 `password_hash` 以及不含密码等多种状态。
diff --git a/docs/zh/docs/tutorial/header-params.md b/docs/zh/docs/tutorial/header-params.md
index 19bb455cf4..ccb88ae7fa 100644
--- a/docs/zh/docs/tutorial/header-params.md
+++ b/docs/zh/docs/tutorial/header-params.md
@@ -1,14 +1,14 @@
-# Header 参数
+# Header 参数 { #header-parameters }
定义 `Header` 参数的方式与定义 `Query`、`Path`、`Cookie` 参数相同。
-## 导入 `Header`
+## 导入 `Header` { #import-header }
首先,导入 `Header`:
{* ../../docs_src/header_params/tutorial001_an_py310.py hl[3] *}
-## 声明 `Header` 参数
+## 声明 `Header` 参数 { #declare-header-parameters }
然后,使用和 `Path`、`Query`、`Cookie` 一样的结构定义 header 参数。
@@ -24,13 +24,13 @@
///
-/// info | 说明
+/// info | 信息
必须使用 `Header` 声明 header 参数,否则该参数会被解释为查询参数。
///
-## 自动转换
+## 自动转换 { #automatic-conversion }
`Header` 比 `Path`、`Query` 和 `Cookie` 提供了更多功能。
@@ -54,7 +54,7 @@
///
-## 重复的请求头
+## 重复的请求头 { #duplicate-headers }
有时,可能需要接收重复的请求头。即同一个请求头有多个值。
@@ -84,7 +84,7 @@ X-Token: bar
}
```
-## 小结
+## 小结 { #recap }
使用 `Header` 声明请求头的方式与 `Query`、`Path` 、`Cookie` 相同。
diff --git a/docs/zh/docs/tutorial/index.md b/docs/zh/docs/tutorial/index.md
index 3ca927337f..7934583023 100644
--- a/docs/zh/docs/tutorial/index.md
+++ b/docs/zh/docs/tutorial/index.md
@@ -1,12 +1,12 @@
-# 教程 - 用户指南
+# 教程 - 用户指南 { #tutorial-user-guide }
本教程将一步步向您展示如何使用 **FastAPI** 的绝大部分特性。
-各个章节的内容循序渐进,但是又围绕着单独的主题,所以您可以直接跳转到某个章节以解决您的特定需求。
+各个章节的内容循序渐进,但是又围绕着单独的主题,所以您可以直接跳转到某个章节以解决您的特定 API 需求。
本教程同样可以作为将来的参考手册,所以您可以随时回到本教程并查阅您需要的内容。
-## 运行代码
+## 运行代码 { #run-the-code }
所有代码片段都可以复制后直接使用(它们实际上是经过测试的 Python 文件)。
@@ -58,7 +58,7 @@ $ fastapi dev
-/// note
+/// note | 注意
-当您使用 `pip install "fastapi[standard]"` 进行安装时,它会附带一些默认的可选标准依赖项。
+当您使用 `pip install "fastapi[standard]"` 安装时,它会附带一些默认的可选标准依赖项,其中包括 `fastapi-cloud-cli`,它可以让您部署到 FastAPI Cloud。
如果您不想安装这些可选依赖,可以选择安装 `pip install fastapi`。
+如果您想安装标准依赖但不包含 `fastapi-cloud-cli`,可以使用 `pip install "fastapi[standard-no-fastapi-cloud-cli]"` 安装。
+
///
-## 进阶用户指南
+## 进阶用户指南 { #advanced-user-guide }
在本**教程-用户指南**之后,您可以阅读**进阶用户指南**。
diff --git a/docs/zh/docs/tutorial/metadata.md b/docs/zh/docs/tutorial/metadata.md
index d29a1e6d05..6ec7e9add1 100644
--- a/docs/zh/docs/tutorial/metadata.md
+++ b/docs/zh/docs/tutorial/metadata.md
@@ -1,28 +1,28 @@
-# 元数据和文档 URL
+# 元数据和文档 URL { #metadata-and-docs-urls }
你可以在 FastAPI 应用程序中自定义多个元数据配置。
-## API 元数据
+## API 元数据 { #metadata-for-api }
你可以在设置 OpenAPI 规范和自动 API 文档 UI 中使用的以下字段:
| 参数 | 类型 | 描述 |
|------------|------|-------------|
| `title` | `str` | API 的标题。 |
-| `summary` | `str` | API 的简短摘要。 自 OpenAPI 3.1.0、FastAPI 0.99.0 起可用。. |
-| `description` | `str` | API 的简短描述。可以使用Markdown。 |
-| `version` | `string` | API 的版本。这是您自己的应用程序的版本,而不是 OpenAPI 的版本。例如 `2.5.0` 。 |
+| `summary` | `str` | API 的简短摘要。 自 OpenAPI 3.1.0、FastAPI 0.99.0 起可用。 |
+| `description` | `str` | API 的简短描述。可以使用 Markdown。 |
+| `version` | `string` | API 的版本。这是您自己的应用程序的版本,而不是 OpenAPI 的版本。例如 `2.5.0`。 |
| `terms_of_service` | `str` | API 服务条款的 URL。如果提供,则必须是 URL。 |
-| `contact` | `dict` | 公开的 API 的联系信息。它可以包含多个字段。contact 字段| 参数 | Type | 描述 |
|---|---|---|
name | str | 联系人/组织的识别名称。 |
url | str | 指向联系信息的 URL。必须采用 URL 格式。 |
email | str | 联系人/组织的电子邮件地址。必须采用电子邮件地址的格式。 |
license_info 字段| 参数 | 类型 | 描述 |
|---|---|---|
name | str | 必须的 (如果设置了license_info). 用于 API 的许可证名称。 |
identifier | str | 一个API的SPDX许可证表达。 The identifier field is mutually exclusive of the url field. 自 OpenAPI 3.1.0、FastAPI 0.99.0 起可用。 |
url | str | 用于 API 的许可证的 URL。必须采用 URL 格式。 |
contact 字段| 参数 | 类型 | 描述 |
|---|---|---|
name | str | 联系人/组织的识别名称。 |
url | str | 指向联系信息的 URL。必须采用 URL 格式。 |
email | str | 联系人/组织的电子邮件地址。必须采用电子邮件地址的格式。 |
license_info 字段| 参数 | 类型 | 描述 |
|---|---|---|
name | str | 必须(如果设置了 license_info)。用于 API 的许可证名称。 |
identifier | str | API 的 SPDX 许可证表达式。字段 identifier 与字段 url 互斥。自 OpenAPI 3.1.0、FastAPI 0.99.0 起可用。 |
url | str | 用于 API 的许可证的 URL。必须采用 URL 格式。 |
 -## 标签元数据
+## 许可证标识符 { #license-identifier }
-### 创建标签元数据
+自 OpenAPI 3.1.0 和 FastAPI 0.99.0 起,你还可以在 `license_info` 中使用 `identifier` 而不是 `url`。
+
+例如:
+
+{* ../../docs_src/metadata/tutorial001_1_py39.py hl[31] *}
+
+## 标签元数据 { #metadata-for-tags }
+
+你也可以通过参数 `openapi_tags` 为用于分组路径操作的不同标签添加额外的元数据。
+
+它接收一个列表,列表中每个标签对应一个字典。
+
+每个字典可以包含:
+
+- `name`(必填):一个 `str`,与在你的*路径操作*和 `APIRouter` 的 `tags` 参数中使用的标签名相同。
+- `description`:一个 `str`,该标签的简短描述。可以使用 Markdown,并会显示在文档 UI 中。
+- `externalDocs`:一个 `dict`,描述外部文档,包含:
+ - `description`:一个 `str`,该外部文档的简短描述。
+ - `url`(必填):一个 `str`,该外部文档的 URL。
+
+### 创建标签元数据 { #create-metadata-for-tags }
让我们在带有标签的示例中为 `users` 和 `items` 试一下。
创建标签元数据并把它传递给 `openapi_tags` 参数:
-{* ../../docs_src/metadata/tutorial004.py hl[3:16,18] *}
+{* ../../docs_src/metadata/tutorial004_py39.py hl[3:16,18] *}
注意你可以在描述内使用 Markdown,例如「login」会显示为粗体(**login**)以及「fancy」会显示为斜体(_fancy_)。
@@ -48,11 +68,11 @@
///
-### 使用你的标签
+### 使用你的标签 { #use-your-tags }
将 `tags` 参数和*路径操作*(以及 `APIRouter`)一起使用,将其分配给不同的标签:
-{* ../../docs_src/metadata/tutorial004.py hl[21,26] *}
+{* ../../docs_src/metadata/tutorial004_py39.py hl[21,26] *}
/// info | 信息
@@ -60,19 +80,19 @@
///
-### 查看文档
+### 查看文档 { #check-the-docs }
如果你现在查看文档,它们会显示所有附加的元数据:
-## 标签元数据
+## 许可证标识符 { #license-identifier }
-### 创建标签元数据
+自 OpenAPI 3.1.0 和 FastAPI 0.99.0 起,你还可以在 `license_info` 中使用 `identifier` 而不是 `url`。
+
+例如:
+
+{* ../../docs_src/metadata/tutorial001_1_py39.py hl[31] *}
+
+## 标签元数据 { #metadata-for-tags }
+
+你也可以通过参数 `openapi_tags` 为用于分组路径操作的不同标签添加额外的元数据。
+
+它接收一个列表,列表中每个标签对应一个字典。
+
+每个字典可以包含:
+
+- `name`(必填):一个 `str`,与在你的*路径操作*和 `APIRouter` 的 `tags` 参数中使用的标签名相同。
+- `description`:一个 `str`,该标签的简短描述。可以使用 Markdown,并会显示在文档 UI 中。
+- `externalDocs`:一个 `dict`,描述外部文档,包含:
+ - `description`:一个 `str`,该外部文档的简短描述。
+ - `url`(必填):一个 `str`,该外部文档的 URL。
+
+### 创建标签元数据 { #create-metadata-for-tags }
让我们在带有标签的示例中为 `users` 和 `items` 试一下。
创建标签元数据并把它传递给 `openapi_tags` 参数:
-{* ../../docs_src/metadata/tutorial004.py hl[3:16,18] *}
+{* ../../docs_src/metadata/tutorial004_py39.py hl[3:16,18] *}
注意你可以在描述内使用 Markdown,例如「login」会显示为粗体(**login**)以及「fancy」会显示为斜体(_fancy_)。
@@ -48,11 +68,11 @@
///
-### 使用你的标签
+### 使用你的标签 { #use-your-tags }
将 `tags` 参数和*路径操作*(以及 `APIRouter`)一起使用,将其分配给不同的标签:
-{* ../../docs_src/metadata/tutorial004.py hl[21,26] *}
+{* ../../docs_src/metadata/tutorial004_py39.py hl[21,26] *}
/// info | 信息
@@ -60,19 +80,19 @@
///
-### 查看文档
+### 查看文档 { #check-the-docs }
如果你现在查看文档,它们会显示所有附加的元数据:
 -### 标签顺序
+### 标签顺序 { #order-of-tags }
每个标签元数据字典的顺序也定义了在文档用户界面显示的顺序。
例如按照字母顺序,即使 `users` 排在 `items` 之后,它也会显示在前面,因为我们将它的元数据添加为列表内的第一个字典。
-## OpenAPI URL
+## OpenAPI URL { #openapi-url }
默认情况下,OpenAPI 模式服务于 `/openapi.json`。
@@ -80,21 +100,21 @@
例如,将其设置为服务于 `/api/v1/openapi.json`:
-{* ../../docs_src/metadata/tutorial002.py hl[3] *}
+{* ../../docs_src/metadata/tutorial002_py39.py hl[3] *}
如果你想完全禁用 OpenAPI 模式,可以将其设置为 `openapi_url=None`,这样也会禁用使用它的文档用户界面。
-## 文档 URLs
+## 文档 URLs { #docs-urls }
你可以配置两个文档用户界面,包括:
-* **Swagger UI**:服务于 `/docs`。
- * 可以使用参数 `docs_url` 设置它的 URL。
- * 可以通过设置 `docs_url=None` 禁用它。
-* ReDoc:服务于 `/redoc`。
- * 可以使用参数 `redoc_url` 设置它的 URL。
- * 可以通过设置 `redoc_url=None` 禁用它。
+- **Swagger UI**:服务于 `/docs`。
+ - 可以使用参数 `docs_url` 设置它的 URL。
+ - 可以通过设置 `docs_url=None` 禁用它。
+- **ReDoc**:服务于 `/redoc`。
+ - 可以使用参数 `redoc_url` 设置它的 URL。
+ - 可以通过设置 `redoc_url=None` 禁用它。
例如,设置 Swagger UI 服务于 `/documentation` 并禁用 ReDoc:
-{* ../../docs_src/metadata/tutorial003.py hl[3] *}
+{* ../../docs_src/metadata/tutorial003_py39.py hl[3] *}
diff --git a/docs/zh/docs/tutorial/query-param-models.md b/docs/zh/docs/tutorial/query-param-models.md
index c6a79a71a2..fc691839d5 100644
--- a/docs/zh/docs/tutorial/query-param-models.md
+++ b/docs/zh/docs/tutorial/query-param-models.md
@@ -1,16 +1,16 @@
-# 查询参数模型
+# 查询参数模型 { #query-parameter-models }
如果你有一组具有相关性的**查询参数**,你可以创建一个 **Pydantic 模型**来声明它们。
这将允许你在**多个地方**去**复用模型**,并且一次性为所有参数声明验证和元数据。😎
-/// note
+/// note | 注意
FastAPI 从 `0.115.0` 版本开始支持这个特性。🤓
///
-## 使用 Pydantic 模型的查询参数
+## 使用 Pydantic 模型的查询参数 { #query-parameters-with-a-pydantic-model }
在一个 **Pydantic 模型**中声明你需要的**查询参数**,然后将参数声明为 `Query`:
@@ -18,7 +18,7 @@ FastAPI 从 `0.115.0` 版本开始支持这个特性。🤓
**FastAPI** 将会从请求的**查询参数**中**提取**出**每个字段**的数据,并将其提供给你定义的 Pydantic 模型。
-## 查看文档
+## 查看文档 { #check-the-docs }
你可以在 `/docs` 页面的 UI 中查看查询参数:
@@ -26,11 +26,11 @@ FastAPI 从 `0.115.0` 版本开始支持这个特性。🤓
-### 标签顺序
+### 标签顺序 { #order-of-tags }
每个标签元数据字典的顺序也定义了在文档用户界面显示的顺序。
例如按照字母顺序,即使 `users` 排在 `items` 之后,它也会显示在前面,因为我们将它的元数据添加为列表内的第一个字典。
-## OpenAPI URL
+## OpenAPI URL { #openapi-url }
默认情况下,OpenAPI 模式服务于 `/openapi.json`。
@@ -80,21 +100,21 @@
例如,将其设置为服务于 `/api/v1/openapi.json`:
-{* ../../docs_src/metadata/tutorial002.py hl[3] *}
+{* ../../docs_src/metadata/tutorial002_py39.py hl[3] *}
如果你想完全禁用 OpenAPI 模式,可以将其设置为 `openapi_url=None`,这样也会禁用使用它的文档用户界面。
-## 文档 URLs
+## 文档 URLs { #docs-urls }
你可以配置两个文档用户界面,包括:
-* **Swagger UI**:服务于 `/docs`。
- * 可以使用参数 `docs_url` 设置它的 URL。
- * 可以通过设置 `docs_url=None` 禁用它。
-* ReDoc:服务于 `/redoc`。
- * 可以使用参数 `redoc_url` 设置它的 URL。
- * 可以通过设置 `redoc_url=None` 禁用它。
+- **Swagger UI**:服务于 `/docs`。
+ - 可以使用参数 `docs_url` 设置它的 URL。
+ - 可以通过设置 `docs_url=None` 禁用它。
+- **ReDoc**:服务于 `/redoc`。
+ - 可以使用参数 `redoc_url` 设置它的 URL。
+ - 可以通过设置 `redoc_url=None` 禁用它。
例如,设置 Swagger UI 服务于 `/documentation` 并禁用 ReDoc:
-{* ../../docs_src/metadata/tutorial003.py hl[3] *}
+{* ../../docs_src/metadata/tutorial003_py39.py hl[3] *}
diff --git a/docs/zh/docs/tutorial/query-param-models.md b/docs/zh/docs/tutorial/query-param-models.md
index c6a79a71a2..fc691839d5 100644
--- a/docs/zh/docs/tutorial/query-param-models.md
+++ b/docs/zh/docs/tutorial/query-param-models.md
@@ -1,16 +1,16 @@
-# 查询参数模型
+# 查询参数模型 { #query-parameter-models }
如果你有一组具有相关性的**查询参数**,你可以创建一个 **Pydantic 模型**来声明它们。
这将允许你在**多个地方**去**复用模型**,并且一次性为所有参数声明验证和元数据。😎
-/// note
+/// note | 注意
FastAPI 从 `0.115.0` 版本开始支持这个特性。🤓
///
-## 使用 Pydantic 模型的查询参数
+## 使用 Pydantic 模型的查询参数 { #query-parameters-with-a-pydantic-model }
在一个 **Pydantic 模型**中声明你需要的**查询参数**,然后将参数声明为 `Query`:
@@ -18,7 +18,7 @@ FastAPI 从 `0.115.0` 版本开始支持这个特性。🤓
**FastAPI** 将会从请求的**查询参数**中**提取**出**每个字段**的数据,并将其提供给你定义的 Pydantic 模型。
-## 查看文档
+## 查看文档 { #check-the-docs }
你可以在 `/docs` 页面的 UI 中查看查询参数:
@@ -26,11 +26,11 @@ FastAPI 从 `0.115.0` 版本开始支持这个特性。🤓
 -## 禁止额外的查询参数
+## 禁止额外的查询参数 { #forbid-extra-query-parameters }
在一些特殊的使用场景中(可能不是很常见),你可能希望**限制**你要接收的查询参数。
-你可以使用 Pydantic 的模型配置来 `forbid`(意为禁止 —— 译者注)任何 `extra`(意为额外的 —— 译者注)字段:
+你可以使用 Pydantic 的模型配置来 `forbid` 任何 `extra` 字段:
{* ../../docs_src/query_param_models/tutorial002_an_py310.py hl[10] *}
@@ -57,11 +57,11 @@ https://example.com/items/?limit=10&tool=plumbus
}
```
-## 总结
+## 总结 { #summary }
你可以使用 **Pydantic 模型**在 **FastAPI** 中声明**查询参数**。😎
-/// tip
+/// tip | 提示
剧透警告:你也可以使用 Pydantic 模型来声明 cookie 和 headers,但你将在本教程的后面部分阅读到这部分内容。🤫
diff --git a/docs/zh/docs/tutorial/request-form-models.md b/docs/zh/docs/tutorial/request-form-models.md
index e639e4b9fc..4eb98ea225 100644
--- a/docs/zh/docs/tutorial/request-form-models.md
+++ b/docs/zh/docs/tutorial/request-form-models.md
@@ -1,12 +1,12 @@
-# 表单模型
+# 表单模型 { #form-models }
-您可以使用 **Pydantic 模型**在 FastAPI 中声明**表单字段**。
+你可以在 FastAPI 中使用 **Pydantic 模型**声明**表单字段**。
-/// info
+/// info | 信息
-要使用表单,需预先安装 `python-multipart` 。
+要使用表单,首先安装 `python-multipart`。
-确保您创建、激活一个[虚拟环境](../virtual-environments.md){.internal-link target=_blank}后再安装。
+确保你创建一个[虚拟环境](../virtual-environments.md){.internal-link target=_blank},激活它,然后再安装,例如:
```console
$ pip install python-multipart
@@ -14,51 +14,51 @@ $ pip install python-multipart
///
-/// note
+/// note | 注意
自 FastAPI 版本 `0.113.0` 起支持此功能。🤓
///
-## 表单的 Pydantic 模型
+## 表单的 Pydantic 模型 { #pydantic-models-for-forms }
-您只需声明一个 **Pydantic 模型**,其中包含您希望接收的**表单字段**,然后将参数声明为 `Form` :
+你只需声明一个 **Pydantic 模型**,其中包含你希望接收的**表单字段**,然后将参数声明为 `Form`:
{* ../../docs_src/request_form_models/tutorial001_an_py39.py hl[9:11,15] *}
-**FastAPI** 将从请求中的**表单数据**中**提取**出**每个字段**的数据,并提供您定义的 Pydantic 模型。
+**FastAPI** 将从请求中的**表单数据**中**提取**出**每个字段**的数据,并提供你定义的 Pydantic 模型。
-## 检查文档
+## 检查文档 { #check-the-docs }
-您可以在文档 UI 中验证它,地址为 `/docs` :
+你可以在文档 UI 中验证它,地址为 `/docs`:
-## 禁止额外的查询参数
+## 禁止额外的查询参数 { #forbid-extra-query-parameters }
在一些特殊的使用场景中(可能不是很常见),你可能希望**限制**你要接收的查询参数。
-你可以使用 Pydantic 的模型配置来 `forbid`(意为禁止 —— 译者注)任何 `extra`(意为额外的 —— 译者注)字段:
+你可以使用 Pydantic 的模型配置来 `forbid` 任何 `extra` 字段:
{* ../../docs_src/query_param_models/tutorial002_an_py310.py hl[10] *}
@@ -57,11 +57,11 @@ https://example.com/items/?limit=10&tool=plumbus
}
```
-## 总结
+## 总结 { #summary }
你可以使用 **Pydantic 模型**在 **FastAPI** 中声明**查询参数**。😎
-/// tip
+/// tip | 提示
剧透警告:你也可以使用 Pydantic 模型来声明 cookie 和 headers,但你将在本教程的后面部分阅读到这部分内容。🤫
diff --git a/docs/zh/docs/tutorial/request-form-models.md b/docs/zh/docs/tutorial/request-form-models.md
index e639e4b9fc..4eb98ea225 100644
--- a/docs/zh/docs/tutorial/request-form-models.md
+++ b/docs/zh/docs/tutorial/request-form-models.md
@@ -1,12 +1,12 @@
-# 表单模型
+# 表单模型 { #form-models }
-您可以使用 **Pydantic 模型**在 FastAPI 中声明**表单字段**。
+你可以在 FastAPI 中使用 **Pydantic 模型**声明**表单字段**。
-/// info
+/// info | 信息
-要使用表单,需预先安装 `python-multipart` 。
+要使用表单,首先安装 `python-multipart`。
-确保您创建、激活一个[虚拟环境](../virtual-environments.md){.internal-link target=_blank}后再安装。
+确保你创建一个[虚拟环境](../virtual-environments.md){.internal-link target=_blank},激活它,然后再安装,例如:
```console
$ pip install python-multipart
@@ -14,51 +14,51 @@ $ pip install python-multipart
///
-/// note
+/// note | 注意
自 FastAPI 版本 `0.113.0` 起支持此功能。🤓
///
-## 表单的 Pydantic 模型
+## 表单的 Pydantic 模型 { #pydantic-models-for-forms }
-您只需声明一个 **Pydantic 模型**,其中包含您希望接收的**表单字段**,然后将参数声明为 `Form` :
+你只需声明一个 **Pydantic 模型**,其中包含你希望接收的**表单字段**,然后将参数声明为 `Form`:
{* ../../docs_src/request_form_models/tutorial001_an_py39.py hl[9:11,15] *}
-**FastAPI** 将从请求中的**表单数据**中**提取**出**每个字段**的数据,并提供您定义的 Pydantic 模型。
+**FastAPI** 将从请求中的**表单数据**中**提取**出**每个字段**的数据,并提供你定义的 Pydantic 模型。
-## 检查文档
+## 检查文档 { #check-the-docs }
-您可以在文档 UI 中验证它,地址为 `/docs` :
+你可以在文档 UI 中验证它,地址为 `/docs`:
 /// check | Authorize 按钮!
-页面右上角出现了一个「**Authorize**」按钮。
+页面右上角已经有一个崭新的“Authorize”按钮。
-*路径操作*的右上角也出现了一个可以点击的小锁图标。
+你的*路径操作*右上角还有一个可点击的小锁图标。
///
-点击 **Authorize** 按钮,弹出授权表单,输入 `username` 与 `password` 及其它可选字段:
+点击它,会弹出一个授权表单,可输入 `username` 和 `password`(以及其它可选字段):
/// check | Authorize 按钮!
-页面右上角出现了一个「**Authorize**」按钮。
+页面右上角已经有一个崭新的“Authorize”按钮。
-*路径操作*的右上角也出现了一个可以点击的小锁图标。
+你的*路径操作*右上角还有一个可点击的小锁图标。
///
-点击 **Authorize** 按钮,弹出授权表单,输入 `username` 与 `password` 及其它可选字段:
+点击它,会弹出一个授权表单,可输入 `username` 和 `password`(以及其它可选字段):
 -/// note | 笔记
+/// note | 注意
-目前,在表单中输入内容不会有任何反应,后文会介绍相关内容。
+目前无论在表单中输入什么都不会生效,我们稍后就会实现它。
///
-虽然此文档不是给前端最终用户使用的,但这个自动工具非常实用,可在文档中与所有 API 交互。
+这当然不是面向最终用户的前端,但它是一个很棒的自动化工具,可交互式地为整个 API 提供文档。
-前端团队(可能就是开发者本人)可以使用本工具。
+前端团队(也可能就是你自己)可以使用它。
-第三方应用与系统也可以调用本工具。
+第三方应用和系统也可以使用它。
-开发者也可以用它来调试、检查、测试应用。
+你也可以用它来调试、检查和测试同一个应用。
-## 密码流
+## `password` 流 { #the-password-flow }
-现在,我们回过头来介绍这段代码的原理。
+现在回过头来理解这些内容。
-`Password` **流**是 OAuth2 定义的,用于处理安全与身份验证的方式(**流**)。
+`password` “流”(flow)是 OAuth2 定义的处理安全与身份验证的一种方式。
-OAuth2 的设计目标是为了让后端或 API 独立于服务器验证用户身份。
+OAuth2 的设计目标是让后端或 API 与负责用户认证的服务器解耦。
-但在本例中,**FastAPI** 应用会处理 API 与身份验证。
+但在这个例子中,**FastAPI** 应用同时处理 API 和认证。
-下面,我们来看一下简化的运行流程:
+从这个简化的角度来看看流程:
-- 用户在前端输入 `username` 与`password`,并点击**回车**
-- (用户浏览器中运行的)前端把 `username` 与`password` 发送至 API 中指定的 URL(使用 `tokenUrl="token"` 声明)
-- API 检查 `username` 与`password`,并用令牌(`Token`) 响应(暂未实现此功能):
- - 令牌只是用于验证用户的字符串
- - 一般来说,令牌会在一段时间后过期
- - 过时后,用户要再次登录
- - 这样一来,就算令牌被人窃取,风险也较低。因为它与永久密钥不同,**在绝大多数情况下**不会长期有效
-- 前端临时将令牌存储在某个位置
-- 用户点击前端,前往前端应用的其它部件
-- 前端需要从 API 中提取更多数据:
- - 为指定的端点(Endpoint)进行身份验证
- - 因此,用 API 验证身份时,要发送值为 `Bearer` + 令牌的请求头 `Authorization`
- - 假如令牌为 `foobar`,`Authorization` 请求头就是: `Bearer foobar`
+* 用户在前端输入 `username` 和 `password`,然后按下 `Enter`。
+* 前端(运行在用户浏览器中)把 `username` 和 `password` 发送到我们 API 中的特定 URL(使用 `tokenUrl="token"` 声明)。
+* API 校验 `username` 和 `password`,并返回一个“令牌”(这些我们尚未实现)。
+ * “令牌”只是一个字符串,包含一些内容,之后可用来验证该用户。
+ * 通常,令牌会在一段时间后过期。
+ * 因此,用户过一段时间需要重新登录。
+ * 如果令牌被窃取,风险也更小。它不像一把永久有效的钥匙(在大多数情况下)。
+* 前端会把令牌临时存储在某处。
+* 用户在前端中点击跳转到前端应用的其他部分。
+* 前端需要从 API 获取更多数据。
+ * 但该端点需要身份验证。
+ * 因此,为了与我们的 API 进行身份验证,它会发送一个 `Authorization` 请求头,值为 `Bearer ` 加上令牌。
+ * 如果令牌内容是 `foobar`,`Authorization` 请求头的内容就是:`Bearer foobar`。
-## **FastAPI** 的 `OAuth2PasswordBearer`
+## **FastAPI** 的 `OAuth2PasswordBearer` { #fastapis-oauth2passwordbearer }
-**FastAPI** 提供了不同抽象级别的安全工具。
+**FastAPI** 在不同抽象层级提供了多种安全工具。
-本例使用 **OAuth2** 的 **Password** 流以及 **Bearer** 令牌(`Token`)。为此要使用 `OAuth2PasswordBearer` 类。
+本示例将使用 **OAuth2** 的 **Password** 流程并配合 **Bearer** 令牌,通过 `OAuth2PasswordBearer` 类来实现。
-/// info | 说明
+/// info | 信息
-`Bearer` 令牌不是唯一的选择。
+“Bearer” 令牌并非唯一选项。
-但它是最适合这个用例的方案。
+但它非常适合我们的用例。
-甚至可以说,它是适用于绝大多数用例的最佳方案,除非您是 OAuth2 的专家,知道为什么其它方案更合适。
+对于大多数用例,它也可能是最佳选择,除非你是 OAuth2 专家,并明确知道为何其他方案更适合你的需求。
-本例中,**FastAPI** 还提供了构建工具。
+在那种情况下,**FastAPI** 同样提供了相应的构建工具。
///
-创建 `OAuth2PasswordBearer` 的类实例时,要传递 `tokenUrl` 参数。该参数包含客户端(用户浏览器中运行的前端) 的 URL,用于发送 `username` 与 `password`,并获取令牌。
+创建 `OAuth2PasswordBearer` 类实例时,需要传入 `tokenUrl` 参数。该参数包含客户端(运行在用户浏览器中的前端)用来发送 `username` 和 `password` 以获取令牌的 URL。
-{* ../../docs_src/security/tutorial001.py hl[6] *}
+{* ../../docs_src/security/tutorial001_an_py39.py hl[8] *}
/// tip | 提示
-在此,`tokenUrl="token"` 指向的是暂未创建的相对 URL `token`。这个相对 URL 相当于 `./token`。
+这里的 `tokenUrl="token"` 指向的是尚未创建的相对 URL `token`,等价于 `./token`。
-因为使用的是相对 URL,如果 API 位于 `https://example.com/`,则指向 `https://example.com/token`。但如果 API 位于 `https://example.com/api/v1/`,它指向的就是`https://example.com/api/v1/token`。
+因为使用的是相对 URL,若你的 API 位于 `https://example.com/`,它将指向 `https://example.com/token`;若你的 API 位于 `https://example.com/api/v1/`,它将指向 `https://example.com/api/v1/token`。
-使用相对 URL 非常重要,可以确保应用在遇到[使用代理](../../advanced/behind-a-proxy.md){.internal-link target=_blank}这样的高级用例时,也能正常运行。
+使用相对 URL 很重要,这能确保你的应用在诸如[使用代理](../../advanced/behind-a-proxy.md){.internal-link target=_blank}等高级用例中依然正常工作。
///
-该参数不会创建端点或*路径操作*,但会声明客户端用来获取令牌的 URL `/token` 。此信息用于 OpenAPI 及 API 文档。
+这个参数不会创建该端点/*路径操作*,而是声明客户端应使用 `/token` 这个 URL 来获取令牌。这些信息会用于 OpenAPI,进而用于交互式 API 文档系统。
-接下来,学习如何创建实际的路径操作。
+我们很快也会创建对应的实际路径操作。
-/// info | 说明
+/// info | 信息
-严苛的 **Pythonista** 可能不喜欢用 `tokenUrl` 这种命名风格代替 `token_url`。
+如果你是非常严格的 “Pythonista”,可能不喜欢使用参数名 `tokenUrl` 而不是 `token_url`。
-这种命名方式是因为要使用与 OpenAPI 规范中相同的名字。以便在深入校验安全方案时,能通过复制粘贴查找更多相关信息。
+这是因为它使用了与 OpenAPI 规范中相同的名称。这样当你需要深入了解这些安全方案时,可以直接复制粘贴去查找更多信息。
///
-`oauth2_scheme` 变量是 `OAuth2PasswordBearer` 的实例,也是**可调用项**。
+`oauth2_scheme` 变量是 `OAuth2PasswordBearer` 的一个实例,同时它也是“可调用”的。
-以如下方式调用:
+可以像这样调用:
```Python
oauth2_scheme(some, parameters)
```
-因此,`Depends` 可以调用 `oauth2_scheme` 变量。
+因此,它可以与 `Depends` 一起使用。
-### 使用
+### 使用 { #use-it }
-接下来,使用 `Depends` 把 `oauth2_scheme` 传入依赖项。
+现在你可以通过 `Depends` 将 `oauth2_scheme` 作为依赖传入。
-{* ../../docs_src/security/tutorial001.py hl[10] *}
+{* ../../docs_src/security/tutorial001_an_py39.py hl[12] *}
-该依赖项使用字符串(`str`)接收*路径操作函数*的参数 `token` 。
+该依赖会提供一个 `str`,赋值给*路径操作函数*的参数 `token`。
-**FastAPI** 使用依赖项在 OpenAPI 概图(及 API 文档)中定义**安全方案**。
+**FastAPI** 会据此在 OpenAPI 架构(以及自动生成的 API 文档)中定义一个“安全方案”。
/// info | 技术细节
-**FastAPI** 使用(在依赖项中声明的)类 `OAuth2PasswordBearer` 在 OpenAPI 中定义安全方案,这是因为它继承自 `fastapi.security.oauth2.OAuth2`,而该类又是继承自`fastapi.security.base.SecurityBase`。
+**FastAPI** 之所以知道可以使用(在依赖中声明的)`OAuth2PasswordBearer` 在 OpenAPI 中定义安全方案,是因为它继承自 `fastapi.security.oauth2.OAuth2`,而后者又继承自 `fastapi.security.base.SecurityBase`。
-所有与 OpenAPI(及 API 文档)集成的安全工具都继承自 `SecurityBase`, 这就是为什么 **FastAPI** 能把它们集成至 OpenAPI 的原因。
+所有与 OpenAPI(以及自动 API 文档)集成的安全工具都继承自 `SecurityBase`,这就是 **FastAPI** 能将它们集成到 OpenAPI 的方式。
///
-## 实现的操作
+## 它做了什么 { #what-it-does }
-FastAPI 校验请求中的 `Authorization` 请求头,核对请求头的值是不是由 `Bearer ` + 令牌组成, 并返回令牌字符串(`str`)。
+它会在请求中查找 `Authorization` 请求头,检查其值是否为 `Bearer ` 加上一些令牌,并将该令牌作为 `str` 返回。
-如果没有找到 `Authorization` 请求头,或请求头的值不是 `Bearer ` + 令牌。FastAPI 直接返回 401 错误状态码(`UNAUTHORIZED`)。
+如果没有 `Authorization` 请求头,或者其值不包含 `Bearer ` 令牌,它会直接返回 401 状态码错误(`UNAUTHORIZED`)。
-开发者不需要检查错误信息,查看令牌是否存在,只要该函数能够执行,函数中就会包含令牌字符串。
+你甚至无需检查令牌是否存在即可返回错误;只要你的函数被执行,就可以确定会拿到一个 `str` 类型的令牌。
-正如下图所示,API 文档已经包含了这项功能:
+你已经可以在交互式文档中试试了:
-/// note | 笔记
+/// note | 注意
-目前,在表单中输入内容不会有任何反应,后文会介绍相关内容。
+目前无论在表单中输入什么都不会生效,我们稍后就会实现它。
///
-虽然此文档不是给前端最终用户使用的,但这个自动工具非常实用,可在文档中与所有 API 交互。
+这当然不是面向最终用户的前端,但它是一个很棒的自动化工具,可交互式地为整个 API 提供文档。
-前端团队(可能就是开发者本人)可以使用本工具。
+前端团队(也可能就是你自己)可以使用它。
-第三方应用与系统也可以调用本工具。
+第三方应用和系统也可以使用它。
-开发者也可以用它来调试、检查、测试应用。
+你也可以用它来调试、检查和测试同一个应用。
-## 密码流
+## `password` 流 { #the-password-flow }
-现在,我们回过头来介绍这段代码的原理。
+现在回过头来理解这些内容。
-`Password` **流**是 OAuth2 定义的,用于处理安全与身份验证的方式(**流**)。
+`password` “流”(flow)是 OAuth2 定义的处理安全与身份验证的一种方式。
-OAuth2 的设计目标是为了让后端或 API 独立于服务器验证用户身份。
+OAuth2 的设计目标是让后端或 API 与负责用户认证的服务器解耦。
-但在本例中,**FastAPI** 应用会处理 API 与身份验证。
+但在这个例子中,**FastAPI** 应用同时处理 API 和认证。
-下面,我们来看一下简化的运行流程:
+从这个简化的角度来看看流程:
-- 用户在前端输入 `username` 与`password`,并点击**回车**
-- (用户浏览器中运行的)前端把 `username` 与`password` 发送至 API 中指定的 URL(使用 `tokenUrl="token"` 声明)
-- API 检查 `username` 与`password`,并用令牌(`Token`) 响应(暂未实现此功能):
- - 令牌只是用于验证用户的字符串
- - 一般来说,令牌会在一段时间后过期
- - 过时后,用户要再次登录
- - 这样一来,就算令牌被人窃取,风险也较低。因为它与永久密钥不同,**在绝大多数情况下**不会长期有效
-- 前端临时将令牌存储在某个位置
-- 用户点击前端,前往前端应用的其它部件
-- 前端需要从 API 中提取更多数据:
- - 为指定的端点(Endpoint)进行身份验证
- - 因此,用 API 验证身份时,要发送值为 `Bearer` + 令牌的请求头 `Authorization`
- - 假如令牌为 `foobar`,`Authorization` 请求头就是: `Bearer foobar`
+* 用户在前端输入 `username` 和 `password`,然后按下 `Enter`。
+* 前端(运行在用户浏览器中)把 `username` 和 `password` 发送到我们 API 中的特定 URL(使用 `tokenUrl="token"` 声明)。
+* API 校验 `username` 和 `password`,并返回一个“令牌”(这些我们尚未实现)。
+ * “令牌”只是一个字符串,包含一些内容,之后可用来验证该用户。
+ * 通常,令牌会在一段时间后过期。
+ * 因此,用户过一段时间需要重新登录。
+ * 如果令牌被窃取,风险也更小。它不像一把永久有效的钥匙(在大多数情况下)。
+* 前端会把令牌临时存储在某处。
+* 用户在前端中点击跳转到前端应用的其他部分。
+* 前端需要从 API 获取更多数据。
+ * 但该端点需要身份验证。
+ * 因此,为了与我们的 API 进行身份验证,它会发送一个 `Authorization` 请求头,值为 `Bearer ` 加上令牌。
+ * 如果令牌内容是 `foobar`,`Authorization` 请求头的内容就是:`Bearer foobar`。
-## **FastAPI** 的 `OAuth2PasswordBearer`
+## **FastAPI** 的 `OAuth2PasswordBearer` { #fastapis-oauth2passwordbearer }
-**FastAPI** 提供了不同抽象级别的安全工具。
+**FastAPI** 在不同抽象层级提供了多种安全工具。
-本例使用 **OAuth2** 的 **Password** 流以及 **Bearer** 令牌(`Token`)。为此要使用 `OAuth2PasswordBearer` 类。
+本示例将使用 **OAuth2** 的 **Password** 流程并配合 **Bearer** 令牌,通过 `OAuth2PasswordBearer` 类来实现。
-/// info | 说明
+/// info | 信息
-`Bearer` 令牌不是唯一的选择。
+“Bearer” 令牌并非唯一选项。
-但它是最适合这个用例的方案。
+但它非常适合我们的用例。
-甚至可以说,它是适用于绝大多数用例的最佳方案,除非您是 OAuth2 的专家,知道为什么其它方案更合适。
+对于大多数用例,它也可能是最佳选择,除非你是 OAuth2 专家,并明确知道为何其他方案更适合你的需求。
-本例中,**FastAPI** 还提供了构建工具。
+在那种情况下,**FastAPI** 同样提供了相应的构建工具。
///
-创建 `OAuth2PasswordBearer` 的类实例时,要传递 `tokenUrl` 参数。该参数包含客户端(用户浏览器中运行的前端) 的 URL,用于发送 `username` 与 `password`,并获取令牌。
+创建 `OAuth2PasswordBearer` 类实例时,需要传入 `tokenUrl` 参数。该参数包含客户端(运行在用户浏览器中的前端)用来发送 `username` 和 `password` 以获取令牌的 URL。
-{* ../../docs_src/security/tutorial001.py hl[6] *}
+{* ../../docs_src/security/tutorial001_an_py39.py hl[8] *}
/// tip | 提示
-在此,`tokenUrl="token"` 指向的是暂未创建的相对 URL `token`。这个相对 URL 相当于 `./token`。
+这里的 `tokenUrl="token"` 指向的是尚未创建的相对 URL `token`,等价于 `./token`。
-因为使用的是相对 URL,如果 API 位于 `https://example.com/`,则指向 `https://example.com/token`。但如果 API 位于 `https://example.com/api/v1/`,它指向的就是`https://example.com/api/v1/token`。
+因为使用的是相对 URL,若你的 API 位于 `https://example.com/`,它将指向 `https://example.com/token`;若你的 API 位于 `https://example.com/api/v1/`,它将指向 `https://example.com/api/v1/token`。
-使用相对 URL 非常重要,可以确保应用在遇到[使用代理](../../advanced/behind-a-proxy.md){.internal-link target=_blank}这样的高级用例时,也能正常运行。
+使用相对 URL 很重要,这能确保你的应用在诸如[使用代理](../../advanced/behind-a-proxy.md){.internal-link target=_blank}等高级用例中依然正常工作。
///
-该参数不会创建端点或*路径操作*,但会声明客户端用来获取令牌的 URL `/token` 。此信息用于 OpenAPI 及 API 文档。
+这个参数不会创建该端点/*路径操作*,而是声明客户端应使用 `/token` 这个 URL 来获取令牌。这些信息会用于 OpenAPI,进而用于交互式 API 文档系统。
-接下来,学习如何创建实际的路径操作。
+我们很快也会创建对应的实际路径操作。
-/// info | 说明
+/// info | 信息
-严苛的 **Pythonista** 可能不喜欢用 `tokenUrl` 这种命名风格代替 `token_url`。
+如果你是非常严格的 “Pythonista”,可能不喜欢使用参数名 `tokenUrl` 而不是 `token_url`。
-这种命名方式是因为要使用与 OpenAPI 规范中相同的名字。以便在深入校验安全方案时,能通过复制粘贴查找更多相关信息。
+这是因为它使用了与 OpenAPI 规范中相同的名称。这样当你需要深入了解这些安全方案时,可以直接复制粘贴去查找更多信息。
///
-`oauth2_scheme` 变量是 `OAuth2PasswordBearer` 的实例,也是**可调用项**。
+`oauth2_scheme` 变量是 `OAuth2PasswordBearer` 的一个实例,同时它也是“可调用”的。
-以如下方式调用:
+可以像这样调用:
```Python
oauth2_scheme(some, parameters)
```
-因此,`Depends` 可以调用 `oauth2_scheme` 变量。
+因此,它可以与 `Depends` 一起使用。
-### 使用
+### 使用 { #use-it }
-接下来,使用 `Depends` 把 `oauth2_scheme` 传入依赖项。
+现在你可以通过 `Depends` 将 `oauth2_scheme` 作为依赖传入。
-{* ../../docs_src/security/tutorial001.py hl[10] *}
+{* ../../docs_src/security/tutorial001_an_py39.py hl[12] *}
-该依赖项使用字符串(`str`)接收*路径操作函数*的参数 `token` 。
+该依赖会提供一个 `str`,赋值给*路径操作函数*的参数 `token`。
-**FastAPI** 使用依赖项在 OpenAPI 概图(及 API 文档)中定义**安全方案**。
+**FastAPI** 会据此在 OpenAPI 架构(以及自动生成的 API 文档)中定义一个“安全方案”。
/// info | 技术细节
-**FastAPI** 使用(在依赖项中声明的)类 `OAuth2PasswordBearer` 在 OpenAPI 中定义安全方案,这是因为它继承自 `fastapi.security.oauth2.OAuth2`,而该类又是继承自`fastapi.security.base.SecurityBase`。
+**FastAPI** 之所以知道可以使用(在依赖中声明的)`OAuth2PasswordBearer` 在 OpenAPI 中定义安全方案,是因为它继承自 `fastapi.security.oauth2.OAuth2`,而后者又继承自 `fastapi.security.base.SecurityBase`。
-所有与 OpenAPI(及 API 文档)集成的安全工具都继承自 `SecurityBase`, 这就是为什么 **FastAPI** 能把它们集成至 OpenAPI 的原因。
+所有与 OpenAPI(以及自动 API 文档)集成的安全工具都继承自 `SecurityBase`,这就是 **FastAPI** 能将它们集成到 OpenAPI 的方式。
///
-## 实现的操作
+## 它做了什么 { #what-it-does }
-FastAPI 校验请求中的 `Authorization` 请求头,核对请求头的值是不是由 `Bearer ` + 令牌组成, 并返回令牌字符串(`str`)。
+它会在请求中查找 `Authorization` 请求头,检查其值是否为 `Bearer ` 加上一些令牌,并将该令牌作为 `str` 返回。
-如果没有找到 `Authorization` 请求头,或请求头的值不是 `Bearer ` + 令牌。FastAPI 直接返回 401 错误状态码(`UNAUTHORIZED`)。
+如果没有 `Authorization` 请求头,或者其值不包含 `Bearer ` 令牌,它会直接返回 401 状态码错误(`UNAUTHORIZED`)。
-开发者不需要检查错误信息,查看令牌是否存在,只要该函数能够执行,函数中就会包含令牌字符串。
+你甚至无需检查令牌是否存在即可返回错误;只要你的函数被执行,就可以确定会拿到一个 `str` 类型的令牌。
-正如下图所示,API 文档已经包含了这项功能:
+你已经可以在交互式文档中试试了:
 -目前,暂时还没有实现验证令牌是否有效的功能,不过后文很快就会介绍的。
+我们还没有验证令牌是否有效,但这已经是一个良好的开端。
-## 小结
+## 小结 { #recap }
-看到了吧,只要多写三四行代码,就可以添加基础的安全表单。
+只需增加三四行代码,你就已经拥有了一种初步的安全机制。
diff --git a/docs/zh/docs/tutorial/security/get-current-user.md b/docs/zh/docs/tutorial/security/get-current-user.md
index 1f254a1037..c14bba28af 100644
--- a/docs/zh/docs/tutorial/security/get-current-user.md
+++ b/docs/zh/docs/tutorial/security/get-current-user.md
@@ -1,23 +1,23 @@
-# 获取当前用户
+# 获取当前用户 { #get-current-user }
上一章中,(基于依赖注入系统的)安全系统向*路径操作函数*传递了 `str` 类型的 `token`:
-{* ../../docs_src/security/tutorial001.py hl[10] *}
+{* ../../docs_src/security/tutorial001_an_py39.py hl[12] *}
但这并不实用。
接下来,我们学习如何返回当前用户。
-## 创建用户模型
+## 创建用户模型 { #create-a-user-model }
首先,创建 Pydantic 用户模型。
与使用 Pydantic 声明请求体相同,并且可在任何位置使用:
-{* ../../docs_src/security/tutorial002.py hl[5,12:16] *}
+{* ../../docs_src/security/tutorial002_an_py310.py hl[5,12:6] *}
-## 创建 `get_current_user` 依赖项
+## 创建 `get_current_user` 依赖项 { #create-a-get-current-user-dependency }
创建 `get_current_user` 依赖项。
@@ -27,19 +27,19 @@
与之前直接在路径操作中的做法相同,新的 `get_current_user` 依赖项从子依赖项 `oauth2_scheme` 中接收 `str` 类型的 `token`:
-{* ../../docs_src/security/tutorial002.py hl[25] *}
+{* ../../docs_src/security/tutorial002_an_py310.py hl[25] *}
-## 获取用户
+## 获取用户 { #get-the-user }
`get_current_user` 使用创建的(伪)工具函数,该函数接收 `str` 类型的令牌,并返回 Pydantic 的 `User` 模型:
-{* ../../docs_src/security/tutorial002.py hl[19:22,26:27] *}
+{* ../../docs_src/security/tutorial002_an_py310.py hl[19:22,26:27] *}
-## 注入当前用户
+## 注入当前用户 { #inject-the-current-user }
在*路径操作* 的 `Depends` 中使用 `get_current_user`:
-{* ../../docs_src/security/tutorial002.py hl[31] *}
+{* ../../docs_src/security/tutorial002_an_py310.py hl[31] *}
注意,此处把 `current_user` 的类型声明为 Pydantic 的 `User` 模型。
@@ -61,7 +61,7 @@
///
-## 其它模型
+## 其它模型 { #other-models }
接下来,直接在*路径操作函数*中获取当前用户,并用 `Depends` 在**依赖注入**系统中处理安全机制。
@@ -78,7 +78,7 @@
尽管使用应用所需的任何模型、类、数据库。**FastAPI** 通过依赖注入系统都能帮您搞定。
-## 代码大小
+## 代码大小 { #code-size }
这个示例看起来有些冗长。毕竟这个文件同时包含了安全、数据模型的工具函数,以及路径操作等代码。
@@ -94,9 +94,9 @@
所有*路径操作*只需 3 行代码就可以了:
-{* ../../docs_src/security/tutorial002.py hl[30:32] *}
+{* ../../docs_src/security/tutorial002_an_py310.py hl[30:32] *}
-## 小结
+## 小结 { #recap }
现在,我们可以直接在*路径操作函数*中获取当前用户。
diff --git a/docs/zh/docs/tutorial/security/index.md b/docs/zh/docs/tutorial/security/index.md
index 1484b99fd8..589f93c3e9 100644
--- a/docs/zh/docs/tutorial/security/index.md
+++ b/docs/zh/docs/tutorial/security/index.md
@@ -1,4 +1,4 @@
-# 安全性
+# 安全性 { #security }
有许多方法可以处理安全性、身份认证和授权等问题。
@@ -10,11 +10,11 @@
但首先,让我们来看一些小的概念。
-## 没有时间?
+## 没有时间? { #in-a-hurry }
-如果你不关心这些术语,而只需要*立即*通过基于用户名和密码的身份认证来增加安全性,请跳转到下一章。
+如果你不关心这些术语,而只需要*立即*通过基于用户名和密码的身份认证来增加安全性,请跳转到接下来的章节。
-## OAuth2
+## OAuth2 { #oauth2 }
OAuth2是一个规范,它定义了几种处理身份认证和授权的方法。
@@ -24,7 +24,7 @@ OAuth2是一个规范,它定义了几种处理身份认证和授权的方法
这就是所有带有「使用 Facebook,Google,X (Twitter),GitHub 登录」的系统背后所使用的机制。
-### OAuth 1
+### OAuth 1 { #oauth-1 }
有一个 OAuth 1,它与 OAuth2 完全不同,并且更为复杂,因为它直接包含了有关如何加密通信的规范。
@@ -32,13 +32,13 @@ OAuth2是一个规范,它定义了几种处理身份认证和授权的方法
OAuth2 没有指定如何加密通信,它期望你为应用程序使用 HTTPS 进行通信。
-/// tip
+/// tip | 提示
在有关**部署**的章节中,你将了解如何使用 Traefik 和 Let's Encrypt 免费设置 HTTPS。
///
-## OpenID Connect
+## OpenID Connect { #openid-connect }
OpenID Connect 是另一个基于 **OAuth2** 的规范。
@@ -48,7 +48,7 @@ OpenID Connect 是另一个基于 **OAuth2** 的规范。
但是 Facebook 登录不支持 OpenID Connect。它具有自己的 OAuth2 风格。
-### OpenID(非「OpenID Connect」)
+### OpenID(非「OpenID Connect」) { #openid-not-openid-connect }
还有一个「OpenID」规范。它试图解决与 **OpenID Connect** 相同的问题,但它不是基于 OAuth2。
@@ -56,7 +56,7 @@ OpenID Connect 是另一个基于 **OAuth2** 的规范。
如今它已经不是很流行,没有被广泛使用了。
-## OpenAPI
+## OpenAPI { #openapi }
OpenAPI(以前称为 Swagger)是用于构建 API 的开放规范(现已成为 Linux Foundation 的一部分)。
@@ -75,7 +75,7 @@ OpenAPI 定义了以下安全方案:
* 请求头。
* cookie。
* `http`:标准的 HTTP 身份认证系统,包括:
- * `bearer`: 一个值为 `Bearer` 加令牌字符串的 `Authorization` 请求头。这是从 OAuth2 继承的。
+ * `bearer`: 一个值为 `Bearer ` 加令牌字符串的 `Authorization` 请求头。这是从 OAuth2 继承的。
* HTTP Basic 认证方式。
* HTTP Digest,等等。
* `oauth2`:所有的 OAuth2 处理安全性的方式(称为「流程」)。
@@ -89,7 +89,7 @@ OpenAPI 定义了以下安全方案:
* 此自动发现机制是 OpenID Connect 规范中定义的内容。
-/// tip
+/// tip | 提示
集成其他身份认证/授权提供者(例如Google,Facebook,X (Twitter),GitHub等)也是可能的,而且较为容易。
@@ -97,10 +97,10 @@ OpenAPI 定义了以下安全方案:
///
-## **FastAPI** 实用工具
+## **FastAPI** 实用工具 { #fastapi-utilities }
FastAPI 在 `fastapi.security` 模块中为每个安全方案提供了几种工具,这些工具简化了这些安全机制的使用方法。
-在下一章中,你将看到如何使用 **FastAPI** 所提供的这些工具为你的 API 增加安全性。
+在接下来的章节中,你将看到如何使用 **FastAPI** 所提供的这些工具为你的 API 增加安全性。
而且你还将看到它如何自动地被集成到交互式文档系统中。
diff --git a/docs/zh/docs/tutorial/security/oauth2-jwt.md b/docs/zh/docs/tutorial/security/oauth2-jwt.md
index 7d338419b5..c7eb9bd907 100644
--- a/docs/zh/docs/tutorial/security/oauth2-jwt.md
+++ b/docs/zh/docs/tutorial/security/oauth2-jwt.md
@@ -1,34 +1,36 @@
-# OAuth2 实现密码哈希与 Bearer JWT 令牌验证
+# 使用密码(及哈希)的 OAuth2,基于 JWT 的 Bearer 令牌 { #oauth2-with-password-and-hashing-bearer-with-jwt-tokens }
-至此,我们已经编写了所有安全流,本章学习如何使用 JWT 令牌(Token)和安全密码哈希(Hash)实现真正的安全机制。
+现在我们已经有了完整的安全流程,接下来用 JWT 令牌和安全的密码哈希,让应用真正安全起来。
-本章的示例代码真正实现了在应用的数据库中保存哈希密码等功能。
+这些代码可以直接用于你的应用,你可以把密码哈希保存到数据库中,等等。
-接下来,我们紧接上一章,继续完善安全机制。
+我们将从上一章结束的地方继续,逐步完善。
-## JWT 简介
+## 关于 JWT { #about-jwt }
-JWT 即**JSON 网络令牌**(JSON Web Tokens)。
+JWT 意为 “JSON Web Tokens”。
-JWT 是一种将 JSON 对象编码为没有空格,且难以理解的长字符串的标准。JWT 的内容如下所示:
+它是一种标准,把一个 JSON 对象编码成没有空格、很密集的一长串字符串。看起来像这样:
```
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
```
-JWT 字符串没有加密,任何人都能用它恢复原始信息。
+它不是加密的,所以任何人都可以从内容中恢复信息。
-但 JWT 使用了签名机制。接受令牌时,可以用签名校验令牌。
+但它是“签名”的。因此,当你收到一个自己签发的令牌时,你可以验证它确实是你签发的。
-使用 JWT 创建有效期为一周的令牌。第二天,用户持令牌再次访问时,仍为登录状态。
+这样你就可以创建一个例如有效期为 1 周的令牌。然后当用户第二天带着这个令牌回来时,你能知道该用户仍然处于登录状态。
-令牌于一周后过期,届时,用户身份验证就会失败。只有再次登录,才能获得新的令牌。如果用户(或第三方)篡改令牌的过期时间,因为签名不匹配会导致身份验证失败。
+一周后令牌过期,用户将不再被授权,需要重新登录以获取新令牌。而如果用户(或第三方)尝试修改令牌来更改过期时间,你也能发现,因为签名将不匹配。
-如需深入了解 JWT 令牌,了解它的工作方式,请参阅 https://jwt.io。
+如果你想动手体验 JWT 令牌并了解它的工作方式,请访问 https://jwt.io。
-## 安装 `PyJWT`
+## 安装 `PyJWT` { #install-pyjwt }
-安装 `PyJWT`,在 Python 中生成和校验 JWT 令牌:
+我们需要安装 `PyJWT`,以便在 Python 中生成和校验 JWT 令牌。
+
+请确保创建并激活一个[虚拟环境](../../virtual-environments.md){.internal-link target=_blank},然后安装 `pyjwt`:
-目前,暂时还没有实现验证令牌是否有效的功能,不过后文很快就会介绍的。
+我们还没有验证令牌是否有效,但这已经是一个良好的开端。
-## 小结
+## 小结 { #recap }
-看到了吧,只要多写三四行代码,就可以添加基础的安全表单。
+只需增加三四行代码,你就已经拥有了一种初步的安全机制。
diff --git a/docs/zh/docs/tutorial/security/get-current-user.md b/docs/zh/docs/tutorial/security/get-current-user.md
index 1f254a1037..c14bba28af 100644
--- a/docs/zh/docs/tutorial/security/get-current-user.md
+++ b/docs/zh/docs/tutorial/security/get-current-user.md
@@ -1,23 +1,23 @@
-# 获取当前用户
+# 获取当前用户 { #get-current-user }
上一章中,(基于依赖注入系统的)安全系统向*路径操作函数*传递了 `str` 类型的 `token`:
-{* ../../docs_src/security/tutorial001.py hl[10] *}
+{* ../../docs_src/security/tutorial001_an_py39.py hl[12] *}
但这并不实用。
接下来,我们学习如何返回当前用户。
-## 创建用户模型
+## 创建用户模型 { #create-a-user-model }
首先,创建 Pydantic 用户模型。
与使用 Pydantic 声明请求体相同,并且可在任何位置使用:
-{* ../../docs_src/security/tutorial002.py hl[5,12:16] *}
+{* ../../docs_src/security/tutorial002_an_py310.py hl[5,12:6] *}
-## 创建 `get_current_user` 依赖项
+## 创建 `get_current_user` 依赖项 { #create-a-get-current-user-dependency }
创建 `get_current_user` 依赖项。
@@ -27,19 +27,19 @@
与之前直接在路径操作中的做法相同,新的 `get_current_user` 依赖项从子依赖项 `oauth2_scheme` 中接收 `str` 类型的 `token`:
-{* ../../docs_src/security/tutorial002.py hl[25] *}
+{* ../../docs_src/security/tutorial002_an_py310.py hl[25] *}
-## 获取用户
+## 获取用户 { #get-the-user }
`get_current_user` 使用创建的(伪)工具函数,该函数接收 `str` 类型的令牌,并返回 Pydantic 的 `User` 模型:
-{* ../../docs_src/security/tutorial002.py hl[19:22,26:27] *}
+{* ../../docs_src/security/tutorial002_an_py310.py hl[19:22,26:27] *}
-## 注入当前用户
+## 注入当前用户 { #inject-the-current-user }
在*路径操作* 的 `Depends` 中使用 `get_current_user`:
-{* ../../docs_src/security/tutorial002.py hl[31] *}
+{* ../../docs_src/security/tutorial002_an_py310.py hl[31] *}
注意,此处把 `current_user` 的类型声明为 Pydantic 的 `User` 模型。
@@ -61,7 +61,7 @@
///
-## 其它模型
+## 其它模型 { #other-models }
接下来,直接在*路径操作函数*中获取当前用户,并用 `Depends` 在**依赖注入**系统中处理安全机制。
@@ -78,7 +78,7 @@
尽管使用应用所需的任何模型、类、数据库。**FastAPI** 通过依赖注入系统都能帮您搞定。
-## 代码大小
+## 代码大小 { #code-size }
这个示例看起来有些冗长。毕竟这个文件同时包含了安全、数据模型的工具函数,以及路径操作等代码。
@@ -94,9 +94,9 @@
所有*路径操作*只需 3 行代码就可以了:
-{* ../../docs_src/security/tutorial002.py hl[30:32] *}
+{* ../../docs_src/security/tutorial002_an_py310.py hl[30:32] *}
-## 小结
+## 小结 { #recap }
现在,我们可以直接在*路径操作函数*中获取当前用户。
diff --git a/docs/zh/docs/tutorial/security/index.md b/docs/zh/docs/tutorial/security/index.md
index 1484b99fd8..589f93c3e9 100644
--- a/docs/zh/docs/tutorial/security/index.md
+++ b/docs/zh/docs/tutorial/security/index.md
@@ -1,4 +1,4 @@
-# 安全性
+# 安全性 { #security }
有许多方法可以处理安全性、身份认证和授权等问题。
@@ -10,11 +10,11 @@
但首先,让我们来看一些小的概念。
-## 没有时间?
+## 没有时间? { #in-a-hurry }
-如果你不关心这些术语,而只需要*立即*通过基于用户名和密码的身份认证来增加安全性,请跳转到下一章。
+如果你不关心这些术语,而只需要*立即*通过基于用户名和密码的身份认证来增加安全性,请跳转到接下来的章节。
-## OAuth2
+## OAuth2 { #oauth2 }
OAuth2是一个规范,它定义了几种处理身份认证和授权的方法。
@@ -24,7 +24,7 @@ OAuth2是一个规范,它定义了几种处理身份认证和授权的方法
这就是所有带有「使用 Facebook,Google,X (Twitter),GitHub 登录」的系统背后所使用的机制。
-### OAuth 1
+### OAuth 1 { #oauth-1 }
有一个 OAuth 1,它与 OAuth2 完全不同,并且更为复杂,因为它直接包含了有关如何加密通信的规范。
@@ -32,13 +32,13 @@ OAuth2是一个规范,它定义了几种处理身份认证和授权的方法
OAuth2 没有指定如何加密通信,它期望你为应用程序使用 HTTPS 进行通信。
-/// tip
+/// tip | 提示
在有关**部署**的章节中,你将了解如何使用 Traefik 和 Let's Encrypt 免费设置 HTTPS。
///
-## OpenID Connect
+## OpenID Connect { #openid-connect }
OpenID Connect 是另一个基于 **OAuth2** 的规范。
@@ -48,7 +48,7 @@ OpenID Connect 是另一个基于 **OAuth2** 的规范。
但是 Facebook 登录不支持 OpenID Connect。它具有自己的 OAuth2 风格。
-### OpenID(非「OpenID Connect」)
+### OpenID(非「OpenID Connect」) { #openid-not-openid-connect }
还有一个「OpenID」规范。它试图解决与 **OpenID Connect** 相同的问题,但它不是基于 OAuth2。
@@ -56,7 +56,7 @@ OpenID Connect 是另一个基于 **OAuth2** 的规范。
如今它已经不是很流行,没有被广泛使用了。
-## OpenAPI
+## OpenAPI { #openapi }
OpenAPI(以前称为 Swagger)是用于构建 API 的开放规范(现已成为 Linux Foundation 的一部分)。
@@ -75,7 +75,7 @@ OpenAPI 定义了以下安全方案:
* 请求头。
* cookie。
* `http`:标准的 HTTP 身份认证系统,包括:
- * `bearer`: 一个值为 `Bearer` 加令牌字符串的 `Authorization` 请求头。这是从 OAuth2 继承的。
+ * `bearer`: 一个值为 `Bearer ` 加令牌字符串的 `Authorization` 请求头。这是从 OAuth2 继承的。
* HTTP Basic 认证方式。
* HTTP Digest,等等。
* `oauth2`:所有的 OAuth2 处理安全性的方式(称为「流程」)。
@@ -89,7 +89,7 @@ OpenAPI 定义了以下安全方案:
* 此自动发现机制是 OpenID Connect 规范中定义的内容。
-/// tip
+/// tip | 提示
集成其他身份认证/授权提供者(例如Google,Facebook,X (Twitter),GitHub等)也是可能的,而且较为容易。
@@ -97,10 +97,10 @@ OpenAPI 定义了以下安全方案:
///
-## **FastAPI** 实用工具
+## **FastAPI** 实用工具 { #fastapi-utilities }
FastAPI 在 `fastapi.security` 模块中为每个安全方案提供了几种工具,这些工具简化了这些安全机制的使用方法。
-在下一章中,你将看到如何使用 **FastAPI** 所提供的这些工具为你的 API 增加安全性。
+在接下来的章节中,你将看到如何使用 **FastAPI** 所提供的这些工具为你的 API 增加安全性。
而且你还将看到它如何自动地被集成到交互式文档系统中。
diff --git a/docs/zh/docs/tutorial/security/oauth2-jwt.md b/docs/zh/docs/tutorial/security/oauth2-jwt.md
index 7d338419b5..c7eb9bd907 100644
--- a/docs/zh/docs/tutorial/security/oauth2-jwt.md
+++ b/docs/zh/docs/tutorial/security/oauth2-jwt.md
@@ -1,34 +1,36 @@
-# OAuth2 实现密码哈希与 Bearer JWT 令牌验证
+# 使用密码(及哈希)的 OAuth2,基于 JWT 的 Bearer 令牌 { #oauth2-with-password-and-hashing-bearer-with-jwt-tokens }
-至此,我们已经编写了所有安全流,本章学习如何使用 JWT 令牌(Token)和安全密码哈希(Hash)实现真正的安全机制。
+现在我们已经有了完整的安全流程,接下来用 JWT 令牌和安全的密码哈希,让应用真正安全起来。
-本章的示例代码真正实现了在应用的数据库中保存哈希密码等功能。
+这些代码可以直接用于你的应用,你可以把密码哈希保存到数据库中,等等。
-接下来,我们紧接上一章,继续完善安全机制。
+我们将从上一章结束的地方继续,逐步完善。
-## JWT 简介
+## 关于 JWT { #about-jwt }
-JWT 即**JSON 网络令牌**(JSON Web Tokens)。
+JWT 意为 “JSON Web Tokens”。
-JWT 是一种将 JSON 对象编码为没有空格,且难以理解的长字符串的标准。JWT 的内容如下所示:
+它是一种标准,把一个 JSON 对象编码成没有空格、很密集的一长串字符串。看起来像这样:
```
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
```
-JWT 字符串没有加密,任何人都能用它恢复原始信息。
+它不是加密的,所以任何人都可以从内容中恢复信息。
-但 JWT 使用了签名机制。接受令牌时,可以用签名校验令牌。
+但它是“签名”的。因此,当你收到一个自己签发的令牌时,你可以验证它确实是你签发的。
-使用 JWT 创建有效期为一周的令牌。第二天,用户持令牌再次访问时,仍为登录状态。
+这样你就可以创建一个例如有效期为 1 周的令牌。然后当用户第二天带着这个令牌回来时,你能知道该用户仍然处于登录状态。
-令牌于一周后过期,届时,用户身份验证就会失败。只有再次登录,才能获得新的令牌。如果用户(或第三方)篡改令牌的过期时间,因为签名不匹配会导致身份验证失败。
+一周后令牌过期,用户将不再被授权,需要重新登录以获取新令牌。而如果用户(或第三方)尝试修改令牌来更改过期时间,你也能发现,因为签名将不匹配。
-如需深入了解 JWT 令牌,了解它的工作方式,请参阅 https://jwt.io。
+如果你想动手体验 JWT 令牌并了解它的工作方式,请访问 https://jwt.io。
-## 安装 `PyJWT`
+## 安装 `PyJWT` { #install-pyjwt }
-安装 `PyJWT`,在 Python 中生成和校验 JWT 令牌:
+我们需要安装 `PyJWT`,以便在 Python 中生成和校验 JWT 令牌。
+
+请确保创建并激活一个[虚拟环境](../../virtual-environments.md){.internal-link target=_blank},然后安装 `pyjwt`:
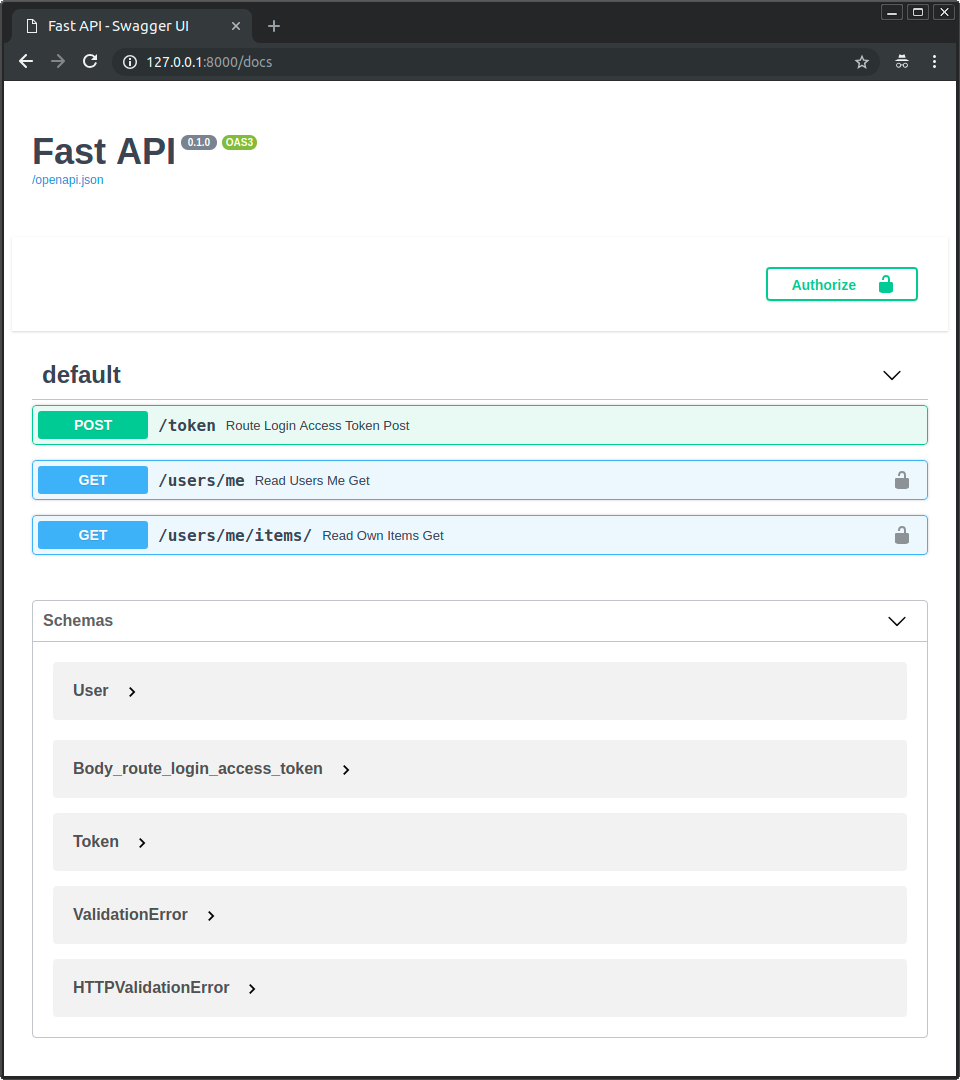 +
+ -用与上一章同样的方式实现应用授权。
+像之前一样进行授权。
-使用如下凭证:
+使用以下凭证:
-用户名: `johndoe` 密码: `secret`
+用户名: `johndoe`
+密码: `secret`
/// check | 检查
-注意,代码中没有明文密码**`secret`**,只保存了它的哈希值。
+注意,代码中的任何地方都没有明文密码 “`secret`”,我们只有它的哈希版本。
///
-
-用与上一章同样的方式实现应用授权。
+像之前一样进行授权。
-使用如下凭证:
+使用以下凭证:
-用户名: `johndoe` 密码: `secret`
+用户名: `johndoe`
+密码: `secret`
/// check | 检查
-注意,代码中没有明文密码**`secret`**,只保存了它的哈希值。
+注意,代码中的任何地方都没有明文密码 “`secret`”,我们只有它的哈希版本。
///
-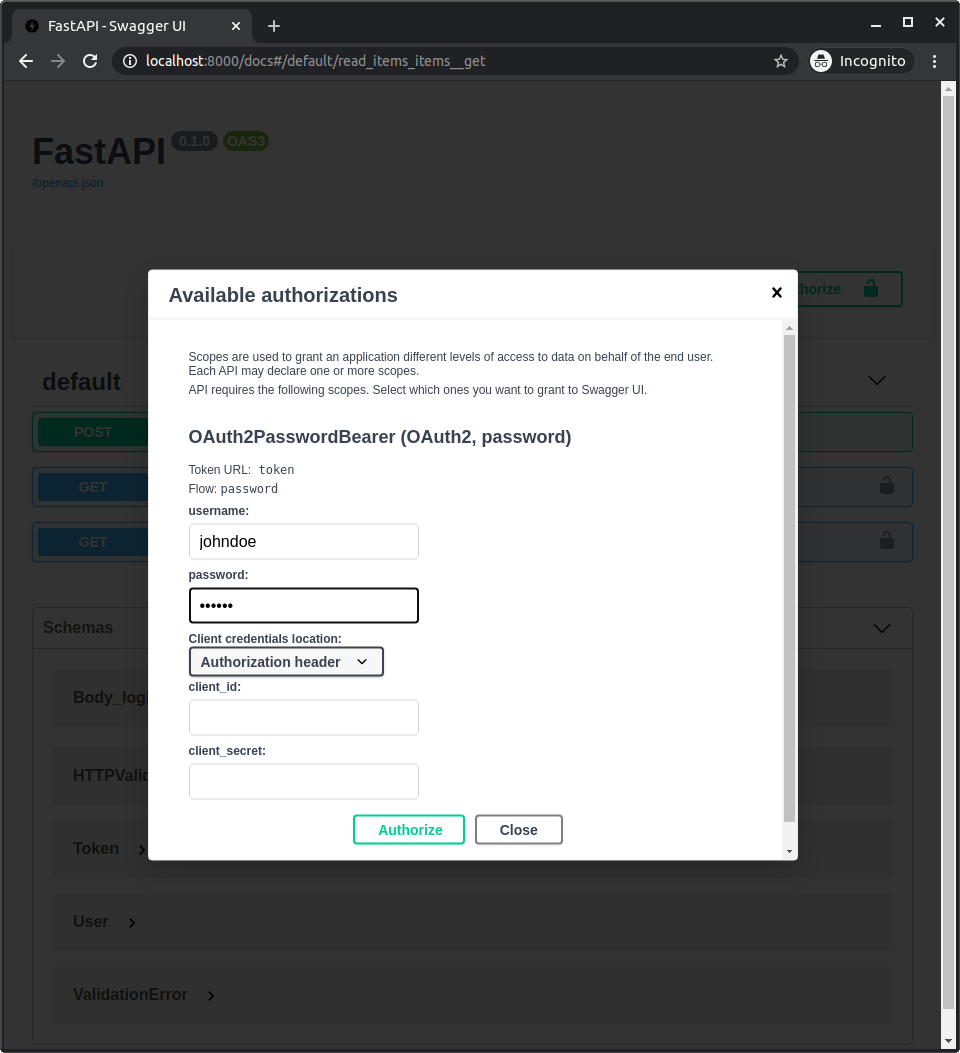 +
+ -调用 `/users/me/` 端点,收到下面的响应:
+调用 `/users/me/` 端点,你将得到如下响应:
```JSON
{
@@ -225,46 +228,46 @@ JWT 规范还包括 `sub` 键,值是令牌的主题。
}
```
-
-调用 `/users/me/` 端点,收到下面的响应:
+调用 `/users/me/` 端点,你将得到如下响应:
```JSON
{
@@ -225,46 +228,46 @@ JWT 规范还包括 `sub` 键,值是令牌的主题。
}
```
-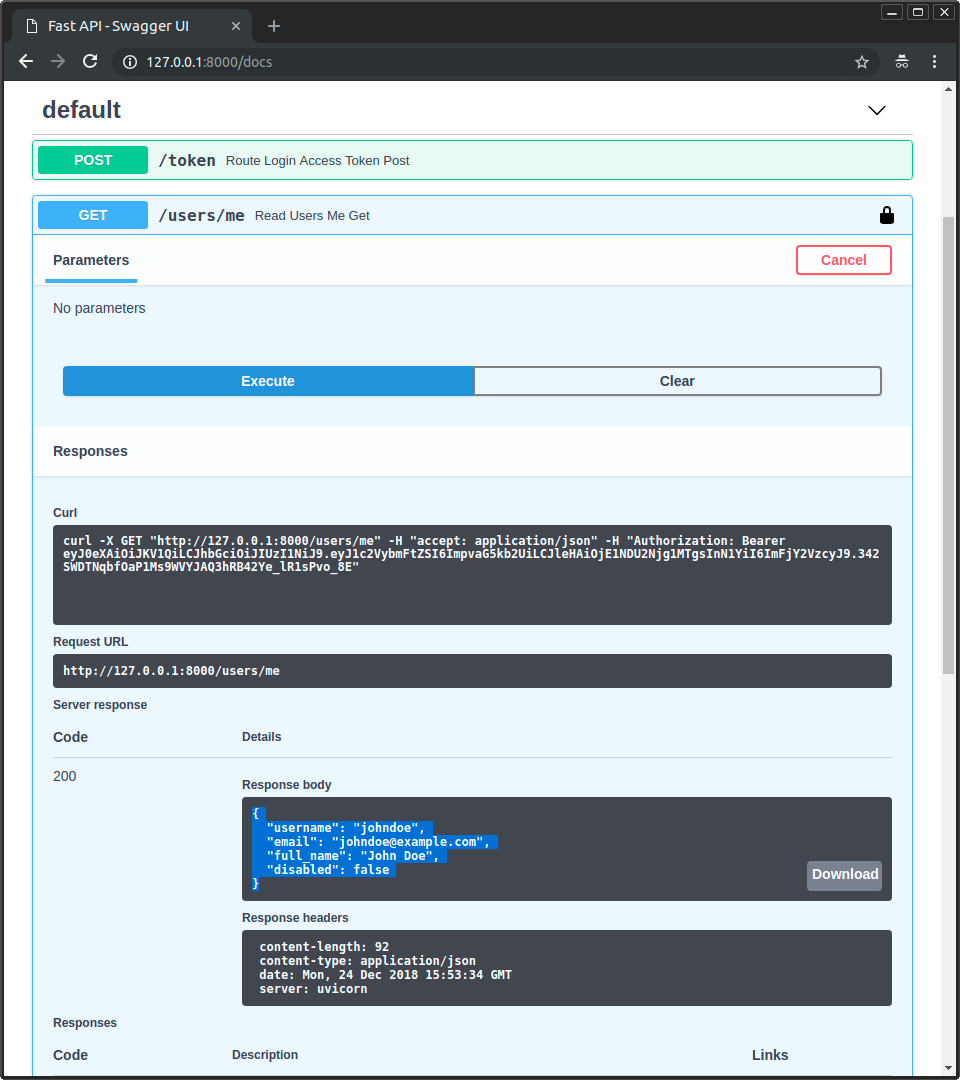 +
+ -打开浏览器的开发者工具,查看数据是怎么发送的,而且数据里只包含了令牌,只有验证用户的第一个请求才发送密码,并获取访问令牌,但之后不会再发送密码:
+如果你打开开发者工具,你会看到发送的数据只包含令牌。密码只会在第一个请求中用于认证用户并获取访问令牌,之后就不会再发送密码了:
-
-打开浏览器的开发者工具,查看数据是怎么发送的,而且数据里只包含了令牌,只有验证用户的第一个请求才发送密码,并获取访问令牌,但之后不会再发送密码:
+如果你打开开发者工具,你会看到发送的数据只包含令牌。密码只会在第一个请求中用于认证用户并获取访问令牌,之后就不会再发送密码了:
-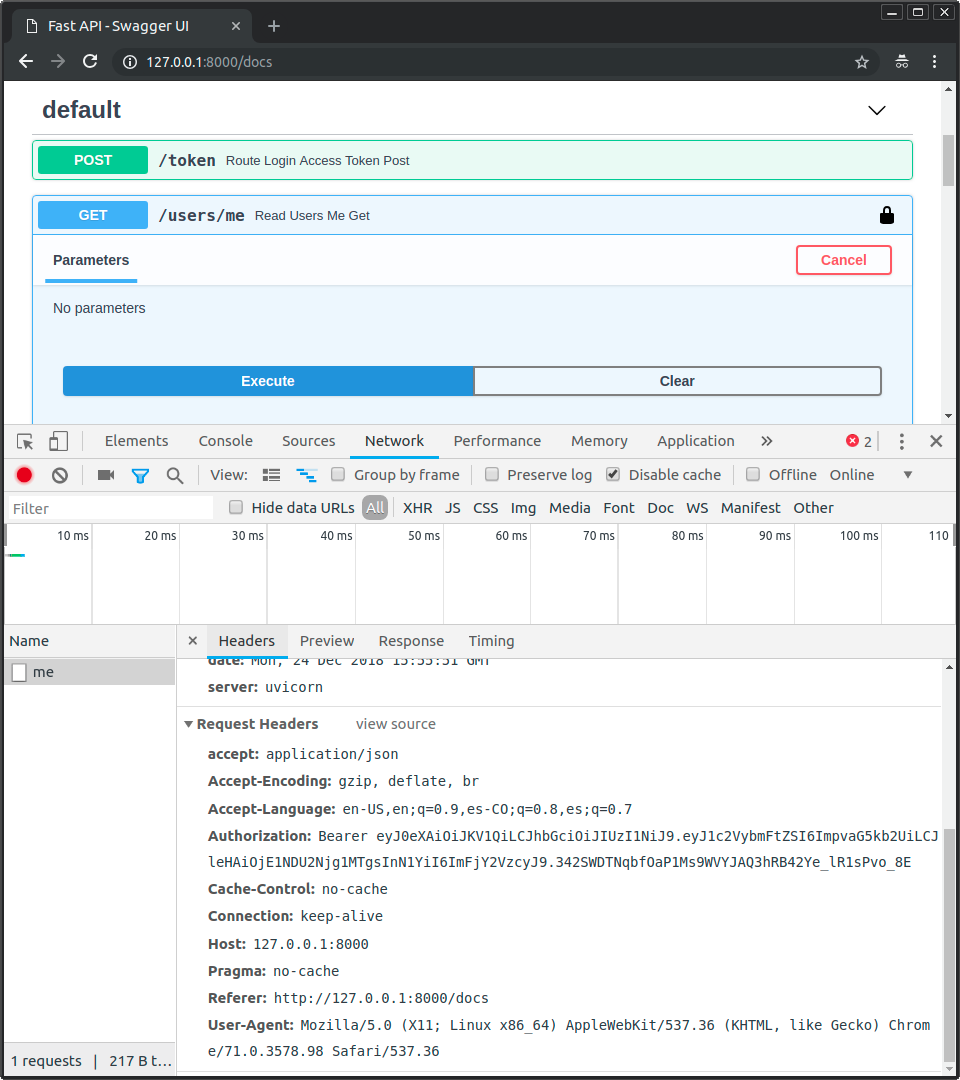 +
+ -/// note | 笔记
+/// note | 注意
-注意,请求中 `Authorization` 响应头的值以 `Bearer` 开头。
+注意 `Authorization` 请求头,其值以 `Bearer ` 开头。
///
-## `scopes` 高级用法
+## 使用 `scopes` 的高级用法 { #advanced-usage-with-scopes }
-OAuth2 支持**`scopes`**(作用域)。
+OAuth2 支持 “scopes”(作用域)。
-**`scopes`**为 JWT 令牌添加指定权限。
+你可以用它们为 JWT 令牌添加一组特定的权限。
-让持有令牌的用户或第三方在指定限制条件下与 API 交互。
+然后你可以把这个令牌直接交给用户或第三方,在一组限制条件下与 API 交互。
-**高级用户指南**中将介绍如何使用 `scopes`,及如何把 `scopes` 集成至 **FastAPI**。
+在**高级用户指南**中你将学习如何使用它们,以及它们如何集成进 **FastAPI**。
-## 小结
+## 小结 { #recap }
-至此,您可以使用 OAuth2 和 JWT 等标准配置安全的 **FastAPI** 应用。
+通过目前所学内容,你可以使用 OAuth2 和 JWT 等标准来搭建一个安全的 **FastAPI** 应用。
-几乎在所有框架中,处理安全问题很快都会变得非常复杂。
+在几乎任何框架中,处理安全问题都会很快变得相当复杂。
-有些包为了简化安全流,不得不在数据模型、数据库和功能上做出妥协。而有些过于简化的软件包其实存在了安全隐患。
+许多把安全流程大幅简化的包,往往要在数据模型、数据库和可用特性上做出大量妥协。而有些过度简化的包实际上在底层存在安全隐患。
---
-**FastAPI** 不向任何数据库、数据模型或工具做妥协。
+**FastAPI** 不会在任何数据库、数据模型或工具上做妥协。
-开发者可以灵活选择最适合项目的安全机制。
+它给予你完全的灵活性,选择最适合你项目的方案。
-还可以直接使用 `passlib` 和 `PyJWT` 等维护良好、使用广泛的包,这是因为 **FastAPI** 不需要任何复杂机制,就能集成外部的包。
+而且你可以直接使用许多维护良好、广泛使用的包,比如 `pwdlib` 和 `PyJWT`,因为 **FastAPI** 不需要复杂机制来集成外部包。
-而且,**FastAPI** 还提供了一些工具,在不影响灵活、稳定和安全的前提下,尽可能地简化安全机制。
+同时它也为你提供尽可能简化流程的工具,而不牺牲灵活性、健壮性或安全性。
-**FastAPI** 还支持以相对简单的方式,使用 OAuth2 等安全、标准的协议。
+你可以以相对简单的方式使用和实现像 OAuth2 这样的安全、标准协议。
-**高级用户指南**中详细介绍了 OAuth2**`scopes`**的内容,遵循同样的标准,实现更精密的权限系统。OAuth2 的作用域是脸书、谷歌、GitHub、微软、推特等第三方身份验证应用使用的机制,让用户授权第三方应用与 API 交互。
+在**高级用户指南**中,你可以进一步了解如何使用 OAuth2 的 “scopes”,以遵循相同标准实现更细粒度的权限系统。带作用域的 OAuth2 是许多大型身份认证提供商(如 Facebook、Google、GitHub、Microsoft、X(Twitter)等)用来授权第三方应用代表其用户与其 API 交互的机制。
diff --git a/docs/zh/docs/tutorial/security/simple-oauth2.md b/docs/zh/docs/tutorial/security/simple-oauth2.md
index f70678df8f..3037a983b3 100644
--- a/docs/zh/docs/tutorial/security/simple-oauth2.md
+++ b/docs/zh/docs/tutorial/security/simple-oauth2.md
@@ -1,8 +1,8 @@
-# OAuth2 实现简单的 Password 和 Bearer 验证
+# OAuth2 实现简单的 Password 和 Bearer 验证 { #simple-oauth2-with-password-and-bearer }
本章添加上一章示例中欠缺的部分,实现完整的安全流。
-## 获取 `username` 和 `password`
+## 获取 `username` 和 `password` { #get-the-username-and-password }
首先,使用 **FastAPI** 安全工具获取 `username` 和 `password`。
@@ -18,7 +18,7 @@ OAuth2 规范要求使用**密码流**时,客户端或用户必须以表单数
该规范要求必须以表单数据形式发送 `username` 和 `password`,因此,不能使用 JSON 对象。
-### `Scope`(作用域)
+### `scope` { #scope }
OAuth2 还支持客户端发送**`scope`**表单字段。
@@ -32,7 +32,7 @@ OAuth2 还支持客户端发送**`scope`**表单字段。
* 脸书和 Instagram 使用 `instagram_basic`
* 谷歌使用 `https://www.googleapis.com/auth/drive`
-/// info | 说明
+/// info | 信息
OAuth2 中,**作用域**只是声明指定权限的字符串。
@@ -44,15 +44,15 @@ OAuth2 中,**作用域**只是声明指定权限的字符串。
///
-## 获取 `username` 和 `password` 的代码
+## 获取 `username` 和 `password` 的代码 { #code-to-get-the-username-and-password }
接下来,使用 **FastAPI** 工具获取用户名与密码。
-### `OAuth2PasswordRequestForm`
+### `OAuth2PasswordRequestForm` { #oauth2passwordrequestform }
首先,导入 `OAuth2PasswordRequestForm`,然后,在 `/token` *路径操作* 中,用 `Depends` 把该类作为依赖项。
-{* ../../docs_src/security/tutorial003.py hl[4,76] *}
+{* ../../docs_src/security/tutorial003_an_py310.py hl[4,78] *}
`OAuth2PasswordRequestForm` 是用以下几项内容声明表单请求体的类依赖项:
@@ -72,7 +72,7 @@ OAuth2 中,**作用域**只是声明指定权限的字符串。
* 可选的 `client_id`(本例未使用)
* 可选的 `client_secret`(本例未使用)
-/// info | 说明
+/// info | 信息
`OAuth2PasswordRequestForm` 与 `OAuth2PasswordBearer` 一样,都不是 FastAPI 的特殊类。
@@ -84,7 +84,7 @@ OAuth2 中,**作用域**只是声明指定权限的字符串。
///
-### 使用表单数据
+### 使用表单数据 { #use-the-form-data }
/// tip | 提示
@@ -100,9 +100,9 @@ OAuth2 中,**作用域**只是声明指定权限的字符串。
本例使用 `HTTPException` 异常显示此错误:
-{* ../../docs_src/security/tutorial003.py hl[3,77:79] *}
+{* ../../docs_src/security/tutorial003_an_py310.py hl[3,79:81] *}
-### 校验密码
+### 校验密码 { #check-the-password }
至此,我们已经从数据库中获取了用户数据,但尚未校验密码。
@@ -112,7 +112,7 @@ OAuth2 中,**作用域**只是声明指定权限的字符串。
如果密码不匹配,则返回与上面相同的错误。
-#### 密码哈希
+#### 密码哈希 { #password-hashing }
**哈希**是指,将指定内容(本例中为密码)转换为形似乱码的字节序列(其实就是字符串)。
@@ -120,15 +120,15 @@ OAuth2 中,**作用域**只是声明指定权限的字符串。
但这个乱码无法转换回传入的密码。
-##### 为什么使用密码哈希
+##### 为什么使用密码哈希 { #why-use-password-hashing }
原因很简单,假如数据库被盗,窃贼无法获取用户的明文密码,得到的只是哈希值。
这样一来,窃贼就无法在其它应用中使用窃取的密码,要知道,很多用户在所有系统中都使用相同的密码,风险超大。
-{* ../../docs_src/security/tutorial003.py hl[80:83] *}
+{* ../../docs_src/security/tutorial003_an_py310.py hl[82:85] *}
-#### 关于 `**user_dict`
+#### 关于 `**user_dict` { #about-user-dict }
`UserInDB(**user_dict)` 是指:
@@ -144,13 +144,13 @@ UserInDB(
)
```
-/// info | 说明
+/// info | 信息
-`user_dict` 的说明,详见[**更多模型**一章](../extra-models.md#user_indict){.internal-link target=_blank}。
+`user_dict` 的说明,详见[**更多模型**一章](../extra-models.md#about-user-in-dict){.internal-link target=_blank}。
///
-## 返回 Token
+## 返回 Token { #return-the-token }
`token` 端点的响应必须是 JSON 对象。
@@ -162,13 +162,13 @@ UserInDB(
/// tip | 提示
-下一章介绍使用哈希密码和 JWT Token 的真正安全机制。
+下一章介绍使用哈希密码和 JWT Token 的真正安全机制。
但现在,仅关注所需的特定细节。
///
-{* ../../docs_src/security/tutorial003.py hl[85] *}
+{* ../../docs_src/security/tutorial003_an_py310.py hl[87] *}
/// tip | 提示
@@ -182,7 +182,7 @@ UserInDB(
///
-## 更新依赖项
+## 更新依赖项 { #update-the-dependencies }
接下来,更新依赖项。
@@ -194,9 +194,9 @@ UserInDB(
因此,在端点中,只有当用户存在、通过身份验证、且状态为激活时,才能获得该用户:
-{* ../../docs_src/security/tutorial003.py hl[58:67,69:72,90] *}
+{* ../../docs_src/security/tutorial003_an_py310.py hl[58:66,69:74,94] *}
-/// info | 说明
+/// info | 信息
此处返回值为 `Bearer` 的响应头 `WWW-Authenticate` 也是规范的一部分。
@@ -210,15 +210,15 @@ UserInDB(
说不定什么时候,就有工具用得上它,而且,开发者或用户也可能用得上。
-这就是遵循标准的好处……
+这就是遵循标准的好处...
///
-## 实际效果
+## 实际效果 { #see-it-in-action }
打开 API 文档:http://127.0.0.1:8000/docs。
-### 身份验证
+### 身份验证 { #authenticate }
点击**Authorize**按钮。
@@ -228,13 +228,13 @@ UserInDB(
密码:`secret`
-
-/// note | 笔记
+/// note | 注意
-注意,请求中 `Authorization` 响应头的值以 `Bearer` 开头。
+注意 `Authorization` 请求头,其值以 `Bearer ` 开头。
///
-## `scopes` 高级用法
+## 使用 `scopes` 的高级用法 { #advanced-usage-with-scopes }
-OAuth2 支持**`scopes`**(作用域)。
+OAuth2 支持 “scopes”(作用域)。
-**`scopes`**为 JWT 令牌添加指定权限。
+你可以用它们为 JWT 令牌添加一组特定的权限。
-让持有令牌的用户或第三方在指定限制条件下与 API 交互。
+然后你可以把这个令牌直接交给用户或第三方,在一组限制条件下与 API 交互。
-**高级用户指南**中将介绍如何使用 `scopes`,及如何把 `scopes` 集成至 **FastAPI**。
+在**高级用户指南**中你将学习如何使用它们,以及它们如何集成进 **FastAPI**。
-## 小结
+## 小结 { #recap }
-至此,您可以使用 OAuth2 和 JWT 等标准配置安全的 **FastAPI** 应用。
+通过目前所学内容,你可以使用 OAuth2 和 JWT 等标准来搭建一个安全的 **FastAPI** 应用。
-几乎在所有框架中,处理安全问题很快都会变得非常复杂。
+在几乎任何框架中,处理安全问题都会很快变得相当复杂。
-有些包为了简化安全流,不得不在数据模型、数据库和功能上做出妥协。而有些过于简化的软件包其实存在了安全隐患。
+许多把安全流程大幅简化的包,往往要在数据模型、数据库和可用特性上做出大量妥协。而有些过度简化的包实际上在底层存在安全隐患。
---
-**FastAPI** 不向任何数据库、数据模型或工具做妥协。
+**FastAPI** 不会在任何数据库、数据模型或工具上做妥协。
-开发者可以灵活选择最适合项目的安全机制。
+它给予你完全的灵活性,选择最适合你项目的方案。
-还可以直接使用 `passlib` 和 `PyJWT` 等维护良好、使用广泛的包,这是因为 **FastAPI** 不需要任何复杂机制,就能集成外部的包。
+而且你可以直接使用许多维护良好、广泛使用的包,比如 `pwdlib` 和 `PyJWT`,因为 **FastAPI** 不需要复杂机制来集成外部包。
-而且,**FastAPI** 还提供了一些工具,在不影响灵活、稳定和安全的前提下,尽可能地简化安全机制。
+同时它也为你提供尽可能简化流程的工具,而不牺牲灵活性、健壮性或安全性。
-**FastAPI** 还支持以相对简单的方式,使用 OAuth2 等安全、标准的协议。
+你可以以相对简单的方式使用和实现像 OAuth2 这样的安全、标准协议。
-**高级用户指南**中详细介绍了 OAuth2**`scopes`**的内容,遵循同样的标准,实现更精密的权限系统。OAuth2 的作用域是脸书、谷歌、GitHub、微软、推特等第三方身份验证应用使用的机制,让用户授权第三方应用与 API 交互。
+在**高级用户指南**中,你可以进一步了解如何使用 OAuth2 的 “scopes”,以遵循相同标准实现更细粒度的权限系统。带作用域的 OAuth2 是许多大型身份认证提供商(如 Facebook、Google、GitHub、Microsoft、X(Twitter)等)用来授权第三方应用代表其用户与其 API 交互的机制。
diff --git a/docs/zh/docs/tutorial/security/simple-oauth2.md b/docs/zh/docs/tutorial/security/simple-oauth2.md
index f70678df8f..3037a983b3 100644
--- a/docs/zh/docs/tutorial/security/simple-oauth2.md
+++ b/docs/zh/docs/tutorial/security/simple-oauth2.md
@@ -1,8 +1,8 @@
-# OAuth2 实现简单的 Password 和 Bearer 验证
+# OAuth2 实现简单的 Password 和 Bearer 验证 { #simple-oauth2-with-password-and-bearer }
本章添加上一章示例中欠缺的部分,实现完整的安全流。
-## 获取 `username` 和 `password`
+## 获取 `username` 和 `password` { #get-the-username-and-password }
首先,使用 **FastAPI** 安全工具获取 `username` 和 `password`。
@@ -18,7 +18,7 @@ OAuth2 规范要求使用**密码流**时,客户端或用户必须以表单数
该规范要求必须以表单数据形式发送 `username` 和 `password`,因此,不能使用 JSON 对象。
-### `Scope`(作用域)
+### `scope` { #scope }
OAuth2 还支持客户端发送**`scope`**表单字段。
@@ -32,7 +32,7 @@ OAuth2 还支持客户端发送**`scope`**表单字段。
* 脸书和 Instagram 使用 `instagram_basic`
* 谷歌使用 `https://www.googleapis.com/auth/drive`
-/// info | 说明
+/// info | 信息
OAuth2 中,**作用域**只是声明指定权限的字符串。
@@ -44,15 +44,15 @@ OAuth2 中,**作用域**只是声明指定权限的字符串。
///
-## 获取 `username` 和 `password` 的代码
+## 获取 `username` 和 `password` 的代码 { #code-to-get-the-username-and-password }
接下来,使用 **FastAPI** 工具获取用户名与密码。
-### `OAuth2PasswordRequestForm`
+### `OAuth2PasswordRequestForm` { #oauth2passwordrequestform }
首先,导入 `OAuth2PasswordRequestForm`,然后,在 `/token` *路径操作* 中,用 `Depends` 把该类作为依赖项。
-{* ../../docs_src/security/tutorial003.py hl[4,76] *}
+{* ../../docs_src/security/tutorial003_an_py310.py hl[4,78] *}
`OAuth2PasswordRequestForm` 是用以下几项内容声明表单请求体的类依赖项:
@@ -72,7 +72,7 @@ OAuth2 中,**作用域**只是声明指定权限的字符串。
* 可选的 `client_id`(本例未使用)
* 可选的 `client_secret`(本例未使用)
-/// info | 说明
+/// info | 信息
`OAuth2PasswordRequestForm` 与 `OAuth2PasswordBearer` 一样,都不是 FastAPI 的特殊类。
@@ -84,7 +84,7 @@ OAuth2 中,**作用域**只是声明指定权限的字符串。
///
-### 使用表单数据
+### 使用表单数据 { #use-the-form-data }
/// tip | 提示
@@ -100,9 +100,9 @@ OAuth2 中,**作用域**只是声明指定权限的字符串。
本例使用 `HTTPException` 异常显示此错误:
-{* ../../docs_src/security/tutorial003.py hl[3,77:79] *}
+{* ../../docs_src/security/tutorial003_an_py310.py hl[3,79:81] *}
-### 校验密码
+### 校验密码 { #check-the-password }
至此,我们已经从数据库中获取了用户数据,但尚未校验密码。
@@ -112,7 +112,7 @@ OAuth2 中,**作用域**只是声明指定权限的字符串。
如果密码不匹配,则返回与上面相同的错误。
-#### 密码哈希
+#### 密码哈希 { #password-hashing }
**哈希**是指,将指定内容(本例中为密码)转换为形似乱码的字节序列(其实就是字符串)。
@@ -120,15 +120,15 @@ OAuth2 中,**作用域**只是声明指定权限的字符串。
但这个乱码无法转换回传入的密码。
-##### 为什么使用密码哈希
+##### 为什么使用密码哈希 { #why-use-password-hashing }
原因很简单,假如数据库被盗,窃贼无法获取用户的明文密码,得到的只是哈希值。
这样一来,窃贼就无法在其它应用中使用窃取的密码,要知道,很多用户在所有系统中都使用相同的密码,风险超大。
-{* ../../docs_src/security/tutorial003.py hl[80:83] *}
+{* ../../docs_src/security/tutorial003_an_py310.py hl[82:85] *}
-#### 关于 `**user_dict`
+#### 关于 `**user_dict` { #about-user-dict }
`UserInDB(**user_dict)` 是指:
@@ -144,13 +144,13 @@ UserInDB(
)
```
-/// info | 说明
+/// info | 信息
-`user_dict` 的说明,详见[**更多模型**一章](../extra-models.md#user_indict){.internal-link target=_blank}。
+`user_dict` 的说明,详见[**更多模型**一章](../extra-models.md#about-user-in-dict){.internal-link target=_blank}。
///
-## 返回 Token
+## 返回 Token { #return-the-token }
`token` 端点的响应必须是 JSON 对象。
@@ -162,13 +162,13 @@ UserInDB(
/// tip | 提示
-下一章介绍使用哈希密码和 JWT Token 的真正安全机制。
+下一章介绍使用哈希密码和 JWT Token 的真正安全机制。
但现在,仅关注所需的特定细节。
///
-{* ../../docs_src/security/tutorial003.py hl[85] *}
+{* ../../docs_src/security/tutorial003_an_py310.py hl[87] *}
/// tip | 提示
@@ -182,7 +182,7 @@ UserInDB(
///
-## 更新依赖项
+## 更新依赖项 { #update-the-dependencies }
接下来,更新依赖项。
@@ -194,9 +194,9 @@ UserInDB(
因此,在端点中,只有当用户存在、通过身份验证、且状态为激活时,才能获得该用户:
-{* ../../docs_src/security/tutorial003.py hl[58:67,69:72,90] *}
+{* ../../docs_src/security/tutorial003_an_py310.py hl[58:66,69:74,94] *}
-/// info | 说明
+/// info | 信息
此处返回值为 `Bearer` 的响应头 `WWW-Authenticate` 也是规范的一部分。
@@ -210,15 +210,15 @@ UserInDB(
说不定什么时候,就有工具用得上它,而且,开发者或用户也可能用得上。
-这就是遵循标准的好处……
+这就是遵循标准的好处...
///
-## 实际效果
+## 实际效果 { #see-it-in-action }
打开 API 文档:http://127.0.0.1:8000/docs。
-### 身份验证
+### 身份验证 { #authenticate }
点击**Authorize**按钮。
@@ -228,13 +228,13 @@ UserInDB(
密码:`secret`
-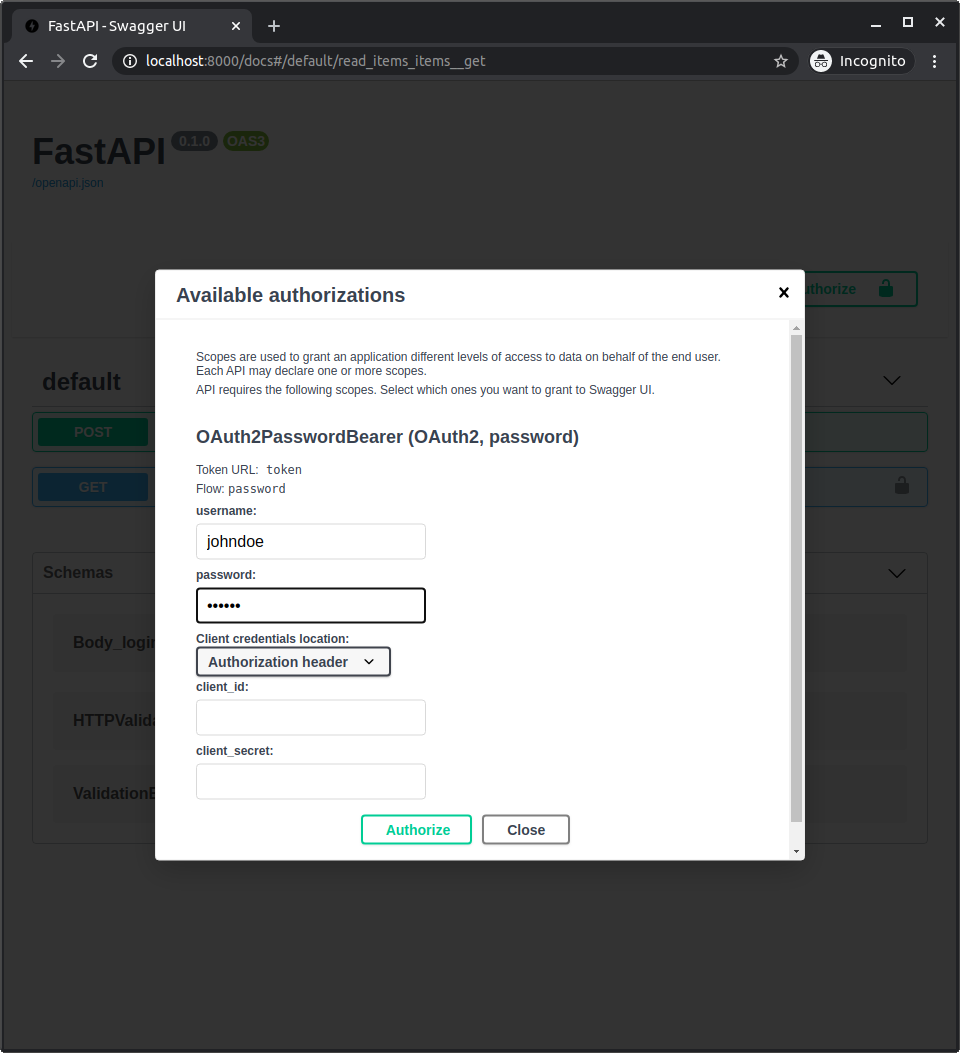 +
+ 通过身份验证后,显示下图所示的内容:
-
通过身份验证后,显示下图所示的内容:
-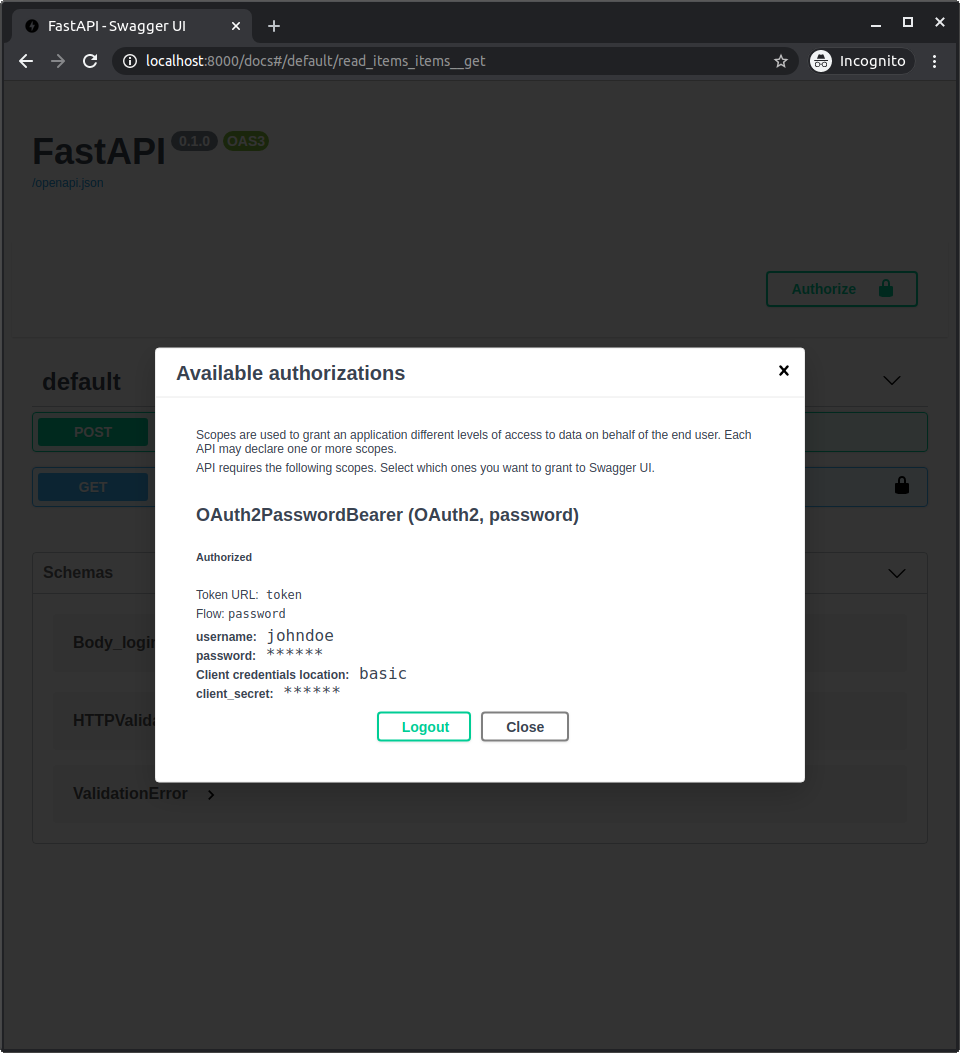 +
+ -### 获取当前用户数据
+### 获取当前用户数据 { #get-your-own-user-data }
使用 `/users/me` 路径的 `GET` 操作。
@@ -250,7 +250,7 @@ UserInDB(
}
```
-
-### 获取当前用户数据
+### 获取当前用户数据 { #get-your-own-user-data }
使用 `/users/me` 路径的 `GET` 操作。
@@ -250,7 +250,7 @@ UserInDB(
}
```
-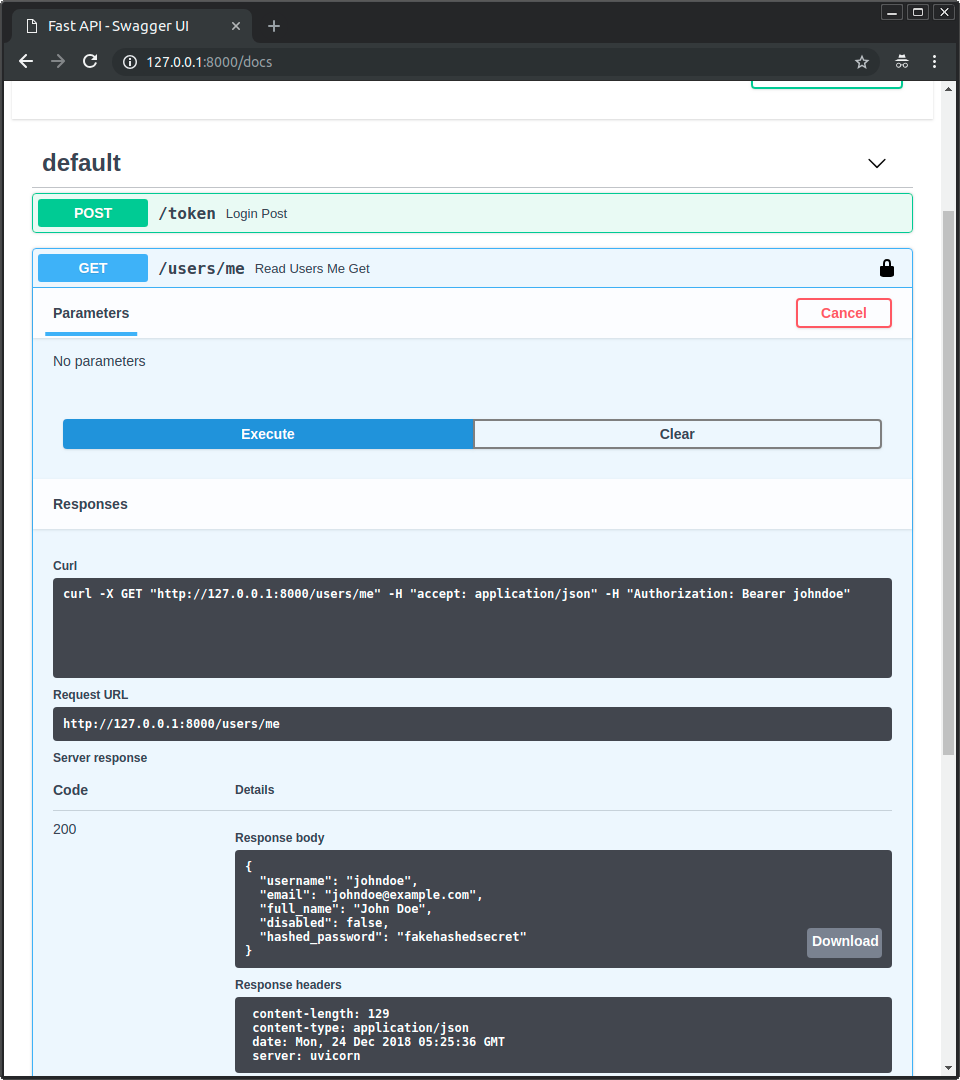 +
+ 点击小锁图标,注销后,再执行同样的操作,则会得到 HTTP 401 错误:
@@ -260,7 +260,7 @@ UserInDB(
}
```
-### 未激活用户
+### 未激活用户 { #inactive-user }
测试未激活用户,输入以下信息,进行身份验证:
@@ -278,7 +278,7 @@ UserInDB(
}
```
-## 小结
+## 小结 { #recap }
使用本章的工具实现基于 `username` 和 `password` 的完整 API 安全系统。
@@ -286,4 +286,4 @@ UserInDB(
唯一欠缺的是,它仍然不是真的**安全**。
-下一章,介绍使用密码哈希支持库与 JWT 令牌实现真正的安全机制。
+下一章,介绍使用密码哈希支持库与 JWT 令牌实现真正的安全机制。
diff --git a/docs/zh/docs/tutorial/sql-databases.md b/docs/zh/docs/tutorial/sql-databases.md
index fbdf3be6cc..944e960a76 100644
--- a/docs/zh/docs/tutorial/sql-databases.md
+++ b/docs/zh/docs/tutorial/sql-databases.md
@@ -1,40 +1,40 @@
-# SQL(关系型)数据库
+# SQL(关系型)数据库 { #sql-relational-databases }
-**FastAPI** 并不要求您使用 SQL(关系型)数据库。您可以使用**任何**想用的数据库。
+**FastAPI** 并不要求你使用 SQL(关系型)数据库。你可以使用你想用的**任何数据库**。
这里,我们来看一个使用 SQLModel 的示例。
-**SQLModel** 是基于 SQLAlchemy 和 Pydantic 构建的。它由 **FastAPI** 的同一作者制作,旨在完美匹配需要使用 **SQL 数据库**的 FastAPI 应用程序。
+**SQLModel** 基于 SQLAlchemy 和 Pydantic 构建。它由 **FastAPI** 的同一作者制作,旨在完美匹配需要使用**SQL 数据库**的 FastAPI 应用程序。
-/// tip
+/// tip | 提示
-您可以使用任何其他您想要的 SQL 或 NoSQL 数据库(在某些情况下称为 “ORM”),FastAPI 不会强迫您使用任何东西。😎
+你可以使用任意其他你想要的 SQL 或 NoSQL 数据库库(在某些情况下称为 "ORMs"),FastAPI 不会强迫你使用任何东西。😎
///
-由于 SQLModel 基于 SQLAlchemy,因此您可以轻松使用任何由 SQLAlchemy **支持的数据库**(这也让它们被 SQLModel 支持),例如:
+由于 SQLModel 基于 SQLAlchemy,因此你可以轻松使用任何由 SQLAlchemy **支持的数据库**(这也让它们被 SQLModel 支持),例如:
* PostgreSQL
* MySQL
* SQLite
* Oracle
-* Microsoft SQL Server 等.
+* Microsoft SQL Server 等
-在这个例子中,我们将使用 **SQLite**,因为它使用单个文件,并且 Python 对其有集成支持。因此,您可以直接复制这个例子并运行。
+在这个示例中,我们将使用 **SQLite**,因为它使用单个文件,并且 Python 对其有集成支持。因此,你可以直接复制这个示例并运行。
-之后,对于您的生产应用程序,您可能会想要使用像 PostgreSQL 这样的数据库服务器。
+之后,对于你的生产应用程序,你可能会想要使用像 **PostgreSQL** 这样的数据库服务器。
-/// tip
+/// tip | 提示
-有一个使用 **FastAPI** 和 **PostgreSQL** 的官方的项目生成器,其中包括了前端和更多工具: https://github.com/fastapi/full-stack-fastapi-template
+有一个使用 **FastAPI** 和 **PostgreSQL** 的官方项目生成器,其中包括了前端和更多工具: https://github.com/fastapi/full-stack-fastapi-template
///
-这是一个非常简单和简短的教程。如果您想了解一般的数据库、SQL 或更高级的功能,请查看 SQLModel 文档。
+这是一个非常简单和简短的教程。如果你想了解一般的数据库、SQL 或更高级的功能,请查看 SQLModel 文档。
-## 安装 `SQLModel`
+## 安装 `SQLModel` { #install-sqlmodel }
-首先,确保您创建并激活了[虚拟环境](../virtual-environments.md){.internal-link target=_blank},然后安装了 `sqlmodel` :
+首先,确保你创建并激活了[虚拟环境](../virtual-environments.md){.internal-link target=_blank},然后安装 `sqlmodel`:
点击小锁图标,注销后,再执行同样的操作,则会得到 HTTP 401 错误:
@@ -260,7 +260,7 @@ UserInDB(
}
```
-### 未激活用户
+### 未激活用户 { #inactive-user }
测试未激活用户,输入以下信息,进行身份验证:
@@ -278,7 +278,7 @@ UserInDB(
}
```
-## 小结
+## 小结 { #recap }
使用本章的工具实现基于 `username` 和 `password` 的完整 API 安全系统。
@@ -286,4 +286,4 @@ UserInDB(
唯一欠缺的是,它仍然不是真的**安全**。
-下一章,介绍使用密码哈希支持库与 JWT 令牌实现真正的安全机制。
+下一章,介绍使用密码哈希支持库与 JWT 令牌实现真正的安全机制。
diff --git a/docs/zh/docs/tutorial/sql-databases.md b/docs/zh/docs/tutorial/sql-databases.md
index fbdf3be6cc..944e960a76 100644
--- a/docs/zh/docs/tutorial/sql-databases.md
+++ b/docs/zh/docs/tutorial/sql-databases.md
@@ -1,40 +1,40 @@
-# SQL(关系型)数据库
+# SQL(关系型)数据库 { #sql-relational-databases }
-**FastAPI** 并不要求您使用 SQL(关系型)数据库。您可以使用**任何**想用的数据库。
+**FastAPI** 并不要求你使用 SQL(关系型)数据库。你可以使用你想用的**任何数据库**。
这里,我们来看一个使用 SQLModel 的示例。
-**SQLModel** 是基于 SQLAlchemy 和 Pydantic 构建的。它由 **FastAPI** 的同一作者制作,旨在完美匹配需要使用 **SQL 数据库**的 FastAPI 应用程序。
+**SQLModel** 基于 SQLAlchemy 和 Pydantic 构建。它由 **FastAPI** 的同一作者制作,旨在完美匹配需要使用**SQL 数据库**的 FastAPI 应用程序。
-/// tip
+/// tip | 提示
-您可以使用任何其他您想要的 SQL 或 NoSQL 数据库(在某些情况下称为 “ORM”),FastAPI 不会强迫您使用任何东西。😎
+你可以使用任意其他你想要的 SQL 或 NoSQL 数据库库(在某些情况下称为 "ORMs"),FastAPI 不会强迫你使用任何东西。😎
///
-由于 SQLModel 基于 SQLAlchemy,因此您可以轻松使用任何由 SQLAlchemy **支持的数据库**(这也让它们被 SQLModel 支持),例如:
+由于 SQLModel 基于 SQLAlchemy,因此你可以轻松使用任何由 SQLAlchemy **支持的数据库**(这也让它们被 SQLModel 支持),例如:
* PostgreSQL
* MySQL
* SQLite
* Oracle
-* Microsoft SQL Server 等.
+* Microsoft SQL Server 等
-在这个例子中,我们将使用 **SQLite**,因为它使用单个文件,并且 Python 对其有集成支持。因此,您可以直接复制这个例子并运行。
+在这个示例中,我们将使用 **SQLite**,因为它使用单个文件,并且 Python 对其有集成支持。因此,你可以直接复制这个示例并运行。
-之后,对于您的生产应用程序,您可能会想要使用像 PostgreSQL 这样的数据库服务器。
+之后,对于你的生产应用程序,你可能会想要使用像 **PostgreSQL** 这样的数据库服务器。
-/// tip
+/// tip | 提示
-有一个使用 **FastAPI** 和 **PostgreSQL** 的官方的项目生成器,其中包括了前端和更多工具: https://github.com/fastapi/full-stack-fastapi-template
+有一个使用 **FastAPI** 和 **PostgreSQL** 的官方项目生成器,其中包括了前端和更多工具: https://github.com/fastapi/full-stack-fastapi-template
///
-这是一个非常简单和简短的教程。如果您想了解一般的数据库、SQL 或更高级的功能,请查看 SQLModel 文档。
+这是一个非常简单和简短的教程。如果你想了解一般的数据库、SQL 或更高级的功能,请查看 SQLModel 文档。
-## 安装 `SQLModel`
+## 安装 `SQLModel` { #install-sqlmodel }
-首先,确保您创建并激活了[虚拟环境](../virtual-environments.md){.internal-link target=_blank},然后安装了 `sqlmodel` :
+首先,确保你创建并激活了[虚拟环境](../virtual-environments.md){.internal-link target=_blank},然后安装 `sqlmodel`:

